
Amo a Ceph He estado trabajando con él durante 4 años (0.80.x - 12.2.6 , 12.2.5). A veces me apasiona tanto que paso tardes y noches en su compañía, y no con mi novia. He encontrado varios problemas en este producto, y sigo viviendo con algunos hasta el día de hoy. A veces me regocijaba por las decisiones fáciles, y otras soñaba con reunirme con desarrolladores para expresar mi indignación. Pero Ceph todavía se usa en nuestro proyecto y es posible que se use en nuevas tareas, al menos para mí. En esta historia compartiré nuestra experiencia de operar Ceph, de alguna manera me expresaré sobre el tema de lo que no me gusta de esta solución y tal vez ayude a aquellos que solo la están viendo. Los eventos que comenzaron hace aproximadamente un año cuando traje el Dell EMC ScaleIO, ahora conocido como Dell EMC VxFlex OS, me empujaron a escribir este artículo.
¡Esto no es en absoluto un anuncio para Dell EMC o su producto! Personalmente, no soy muy bueno con las grandes corporaciones y las cajas negras como VxFlex OS. Pero como saben, todo en el mundo es relativo y, utilizando el ejemplo del sistema operativo VxFlex, es muy conveniente mostrar qué es Ceph en términos de operación, y trataré de hacerlo.
Parámetros ¡Se trata de números de 4 dígitos!
Servicios Ceph como MON, OSD, etc. tener varios parámetros para configurar todo tipo de subsistemas. Los parámetros se establecen en el archivo de configuración, los demonios los leen en el momento del lanzamiento. Algunos valores se pueden cambiar convenientemente sobre la marcha utilizando el mecanismo de "inyección", que se describe a continuación. Todo es casi super, si omites el momento en que hay cientos de parámetros:
Martillo
> ceph daemon mon.a config show | wc -l 863
Luminosa:
> ceph daemon mon.a config show | wc -l 1401
Resulta ~ 500 nuevos parámetros en dos años. En general, la parametrización es genial, no es bueno que haya dificultades para comprender el 80% de esta lista. La documentación describe según mis estimaciones ~ 20% y en algunos lugares es ambigua. Debe entenderse el significado de la mayoría de los parámetros en el github del proyecto o en las listas de correo, pero esto no siempre ayuda.
Aquí hay un ejemplo de varios parámetros que me interesaron hace poco, los encontré en el blog de un Ceph-gadfly:
throttler_perf_counter = false // enable/disable throttler perf counter osd_enable_op_tracker = false // enable/disable OSD op tracking
Comentarios de código en el espíritu de las mejores prácticas. Como si entendiera las palabras e incluso más o menos de qué se tratan, pero lo que me dará no lo es.
O aquí: osd_op_threads en Luminous desapareció y solo las fuentes ayudaron a encontrar un nuevo nombre: osd_peering_wq threads
También me gusta que hay opciones especialmente holísticas. Aquí amigo muestra que aumentar rgw_num _rados_handles es bueno :
y el otro tipo piensa que> 1 es imposible e incluso peligroso .
Y lo que más me gusta es cuando los principiantes dan ejemplos de una configuración en sus publicaciones de blog, donde todos los parámetros se copian sin pensar (me parece) copiados de otro blog del mismo tipo, por lo que un montón de parámetros que nadie conoce, excepto el autor del código, se desvían de config a config.
También me quemo salvajemente con lo que hicieron en Luminous. Hay una característica genial: cambiar los parámetros sobre la marcha, sin reiniciar los procesos. Puede, por ejemplo, cambiar el parámetro de un OSD específico:
> ceph tell osd.12 injectargs '--filestore_fd_cache_size=512'
o ponga '*' en lugar de 12 y el valor cambiará en todos los OSD. Es genial, de verdad. Pero, como mucho en Ceph, esto se hace con el pie izquierdo. El diseño Bai no puede cambiar todos los valores de los parámetros sobre la marcha. Más precisamente, se pueden configurar y aparecerán modificados en la salida, pero de hecho, solo unos pocos se vuelven a leer y se vuelven a aplicar. Por ejemplo, no puede cambiar el tamaño del grupo de subprocesos sin reiniciar el proceso. Para que el ejecutor del equipo comprenda que es inútil cambiar el parámetro de esta manera, decidieron imprimir un mensaje. Hola
Por ejemplo:
> ceph tell mon.* injectargs '--mon_allow_pool_delete=true' mon.c: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.a: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.b: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
Ambiguo De hecho, la eliminación de las piscinas se hace posible después de la inyección. Es decir, esta advertencia no es relevante para este parámetro. Ok, pero todavía hay cientos de parámetros, incluidos algunos muy útiles, que también tienen una advertencia y no hay forma de verificar su aplicabilidad real. Por el momento, ni siquiera puedo entender por el código qué parámetros se aplican después de la inyección y cuáles no. Para confiabilidad, debe reiniciar los servicios y esto, ya sabe, enfurece. Se enfurece porque sé que hay un mecanismo de inyección.
¿Qué pasa con VxFlex OS? Procesos similares como MON (en VxFlex es MDM), OSD (SDS en VxFlex) también tienen archivos de configuración, en los que hay docenas de parámetros para todos. Es cierto que sus nombres tampoco dicen nada, pero la buena noticia es que nunca recurrimos a ellos para quemar tanto como con Ceph.
