Este artículo se centrará en el equilibrio de carga en proyectos web. Muchos creen que la solución a este problema es la distribución de la carga entre servidores: cuanto más precisa, mejor. Pero sabemos que esto no es del todo cierto.
La estabilidad del sistema es mucho más importante desde el punto de vista comercial .
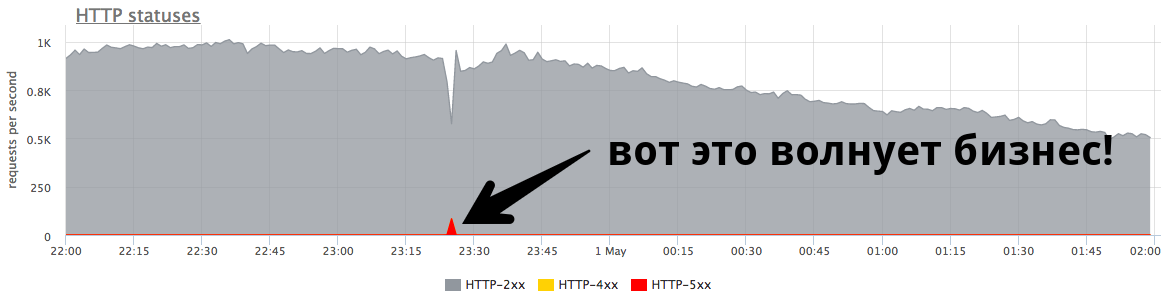
El pequeño pico de minutos a 84 RPS de "quinientos" es de cinco mil errores que recibieron los usuarios reales. Esto es mucho y es muy importante. Es necesario buscar razones, trabajar en los errores e intentar continuar para evitar tales situaciones.
Nikolay Sivko (
NikolaySivko ) en su informe sobre RootConf 2018 habló sobre los aspectos sutiles y aún no muy populares del equilibrio de carga:
- cuándo repetir la solicitud (reintentos);
- cómo seleccionar valores para tiempos de espera;
- cómo no matar los servidores subyacentes en el momento del accidente / congestión;
- si se necesitan controles de salud;
- Cómo manejar los problemas de parpadeo.
Bajo decodificación de gato de este informe.
Sobre el orador: Nikolay Sivko cofundador de okmeter.io. Trabajó como administrador del sistema y líder de un grupo de administradores. Operación supervisada en hh.ru. Fundó el servicio de monitoreo okmeter.io. Como parte de este informe, el monitoreo de la experiencia de desarrollo es la principal fuente de casos.
¿De qué vamos a hablar?
Este artículo hablará sobre proyectos web. A continuación se muestra un ejemplo de producción en vivo: el gráfico muestra las solicitudes por segundo para un determinado servicio web.
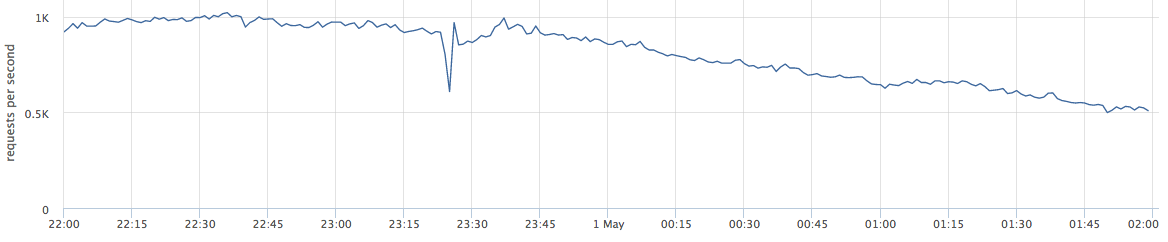
Cuando hablo sobre el equilibrio, muchos lo perciben como "necesitamos distribuir la carga entre los servidores; cuanto más preciso, mejor".
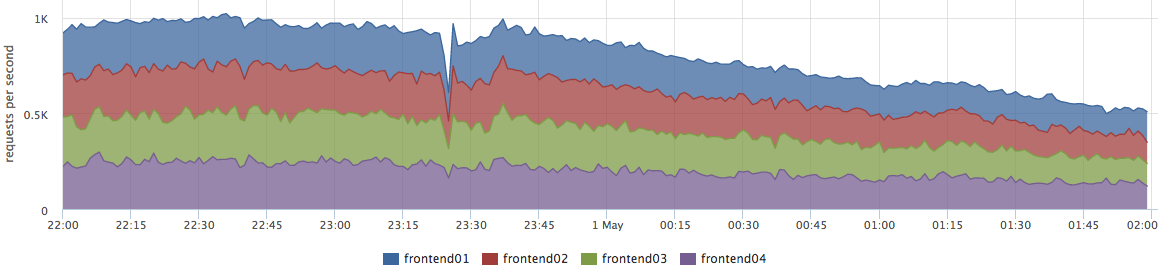
De hecho, esto no es del todo cierto. Este problema es relevante para un número muy pequeño de empresas. Con mayor frecuencia, las empresas están preocupadas por los errores y la estabilidad del sistema.
