En este artículo, hablaremos sobre cómo y por qué desarrollamos
el Sistema de interacción , un mecanismo que transfiere información entre las aplicaciones cliente y los servidores 1C: Enterprise, desde la configuración de la tarea hasta la reflexión sobre la arquitectura y los detalles de implementación.
El Sistema de interacción (en lo sucesivo, CB) es un sistema distribuido de mensajería tolerante a fallas con entrega garantizada. CB está diseñado como un servicio altamente cargado con alta escalabilidad, y está disponible como un servicio en línea (proporcionado por 1C) y como un producto de circulación que se puede implementar en las capacidades de su servidor.
CB utiliza el almacenamiento distribuido
Hazelcast y el motor de búsqueda
Elasticsearch . También hablaremos sobre Java y cómo escalamos PostgreSQL horizontalmente.

Declaración del problema.
Para aclarar por qué creamos el Sistema de interacción, le contaré un poco sobre cómo funciona el desarrollo de aplicaciones empresariales en 1C.
Para empezar, un poco sobre nosotros para aquellos que aún no saben lo que estamos haciendo :) Estamos creando la plataforma de tecnología 1C: Enterprise. La plataforma incluye una herramienta para desarrollar aplicaciones comerciales, así como tiempo de ejecución, que permite que las aplicaciones comerciales funcionen en un entorno multiplataforma.
Paradigma de desarrollo cliente-servidor
Las aplicaciones empresariales creadas en "1C: Enterprise" funcionan en la arquitectura
cliente-servidor de tres niveles "DBMS - servidor de aplicaciones - cliente". El código de aplicación escrito en el
lenguaje incrustado 1C se puede ejecutar en el servidor de aplicaciones o en el cliente. Todo el trabajo con objetos de aplicación (directorios, documentos, etc.), así como la lectura y escritura en la base de datos, se realiza solo en el servidor. La funcionalidad de los formularios y la interfaz de comandos también se implementa en el servidor. El cliente recibe, abre y muestra formularios, "se comunica" con el usuario (advertencias, preguntas ...), pequeños cálculos en formularios que requieren una reacción rápida (por ejemplo, multiplicando el precio por la cantidad), trabajando con archivos locales, trabajando con equipos.
En el código de la aplicación, los encabezados de los procedimientos y funciones deben indicar explícitamente dónde se ejecutará el código, utilizando las directivas & En el Cliente / y en el Servidor (& AtClient / & AtServer en la versión en inglés). Los desarrolladores de 1C me corregirán ahora, diciendo que en realidad hay
más directivas, pero para nosotros esto no es esencial ahora.
El código del servidor se puede llamar desde el código del cliente, pero el código del cliente no se puede llamar desde el código del servidor. Esta es una limitación fundamental que hicimos por varias razones. En particular, porque el código del servidor debe escribirse de manera que se ejecute por igual, sin importar dónde se llame, desde el cliente o desde el servidor. Y en caso de llamar al código del servidor desde otro código del servidor, el cliente está ausente como tal. Y porque durante la ejecución del código del servidor, el cliente que lo causó podría cerrarse, salir de la aplicación y el servidor no tendría a quién llamar.
