Cuando las personas buscan en Internet una foto o un video, a menudo agregan la frase "de buena calidad". La calidad generalmente se refiere a la resolución: los usuarios quieren que la imagen sea grande y al mismo tiempo se vea bien en la pantalla de una computadora moderna, teléfono inteligente o TV. Pero, ¿qué pasa si la fuente de buena calidad simplemente no existe?
Hoy les diremos a los lectores de Habr cómo, con la ayuda de las redes neuronales, podemos aumentar la resolución del video en tiempo real. También aprenderá cómo el enfoque teórico para resolver este problema difiere del práctico. Si no está interesado en los detalles técnicos, puede desplazarse con seguridad por la publicación; al final encontrará ejemplos de nuestro trabajo.

Hay mucho contenido de video en Internet en baja calidad y resolución. Pueden ser películas filmadas hace décadas o transmitir canales de televisión, que por diversas razones no tienen la mejor calidad. Cuando los usuarios extienden dicho video a pantalla completa, la imagen se vuelve turbia y borrosa. Una solución ideal para películas antiguas sería encontrar la película original, escanearla con equipos modernos y restaurarla manualmente, pero esto no siempre es posible. Las transmisiones son aún más complicadas: deben procesarse en vivo. En este sentido, la opción más aceptable para que trabajemos es aumentar la resolución y limpiar los artefactos utilizando la tecnología de visión por computadora.
En la industria, la tarea de aumentar las imágenes y los videos sin pérdida de calidad se denomina término superresolución. Ya se han escrito muchos artículos sobre este tema, pero las realidades de la aplicación de "combate" resultaron ser mucho más complicadas e interesantes. Brevemente sobre los principales problemas que tuvimos que resolver en nuestra propia tecnología DeepHD:
- Debe poder restaurar los detalles que no estaban en el video original debido a su baja resolución y calidad, para "terminarlos".
- Las soluciones de súper resolución restauran los detalles, pero hacen que sean claros y detallados no solo los objetos en el video, sino también los artefactos de compresión, lo que causa disgusto a la audiencia.
- Hay un problema con la recolección de la muestra de entrenamiento: se requiere una gran cantidad de pares en los que el mismo video está presente en baja resolución y calidad, y en alta. En realidad, generalmente no hay pares de calidad para contenido deficiente.
- La solución debería funcionar en tiempo real.
Selección de tecnología
En los últimos años, el uso de redes neuronales ha llevado a un éxito significativo en la resolución de casi todas las tareas de la visión por computadora, y la tarea de la superresolución no es una excepción. Encontramos las soluciones más prometedoras basadas en GAN (Redes Adversarias Generativas, redes rivales generativas). Le permiten obtener imágenes fotorrealistas de alta definición, que las complementan con los detalles que faltan, por ejemplo, dibujando cabello y pestañas en las imágenes de las personas.

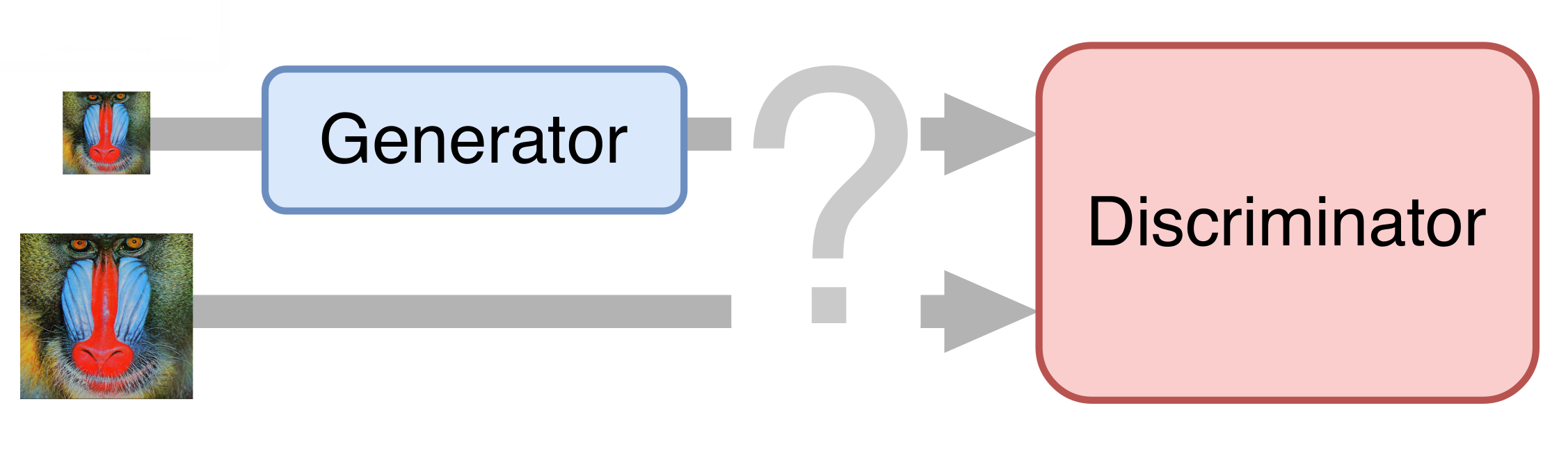
En el caso más simple, una red neuronal consta de dos partes. La primera parte, el generador, toma una imagen de entrada y devuelve una ampliación duplicada. La segunda parte, el discriminador, recibe la imagen generada y "real" como entrada, y trata de distinguirla entre sí.