El pequeño pico en el gráfico es "quinientos", que el servidor devolvió en un minuto y luego se detuvo. Desde el punto de vista de una empresa, como una tienda en línea, este pequeño pico a 84 RPS de "quinientos" es 5040 errores para usuarios reales. Algunos no encontraron algo en su catálogo, otros no pudieron poner los productos en la cesta. Y esto es muy importante. Aunque este pico no se ve muy grande en el gráfico,
es mucho en usuarios reales .
Como regla general, todos tienen esos picos, y los administradores no siempre responden a ellos. Muy a menudo, cuando una empresa pregunta qué fue, le responden:
- "Esta es una breve explosión!"
- "Es solo un lanzamiento rodante".
- "El servidor está muerto, pero todo ya está en orden".
- "Vasya cambió la red de uno de los servidores".
A menudo, las personas
ni siquiera tratan de entender las razones por
las que esto sucedió, y no hacen ningún trabajo posterior para que no vuelva a suceder.
Buena sintonía
Llamé al informe "Ajuste fino" (Ing. Ajuste fino), porque pensé que no todos llegan a esta tarea, pero valdría la pena. ¿Por qué no llegan allí?
- No todos llegan a esta tarea, porque cuando todo funciona, no es visible. Esto es muy importante para los problemas. Fakapa no ocurre todos los días, y un problema tan pequeño requiere esfuerzos muy serios para resolverlo.
- Necesitas pensar mucho. Muy a menudo, el administrador, la persona que ajusta el equilibrio, no puede resolver este problema de forma independiente. A continuación veremos por qué.
- Atrapa los niveles subyacentes. Esta tarea está muy relacionada con el desarrollo, con la adopción de decisiones que afectan a su producto y a sus usuarios.
Afirmo que es hora de hacer esta tarea por varias razones:- El mundo está cambiando, volviéndose más dinámico, hay muchos lanzamientos. Dicen que ahora es correcto lanzar 100 veces al día, y el lanzamiento es el futuro fakap con una probabilidad de 50 a 50 (al igual que la probabilidad de encontrarse con un dinosaurio)
- Desde el punto de vista de la tecnología, todo también es muy dinámico. Kubernetes y otros orquestadores aparecieron. No hay una buena implementación anterior, cuando se apaga un backend en alguna IP, se actualiza una actualización y el servicio se activa. Ahora, en el proceso de implementación en k8s, la lista de IP ascendente está cambiando por completo.
- Microservicios: ahora todos se comunican a través de la red, lo que significa que debe hacerlo de manera confiable. El equilibrio juega un papel importante.
Banco de pruebas
Comencemos con casos simples y obvios. Para mayor claridad, usaré un banco de pruebas. Esta es una aplicación de Golang que proporciona http-200, o puede cambiarla al modo "give http-503".
Comenzamos 3 instancias:
- 127.0.0.1:20001
- 127.0.0.1:20002
- 127.0.0.1:20003
Servimos 100 rps a través de yandex.tank a través de nginx.
Nginx fuera de la caja:
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; location / { proxy_pass http://backends; } }
Escenario primitivo
En algún momento, encienda uno de los backends en el modo give 503, y obtenemos exactamente un tercio de los errores.
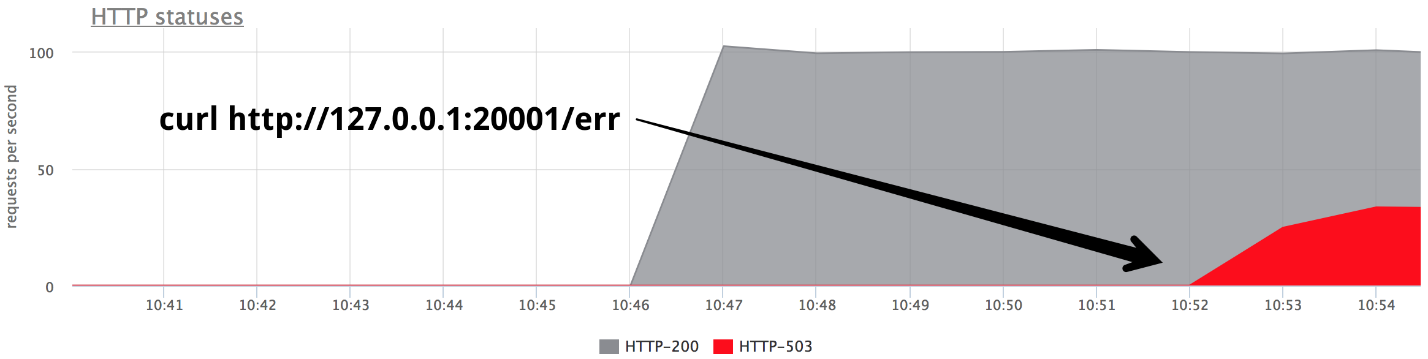
Está claro que nada funciona fuera de la caja: nginx no vuelve a intentarlo si recibió
alguna respuesta del servidor.
Nginx default: proxy_next_upstream error timeout;
De hecho, esto es bastante lógico desde el punto de vista de los desarrolladores de nginx: nginx no tiene derecho a decidir por usted qué desea retransmitir y qué no.
Por consiguiente, necesitamos reintentos, reintentos, y comenzamos a hablar sobre ellos.
Reintentos
Es necesario encontrar un compromiso entre:
- La solicitud del usuario es sagrada, hiere, pero responde. Queremos responder al usuario a toda costa, el usuario es lo más importante.
