El espacio del mundo circundante está lleno de eventos individuales y sus cadenas: estos eventos se reflejan en los medios de comunicación, en las cuentas de blogueros y personas comunes en las redes sociales. Una imagen de la realidad circundante, reclamando un cierto grado de objetividad, solo se puede obtener si reunimos diferentes puntos de vista sobre el mismo problema. El categorizador de eventos es la herramienta que "reúne" la información recopilada: versiones de la descripción de eventos. A continuación, proporcione acceso a la información sobre eventos a los usuarios a través de herramientas de búsqueda, recomendaciones y representaciones visuales de secuencias temporales de eventos.
Hoy hablaremos sobre nuestro sistema, más precisamente sobre su núcleo de software, bajo el nombre en clave "Varya", en honor del desarrollador principal.
Todavía no podemos mencionar el nombre de nuestra startup, a pedido de la administración de Habrahabr, ahora hemos enviado una solicitud para asignarnos el estado de Startup. Sin embargo, podemos informarle sobre la funcionalidad y nuestras ideas ahora. Nuestro sistema garantiza la relevancia de la información del evento para el usuario y la gestión de datos competente: en el sistema, cada usuario determina qué ver y leer, controla la búsqueda y las recomendaciones.
Nuestro proyecto es una startup con un equipo de 8 personas con competencias en el diseño de sistemas, programación, marketing y gestión técnica y algorítmicamente complejos.
Juntos, todos los días, el equipo trabaja en el proyecto: ya se han implementado algoritmos para clasificar, buscar y presentar información. La implementación de algoritmos relacionados con las recomendaciones para el usuario aún está por delante: en función de la relación de eventos, personas y análisis de la actividad e intereses del usuario.
¿Qué tareas resolvemos y por qué hablamos al respecto? Ayudamos a las personas a obtener información detallada sobre eventos de cualquier escala, sin importar dónde y cuándo ocurrieron.
El proyecto proporciona a los usuarios una plataforma para discutir eventos en un círculo de personas de ideas afines, le permite compartir un comentario o su propia versión de lo que sucedió. La plataforma de redes sociales fue creada para aquellos que quieren saber "por encima del promedio" y tener una opinión personal sobre los principales eventos del pasado, presente y futuro.
Los propios usuarios encuentran y crean contenido útil en el espacio de los medios y controlan su fiabilidad. Mantenemos un recuerdo de los acontecimientos de su vida.
Ahora el proyecto está en la etapa de MVP, estamos probando hipótesis sobre la funcionalidad y el trabajo del categorizador para determinar la dirección correcta para un mayor desarrollo. En este artículo hablaremos sobre las tecnologías con las que resolvemos nuestras tareas y compartimos nuestras mejores prácticas.
Los motores de búsqueda resuelven la tarea del procesamiento de textos de máquina: Yandex, Google, Bing, etc. Un sistema ideal para trabajar con flujos de información y aislar eventos en ellos podría tener el siguiente aspecto.
Se construyó una infraestructura similar a Yandex y Google para el sistema, se escaneó toda la Internet en tiempo real en busca de actualizaciones, y luego los núcleos de eventos se distinguen en el flujo de información, alrededor del cual se forman las aglomeraciones de sus versiones y contenido relacionado. La implementación del software del servicio se basa en una red neuronal de aprendizaje profundo y / o una solución basada en la biblioteca Yandex: CatBoost.
Genial Sin embargo, todavía no tenemos ese volumen de datos, y no hay recursos informáticos correspondientes para la asimilación.
La clasificación por tema es una tarea popular, existen muchos algoritmos para resolverla: clasificadores ingenuos de Bayes, colocación de Dirichlet latente, impulso sobre árboles de decisión y redes neuronales. Como, probablemente, en todos los problemas de aprendizaje automático, cuando se utilizan los algoritmos descritos, surgen dos problemas:
Primero, ¿dónde obtener una gran cantidad de datos?
En segundo lugar, ¿cómo colocarlos de manera barata y enojada?
¿Qué enfoque elegimos para un sistema basado en eventos?
Nuestro producto funciona con eventos. Los eventos son algo diferentes de los artículos regulares.
Para superar el "arranque en frío", decidimos utilizar dos proyectos de WikiMedia: Wikipedia y Wikinoticias. Un artículo de Wikipedia puede describir varios eventos (por ejemplo, la historia del desarrollo de Sun Microsystems, una biografía de Mayakovsky o el curso de la Gran Guerra Patriótica).
Otras fuentes de información de eventos son los canales RSS. La noticia ocurre de diferentes maneras: los artículos analíticos grandes contienen varios eventos, como textos de Wikipedia, y mensajes informativos cortos de varias fuentes representan el mismo evento.