Preparación del set de entrenamiento
Para el entrenamiento, hemos recopilado docenas de clips en calidad UltraHD. Primero, los redujimos a una resolución de 1080p, obteniendo ejemplos de referencia. Luego redujimos a la mitad estos videos, comprimiéndolos a una tasa de bits diferente en el camino para obtener algo similar a un video real en baja calidad. Dividimos los videos resultantes en marcos y los usamos de tal manera para entrenar la red neuronal.
Desbloqueo
Por supuesto, queríamos obtener una solución de extremo a extremo: entrenar a la red neuronal para generar video de alta resolución y calidad directamente desde el original. Sin embargo, las GAN resultaron ser muy caprichosas y constantemente intentaron refinar los artefactos de compresión, en lugar de eliminarlos. Por lo tanto, tuve que dividir el proceso en varias etapas. El primero es la supresión de los artefactos de compresión de video, también conocidos como desbloqueo.
Un ejemplo de uno de los métodos de lanzamiento:

En esta etapa, minimizamos la desviación estándar entre el fotograma generado y el original. Por lo tanto, aunque aumentamos la resolución de la imagen, no obtuvimos un aumento real en la resolución debido a la regresión al promedio: la red neuronal, al no saber en qué píxeles específicos pasa un borde particular en la imagen, se vio obligada a promediar varias opciones, obteniendo un resultado borroso. Lo principal que hemos logrado en esta etapa es la eliminación de los artefactos de