La gente siempre ha querido enseñarle a una máquina a entender a una persona. Sin embargo, solo ahora estamos un poco más cerca de las tramas de las películas de ciencia ficción: podemos pedirle a Alice que baje el volumen, el Asistente de Google, pedir un taxi o Siri, configurar una alarma. Las tecnologías de procesamiento de lenguaje tienen demanda en desarrollos relacionados con la construcción de inteligencia artificial: en motores de búsqueda, para extraer hechos, evaluar la tonalidad del texto, la traducción automática y el diálogo.
Hablaremos de las dos últimas áreas: tienen una rica historia y han tenido un impacto significativo en el procesamiento del lenguaje. Además, abordaremos las posibilidades básicas de procesar el lenguaje natural al crear un bot de chat junto con el orador de nuestro curso
AI Weekend, la lingüista de informática Anna Vlasova.
¿Cómo empezó todo?
La primera charla sobre el procesamiento del lenguaje natural con una computadora comenzó en los años 30 del siglo XX con el razonamiento filosófico de Ayer: propuso distinguir a una persona inteligente de una máquina estúpida utilizando una prueba empírica. En 1950, Alan Turing en la revista filosófica
Mind propuso una prueba en la que el juez debe determinar con quién está hablando: una persona o una computadora. Utilizando la prueba, se establecieron criterios para evaluar el trabajo de la inteligencia artificial, no se cuestionó la posibilidad de su construcción. La prueba tiene muchas limitaciones y desventajas, pero tuvo un impacto significativo en el desarrollo de bots de chat.
La primera área donde el procesamiento del lenguaje se aplicó con éxito fue la traducción automática. En 1954, la Universidad de Georgetown junto con IBM demostró un programa de traducción automática del ruso al inglés, que funcionaba sobre la base de un diccionario de 250 palabras y un conjunto de 6 reglas gramaticales. El programa estaba lejos de lo que realmente podría llamarse traducción automática, y tradujo 49 ofertas preseleccionadas en una demostración. Hasta mediados de los años 60, se hicieron muchos intentos para crear un programa de traducción completamente funcional, pero en 1966 la Comisión Asesora sobre Procesamiento Automático del Idioma
(ALPAC) declaró que la traducción automática era una dirección inútil. Los subsidios estatales cesaron por algún tiempo, el interés público en la traducción automática disminuyó, pero la investigación no se detuvo allí.

Paralelamente a los intentos de enseñar a una computadora a traducir texto, científicos y universidades enteras estaban pensando en crear un robot que pudiera imitar el comportamiento del habla humana. La primera implementación exitosa del chatbot fue el interlocutor virtual ELIZA, escrito en 1966 por Joseph Weizenbaum. Eliza parodió el comportamiento del psicoterapeuta, extrayendo palabras significativas de la frase del interlocutor y haciendo una contrapregunta. Podemos suponer que este fue el primer bot de chat basado en reglas (bot basado en reglas), y sentó las bases para toda una clase de tales sistemas. Entrevistadores como Cleverbot, WeChat Xiaoice, Eugene Goostman, pasaron formalmente la prueba de Turing en 2014, e incluso Siri, Jarvis y Alexa no habrían aparecido sin Eliza.
En 1968, Terry Grapes desarrolló el programa SHRDLU en LISP. Ella movía objetos simples a la orden: conos, cubos, bolas, y podía soportar el contexto: entendía qué elemento debía moverse, si se mencionaba anteriormente. El siguiente paso en el desarrollo de bots de chat fue el programa ALICE, para el cual Richard Wallace desarrolló un lenguaje de marcado especial: AIML
(Lenguaje de marcado de inteligencia artificial en inglés) . Luego, en 1995, las expectativas del chatbot fueron exageradas: pensaron que ALICE sería aún más inteligente que una persona. Por supuesto, el chatbot no logró ser más inteligente, y durante algún tiempo el negocio de los chatbots estuvo decepcionado, y los inversores durante mucho tiempo eludieron el tema de los asistentes virtuales.
El idioma importa
Hoy en día, los chatbots aún funcionan sobre la base de un conjunto de reglas y escenarios de comportamiento, sin embargo, un lenguaje natural es difuso y ambiguo, un pensamiento puede tener muchas formas de presentación, por lo tanto, el éxito comercial de los sistemas de diálogo depende de la resolución de los problemas de procesamiento del lenguaje. Se debe enseñar a la máquina a clasificar claramente toda la variedad de preguntas entrantes e interpretarlas claramente.