- Es mejor responder con un error que sobrecargar los servidores.
- Integridad de los datos (para solicitudes no idempotentes), es decir, es imposible repetir ciertos tipos de solicitudes.
La verdad, como de costumbre, está en algún punto intermedio: nos vemos obligados a equilibrar estos tres puntos. Tratemos de entender qué y cómo.
Dividí los intentos fallidos en 3 categorías:
1.
Error de transportePara el transporte HTTP es TCP y, por regla general, aquí hablamos de los errores de configuración de conexión y los tiempos de espera de configuración de conexión. En mi informe, mencionaré 3 balanceadores comunes (hablaremos un poco más sobre Envoy):
- nginx : errores + tiempo de espera (proxy_connect_timeout);
- HAProxy : tiempo de espera de conexión;
- Enviado : error de conexión + flujo rechazado.
Nginx tiene la oportunidad de decir que un intento fallido es un error de conexión y un tiempo de espera de conexión; HAProxy tiene un tiempo de espera de conexión, Envoy también tiene todo estándar y normal.
2.
Solicitar tiempo de espera:Supongamos que enviamos una solicitud al servidor, que nos conectamos con éxito, pero la respuesta no llega a nosotros, la esperamos y entendemos que no tiene sentido esperar más. Esto se llama tiempo de espera de solicitud:
- Nginx tiene: tiempo de espera (prox_send_timeout * + proxy_read_timeout *);
- HAProxy tiene OOPS :( - no existe en principio. Muchas personas no saben que HAProxy, si ha establecido una conexión con éxito, nunca intentará reenviar la solicitud.
- El enviado puede hacer todo: tiempo de espera || per_try_timeout.
3.
estado HTTPTodos los equilibradores, a excepción de HAProxy, pueden procesar, sin embargo, el backend le respondió, pero con algún tipo de código erróneo.
- nginx : http_ *
- HAProxy : OOPS :(
- Enviado : 5xx, error de puerta de enlace (502, 503, 504), recuperable-4xx (409)
Tiempos de espera
Ahora hablemos en detalle sobre los tiempos de espera, me parece que vale la pena prestar atención a esto. No habrá más ciencia espacial: se trata simplemente de información estructurada sobre lo que generalmente sucede y cómo se relaciona con él.
Tiempo de espera de conexión
El tiempo de espera de conexión es el momento de establecer una conexión. Esta es una característica de su red y su servidor específico, y no depende de la solicitud. Por lo general, el valor predeterminado para el tiempo de espera de conexión se establece en pequeño. En todos los proxies, el valor predeterminado es lo suficientemente grande, y esto es incorrecto: deberían ser
unidades, a veces decenas de milisegundos (si estamos hablando de una red dentro de un DC).
Si desea identificar servidores problemáticos un poco más rápido que estas unidades (decenas de milisegundos), puede ajustar la carga en el backend configurando una pequeña acumulación para recibir conexiones TCP. En este caso, puede, cuando el trabajo atrasado de la aplicación esté lleno, indicarle a Linux que lo reinicie para desbordar el trabajo atrasado. Entonces podrá disparar al backend sobrecargado "malo" un poco antes del tiempo de espera de conexión:
fail fast: listen backlog + net.ipv4.tcp_abort_on_overflow
Solicitar tiempo de espera
El tiempo de espera de la solicitud no es una característica de la red, sino una
característica de un grupo de solicitudes (manejador). Hay diferentes solicitudes: su gravedad es diferente, tienen una lógica completamente diferente en su interior, necesitan acceder a repositorios completamente diferentes.
Nginx en sí
no tiene un tiempo de espera para toda la solicitud. El tiene:
- proxy_send_timeout: tiempo entre dos operaciones de escritura exitosas write ();
- proxy_read_timeout: tiempo entre dos lecturas de lectura exitosas ().
Es decir, si tienes un backend lento, un byte de veces, da algo en un tiempo de espera, entonces todo está bien. Como tal, nginx no tiene request_timeout. Pero estamos hablando de aguas arriba. En nuestro centro de datos son controlados por nosotros, por lo tanto, suponiendo que la red no tenga loris lentos, entonces, en principio, read_timeout puede usarse como request_timeout.
El enviado lo tiene todo: tiempo de espera || per_try_timeout.
Seleccionar solicitud de tiempo de espera
Ahora, lo más importante, en mi opinión, es qué request_timeout poner. Procedemos de cuánto está permitido que el usuario espere; este es un cierto máximo. Está claro que el usuario no esperará más de 10 s, por lo que debe responderle más rápido.
- Si queremos manejar la falla de un solo servidor, entonces el tiempo de espera debe ser menor que el tiempo de espera máximo permitido: request_timeout <max.
- Si desea tener 2 intentos garantizados para enviar una solicitud a dos backends diferentes, el tiempo de espera para un intento es igual a la mitad de este intervalo permitido: per_try_timeout = 0.5 * max.
- También hay una opción intermedia: 2 intentos optimistas en caso de que el primer backend se haya "embotado", pero el segundo responderá rápidamente: per_try_timeout = k * max (donde k> 0.5).
Existen diferentes enfoques, pero en general,
elegir un tiempo de espera es difícil . Siempre habrá casos límite, por ejemplo, el mismo controlador en el 99% de los casos se procesa en 10 ms, pero hay un 1% de los casos cuando esperamos 500 ms, y esto es normal. Esto tendrá que ser resuelto.