compresión de video, por lo que la red generativa en la siguiente etapa solo necesitaba aumentar la claridad y agregar los pequeños detalles y texturas que faltan. Después de cientos de experimentos, seleccionamos la arquitectura óptima en términos de rendimiento y calidad, que recuerda vagamente a la arquitectura
DRCN :
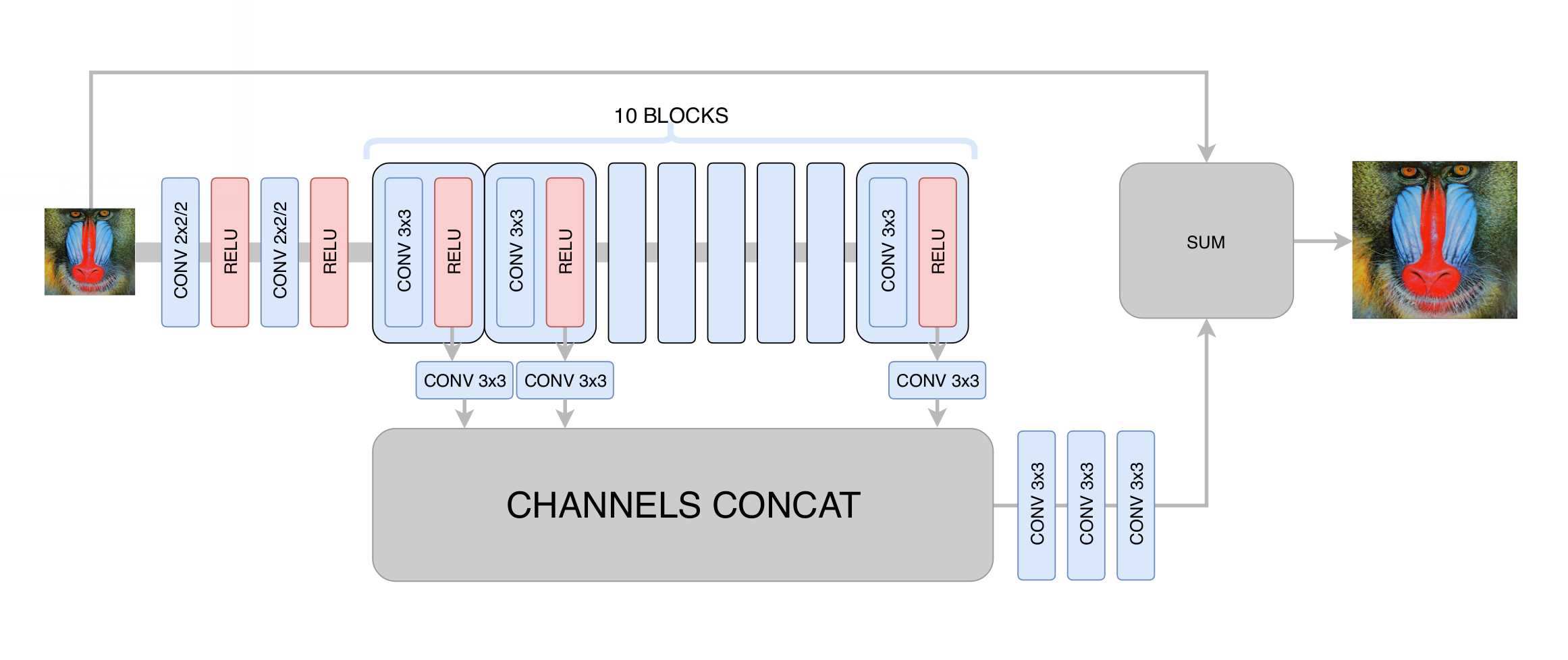
La idea principal de tal arquitectura es el deseo de obtener la arquitectura más profunda, sin tener problemas de convergencia en su formación. Por un lado, cada capa convolucional subsiguiente extrae características cada vez más complejas de la imagen de entrada, lo que le permite determinar qué tipo de objeto se encuentra en un punto determinado de la imagen y restaurar partes complejas y muy dañadas. Por otro lado, la distancia en el gráfico de una red neuronal desde cualquiera de sus capas hasta la salida sigue siendo pequeña, lo que mejora la convergencia de la red neuronal y permite utilizar una gran cantidad de capas.
Entrenamiento de red generativa
Tomamos la arquitectura
SRGAN como base de una red neuronal para aumentar la resolución. Antes de entrenar una red competitiva, debe entrenar previamente el generador, entrenarlo de la misma manera que en la etapa de desbloqueo. De lo contrario, al comienzo del entrenamiento, el generador devolverá solo ruido, el discriminador comenzará inmediatamente a "ganar": aprenderá fácilmente a distinguir el ruido de los cuadros reales, y ningún entrenamiento funcionará.