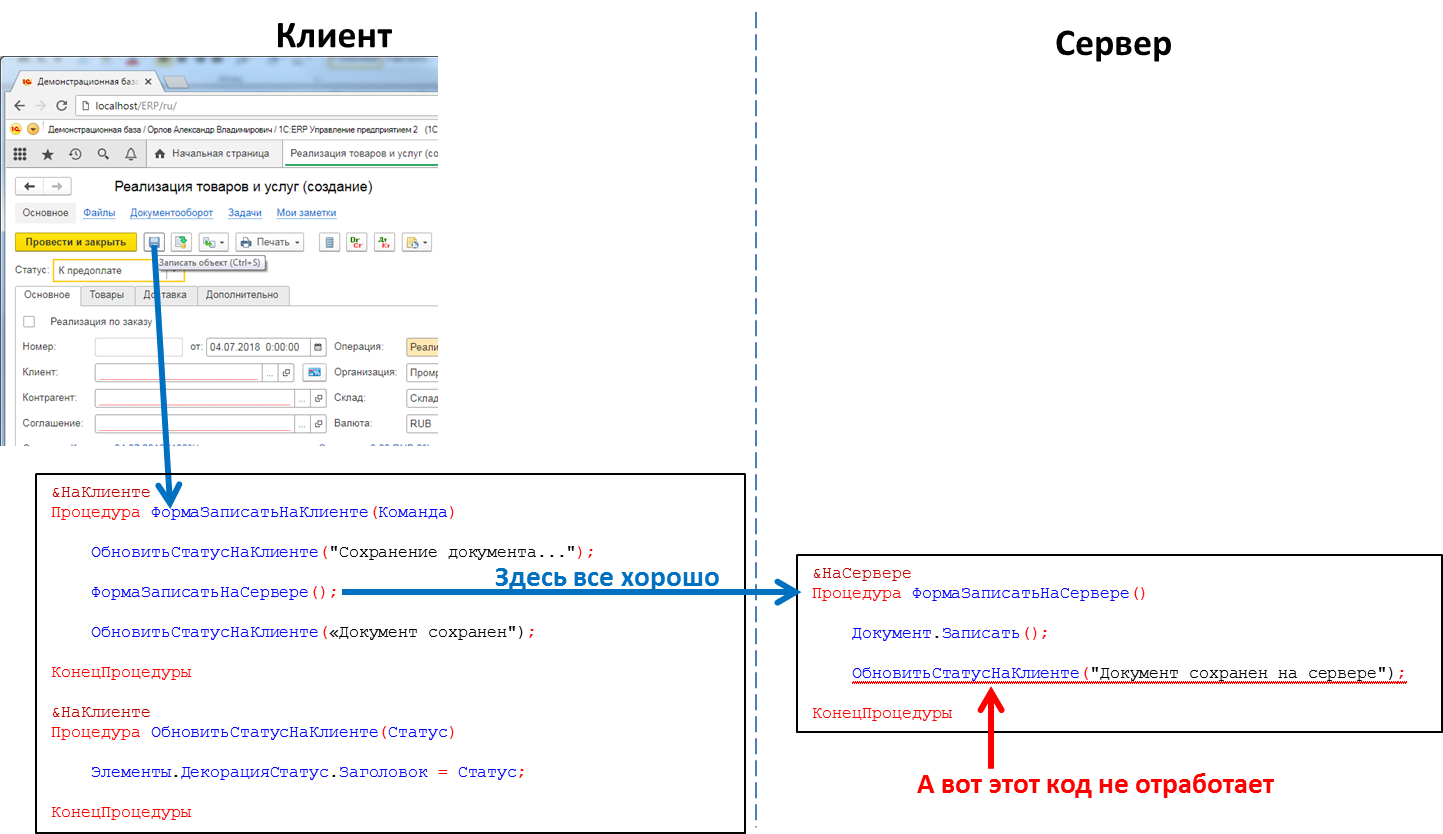 El código que procesa el botón hace clic: la llamada de procedimiento del servidor del cliente funcionará, la llamada de procedimiento del cliente del servidor no funcionará
El código que procesa el botón hace clic: la llamada de procedimiento del servidor del cliente funcionará, la llamada de procedimiento del cliente del servidor no funcionaráEsto significa que si queremos enviar algún mensaje a la aplicación cliente desde el servidor, por ejemplo, que la formación de un informe "de larga duración" ha finalizado y el informe puede verse, no tenemos ese método. Tenemos que ir a trucos, por ejemplo, desde el código del cliente para sondear periódicamente el servidor. Pero este enfoque carga el sistema con llamadas innecesarias y, de hecho, no se ve muy elegante.
Y también es necesario, por ejemplo, cuando llega una llamada telefónica
SIP , notifique a la aplicación del cliente para que, por el número de la persona que llama, la encuentre en la base de datos de la contraparte y muestre la información del usuario sobre la contraparte que llama. O, por ejemplo, al recibir el pedido en el almacén, notifíqueselo a la aplicación del cliente del cliente. En general, hay muchos casos en los que tal mecanismo sería útil.
Realmente puesta en escena
Crea un motor de mensajería. Rápido, confiable, con entrega garantizada, con la capacidad de buscar mensajes de manera flexible. Según el mecanismo, implemente un mensajero (mensajes, videollamadas) que funcione dentro de las aplicaciones 1C.
Diseñar un sistema escalable horizontalmente. El aumento de la carga debe cerrarse aumentando el número de nodos.
Implementación
Decidimos no incrustar la parte del servidor de SV directamente en la plataforma 1C: Enterprise, sino implementarlo como un producto separado, cuya API se puede llamar desde el código de la aplicación 1C. Esto se hizo por varias razones, la principal de las cuales: quería hacer posible el intercambio de mensajes entre diferentes aplicaciones 1C (por ejemplo, entre la Oficina de Comercio y Contabilidad). Se pueden ejecutar diferentes aplicaciones de 1C en diferentes versiones de la plataforma 1C: Enterprise, estar en diferentes servidores, etc. En tales condiciones, la implementación de CB como un producto separado ubicado "al costado" de las instalaciones de 1C es la solución óptima.
Entonces, decidimos hacer CB como un producto separado. Para pequeñas empresas, recomendamos utilizar el servidor CB que instalamos en nuestra nube (wss: //1cdialog.com) para evitar los gastos generales asociados con la instalación y configuración del servidor localmente. Sin embargo, los grandes clientes pueden considerar apropiado instalar su propio servidor CB en sus instalaciones. Utilizamos un enfoque similar en nuestro producto SaaS basado en la nube
1cFresh : se lanza como un producto de circulación para la instalación de los clientes y también se implementa en nuestra nube
https://1cfresh.com/ .
