En la presentación de NVIDIA SIGGRAPH 2018, el CEO de la compañía, Jensen Juan, presentó oficialmente la tan esperada (y se rumoreaba y especulaba) arquitectura de GPU Turing. La próxima generación de GPU NVIDIA, Turing, incluirá una serie de nuevas características y verá el mundo a finales de este año. Aunque la visualización profesional (ProViz) ha sido el foco de los anuncios de hoy, esperamos que la nueva arquitectura se use en otros productos NVIDIA. La revisión de hoy no es solo una lista de todas las características de Turing.

Procesamiento híbrido y redes neuronales: RT y núcleos tensoriales
Entonces, ¿qué tiene de especial y nuevo la arquitectura de Turing? Marquee, al menos para la comunidad NVIDIA ProViz, está diseñado para renderizado híbrido, que combina el trazado de rayos con la rasterización tradicional.

Cambio importante: NVIDIA ha incluido aún más equipos de trazado de rayos en Turing para ofrecer el trazado de rayos acelerado por hardware más rápido. Una novedad en la arquitectura de Turing es la unidad de computación especializada RT Core, como lo llama NVIDIA, actualmente no hay suficiente información al respecto, solo se sabe que su función es compatible con el trazado de rayos. Estas unidades de procesador aceleran tanto la comprobación de la intersección de rayos y triángulos como la manipulación de BVH (jerarquías de volúmenes delimitadores).
NVIDIA afirma que los componentes de Turing más rápidos pueden contar con 10 mil millones de rayos (Giga) por segundo, lo cual es una mejora de 25 veces en el rendimiento del trazado de rayos en comparación con el Pascal no acelerado.
La arquitectura de Turing incluye núcleos de tensor Volta que se han reforzado. Los núcleos tensoriales son un aspecto importante de varias iniciativas de NVIDIA. Junto con la aceleración del trazado de rayos, una herramienta importante en la "bolsa de trucos de magia" de NVIDIA es reducir la cantidad de rayos requeridos en la escena usando la reducción de ruido de IA para borrar la imagen, aquí los núcleos tensoriales funcionan mejor. Por supuesto, esta no es la única área en la que son buenos: todas las redes neuronales y los imperios de inteligencia artificial de NVIDIA están construidos sobre ellos.
Turing se caracteriza por el soporte de un rango más amplio de precisión, lo que significa la posibilidad de una aceleración significativa en las cargas de trabajo que no tienen requisitos de alta precisión. Además del modo de precisión Volta FP16, los núcleos tensoriales de Turing admiten INT8 e incluso INT4. Esto es 2 y 4 veces más rápido que FP16, respectivamente. Aunque NVIDIA no quería entrar en detalles en la presentación, sugeriría que implementen algo similar al empaquetado de datos, que se utiliza para operaciones de baja precisión en núcleos CUDA. A pesar de la precisión reducida de la red neuronal (el retorno se reduce, de acuerdo con INT4 obtenemos solo 16 (!) Valores), hay ciertos modelos que realmente necesitan este bajo nivel de precisión. Como resultado, los modos de precisión reducida mostrarán un buen rendimiento, especialmente en tareas de salida, lo que sin duda complacerá a algunos usuarios.
Volviendo al renderizado híbrido en general, es interesante que a pesar de estas grandes aceleraciones individuales, la promesa general de NVIDIA de aumentar el rendimiento parece un poco más modesta. Aunque la compañía promete aumentar la productividad en 6 veces en comparación con Pascal, es hora de preguntar qué partes se aceleran, y en comparación con cuáles. El tiempo lo dirá.
Mientras tanto, para hacer un mejor uso de los núcleos tensoriales fuera del trazado de rayos y las tareas de aprendizaje profundo enfocadas de forma estrecha, NVIDIA implementará un SDK, NVIDIA NGX, que permitirá la integración de redes neuronales en el procesamiento de imágenes. NVIDIA espera el uso de redes neuronales y núcleos tensoriales para el procesamiento adicional de imágenes y videos, incluidos métodos como el próximo Deep-Anti-Aliasing (DLAA).
Turing SM: núcleos INT dedicados, caché individual, sombreado de velocidad variable
Junto con los núcleos de RT y tensor, la propia arquitectura Turing Streaming Multiprocessor (SM) presenta nuevos trucos. En particular, uno de los últimos cambios de Volta fue heredado, como resultado de lo cual los núcleos Integer se asignan en sus propios bloques y no forman parte de los núcleos de coma flotante CUDA. La ventaja es una generación de direcciones más rápida y un rendimiento de Fusion Multiply Add (FMA).
