Hola Habr!
Hoy quiero hablar sobre la segunda parte del proyecto de servicio para la identificación y clasificación de obras de arte. Permíteme recordarte que resolvimos dos tareas principales:
- buscar una imagen en la base de datos de una fotografía tomada por un teléfono móvil;
- determinación del estilo y género de una imagen que no está en la base de datos.
Hoy consideraremos el uso de una red neuronal convolucional para clasificar imágenes por estilo y género.

¿Ayuda a Dasha a entender el arte contemporáneo?
Determinando el estilo de las pinturas
De casi 250,000 pinturas en la base de datos de Arthive, a menos del 20% se le asigna un género, estilo o técnica, a menudo las clases que se muestran en la base de datos no corresponden a los valores verdaderos, muchas clases que contienen muy pocas imágenes. Parece que incluso hay clases que contienen unidades de imágenes. Aparentemente, algunos autores consideran necesario crear un nombre para su propio estilo.
En total, se asignaron alrededor de 75 estilos en la base de datos, sin embargo, para nuestro trabajo, el cliente seleccionó 27 estilos obligatorios (a los que posteriormente se agregó otro), que el sistema debe reconocer.
Para ellos, la distribución del relleno resultó ser muy desigual.
| Estilo | cantidad | Estilo | cantidad |
|---|
| Realismo | 19594 | Primitivismo | 1234 |
| Impresionismo | 15864 | Art Decó | 1092 |
| Romanticismo | 8963 | Renacimiento del norte | 921 |
| Barroco | 7726 | Cubismo | 902 |
| Moderno | 4882 | Academicismo | 707 |
| Surrealismo | 4793 | Gótico | 608 |
| Renacimiento | 4709 | Modernismo | 539 |
| Expresionismo | 4329 | Realismo socialista | 481 |
| Simbolismo | 4321 | Arte pop | 475 |
| Postimpresionismo | 3951 | Puntillismo | 275 |
| Arte abstracto | 3664 | Fauvismo | 217 |
| Ukiyo-e | 3136 | Vanguardia | 174 |
| Clasicismo | 1730 | Hiperrealismo | 13 |
| Rococó | 1600 | Fantasía | 8 |
| | Total | 96908 |
Todos los estilos| Estilo | cantidad | Estilo | cantidad | Estilo | cantidad |
|---|
| Realismo | 19594 | Arte pop | 475 | Decorativismo | 66 |
| Impresionismo | 15864 | Biedermeier | 471 | Minimalismo | 66 |
| Romanticismo | 8963 | Realismo fantástico | 386 | Sentimentalismo | 66 |
| Barroco | 7726 | Expresionismo abstracto | 358 | Cloisonismo | 60 60 |
| Moderno | 4882 | Nabis | 339 | Pintura metafísica | 56 |
| Surrealismo | 4793 | Puntillismo | 275 | Machiaioli | 52 |
| Renacimiento | 4709 | Suprematismo | 273 | Orfismo | 51 |
| Expresionismo | 4329 | Prerrafaelitas | 252 | Dada | 50 |
| Simbolismo | 4321 | Realismo mágico | 248 | Neoimpresionismo | 49 |
| Postimpresionismo | 3951 | Renacimiento temprano | 232 | Luminismo | 41 |
| Arte abstracto | 3664 | Neoexpresionismo | 230 | Proto-renacimiento | 39 |
| La edad de oro de Holanda | 3292 | Fauvismo | 217 | Plantanismo | 37 |
| Ukiyo-e | 3136 | Posmodernismo | 192 | Tenebrizm | 35 |
| Clasicismo | 1730 | Vanguardia | 174 | Impresionismo abstracto | 34 |
| Rococó | 1600 | Arte contemporáneo | 149 | Conceptualismo | 29 |
| Primitivismo | 1234 | Precisión | 138 | Japonismo | 24 |
| Art Decó | 1092 | Cubofuturismo | 108 | Posmoderna | 24 |
| Renacimiento del norte | 921 | Constructivismo | 104 | Luchismo | 24 |
| Cubismo | 902 | Tonalismo | 103 | Bizantino | 20 |
| Academicismo | 707 | Orfismo | 94 | Realismo romantico | 19 |
| Gótico | 608 | Regionalismo | 93 | Hiperrealismo | 13 |
| Neoclasicismo | 601 | Realismo analítico | 89 | Verismo | 11 |
| Manierismo | 544 | Naturalismo | 73 | Neo-primitivismo | 10 |
| Modernismo | 539 | Neo-modernismo | 70 | Fantasía | 8 |
| Realismo socialista | 481 | Futurismo | 67 | Metarealismo | 7 7 |
| | | | Total | 106284 |
Nos enfrentamos a la tarea de clasificar imágenes, pero no podemos seleccionar ninguna característica simple manualmente. Por lo tanto, utilizaremos el aprendizaje automático profundo, en el que características tan complejas se identifican automáticamente en el proceso de aprendizaje.