App
Para el equilibrio de carga y la tolerancia a fallas, implementaremos no una aplicación Java, sino varias, colocaremos un equilibrador de carga frente a ellas. Si necesita transferir un mensaje de nodo a nodo, use publicar / suscribirse en Hazelcast.
Comunicación del cliente con el servidor - por websocket. Es muy adecuado para sistemas en tiempo real.
Caché distribuida
Elija entre Redis, Hazelcast y Ehcache. En el patio 2015. Redis acaba de lanzar un nuevo clúster (demasiado nuevo, aterrador), hay un Sentinel con muchas restricciones. Ehcache no sabe cómo ensamblar en un clúster (esta funcionalidad apareció más adelante). Decidimos probar con Hazelcast 3.4.
Hazelcast va al grupo fuera de la caja. En el modo de nodo único, no es muy útil y solo puede caber como caché: no sabe cómo volcar datos en el disco, perdió un solo nodo, perdió datos. Implementamos varios Hazelcasts entre los cuales respaldamos datos críticos. El caché no es una copia de seguridad, no es una pena.
Para nosotros, Hazelcast es:
- Repositorio de sesiones de usuario. Cada vez, ir a la base de datos para una sesión es mucho tiempo, por lo que colocamos todas las sesiones en Hazelcast.
- Caché Buscando un perfil de usuario: verifique en el caché. Escribió un nuevo mensaje, póngalo en la caché.
- Temas para comunicar instancias de aplicaciones. Noda genera un evento y lo coloca en el tema Hazelcast. Otros nodos de aplicación suscritos a este tema reciben y procesan el evento.
- Grupo de cerraduras. Por ejemplo, creamos una discusión sobre una clave única (discusión-singleton dentro del marco de la base de datos 1C):
conversationKeyChecker.check(""); doInClusterLock("", () -> { conversationKeyChecker.check(""); createChannel(""); });
Comprobado que no hay canal. Tomaron la cerradura, revisaron nuevamente, crearon. Si no verifica el bloqueo después de tomarlo, existe la posibilidad de que otro hilo en ese momento también lo verifique y ahora intente crear la misma discusión, pero ya existe. Es imposible hacer el bloqueo a través del bloqueo Java sincronizado o habitual. A través de la base, lentamente, y la base es una pena, a través de Hazelcast, lo que necesita.
Elegir un DBMS
Tenemos una amplia y exitosa experiencia trabajando con PostgreSQL y colaborando con los desarrolladores de este DBMS.
PostgreSQL no es fácil con un clúster: tiene
XL ,
XC ,
Citus , pero, en general, estos no son noSQL, que se escalan de
fábrica . NoSQL no fue considerado como el repositorio principal, fue suficiente que tomamos Hazelcast, con el que no habíamos trabajado antes.
Como necesita escalar una base de datos relacional, significa
fragmentación . Como sabe, al fragmentar, dividimos la base de datos en partes separadas para que cada una de ellas se pueda mover a un servidor separado.
La primera versión de nuestro sharding implicaba la capacidad de distribuir cada una de las tablas de nuestra aplicación a diferentes servidores en diferentes proporciones. Hay muchos mensajes en el servidor A, por favor, transfiramos parte de esta tabla al servidor B. Tal solución simplemente gritó acerca de la optimización prematura, por lo que decidimos limitarnos a un enfoque multiinquilino.
Puede
leer sobre inquilinos múltiples, por ejemplo, en el
sitio web de
Citus Data .
En SV hay conceptos de aplicación y suscriptor. Una aplicación es una instalación específica de una aplicación comercial, como ERP o Contabilidad, con sus usuarios y datos comerciales. Un suscriptor es una organización o un individuo en cuyo nombre la aplicación está registrada en el servidor CB. Un suscriptor puede registrar varias aplicaciones, y estas aplicaciones pueden intercambiar mensajes entre sí. El suscriptor también se convirtió en el inquilino de nuestro sistema. Los mensajes de varios suscriptores pueden estar en una base física; Si vemos que algún suscriptor comenzó a generar mucho tráfico, lo llevamos a una base física separada (o incluso a un servidor de base de datos separado).
Tenemos una base de datos principal donde se almacena una tabla de enrutamiento con información sobre la ubicación de todas las bases de datos de suscriptores.
