En Python, puede trabajar con datos y visualizarlos. No solo los programadores aprovechan esto, sino también los científicos: biólogos, físicos y sociólogos. Hoy, junto con
shwars , el curador de nuestro
Python Jumpstart para el curso de
IA , nos convertiremos brevemente en meteorólogos y estudiaremos el clima de las ciudades rusas. Desde bibliotecas para visualización y trabajo con datos, utilizamos Pandas, Matplotlib y Bokeh.

Investigamos en
Azure Notebooks , la versión basada en la nube de Jupyther Notebook. Por lo tanto, para comenzar con Python, no necesitamos instalar nada en nuestra computadora y podemos trabajar directamente desde el navegador. Solo necesita iniciar sesión con su cuenta de Microsoft, crear una biblioteca y la nueva computadora portátil Python 3. ¡Luego puede tomar los fragmentos de código de este artículo y experimentar!
Obtenemos los datos
En primer lugar, importamos las bibliotecas principales que necesitamos.
Pandas es una biblioteca para trabajar con datos tabulares, o los llamados marcos de datos, y
pyplot nos permitirá construir gráficos.
import pandas as pd import matplotlib.pyplot as plt
Los datos de origen son fáciles de encontrar en Internet, pero ya los hemos preparado en un formato CSV conveniente. CSV es un formato de texto en el que todas las columnas están separadas por comas. De ahí el nombre: valores separados por comas.
Los pandas pueden abrir archivos CSV desde un disco local, así como directamente desde Internet. Los datos en sí se encuentran en nuestro
repositorio en GitHub , por lo que solo necesitamos especificar la URL correcta.
data = pd.read_csv("https://raw.githubusercontent.com/shwars/PythonJump/master/Data/climat_russia_cities.csv") data

Cambie el nombre de las columnas de la tabla para que sea más conveniente acceder a ellas por nombre. También necesitamos convertir cadenas en valores numéricos para poder operar en ellas. Cuando intentamos hacer esto usando la función
pd.to_numeric , encontramos que ocurre un error extraño. Esto se debe al hecho de que en lugar de un signo menos, se utiliza un guión largo en el texto.
data.columns=["City","Lat","Long","TempMin","TempColdest","AvgAnnual","TempWarmest","AbsMax","Precipitation"] data["TempMin"] = pd.to_numeric(data["TempMin"])
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) pandas/_libs/src/inference.pyx in pandas._libs.lib.maybe_convert_numeric() ValueError: Unable to parse string "−38.0" ... ... ... ValueError: Unable to parse string "−38.0" at position 0
De este problema se desprende una moralidad importante: los datos generalmente vienen en una forma "sucia", lo cual es incómodo de usar, y la tarea de un científico de datos es llevar estos datos a una buena vista.
Puede ver que algunas de las columnas de nuestra tabla son de tipo
object , en lugar del tipo numérico
float64 . En tales columnas, reemplazaremos el guión con un signo menos y luego convertiremos toda la tabla a un formato numérico. Las columnas que no se pueden convertir (nombres de ciudades) permanecerán sin cambios (para esto utilizamos los
errors='ignore' clave
errors='ignore' ).
print(data.dtypes) for x in ["TempMin","TempColdest","AvgAnnual"]: data[x] = data[x].str.replace('−','-') data = data.apply(pd.to_numeric,errors='ignore') print(data.dtypes)
City object Lat float64 Long float64 TempMin object TempColdest object AvgAnnual object TempWarmest float64 AbsMax float64 Precipitation int64 dtype: object City object Lat float64 Long float64 TempMin float64 TempColdest float64 AvgAnnual float64 TempWarmest float64 AbsMax float64 Precipitation int64 dtype: object
Investigamos datos
Ahora que tenemos datos limpios, podemos intentar construir gráficos interesantes.
Temperatura media anual
Por ejemplo, veamos cómo la temperatura promedio depende de la latitud.
ax = data.plot(x="Lat",y="AvgAnnual",kind="Scatter") ax.set_xlabel("") ax.set_ylabel(" ")