Transferencia de aprendizaje
Considere la red de inicio v3.
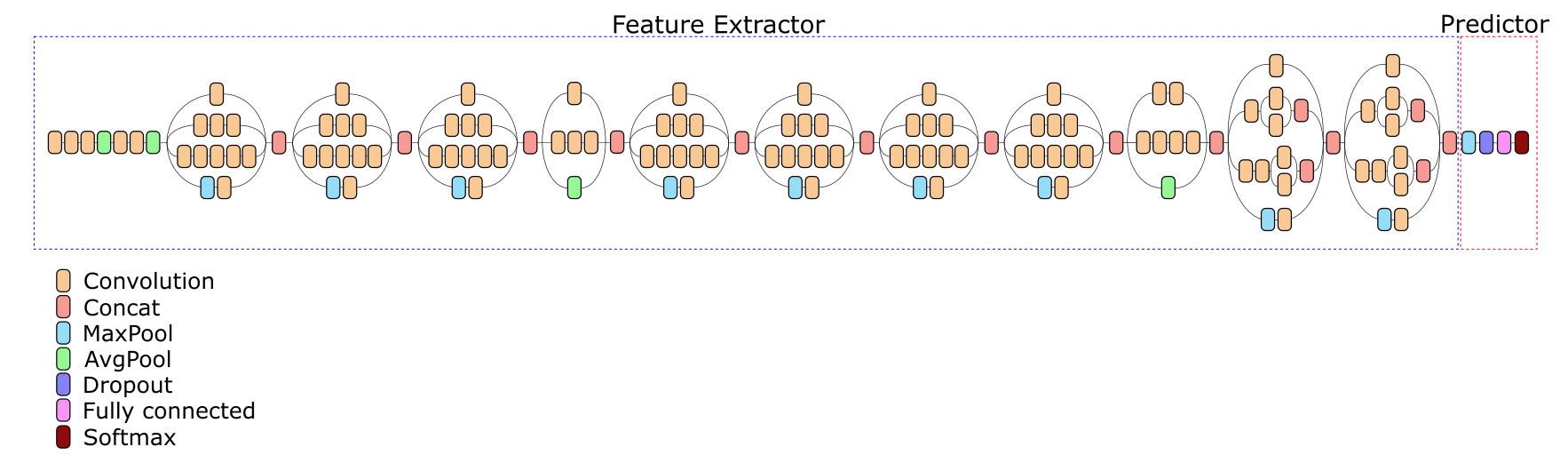
En su arquitectura (y en cualquier otra red profunda), dos componentes principales se pueden distinguir condicionalmente: Feature Extractor y Predictor.
Feature Extractor asigna la imagen de color de entrada en un espacio de características multidimensional (mapa de características multicanal). El mapa de características almacena información espacial, es decir, es un tensor tridimensional con dimensiones para el ancho, la altura y el número de canales de características; la agrupación final aún no se ha aplicado aquí, lo que eliminará por completo la información sobre la posición relativa de las características en la imagen original. La red Inception v3 Feature Extractor recibe 299 imágenes de entrada 299 3, y en la salida forma un mapa de signos de tamaño 17 17 2048. El tamaño de entrada puede variar, lo que conducirá a cambios en el tamaño del mapa de características y puede ser útil para reducir los costos computacionales cuando se trabaja con la red.
Predictor es una red que genera resultados basados en un mapa de características generado por Feature Extractor. Como regla general, para la tarea de clasificación, Predictor es una capa de neuronas completamente conectada, cuyo número de salidas coincide con el número de clases del problema.
El aprendizaje de transferencia clásico supone que tomamos una red capacitada, separamos Feature Extractor de ella y la complementamos con un nuevo predictor con la cantidad de clases que necesitamos. La red resultante se entrena a baja velocidad con pesos parcial o completamente congelados de capas de Extractor de características.
Aplicamos el aprendizaje de transferencia para clasificar estilos. Tome la red Inception-v3 entrenada en un conjunto de datos imagenet y reemplace la capa de salida de neuronas en ella, que clasifica las imágenes de entrada en el número de estilos seleccionados. Capacitamos a la red en imágenes de diferentes estilos, congelando la capacitación de todas las capas, excepto la última.