Deuda técnica
Cuando comienzas a conocer a Ceph con la versión más relevante para hoy, entonces todo parece estar bien, y quieres escribir un artículo positivo. Pero cuando vives con él en la producción de la versión 0.80, entonces no todo parece tan color de rosa.
Antes de Jewel, los procesos de Ceph se ejecutaban como root. Jewel decidió que deberían trabajar desde el usuario 'ceph' y esto requería un cambio de propiedad para todos los directorios que utilizan los servicios de Ceph. Parecería que esto? Imagine una OSD que da servicio a un disco magnético SATA de capacidad total de 2 TB. Por lo tanto, la presentación de dicho disco, en paralelo (a diferentes subdirectorios) con una utilización completa del disco, demora de 3 a 4 horas. Imagine, por ejemplo, que tiene 3 cientos de esos discos. Incluso si actualiza los nodos (se muestran inmediatamente entre 8 y 12 discos), obtiene una actualización bastante larga, en la que el clúster tendrá OSD de diferentes versiones y una réplica de datos es menor en el momento en que se actualiza el servidor. En general, pensamos que era absurdo, reconstruimos los paquetes de Ceph y dejamos el OSD ejecutándose como root. Decidimos que a medida que ingresamos o reemplazamos el OSD, los transferiremos a un nuevo usuario. Ahora estamos cambiando 2-3 unidades por mes y agregando 1-2, creo que podemos manejarlo para 2022).
Aplastables sintonizables
CRUSH es el corazón de Ceph, todo gira a su alrededor. Este es el algoritmo mediante el cual, de manera pseudoaleatoria, se selecciona la ubicación de los datos y gracias a la cual los clientes que trabajan con el grupo RADOS descubrirán en qué OSD se almacenan los datos (objetos) que necesitan. La característica clave de CRUSH es que no hay necesidad de ningún servidor de metadatos, como Luster o IBM GPFS (ahora Spectrum Scale). CRUSH permite que los clientes y OSD interactúen directamente entre ellos. Aunque, por supuesto, es difícil comparar el primitivo almacenamiento de objetos RADOS y los sistemas de archivos, que di como ejemplo, pero creo que la idea es clara.
Los parámetros ajustables de CRUSH, a su vez, son un conjunto de parámetros / indicadores que afectan el funcionamiento de CRUSH, lo que lo hace más eficiente, al menos en teoría.
Entonces, al actualizar de Hammer a Jewel (prueba natural), apareció una advertencia que decía que el perfil de sintonización tiene parámetros que no son óptimos para la versión actual (Jewel) y se recomienda cambiar el perfil a uno óptimo. En general, todo está claro. El dock dice que esto es muy importante y esta es la forma correcta, pero también se dice que después del cambio de datos habrá un reequilibrio del 10% de los datos. 10%: no suena aterrador, pero decidimos probarlo. Para un clúster, es aproximadamente 10 veces menos que en un producto, con el mismo número de PG por OSD, lleno de datos de prueba, ¡obtuvimos un equilibrio del 60%! ¡Imagine, por ejemplo, con 100 TB de datos, 60 TB comienza a moverse entre OSD y esto es con una carga constante del cliente que demanda latencia! Si aún no lo he dicho, proporcionamos s3 y no tenemos mucha menos carga en rgw incluso de noche, de los cuales hay 8 y 4 más en sitios web estáticos. En general, decidimos que este no era nuestro camino, especialmente porque hacer esa reconstrucción en la nueva versión, con la que no habíamos trabajado en la producción, era al menos demasiado optimista. Además, teníamos índices de cubos grandes que se estaban reconstruyendo muy mal y esta también fue la razón del retraso en el cambio de perfil. Sobre los índices serán por separado un poco más bajos. Al final, simplemente eliminamos la advertencia y decidimos volver a esto más tarde.
Y al cambiar el perfil en las pruebas, los clientes cephfs que están en los núcleos CentOS 7.2 se cayeron porque no podían trabajar con el algoritmo de hash más nuevo del nuevo perfil que vino. No usamos cephfs en el producto, pero si solíamos hacerlo, esta sería otra razón para no cambiar el perfil.
Por cierto, el muelle dice que si lo que sucede durante el reequilibrio no le conviene, puede retroceder el perfil. De hecho, después de una instalación limpia de la versión Hammer y la actualización a Jewel, el perfil se ve así:
> ceph osd crush show-tunables { ... "straw_calc_version": 1, "allowed_bucket_algs": 22, "profile": "unknown", "optimal_tunables": 0, ... }
Es importante que sea "desconocido" y si intentas detener la reconstrucción cambiándolo a "heredado" (como se indica en el muelle) o incluso a "martillo", entonces el equilibrio no se detendrá, simplemente continuará de acuerdo con otros ajustables, y no " óptimo ". En general, todo debe ser revisado a fondo y doblemente, ceph no es confiable.