Todos los idiomas están organizados de manera diferente, y esto es muy importante para el análisis. Desde el punto de vista de la composición morfológica, los elementos significativos de la palabra pueden unirse secuencialmente a la raíz, como, por ejemplo, en las lenguas turcas, o pueden romper la raíz, como en árabe y hebreo. Desde el punto de vista de la sintaxis, algunos idiomas permiten el orden libre de las palabras en una frase, mientras que otros están organizados de manera más rígida. En los sistemas clásicos, el orden de las palabras juega un papel esencial. Para los métodos estadísticos modernos de PNL, no tiene ese valor, ya que el procesamiento no ocurre a nivel de palabras, sino de oraciones completas.
Otras dificultades en el desarrollo de bots de chat surgen en relación con el desarrollo de la comunicación multilingüe. Ahora las personas a menudo no se comunican en sus idiomas nativos, usan palabras incorrectamente. Por ejemplo, en la frase "He enviado hace dos días, pero los productos no vinieron", desde el punto de vista del vocabulario, deberíamos hablar sobre la entrega de objetos físicos, por ejemplo, bienes, y no sobre la transacción de dinero electrónico, que es descrita por estas palabras por una persona que no habla en el idioma nativo Pero en una comunicación real, una persona entenderá al interlocutor correctamente y el bot de chat puede tener problemas. En ciertos temas, como inversiones, banca o TI, las personas a menudo cambian a otros idiomas. Pero es poco probable que el chatbot entienda lo que está en juego, ya que probablemente esté entrenado en un idioma.
Historia de éxito: traductores de máquina
Antes de la llegada de los asistentes de voz y la difusión generalizada de los chatbots, la traducción automática era la tarea intelectual más demandada, que requería el procesamiento de un lenguaje natural. Las conversaciones sobre redes neuronales y aprendizaje profundo se remontan a los años 90, y la primera neurocomputadora Mark-1 apareció en general en 1958. Pero en todas partes no fue posible usarlos debido al bajo rendimiento de las computadoras y la falta de suficiente lenguaje. Solo grandes equipos de investigación pueden permitirse hacer investigaciones en el campo de las redes neuronales.
Los traductores automáticos a mediados del siglo XX estaban lejos de Google Translate y Yandex.Translator, pero con cada nuevo método de traducción surgieron ideas que se aplicaron de una forma u otra incluso hoy.
1970 La traducción automática basada en
reglas (RBMT) fue el primer intento de enseñar a una máquina a traducir. La traducción se obtuvo como en un alumno de quinto grado con un diccionario, pero de una forma u otra, las reglas para un traductor automático o bot de chat todavía se están utilizando.
1984 La traducción automática basada en
ejemplos (EBMT) pudo traducir incluso idiomas que eran completamente diferentes entre sí, donde era inútil establecer reglas. Todos los traductores automáticos modernos y los bots de chat usan ejemplos y patrones listos.
1990. La traducción automática estadística
(SMT en
inglés) en la era del desarrollo de Internet hizo posible el uso no solo de idiomas ya preparados, sino también de libros y artículos traducidos libremente. Más datos disponibles aumentaron la calidad de la traducción. Los métodos estadísticos ahora se utilizan activamente en el procesamiento del lenguaje.
Redes neuronales al servicio de la PNL
Con el desarrollo del procesamiento del lenguaje natural, muchos problemas se resolvieron mediante métodos estadísticos clásicos y muchas reglas, pero esto no resolvió el problema de la falta de claridad y la ambigüedad en el lenguaje. Si decimos "inclinarse" sin ningún contexto, es probable que incluso un interlocutor vivo no entienda lo que se dice. La semántica de la palabra en el texto está determinada por las palabras vecinas. Pero, ¿cómo explicar esto a una máquina si solo comprende una representación numérica? Así nació el método de análisis de texto estadístico
word2vec (inglés Word to vector) .
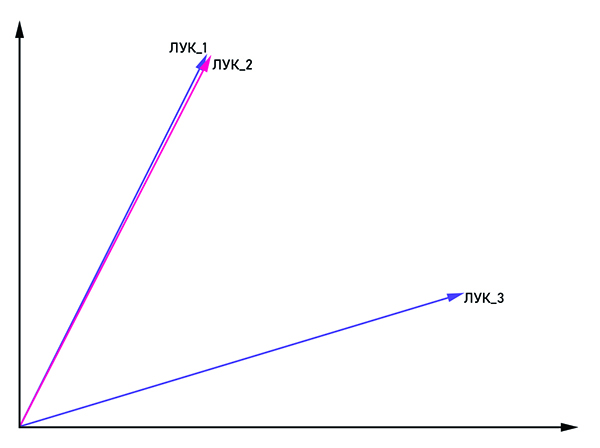 Los vectores bow_1 y bow_2 son paralelos, por lo tanto, esta es una palabra, y bow_3 es un homónimo.
