La introducción de AI a nivel de chip le permite procesar más datos localmente, porque un aumento en la cantidad de dispositivos ya no da el mismo efecto.
Los fabricantes de chips están trabajando en nuevas arquitecturas que aumentan significativamente la cantidad de datos procesados por vatio y ciclo. El terreno está listo para una de las mayores revoluciones en la arquitectura de chips en las últimas décadas.
Todos los principales fabricantes de chips y sistemas están cambiando la dirección del desarrollo. Entraron en la carrera de las arquitecturas, lo que proporciona un cambio de paradigma en todo: desde los métodos de lectura y escritura hasta la memoria, su procesamiento y, en última instancia, el diseño de varios elementos en un chip. Aunque la miniaturización continúa, nadie está apostando por escalar para hacer frente al crecimiento explosivo de datos de los sensores y aumentar el volumen de tráfico entre máquinas.
Entre los cambios en las nuevas arquitecturas:
- Nuevos métodos para procesar una mayor cantidad de datos en 1 ciclo de reloj, a veces con menos precisión o por prioridad de ciertas operaciones, dependiendo de la aplicación.
- Nuevas arquitecturas de memoria que cambian la forma en que almacenamos, leemos, escribimos y accedemos a los datos.
- Módulos de procesamiento más especializados ubicados en todo el sistema cerca de la memoria. En lugar de un procesador central, los aceleradores se seleccionan según el tipo de datos y la aplicación.
- En el campo de la IA, se está trabajando para combinar varios tipos de datos en forma de plantillas, lo que aumenta efectivamente la densidad de datos y minimiza las discrepancias entre los diferentes tipos.
- Ahora, el diseño en el caso es el componente principal de la arquitectura, y se presta cada vez más atención a la facilidad de cambiar estos diseños.
"Hay varias tendencias que afectan los avances tecnológicos", dijo Stephen Wu, un distinguido ingeniero de Rambus. - En los centros de datos, aprovecha al máximo el hardware y el software. Desde este ángulo, los propietarios de centros de datos están mirando la economía. Introducir algo nuevo es costoso. Pero los cuellos de botella están cambiando, por lo que se están introduciendo chips especializados para una informática más eficiente. Y si reduce los flujos de datos de ida y vuelta a E / S y memoria, esto puede tener un gran impacto ".
Los cambios son más evidentes en el borde de la infraestructura informática, es decir, entre los sensores finales. Los fabricantes de repente se dieron cuenta de que decenas de miles de millones de dispositivos generarían demasiados datos: ese volumen no podría enviarse a la nube para su procesamiento. Pero el procesamiento de todos estos datos en el borde presenta otros problemas: requiere mejoras de rendimiento importantes sin un aumento significativo en el consumo de energía.
"Hay una nueva tendencia hacia una menor precisión", dijo Robert Ober, arquitecto principal de la plataforma de Tesla en Nvidia. - Estos no son solo ciclos computacionales. Este es un paquete de datos más intensivo en la memoria, donde se utiliza el formato de instrucciones de 16 bits ".
Aubert cree que gracias a una serie de optimizaciones arquitectónicas en el futuro previsible, puede duplicar la velocidad de procesamiento cada dos años. "Veremos un aumento dramático en la productividad", dijo. - Para esto necesitas hacer tres cosas. El primero es la informática. El segundo es la memoria. La tercera área es el ancho de banda del host y el ancho de banda de E / S. Se necesita mucho trabajo para optimizar el almacenamiento y la pila de red ".
Ya se está implementando algo. En una presentación en la conferencia Hot Chips 2018, Jeff Rupley, arquitecto principal en el Centro de Investigación Austin de Samsung, señaló varios cambios arquitectónicos importantes en el procesador M3. Uno incluye más instrucciones por latido: seis en lugar de cuatro en el último chip M2. Además, se implementó la predicción de ramificación en redes neuronales y se duplicó la cola de instrucciones.
Tales cambios trasladan el punto de innovación de la fabricación directa de microcircuitos a la arquitectura y el diseño, por un lado, y al diseño de elementos en el otro lado de la cadena de producción. Aunque las innovaciones continuarán en los procesos tecnológicos, es solo a expensas de esto que es increíblemente difícil lograr un aumento del 15-20% en la productividad y la potencia en cada nuevo modelo de chip, y esto no es suficiente para hacer frente al rápido crecimiento en el volumen de datos.
"Los cambios están teniendo lugar a un ritmo exponencial", dijo Victor Pan, presidente y director ejecutivo de Xilinx, en un discurso en la conferencia Hot Chips, "se generarán 10 zettabytes [10
21 bytes] de datos cada año, y la mayoría de ellos no están estructurados".
Nuevos enfoques de la memoria.