Aplastar el comercio de
Como saben, todo en este mundo es equilibrado y las desventajas se aplican a todas las ventajas. La desventaja de CRUSH es que los PG están distribuidos de manera desigual en diferentes OSD, incluso con el mismo peso de estos últimos. Además, nada impide que diferentes PG crezcan a diferentes velocidades, mientras que la función hash caerá. Específicamente, tenemos un rango de utilización de OSD de 48-84%, a pesar de que tienen el mismo tamaño y, en consecuencia, peso. Incluso intentamos hacer que los servidores tengan el mismo peso, pero esto es así, solo nuestro perfeccionismo, no más. Y con el hecho de que IO se distribuye de manera desigual entre los discos, lo peor es que cuando alcanza el estado completo (95%) de al menos un OSD en el clúster, la grabación completa se detiene y el clúster pasa a ser de solo lectura. ¡Todo el grupo! Y no importa que el grupo aún esté lleno de espacio. ¡Todo, la final, sal! Esta es una característica arquitectónica de CRUSH. Imagine que está de vacaciones, algunos OSD rompieron la marca del 85% (la primera advertencia por defecto) y tiene un 10% en stock para evitar que se detenga la grabación. Y el 10% con grabación activa no es tanto / largo. Idealmente, con tal diseño, Ceph necesita una persona de turno que pueda seguir las instrucciones preparadas en tales casos.
Entonces, decidimos que significa desequilibrar los datos en el clúster, porque varios OSD estuvieron cerca de la marca casi completa (85%).
Hay varias formas:
La forma más fácil es un poco derrochador y no muy efectivo, porque los datos en sí mismos no pueden moverse desde el OSD abarrotado o el movimiento será insignificante.
- Cambiar el peso permanente de la OSD (PESO)
Esto conduce a un cambio en el peso de toda la jerarquía de cubo superior (terminología CRUSH), servidor OSD, centro de datos, etc. y, como resultado, al movimiento de datos, incluso no de aquellos OSD de los cuales es necesario.
Intentamos, redujimos el peso de un OSD, después de que se rellenaron los datos para reconstruir otro, lo redujimos, luego el tercero y nos dimos cuenta de que jugaríamos esto durante mucho tiempo.
- Cambiar el peso OSD no permanente (REWEIGHT)
Esto es lo que se hace llamando 'ceph osd reweight-by-utilization'. Esto lleva a un cambio en el llamado peso de ajuste de OSD, y el peso del cubo más alto no cambia. Como resultado, los datos se equilibran entre diferentes OSD de un servidor, por así decirlo, sin ir más allá de los límites del depósito CRUSH. Realmente nos gustó este enfoque, observamos la ejecución en seco de los cambios y los realizamos en el producto. Todo estuvo bien hasta que el proceso de reequilibrio tuvo una participación en el medio. Nuevamente busca en Google, lee boletines informativos, experimenta con diferentes opciones, y al final resulta que la parada fue causada por la falta de algunos sintonizables en el perfil mencionado anteriormente. Nuevamente nos vimos atrapados en deudas técnicas. Como resultado, seguimos el camino de agregar discos y la reconstrucción más ineficaz. Afortunadamente, todavía necesitábamos hacer esto porque Se planeó cambiar el perfil CRUSH con un margen suficiente en capacidad.
Sí, sabemos sobre el equilibrador (Luminous y superior), que es parte de mgr, que está diseñado para resolver el problema de la distribución desigual de datos moviendo PG entre OSD, por ejemplo, en la noche. Pero aún no he escuchado críticas positivas sobre su trabajo, incluso en el Mimic actual.
Probablemente dirá que la deuda técnica es puramente nuestro problema y probablemente estaría de acuerdo. Pero durante cuatro años con Ceph en la producción, solo tuvimos un tiempo de inactividad s3 registrado, que duró una hora completa. Y luego, el problema no estaba en RADOS, sino en RGW, que, después de escribir sus 100 subprocesos predeterminados, se colgó y la mayoría de los usuarios no cumplieron con las solicitudes. Todavía estaba en Hammer. En mi opinión, este es un buen indicador y se logra debido al hecho de que no hacemos movimientos bruscos y somos bastante escépticos sobre todo en Ceph.
