En este artículo, me gustaría hablar sobre algunas técnicas para trabajar con datos al entrenar un modelo. En particular, cómo extraer la segmentación de los objetos en las cajas, así como cómo entrenar al modelo y obtener el marcado del conjunto de datos, marcando solo unas pocas muestras.
Desafío
Hay un cierto proceso de hacer pizza y fotos de sus diversas etapas (incluida no solo pizza). Se sabe que si la receta de masa se echa a perder, habrá granos blancos en la corteza. También hay una marca binaria de la calidad de la prueba para cada instancia de pizza, hecha por expertos. Es necesario desarrollar un algoritmo que determine la calidad de la prueba de acuerdo con la fotografía.
El conjunto de datos consta de fotografías tomadas desde diferentes teléfonos, en diferentes condiciones, diferentes ángulos. Instancias de pizza - 17k. Fotos totales - 60k.
En mi opinión, la tarea es bastante típica y adecuada para mostrar diferentes enfoques para el manejo de datos. Para resolverlo, debes:
1. Elija fotos donde haya una masa de pizza;
2. En las fotos seleccionadas, resalte el pastel;
3. Entrene la red neuronal en las áreas seleccionadas.
Filtrando fotos
A primera vista parece que la forma más fácil sería dar esta tarea a los redactores, y luego entrenar el conjunto de datos en datos limpios. Sin embargo, decidí que era más fácil para mí marcar una pequeña parte yo mismo que explicarle a un escriba qué ángulo era el correcto. Además, no tenía un criterio difícil para el ángulo correcto.
Entonces, esto es lo que hice:
1. Marcado 100 fotos de borde;

2. Calculé las características después de la extracción global de la cuadrícula resnet-152 con pesos de imagenet11k_places365;
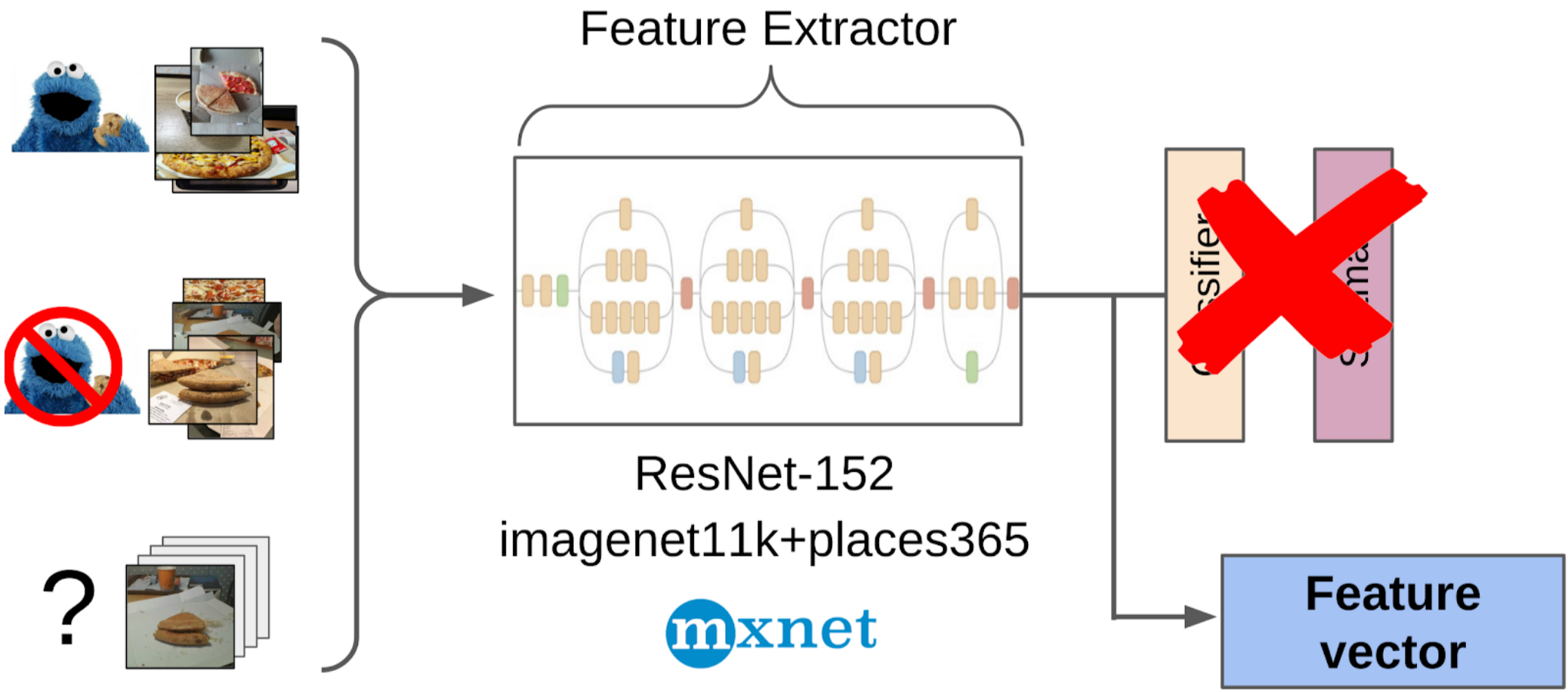
3. Tomó el promedio de características de cada clase, recibiendo dos anclas;
4. Calculé la distancia desde cada ancla a todas las características de las 50k fotos restantes;
5. Los 300 superiores en proximidad a un ancla son relevantes para la clase positiva, los 500 superiores más cercanos al otro ancla son negativos;
6. Entrené a LightGBM en estas muestras con las mismas características (XGboost se indica en la imagen, porque tiene un logotipo y es más reconocible, pero LightGBM no tiene un logotipo);
