System.IO.Pipelines es una nueva biblioteca que simplifica la organización del código en .NET. Es difícil garantizar un alto rendimiento y precisión si tiene que lidiar con un código complejo. La tarea de System.IO.Pipelines es simplificar el código. Más detalles debajo del corte!

La biblioteca surgió como resultado de los esfuerzos del equipo de desarrollo de .NET Core para hacer de Kestrel uno de
los servidores web más rápidos de la industria . Originalmente fue concebido como parte de la implementación de Kestrel, pero se ha convertido en una API reutilizable, disponible en la versión 2.1 como una API BCL de primera clase (System.IO.Pipelines).
¿Qué problemas resuelve ella?
Para analizar adecuadamente los datos de una secuencia o socket, debe escribir una gran cantidad de código estándar. Al mismo tiempo, hay muchas trampas que complican el código en sí y su soporte.
¿Qué dificultades surgen hoy?
Comencemos con una tarea simple. Necesitamos escribir un servidor TCP que reciba mensajes delimitados por línea (\ n) del cliente.
Servidor TCP con NetworkStream
DESVIACIÓN: como en cualquier tarea que requiera un alto rendimiento, cada caso específico debe considerarse en función de las características de su aplicación. Puede que no tenga sentido gastar recursos en el uso de varios enfoques, que se discutirán más adelante, si la escala de la aplicación de red no es muy grande.
El código .NET normal antes de usar tuberías se parece a esto:
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; await stream.ReadAsync(buffer, 0, buffer.Length);
ver
sample1.cs en
githubEste código probablemente funcionará con pruebas locales, pero tiene varios errores:
- Quizás después de una sola llamada a ReadAsync, no se reciba el mensaje completo (hasta el final de la línea).
- Ignora el resultado del método stream.ReadAsync (): la cantidad de datos realmente transferidos al búfer.
- El código no maneja la recepción de varias líneas en una sola llamada ReadAsync.
Estos son los errores de lectura de datos de transmisión más comunes. Para evitarlos, debe realizar una serie de cambios:
- Necesita almacenar en búfer los datos entrantes hasta que se encuentre una nueva línea.
- Es necesario analizar todas las líneas devueltas al búfer.
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; var bytesBuffered = 0; var bytesConsumed = 0; while (true) { var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, buffer.Length - bytesBuffered); if (bytesRead == 0) {
ver
sample2.cs en
githubRepito: esto podría funcionar con pruebas locales, pero a veces hay cadenas de más de 1 Kb (1024 bytes). Es necesario aumentar el tamaño del búfer de entrada hasta que se encuentre una nueva línea.
Además, recopilamos buffers en una matriz cuando procesamos cadenas largas. Podemos mejorar este proceso con ArrayPool, que evita la reasignación de buffers durante el análisis de largas colas desde el cliente.
async Task ProcessLinesAsync(NetworkStream stream) { byte[] buffer = ArrayPool<byte>.Shared.Rent(1024); var bytesBuffered = 0; var bytesConsumed = 0; while (true) {
ver sample3.cs en githubEl código funciona, pero ahora el tamaño del búfer ha cambiado, como resultado, aparecen muchas copias. También se usa más memoria, ya que la lógica no reduce el búfer después de procesar las líneas. Para evitar esto, puede guardar la lista de búferes, en lugar de cambiar el tamaño del búfer cada vez que una cadena llega a más de 1 Kb.
Además, no aumentamos el tamaño del búfer de 1 KB, hasta que esté completamente vacío. Esto significa que transferiremos memorias intermedias cada vez más pequeñas a ReadAsync, como resultado, aumentará la cantidad de llamadas al sistema operativo.
