No vale la pena hablar en detalle del concepto de computación diferida. La idea de hacer lo mismo con menos frecuencia, especialmente si es larga y pesada, es tan antigua como el mundo. Porque inmediatamente al grano.
Según el autor de este texto, un lenificador normal debería:
- Guardar cálculos entre llamadas de programa.
- Rastree los cambios en el árbol de cálculo.
- Tener una sintaxis moderadamente transparente.

Concepto
En orden:
- Guardar cálculos entre llamadas de programa:
De hecho, si llamamos al mismo script varias decenas y cientos de veces al día, ¿por qué deberíamos volver a calcular el mismo cada vez que se llama al script, si es posible almacenar el objeto de resultado en un archivo? Es mejor extraer un objeto del disco, pero ... debemos estar seguros de su relevancia. De repente, el guión se reescribe y el objeto guardado está desactualizado. En base a esto, no podemos simplemente cargar el objeto cuando existe un archivo. El segundo punto se sigue de esto. - Rastree los cambios en el árbol de cálculo:
La necesidad de actualizar el objeto debe calcularse sobre la base de los datos sobre los argumentos de la función que lo genera. Entonces nos aseguraremos de que el objeto cargado sea válido. De hecho, para una función pura, el valor de retorno depende solo de los argumentos. Esto significa que mientras almacenamos en caché los resultados de las funciones puras y monitoreamos los cambios en los argumentos, podemos estar tranquilos sobre la relevancia de la memoria caché. Al mismo tiempo, si el objeto calculado depende de otro objeto en caché (perezoso), que a su vez depende de otro, debe resolver correctamente los cambios en estos objetos, actualizando a tiempo los nodos de la cadena que ya no son relevantes. Por otro lado, sería bueno tener en cuenta que no siempre necesitamos cargar los datos de toda la cadena de cálculo. A menudo, cargar solo el objeto del resultado final es suficiente. - Tener una sintaxis moderadamente transparente:
Este punto es claro. Si para reescribir la secuencia de comandos a cálculos diferidos es necesario cambiar todo el código, esta es una solución regular. Los cambios deben hacerse al mínimo.
Esta línea de razonamiento condujo a una solución técnica, diseñada en python por la biblioteca evalcache (enlaces al final del artículo).
Solución de sintaxis y mecanismo de trabajo
Ejemplo simpleimport evalcache import hashlib import shelve lazy = evalcache.Lazy(cache = shelve.open(".cache"), algo = hashlib.sha256) @lazy def summ(a,b,c): return a + b + c @lazy def sqr(a): return a * a a = 1 b = sqr(2) c = lazy(3) lazyresult = summ(a, b, c) result = lazyresult.unlazy() print(lazyresult)
Como funciona
Lo primero que llama la atención aquí es la creación del decorador perezoso. Tal solución sintáctica es bastante estándar para las pitones Python. Al decorador perezoso se le pasa un objeto de caché en el que el lenificador almacenará los resultados de los cálculos. Los requisitos de la interfaz tipo dict se superponen en el tipo de caché. En otras palabras, podemos almacenar en caché todo lo que implemente la misma interfaz que el tipo dict. Para demostrar en el ejemplo anterior, utilizamos el diccionario de la biblioteca de estanterías.
Al decorador también se le envía un protocolo hash que usará para construir claves hash de objetos y algunas opciones adicionales (permiso de escritura, permiso de lectura, salida de depuración), que se pueden encontrar en la documentación o el código.
El decorador se puede aplicar tanto a funciones como a objetos de otros tipos. En este momento, un objeto vago se construye sobre la base de una clave hash calculada sobre la base de la representación (o utilizando una función hash especialmente definida para este tipo de función).
Una característica clave de la biblioteca es que un objeto perezoso puede generar otros objetos perezosos, y la clave hash del padre (o padres) se mezclará con la clave hash del descendiente. Para objetos perezosos, se permite el uso de la operación de tomar un atributo, el uso de llamadas ( __call__ ) de objetos y el uso de operadores.
Al pasar por un script, de hecho, no se realizan cálculos. Para b el cuadrado no se calcula, y para el resultado diferido no se considera la suma de los argumentos. En cambio, se construye un árbol de operaciones y se calculan las claves hash de los objetos perezosos.
Los cálculos reales (si el resultado no se colocó previamente en la memoria caché) se realizarán solo en la línea: result = lazyresult.unlazy()
Si el objeto se calculó previamente, se cargará desde el archivo.