7. Usando este modelo, obtuve el marcado de todo el conjunto de datos.

Utilicé aproximadamente el mismo enfoque en las competencias de kaggle como
línea de base .
Una explicación en los dedos de por qué este enfoque incluso funcionaUna red neuronal se puede percibir como una transformación fuertemente no lineal de una imagen. En el caso de la clasificación, la imagen se convierte en las probabilidades de las clases que estaban en el conjunto de entrenamiento. Y estas probabilidades se pueden usar esencialmente como características para Light GBM. Sin embargo, esta es una descripción bastante pobre, y en el caso de la pizza, diremos que la clase de pastel es condicionalmente 0.3 gatos y 0.7 perros, y la basura es el resto. En cambio, puede usar características menos dispersas después de la Agrupación promedio global. Tienen una propiedad tal que las características se generan a partir de las muestras del conjunto de entrenamiento, que deben estar separadas por una transformación lineal (una capa completamente conectada con Softmax). Sin embargo, debido al hecho de que no había una pizza explícita en el tren imagenet, es mejor realizar una transformación no lineal en forma de árboles para separar las clases del nuevo conjunto de entrenamiento. En principio, puede ir aún más lejos y tomar características de algunas capas intermedias de la red neuronal. Serán mejores porque todavía no han perdido la localidad de los objetos. Pero son mucho peores debido al tamaño del vector de características. Y además, son menos lineales que frente a una capa totalmente conectada.
Una ligera digresión
ODS recientemente se quejó de que nadie escribe sobre sus fallas. Corrigiendo la situación. Hace aproximadamente un año, participé en la competencia
Kaggle Sea Lions con
Eugene Nizhibitsky . La tarea consistía en contar los lobos marinos en las imágenes del dron. El marcado se dio simplemente en forma de coordenadas de canal, pero en algún momento
Vladimir Iglovikov los marcó con cajas y lo compartió generosamente con la comunidad. En ese momento, me consideraba un padre de segmentación semántica (después de
Kaggle Dstl ) y decidí que Unet facilitaría enormemente la tarea de contar si aprendía a distinguir clásicamente a los gatos.
Explicación de la segmentación semántica.La segmentación semántica es esencialmente una clasificación píxel por píxel de una imagen. Es decir, cada píxel fuente de la imagen debe asociarse con una clase. En el caso de la segmentación binaria (caso del artículo), será una clase positiva o negativa. En el caso de la segmentación multiclase, a cada píxel se le asignará una clase del conjunto de entrenamiento (fondo, hierba, gato, hombre, etc.). En el caso de la segmentación binaria, la arquitectura de red neuronal
U-net funcionaba bien en ese momento. Esta red neuronal es similar en estructura a un codificador-decodificador convencional, pero con reenvío de características desde la parte del codificador al decodificador en las etapas de tamaño apropiado.

Sin embargo, en forma de vainilla, ya nadie lo usa, pero al menos agregan Batch Norm. Bueno, como regla general, toman un
codificador gordo e inflan el decodificador. Las arquitecturas similares a U-net han sido reemplazadas por nuevas cuadrículas de segmentación
FPN , que muestran un buen rendimiento en algunas tareas. Sin embargo, las arquitecturas similares a Unet no han perdido su relevancia hasta el día de hoy. Funcionan bien como línea base, son fáciles de entrenar y es muy simple variar la profundidad / tamaño de la neurociencia cambiando diferentes eccoders.
En consecuencia, comencé a enseñar segmentación, teniendo como objetivo en la primera etapa solo gatos de boxeo. Después de la primera etapa de entrenamiento, predije el tren y miré cómo se ven las predicciones. Con la ayuda de la heurística, se podría seleccionar la confianza abstracta de la máscara y dividir condicionalmente las predicciones en dos grupos: donde todo es bueno y donde todo es malo.

Las predicciones donde todo está bien podrían usarse para entrenar la próxima iteración del modelo. Las predicciones, donde todo es malo, podrían elegirse con grandes áreas sin sellos, manos enmascaradas y también arrojadas al tren. Y de manera iterativa, Eugene y yo entrenamos un modelo que incluso aprendió a segmentar aletas de lobo marino para individuos grandes.