Intentaremos eliminar esto y asignaremos un nuevo buffer tan pronto como el tamaño del existente sea menor a 512 bytes:
public class BufferSegment { public byte[] Buffer { get; set; } public int Count { get; set; } public int Remaining => Buffer.Length - Count; } async Task ProcessLinesAsync(NetworkStream stream) { const int minimumBufferSize = 512; var segments = new List<BufferSegment>(); var bytesConsumed = 0; var bytesConsumedBufferIndex = 0; var segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) }; segments.Add(segment); while (true) {
ver sample4.cs en githubComo resultado, el código es significativamente complicado. Durante la búsqueda del delimitador, rastreamos los buffers llenos. Para hacer esto, use una Lista, que muestra datos almacenados en el búfer cuando busca un nuevo separador de línea. Como resultado, ProcessLine e IndexOf aceptarán List en lugar de byte [], offset y count. La lógica de análisis comenzará a procesar un segmento del búfer o varios.
Y ahora el servidor procesará mensajes parciales y usará la memoria compartida para reducir el consumo general de memoria. Sin embargo, se deben realizar varios cambios:
- Desde ArrayPoolbyte utilizamos solo Byte []: matrices administradas de manera estándar. En otras palabras, cuando se ejecutan las funciones ReadAsync o WriteAsync, el período de validez de los buffers está vinculado al tiempo de la operación asincrónica (para interactuar con las API de E / S propias del sistema operativo). Dado que la memoria anclada no se puede mover, esto afecta el rendimiento del recolector de basura y puede causar la fragmentación de la matriz. Es posible que deba cambiar la implementación del grupo, dependiendo de cuánto tiempo esperarán las operaciones asincrónicas para su ejecución.
- El rendimiento puede mejorarse rompiendo el vínculo entre la lectura y la lógica del proceso. Obtenemos el efecto del procesamiento por lotes, y ahora la lógica de análisis podrá leer grandes cantidades de datos, procesando grandes bloques de memorias intermedias, en lugar de analizar líneas individuales. Como resultado, el código se vuelve aún más complicado:
- Es necesario crear dos ciclos que funcionen independientemente uno del otro. El primero leerá los datos del socket y el segundo analizará los buffers.
- Lo que se necesita es una forma de decirle a la lógica de análisis que los datos están disponibles.
- También es necesario determinar qué sucede si el ciclo lee los datos del socket demasiado rápido. Necesitamos una forma de ajustar el ciclo de lectura si la lógica de análisis no lo mantiene. Esto se conoce comúnmente como "control de flujo" o "resistencia de flujo".
- Debemos asegurarnos de que los datos se transmitan de forma segura. Ahora, tanto el ciclo de lectura como el ciclo de análisis utilizan el conjunto de buffers; funcionan de forma independiente entre sí en diferentes subprocesos.
- La lógica de administración de memoria también está involucrada en dos partes diferentes de código: tomar prestados datos del grupo de búferes, que lee los datos del socket, y regresar del grupo de búferes, que es la lógica de análisis.
- Hay que tener mucho cuidado al devolver los buffers después de ejecutar la lógica de análisis. De lo contrario, existe la posibilidad de que devolvamos el búfer en el que todavía se está escribiendo la lógica de lectura del socket.
La complejidad comienza a ir por las nubes (¡y esto está lejos de todos los casos!). Para crear una red de alto rendimiento, debe escribir código muy complejo.
El propósito de System.IO.Pipelines es simplificar este procedimiento.
Servidor TCP y System.IO.Pipelines
Veamos cómo funciona System.IO.Pipelines:
async Task ProcessLinesAsync(Socket socket) { var pipe = new Pipe(); Task writing = FillPipeAsync(socket, pipe.Writer); Task reading = ReadPipeAsync(pipe.Reader); return Task.WhenAll(reading, writing); } async Task FillPipeAsync(Socket socket, PipeWriter writer) { const int minimumBufferSize = 512; while (true) {
ver sample5.cs en githubLa versión canalizada de nuestro lector de línea tiene dos bucles:
- FillPipeAsync lee del socket y escribe en PipeWriter.
- ReadPipeAsync lee de PipeReader y analiza las líneas entrantes.
A diferencia de los primeros ejemplos, no hay memorias intermedias asignadas especialmente. Esta es una de las principales funciones de System.IO.Pipelines. Todas las tareas de administración de búfer se transfieren a las implementaciones de PipeReader / PipeWriter.
El procedimiento se simplifica: utilizamos el código solo para la lógica empresarial, en lugar de implementar una gestión compleja del búfer.
