Una característica importante de las tareas de aprendizaje automático es que se pueden lograr resultados igualmente buenos utilizando diferentes métodos. Esto da emoción a los concursos de ML: incluso teniendo otras competencias que un oponente obviamente fuerte, aún puedes ganar. Los equipos de Tensorborne y Neurobotics tenían casi las mismas posibilidades de ganar el hackathon DeepHack y finalmente tomaron los primeros dos lugares. En el
entrenamiento de Yandex, los representantes de ambos equipos hicieron un voluminoso informe. En la decodificación, encontrará análisis detallados de soluciones y consejos para competidores principiantes.
Y, por supuesto, tomar unas vacaciones de hackathon. Cuando participas en un hackathon semanal y también trabajas al mismo tiempo, es malo. Llegas a las 7 pm, después de haber trabajado un poco, siéntate y compila Docker con TensorFlow, Keras, para que todo esto comience en algunos servidores remotos a los que ni siquiera tienes acceso. En algún lugar en dos noches se contrae la catarsis, y funciona para ti, sin Docker, sin todo, porque entendiste que es posible y así.
Vitaly Davydov:
- Hola a todos! Deberíamos haber tenido dos informes, pero decidimos combinarlos en uno grande, porque estamos hablando del primer y segundo lugar en la competencia DeepHack. Representamos a dos equipos. Nuestro equipo Tensorborne ocupó el segundo lugar y el equipo de Gregory Neurobotics, el primero.

El informe constará de tres partes principales. En la introducción, hablaré sobre la historia de DeepHack, qué es, cuáles fueron las métricas, etc. A continuación, los chicos hablarán sobre soluciones, sobre qué problemas, ejemplos, etc.
Antes de hablar sobre DeepHack, debe tenerse en cuenta que es un pequeño subconjunto de otra competencia global muy grande, ConvAI2, que lanzó Facebook el año pasado. Este año es la segunda iteración. En algún momento, Facebook patrocinó el Instituto de Física y Tecnología de Moscú, y la competencia DeepHack se creó sobre la base del laboratorio PhysTech.

Lea más sobre ConvAI en sí. ¿Qué problema está tratando de resolver? Se especializa en sistemas interactivos. El problema con los sistemas de diálogo es que no existe una herramienta de evaluación única, una herramienta de evaluación, para comprender la calidad de los diálogos. Esto es muy subjetivo de persona a persona: a alguien le puede gustar la conversación, a alguien no. La tarea global general de ConvAI es crear una métrica unificada común para evaluar diálogos, que aún no está disponible. Premio: $ 20,000 para AWS Mechanical Turk. Estos no son préstamos a Amazon, son préstamos solo a Mechanical Turk, que de hecho es un análogo de Yandex.Tolki. Este es un servicio de crowdsourcing que le permite realizar un marcado en los datos.
La tarea, que se basa en ConvAI, es construir un chit-chat-bot con el que puedas entablar algún tipo de diálogo. Eligieron tres métricas: Perplejidad, Hits @ 1 y F1. A continuación, mostraré la tabla que estaba en el momento de nuestra presentación.
La evaluación por la cual intentaron hacer esto pasó por tres etapas. La primera etapa son las métricas automáticas, luego la evaluación de AWS Mechanical Turk y luego el chat en vivo con voluntarios.
Como ConvAI está patrocinado por Facebook, está promoviendo activamente su biblioteca para crear sistemas de conversación ParlAI. Es bastante complicado, pero creo que todos los participantes usaron esta biblioteca. Lo tratamos durante bastante tiempo, no es compatible con Python 3.6, por ejemplo, y hay varios problemas con él.
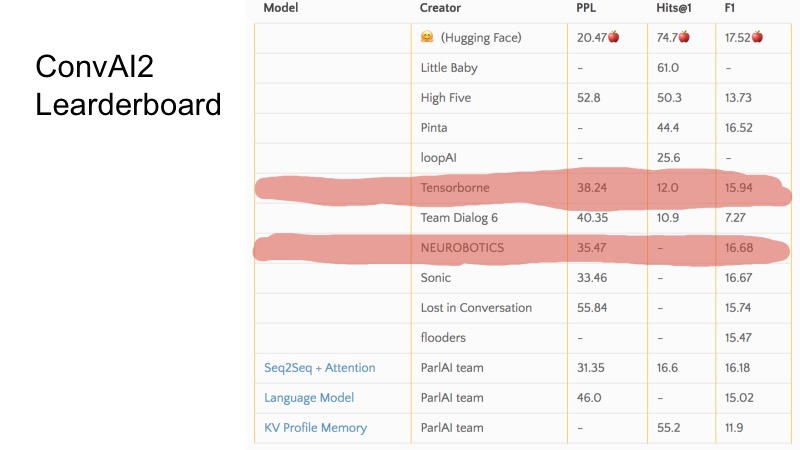
En estas pocas líneas puede ver qué puestos ocupamos en el momento de la presentación. En general, ConvAI está extrañamente organizado en el sentido de que hay tres métricas y no está muy claro cómo va la clasificación en esta tabla. Se puede ver que para algunas métricas, algunos equipos son más altos y otros más bajos. La organización de todo el ConvAI fue un poco extraña.
Pero hay tres líneas de base básicas. Para calificar para DeepHack, era necesario romper esta línea de base, y los 10 mejores mejores equipos llegaron a la final. En secreto, diré que solo 8 equipos enviaron decisiones, y todos llegaron a la final. No fue muy difícil.