Trabajar con tantos datos requiere un replanteamiento de cada componente del sistema, desde los métodos de procesamiento de datos hasta su almacenamiento.
"Ha habido muchos intentos de crear nuevas arquitecturas de memoria", dijo Carlos Machin, director senior de innovación de eSilicon EMEA. - El problema es que necesita leer todas las líneas y seleccionar un bit en cada una. Una opción es crear una memoria que se pueda leer de izquierda a derecha, así como de arriba a abajo. Puede ir aún más lejos y agregar computación a la memoria ".
Estos cambios incluyen cambiar los métodos para leer la memoria, la ubicación y el tipo de elementos de procesamiento, así como la introducción de IA para priorizar el almacenamiento, el procesamiento y el movimiento de datos en todo el sistema.
"¿Qué pasa si, en el caso de datos dispersos, solo podemos leer un byte de esta matriz a la vez, o tal vez ocho bytes consecutivos de la misma ruta de bytes sin desperdiciar energía en otros bytes o rutas de bytes que no nos interesan? ? "Pregunta Mark Greenberg, director de marketing de productos de Cadence". - En el futuro, esto es posible. Si observa la arquitectura de HBM2, por ejemplo, la pila está organizada en 16 canales virtuales de 64 bits cada uno, y necesita obtener solo 4 palabras consecutivas de 64 bits para acceder a cualquier canal virtual. Por lo tanto, es posible crear matrices de datos con un ancho de 1024 bits, escribir horizontalmente, pero leer verticalmente cuatro palabras de 64 bits a la vez ".
La memoria es uno de los componentes principales de la arquitectura von Neumann, pero ahora también se ha convertido en uno de los principales escenarios para los experimentos. "El enemigo principal son los sistemas de memoria virtual, donde los datos se mueven de manera más antinatural", dijo Dan Bouvier, arquitecto jefe de productos para clientes de AMD. - Esta es una transmisión de difusión. Estamos acostumbrados a esto en el campo de los gráficos. Pero si resolvemos los conflictos en el banco de memoria DRAM, obtenemos una transmisión mucho más eficiente. Luego, una GPU separada puede usar DRAM en el rango de eficiencia del 90%, lo cual es muy bueno. Pero si configura la transmisión sin interrupciones, la CPU y la APU también caerán en el rango de eficiencia del 80% al 85% ".
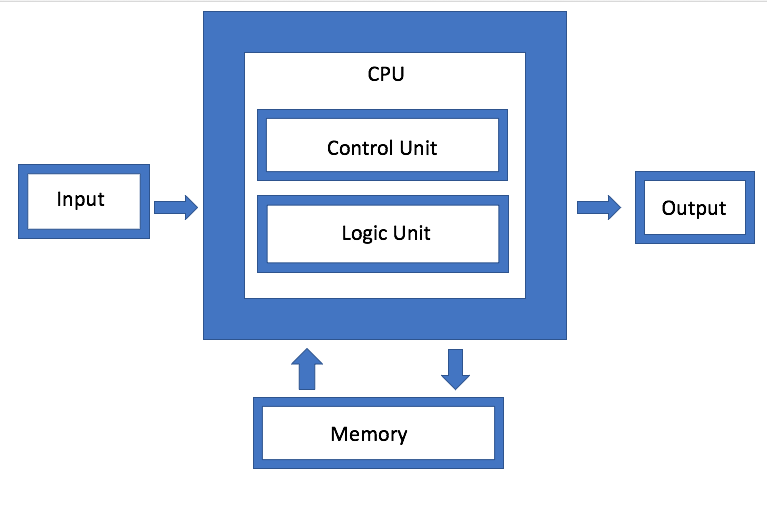 Fig. 1. Arquitectura von Neumann. Fuente: Ingeniería de semiconductores
Fig. 1. Arquitectura von Neumann. Fuente: Ingeniería de semiconductoresIBM está desarrollando un tipo diferente de arquitectura de memoria, que es esencialmente una versión actualizada de la agregación de discos. El objetivo es que, en lugar de usar una sola unidad, el sistema puede usar arbitrariamente cualquier memoria disponible a través de un conector, que Jeff Stucheli, un arquitecto de hardware de IBM, llama "Swiss Army Knife" para conectar elementos. La ventaja del enfoque es que le permite mezclar y combinar diferentes tipos de datos.
"El procesador se está convirtiendo en el centro de una interfaz de señalización de alto rendimiento", dice Stucelli. "Si cambia la microarquitectura, el núcleo realiza más operaciones por ciclo a la misma frecuencia".