Gc salvaje
Como sabe, eliminar datos directamente del disco es una tarea bastante exigente y en los sistemas avanzados, la eliminación se retrasa o no se realiza en absoluto. Ceph también es un sistema avanzado y, en el caso de RGW, al eliminar un objeto s3, los objetos RADOS correspondientes no se eliminan inmediatamente del disco. RGW marca los objetos s3 como eliminados, y un gc-stream separado elimina objetos directamente de los grupos RADOS y, en consecuencia, se pospone de los discos. Después de actualizar a Luminous, el comportamiento de gc cambió notablemente, comenzó a funcionar de manera más agresiva, aunque los parámetros de gc siguieron siendo los mismos. Por la palabra notablemente, quiero decir que comenzamos a ver a gc trabajando en monitoreo externo del servicio para saltar la latencia. Esto fue acompañado por un alto IO en el grupo rgw.gc. Pero el problema que enfrentamos es mucho más épico que solo IO. Cuando se ejecuta gc, se generan muchos registros del formulario:
0 <cls> /builddir/build/BUILD/ceph-12.2.5/src/cls/rgw/cls_rgw.cc:3284: gc_iterate_entries end_key=1_01530264199.726582828
Donde 0 al principio es el nivel de registro en el que se imprime este mensaje. Por así decirlo, no hay ningún lugar para reducir el registro debajo de cero. Como resultado, un OSD generó ~ 1 GB de registros en un par de horas en un par de horas, y todo habría estado bien si los nodos ceph no estuvieran sin disco ... Cargamos el sistema operativo a través de PXE directamente en la memoria y no utilizamos el disco local o NFS, NBD para la partición del sistema (/). Resulta servidores sin estado. Después de un reinicio, la automatización completa todo el estado. Cómo funciona, lo describiré de alguna manera en un artículo separado, ahora es importante que se asignen 6 GB de memoria para "/", de los cuales ~ 4 generalmente son gratuitos. Enviamos todos los registros a Graylog y utilizamos una política de rotación de registros bastante agresiva y generalmente no experimentamos ningún problema con el desbordamiento de disco / RAM. Pero no estábamos preparados para esto, con 12 OSD, el servidor "/" se llenó muy rápido, los asistentes a tiempo no respondieron al disparador en Zabbix y OSD comenzó a detenerse debido a la incapacidad de escribir un registro. Como resultado, redujimos la intensidad de gc, el boleto no comenzó porque Ya estaba allí, y agregamos un script a cron, en el que forzamos a los registros de OSD a truncarse cuando se excede una cierta cantidad sin esperar logrotate. Por cierto, el nivel de registro aumentó .
Grupos de colocación y escalabilidad elogiada
En mi opinión, PG es la abstracción más difícil de entender. Se necesita PG para hacer CRUSH más efectivo. El objetivo principal de PG es agrupar objetos para reducir el consumo de recursos, aumentar la productividad y la escalabilidad. Dirigir objetos directamente, individualmente, sin combinarlos en PG sería muy costoso.
El principal problema de PG es determinar su número para un nuevo grupo. Del blog de Ceph:
"Elegir el número correcto de PG para su clúster es un poco de arte negro y una pesadilla de usabilidad".
Esto siempre es muy específico para una instalación en particular y requiere mucho pensamiento y cálculo.
Recomendaciones clave
- Demasiados PG en el OSD son malos; habrá un gasto excesivo de recursos para su mantenimiento y frenos durante el reequilibrio / recuperación.
- Pocos PG en OSD son malos, el rendimiento se verá afectado y los OSD se llenarán de manera desigual.
- El número PG debe ser un múltiplo de grado 2. Esto ayudará a obtener el "poder de CRUSH".
Y aquí arde conmigo. Los PG no están limitados en volumen o en la cantidad de objetos. ¿Cuántos recursos (en números reales) se necesitan para dar servicio a un PG? ¿Depende de su tamaño? ¿Depende del número de réplicas de esta PG? ¿Debo tomar un baño de vapor si tengo suficiente memoria, CPU rápidas y una buena red?
Y también debe pensar en el crecimiento futuro del clúster. El número de PG no puede reducirse, solo aumentarse. Al mismo tiempo, no se recomienda hacer esto, ya que esto implicará, en esencia, dividir parte de PG a una reconstrucción nueva y salvaje.
"Aumentar el recuento de PG de un grupo es uno de los eventos más impactantes en un Ceph Cluster, y debe evitarse para los grupos de producción si es posible".
Por lo tanto, debe pensar en el futuro de inmediato, si es posible.
Un verdadero ejemplo.
Un clúster de 3 servidores con OSD de 14x2 TB cada uno, un total de 42 OSD. Réplica 3, lugar útil ~ 28 TB. Para ser utilizado en S3, debe calcular el número de PG para el grupo de datos y el grupo de índice. RGW usa más grupos, pero los dos son primarios.
Entramos en la calculadora PG (existe una calculadora de este tipo), consideramos que con los 100 PG recomendados en el OSD, obtenemos solo 1312 PG. Pero no todo es tan simple: tenemos uno introductorio: el clúster definitivamente crecerá tres veces en un año, pero el hierro se comprará un poco más tarde. Aumentamos "Target PGs por OSD" tres veces, a 300 y obtenemos 4480 PG.
