Hace unos años, los sistemas de recomendación recién comenzaban a ganarse a sus consumidores. Las tiendas en línea están utilizando activamente algoritmos de recomendación, ofreciendo a sus clientes más y más productos nuevos basados en su historial de compras.
En el servicio al cliente, los sistemas de recomendación se han vuelto relevantes no hace mucho tiempo. Debido al aumento en el contenido ofrecido, los clientes comenzaron a perderse en los flujos de información de qué, dónde y cuándo necesitan ver. Los operadores de televisión de pago y las salas de cine en línea asumieron el dolor de cabeza de los amantes del contenido de video.

Como una forma efectiva de resolver el eterno problema de "¿qué ver?" Han aparecido sistemas de recomendación que funcionan sobre la base de un modelo matemático particular.
Hace dos años implementamos un sistema de recomendación, luego lo complementamos con selecciones editoriales y sentimos un efecto notable tanto en las ventas como en la duración del uso de nuestro servicio.
¿Qué son los sistemas de recomendación?
Un sistema de recomendación es cuando desea ver algo, pero no sabe exactamente qué, y el televisor adivina con éxito sus preferencias. Este es un filtro de contenido que selecciona películas y programas de televisión en función de las preferencias y el análisis del comportamiento del usuario. El sistema utilizado por el operador debe predecir la reacción del espectador a un elemento en particular y ofrecer contenido que le pueda gustar.
Al programar sistemas de recomendación, se utilizan tres métodos principales: filtrado colaborativo, filtrado basado en contenido y sistemas expertos (sistemas basados en conocimiento).
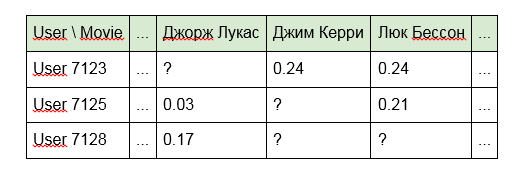
El filtrado colaborativo se basa en tres etapas: recopilar información del usuario, crear una matriz para calcular asociaciones y emitir recomendaciones confiables.
Un buen ejemplo de filtrado colaborativo es Cinematch, que utiliza Netflix. Los usuarios otorgan explícita o implícitamente calificaciones a las películas vistas, y las recomendaciones se forman teniendo en cuenta tanto las calificaciones de los usuarios como las de otros espectadores. Para hacer esto, el sistema selecciona usuarios con preferencias similares, cuyas calificaciones son cercanas a las suyas. Según la opinión de este círculo de personas, el espectador recibe automáticamente la recomendación: ver una película en particular.
Para el funcionamiento correcto máximo del sistema de recomendación, por supuesto, los datos acumulados y recopilados juegan un papel fundamental. Cuantos más datos se acumulen sobre el perfil de consumo de un suscriptor en particular, se le enviarán recomendaciones con mayor precisión.
El sistema de recomendación de contenido se formula en función de los atributos asignados a cada elemento. Si mira películas de un determinado género, el sistema le ofrecerá automáticamente contenido cercano a su género en ciertas posiciones. Es sobre la base de dicho sistema de recomendación que funciona el sitio web de Pandora.
Los sistemas de recomendación de expertos ofrecen recomendaciones no basadas en clasificaciones, sino en base a similitudes entre los requisitos del usuario y las descripciones del producto, o dependiendo de las restricciones establecidas por el usuario al especificar el producto deseado. Por lo tanto, este tipo de sistema es único, ya que permite al cliente indicar explícitamente lo que quiere.
Los sistemas expertos son más efectivos en contextos donde la cantidad de datos disponibles es limitada, y el filtrado colaborativo funciona mejor en entornos donde hay grandes cantidades de datos. Pero cuando los datos se diversifican, es posible resolver el mismo problema con diferentes métodos. Esto significa que combinará de manera óptima las recomendaciones recibidas de varias maneras, mejorando así la calidad del sistema en su conjunto.