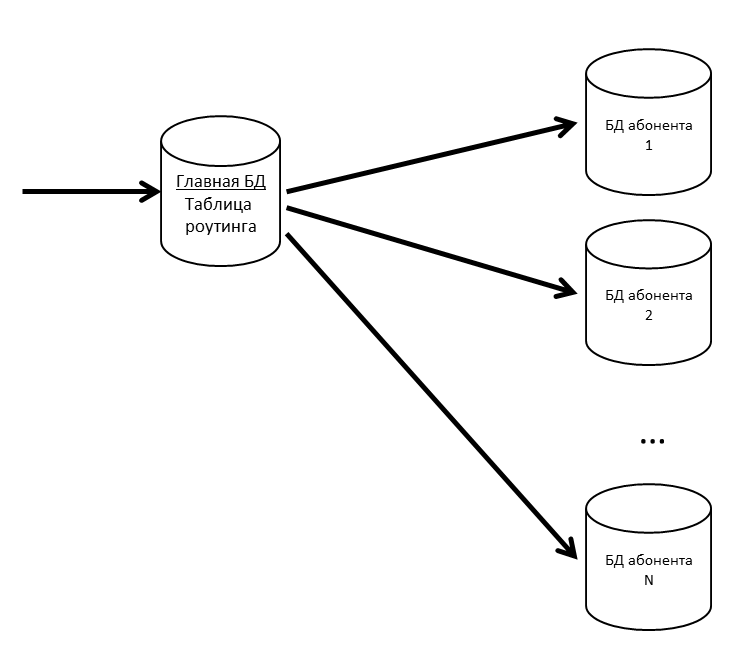
Para que la base de datos principal no sea un cuello de botella, mantenemos la tabla de enrutamiento (y otros datos solicitados con frecuencia) en la memoria caché.
Si la base de datos de suscriptores comienza a ralentizarse, la dividiremos en particiones. En otros proyectos, usamos pg_pathman para particionar tablas grandes.
Como perder mensajes de usuario es malo, admitimos nuestras bases de datos con réplicas. La combinación de réplicas síncronas y asíncronas le permite estar seguro en caso de pérdida de la base de datos principal. La pérdida de mensajes ocurrirá solo en caso de falla simultánea de la base de datos principal y su réplica síncrona.
Si se pierde la réplica síncrona, la réplica asíncrona se vuelve síncrona.
Si se pierde la base de datos principal, la réplica síncrona se convierte en la base de datos principal, la réplica asíncrona se convierte en la réplica síncrona.
Elasticsearch para búsqueda
Dado que, entre otras cosas, CB también es un mensajero, aquí necesita una búsqueda rápida, conveniente y flexible, teniendo en cuenta la morfología, por coincidencias inexactas. Decidimos no reinventar la rueda y usar el motor de búsqueda gratuito Elasticsearch, basado en la biblioteca
Lucene . También implementamos Elasticsearch en un clúster (maestro - datos - datos) para eliminar problemas en caso de falla de los nodos de la aplicación.
En github, encontramos un
complemento de morfología rusa para Elasticsearch y lo usamos. En el índice Elasticsearch, almacenamos las raíces de las palabras (que define el complemento) y N-gramos. A medida que el usuario ingresa el texto para buscar, buscamos el texto escrito entre los N-gramos. Cuando se almacena en el índice, la palabra "textos" se dividirá en los siguientes N-gramos:
[esos, tecnología, tex, texto, textos, ek, eks, ekst, eksts, ks, kst, kst, kst, st, st, usted],
Y también se guardará la raíz de la palabra "texto". Este enfoque le permite buscar al principio, en el medio y al final de la palabra.
Cuadro general
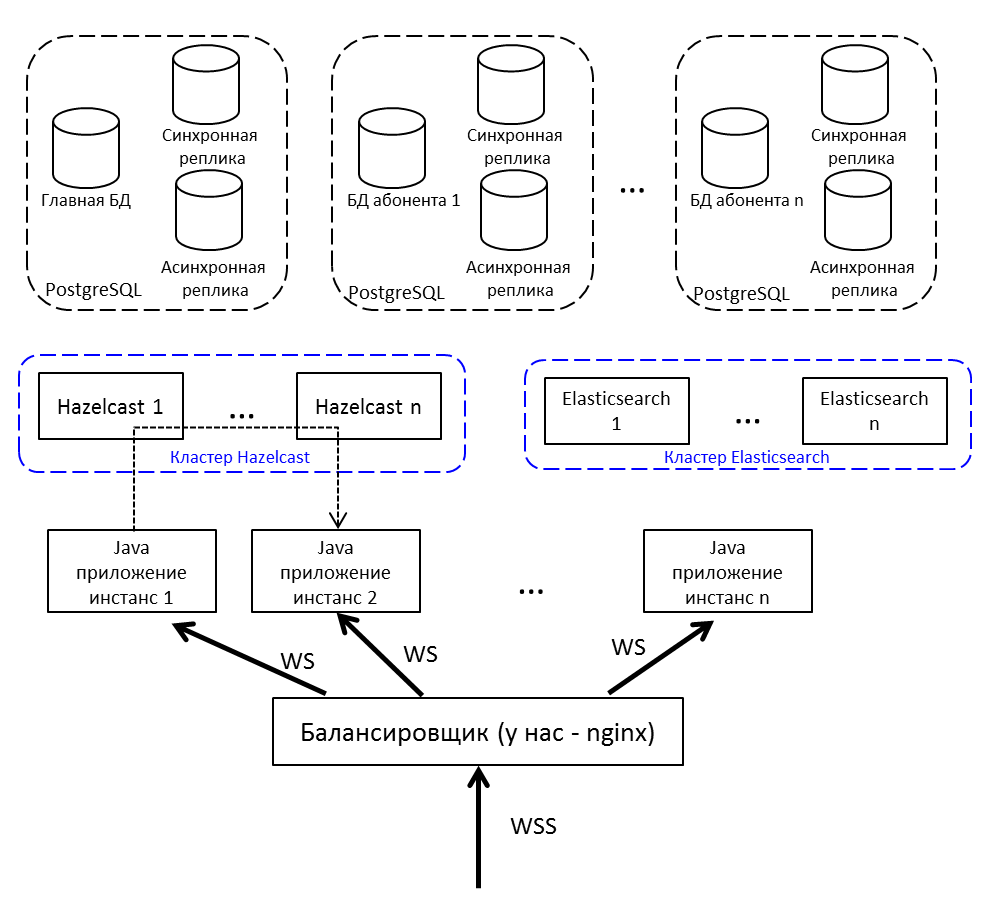
Repitiendo la imagen desde el comienzo del artículo, pero con explicaciones:
- Balanceador de internet; tenemos nginx, puede ser cualquiera.