Con este 1%, es necesario hacer algo, porque todo el grupo de solicitudes debe, por ejemplo, cumplir con el SLA y ajustarse en 100 ms. Muy a menudo en estos momentos se procesa la solicitud:
- La paginación aparece en aquellos lugares donde es imposible devolver todos los datos en un tiempo de espera.
- El administrador / informes se separan en un grupo separado de URL para aumentar el tiempo de espera para ellos, y sí para reducir las solicitudes de los usuarios.
- Reparamos / optimizamos aquellas solicitudes que no se ajustan a nuestro tiempo de espera.
Inmediatamente, debemos tomar una decisión que no sea muy simple desde el punto de vista psicológico de que si no tenemos tiempo para responder al usuario en el tiempo asignado, damos un error (es como en un antiguo dicho chino: "Si la yegua está muerta, ¡bájese!")
.Después de eso, el proceso de monitoreo de su servicio desde el punto de vista del usuario se simplifica:
- Si hay errores, todo está mal, necesita ser reparado.
- Si no hay errores, encajamos en el tiempo de respuesta correcto, entonces todo está bien.
Reintentos especulativos # nifig
Nos aseguramos de que elegir un valor de tiempo de espera sea bastante difícil. Como sabes, para simplificar algo, necesitas complicar algo :)
Retraso especulativo : una solicitud repetida a otro servidor, que se inicia por alguna condición, pero la primera solicitud no se interrumpe. Tomamos la respuesta del servidor que respondió más rápido.
No vi esta característica en equilibradores que conozco, pero hay un excelente ejemplo con Cassandra (protección de lectura rápida):
speculative_retry = N ms |
Percentil MDe esta manera
no tienes
que esperar . Puede dejarlo en un nivel aceptable y, en cualquier caso, tener un segundo intento de obtener una respuesta a la solicitud.
Cassandra tiene una oportunidad interesante para establecer un intento especulativo estático o dinámico, luego el segundo intento se realizará a través del percentil del tiempo de respuesta. Cassandra acumula estadísticas sobre los tiempos de respuesta de solicitudes anteriores y adapta un valor de tiempo de espera específico. Esto funciona bastante bien.
En este enfoque, todo se basa en el equilibrio entre la confiabilidad y la carga espuria. No los servidores. Usted brinda confiabilidad, pero a veces recibe solicitudes adicionales al servidor. Si tenía prisa en algún lugar y envió una segunda solicitud, pero la primera aún respondió, el servidor recibió un poco más de carga. En un solo caso, este es un pequeño problema.

La coherencia del tiempo de espera es otro aspecto importante. Hablaremos más sobre la cancelación de la solicitud, pero en general, si el tiempo de espera para toda la solicitud del usuario es de 100 ms, entonces no tiene sentido establecer el tiempo de espera para la solicitud en la base de datos durante 1 s. Hay sistemas que le permiten hacer esto dinámicamente: el servicio a servicio transfiere el resto del tiempo que esperará una respuesta a esta solicitud. Es complicado, pero si de repente lo necesita, puede descubrir fácilmente cómo hacerlo en el mismo Enviado.
¿Qué más necesitas saber sobre el reintento?
Punto de no retorno (V1)
Aquí V1 no es la versión 1. En la aviación existe ese concepto: velocidad V1. Esta es la velocidad después de la cual es imposible reducir la velocidad de aceleración en la pista. Es necesario despegar y luego tomar una decisión sobre qué hacer a continuación.
El mismo punto de no retorno se encuentra en los equilibradores de carga:
cuando pasa 1 byte de la respuesta a su cliente, no se pueden corregir los errores . Si el backend muere en este punto, ningún reintento ayudará. Solo puede reducir la probabilidad de que se desencadene un escenario de este tipo, hacer un cierre elegante, es decir, decirle a su aplicación: "¡No acepta nuevas solicitudes ahora, pero modifica las antiguas!", Y solo luego extingue.
Si controla al cliente, esta es una aplicación móvil o Ajax complicada, puede intentar repetir la solicitud y luego puede salir de esta situación.
Punto de No Retorno [Enviado]
El enviado tenía un truco tan extraño. Hay per_try_timeout: limita cuánto puede tomar cada intento de obtener una respuesta a una solicitud. Si este tiempo de espera funcionó, pero el backend ya comenzó a responder al cliente, entonces todo se interrumpió, el cliente recibió un error.
Mi colega Pavel Trukhanov (
tru_pablo ) hizo un
parche , que ya está en Master Envoy y estará en 1.7. Ahora funciona como debería: si la respuesta ha comenzado a transmitirse, solo funcionará el tiempo de espera global.
Reintentos: es necesario limitar
Los reintentos son buenos, pero existen las llamadas solicitudes asesinas: las consultas pesadas que realizan una lógica muy compleja acceden mucho a la base de datos y a menudo no se ajustan a per_try_timeout. Si enviamos reintentos una y otra vez, entonces matamos nuestra base. Porque
en la mayoría de los servicios de bases de datos (99.9%) no hay cancelación de solicitud .