La tarea de DeepHack fue un poco más comprensible y directa. Tuvimos que volver a construir un robot hablador, pero que emularía cierta personalidad. Es decir, al robot se le dio una descripción de una persona en la entrada, y durante una conversación con él tuvo que revelarlo. El premio fue bastante interesante: un viaje a los NIPS este otoño, que está totalmente patrocinado.
La métrica, a diferencia de ConvAI, ya era diferente. Hubo dos métricas, y la métrica total se pondera entre las dos. La primera métrica es la calidad general, una evaluación de qué tan adecuadamente respondió el bot, qué tan interesante fue comunicarse con él, si estaba escribiendo basura, etc. La segunda métrica es el juego de roles, ya sea 0 o 1. Significa ¿El bot entró en la descripción que le dieron? La persona que se comunica con el bot no ve la descripción. La evaluación tuvo lugar en Telegram, es decir, había un solo bot de Telegram, y cuando el usuario comenzó a comunicarse con él, llegó a algún bot aleatorio de todas las presentaciones, para ser honesto. Yandex y MIPT, al parecer, vertieron un poco de tráfico allí, y hubo alrededor de 10 mil diálogos, por lo que recuerdo.
Ya dije sobre la ronda de clasificación. La final fue a tiempo completo. Tuvo lugar durante siete días de trabajo en el Instituto de Física y Tecnología de Moscú, se proporcionó un grupo, un lugar, nos sentamos y trabajamos allí. De hecho, la evaluación se realizó todos los días, y el puntaje final, la calificación del bot al final, se calculó de esta manera. La competencia comenzó el lunes, la primera presentación fue el martes y la evaluación tuvo lugar al día siguiente. La solución que publicó el martes fue evaluada el miércoles con un peso de 1.5. Lo que envió el miércoles, con un peso de 1.4, etc.