Es un sistema híbrido de E-Contenta que funciona en nuestro servicio de
TV WiFire . Se puso en funcionamiento y se depuró en diciembre de 2016 y funciona de acuerdo con el siguiente principio: si el sistema sabe mucho sobre el usuario o sobre el contenido, prevalecen los algoritmos de filtrado colaborativo. Si el contenido es nuevo, o se recopila información insuficiente sobre la interacción de los usuarios con él, entonces los algoritmos de contenido se utilizan para evaluar la similitud del contenido en función de los metadatos existentes.
Cómo se construyeron los algoritmos de recomendaciones
Para crear una selección personalizada en E-Contenta, era necesario clasificar todo el contenido disponible según la probabilidad de que un usuario en particular estuviera interesado en este contenido.
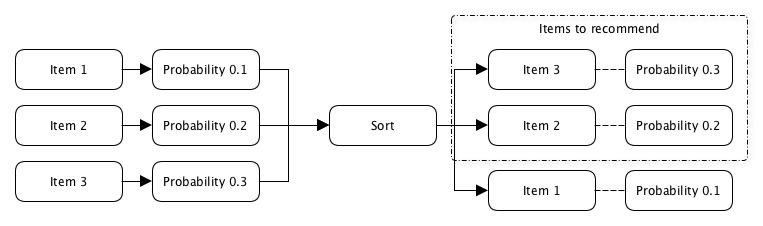
El interés del usuario se determina principalmente en el momento en que hace clic en el contenido que se le recomienda, y la probabilidad se define como la relación entre la cantidad de clics y la cantidad de veces que se recomendó este contenido a este usuario.
p (clic) = N clics / N pantallasLa dificultad radica en el hecho de que necesita recomendar al usuario algo que nunca ha visto, lo que significa que simplemente no hay datos sobre el número de clics o impresiones para calcular esta probabilidad.
Por lo tanto, en lugar de la probabilidad real, se decidió utilizar una estimación de esta probabilidad, en otras palabras, el valor predicho.
La idea de un filtro colaborativo es simple:
- Tome datos históricos sobre los usuarios que ven contenido
- Según estos datos, agrupe a los usuarios por el contenido que vieron
- Para que un usuario determinado prediga la probabilidad de su interés en una unidad particular de contenido, en base a datos históricos de otros usuarios en el mismo grupo.
Por lo tanto, los usuarios participan conjuntamente en el proceso de selección de contenido.
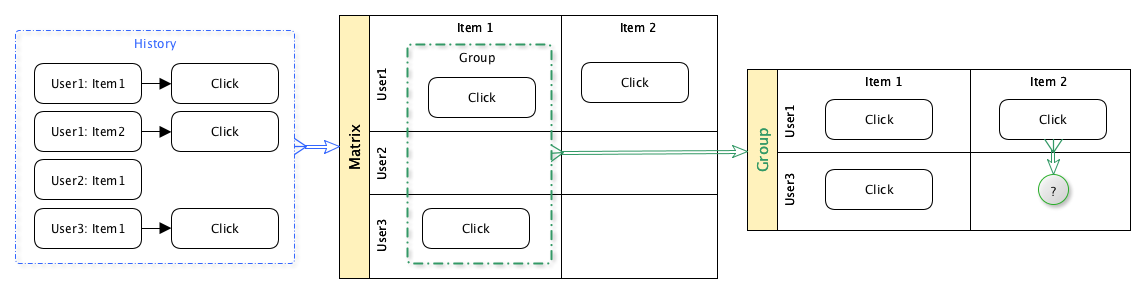
Hay muchas opciones diferentes para implementar este enfoque:
1. Cree un modelo utilizando directamente los identificadores de las unidades de contenido:
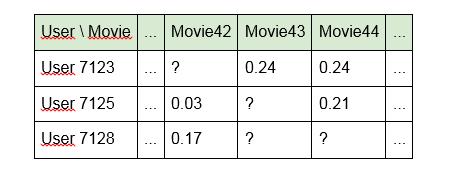
La desventaja de este enfoque es que el modelo "no ve" ningún vínculo entre las unidades de contenido. Por ejemplo, "Terminator" y "Terminator 2" para ella estarán tan lejos el uno del otro como "Alien" y "Good night, Kids!". Además, la matriz en sí misma resulta ser muy escasa (muchas celdas vacías y un poco llenas).