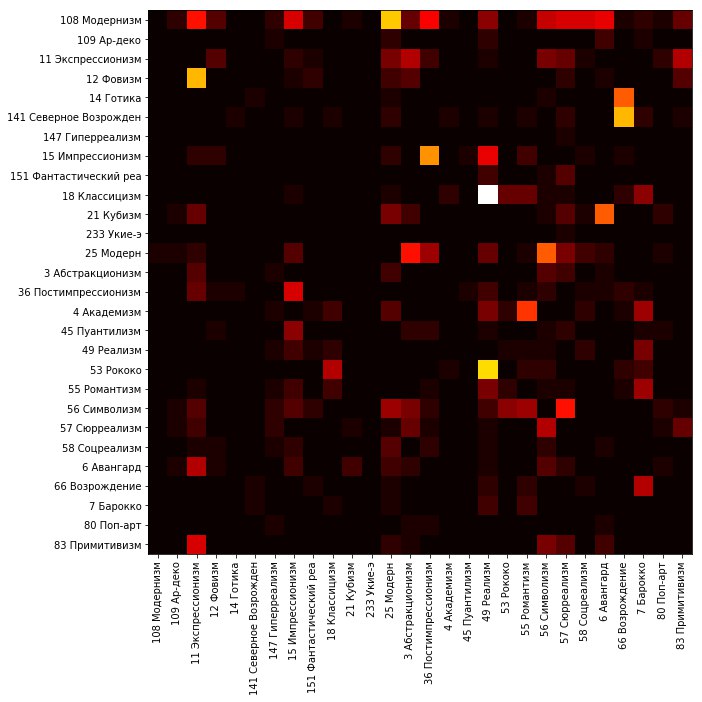
Para el análisis de datos, mostramos la distribución del conjunto de validación por clase.

Cada fila corresponde a una clase del conjunto de validación. El brillo de los cuadrados en la fila es proporcional al número de imágenes que caen en la clase correspondiente a la columna.
Para mayor claridad, excluimos la diagonal principal y re-normalizamos los valores de cada fila.
Además, intentaremos mapear la distribución de estilos al espacio bidimensional usando TSNE.
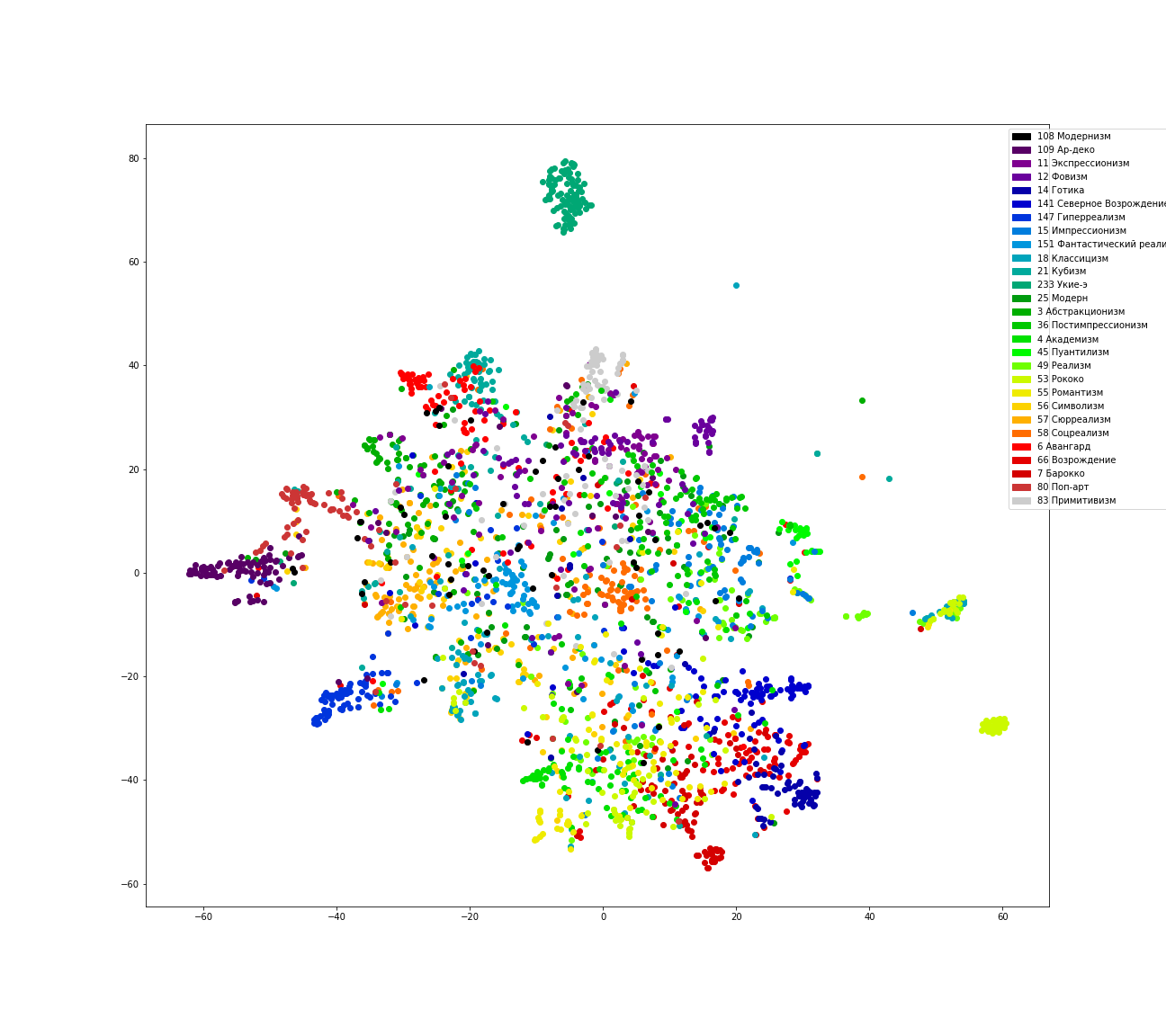
Se puede observar que se observan muchos errores, por ejemplo, en la clasificación de pinturas al estilo del fauvismo; una parte importante de ellas se refiere al expresionismo de la red. El Renacimiento del Norte y el gótico a menudo se conocen como renacimiento. Muchas imágenes del estilo rococó y el clasicismo se relacionan con el realismo. El modernismo y la modernidad generalmente caen en muchos estilos.
Después de lanzar un script simple que analizaba la base de datos de capacitación en carpetas de acuerdo con el estilo definido por la red, realizamos un análisis rápido de errores. Resultó que el marcado de la base de datos al menos plantea preguntas.
Muchas imágenes en el estilo del modernismo (que, aunque fue marcado por el cliente como obligatorio, pero en general no es un estilo, sino una tendencia en el arte en general), en realidad se duplicaron en otros estilos, especialmente en el modernismo (pero este ya es un estilo).
En el estilo del realismo socialista, estaban presentes imágenes abstractas, por ejemplo, las obras de Lissitzky. Lo más probable es que llegaron allí gracias al trabajo de Lissitzky en el cartel soviético, que tiene una relación muy indirecta con el realismo socialista.