Sobre el conjunto de datos que Facebook dio para capacitación. Se llama Persona-Chat y es una descripción de dos personalidades y un conjunto de diálogos. Hay una descripción de la primera persona y la segunda. En el proceso de describir el diálogo, intentan revelarse mutuamente. Eso es todo lo que se ha dado. Sin embargo, como siempre, en la competencia no estaba prohibido usar otros conjuntos de datos de terceros.
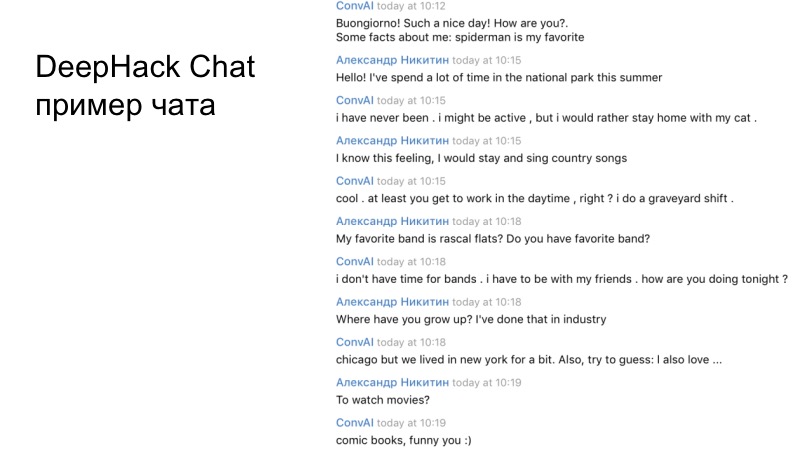
Un ejemplo del diálogo de nuestro equipo. Si lees detenidamente, está claro que el bot resultante funciona de manera bastante adecuada y responde de manera bastante correcta.
Gregory hablará sobre el primer lugar.
Grigory Rashkov:
- Me gustaría hablar sobre nuestra experiencia en participar en la competencia, nuestra estrategia y nuestra decisión.

En primer lugar, la peculiaridad de la competencia es que es de larga duración, no teníamos dos días, como en un hackatón ordinario, sino cinco días, para los cuales podríamos tomar muchas decisiones.

Evaluaciones muy subjetivas, porque personas completamente diferentes con sus criterios evaluados, en particular, el organizador del hackathon Mikhail Bubtsev dijo que si incluso adivinaba de qué perfil estaba hablando, pero el robot en algún momento contradecía su perfil, respondía la pregunta no tanto , como está escrito, eligió un perfil diferente, incluso si sabía de qué se trataba.
Y el tercero es la falta de validación. Los participantes no pudieron hacer un pequeño cambio e inmediatamente recibieron comentarios.
Como en todas las películas de terror, nuestro equipo al principio decidió separarse. El primer grupo participó en nuestra solución principal basada en la WAN de Wasserstein, el segundo grupo participó en el bot, el panel de administración del bot basado en la línea de base. Porque tuvimos que enviar algo el primer y segundo día.

Brevemente sobre la línea base: Seq2Seq más atención, que está ligeramente adaptada para esta tarea específica. Como exactamente Se envía una frase a la entrada, la incrustación se toma de GloVe, pero luego se considera más la presentación de cada frase como una incrustación ponderada. Los pesos se seleccionan en función de la frecuencia inversa de la palabra. Cuanto más rara vez aparece una palabra, más peso trae.

Esto es necesario para reflejar la singularidad de estas características. Todo iba a un conjunto, una matriz, se construyó una máscara sobre la base de este conjunto y un estado oculto, luego esta máscara se superpuso en el conjunto, se obtuvo un contexto y luego se conectó, a través de la no linealidad, se alimentó a la entrada de los decodificadores.