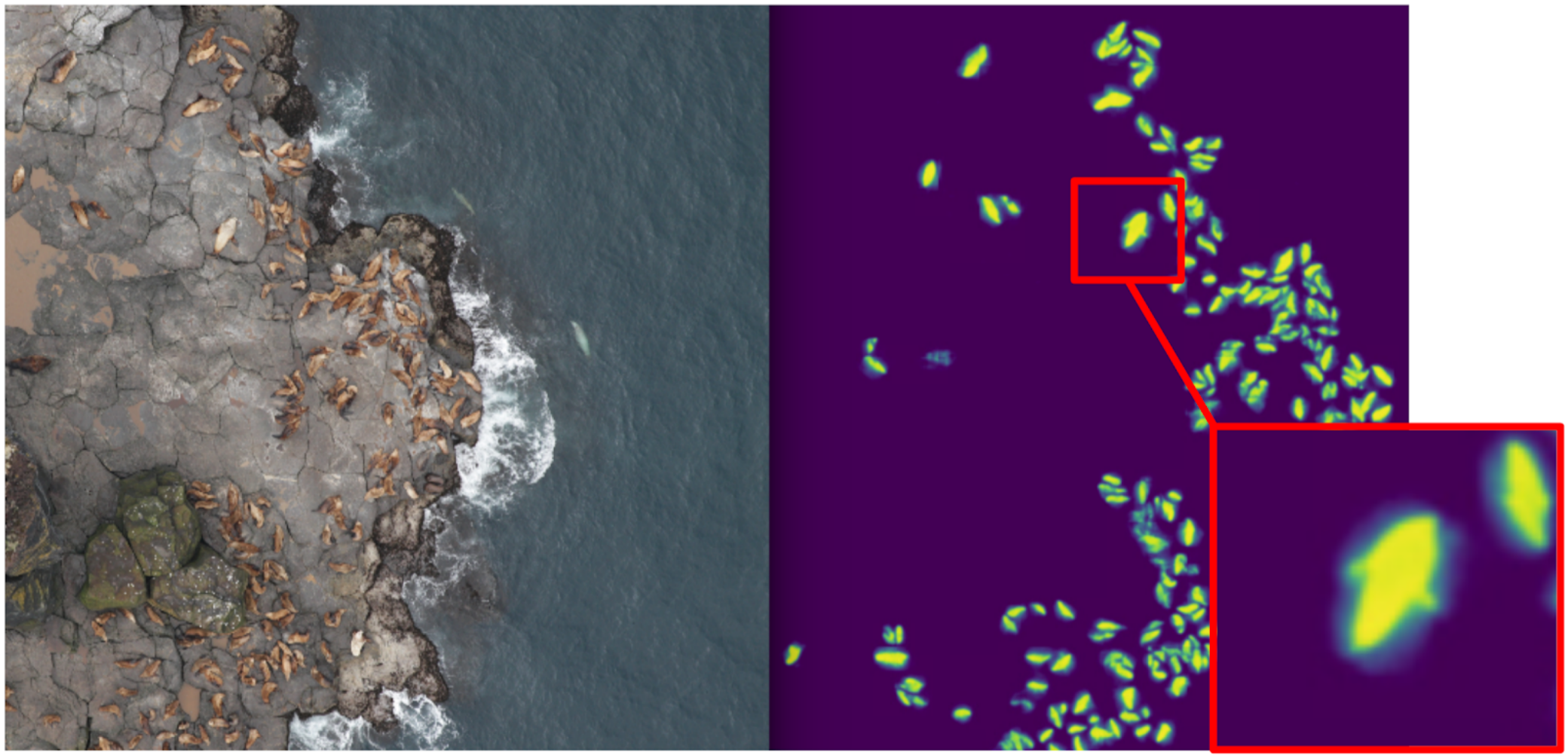
Pero fue un fracaso feroz: pasamos mucho tiempo aprendiendo a segmentar gatos geniales y ... Casi no ayudó en su cálculo. La suposición de que la densidad de los sellos (el número de individuos por unidad de área de la máscara) es constante no funcionó, porque el dron voló a diferentes alturas y las imágenes tenían diferentes escalas. Y al mismo tiempo, la segmentación aún no distinguía a los individuos individuales si se mantenían apretados, lo que sucedía con bastante frecuencia. Y antes del
enfoque innovador para la separación de los objetos del equipo Tocoder en DSB2018, todavía había otro año. Como resultado, nos quedamos sin nada más que terminar en el lugar 40 de 600 equipos.
Sin embargo, saqué dos conclusiones: la segmentación semántica es un enfoque conveniente para visualizar y analizar el funcionamiento del algoritmo, y se pueden soldar máscaras de las cajas con cierto esfuerzo.
Pero volvamos a la pizza. Para resaltar el pastel en las fotos seleccionadas y filtradas, la opción más correcta sería dar la tarea a los redactores. En ese momento, ya habíamos implementado los cuadros y el algoritmo de consenso para ellos. Así que solo lancé un par de ejemplos y se los di al marcado. Como resultado, obtuve 500 muestras con un área de corteza seleccionada con precisión.