La cancelación de la solicitud significa que el cliente se ha desenganchado, debe detener todo el trabajo en este momento. Golang está promoviendo activamente este enfoque, pero desafortunadamente termina con un back-end, y muchos repositorios de bases de datos no lo admiten.
En consecuencia, los reintentos deben ser limitados, lo que permite casi todos los equilibradores (de ahora en adelante, dejamos de considerar HAProxy).
Nginx:- proxy_next_upstream_timeout (global)
- proxt_read_timeout ** como per_try_timeout
- proxy_next_upstream_tries
Enviado- tiempo de espera (global)
- per_try_timeout
- num_retries
En Nginx, podemos decir que estamos tratando de hacer reintentos en toda la ventana X, es decir, en un intervalo de tiempo dado, por ejemplo, 500 ms, hacemos tantos reintentos como sea conveniente. O hay una configuración que limita el número de muestras repetidas. En
Envoy , lo mismo es cantidad o tiempo de espera (global).
Reintentos: aplicar [nginx]
Considere un ejemplo: establecemos intentos de reintento en nginx 2; en consecuencia, después de recibir HTTP 503, intentamos enviar una solicitud al servidor nuevamente. Luego apague los
dos backends.
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; proxy_next_upstream error timeout http_503; proxy_next_upstream_tries 2; location / { proxy_pass http://backends; } }
A continuación se muestran los gráficos de nuestro banco de pruebas. No hay errores en el gráfico superior, porque hay muy pocos de ellos. Si deja solo errores, está claro que lo son.
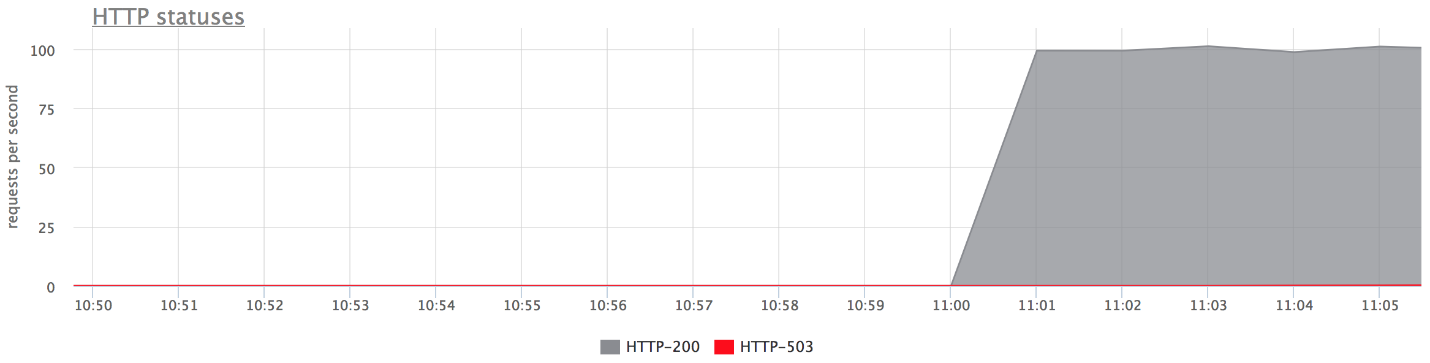
 Que paso
Que paso- proxy_next_upstream_tries = 2.
- En el caso de que haga el primer intento al servidor "muerto", y el segundo al otro "muerto", obtendrá HTTP-503 en caso de que ambos intentos lleguen al servidor "malo".
- Hay pocos errores, ya que nginx "prohíbe" un servidor defectuoso. Es decir, si en nginx han regresado algunos errores del backend, deja de hacer los siguientes intentos de enviarle una solicitud. Esto se rige por la variable fail_timeout.
Pero hay errores, y esto no nos conviene.
¿Qué hacer al respecto?Podemos aumentar el número de reintentos (pero luego volver al problema de las "solicitudes asesinas"), o podemos reducir la probabilidad de que una solicitud llegue a backends "muertos". Esto se puede hacer con
controles de salud.Controles de salud
Sugiero considerar las comprobaciones de estado como una optimización del proceso de elección de un servidor "en vivo".
Esto de ninguna manera da ninguna garantía. En consecuencia, durante la ejecución de una solicitud de usuario, es más probable que accedamos solo a servidores "en vivo". El equilibrador accede regularmente a una URL específica, el servidor le responde: "Estoy vivo y listo".
Verificaciones de salud: en términos de backend
Desde el punto de vista del backend, puedes hacer cosas interesantes:
- Compruebe la disponibilidad para el funcionamiento de todos los subsistemas subyacentes de los que depende la operación de back-end: se establece el número necesario de conexiones a la base de datos, el grupo tiene conexiones libres, etc., etc.
- Puede colgar su propia lógica en la URL de comprobaciones de estado si el equilibrador utilizado no es muy inteligente (por ejemplo, toma el equilibrador de carga del host). El servidor puede recordar que "en el último minuto cometí tantos errores, probablemente soy una especie de servidor" incorrecto "y durante los próximos 2 minutos responderé con" quinientos "a las comprobaciones de estado. ¡Así me prohibiré! " Esto a veces ayuda mucho cuando tienes un Load Balancer no controlado.
- Por lo general, el intervalo de verificación es de aproximadamente un segundo, y necesita el controlador de verificación de estado para no matar su servidor. Debería ser ligero.