Para el primer día, aún no hemos escrito nuestra decisión, tuvimos que enviar algo, así que escribimos un agente basado en la línea de base, pero nos propusimos destacar de alguna manera entre la masa gris de agentes. Para hacer esto, usamos heurística simple, nuestro bot fue el primero en iniciar un diálogo y usó una sonrisa en esta frase. Y funcionó.
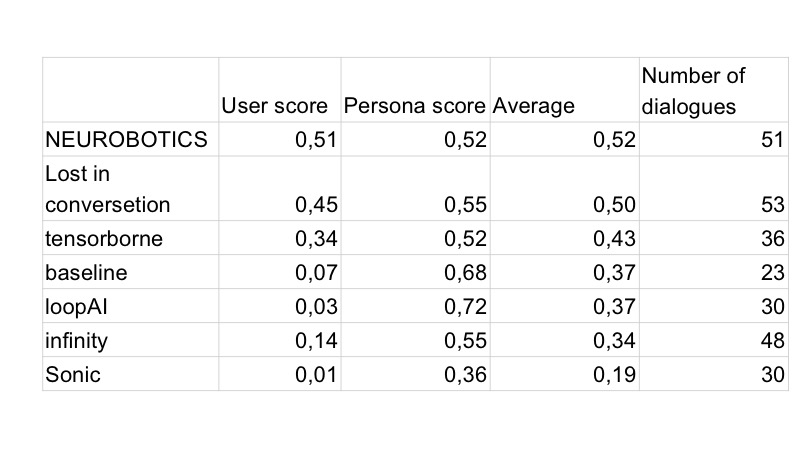
Naturalmente, al día siguiente, todos los bots comenzaron a fabricarse primero, y todos tenían emoticones. El segundo día, los residentes de Vilabaggio continuaron trabajando con la GAN, los residentes de Vilaribo probaron otras heurísticas.
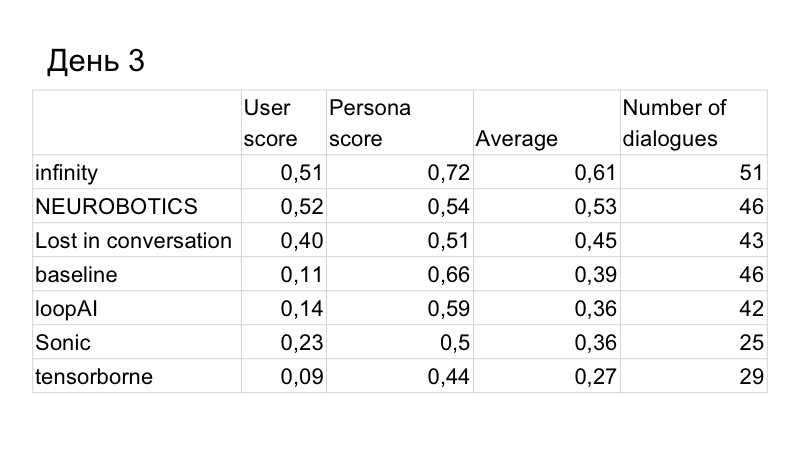
Como resultado, la puntuación en la calidad del diálogo mejoró ligeramente, pero la persona nos superó. Estos son los resultados del tercer día, solo quedaban dos días. Entendimos que no tenemos suficiente tiempo para escribir un GAN y probarlo normalmente, porque ha estado estudiando durante mucho tiempo, mucho, tenemos que seleccionar muchos hiperparámetros. Así que decidimos cambiar a la línea de base, porque funciona muy bien.