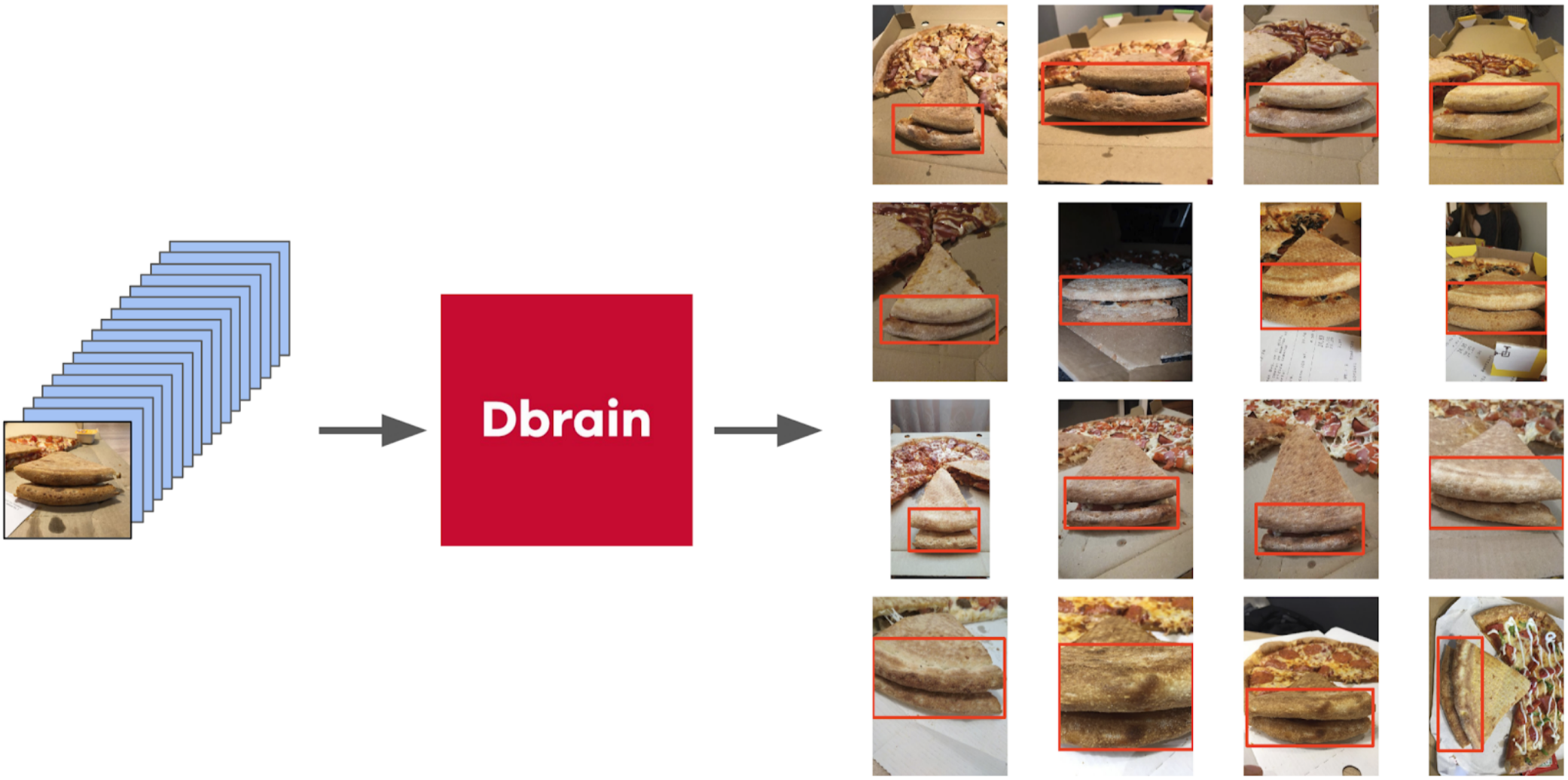
Luego saqué mi código de los sellos y me acerqué más formalmente al procedimiento actual. Después de la primera iteración del entrenamiento, también fue claramente visible dónde se equivocó el modelo. Y la confianza de las predicciones se puede definir de la siguiente manera:
1 - (área gris) / (área de máscara) # habrá una fórmula, lo prometo
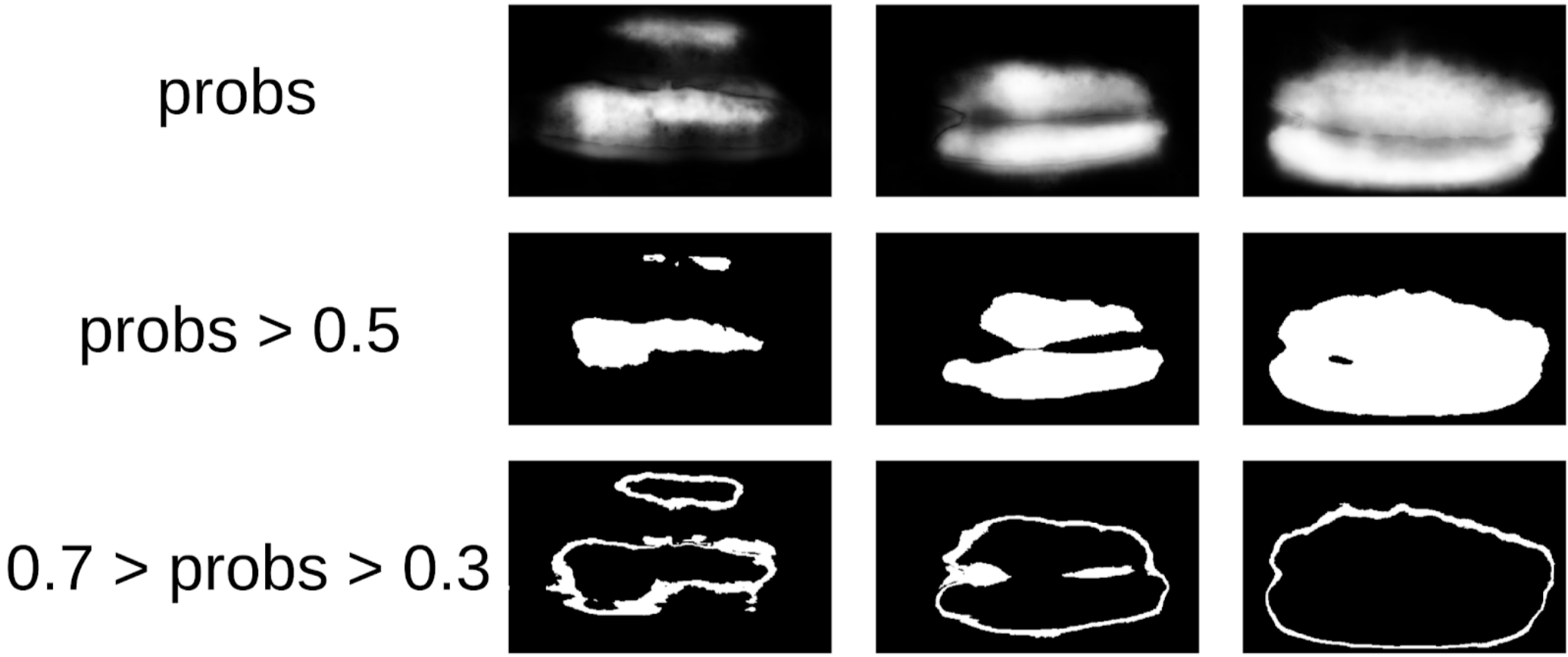
Ahora, para hacer la próxima iteración de tirar de las cajas en las máscaras, un pequeño conjunto predecirá el tren