Por lo tanto, el artículo y los eventos forman relaciones de muchos a muchos. Pero en la etapa de MVP, asumimos que un artículo es un evento.
Si observa la interfaz de Google o Yandex, podría pensar que los motores de búsqueda solo buscan palabras clave. Esto es solo para minoristas en línea muy simples. La mayoría de los motores de búsqueda son de criterios múltiples, y el motor de nuestro proyecto no es una excepción. Además, lejos de todos los parámetros tomados en cuenta durante la búsqueda se muestran en la interfaz de usuario. Nuestro proyecto tiene una lista de parámetros que el usuario selecciona, como:
temas y palabras clave:
"¿qué?" ; ubicación -
"¿dónde?" ; fecha -
"cuando?" ;
Quienes escriben motores de búsqueda saben que las palabras clave por sí solas causan muchos problemas. Bueno, el resto de las opciones tampoco son tan simples.
El tema del evento es algo muy difícil. El cerebro humano está diseñado para que le encante categorizar todo, y el mundo real no está de acuerdo con esto. Los artículos entrantes desean formar sus propios grupos de temas, y no son en absoluto en quienes nosotros y nuestros entusiastas usuarios los distribuimos.
Ahora tenemos 15 temas principales de eventos, y esta lista ha sido revisada varias veces y, como mínimo, crecerá.
Los lugares y las fechas se arreglan un poco más formalmente, pero aquí hay dificultades.
Entonces, tenemos un conjunto de criterios formalizados y datos sin procesar que necesitamos asignar a estos criterios. Y así es como lo hacemos.
Araña
La tarea de la araña es doblar los artículos entrantes para que puedan buscarse rápidamente. Para hacer esto, la araña debe poder atribuir el tema, la ubicación y la fecha a los artículos, así como algunos otros parámetros necesarios para la clasificación. Nuestra araña de entrada recibe un modelo de texto del artículo creado por el rastreador. Un modelo de texto es una lista de partes de un artículo y sus textos correspondientes. Por ejemplo, casi todos los artículos tienen al menos un título y un texto corporal. De hecho, todavía tiene el primer párrafo, un conjunto de categorías a las que este texto se refiere a su fuente y una lista de campos de cuadro de información (para Wikipedia y las fuentes que tienen tales etiquetas de metadatos). Todavía hay una fecha de publicación. Para clasificar en un motor de búsqueda, será importante que sepamos si, por ejemplo, se encuentra una fecha en el encabezado o en algún lugar al final del texto. Se utiliza un modelo de texto para crear un modelo de tema, un modelo de ubicación y un modelo de fecha, y luego el resultado se agrega al índice. Se puede escribir un artículo separado sobre cada uno de estos modelos, por lo que aquí solo describiremos brevemente los enfoques.
Tema
Determinar el tema de los documentos es una tarea común. Los sujetos pueden ser atribuidos manualmente por el autor del documento, o pueden determinarse automáticamente. Por supuesto, tenemos temas que las fuentes de noticias y Wikipedia han atribuido a nuestros documentos, pero estos temas no son sobre eventos. ¿Suele encontrar el tema "Vacaciones" en las noticias? Más bien, conocerás el tema de "Sociedad". También tuvimos esto en una de las primeras ediciones. No pudimos determinar qué debería relacionarse con él, y nos vimos obligados a eliminarlo. Y además, todas las fuentes tienen su propio conjunto de temas.
Queremos gestionar la lista de temas que se muestran a nuestros usuarios en la interfaz, por lo que para nosotros la tarea de determinar el tema del documento es la tarea de clasificación difusa. La tarea de clasificación requiere ejemplos etiquetados, es decir, una lista de documentos a los que ya se han atribuido nuestros temas deseados. Nuestra lista es similar a todas las listas de temas similares, pero no coincide con ellas, por lo que no teníamos una muestra etiquetada. También puede obtenerlo de forma manual o automática, pero si nuestra lista de temas cambia (y lo hará), entonces, manualmente, no es una opción.
Si no tiene una muestra etiquetada, puede usar la colocación de Dirichlet latente y otros algoritmos de modelado temático, sin embargo, el conjunto de los que obtendrá será el que resultó y no el que deseaba.
Aquí debemos mencionar un punto más: nuestros artículos provienen de diferentes fuentes. Todos los modelos temáticos se construyen de una forma u otra sobre el vocabulario utilizado. Para las noticias y Wikipedia, es diferente, diferente incluso las frecuencias altas tamizadas.