En cuanto a ALU (todavía estoy esperando la confirmación de Turing): soporte para operaciones más rápidas con baja precisión (por ejemplo, FP16 rápido). En Volta, esto se implementa como operaciones de FP16 a doble frecuencia en relación con FP32, y operaciones INT8 a una velocidad 4x. Los núcleos tensoriales ya admiten este concepto, por lo que sería lógico transferirlo a los núcleos CUDA.
El FP16 rápido, la tecnología matemática empaquetada rápida y otras formas de empaquetar múltiples operaciones pequeñas en una operación grande son componentes clave para mejorar el rendimiento de la GPU en un momento en que la Ley de Moore se está desacelerando.
Utilizando tipos de datos grandes (exactos) solo cuando sea necesario, se pueden agrupar para hacer más trabajo en el mismo período de tiempo. Esto es principalmente importante para la salida de redes neuronales, así como para el desarrollo de juegos. El hecho es que no todos los programas de sombreado necesitan precisión FP32, y reducir la precisión puede mejorar el rendimiento y reducir el ancho de banda de memoria útil y el uso del archivo de registro.
Turing SM incluye algo que NVIDIA llama "arquitectura de caché unificada". Como todavía estoy esperando diagramas SMID oficiales de NVIDIA, no está claro si esta es la misma unificación que vimos con Volta, donde el caché L1 se combinó con la memoria compartida, o si NVIDIA lo llevó un paso más allá. En cualquier caso, NVIDIA afirma que ahora ha ofrecido el doble de ancho de banda en relación con la "generación anterior", pero no está claro si se trata de Pascal o Volta (la última es más probable).
Finalmente, profundamente oculto en el comunicado de prensa de Turing, se mencionó el soporte de sombreado de velocidad variable. Esta es una tecnología de representación gráfica relativamente joven y en evolución, sobre la cual hay poca información (especialmente acerca de cómo NVIDIA la implementa exactamente). Pero a un nivel muy alto de abstracción, suena como "la tecnología de última generación de NVIDIA que le permite aplicar sombreado con diferentes resoluciones, lo que permite a los desarrolladores mostrar diferentes áreas de la pantalla con diferentes resoluciones efectivas para la calidad de la concentración (y el tiempo de representación) en las áreas donde más se necesita" .
Alimentar a la bestia: soporte GDDR6
Dado que la memoria utilizada por las GPU es desarrollada por compañías externas, no hay secretos. JEDEC y su gran Samsung de 3 miembros, SK Hynix y Micron están desarrollando memoria GDDR6 como el sucesor de GDDR5 y GDDR5X. NVIDIA ha confirmado que Turing lo apoyará. Dependiendo del fabricante, se anuncia que la GDDR6 de primera generación tiene un ancho de banda de memoria de hasta 16 Gb / s por bus, que es el doble que las tarjetas NVIDIA GDDR5 de última generación y un 40% más rápido que las tarjetas NVIDIA GDDR5X más recientes.
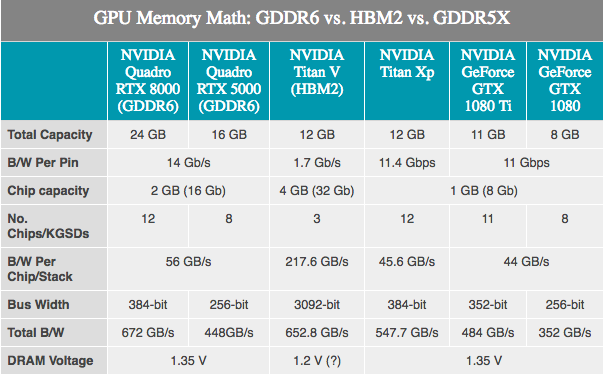
En comparación con GDDR5X, GDDR6 no parece un gran avance, ya que muchas de las innovaciones de GDDR6 ya se han aplicado a GDDR5X. Los cambios fundamentales aquí incluyen voltajes operativos más bajos (1.35v), y la memoria interna ahora está dividida: dos canales de memoria por microcircuito. Para un chip estándar de 32 bits: dos canales de memoria de 16 bits, en total tenemos 16 de esos canales en una tarjeta de 256 bits. Aunque esto, a su vez, dice que hay una gran cantidad de canales, las GPU obtendrán el máximo beneficio de la innovación, porque históricamente son los dispositivos más "paralelos".

NVIDIA, por su parte, ha confirmado que las primeras tarjetas Turing Quadro usarán GDDR6 a 14 Gb / s. Al mismo tiempo, NVIDIA también confirmó el uso de la memoria de Samsung, especialmente para sus dispositivos avanzados de 16 gigabytes. Esto es importante porque significa que una GPU NVIDIA de 256 bits típica puede equiparse con 8 módulos estándar y obtener 16 GB de capacidad de memoria total, o incluso 32 GB si usan el modo clamshell (permite el direccionamiento de 32 GB de memoria en 256 bits estándar bus).