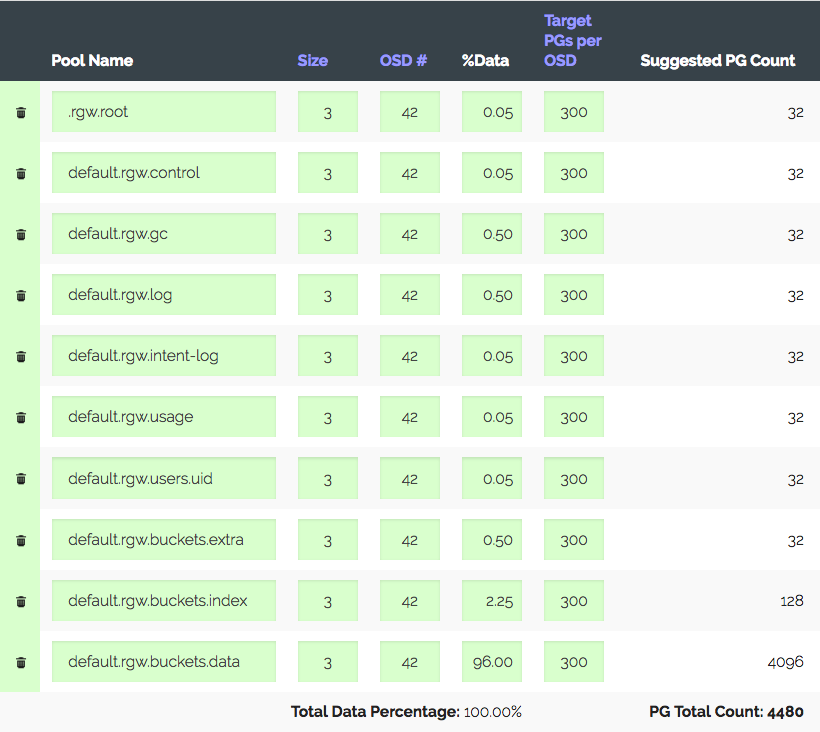
Establezca el número de PG para los grupos correspondientes; recibimos una advertencia: demasiados PG por OSD ... llegaron. Recibió ~ 300 PG en OSD con un límite de 200 (Luminous). Solía ser 300, por cierto. Y lo más interesante es que todos los PG innecesarios no pueden mirar, es decir, esto no es solo una advertencia. Como resultado, creemos que estamos haciendo todo bien, elevando los límites, apagando la advertencia y avanzando.
Otro ejemplo real es más interesante.
S3, volumen utilizable de 152 TB, 252 OSD a 1.81 TB, ~ 105 PG en OSD. El clúster creció gradualmente, todo estuvo bien hasta que con las nuevas leyes en nuestro país hubo una necesidad de crecer a 1 PB, es decir, + ~ 850 TB, y al mismo tiempo necesita mantener el rendimiento, que ahora es bastante bueno para S3. Supongamos que tomamos discos de 6 (5,7 reales) TB y teniendo en cuenta la réplica 3 obtenemos + 447 OSD. Teniendo en cuenta los actuales, obtenemos 699 OSD con 37 PG cada uno, y si tenemos en cuenta diferentes pesos, resulta que los OSD antiguos tienen solo una docena de PG. ¿Entonces me dices cómo tolerablemente esto funcionará? El rendimiento de un clúster con un número diferente de PG es bastante difícil de medir sintéticamente, pero las pruebas que realicé muestran que para un rendimiento óptimo es necesario de 50 PG a 2 TB OSD. ¿Y qué hay de un mayor crecimiento? Sin aumentar el número de PG, puede ir a la asignación de PG a OSD 1: 1. ¿Quizás no entiendo algo?
Sí, puede crear un nuevo grupo para RGW con el número deseado de PG y asignarle una región S3 separada. O incluso construir un nuevo grupo cercano. Pero debes admitir que todas estas son muletas. Y resulta que parece un Ceph bien escalable debido a su concepto, PG escala con reservas. Tendrá que vivir con vorings deshabilitados en preparación para el crecimiento, o en algún momento reconstruir todos los datos en el clúster, o puntuar sobre el rendimiento y vivir con lo que sucede. O ve a través de todo.
Me alegra que los desarrolladores de Ceph entiendan que PG es una abstracción compleja y superflua para el usuario y que es mejor no saberlo.
"En Luminous hemos tomado medidas importantes para finalmente eliminar una de las formas más comunes de conducir su clúster a una zanja, y esperamos poder ocultar eventualmente los PG por completo para que no sean algo que la mayoría de los usuarios tengan que saber o pensar en ".
En vxFlex no existe el concepto de PG ni ningún análogo. Simplemente agrega discos al grupo y eso es todo. Y así sucesivamente hasta 16 PB. Imagínese, no es necesario calcular nada, no hay un montón de estados de estos PG, los discos se eliminan de manera uniforme durante todo el crecimiento. Porque los discos se entregan a vxFlex en su conjunto (no hay ningún sistema de archivos encima), no hay forma de evaluar la plenitud y no existe tal problema en absoluto. Ni siquiera sé cómo transmitirle lo agradable que es.
"Necesito esperar al SP1"
Otra historia de "éxito". Como saben, RADOS es el almacenamiento clave-valor más primitivo. S3, implementado sobre RADOS, también es primitivo, pero aún un poco más funcional. , S3 . , , RGW . — RADOS-, OSD. . , . OSD down. , , . , scrub' . , - 503, .
Bucket Index resharding — , (RADOS-) , , OSD, .
, , Jewel ! Hammer, .. -. ?
Hammer 20+ , , OSD Graylog , . , .. IO . Luminous, .. . Luminous, , . , . IO index-, , . , IO , . , … ; , :
, . , .. , .
, Hammer->Jewel - . OSD - . , OSD .
— , , . Hammer s3, . , . , , etag, body, . . , . Suspend . "" . , .
, 2 — , Cloudmouse. , Ceph, , .
vxFlex OS 2 . , . , . , . , , , Dell EMC.
. , ? . , . , Ceph, vxFlex . - . , .