Nuestra tarea era mejorar el reconocimiento del perfil del usuario. Propusimos tal heurística. Cual era el problema El usuario habló felizmente con el bot, preguntándole qué tipo de trabajo tenía, pasatiempos, qué tipo de automóvil maneja, el bot respondió a todo esto bien, porque el bot generalmente respondió bien. Como resultado, al final del diálogo, el usuario vio dos perfiles que no tenían nada que ver con lo que estaba en el diálogo, simplemente porque allí se indicaban otras cosas que las que el usuario preguntaba. Por lo tanto, decidimos que era necesario de alguna manera dar información del perfil.
¿Cómo hacer esto de la manera más lógica? Si una persona tiene algún interés, probablemente hablará de ellos, busque intereses comunes. Por lo tanto, decidimos que el bot en algunos puntos hará preguntas en función de su perfil. Hubo un efecto interesante de que el generador, que se escribió simplemente de acuerdo con las reglas lingüísticas de G, utiliza algún hecho A del perfil, como resultado, G (A) se ingresa en el diálogo, todo esto se envía a la memoria del bot, y la próxima vez que el modelo genera información, procediendo tanto del perfil como de este diálogo, es decir, con mayor probabilidad dirá algo relacionado con el perfil.
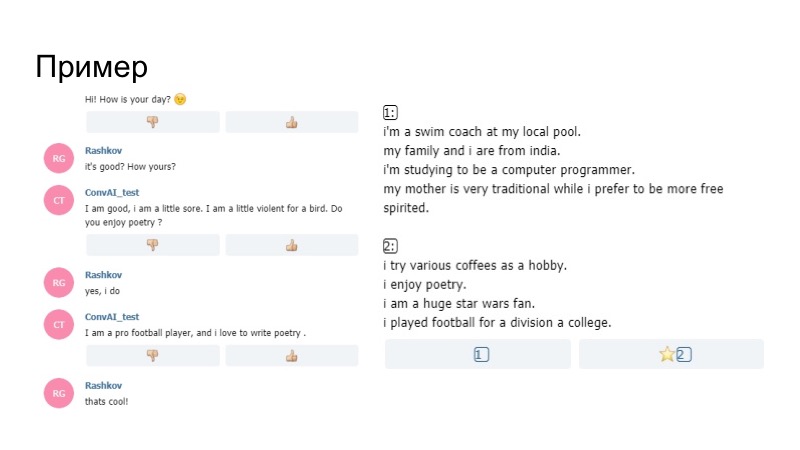
¿Cómo se veía en realidad? El bot en el perfil dice que está encantado con la poesía, luego, durante la conversación, me pregunta si me gusta la poesía. Yo digo que sí, y más allá de su modelo, no el generador que construimos de acuerdo con las reglas, dice que le gusta escribir poesía. Por lo tanto, el bot se centró en su perfil y funcionó.

Regresamos al primer lugar nuevamente. El último día quedó. Notamos que, sin embargo, estamos perdiendo como diálogo.

Aprovechamos varias soluciones más. En primer lugar, usaron paráfrasis, analizaron lo que dijeron otras personas, porque los organizadores presentaron esta base de datos y notaron que muchas personas se comunican con el bot no es del todo correcto.
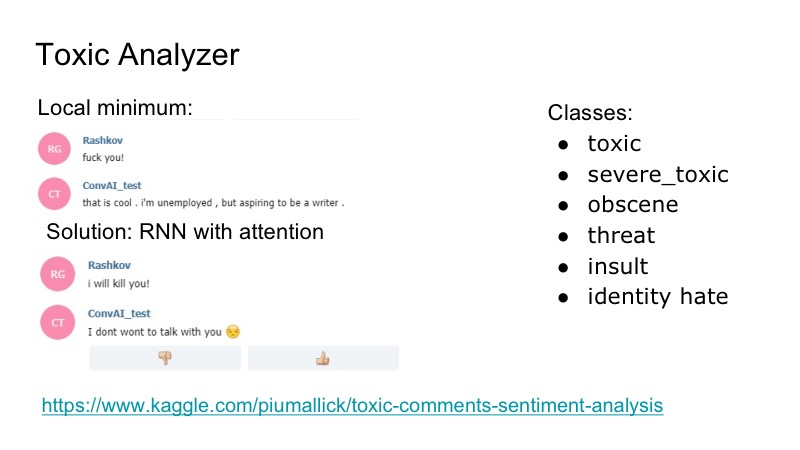
Hay un mínimo local interesante en el bot: responde muy bien a cualquier insulto, está de acuerdo con ellos, y para solucionarlo, decidimos usar la competencia de Kaggle para el analizador de comentarios tóxicos, escribimos un clasificador muy simple, también con atención de RNN. En ese conjunto de datos había las siguientes clases, superpuestas: insultos, amenazas ... Decidimos no estudiar el modelo por separado, quién hablará, porque tal problema se encontró, pero no fue muy frecuente. Por lo tanto, acabamos de escribir una especie de mordaza que el bot respondió, y todos estaban contentos.