El gráfico muestra que cuanto más cerca del ecuador, más cálido.
Grabar ciudades
Ahora echemos un vistazo a las ciudades que son campeones de la temperatura y veamos si existe una correlación entre las temperaturas mínimas y máximas en la ciudad.
ax=data.plot(x="TempMin",y="AbsMax",kind="scatter") ax.set_xlabel(" ") ax.set_ylabel(" ") ax.invert_xaxis()
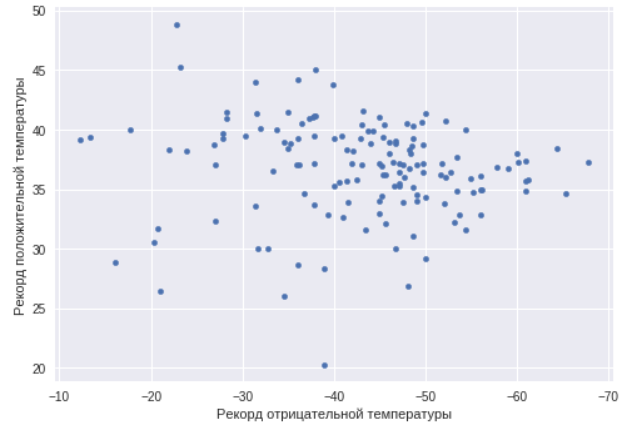
Como puede ver, en este caso no existe tal correlación. Hay ciudades con un clima continental fuerte, y solo ciudades cálidas y frías. Encontramos ciudades con una temperatura máxima, es decir, ciudades con un clima fuertemente continental.
data['spread'] = data['TempWarmest'] - data['TempColdest'] data.nlargest(3,'spread')

Esta vez no tomamos máximos históricos, sino los promedios del mes más cálido y más frío. Como se esperaba, la dispersión más grande entre las ciudades de la República de Sakha (Yakutia).
Invierno y verano
Para una mayor investigación, considere las ciudades dentro de un radio de 300 km de Moscú. Para calcular la distancia entre los puntos en latitud y longitud, utilizamos la biblioteca de
geopy , que primero debe instalarse utilizando
pip install .
!pip install geopy import geopy.distance
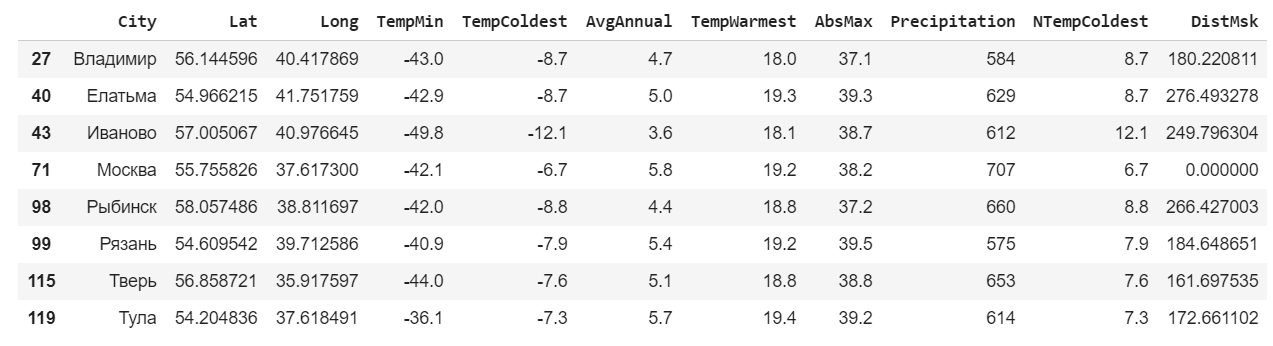
Agregue una columna más a la tabla: la distancia a Moscú.
msk_coords = tuple(data.loc[data["City"]==""][["Lat","Long"]].iloc[0]) data["DistMsk"] = data.apply(lambda row : geopy.distance.distance(msk_coords,(row["Lat"],row["Long"])).km,axis=1) data.head()