Comprobaciones de estado: implementaciones
Como regla general, todo aquí es igual para todos:
- Solicitud;
- Tiempo de espera en él;
- Intervalo a través del cual hacemos verificaciones. Los proxies engañados tienen jitter , es decir, algo de aleatorización para que todos los controles de salud no lleguen al backend a la vez y no lo maten.
- Umbral no saludable : el umbral de cuántas comprobaciones de salud fallidas deben pasar para que el servicio lo marque como no saludable.
- Umbral saludable : por el contrario, cuántos intentos exitosos deben pasar para que el servidor vuelva a funcionar.
- Lógica adicional Puede analizar Verificar estado + cuerpo, etc.
Nginx implementa funciones de comprobación de estado solo en la versión paga de nginx +.
Observo una característica de
Envoy , tiene un
modo de pánico de comprobación de estado
. Cuando prohibimos, como "insalubres", más del N% de los hosts (por ejemplo, el 70%), él cree que todos nuestros controles de salud están mintiendo y que todos los hosts están realmente vivos. En un caso muy malo, esto lo ayudará a no encontrarse con una situación en la que usted mismo le disparó a su pierna y prohibió todos los servidores. Esta es una manera de estar seguro nuevamente.
Poniendo todo junto
Por lo general, para los controles de salud establecidos:
- O nginx +;
- O nginx + algo más :)
En nuestro país, existe una tendencia a establecer nginx + HAProxy, porque la versión gratuita de nginx no tiene controles de salud, y hasta 1.11.5 no había límite en el número de conexiones al backend. Pero esta opción es mala porque HAProxy no sabe cómo retirarse después de establecer una conexión. Mucha gente piensa que si HAProxy devuelve un error en nginx y nginx reintentos, entonces todo estará bien. En realidad no Puede acceder a otro HAProxy y al mismo backend, porque los grupos de backend son los mismos. Entonces, introduce un nivel más de abstracción para usted, lo que reduce la precisión de su equilibrio y, en consecuencia, la disponibilidad del servicio.
Tenemos nginx + Envoy, pero si te confundes, puedes limitarte solo a Envoy.
¿Qué tipo de enviado?
Envoy es un equilibrador de carga juvenil moderno, desarrollado originalmente en Lyft, escrito en C ++.
Fuera de la caja, puede hacer un montón de bollos sobre nuestro tema hoy. Probablemente lo viste como una malla de servicio para Kubernetes. Como regla, Envoy actúa como un plano de datos, es decir, equilibra directamente el tráfico, y también hay un plano de control que proporciona información sobre lo que necesita para distribuir la carga (descubrimiento de servicio, etc.).
Te diré algunas palabras sobre sus bollos.
Para aumentar la probabilidad de una respuesta de reintento exitosa la próxima vez que lo intente, puede dormir un poco y esperar a que los backends recuperen sus sentidos. De esta manera manejaremos problemas cortos de la base de datos. Enviado tiene un
retraso para los reintentos : pausas entre reintentos. Además, el intervalo de retraso entre intentos aumenta exponencialmente. El primer reintento ocurre después de 0-24 ms, el segundo después de 0-74 ms, y luego, para cada intento posterior, el intervalo aumenta, y el retraso específico se selecciona aleatoriamente de este intervalo.
El segundo enfoque no es específico del Enviado, sino un patrón llamado
Interrupción de circuito (encendido, interruptor de circuito o fusible). Cuando nuestro backend se embota, de hecho tratamos de terminarlo cada vez. Esto se debe a que los usuarios en cualquier situación incomprensible hacen clic en la página de actualización y le envían más y más solicitudes nuevas. Sus equilibradores se ponen nerviosos, envían reintentos, aumenta el número de solicitudes: la carga está creciendo y, en esta situación, sería bueno no enviar solicitudes.
El interruptor de circuito simplemente le permite determinar que estamos en este estado, disparar rápidamente el error y darles a los backends "recuperar el aliento".
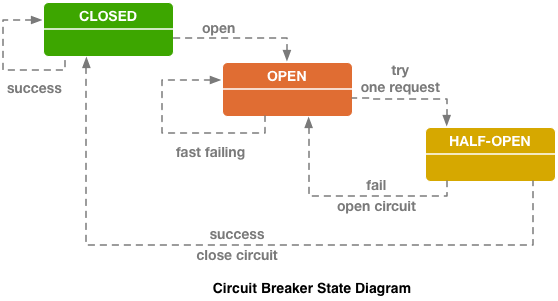 Disyuntor (hystrix como libs), original en el blog de eBay.
Disyuntor (hystrix como libs), original en el blog de eBay.Arriba está el circuito del disyuntor Hystrix. Hystrix es la biblioteca Java de Netflix que está diseñada para implementar patrones de tolerancia a fallas.
- El "fusible" puede estar en el estado "cerrado" cuando todas las solicitudes se envían al backend y no hay errores.
- Cuando se activa un cierto umbral de falla, es decir, se han producido algunos errores, el disyuntor entra en el estado "Abierto". Devuelve rápidamente un error al cliente y las solicitudes no llegan al backend.
- Una vez en un cierto período de tiempo, todavía se envía una pequeña parte de las solicitudes al backend. Si se dispara un error, el estado permanece "Abierto". Si todo comienza a funcionar bien y responde, el "fusible" se cierra y el trabajo continúa.