Además, utilizamos paráfrasis para enriquecer el discurso de nuestro bot. Esto tampoco fue muy difícil, reemplazamos las palabras de la frase por sinónimos, observamos los n-gramos resultantes en la frase, de modo que no diferían mucho de los que eran originalmente, y luego elegimos la combinación más adecuada para la frase con la mayor probabilidad.
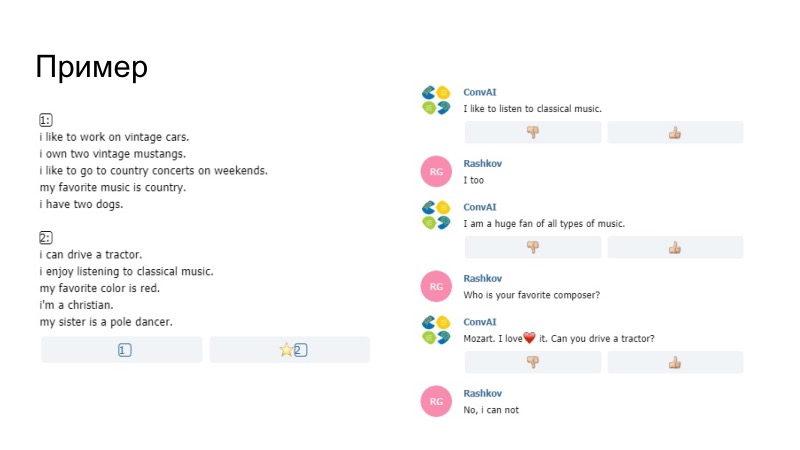
Como ejemplo de lo que sucedió, el bot aquí dice que le gusta escuchar música, dice disfrutar en el perfil, ha sido reemplazado por me gusta con nosotros. No estamos seguros de si el modelo en sí o nuestro Paraphraser lo generó, pero esto pasó. Otro comentario de que era imposible enviar solo datos del perfil. Los pentagramas se compararon allí. Si los pentagramas coincidieron con su comentario y su perfil, entonces simplemente esta frase no pasó, los organizadores lo organizaron. Además, entre otras cosas, agregamos un diccionario sonriente.

El segundo ejemplo, tenemos muchas sonrisas. Luego hubo heurísticas, cuando el bot reaccionó a su comportamiento que no le escribió durante mucho tiempo. Parafraser también trabajó aquí, y dio un buen resultado.

La calidad del diálogo fue la mejor, la calidad de representar el papel también.
Intentamos que el modelo generara un conjunto de opciones, y las comparamos con el perfil. Pero me pareció que en este caso el bot funciona peor, no pudimos realizar la validación, solo evaluaciones subjetivas en dos o tres conversaciones. Por lo tanto, decidieron no poner tal cosa, porque el perfil ya estaba bien reconocido.
Luego escribimos una solución al problema inverso, el segundo modelo, que seleccionó el perfil deseado del diálogo. Planeamos usarlo inicialmente para el entrenamiento, con el fin de leer la función de pérdida y distribuirlo aún más en la cuadrícula. Pero esto podría empeorar al hablador en sí mismo, por lo que decidieron no decirlo así. También pensamos usar esto para el comportamiento del bot, pero no tuvimos tiempo para probarlo todo, y decidimos rechazarlo. Además, decidimos poner emoticones basados en el color emocional de la frase, escribimos un modelo, pero no encontramos un conjunto de datos adecuado, y los que se usaron no eran un poco acerca de eso.

Nuestro equipo
Incluso si su modelo principal, que está esperando, no puede escribirlo o da un mal resultado, no se rinda de inmediato, debe intentar algunas cosas más simples, lo cual es bastante natural. Y lo segundo, a veces vale la pena ver lo que le falta a su modelo y pensar en tareas específicas, descomponerlas y resolver problemas específicos, lo cual hicimos. Gracias por su atencion
Sergey Kolesnikov:
- Mi nombre es Sergey Kolesnikov, representaré la decisión de Tensorborne.