Todo tipo de detalles: NVLink, VirtualLink y 8K HEVC
Ya terminando con una revisión de la arquitectura de Turing, NVIDIA confirmó casualmente el soporte para algunas de las nuevas funciones de E / S externas. El soporte de NVLink estará presente en al menos varios productos de Turing. Recuerde que NVIDIA lo usa en las tres nuevas tarjetas Quadro. NVIDIA ofrece una configuración de GPU bidireccional.
Un punto importante (antes de que una parte de nuestra audiencia orientada al juego profundice en la lectura): la presencia de NVLink en el equipo de Turing no significa que se utilizará en tarjetas de video de consumo. Quizás todo se limitará solo a las tarjetas Quadro y Tesla.
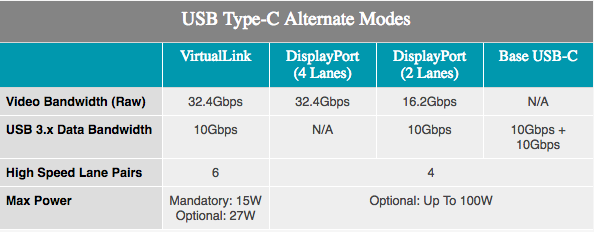
Con la adición del soporte VirtualLink, los jugadores y usuarios de ProViz tendrán qué esperar de la realidad virtual. El mes pasado se anunció un modo USB tipo C alternativo que admite 15 W + de potencia, 10 Gb / s de transferencia de datos gracias a USB 3.1 Gen 2, 4 bandas DisplayPort HBR3 en un cable. En otras palabras, esta es una conexión DisplayPort 1.4 con datos y potencia adicionales. Esto permite que la tarjeta de video controle directamente los auriculares VR. El estándar es compatible con NVIDIA, AMD, Oculus, Valve y Microsoft, por lo que los productos de Turing serán los primeros de una serie de productos que admitirán el nuevo estándar.
Aunque NVIDIA apenas tocó el tema, sabemos que la unidad de codificador de video NVENC se ha actualizado en Turing. La última iteración de NVENC agrega soporte especial de codificación HEKC 8K. Mientras tanto, NVIDIA pudo mejorar la calidad de su codificador, permitiéndole lograr la misma calidad que antes, con una tasa de bits de video un 25% menor.
Indicadores de desempeño
Junto con las especificaciones de hardware anunciadas, NVIDIA muestra varias cifras del rendimiento del equipo de Turing. Cabe señalar que aquí sabemos muy, muy poco. Aparentemente, los componentes se basan en los SKU de Turing incluidos total y parcialmente con 4608 núcleos CUDA y 576 núcleos tensoriales. Sin embargo, las frecuencias no se revelaron, ya que estos números están perfilados para el hardware Quadro, es probable que veamos velocidades de reloj más bajas que en cualquier equipo de consumo.

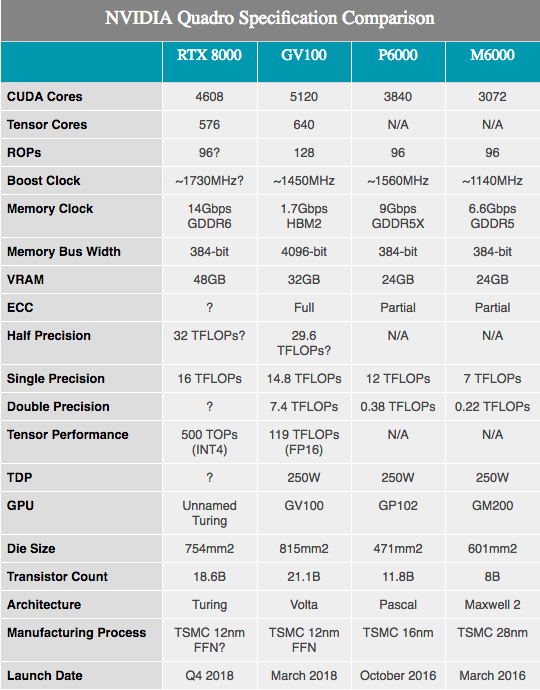
Junto con los 10GigaRays / seg antes mencionados para los núcleos RT, el rendimiento de los núcleos tensoriales NVIDIA es de 500 trillones de operaciones de tensor por segundo (TOP 500T). Como referencia, NVIDIA a menudo menciona la GPU GV100 como capaz de entregar un máximo de 120T TOP, pero esto no es lo mismo. En particular, mientras que el GV100 se menciona en el procesamiento de las operaciones de FP16, el rendimiento de Turing se cita con una precisión extremadamente baja INT4, que es solo una cuarta parte del tamaño de FP16 y, por lo tanto, aumenta el rendimiento cuatro veces. Si normalizamos la precisión, los núcleos tensoriales de Turing no parecen tener el mejor rendimiento por núcleo, sino que ofrecen más opciones de precisión que Volta. En cualquier caso, 576 núcleos tensoriales en este chip lo ponen casi a la par con el GV100, que tiene 640 de esos núcleos.