Puedes visualizar el árbol de construcción:
Construir visualización de árbol evalcache.print_tree(lazyresult) ... generic: <function summ at 0x7f1cfc0d5048> args: 1 generic: <function sqr at 0x7f1cf9af29d8> args: 2 ------- 3 -------
Dado que los hashes de los objetos se construyen sobre la base de los datos sobre los argumentos que generan estos objetos, cuando el argumento cambia, el hash del objeto cambia y con él los hashes de toda la cadena dependiendo de él. Esto le permite mantener los datos de caché actualizados haciendo actualizaciones a tiempo.
Los objetos perezosos se alinean en un árbol. Si realizamos una operación lenta en uno de los objetos, se cargarán y contarán exactamente tantos objetos como sea necesario para obtener un resultado válido. Idealmente, el objeto necesario simplemente se cargará. En este caso, el algoritmo no extraerá los objetos en formación en la memoria.
En acción
Lo anterior fue un ejemplo simple que muestra la sintaxis pero no demuestra el poder computacional del enfoque.
Aquí hay un ejemplo un poco más cercano a la vida real (usado por sympy).
Ejemplo usando sympy y numpy Las operaciones para simplificar las expresiones simbólicas son extremadamente costosas y literalmente piden lenificación. La construcción adicional de una gran matriz lleva aún más tiempo, pero gracias a la lenificación, los resultados se extraerán del caché. Tenga en cuenta que si se cambia algún coeficiente en la parte superior del script donde se genera la expresión sympy, los resultados se volverán a calcular porque la clave hash del objeto vago cambiará (gracias a las interesantes declaraciones __repr__ ).
Muy a menudo, una situación ocurre cuando un investigador realiza experimentos computacionales en un objeto generado desde hace mucho tiempo. Puede usar varios scripts para separar la generación y el uso del objeto, lo que puede causar problemas con la actualización prematura de datos. El enfoque propuesto puede facilitar este caso.
¿De qué se trata todo esto?
evalcache es parte del proyecto zencad. Este es un pequeño script cadic, inspirado y que explota las mismas ideas que openscad. A diferencia de openscad orientado a la malla, zencad que se ejecuta en el núcleo de opencascade utiliza una representación breve de objetos y los scripts se escriben en python.
Las operaciones geométricas a menudo se realizan durante mucho tiempo. La desventaja de los sistemas de secuencias de comandos cad es que cada vez que ejecuta la secuencia de comandos, el producto se vuelve a contar por completo. Además, con el crecimiento y la complicación del modelo, los costos generales no crecen linealmente. Esto lleva al hecho de que puede trabajar cómodamente solo con modelos extremadamente pequeños.
La tarea de evalcache era suavizar este problema. En zencad, todas las operaciones se declaran perezosas.
Ejemplos:
Ejemplo de construcción modelo
Este script genera el siguiente modelo:
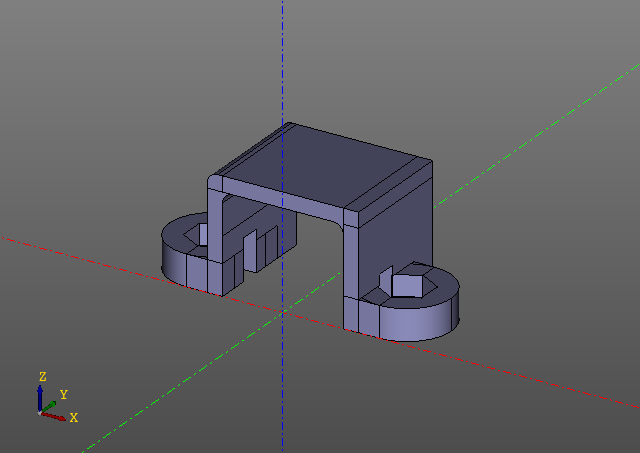
Tenga en cuenta que no hay llamadas evalcache en el script. El truco es que la lenificación está incrustada en la propia biblioteca zencad y ni siquiera es visible a primera vista, aunque todo el trabajo aquí está trabajando con objetos perezosos, y el cálculo directo se realiza solo en la función 'mostrar'. Por supuesto, si se cambia algún parámetro del modelo, el modelo se volverá a contar desde el lugar donde cambió la primera clave hash.