Se nos ocurrió un nombre hermoso, fuimos al concurso, se nos ocurrieron muchas piezas diferentes para lanzar dos artículos después de eso, pero no ganamos el hackathon. Por lo tanto, se llamará: "Cómo no ganar el hackathon, pero aún así publicar los dos malditos artículos". Académicos, señor.
Las características de la competencia en la que participamos excedieron nuestra motivación. Debido al hecho de que la evaluación se llevó a cabo diariamente, los paquetes también tuvieron que hacerse a diario, y la recompensa final se determinó, como nos gusta en RL, mediante la suma de descuento. Todo esto se convirtió en el hecho de que teníamos que enviar al menos algo todos los días para que funcionara, y obtuvimos al menos algún tipo de puntaje. Como resultado, realmente se convirtió en lo que quieres: no quieres, pero tenías que remar.
Que tuvimos Vista previa para toda la semana.
A pesar de que el hackathon dijo que era semanal, todo se decidió en cuatro días, lo que parece no ser suficiente para esta tarea ConvAI.
Inicialmente, éramos cinco, todos buenos graduados académicos más o menos Fiztekh, así que el lunes vinimos y lanzamos muchas sugerencias, ideas que puedes probar, qué modelos de aprendizaje profundo probar. Es cierto que no experimentamos con GAN, porque ya experimentamos con ellos para textos y esto no funciona, por lo que tomamos algo más simple, además, había competencias muy similares y teníamos modelos de preentrenamiento. El martes, incluso pudimos lanzar algo sobre aprendizaje profundo, ML fue siempre que fue posible, lanzamos maravillosos acopladores con soporte de GPU y otras cosas para Tensorflow y Keras, tenemos que dar una medalla por separado, ya que esto no es tan trivial como me gustaria
Según los resultados del martes, fueron prometedores, y decidimos mejorar ligeramente nuestro ML con pequeñas heurísticas y similares, y fallamos en el séptimo lugar. Pero gracias a nuestros compañeros de equipo, alguien encontró ElasticSearch y lo intentó. Hubo un momento muy incómodo cuando ElasticSearch funcionó bien, y los modelos DL y ML, etc., fueron un poco menos robustos. El final del concurso estaba cerca. Y como señaló el orador anterior, decidimos remar en la dirección que funciona. Tomamos ElasticSearch, pequeñas heurísticas y pensamos que era lo suficientemente bueno, y realmente bueno, porque ocupamos el segundo lugar.
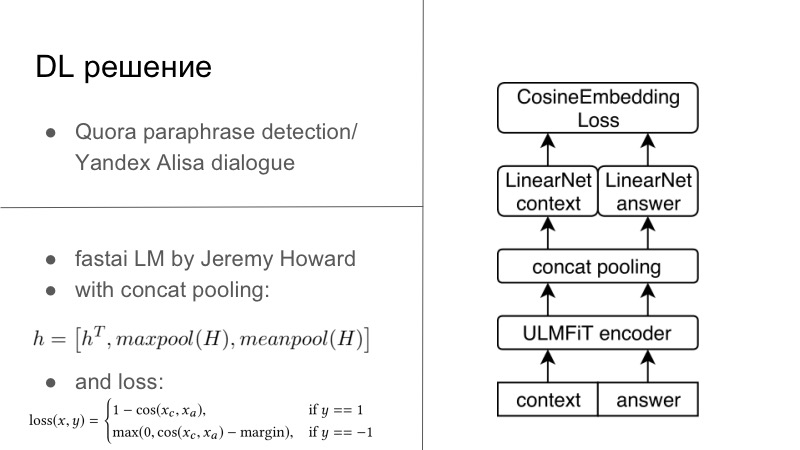
Más detalles En realidad, había varias soluciones DL. La primera solución DL fue bastante simple. Quién recuerda, el año anterior al año pasado, hubo un concurso de detección de paráfrasis de Quora, y este año hubo un concurso de Yandex para que Alice construyera diálogos y más. Puede notar que las tareas allí son muy cercanas. En el primero era necesario decir si estas dos frases eran paráfrasis, y en el segundo era necesario continuar el diálogo. Pensamos que ya que estamos desarrollando sistemas de diálogo, sigamos también el diálogo bien. Y funcionó perfectamente, el diálogo con Quora fue muy personal.