- Las instancias de aplicaciones Java se comunican entre sí a través de Hazelcast.
- Para trabajar con un socket web utilizamos Netty .
- La aplicación Java escrita en Java 8 consta de paquetes OSGi . Los planes: migración a Java 10 y transición a módulos.
Desarrollo y pruebas
En el proceso de desarrollo y prueba de CB, encontramos una serie de características interesantes de los productos que utilizamos.
Pruebas de carga y pérdidas de memoria
El lanzamiento de cada lanzamiento CB es una prueba de esfuerzo. Tuvo éxito cuando:
- La prueba funcionó durante varios días y no hubo denegación de servicio.
- El tiempo de respuesta para las operaciones clave no excedió un umbral cómodo
- La degradación del rendimiento en comparación con la versión anterior no es más del 10%
Llenamos la base de prueba con datos: para esto obtenemos información sobre el suscriptor más activo del servidor de producción, multiplicamos sus números por 5 (el número de mensajes, discusiones, usuarios) y así lo probamos.
Realizamos pruebas de carga del sistema de interacción en tres configuraciones:
- Prueba de esfuerzo
- Solo conexiones
- Registro de suscriptor
Durante la prueba de esfuerzo, comenzamos varios cientos de hilos, y ellos cargan el sistema sin parar: escriben mensajes, crean discusiones, obtienen una lista de mensajes. Simulamos las acciones de los usuarios comunes (obtener una lista de mis mensajes no leídos, escribir a alguien) y soluciones de software (transferir un paquete de una configuración diferente, procesar la notificación).
Por ejemplo, esto es parte de la prueba de esfuerzo:
- El usuario inicia sesión.
- Solicita debates no leídos
- 50% de posibilidades de leer mensajes
- Con 50% de probabilidad escribe mensajes
- Próximo usuario:
- Con 20% de probabilidad crea una nueva discusión.
- Selecciona aleatoriamente cualquiera de sus discusiones
- Va adentro
- Solicita mensajes, perfiles de usuario
- Crea cinco mensajes dirigidos a usuarios aleatorios de esta discusión.
- Fuera de discusión
- Se repite 20 veces
- Cierra la sesión, vuelve al comienzo del guión
- El chat bot ingresa al sistema (emula el intercambio de mensajes del código de soluciones aplicadas)
- Con un 50% de probabilidad crea un nuevo canal para el intercambio de datos (discusión especial)
- Con una probabilidad del 50% escribe un mensaje en cualquiera de los canales existentes
El escenario "Solo conexiones" apareció por una razón. Existe una situación: los usuarios conectaron el sistema, pero aún no se han involucrado. Cada usuario de la mañana a las 09:00 enciende la computadora, establece una conexión con el servidor y permanece en silencio. Estos tipos son peligrosos, hay muchos de ellos: de los paquetes solo tienen PING / PONG, pero mantienen la conexión con el servidor (no pueden mantenerlo, pero de repente un nuevo mensaje). La prueba reproduce la situación cuando en media hora un gran número de dichos usuarios intenta iniciar sesión en el sistema. Parece una prueba de esfuerzo, pero se enfoca precisamente en esta primera entrada, para que no haya fallas (una persona no usa el sistema, pero ya se está cayendo, es difícil encontrar algo peor).