2. En lugar de identificadores, use las palabras incluidas en el título de artículos, programas o películas:
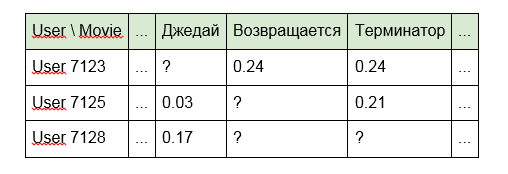
3. Para películas, nombres de actores, directores o datos de IMDb:
Las opciones segunda y tercera eliminan parcialmente las desventajas del primer enfoque, dada la conexión de contenido que tiene características comunes (del mismo director o las mismas palabras en el título). Sin embargo, la escasez de la matriz también se reduce, pero como dicen, no hay límite para la perfección.
Mantener una gama completa de clasificaciones de usuarios en la memoria es bastante costoso. Tomando estimaciones aproximadas del número de usuarios de Runet en 80 millones de personas y el tamaño de la base de datos de IMDb en 370 mil películas, obtenemos el tamaño requerido de 27 Terabytes. La descomposición singular es un método para reducir la dimensión de la matriz.
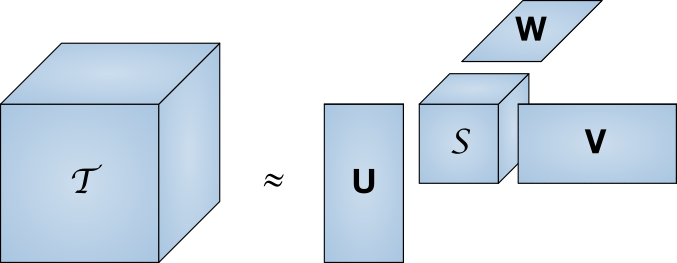 Una matriz T grande se representa como el producto de un conjunto de matrices más pequeñas.
Una matriz T grande se representa como el producto de un conjunto de matrices más pequeñas.En otras palabras, la búsqueda de la matriz "núcleo", que tiene las mismas propiedades que la matriz completa, pero mucho más pequeña. Junto con una disminución en la dimensión, la descarga también disminuye. En este artículo, no profundizaremos en las complejidades de la implementación, especialmente dado que las bibliotecas preparadas ya existen para varios lenguajes de programación.
Dificultades técnicas
Arranque en fríoLa situación en la que la falta de datos para el nuevo contenido o el usuario no permite dar recomendaciones de alta calidad, también conocido como "arranque en frío", es un problema típico para el filtrado colaborativo.
Una solución es mezclar varias unidades de contenido en las recomendaciones que no recopilan suficientes datos. Al mismo tiempo, se recomendará el contenido más popular al nuevo usuario.
Más popularUtilizando el enfoque anterior, es importante no olvidar que su consecuencia será un aumento sistemático en la frecuencia de aparición de los "más populares" en la lista recomendada. Aprendiendo del comportamiento de los usuarios que a menudo se les ofrece el "más popular", el sistema de recomendación corre el riesgo de aprender a recomendar exclusivamente el contenido más popular.
La principal diferencia entre las recomendaciones personales y las recomendaciones banales del contenido más popular es que tienen en cuenta los gustos individuales, que pueden diferir significativamente de los "promedio".
Por lo tanto, la muestra de reacciones del usuario al contenido utilizado para entrenar el modelo de recomendación debería normalizarse.
Disponibilidad, conmutación por error y escalabilidadEl número de usuarios del recurso puede crear una carga de cientos y miles de solicitudes al sistema de recomendación por segundo. Además, la falla de uno o varios servidores no debería conducir a una denegación de servicio.