En muchos sentidos, estos son realmente errores, pero a veces la razón es la debatibilidad del tema de resaltar algunos estilos, especialmente modernos. Vale la pena considerar que la base de datos está llena de varios usuarios, y entre ellos a veces no hay consenso.
Los errores en los datos conducen a errores correspondientes en la clasificación de imágenes por la red. En el proceso de limpieza de la base, tanto por nosotros como por el crítico de arte experto por parte del cliente, el margen de beneficio para la muestra de capacitación se mejoró significativamente.
Sin embargo, el grueso de los errores de clasificación de la red (en total) se refiere a estilos más o menos bien establecidos, como el rococó, el clasicismo y el realismo. La atribución de obras a estos estilos, por regla general, se lleva a cabo sobre la base de una época o autoría y, al parecer, no causa dudas ni disputas. ¿Por qué la red no puede distinguir su estilo? La razón principal radica en el uso de una red pre-entrenada para extraer rasgos.
El hecho es que esta red fue entrenada para clasificar objetos, determinar qué se representa exactamente, al tiempo que descarta información que no es esencial para la tarea sobre cómo se representa. Por ejemplo, desde el punto de vista de la red, en todas las imágenes al comienzo del artículo, en general, se representa a una persona.
Para resolver este problema, creamos una red con salidas intermedias: se cree que los signos se vuelven más difíciles a medida que se mueven a lo largo de la red, y la información no esencial desaparece gradualmente. Tratemos de extraer de las capas intermedias lo que no era esencial para la clasificación de imagenet.