Básicamente, parecía que teníamos un codificador, generalmente todos entrenamos en nuestros RNN habituales, y preferiblemente LSTM con atención y otras cosas. Y luego usamos de manera estándar la pérdida de incrustación de Cosaine presentada en la diapositiva a continuación, u otra pérdida de incrustación del tipo de pérdida de Tripler, o algo más que incorpora paráfrasis o respuestas a un diálogo específico, y no retrasos de paráfrasis, etc. Esta fue la primera solución, estaba en Tensorflow, Keras, estaba lista, la probamos y fue bastante buena.
Otra solución nació en un día dos hackatones por las tardes. Hay un tipo maravilloso, Jeremy Howard, él promueve DL y ML para todos, tiene dos cursos maravillosos que le presentan el curso de este negocio y otras cosas, y para este curso escribió su FastAI. Todo esto funciona en PyTorch, y en muchos sentidos, incluso reescribe PyTorch, este es uno de los inconvenientes de esta lib. Pero por las ventajas, Jeremy tiene poco que ver con la PNL, este año en marzo publicaron un artículo con otro estudiante donde entrenaron a LSTM en todas las mejores prácticas en el maravilloso FastAI, con muchos trucos que promueve en su curso, y obtuvieron prácticamente SOTA para todo
Como soy un pequeño evangelista de PyTorch, todavía pude arrancar de raíz este modelo de FastAI, incluirlo, ya se puede decir, en mi marco de PyTorch, e incluso entrenarlo todo para esta tarea. Básicamente, teníamos un cierto contexto de diálogo, de hecho, incluso si teníamos varias oraciones, simplemente lo concatena en una oración fuerte. answer, . FastAI, Universal Language Model — — Encoder.
, , , 1 , seq2seq. . , , FastAI — Concat poolling. ? seq2seq, attention. maxpool minpool , , .
, , , , maxpool minpool, . , — H, Hc Ha. , feedforward , . , , , , metric learning. — CosineEmbedding Loss, PyTorch.
, loss . , contrastive loss, , . , .
DL-. ElasticSearch, .
? , - ElasticSearch . - - Persona Dataset , , Facebook, , , - . - . , , , , , Persona Dataset , Amazon Mechanical Turk , .
ElasticSearch, , . , Persona Dataset , , 10 . , . , , , , .
- . , Persona , , , , , evaluation. heuristic solutions.
, , , , . . , , , , , . .
— . , — -, -, , .
dirty hack. , , . . — , .

? , -DL- , DL, . , , , . . , -, , , . , , . . , , . DL , ElasticSearch .
, personality score. , -, 0,25–0,3 , . , , - .

. — , , , Docker ElasticSearch, . , . . . Also, try to guess… , — , funny you. , general, . , , .
, , . . , — , , . , Docker, .

? ConvAI , NIPS, - .
-, ElasticSearch . , , . , , ElasticSearch . , DL.
-, DL-. : , , , . , , , , .
, . , . , . — pre-trained- ( — . .), . .
, proposals , RL bandits . , . — . , . , , , , toxic- . .
— . , DeepHacks . NLP, DeepHack , , « ». , . . , , , , , .
— . distributed- , . , DeepHack. - . . , , , , .
! . pre-trained-. , , .
, . , . 7 , , Docker TensorFlow, Keras, - , . - , — Docker, , , .
, , - , , . . Gracias