La conectividad y el rendimiento deberían garantizar el procesamiento de un volumen radicalmente mayor de datos generados. "Los principales cuellos de botella están ahora en las ubicaciones de movimiento de datos", dijo Wu desde Rambus. "La industria ha hecho un gran trabajo aumentando la velocidad de la informática". Pero si espera datos o plantillas de datos especializadas, entonces necesita ejecutar la memoria más rápido. Por lo tanto, si observa DRAM y NVM, el rendimiento depende del patrón de tráfico. Si los datos se transmiten, la memoria proporcionará un rendimiento muy bueno. Pero si los datos vienen en forma aleatoria, es menos eficiente. Y no importa lo que hagas, con un aumento en el volumen aún tienes que hacerlo más rápido ".
Más informática, menos tráfico.
El problema se agrava por el hecho de que hay varios tipos diferentes de datos generados a diferentes frecuencias y velocidades por los dispositivos en el borde. Para que estos datos se muevan libremente entre diferentes módulos de procesamiento, la administración debe ser mucho más eficiente que en el pasado.
"Hay cuatro configuraciones principales: muchos a muchos, subsistemas de memoria, E / S de baja potencia y topologías de cuadrículas y anillos", dice Charlie Janak, presidente y CEO de Arteris IP. - Puede colocar los cuatro en un chip, lo que sucede con los chips IoT clave. O puede agregar subsistemas HBM de alto rendimiento. Pero la complejidad es enorme, porque algunas de estas cargas de trabajo son muy específicas, y el chip tiene varias tareas de trabajo diferentes. Si observa algunos de estos microchips, obtienen grandes cantidades de datos. Esto es en sistemas como los radares de automóviles y los lidars. No pueden existir sin algunas interconexiones avanzadas ".
La tarea es cómo minimizar el movimiento de datos, pero al mismo tiempo maximizar el flujo de datos cuando sea necesario, y de alguna manera encontrar un equilibrio entre el procesamiento local y centralizado sin un aumento innecesario del consumo de energía.
"Por un lado, este es un problema de ancho de banda", dijo Rajesh Ramanujam, gerente de marketing de productos de NetSpeed Systems. - Desea reducir el tráfico tanto como sea posible, de modo que transfiera los datos más cerca del procesador. Pero si aún necesita mover los datos, es recomendable compactarlos tanto como sea posible. Pero nada existe por sí mismo. Todo debe planificarse desde el nivel del sistema. En cada paso, se deben considerar varios ejes interdependientes. Determinan si usa la memoria en la forma tradicional de leer y escribir, o si usa nuevas tecnologías. En algunos casos, es posible que deba cambiar la forma en que almacena los datos. Si necesita un mayor rendimiento, esto generalmente significa un aumento en el área del chip, lo que afecta la disipación de calor. Y ahora, teniendo en cuenta la seguridad funcional, no se puede permitir la sobrecarga de datos ".
Es por eso que varios módulos de procesamiento de datos prestan tanta atención al procesamiento de datos en el borde y al ancho de banda del canal. Pero a medida que desarrolla diferentes arquitecturas, es muy diferente cómo y dónde se implementa este procesamiento de datos.
Por ejemplo, Marvell introdujo un controlador SSD con inteligencia artificial integrada para manejar la pesada carga informática en el borde. El motor de IA se puede usar para análisis directamente dentro de la unidad SSD.
"Puede cargar modelos directamente en el hardware y hacer el procesamiento del hardware en el controlador SSD", dijo Ned Varnitsa, ingeniero jefe de Marvell. - Hoy hace el servidor en la nube (host). Pero si cada disco envía datos a la nube, esto creará una gran cantidad de tráfico de red. Es mejor hacer el procesamiento en el borde, y el host solo emite un comando, que son solo metadatos. Cuantas más unidades tenga, más potencia de procesamiento. Este es un gran beneficio del tráfico reducido ".
Este enfoque es particularmente interesante porque se adapta a diferentes datos según la aplicación. Por lo tanto, el host puede generar una tarea y enviarla al dispositivo de almacenamiento para su procesamiento, después de lo cual solo se envían los metadatos o resultados de cálculo. En otro escenario, un dispositivo de almacenamiento puede almacenar datos, preprocesarlos y generar metadatos, etiquetas e índices, que luego el host recupera según sea necesario para su posterior análisis.
Esta es una de las posibles opciones. Hay otros Rupli de Samsung enfatizó la importancia de procesar y fusionar modismos que pueden decodificar dos instrucciones y combinarlas en una sola operación.
La IA se ocupa del control y la optimización
En todos los niveles de optimización, se utiliza la Inteligencia Artificial: este es uno de los elementos verdaderamente nuevos en la arquitectura de chips. En lugar de permitir que el sistema operativo y el middleware administren funciones, esta función de monitoreo se distribuye a través del chip, entre los chips y al nivel del sistema. En algunos casos, se introducen redes neuronales de hardware.