Con respecto a los núcleos CUDA, NVIDIA afirma que la GPU Turing puede ofrecer un rendimiento de 16 TFLOPS. Esto está ligeramente por delante de los 15 TFLOPS de rendimiento con la precisión única del Tesla V100, o incluso más que los 13.8 TFLOPS del Titan V. Si está buscando información más amigable para el consumidor, es aproximadamente un 32% más que el Titan Xp. Después de haber esbozado algunos cálculos aproximados en papel, podemos suponer que la velocidad de reloj de la GPU es de aproximadamente 1730 MHz, dado que a nivel SM no hubo cambios adicionales que cambiarían las fórmulas tradicionales de rendimiento de ALU.
Mientras tanto, NVIDIA anunció que las tarjetas Quadro vendrán con memoria GDDR6 que operará a 14 Gb / s. Y mirando las dos mejores SKU Quadro que ofrecen GDDR6 de 48 GB y 24 GB, respectivamente, casi vemos el bus de memoria de 384 bits en esta GPU Turing. En cuanto a los números, esto equivale a 672 GB / s de ancho de banda de memoria para las dos tarjetas Quadro de gama alta.
De lo contrario, con un cambio en la arquitectura, es difícil hacer muchas comparaciones de rendimiento útiles, especialmente cuando se compara con Pascal. Por lo que vimos con Volta, el rendimiento general de NVIDIA ha mejorado, especialmente en cargas de trabajo informáticas bien diseñadas. Por lo tanto, una mejora de aproximadamente el 33% en el rendimiento del papel en comparación con la Quadro P6000 puede ser algo mucho más grande.
Mencionaré el tamaño de cristal de la nueva GPU. Ubicado en 754 mm2, no solo es grande, es enorme. En comparación con otras GPU, solo NVIDIA GV100 es el segundo en tamaño, que actualmente sigue siendo el buque insignia de NVIDIA. Pero con 18.600 millones de transistores, es fácil ver por qué el chip resultante debería ser tan grande. Aparentemente, NVIDIA tiene grandes planes para esta GPU, que al final podrá justificar la presencia de dos enormes procesadores gráficos en su paquete de productos.
NVIDIA, por su parte, no ha indicado un número de modelo específico para esta GPU, ya sea una GPU clase 102 tradicional o incluso una clase 100. Me pregunto si veremos una modificación de este tipo de GPU para un producto de consumo de una forma u otra; es tan grande que NVIDIA puede desear conservarlo para sus GPU Quadro y Tesla más rentables.
Lanzado en el cuarto trimestre de 2018, si no antes
En conclusión, diré que junto con el anuncio de la arquitectura de Turing, NVIDIA anunció que las primeras 4 tarjetas Quadro basadas en GPU de Turing: Quadro RTX 8000, RTX 6000 y RTX 5000 comenzarán a enviarse en el cuarto trimestre de este año. Dado que la naturaleza misma de este anuncio está algo invertida, por lo general NVIDIA anuncia por primera vez los componentes del consumidor, no aplicaría la misma línea de tiempo a las tarjetas de consumidor que no tienen requisitos de validación tan estrictos. Veremos equipos de Turing en el cuarto trimestre de este año, si no antes. Aquellos que quieran comprar Quadro pueden comenzar a ahorrar dinero ahora: lo mejor de las nuevas tarjetas Quadro RTX 8000 le costará alrededor de $ 10,000.
Finalmente, para los consumidores con Tesla de NVIDIA, el lanzamiento del Turing deja a Volta en el limbo. NVIDIA no nos dijo si Turing eventualmente se expandiría en el espacio de gama alta de Tesla, reemplazando el GV100, o si su mejor procesador Volta seguiría siendo el maestro de su dominio durante siglos. Sin embargo, dado que las otras tarjetas de Tesla hasta ahora se han basado en Pascal, son los primeros candidatos para desplazarse de Turing en 2019.
Gracias por quedarte con nosotros. ¿Te gustan nuestros artículos? ¿Quieres ver más materiales interesantes?
Apóyenos haciendo un pedido o recomendándolo a sus amigos, un
descuento del 30% para los usuarios de Habr en un análogo único de servidores de nivel de entrada que inventamos para usted: toda la verdad sobre VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps de $ 20 o cómo dividir el servidor? (las opciones están disponibles con RAID1 y RAID10, hasta 24 núcleos y hasta 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 núcleos) 10GB DDR4 240GB SSD 1Gbps hasta diciembre de forma gratuita al pagar por un período de seis meses, puede ordenar
aquí .
Dell R730xd 2 veces más barato? Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los EE. UU. Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?