Usamos la expresión para seleccionar solo las líneas de interés para nosotros.
msk = data.loc[data['DistMsk']<300] msk
Para estas ciudades, construimos un calendario de temperaturas mínimas, medias anuales y máximas.
ax=msk.plot(x="City",y=["TempColdest","AvgAnnual","TempWarmest"],kind="bar",stacked="true") ax.legend(["","",""],loc='lower right')
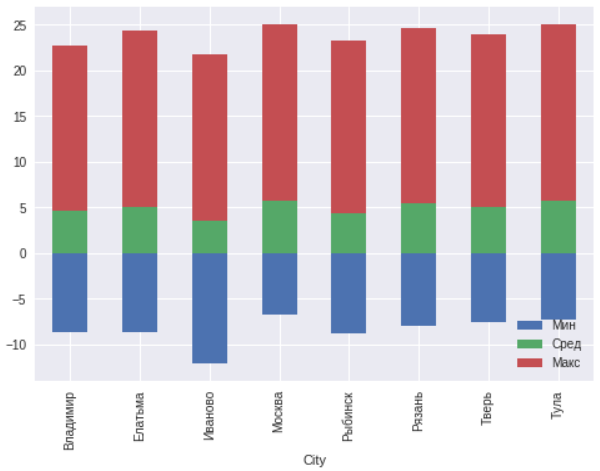
En general, no se observan anomalías dentro de los 300 kilómetros alrededor de Moscú. Ivanovo se encuentra al norte del resto de las ciudades y, por lo tanto, las temperaturas son varios grados más bajas.
Trabajar con datos geográficos
Ahora intentemos mostrar en el mapa la precipitación anual promedio con referencia a las ciudades y ver cómo la precipitación depende de la ubicación geográfica. Para esto utilizamos otra biblioteca de visualización:
Bokeh . También necesita ser instalado.
Luego calculamos otra columna: el tamaño del círculo, que mostrará la cantidad de lluvia. El coeficiente se selecciona empíricamente.
!pip install bokeh from bokeh.io import output_file, output_notebook, show from bokeh.models import ( GMapPlot, GMapOptions, ColumnDataSource, Circle, LogColorMapper, BasicTicker, ColorBar, DataRange1d, PanTool, WheelZoomTool, BoxSelectTool, HoverTool ) from bokeh.models.mappers import ColorMapper, LinearColorMapper from bokeh.palettes import Viridis5 from bokeh.plotting import gmap
Para trabajar con el mapa, necesita la clave API de Google Maps. Debe obtenerse independientemente
en el sitio .
Puede encontrar instrucciones más detalladas sobre el uso de Bokeh para trazar gráficos en mapas
aquí y
aquí .
google_key = "<INSERT YOUR KEY HERE>" data["PrecipSize"] = data["Precipitation"] / 50.0 map_options = GMapOptions(lat=msk_coords[0], lng=msk_coords[1], map_type="roadmap", zoom=4) plot = gmap(google_key,map_options=map_options) plot.title.text = " " source = ColumnDataSource(data=data) my_hover = HoverTool() my_hover.tooltips = [('', '@City'),('','@Precipitation')] plot.circle(x="Long", y="Lat", size="PrecipSize", fill_color="blue", fill_alpha=0.8, source=source) plot.add_tools(PanTool(), WheelZoomTool(), BoxSelectTool(), my_hover) output_notebook() show(plot)
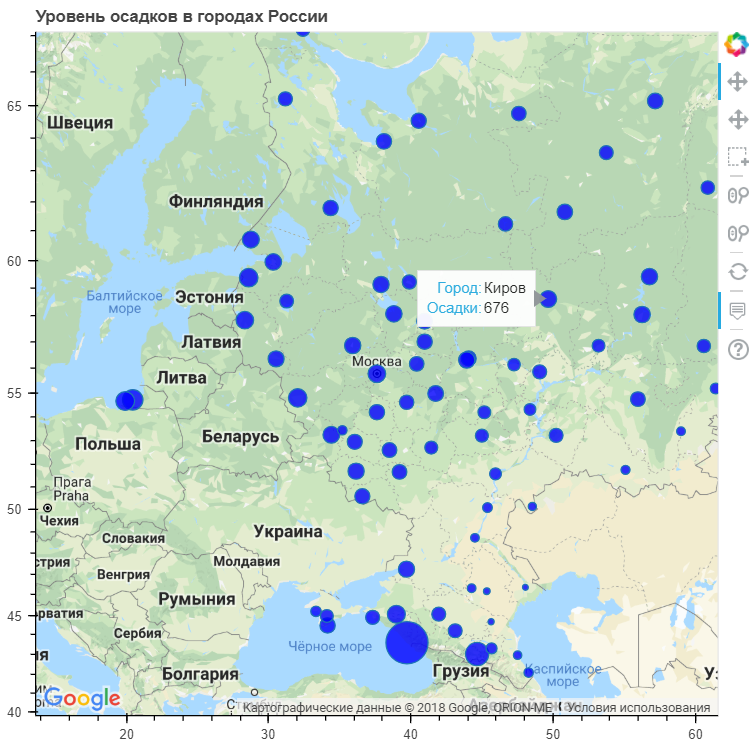
Como puede ver, la mayor cantidad de lluvia ocurre en las ciudades costeras. Aunque hay un número bastante grande de ciudades donde la precipitación es promedio o incluso más baja que el nivel nacional.
El código completo con comentarios escritos por Dmitry Soshnikov, puede ver y ejecutar de forma independiente
aquí .
Resumen
Mostramos las capacidades del lenguaje sin utilizar algoritmos complejos, bibliotecas específicas o escribir cientos de líneas de código. Sin embargo, incluso armado con herramientas estándar, puede analizar sus datos y sacar algunas conclusiones.
Los conjuntos de datos están lejos de estar siempre perfectamente compuestos, por lo que antes de comenzar a trabajar con la visualización, debe ordenarlos. La calidad de la visualización dependerá en gran medida de la calidad de los datos utilizados.
Hay una gran cantidad de varios tipos de cuadros y gráficos, y no es necesario limitarse solo a las bibliotecas estándar.
Hay
Geoplotlib ,
Plotly ,
cuero minimalista y otros.
Si desea obtener más información sobre cómo trabajar con datos en Python, así como familiarizarse con la inteligencia artificial, lo invitamos a un intensivo de un día desde el Distrito Binario:
Python jumpstart para IA .