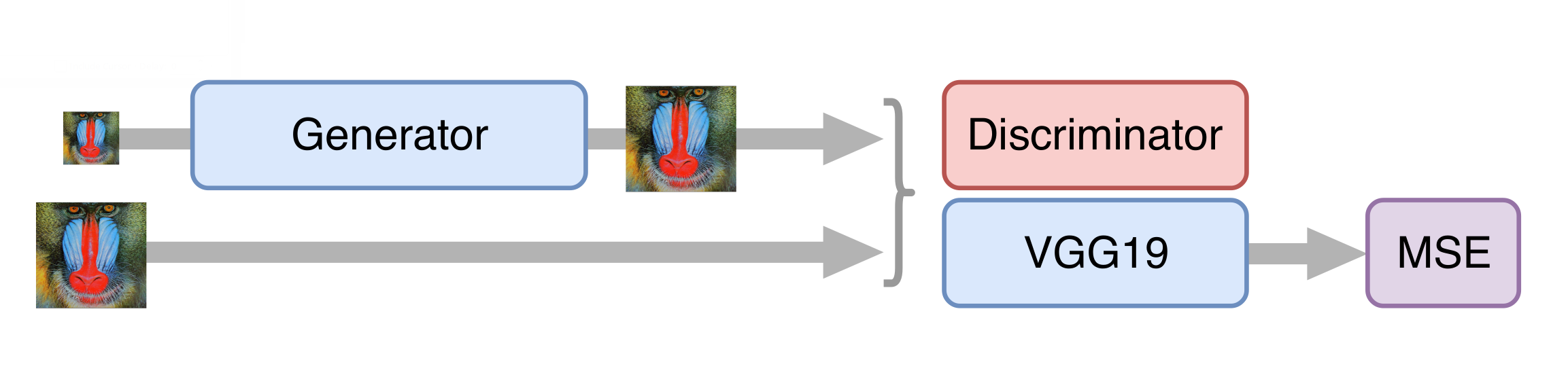
Luego entrenamos GAN, pero hay algunos matices. Es importante para nosotros que el generador no solo cree marcos fotorrealistas, sino que también almacene la información disponible en ellos. Para hacer esto, agregamos la función de pérdida de contenido a la arquitectura clásica de GAN. Representa varias capas de la red neuronal VGG19 capacitadas en el conjunto de datos estándar de ImageNet. Estas capas transforman la imagen en un mapa de características que contiene información sobre el contenido de la imagen. La función de pérdida minimiza la distancia entre dichas tarjetas obtenida de los cuadros generados y originales. Además, la presencia de dicha función de pérdida hace posible no estropear el generador en los primeros pasos del entrenamiento, cuando el discriminador aún no está entrenado y proporciona información inútil.
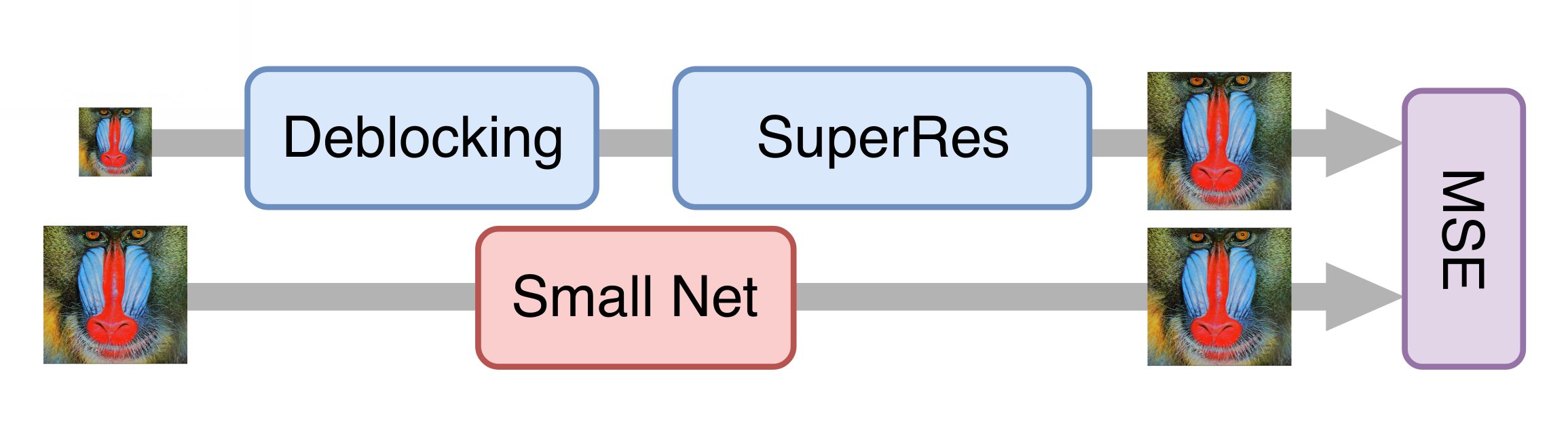
Aceleración de la red neuronal
Todo salió bien, y después de una serie de experimentos, obtuvimos un buen modelo que ya podría aplicarse a películas antiguas. Sin embargo, todavía era demasiado lento para procesar la transmisión de video. Resultó que es imposible simplemente reducir el generador sin una pérdida significativa en la calidad del modelo final. Luego, el enfoque de la destilación del conocimiento nos ayudó. Este método implica entrenar un modelo más ligero para que repita los resultados de uno más pesado. Tomamos muchos videos reales en baja calidad, los procesamos con la red neuronal generativa obtenida en el paso anterior, y capacitamos a la red más ligera para obtener el mismo resultado de los mismos cuadros. Debido a esta técnica, obtuvimos una red que no es muy inferior en calidad a la original, pero diez veces más rápida que ella: para procesar un canal de TV con una resolución de 576p, se requiere una tarjeta NVIDIA Tesla V100.