El escenario de registro de suscriptores se origina desde el primer lanzamiento. Realizamos una prueba de esfuerzo y estábamos seguros de que el sistema no se ralentiza en la correspondencia. Pero los usuarios se fueron y el registro comenzó a caerse en un tiempo de espera. Al registrarnos, usamos
/ dev / random , que está vinculado a la entropía del sistema. El servidor no logró acumular suficiente entropía y se congeló durante decenas de segundos al solicitar un nuevo SecureRandom. Hay muchas maneras de salir de esta situación, por ejemplo: cambiar a menos seguro / dev / urandom, colocar un tablero especial que genere entropía, generar números aleatorios por adelantado y almacenarlos en el grupo. Cerramos temporalmente el problema con un grupo, pero desde entonces hemos estado ejecutando una prueba separada para registrar nuevos suscriptores.
Como generador de carga usamos
JMeter . No sabe cómo trabajar con un socket web; se necesita un complemento. Los primeros resultados de búsqueda para "jmeter websocket" son
artículos con BlazeMeter , que recomiendan un
complemento de Maciej Zaleski .
Con él decidimos comenzar.
Casi inmediatamente después del inicio de las pruebas serias, encontramos que las pérdidas de memoria comenzaron en JMeter.
El complemento es una gran historia separada, con 176 estrellas, tiene 132 tenedores en github. El propio autor no se ha comprometido con él desde 2015 (lo tomamos en 2015, luego esto no levantó sospechas), varios problemas de github sobre pérdidas de memoria, 7 solicitudes de extracción no cerradas.
Si decide realizar pruebas de carga con este complemento, preste atención a las siguientes discusiones:
- En un entorno multiproceso, se usó la LinkedList habitual, como resultado, recibieron NPE en tiempo de ejecución. Se resuelve cambiando a ConcurrentLinkedDeque o mediante bloques sincronizados. Eligieron la primera opción para ellos ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/43 ).
- Pérdida de memoria, la desconexión no elimina la información de conexión ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/44 ).
- En el modo de transmisión (cuando el socket web no se cierra al final de la muestra, pero se usa más en el plan), los patrones de respuesta ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/19 ) no funcionan.
Este es uno de esos en github. Que hemos hecho:
- Tomaron el tenedor Elyran Kogan (@elyrank): los problemas 1 y 3 se solucionaron
- Problema resuelto 2
- Embarcadero actualizado del 9.2.14 al 9.3.12
- SimpleDateFormat envuelto en ThreadLocal; SimpleDateFormat no es seguro para subprocesos, lo que condujo al tiempo de ejecución NPE
- Se eliminó una pérdida de memoria más (la conexión se cerró incorrectamente cuando se desconectó)
¡Y sin embargo fluye!
El recuerdo comenzó a terminar no en un día, sino en dos. No quedaba absolutamente ningún tiempo, decidieron ejecutar menos hilos, pero en cuatro agentes. Eso debería haber sido suficiente durante al menos una semana.
Han pasado dos días ...
Ahora el recuerdo comenzó a agotarse en Hazelcast. Fue evidente en los registros que después de un par de días de pruebas, Hazelcast comienza a quejarse de la falta de memoria, y después de un tiempo, el grupo se desmorona y los nodos continúan muriendo individualmente. Conectamos JVisualVM a hazelcast y vimos una "sierra ascendente", que regularmente llamaba GC, pero no podía borrar su memoria.
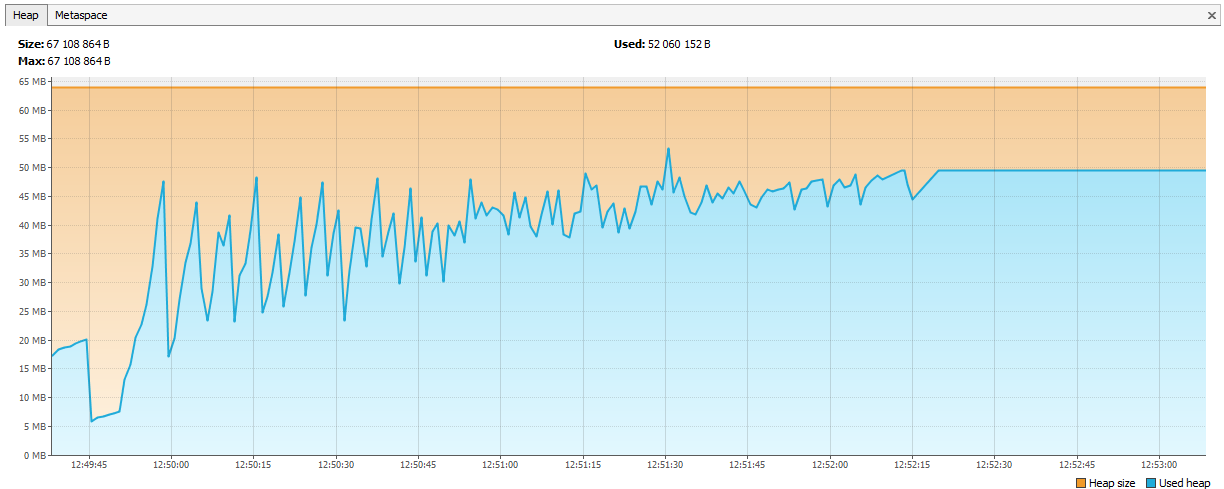
Resultó que en Hazelcast 3.4, al eliminar map / multiMap (map.destroy ()), la memoria no se libera por completo:
github.com/hazelcast/hazelcast/issues/6317github.com/hazelcast/hazelcast/issues/4888Ahora el error se corrigió en 3.5, pero luego fue un problema. Creamos nuevos mapas múltiples con nombres dinámicos y los eliminamos de acuerdo con nuestra lógica. El código se parecía a esto:
public void join(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.put(auth.getUserId(), auth); } public void leave(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.remove(auth.getUserId(), auth); if (sessions.size() == 0) { sessions.destroy(); } }
Llamada:
service.join(auth1, "____UUID1"); service.join(auth2, "____UUID1");
multiMap se creó para cada suscripción y se eliminó cuando no era necesario. Decidimos que comenzaremos Map <String, Set>, la clave será el nombre de la suscripción y los valores serán los identificadores de sesión (desde los cuales puede obtener las ID de usuario, si es necesario).