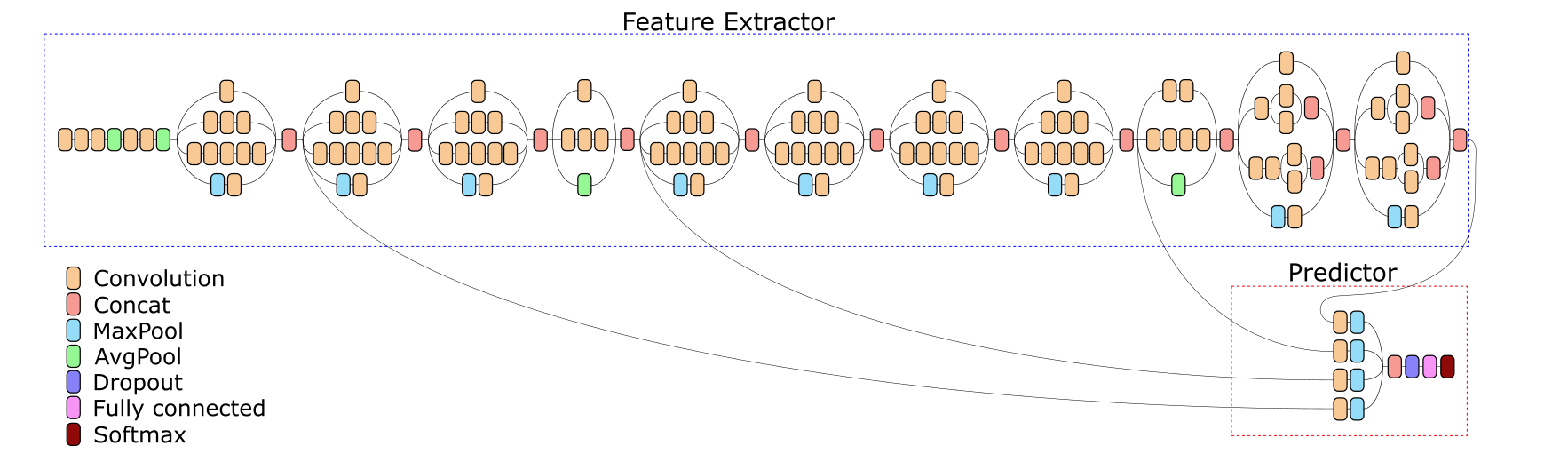
Hay otro problema: gráficos, impresiones, bocetos. En imagenet, en el que la red de inicio se entrenó previamente, simplemente no hay nada como esto, respectivamente, y las características resaltadas por la red no son adecuadas para clasificar tales imágenes.
Por otro lado, las pinturas al estilo de Ukiyo-e , un tipo de grabado que se ha generalizado en Japón desde el siglo XVII, han colgado maravillosamente en una nube separada. Aunque inicialmente no estaban en nuestra lista obligatoria, los agregamos allí.

Después de trabajar con los datos, se logró una mejor distribución entre las clases.
Nos ocupamos de los géneros.
Del número total de géneros, se seleccionaron 13 (resaltados en negrita)
| Género | cantidad |
|---|
| Escena alegórica | 2500 |
| Retrato | 2308 |
| Paisaje | 2213 |
| Fantasía | 2191 |
| Escena literaria | 2096 |
| Paisaje de la ciudad | 2048 |
| Desnudo | 1981 |
| Bodegón | 1932 |
| Escena de género | 1736 |
| Animalismo | 1587 |
| Escena religiosa | 1417 |
| Escena mitológica | 1368 |
| Marina | 1210 |
| Arquitectura | 958 |
| El interior | 635 |
| Escena historica | 534 |
| Escena de batalla | 201 |
| Zakli | 180 |
| Veduta | 124 |
| Paisaje urbano | 16 |
| Total | 27235 |
Básicamente, la reducción en el número de géneros se logró reduciendo los géneros de varias escenas: "religiosa", "mitológica", "alegórica", "literaria" y combinándolas bajo el nombre general de "escena de género". Llegamos a la conclusión de que la separación de estos géneros difícilmente se puede realizar con suficiente precisión sin un análisis cultural significativo.
Por ejemplo, para una escena alegórica, por definición se supone que hay un significado oculto en la imagen, el uso de significados figurativos en los objetos representados. También hay una dificultad con la "escena religiosa": es muy probable que una red entrenada para emitir tal clase también los llame imágenes de caricatura (por ejemplo, parodiando la Última Cena de Da Vinci), y esto puede ofender a alguien .
El marcado de datos por género inicialmente parece ser bueno, excepto por varios géneros para los cuales hay pocas imágenes en la base de datos. Al buscar en Internet, pudimos ampliar ligeramente la cantidad de imágenes en géneros (principalmente la escena de batalla, garzas y vedutas).
Después de combinar géneros difíciles en una "escena de género" común, inmediatamente tratamos de entrenar la red "en la frente" usando redes de aprendizaje de transferencia.