Modelos de computación voluminosaAquí hay otro ejemplo. Esta vez nos limitaremos a las imágenes:
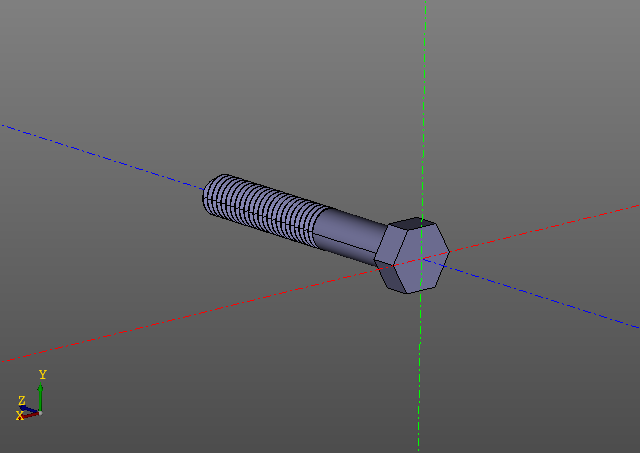
El cálculo de una superficie roscada no es una tarea fácil. En mi computadora, este tornillo está construido en el orden de diez segundos ... Editar un modelo con hilos es mucho más agradable usando el almacenamiento en caché.
Y ahora esto es un milagro:

Cruzar superficies roscadas es una tarea computacional compleja. Valor práctico, sin embargo, nada menos que comprobar las matemáticas. El cálculo lleva un minuto y medio. Un objetivo digno para la lenificación.
Los problemas
Es posible que el caché no funcione según lo previsto.
Los errores de caché se pueden dividir en falso positivo y falso negativo .
Errores falsos negativos
Los falsos errores negativos son situaciones en las que el resultado del cálculo está en la memoria caché, pero el sistema no lo encontró.
Esto sucede si el algoritmo de clave hash utilizado por evalcache por alguna razón produjo una clave diferente para el recálculo. Si la función hash no se reemplaza para el objeto del tipo en caché, evalcache usa la __repr__ objeto para construir la clave.
Se produce un error, por ejemplo, si la clase que se alquila no anula el object.__repr__ estándar object.__repr__ , que cambia de principio a inicio. O, si el __repr__ reemplazado, de alguna manera depende de insignificante para el cálculo de los datos cambiantes (como la dirección del objeto o la marca de tiempo).
Malo:
class A: def __init__(self): self.i = 3 A_lazy = lazy(A) A_lazy().unlazy()
Bueno
class A: def __init__(self): self.i = 3 def __repr__(self): return "A({})".format(self.i) A_lazy = lazy(A) A_lazy().unlazy()
Los falsos errores negativos conducen al hecho de que la lenificación no funciona. El objeto será contado en cada nueva ejecución de script.
Errores falsos positivos
Este es un tipo de error más vil, ya que conduce a errores en el objeto final de cálculo:
Puede suceder por dos razones.
- Increíble:
Se produjo una colisión de clave hash en el caché. Para el algoritmo sha256 que tiene un espacio de 115792089237316195423570985008687907853269984665640564039457584007913129639936 claves posibles, la probabilidad de una colisión es insignificante. - Probable:
Una representación de un objeto (o una función hash anulada) no lo describe completamente o coincide con una representación de un objeto de otro tipo.
class A: def __init__(self): self.i = 3 def __repr__(self): return "({})".format(self.i) class B: def __init__(self): self.i = 3 def __repr__(self): return "({})".format(self.i) A_lazy = lazy(A) B_lazy = lazy(B) a = A_lazy().unlazy() b = B_lazy().unlazy()
Ambos problemas están relacionados con un objeto __repr__ incompatible. Si por alguna razón es imposible sobrescribir el tipo de objeto __repr__ , la biblioteca le permite establecer una función hash especial para el tipo de usuario.
Sobre análogos
Existen muchas bibliotecas de lenificación que básicamente consideran suficiente ejecutar un cálculo no más de una vez por llamada de script.
Hay muchas bibliotecas de almacenamiento en caché de disco que, a petición suya, guardarán un objeto con la clave necesaria para usted.
Pero todavía no pude encontrar bibliotecas que permitieran el almacenamiento en caché de resultados en el árbol de ejecución. Si hay alguno, por favor, inseguro.
Referencias
Proyecto Github
Proyecto Pypi