TTA. Esto puede considerarse en cierta medida la destilación del conocimiento WAAAAGH, pero es más correcto llamar a Pseudo Etiquetado.
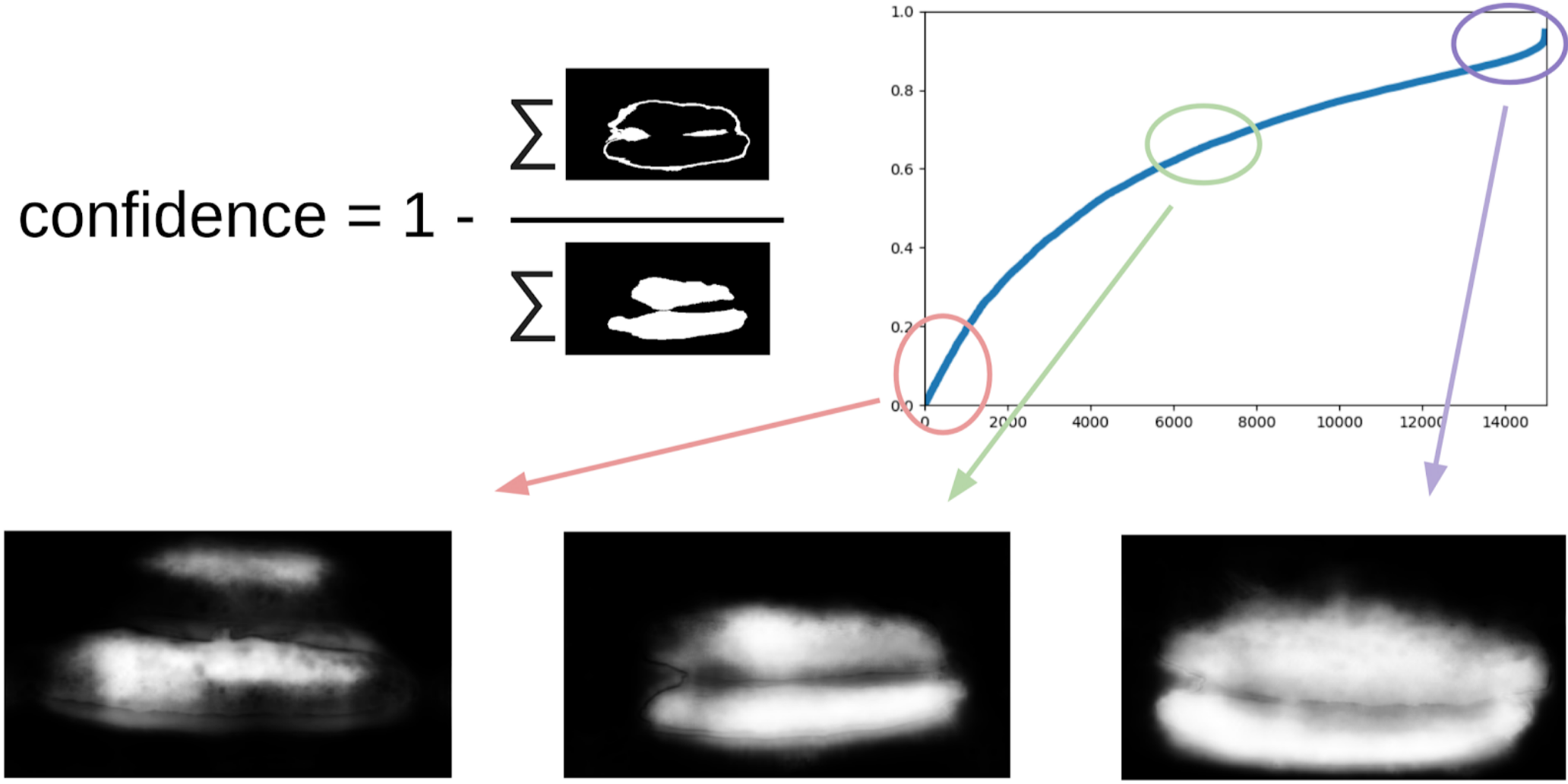
A continuación, debe elegir con sus ojos un cierto umbral de confianza, a partir del cual formamos un nuevo tren. Y, opcionalmente, puede marcar las muestras más complejas que el conjunto no podría manejar. Decidí que sería útil, y pinté unas 20 imágenes en algún lugar mientras digería el almuerzo.
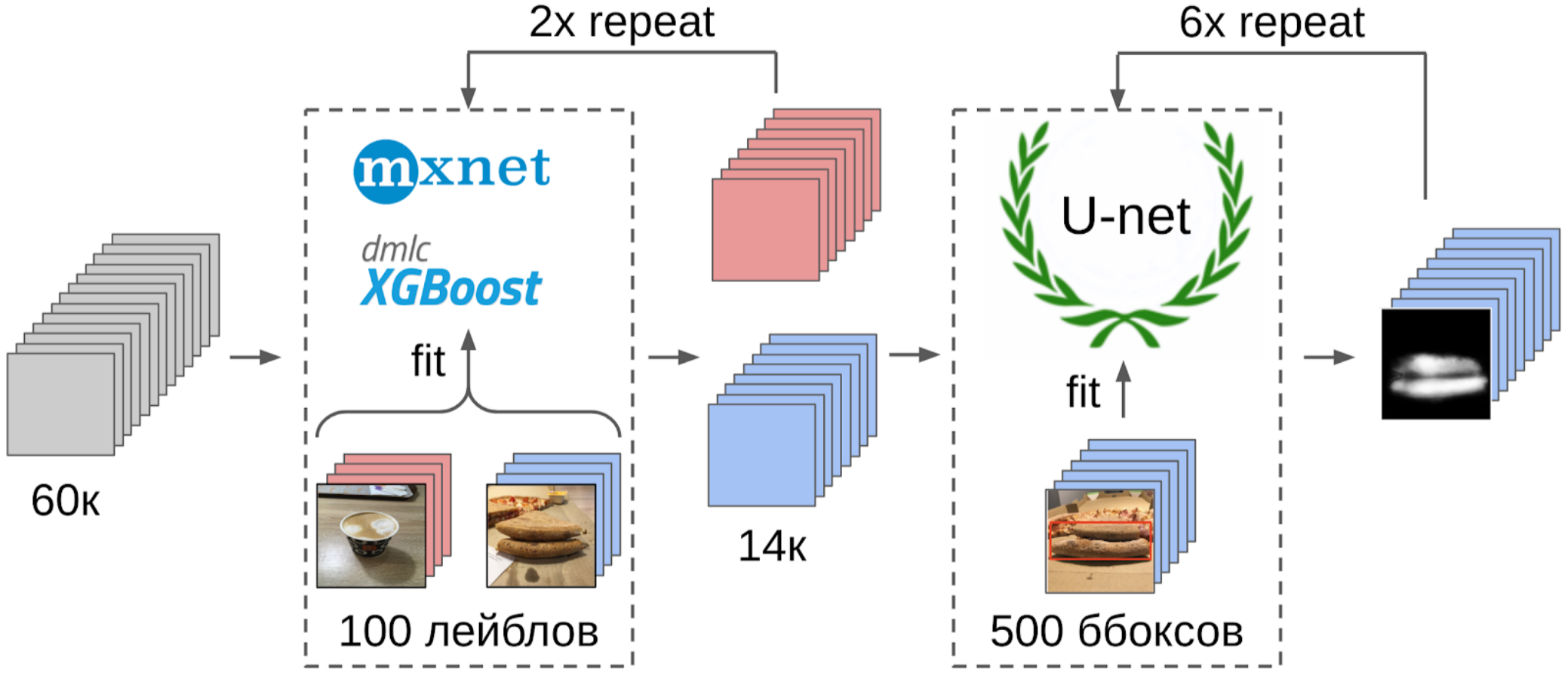
Y ahora la parte final de la tubería: entrenamiento modelo. Para preparar las muestras, extraje el área de la máscara del pastel. También inflé un poco la máscara con dilatación y la apliqué a la imagen para eliminar el fondo, ya que no debería haber información sobre la calidad de la prueba. Y luego acabo de presentar varios modelos del zoológico de Imagenet. En total, pude recolectar alrededor de 12k muestras confiables. Por lo tanto, no enseñé toda la red neuronal, sino solo el último grupo de convoluciones, de modo que el modelo no se volvería a entrenar.