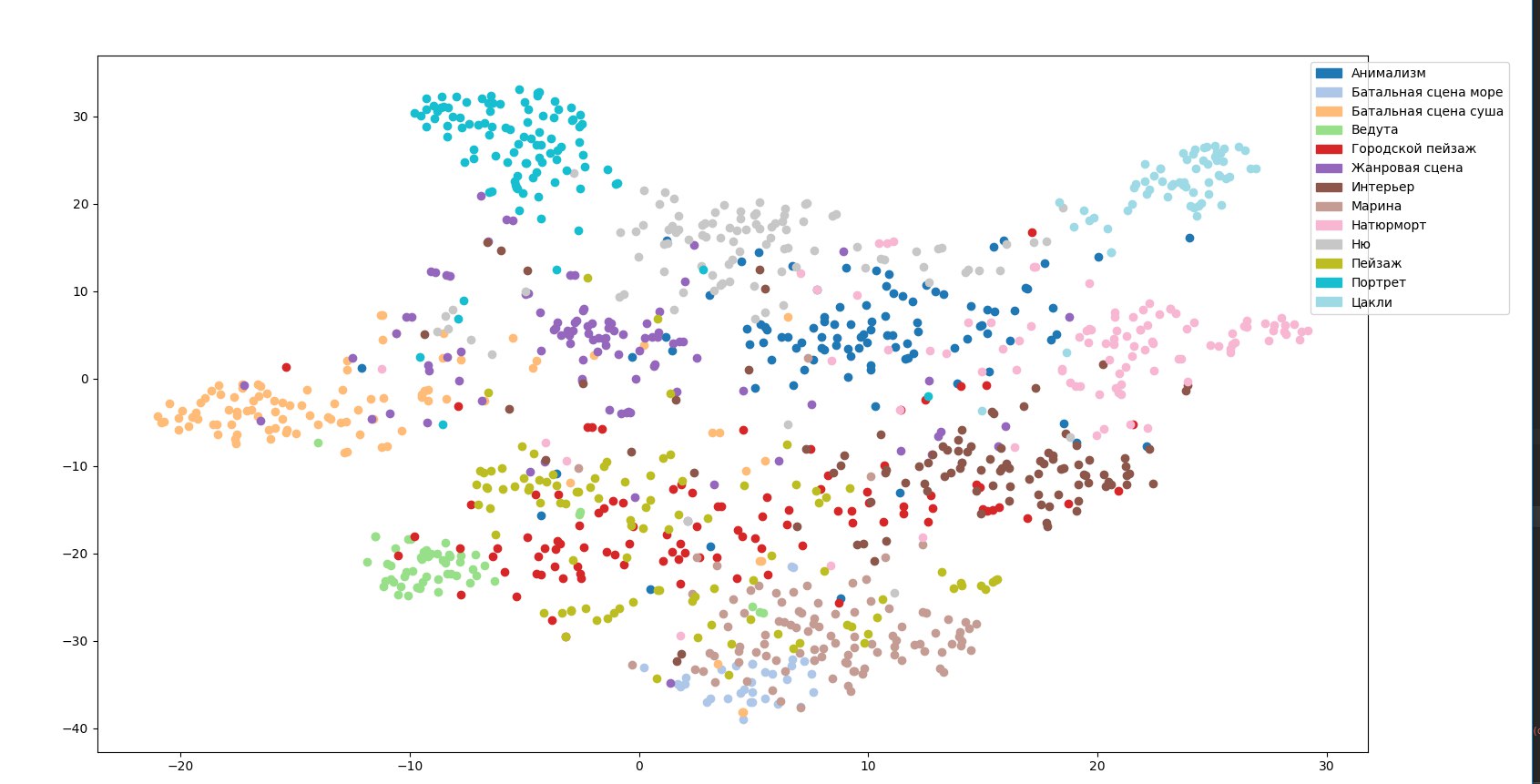
Se puede ver que los puntos correspondientes a imágenes de diferentes géneros se mezclan. Para estas imágenes, la red proporciona valores altos de las probabilidades de pertenecer a varios géneros a la vez, y el género con la probabilidad más alta se determina casi por accidente. Aparentemente, la razón es que los géneros, a diferencia de los estilos, tienen una jerarquía más pronunciada. Intentamos entender estas conexiones, obtuvimos ese mapa de géneros:
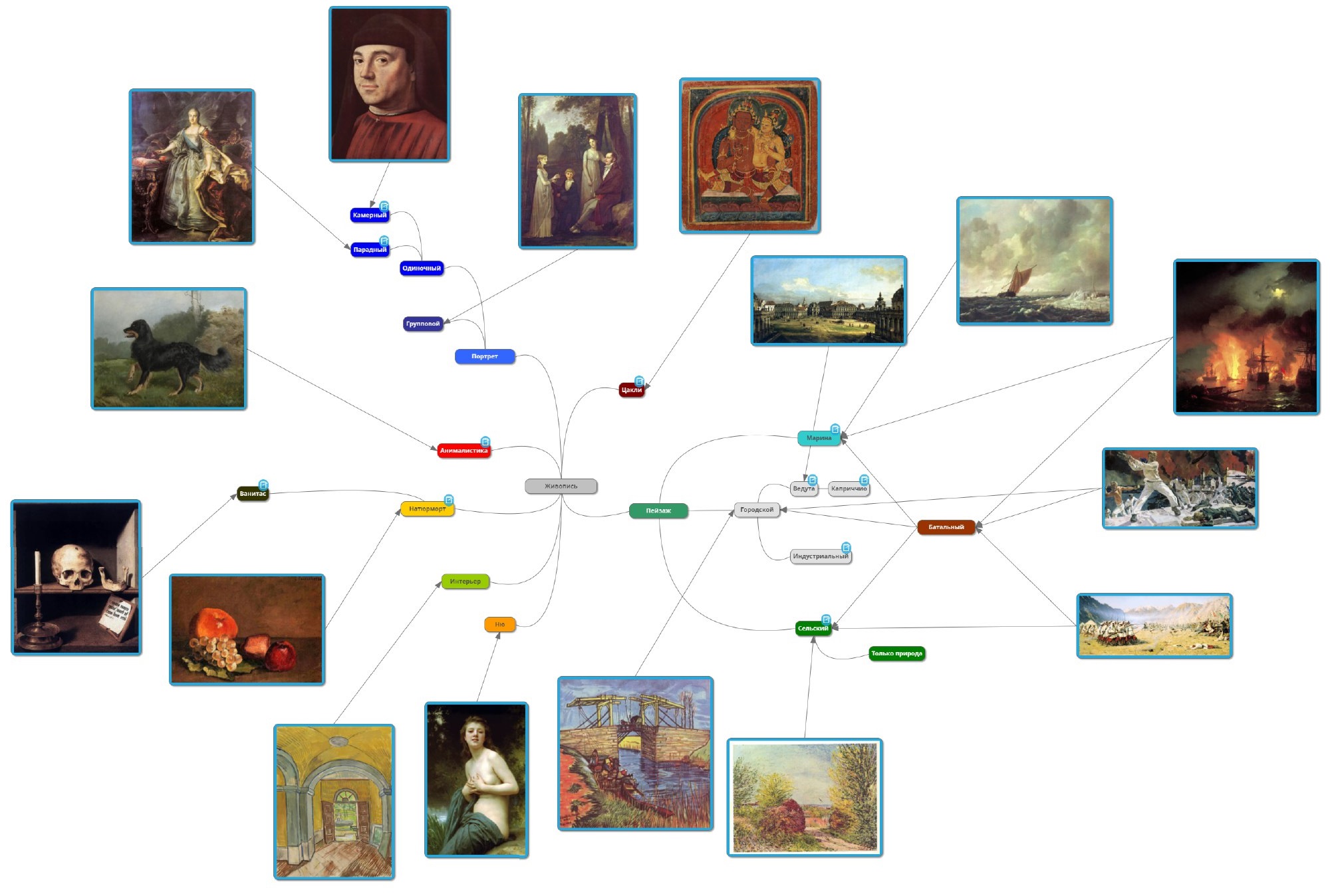
Los géneros de jerarquía subsidiaria y parental a menudo tienen características comunes desde el punto de vista de la red (y también desde nuestro punto de vista). Por ejemplo, la escena de batalla en la tierra en su conjunto tiene las mismas características que el paisaje habitual: la imagen de una gran área abierta o ciudad, y la escena de batalla en el mar es más como el género del puerto deportivo. Por lo tanto, dividimos el género de la escena de batalla en dos: en tierra y en el mar. Otro ejemplo: los retratos, una escena de género y las imágenes de desnudos desde el punto de vista de una red preformada tienen un signo común: la presencia de personas.
En la base de datos, las imágenes de contenido similar a menudo se refieren al género infantil o al padre, dependiendo de dónde fue determinado por el experto que trajo las imágenes a la base de datos. En este sentido, se llevó a cabo una limpieza a gran escala y una nueva división de la base teniendo en cuenta la posible jerarquía de géneros, lo que requirió mucho esfuerzo (logramos automatizarlo, pero no mucho).
Para transferir la jerarquía de géneros a la red, abandonamos el envío directo y configuramos la unidad para imágenes no solo en un género, sino también en su padre, si lo hay, y también reemplazamos la función objetivo del proceso de aprendizaje y la función de activar la capa de salida . Por lo tanto, la tarea se convirtió en clasificación Multilabel (la imagen de entrada puede pertenecer a varias clases).