En este caso, la solución clásica es utilizar un equilibrador de carga que envíe una solicitud a uno de los servidores del clúster. Además, cada uno de los servidores puede procesar una solicitud entrante. En caso de falla de cualquiera de los servidores del clúster, el equilibrador cambia automáticamente la carga a los servidores que permanecen en el sistema. Al elegir HTTP como protocolo de transporte, podemos usar Nginx como equilibrador de carga.
A medida que crece la audiencia del recurso, la cantidad de servidores en el clúster puede crecer. En este caso, es importante minimizar el costo de preparar un nuevo servidor.
El sistema de recomendación requiere la instalación de una serie de componentes en los que se basa funcionalmente. Docker se utiliza para automatizar la implementación de un sistema de recomendación con todas sus dependencias.
Docker le permite recopilar todos los componentes necesarios, "empaquetarlos" en una imagen y colocar dicha imagen en un repositorio (registro), y luego descargarla e implementarla en un nuevo servidor en cuestión de minutos. Una ventaja importante de Docker es que la "sobrecarga" cuando se usa es mínima: el tiempo de llamada de la aplicación en el contenedor de Docker aumenta unos pocos nanosegundos en comparación con la aplicación que se ejecuta en un sistema operativo normal.
Otra ventaja importante es la capacidad de volver rápidamente a la versión estable anterior de la aplicación en caso de una nueva falla (solo tome la versión anterior del registro).
El segundo tipo de solicitudes del sistema que debe atender son las solicitudes que rastrean la actividad del usuario. Para que el usuario no tenga que esperar hasta que el sistema procese completamente la acción que realizó, el proceso de procesamiento se realiza independientemente del proceso de grabación de acciones.
Apache Kafka fue elegido en E-Contenta como una plataforma que proporciona transferencia de datos de acciones de los usuarios a los procesadores. Kafka implementa el patrón arquitectónico Middleware orientado a mensajes), que puede proporcionar la entrega garantizada de decenas y cientos de miles de mensajes por segundo y actúa como un búfer que protege a los procesadores de datos excesivos en las horas pico.
Autoaprendizaje completoEl nuevo contenido y los nuevos usuarios aparecen regularmente; sin capacitación regular, la calidad del modelo se degrada. El entrenamiento debe realizarse en servidores separados para que el proceso de entrenamiento, que requiere importantes recursos informáticos, no afecte el rendimiento de los servidores de combate.
La solución clásica para orquestar tareas distribuidas regulares es Jenkins. El servicio programado comienza a recibir y normalizar nuevas muestras de capacitación, capacitar un modelo de recomendación, entregar nuevos modelos y actualizar todos los servidores del clúster, lo que permite mantener la calidad de las recomendaciones sin esfuerzos adicionales. En el caso de una falla en cualquiera de los pasos, Jenkins regresa independientemente el sistema a su estado estable anterior y notifica al administrador la falla.
Sobre cómo lo implementamos en WifireTV
Además, para que el sistema funcione correctamente, invitamos a un medidor de televisión independiente y lo invitamos a medir la televisión de los suscriptores. Los datos únicos resultantes se animan utilizando algoritmos de ciencia de datos. Los comentarios continuos de los suscriptores que interactúan con las recomendaciones llenan la base de los precedentes para los algoritmos de aprendizaje automático y permiten que las recomendaciones cambien dependiendo de los signos implícitos de las preferencias cambiantes de los suscriptores, como la época del año, acercarse a las vacaciones o cambiar la composición familiar.