En el primer bucle, se llama a PipeWriter.GetMemory (int) para obtener una cierta cantidad de memoria del escritor principal. Luego se llama PipeWriter.Advance (int), que le dice a PipeWriter cuántos datos se escriben realmente en el búfer. Esto es seguido por una llamada a PipeWriter.FlushAsync () para que PipeReader pueda acceder a los datos.
El segundo bucle consume los buffers que fueron escritos por PipeWriter pero originalmente recibidos del socket. Cuando se devuelve la solicitud a PipeReader.ReadAsync (), obtenemos un ReadResult que contiene dos mensajes importantes: datos leídos en el formulario ReadOnlySequence, así como el tipo de datos lógico IsCompleted, que le indica al lector si el escritor ha terminado de trabajar (EOF). Cuando se encuentra el terminador de línea (EOL) y se analiza la cadena, dividiremos el búfer en partes para omitir el fragmento que ya se ha procesado. Después de eso, se llama a PipeReader.AdvanceTo y le dice a PipeReader cuántos datos se han consumido.
Al final de cada ciclo, se completan tanto el lector como el escritor. Como resultado, el canal principal libera toda la memoria asignada.
System.io.pipelines
Lectura parcial
Además de administrar la memoria, System.IO.Pipelines realiza otra función importante: escanea los datos en el canal, pero no los consume.
PipeReader tiene dos API principales: ReadAsync y AdvanceTo. ReadAsync recibe datos del canal, AdvanceTo le dice a PipeReader que el lector ya no necesita estos búferes, por lo que puede deshacerse de ellos (por ejemplo, devolverlos al grupo de búferes principal).
El siguiente es un ejemplo de un analizador HTTP que lee datos de buffers de datos de canales parciales hasta que recibe una línea de inicio adecuada.

ReadOnlySequenceT
La implementación del canal almacena una lista de buffers relacionados pasados entre PipeWriter y PipeReader. PipeReader.ReadAsync expone ReadOnlySequence, que es un nuevo tipo de BCL y consta de uno o más segmentos ReadOnlyMemory <T>. Es similar a Span o Memory, lo que nos da la oportunidad de ver matrices y cadenas.
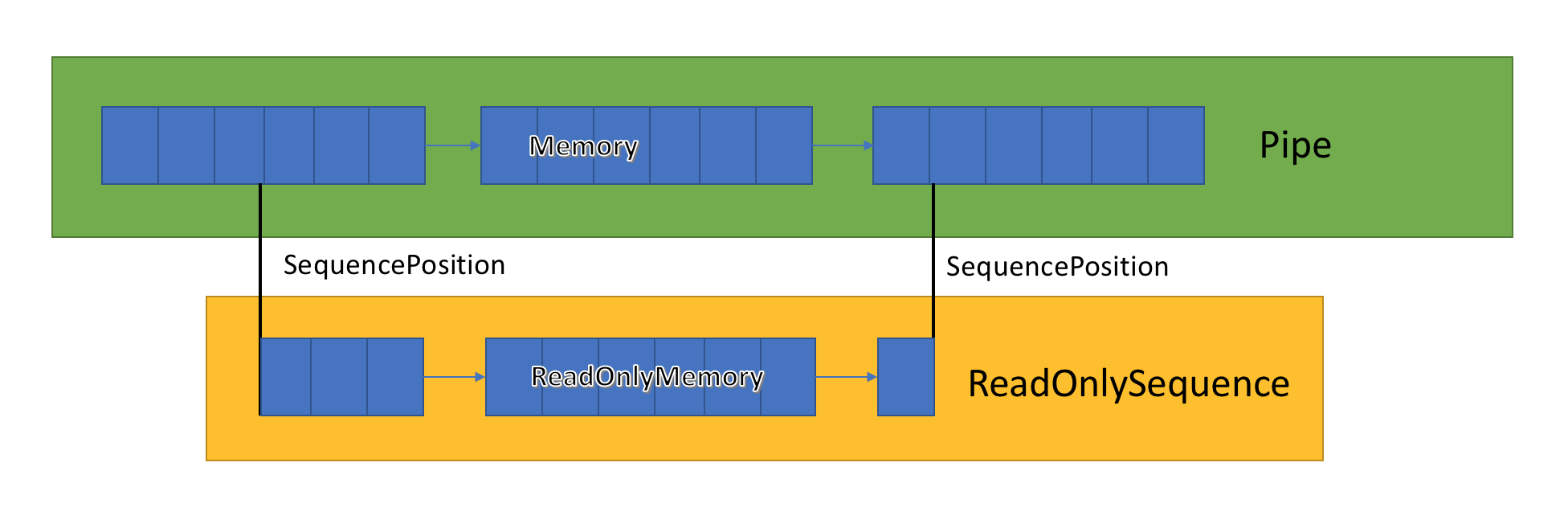
Dentro del canal hay punteros que muestran dónde se encuentran el lector y el escritor en el conjunto general de datos resaltados, y también los actualizan a medida que los datos se escriben y leen. SequencePosition es un punto único en una lista vinculada de buffers y se utiliza para separar de manera eficiente ReadOnlySequence <T>.