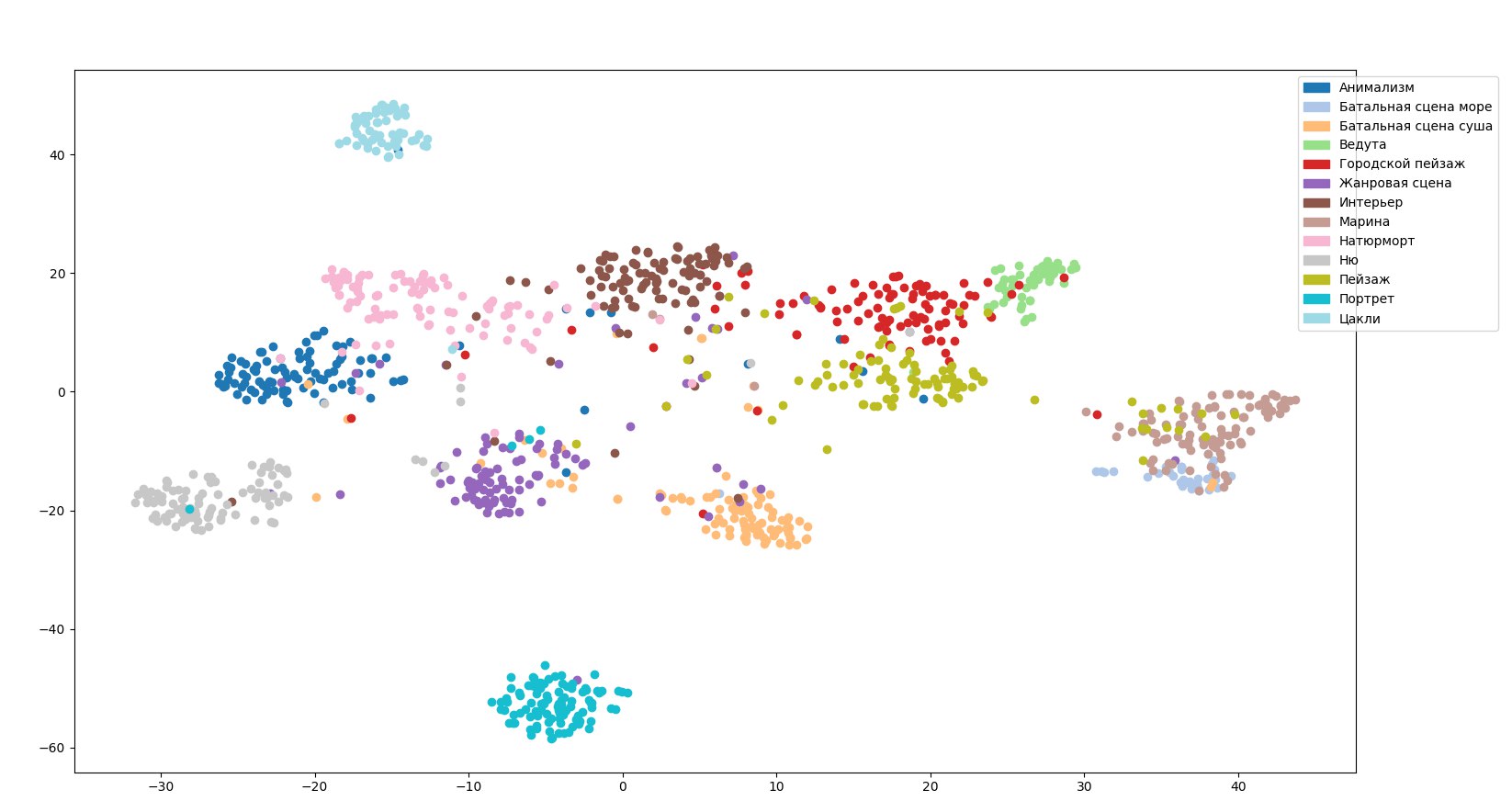
Nos parece que falta otro género aquí: la abstracción. Estrictamente hablando, este no es un género. Al menos los expertos insistieron en que no existía ese género. Para evitar que la red ofrezca respuestas aleatorias a imágenes abstractas, se agregó una más al desglose general de los géneros con el nombre "no se pudo determinar", incluidas las imágenes abstractas y controvertidas.
En lugar de una conclusión
En general, fue posible lograr una precisión satisfactoria en la clasificación de estilos y géneros de imágenes, pero hay mucho que mejorar.
Desafortunadamente, la clasificación de estilos y técnicas no se finalizó, el soporte no se implementó en el servicio.