Evaluación de la calidad de las soluciones.
Quizás el momento más difícil cuando se trabaja con redes generativas es la evaluación de la calidad de los modelos resultantes. No existe una función de error clara, como, por ejemplo, al resolver el problema de clasificación. En cambio, solo conocemos la precisión del discriminador, que no refleja la calidad del generador que nos interesa (un lector que conozca bien esta área podría sugerir el uso de
la métrica de Wasserstein , pero, desafortunadamente, dio un resultado notablemente peor).
La gente nos ayudó a resolver este problema. Mostramos a los usuarios del servicio
Yandex.Tolok pares de imágenes, una de las cuales era la fuente y la otra procesada por una red neuronal, o ambas fueron procesadas por diferentes versiones de nuestras soluciones. Por una tarifa, los usuarios eligieron un mejor video de un par, por lo que obtuvimos una comparación estadísticamente significativa de las versiones, incluso con cambios que son difíciles de ver a simple vista. Nuestros modelos finales ganan en más del 70% de los casos, lo cual es bastante, dado que los usuarios dedican solo unos segundos a calificar un par de videos.
Un resultado interesante también fue el hecho de que el video con una resolución de 576p, aumentado por la tecnología DeepHD a 720p, supera el mismo video original con una resolución de 720p en el 60% de los casos, es decir El procesamiento no solo aumenta la resolución del video, sino que también mejora su percepción visual.
Ejemplos
En primavera, probamos la tecnología DeepHD en varias películas antiguas que se pueden ver en KinoPoisk: "
Rainbow " de Mark Donskoy (1943), "
Cranes are Flying " de Mikhail Kalatozov (1957), "
My Dear Man " de Joseph Kheifits (1958), "
The Fate of a Man " Sergei Bondarchuk (1959), "
Ivan Childhood " de Andrei Tarkovsky (1962), "
Father of a Soldier " Rezo Chkheidze (1964) y "
Tango of Our Childhood " de Albert Mkrtchyan (1985).

La diferencia entre las versiones antes y después del procesamiento es especialmente notable si observa los detalles: estudie las expresiones faciales de los héroes en primeros planos, considere la textura de la ropa o un patrón de tela. Fue posible compensar algunas de las deficiencias de la digitalización: por ejemplo, eliminar la sobreexposición en las caras o hacer objetos más visibles colocados a la sombra.
Más tarde, la tecnología DeepHD comenzó a usarse para mejorar la calidad de las transmisiones de
algunos canales en el servicio Yandex.Air. Reconocer dicho contenido es fácil con la etiqueta
dHD .
Ahora
en Yandex, en calidad mejorada, puede ver "The Snow Queen", "Bremen Town Musicians", "Golden Antelope" y otras caricaturas populares del estudio de cine Soyuzmultfilm. Se pueden ver algunos ejemplos de dinámica en el video:
Para los espectadores exigentes, la diferencia será especialmente notable: la imagen se ha vuelto más nítida, las hojas de los árboles, los copos de nieve, las estrellas en el cielo nocturno sobre la selva y otros pequeños detalles son más visibles.
Más es más.
Enlaces utiles
Jiwon Kim, Jung Kwon Lee, Kyoung Mu Lee Red convolucional profundamente recursiva para la
superresolución de imagen [
arXiv: 1511.04491 ].
Christian Ledig y col. Súper resolución
fotorrealista de una sola imagen utilizando una red
generativa adversa [
arXiv: 1609.04802 ].
Mehdi SM Sajjadi, Bernhard Schölkopf, Michael Hirsch EnhanceNet: Súper resolución de imagen única a través de síntesis de textura automatizada [
arXiv: 1612.07919 ].