¿Por qué necesitas congelar capas?Hay dos beneficios de esto: 1. La red aprende más rápido, porque no necesita leer gradientes para capas congeladas. 2. La red no está reentrenada, ya que ahora tiene menos parámetros libres. Se argumenta que los primeros pocos grupos de convoluciones durante el entrenamiento en Imagenet generan signos bastante comunes, como transiciones de color nítidas y texturas que son adecuadas para una clase muy amplia de objetos en fotografía. Esto significa que no puede entrenarlos durante Transer Learning.
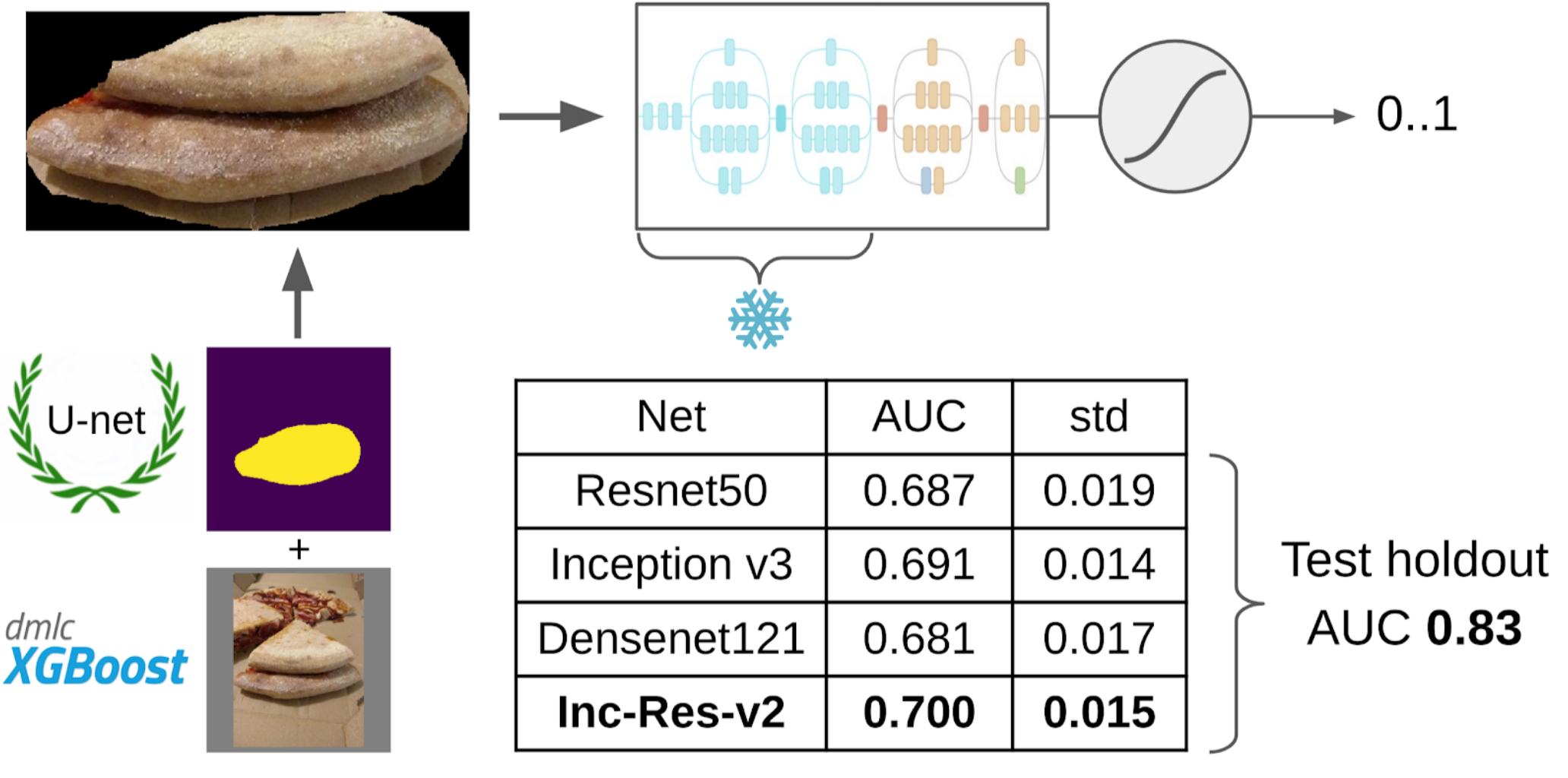
El mejor modelo individual fue Inception-Resnet-v2, y para ella, el ROC-AUC en un pliegue fue de 0.700. Si no selecciona nada y envía imágenes en bruto tal cual, entonces ROC-AUC es 0.58. Mientras estaba desarrollando la solución, el siguiente lote de datos se cocinó en la pizza DODO, y fue posible probar toda la tubería en una reserva honesta. Verificamos toda la tubería y obtuvimos ROC-AUC 0.83.