public void join(Authentication auth, String sub) { addValueToMap(sub, auth.getSessionId()); } public void leave(Authentication auth, String sub) { removeValueFromMap(sub, auth.getSessionId()); }
Los cuadros se enderezaron.
¿Qué más aprendimos sobre las pruebas de estrés?
- JSR223 debe escribirse en caché de compilación habilitado y maravilloso, esto es mucho más rápido. Enlace
- Los gráficos Jmeter-Plugins son más fáciles de entender que el estándar. Enlace
Sobre nuestra experiencia con Hazelcast
Hazelcast era un producto nuevo para nosotros, comenzamos a trabajar con él desde la versión 3.4.1, ahora nuestro servidor de producción tiene la versión 3.9.2 (en el momento de la redacción, la última versión de Hazelcast es la 3.10).
Generación de ID
Comenzamos con identificadores enteros. Imaginemos que necesitamos otro Long para una nueva entidad. La secuencia no cabe en la base de datos, las tablas participan en el particionamiento: resulta que hay un ID de mensaje = 1 en DB1 y un ID de mensaje = 1 en DB2, no puede poner dicha ID en Elasticsearch, ya sea en Hazelcast, pero lo peor es si desea reducir los datos de dos bases de datos en una (por ejemplo, decidir que una base de datos es suficiente para estos suscriptores). Puede crear varios AtomicLongs en Hazelcast y mantener el contador allí, luego el rendimiento de obtener una nueva ID aumentará y Obtenga más el tiempo para una solicitud en Hazelcast. Pero hay algo más óptimo sobre Hazelcast: FlakeIdGenerator. A cada cliente se le asigna un rango de identificación al contactar, por ejemplo, el primero de 1 a 10,000, el segundo de 10,001 a 20,000, y así sucesivamente. Ahora el cliente puede emitir nuevos identificadores de forma independiente hasta que finalice el rango emitido. Funciona rápidamente, pero cuando reinicia la aplicación (y el cliente Hazelcast), comienza una nueva secuencia, de ahí las brechas, etc. Además, los desarrolladores no tienen muy claro por qué los ID son enteros, pero son tan diferentes. Todos pesamos y cambiamos a UUID.
Por cierto, para aquellos que quieren ser como Twitter, existe una biblioteca de Snowcast: esta es una implementación de Snowflake además de Hazelcast. Puedes verlo aquí:
github.com/noctarius/snowcastgithub.com/twitter/snowflakePero no hemos llegado a sus manos.
TransactionalMap.replace
Otra sorpresa: TransactionalMap.replace no funciona. Aquí hay una prueba:
@Test public void replaceInMap_putsAndGetsInsideTransaction() { hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { context.getMap("map").put("key", "oldValue"); context.getMap("map").replace("key", "oldValue", "newValue"); String value = (String) context.getMap("map").get("key"); assertEquals("newValue", value); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); } Expected : newValue Actual : oldValue
Tuve que escribir mi reemplazo usando getForUpdate:
protected <K,V> boolean replaceInMap(String mapName, K key, V oldValue, V newValue) { TransactionalTaskContext context = HazelcastTransactionContextHolder.getContext(); if (context != null) { log.trace("[CACHE] Replacing value in a transactional map"); TransactionalMap<K, V> map = context.getMap(mapName); V value = map.getForUpdate(key); if (oldValue.equals(value)) { map.put(key, newValue); return true; } return false; } log.trace("[CACHE] Replacing value in a not transactional map"); IMap<K, V> map = hazelcastInstance.getMap(mapName); return map.replace(key, oldValue, newValue); }
Pruebe no solo las estructuras de datos regulares, sino también sus versiones transaccionales. Sucede que IMap funciona, pero TransactionalMap se ha ido.