9 ceph-devel : , CPU ( Xeon' !) IOPS All-NVMe Ceph 12.2.7 bluestore.
, , "" Ceph . ( Hammer) Ceph , s3 . , ScaleIO Ceph RBD . Ceph, — CPU. RDMA InfiniBand, jemalloc . , 10-20 , iops, io, Ceph . vxFlex . — Ceph system time, scaleio — io wait. , bluestore, , , -, , Ceph. ScaleIO . , , Ceph Dell EMC.
, , PG. (), IO. - PG IO, , . , nearfull. , .
vxFlex - , . ( ceph-volume), , .
Scrub
, . , , Ceph.
, . " " — - , . , 2 TB >50%, Ceph, . . , .
vxFlex OS , , . — bandwidth . . , .
, , vxFlex scrub-error. Ceph 2 .
Monitoreo
Luminous — . . MGR- Zabbix (3 ). . , , - IO , gc, . — RGW .

. .
S3, "" :
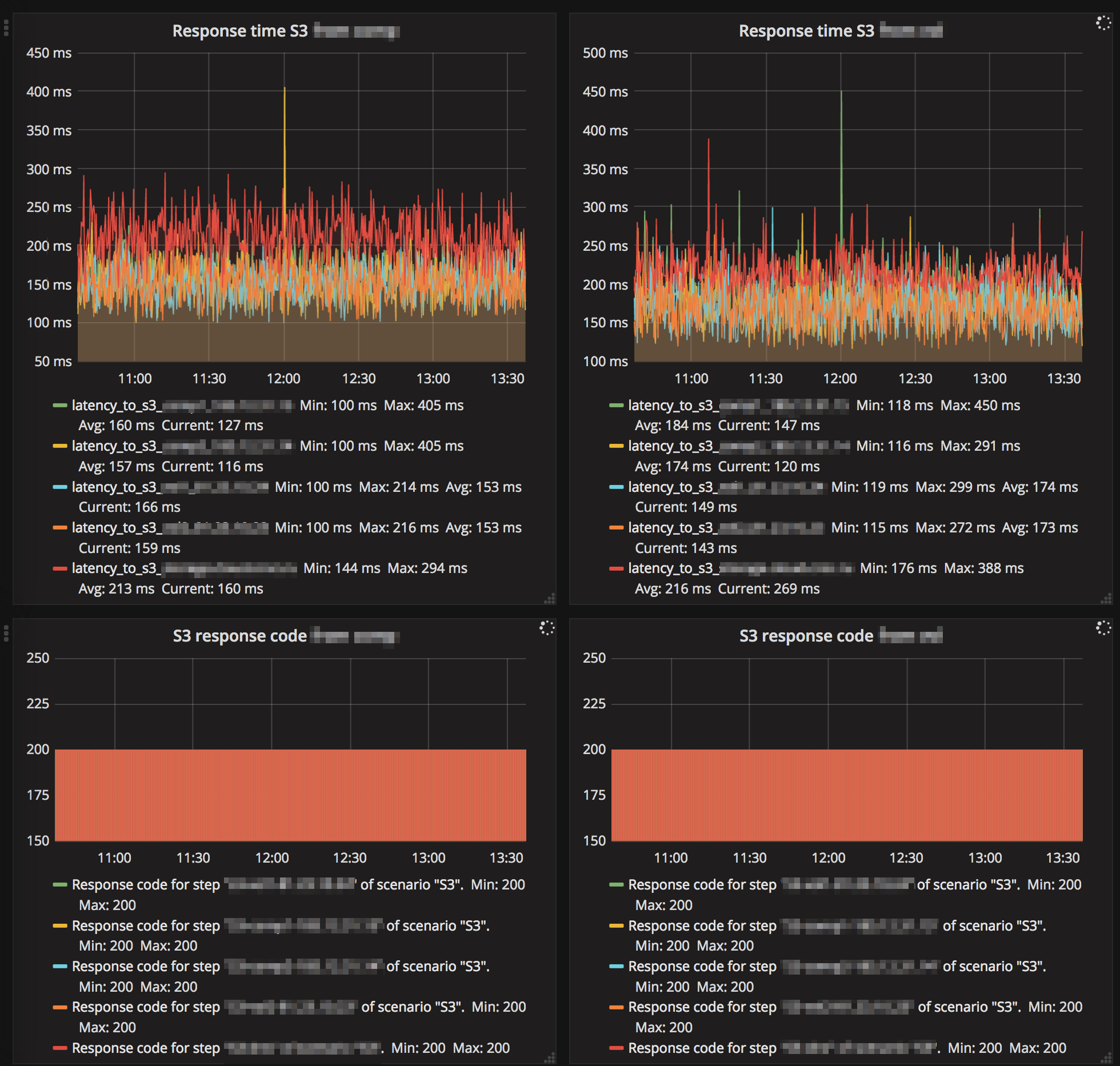
Ceph , , , , .
, eph Graylog GELF . , , OSD down, out, failed . , , OSD down , .