Por lo tanto, nos enfrentamos a dos tareas:
1. Encuentre una manera de distribuir rápidamente nuestros documentos en un modo semiautomático.
2. Cree un modelo extensible de nuestros temas basado en estos documentos.
Para resolverlos, creamos un algoritmo híbrido que contiene las etapas automáticas y manuales que se muestran en la figura.
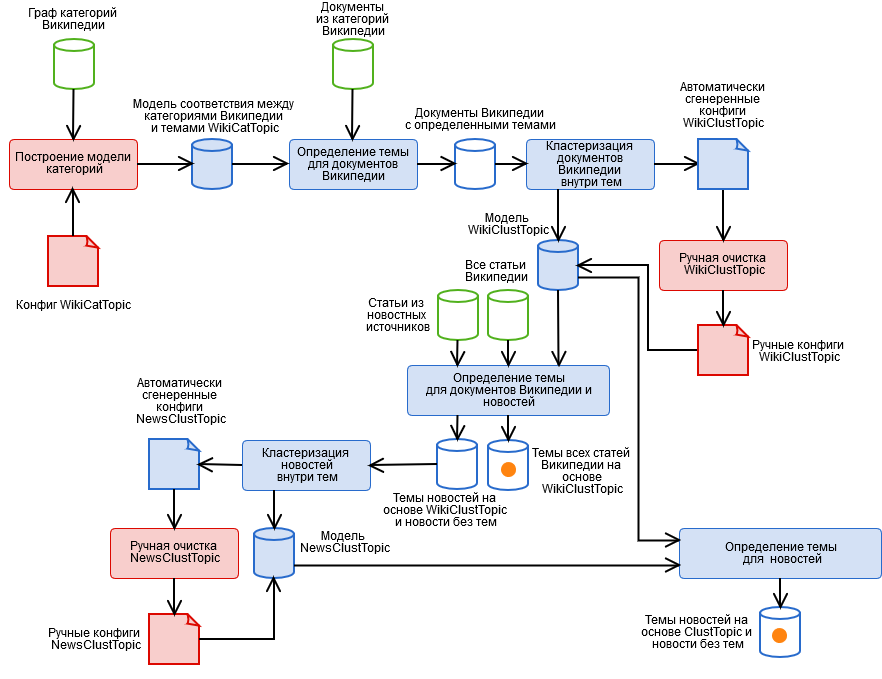
- Marcado manual de categorías de Wikipedia y obtención de un modelo de tema categórico WikiCatTopic. En esta etapa, se crea una configuración que asigna un subgrafo de las categorías WT de Wikipedia a cada uno de nuestros temas T. Wikipedia es una pseudoontología. Esto significa que si algo cae en la categoría de "Ciencia", puede que no se trate de ciencia en absoluto, por ejemplo, de la subcategoría inofensiva "Tecnologías de la información", en realidad puede ir a cualquier artículo de Wikipedia. Se necesita un artículo separado sobre cómo vivir con esto.
- Detecta automáticamente temas para documentos de Wikipedia basados en WikiCatTopic. Al documento se le asigna el tema T si pertenece a una de las categorías del gráfico CT. Tenga en cuenta que este método se aplica solo a los artículos de Wikipedia. Para generalizar la definición de temas a texto arbitrario, fue posible construir una bolsa de palabras de cada tema y considerar la distancia del coseno al tema (y lo intentamos, nada bueno), pero aquí se deben tener en cuenta tres cosas.
- Dichos temas contienen artículos muy diversos, por lo que la imagen del tema en el espacio de palabras no será coherente, lo que significa que la "confianza" de dicho modelo para determinar el tema es muy baja (después de todo, el artículo es similar a un pequeño conjunto de artículos, pero no al resto).
- Un texto arbitrario, principalmente noticias, difiere en su composición léxica de Wikipedia, esto tampoco agrega un modelo de "certeza". Además, algunos temas no se pueden construir en Wikipedia.
- La etapa 1 es un trabajo muy minucioso, y todos son demasiado vagos para hacerlo.
- Agrupación de documentos dentro de temas basados en los resultados del párrafo 2 utilizando el método k-means y obteniendo un modelo de agrupación del tema WikiClustTopic. Un movimiento bastante simple, que nos permitió resolver en gran medida dos de los tres problemas del párrafo 2. Para los grupos, construimos una bolsa de palabras, y la pertenencia a un tema se define como la distancia máxima del coseno a sus grupos. El modelo se describe en nuestros archivos de configuración de correspondencia entre clústeres y documentos de Wikipedia.
- Limpieza manual del modelo WikiClustTopic, habilitar-deshabilitar-transferencia de clústeres. Aquí también volvimos a la etapa 1, cuando se descubrieron grupos completamente incorrectos.
- Detecta automáticamente temas de WikiClustTopic para documentos y noticias de Wikipedia.