Adjunte un nuevo JAR sin tiempo de inactividad
Primero, decidimos grabar objetos de nuestras clases en Hazelcast. Por ejemplo, tenemos una aplicación de clase, queremos guardarla y leerla. Guardar:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); map.set(id, application);
Leemos:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); return map.get(id);
Todo funciona Luego decidimos crear un índice en Hazelcast para buscarlo:
map.addIndex("subscriberId", false);
Y al escribir una nueva entidad, comenzaron a recibir una ClassNotFoundException. Hazelcast intentó complementar el índice, pero no sabía nada sobre nuestra clase y quería que tuviera un JAR con esta clase. Lo hicimos, todo funcionó, pero apareció un nuevo problema: ¿cómo actualizar el JAR sin detener el clúster por completo? Hazelcast no recoge el nuevo JAR durante una actualización inteligente. En este momento, decidimos que podríamos vivir muy bien sin buscar por índice. Después de todo, si usa Hazelcast como almacenamiento de valor clave, ¿funcionará todo? En realidad no Aquí nuevamente, el comportamiento diferente de IMap y TransactionalMap. Donde IMap no importa, TransactionalMap arroja un error.
IMap Escribimos 5000 objetos, lo leímos. Todo se espera.
@Test void get5000() { IMap<UUID, Application> map = hazelcastInstance.getMap("application"); UUID subscriberId = UUID.randomUUID(); for (int i = 0; i < 5000; i++) { UUID id = UUID.randomUUID(); String title = RandomStringUtils.random(5); Application application = new Application(id, title, subscriberId); map.set(id, application); Application retrieved = map.get(id); assertEquals(id, retrieved.getId()); } }
Y no funciona en la transacción, obtenemos una ClassNotFoundException:
@Test void get_transaction() { IMap<UUID, Application> map = hazelcastInstance.getMap("application_t"); UUID subscriberId = UUID.randomUUID(); UUID id = UUID.randomUUID(); Application application = new Application(id, "qwer", subscriberId); map.set(id, application); Application retrievedOutside = map.get(id); assertEquals(id, retrievedOutside.getId()); hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { TransactionalMap<UUID, Application> transactionalMap = context.getMap("application_t"); Application retrievedInside = transactionalMap.get(id); assertEquals(id, retrievedInside.getId()); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); }
En 3.8, apareció el mecanismo de implementación de clase de usuario. Puede asignar un nodo principal y actualizar el archivo JAR en él.
Ahora hemos cambiado completamente el enfoque: lo serializamos en JSON y lo guardamos en Hazelcast. Hazelcast no necesita conocer la estructura de nuestras clases, pero podemos actualizar sin tiempo de inactividad. El control de versiones de los objetos de dominio está controlado por la aplicación. Se pueden iniciar diferentes versiones de la aplicación al mismo tiempo, y es posible que una nueva aplicación escriba objetos con nuevos campos, pero la anterior no conoce estos campos. Y al mismo tiempo, la nueva aplicación lee los objetos grabados por la aplicación anterior, en la que no hay nuevos campos. Manejamos tales situaciones dentro de la aplicación, pero por simplicidad no cambiamos ni eliminamos campos, solo ampliamos las clases agregando nuevos campos.
Cómo brindamos un alto rendimiento
Cuatro viajes a Hazelcast - bueno, dos a la base de datos - malo
Ir al caché para obtener datos siempre es mejor que en la base de datos, pero no desea almacenar registros no reclamados. La decisión sobre qué almacenar en caché la posponemos a la última etapa de desarrollo. Cuando se codifica la nueva funcionalidad, activamos PostgreSQL para registrar todas las consultas (log_min_duration_statement a 0) y ejecutar pruebas de carga durante 20 minutos. Al usar registros recopilados, utilidades como pgFouine y pgBadger pueden generar informes analíticos. En los informes, buscamos principalmente consultas lentas y frecuentes. Para consultas lentas, creamos un plan de ejecución (EXPLICAR) y evaluamos si dicha consulta puede acelerarse. Las solicitudes frecuentes de los mismos datos de entrada están bien almacenadas en caché. Intentamos mantener las solicitudes "planas", una tabla por solicitud.
Operación
SV como servicio en línea se lanzó en la primavera de 2017, ya que se lanzó un producto SV por separado en noviembre de 2017 (en ese momento en estado beta).
Durante más de un año de operación, no ocurrieron problemas serios en la operación del servicio en línea de CB. Monitoreamos el servicio en línea a través de
Zabbix , recopilamos e implementamos desde
Bamboo .
El kit de distribución del servidor CB se entrega en forma de paquetes nativos: RPM, DEB, MSI. Además, para Windows, proporcionamos un único instalador en forma de un EXE, que instala el servidor, Hazelcast y Elasticsearch en una máquina. Al principio llamamos a esta versión de la instalación "demo", pero ahora quedó claro que esta es la opción de implementación más popular.