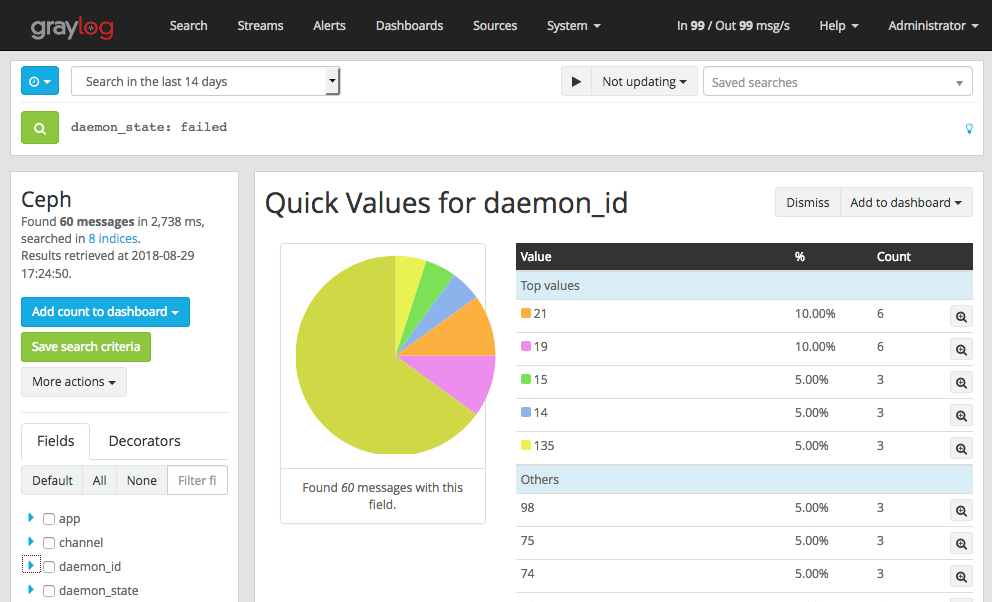
- , OSD heartbeat failed (. ). vm.zone_reclaim_mode=1 NUMA.
Ceph. c vxFlex . :
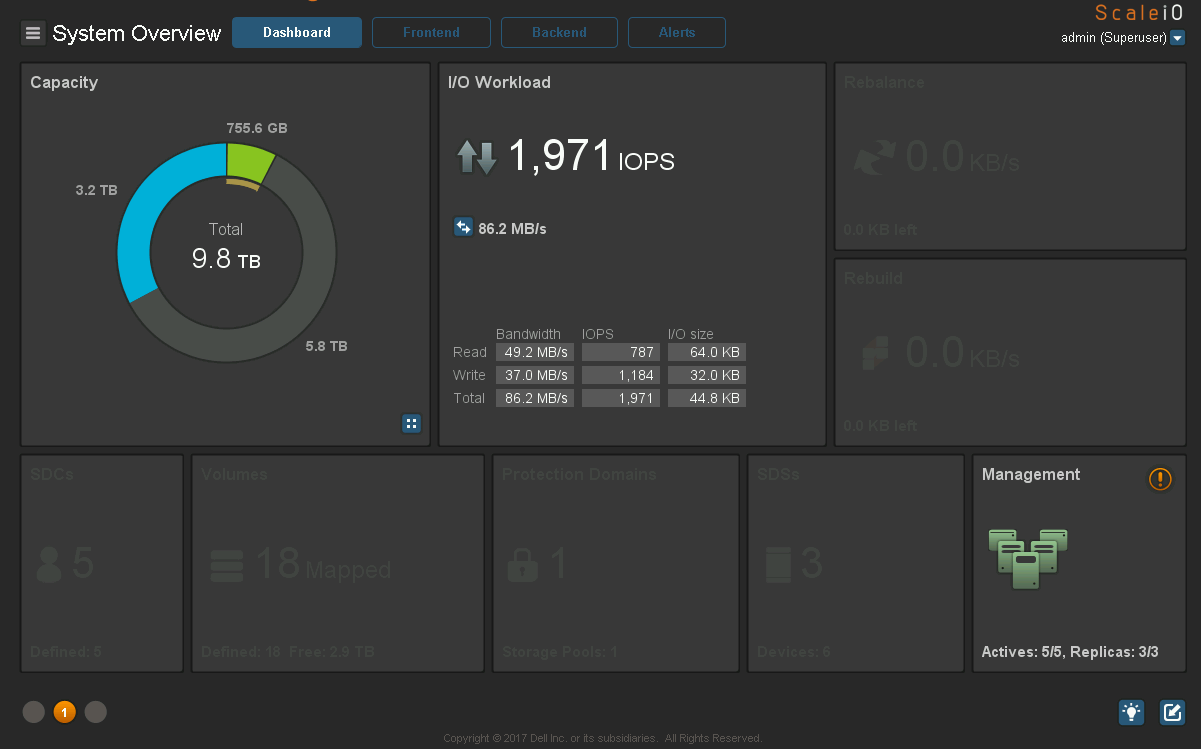
:

IO :
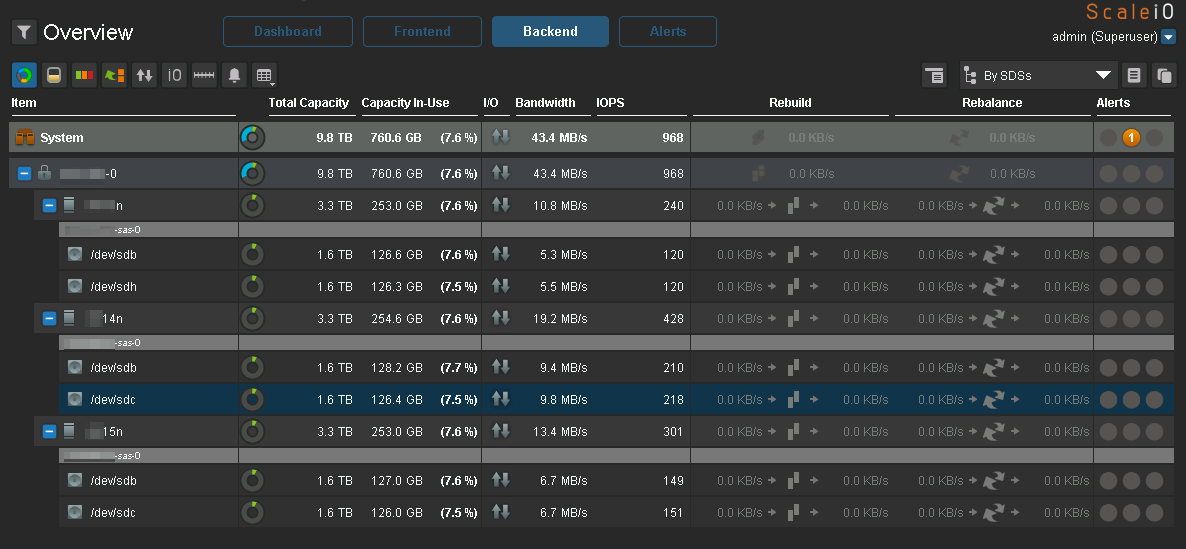
IO, Ceph.
:
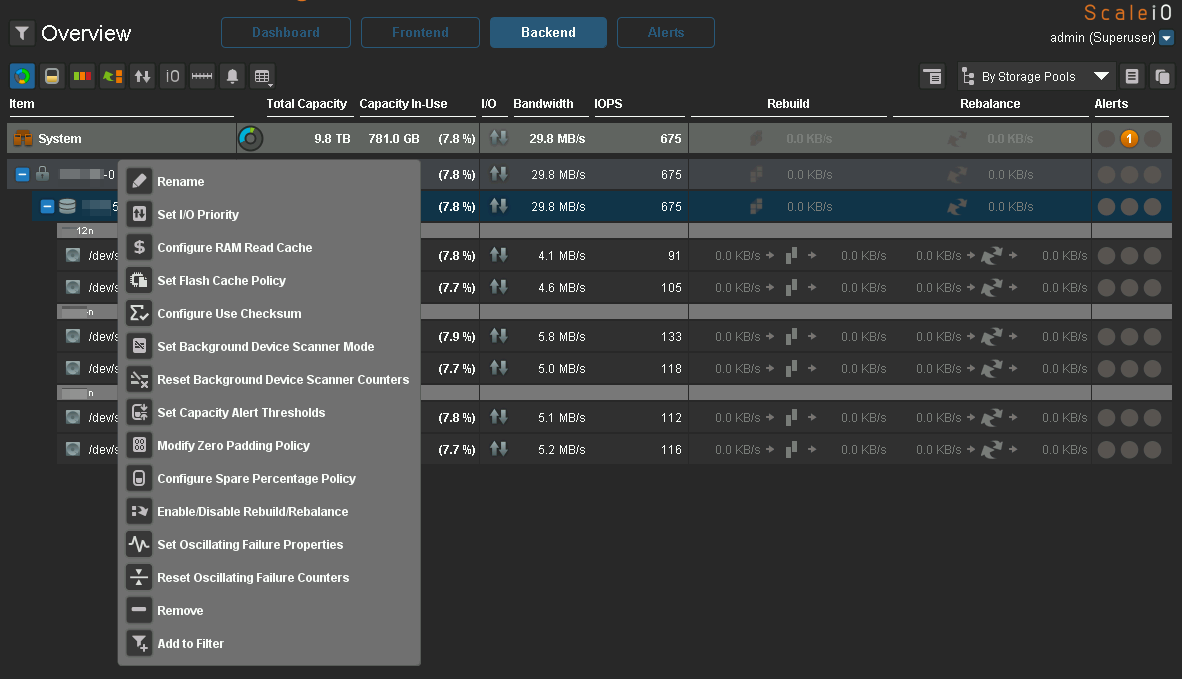
Ceph, Luminous . 2.0, Mimic , .
vxFlex
Degraded state , .
vxFlex — RH . 7.5 , . Ceph RBD cephfs — .
vxFlex Ceph. vxFlex — , , , .
16 PB, . eph 2 PB …
Conclusión
, Ceph , , , Ceph — . .
, Ceph " ". , " , , R&D, - ". . " ", Ceph , , .
Ceph 2k18 , . 24/7 ( S3, , EBS), , Ceph . , . — . / maintenance backfilling , c Ceph , , .
Ceph ? , " ". Ceph. . , , , , …
!
HEALTH_OK!