En Enviado, como tal, esto no es todo. Existen límites de nivel superior en el hecho de que no puede haber más de N solicitudes para un grupo ascendente específico. Si hay más, algo está mal aquí: devolvemos un error. No puede haber más N reintentos activos (es decir, reintentos que están ocurriendo en este momento).
No tuvo reintentos, algo explotó: envíe reintentos. Envoy entiende que más de N es anormal, y todas las solicitudes deben ser disparadas con un error.
Interrupción de circuito [Enviado]- Conexiones máximas de clúster (grupo ascendente)
- Cluster max solicitudes pendientes
- Solicitudes máximas de clúster
- Cluster max reintentos activos
Esta cosa simple funciona bien, es configurable, no tiene que presentar parámetros especiales y la configuración predeterminada es bastante buena.
Disyuntor: nuestra experiencia
Solíamos tener un recopilador de métricas HTTP, es decir, los agentes instalados en los servidores de nuestros clientes enviaban métricas a nuestra nube a través de HTTP. Si tenemos algún problema en la infraestructura, el agente escribe las métricas en su disco y luego trata de enviárnoslas.
Y los agentes constantemente intentan enviarnos datos, no están molestos porque de alguna manera respondemos incorrectamente y no nos vamos.
( , ) , , .
nginx limit req. , , , 200 RPS. , , , limit req.
TCP HTTP ( nginx limit req). . limit req .
, , .
Circuit breaker, , N , , - , , . , , spool .
Circuit breaker + request cancellation ( ). , N Cassandra, N Elastic, , — , . — , .
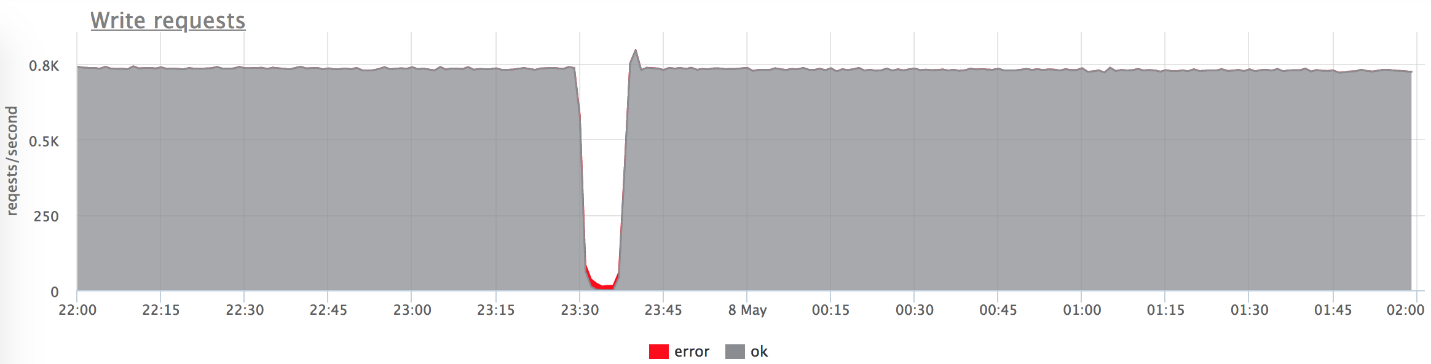
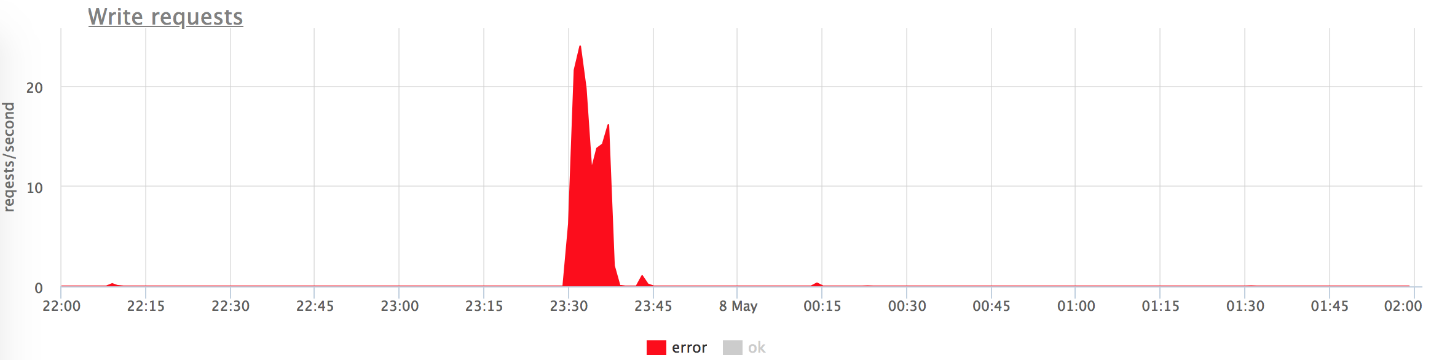
, (: — «», — «»). , 800 RPS 20-30. «», , .
— , .
, , — . .
, , , , Health checks — HTTP 200.
.