Dado que ReadOnlySequence <T> admite uno o más segmentos, la operación estándar de la lógica de alto rendimiento es separar rutas rápidas y lentas en función del número de segmentos.
Como ejemplo, aquí hay una función que convierte ASCII ReadOnlySequence en una cadena:
string GetAsciiString(ReadOnlySequence<byte> buffer) { if (buffer.IsSingleSegment) { return Encoding.ASCII.GetString(buffer.First.Span); } return string.Create((int)buffer.Length, buffer, (span, sequence) => { foreach (var segment in sequence) { Encoding.ASCII.GetChars(segment.Span, span); span = span.Slice(segment.Length); } }); }
ver
sample6.cs en
githubResistencia al flujo y control de flujo
Idealmente, la lectura y el análisis funcionan juntos: el flujo de lectura consume datos de la red y los coloca en buffers, mientras que el flujo de análisis crea estructuras de datos adecuadas. El análisis generalmente lleva más tiempo que simplemente copiar bloques de datos de la red. Como resultado, el flujo de lectura puede sobrecargar fácilmente el flujo de análisis. Por lo tanto, el flujo de lectura se verá obligado a reducir la velocidad o consumir más memoria para guardar datos para el flujo de análisis. Para garantizar un rendimiento óptimo, se requiere un equilibrio entre la frecuencia de pausa y la asignación de una gran cantidad de memoria.
Para resolver este problema, la tubería tiene dos funciones de control de flujo de datos: PauseWriterThreshold y ResumeWriterThreshold. PauseWriterThreshold determina cuántos datos deben almacenarse antes de que PipeWriter.FlushAsync se detenga. ResumeWriterThreshold determina cuánta memoria puede consumir el lector antes de que la grabadora reanude la operación.
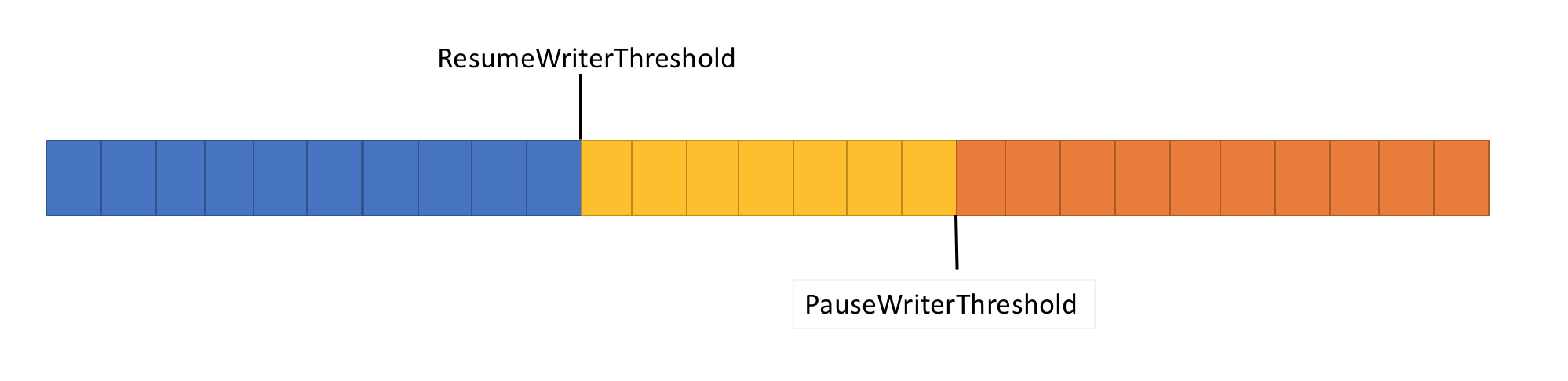
PipeWriter.FlushAsync "se bloquea" cuando la cantidad de datos en la secuencia canalizada excede el límite establecido en PauseWriterThreshold y se "desbloquea" cuando cae por debajo del límite establecido en ResumeWriterThreshold. Para evitar exceder el límite de consumo, solo se utilizan dos valores.