"El objetivo no es tanto agrupar más elementos, sino cambiar la arquitectura tradicional", dice Mike Gianfanya, vicepresidente de marketing de eSilicon. - Con la ayuda de la inteligencia artificial y el aprendizaje automático, puede distribuir elementos en todo el sistema, obteniendo un procesamiento más eficiente con pronósticos. O puede usar chips separados que funcionan independientemente en el sistema o en el módulo ".
ARM ha desarrollado su primer chip de aprendizaje automático, que planea lanzar a finales de este año para varios mercados. "Este es un nuevo tipo de procesador", dijo Ian Bratt, ingeniero de honor de ARM. - Incluye un bloque fundamental: es un motor informático, así como un motor MAC, un motor DMA con un módulo de control y una red de difusión. En total, hay 16 núcleos informáticos realizados con la tecnología de proceso de 7 nm, que producen 4 TeraOps a una frecuencia de 1 GHz ".
Dado que ARM trabaja con un ecosistema asociado, su chip es más versátil y personalizable que otros chips AI / ML que se están desarrollando. En lugar de una estructura monolítica, separa el procesamiento por función, por lo que cada módulo informático funciona en un mapa de características separado. Bratt identificó cuatro ingredientes clave: planificación estática, plegado eficiente, mecanismos de estrechamiento y adaptación programada a futuros cambios de diseño.
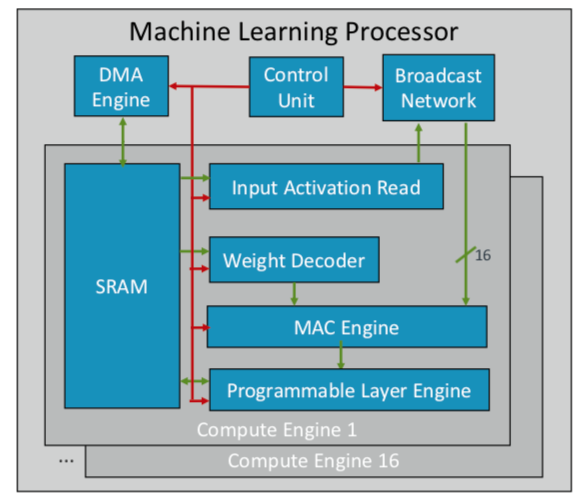 Fig. 2. Arquitectura ARM del procesador ML. Fuente: ARM / Hot Chips
Fig. 2. Arquitectura ARM del procesador ML. Fuente: ARM / Hot ChipsMientras tanto, Nvidia eligió una táctica diferente: crear un motor de aprendizaje profundo dedicado junto a la GPU para optimizar el procesamiento de imágenes y videos.
Conclusión
Utilizando algunos o todos estos enfoques, los fabricantes de chips esperan duplicar el rendimiento cada dos años, manteniéndose al día con el crecimiento explosivo de datos, mientras permanecen dentro del marco ajustado de los presupuestos de energía. Pero esto no es solo más computación. Este es un cambio en la plataforma de diseño de chips y sistemas, cuando el creciente volumen de datos, en lugar de las limitaciones de hardware y software, se convierte en el factor principal.
"Cuando aparecieron las computadoras en las empresas, a muchos les pareció que el mundo que nos rodea se había acelerado", dijo Aart de Gues, presidente y director ejecutivo de Synopsys. - Hicieron contabilidad en trozos de papel con pilas de libros. El libro mayor se ha convertido en una pila de tarjetas perforadas para impresión y computación. Se ha producido un cambio tremendo y lo vemos de nuevo. Con el advenimiento de las computadoras informáticas simples mentalmente, el algoritmo de acciones no ha cambiado: puede rastrear cada paso. Pero ahora está sucediendo algo más que podría conducir a una nueva aceleración. Es como en un campo agrícola incluir riego y aplicar un cierto tipo de fertilizante solo en un día determinado, cuando la temperatura alcanza el nivel deseado. Este uso del aprendizaje automático es una optimización que no era obvia en el pasado ".
No está solo en esta evaluación. "Se adoptarán las nuevas arquitecturas", dijo Wally Raines, presidente y CEO de Mentor, Siemens Business. - Serán diseñados. El aprendizaje automático se utilizará en muchos o la mayoría de los casos, porque su cerebro aprende de su propia experiencia. Visité 20 o más empresas que desarrollan procesadores de IA especializados de un tipo u otro, y cada una de ellas tiene su propio nicho pequeño. Pero verá cada vez más su aplicación en aplicaciones específicas, y complementarán la arquitectura tradicional de von Neumann. La computación neuromórfica se convertirá en la corriente principal. Este es un gran paso en la eficiencia informática y la reducción de costos. Los dispositivos móviles y los sensores comenzarán a hacer el trabajo que los servidores hacen hoy ".