Veamos los errores ahora:
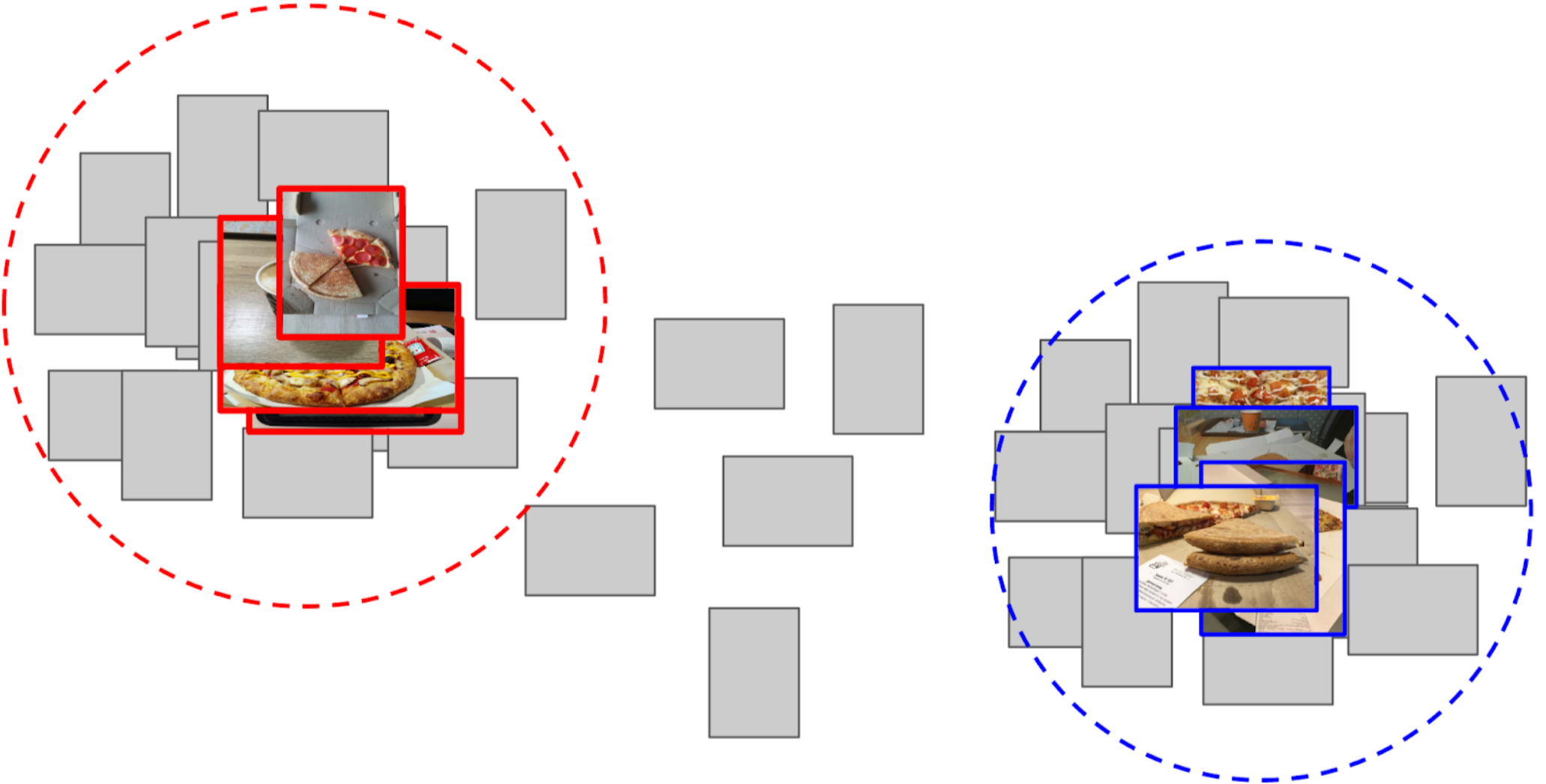
Falso negativo superior

Se puede ver aquí que están asociados con un error al marcar el pastel, ya que claramente hay signos de una prueba estropeada.
Falso positivo superior

Aquí los errores están relacionados con el hecho de que el primer modelo fue elegido con un ángulo no muy bueno, según el cual es difícil encontrar signos clave de la calidad de la prueba.
Conclusión
Los colegas a veces se burlan de mí porque resuelvo muchos problemas segmentando con Unet. Sin embargo, en mi opinión, este es un enfoque bastante poderoso y conveniente. Le permite visualizar errores del modelo y la confianza de sus predicciones. Además, toda la línea de pago parece muy simple y ahora hay un montón de repositorios para cualquier marco.