Los vectores bow_1 y bow_2 son paralelos, por lo tanto, esta es una palabra, y bow_3 es un homónimo.La idea es bastante obvia por el nombre: presentar la palabra en forma de un vector con coordenadas (x
1 , x
2 , ..., x
n ). Para combatir la homonimia, las mismas palabras se unen con la etiqueta: "bow_1", "bow_2" y así sucesivamente. Si los vectores bow_n y bow_m son paralelos, entonces pueden considerarse como una palabra. De lo contrario, estas palabras son homónimas. En la salida, cada palabra tiene su propia representación vectorial en el espacio multidimensional (la dimensión del espacio vectorial puede variar de 50 a 1000).

La pregunta sigue siendo qué tipo de red neuronal usar para entrenar un bot de chat condicional. La consistencia es importante en el discurso humano: sacamos conclusiones y tomamos decisiones basadas en lo que se mencionó en la oración anterior o incluso en el párrafo. Sin embargo, una red neuronal recurrente (RNN) es perfecta para estos criterios, ya que a medida que aumenta la distancia entre las partes conectadas del texto, es necesario aumentar el tamaño del RNN, lo que resulta en una disminución en la calidad del procesamiento de la información. Este problema es resuelto por la red LSTM
(inglés Long short-term memory) . Tiene una característica importante: el estado de la celda, que puede permanecer constante o cambiar si es necesario. Por lo tanto, la información en la cadena no se pierde, lo cual es crítico para procesar el lenguaje natural.
Hoy en día hay una gran cantidad de bibliotecas para procesar el lenguaje natural. Si hablamos del lenguaje Python, que a menudo se usa para el análisis de datos, estos son
NLTK y
Spacy . Las grandes empresas también participan en el desarrollo de bibliotecas para PNL, como
NLP Architect de Intel o
PyTorch de investigadores de Facebook y Uber. A pesar de tal gran interés en las empresas a gran escala en los métodos de procesamiento del lenguaje de la red neuronal, los diálogos coherentes se construyen principalmente sobre la base de los métodos clásicos, y la red neuronal desempeña un papel de apoyo en la solución de los problemas de preprocesamiento y clasificación del habla.
¿Cómo se puede utilizar la PNL en los negocios?
Las aplicaciones más obvias para el procesamiento del lenguaje natural incluyen traductores automáticos, bots de chat y asistentes de voz, algo que encontramos todos los días. La mayoría de los empleados del centro de llamadas pueden ser reemplazados por asistentes virtuales, ya que alrededor del 80% de las solicitudes de los clientes a los bancos se relacionan con problemas bastante típicos. El chatbot también hará frente con calma a la entrevista inicial del candidato y la grabará en una reunión "en vivo". Curiosamente, la jurisprudencia es una dirección bastante precisa, por lo que incluso aquí el bot de chat puede convertirse en un consultor exitoso.

La dirección b2c no es la única donde se pueden usar los bots de chat. En las grandes empresas, la rotación de empleados es bastante activa, por lo que todos deben ayudar a adaptarse al nuevo entorno. Como las preguntas del nuevo empleado son bastante típicas, todo el proceso se automatiza fácilmente. No es necesario buscar una persona que le explique cómo repostar la impresora, a quién contactar en cualquier problema. El bot de chat interno de la compañía funcionará bien con esto.
Usando PNL, puede medir con precisión la satisfacción del usuario con un nuevo producto mediante el análisis de revisiones en Internet. Si el programa identificó la revisión como negativa, entonces el informe se envía automáticamente al departamento apropiado, donde las personas vivas ya están trabajando con él.
Las posibilidades del procesamiento del lenguaje solo se ampliarán, y con ellas el alcance de su aplicación. Si 40 personas trabajan en el centro de llamadas de su empresa, vale la pena considerarlo: ¿tal vez sea mejor reemplazarlos con un equipo de programadores que armarán un bot de chat para usted?
Puede obtener más información sobre las posibilidades del procesamiento del lenguaje en nuestro curso de
fin de semana de IA , donde Anna Vlasova hablará en detalle sobre los bots de chat en el marco del tema de la inteligencia artificial.