- Agrupando noticias dentro de temas basados en los resultados del párrafo 5 usando el método k-means, así como noticias que no recibieron temas, y obteniendo un modelo de agrupación del tema NewsClustTopic. Ahora tenemos un modelo de tema que tiene en cuenta los detalles de las noticias (así como información invaluable sobre la calidad del trabajo del rastreador).
- Limpieza manual del modelo NewsClustTopic.
- Reasignación de temas de noticias basados en el modelo integrado ClustTopic = WikiClustTopic + NewsClustTopic. En base a este modelo, se determinan los temas de los nuevos documentos.
Localizaciones
La determinación automática de ubicación es un caso especial de la tarea de buscar entidades con nombre. Las características de las ubicaciones son las siguientes:
- Todas las listas de ubicaciones son diferentes y no encajan bien. Creamos nuestro propio híbrido, que tiene en cuenta no solo la jerarquía (Rusia incluye la región de Novosibirsk), sino también los cambios de nombre históricos (por ejemplo, el RSFSR se convirtió en Rusia) basado en: Geonames, Wikidata y otras fuentes abiertas. Sin embargo, todavía teníamos que escribir un convertidor de geoetiquetado con Google Maps :)
- Algunas ubicaciones constan de varias palabras, por ejemplo, Nizhny Novgorod, y debe poder recopilarlas.
- Las ubicaciones son similares a otras palabras, especialmente los nombres de aquellos en cuyo honor se nombran: Kirov, Zhukov, Vladimir. Esto es homonimia. Para curar esto, recopilamos estadísticas en artículos de Wikipedia que describen asentamientos, en qué contextos se encuentran los nombres de las ubicaciones, y también tratamos de construir una lista de dichos homónimos utilizando los diccionarios Open Corpora.
- La humanidad no ejerció demasiada presión sobre la imaginación, y muchos lugares reciben el mismo nombre. Nuestro ejemplo favorito: Karasuk en Kazajstán y en Rusia, cerca de Novosibirsk. Esto es homonimia dentro de la clase de ubicaciones. Lo resolvemos, considerando qué otros lugares se encuentran con este, y si son padres o hijos para uno de los homónimos. Esta heurística no es universal, pero funciona bien.
Fechas
Fechas: la encarnación de la formalidad en comparación con los temas y las ubicaciones. Creamos un analizador expandible para ellos en expresiones regulares, y podemos analizar no solo día-mes-año, sino también todo tipo de cosas más interesantes, como "fin del invierno de 1941", "en los años 90 del siglo XIX" y "el mes pasado ", Teniendo en cuenta la era y la fecha base del documento, así como tratando de restaurar el año perdido. Sobre las fechas necesita saber que no todas son buenas. Por ejemplo, al final de un artículo sobre cualquier batalla de la Segunda Guerra Mundial, puede haber una apertura del memorial cuarenta años después, para tratar estos casos, debe cortar el artículo en eventos, pero aún no lo estamos haciendo. Por lo tanto, consideramos solo las fechas más importantes: del encabezado y los primeros párrafos.
Motor de búsqueda
El motor de búsqueda es un artilugio que, en primer lugar, busca documentos a pedido y, en segundo lugar, los organiza en orden descendente de relevancia para la consulta, es decir, en relevancia decreciente. Para calcular la relevancia, utilizamos muchos parámetros, mucho más que solo trivance:
El grado en que el documento pertenece al tema.
El grado de propiedad del documento de ubicación (cuántas veces y en qué partes del documento se encuentra la ubicación seleccionada).
El grado en que el documento coincide con la fecha (tiene en cuenta el número de días en la intersección del intervalo desde la solicitud y las fechas del documento, así como el número de días en la intersección menos la unión).
La longitud del documento. Los artículos largos deberían ser más altos.
La presencia de la imagen. Todos aman las fotos, ¡debería haber más!
Tipo de artículo de Wikipedia. Podemos separar artículos con descripciones de eventos, y deberían aparecer en la muestra.
Fuente del artículo. Las noticias y los artículos personalizados deben ser superiores a Wikipedia.
Como motor de búsqueda, utilizamos Apache Lucene.
Rastreador
La tarea del rastreador es recolectar artículos para la araña. En nuestro caso, aquí también incluimos la limpieza primaria del texto y la construcción de un modelo de texto del documento. Crawler merece un artículo separado.
PD Agradecemos cualquier comentario, lo invitamos a probar nuestro proyecto: para recibir un enlace, escribir mensajes personales (no podemos publicar aquí). Deje sus comentarios debajo del artículo, o si llega a nuestro servicio, allí mismo, a través del formulario de comentarios.