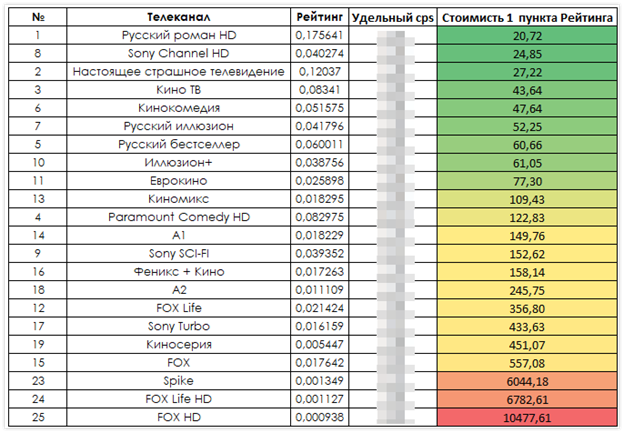
En el proceso de prueba, tuvimos que resolver el problema asociado con la recomendación del contenido de televisión: cómo ayudar a nuestros suscriptores a comprender las transmisiones. La tarea también se complica por los servicios de visualización diferidos. Hemos incorporado un sistema que, en lugar de un cambio de canal cíclico sin fin, ayuda a encontrar un programa interesante con solo presionar 2-3 botones. Para esto, el sistema de recomendaciones monitorea el lanzamiento de nuevas series de programas y predice el interés de los espectadores en programas irregulares y transmisiones de películas. De hecho, los algoritmos de máquina reemplazan el trabajo del editor responsable.
Trabajar con la transmisión de televisión tiene sus propios detalles. Por ejemplo, a menudo los mismos programas de TV populares salen en diferentes canales. En este caso, el sistema de recomendación debe comprender la duplicación de información y elegir una recomendación basada en las preferencias del suscriptor con respecto a los canales, la hora de inicio de la transmisión, etc. Dicha duplicación de información también ocurre cuando un suscriptor tiene una suscripción a las versiones SD y HD de los canales.
Todos estos dos años, experimentamos con diferentes versiones de sistemas de recomendación y encontramos un punto medio, que nos permite mejorar la participación de la audiencia y monetizar de manera más efectiva el contenido existente. Utilizamos la selección automática de recomendaciones descritas anteriormente junto con la sintonización manual - selecciones editoriales.
Este enfoque permitió aumentar significativamente (10 veces) la monetización de los servicios VOD y SVOD.
Las recomendaciones editoriales son colecciones de películas temáticas y series vinculadas a estrenos de alto perfil, días festivos y fechas memorables. Es muy conveniente notificar a los suscriptores y darles la oportunidad de ver películas nuevas, éxitos antiguos o impopulares, pero en nuestra opinión películas muy interesantes en términos de contenido y argumento. Nos comunicamos estrechamente con nuestros proveedores (cines en línea y servicios de video adicionales, como ivi, megogo, amediateka) y seleccionamos personalmente cada película que sea interesante para que la vea nuestro suscriptor.
En vacaciones, hacemos selecciones especiales sobre un tema específico. Por ejemplo, en el Día de la Victoria, estas son películas de temática militar. El 1 de septiembre: una selección de contenido para niños, que consta de programas educativos, dibujos animados y documentales.
La selección manual aumenta perfectamente la lealtad de nuestros suscriptores. Según nuestras estimaciones más conservadoras, aproximadamente el 10% de nuestra base de suscriptores mira películas mensuales que recomendamos y este indicador está en constante crecimiento.
Cual es el resultado?
Wifire TV actualmente ejecuta un sistema de recomendación inteligente de E-Contenta. Se basa en ciencia de datos y metadatos del 90% de los suscriptores del operador. El algoritmo tiene en cuenta cientos de datos: qué está viendo el suscriptor, qué películas y programas son populares, cuándo usa el servicio y quién está ahora frente a la pantalla. Queremos transmitir a nuestros suscriptores el valor de suscribirse a los paquetes de canales premium, mezclándolos en recomendaciones que sean relevantes para el usuario. También queremos mostrar que adquirir y ver contenido de video legal es normal, conveniente y simple.
El sistema de recomendación le contará al suscriptor películas interesantes, incluso si han estado fuera de la categoría de nuevos productos: por lo tanto, el extenso directorio de videos deja de ser una biblioteca polvorienta y se convierte en un escaparate interactivo que se adapta con flexibilidad a los gustos y estados de ánimo de los suscriptores.