Traducción del tutorial de la API de detección de objetos TensorFlow - Capacitación y evaluación del detector de objetos personalizado .Todos sabemos conducir un automóvil, es bastante fácil, ¿verdad? Pero, ¿qué harás si alguien te pide que subas al avión? Así es, leerás las instrucciones. Del mismo modo, el siguiente manual lo ayudará a configurar su API y disfrutar de un vuelo agradable.
En primer lugar, clone el repositorio por
referencia . Espero que ya tengas instalado
TensorFlow .
git clone github.com/tensorflow/models.gitEn el aprendizaje automático, generalmente entrenamos y probamos un modelo usando un archivo CSV. Pero en este caso, actuamos de acuerdo con el esquema que se muestra en la figura:

Antes de continuar, detengámonos en la estructura de directorios que usaremos.
- datos / - Esto contendrá registros y archivos CSV.
- images / - Aquí hay un conjunto de datos para entrenar a nuestro modelo.
- formación / - Aquí guardamos el modelo entrenado.
- eval / - Esto almacenará los resultados de la evaluación del modelo.
Paso 1: guardar imágenes en CSV
Aquí todo es bastante simple. No profundizaremos en esta tarea, solo daré algunos enlaces útiles.
Nuestra tarea es etiquetar la imagen y crear archivos train.CSV y test.CSV.
- Con la herramienta labelImg, marque la imagen. Cómo hacer esto, mira aquí .
- Convierta XML a CSV, como se muestra aquí .
Hay muchas formas de crear archivos CSV, más o menos adecuados para trabajar con cada conjunto de datos específico.
Como parte de nuestro proyecto, intentaremos lograr la detección de ganglios pulmonares utilizando el
conjunto de datos LUNA . Las coordenadas de los nodos ya se conocían y, por lo tanto, la creación de archivos CSV no fue difícil. Para encontrar los nodos, utilizamos las 6 coordenadas que se muestran a continuación:
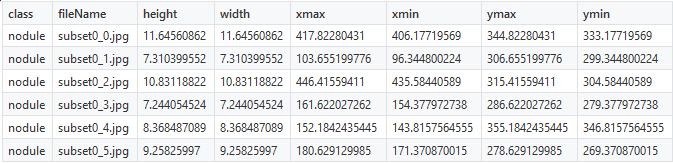
Debe corregir solo el nombre de los
nodules clase (nodos), todo lo demás permanecerá sin cambios. Una vez que los objetos marcados se presentan en forma de números, puede proceder a la creación de TFRecords.
Paso 2: crea TFRecords
La API de detección de objetos TensorFlow no acepta entradas para entrenar el modelo en formato CSV, por lo que debe crear TFRecords utilizando
este archivo. """ Usage: # From tensorflow/models/ # Create train data: python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=train.record # Create test data: python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record """ from __future__ import division from __future__ import print_function from __future__ import absolute_import import os import io import pandas as pd import tensorflow as tf from PIL import Image from object_detection.utils import dataset_util from collections import namedtuple, OrderedDict flags = tf.app.flags flags.DEFINE_string('csv_input', '', 'Path to the CSV input') flags.DEFINE_string('output_path', '', 'Path to output TFRecord') FLAGS = flags.FLAGS
Después de descargar el archivo, realice un pequeño cambio: en la línea 31, en lugar de la palabra
raccoon ponga su propia marca. En el ejemplo dado, estos son
nodules , nodos. Si su modelo necesita definir varios tipos de objetos, cree clases adicionales.
Nota La numeración de las etiquetas debe comenzar desde uno, no desde cero. Por ejemplo, si usa tres tipos de objetos, se les debe asignar los valores 1, 2 y 3, respectivamente.Use el siguiente código para crear el archivo
train.record :
python generate_tfRecord.py --CSV_input=data/train.CSV --output_path=data/train.record
Use el siguiente código para crear el archivo
test.record :
python generate_tfrecord.py — CSV_input=data/test.CSV — output_path=data/test.record
Paso 3: entrenamiento modelo
Una vez que se crean los archivos que necesitamos, estamos casi listos para comenzar a aprender.
- Seleccione el modelo a enseñar. Debe encontrar un compromiso entre velocidad y precisión: cuanto mayor sea la velocidad, menor será la precisión de la determinación y viceversa. Aquí,
sd_mobilenet_v1_coco usa como ejemplo. - Después de decidir con qué modelo trabajará, descargue el archivo de configuración apropiado . En este ejemplo, esto es
ssd_mobilenet_v1_coco.config . - Cree un archivo object-detect.pbtxt que tenga este aspecto:
item { id: 1 name: 'nodule' }
Dale al nodule nombre diferente. Si hay varias clases, aumente el valor de id e ingrese nuevos nombres.
Es hora de configurar el archivo de configuración, haciendo los siguientes ajustes.
Cambie el número de clases de acuerdo a sus requerimientos.
Si la potencia de su GPU es insuficiente, baje el valor del
batch_size del
batch_size .
batch_size: 24
Especifique la ruta al modelo
ssd_mobilenet_v1_coco que hemos descargado anteriormente.
Especifique la ruta al archivo
train.record .
Especifique la ruta al archivo
test.record.
Ahora copie las carpetas de
datos / e
imágenes / a las carpetas de
modelos / investigación / detección de objetos . Si se le solicita que combine carpetas, acéptelo.
Además, necesitaremos el archivo
train.py ubicado en el
directorio de detección de objetos /
. cd models/research/object-detection
Cree la carpeta de
entrenamiento / en la carpeta /
detección de objetos . Está en
formación / salvaremos nuestro modelo. Copie
ssd_mobilenet_v1_coco.config en el
archivo de entrenamiento / configuración. El entrenamiento se realiza usando el comando:
python train.py --logtostderr \ --train_dir=training/ \ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config
Si todo va según el plan, verá cómo cambia la función de pérdida en cada etapa.
Paso 4: Evaluación del modelo
Finalmente, evaluamos el modelo almacenado en el directorio
training / . Para hacer esto, ejecute el archivo
eval.py e ingrese el siguiente comando:
python eval.py \ --logtostderr \ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config \ --checkpoint_dir=training/ \ --eval_dir=eval/
Los resultados de la verificación se reflejarán en la carpeta
eval / . Se pueden visualizar con TensorBoard.
Abra el enlace a través de un navegador. En la pestaña
Imágenes , verá los resultados del modelo:
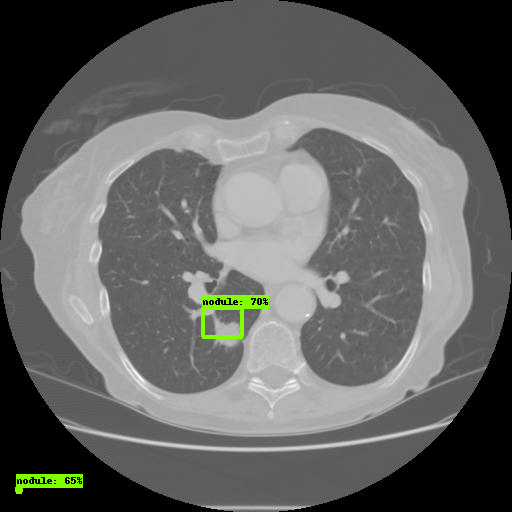
Eso es todo, ha configurado correctamente la API de detección de objetos TensorFlow.
Uno de los errores más comunes:
No module named deployment on object_detection/train.pySe resuelve usando el comando:
Puede leer sobre las formas de cambiar los parámetros Faster-RCNN / SSD
aquí .
Gracias por su atencion!