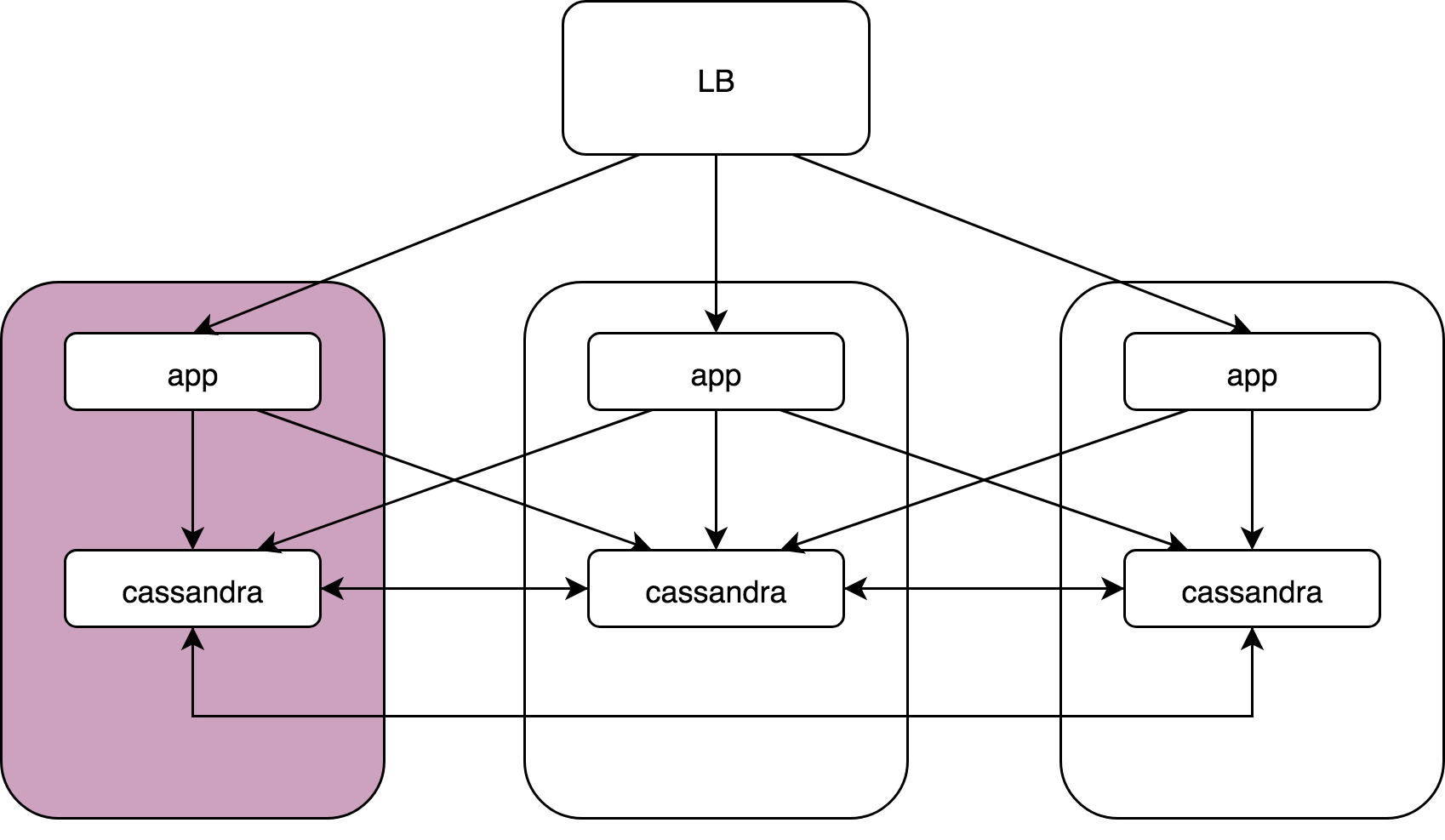
Load Balancer, 3 , Cassandra. Cassandra, Cassandra , Cassandra data noda.
— :
kernel: NETDEV WATCHDOG: eth0 (ixgbe): transmit queue 3 timed out.: ( ), 64 . , 1/64 . reboot, .
, , , . , , , . , , . , .
Cassandra: coordinator -> nodesCassandra, (speculative retries), . latency 99 , .
App -> cassandra coordinator. Cassandra «» , , , latency ..
gocql — cassandra client. . HostSelectionPolicy,
bitly/go-hostpool . Epsilon greedy , .
,
Epsilon-greedy .
(multi-armed bandit): , , N .
:
- « explore» — : 10 , , .
- « exploit» — .
, (10 — 30%)
round -
robin , , , . 70 — 90% .
Host-pool . . ( — , , ). . , , , .
«» () —Cassandra Cassandra coordinator-data. (nginx, Envoy — ) «» Application, Cassandra , , .
Envoy
Outlier detection :
- Consecutive http-5xx.
- Consecutive gateway errors (502,503,504).
- Success rate.
«» , - , . , . — , , . , , .
, «», max_ejection_percent. , outlier, . , 70% — , — , !
, — !
, , . , latency , :
,
, . , , , — , .
. 99% nginx/
HAProxy /Envoy. proxy , «».
proxy ( HAProxy:)),
, .DevOpsConf Russia Kubernetes . .
, — DevOps.
, , YouTube- — .