Programación de E / S
Cuando se usa async / await, las operaciones posteriores generalmente se llaman en los subprocesos del grupo o en el SynchronizationContext actual.
Al realizar E / S, es muy importante monitorear cuidadosamente dónde se ejecuta para hacer un mejor uso de la memoria caché del procesador. Esto es crítico para aplicaciones de alto rendimiento como servidores web. System.IO.Pipelines utiliza PipeScheduler para determinar dónde ejecutar devoluciones de llamada asincrónicas. Esto le permite controlar con mucha precisión qué secuencias utilizar para E / S.
Un ejemplo de una aplicación práctica es el transporte Kestrel Libuv, en el que las devoluciones de llamadas de E / S se realizan en canales dedicados del bucle de eventos.
Hay otros beneficios para la plantilla PipeReader.
- Algunos sistemas base admiten "esperar sin almacenamiento en búfer": no es necesario asignar un búfer hasta que los datos disponibles aparezcan en el sistema base. Entonces, en Linux con epoll, no puede proporcionar un búfer de lectura hasta que los datos estén listos. Esto evita la situación cuando hay muchos subprocesos esperando datos, y necesita reservar inmediatamente una gran cantidad de memoria.
- La canalización predeterminada facilita la escritura de pruebas unitarias de código de red: la lógica de análisis es independiente del código de red, y las pruebas unitarias solo ejecutan esta lógica en memorias intermedias en la memoria, en lugar de consumirla directamente desde la red. También facilita la prueba de patrones complejos mediante el envío de datos parciales. ASP.NET Core lo usa para probar varios aspectos de las herramientas de análisis http de Kestrel.
- Los sistemas que permiten que el código de usuario use los principales buffers del sistema operativo (por ejemplo, API de E / S de Windows registradas) son inicialmente adecuados para usar tuberías porque la implementación de PipeReader siempre proporciona buffers.
Otros tipos relacionados
También agregamos una serie de nuevos tipos de BCL simples a System.IO.Pipelines:
- MemoryPoolT , IMemoryOwnerT , MemoryManagerT . ArrayPoolT se agregó en .NET Core 1.0, y en .NET Core 2.1 ahora hay una representación abstracta más general para un grupo que funciona con cualquier MemoryT. Obtenemos un punto de extensibilidad que nos permite implementar estrategias de distribución más avanzadas, así como controlar la gestión del búfer (por ejemplo, usar búferes predefinidos en lugar de matrices administradas exclusivamente).
- IBufferWriterT es un receptor para grabar datos almacenados temporalmente sincronizados (implementado por PipeWriter).
- IValueTaskSource : ValueTaskT ha existido desde el lanzamiento de .NET Core 1.1, pero en .NET Core 2.1 ha adquirido herramientas extremadamente efectivas que proporcionan operaciones asincrónicas ininterrumpidas sin distribución. Ver aquí para más información.
¿Cómo usar transportadores?
Las API están en el paquete nuget
System.IO.Pipelines .
Para ver un ejemplo de la aplicación de servidor .NET Server 2.1 que utiliza canalizaciones para procesar mensajes en minúscula (del ejemplo anterior), consulte
aquí . Se puede iniciar usando dotnet run (o Visual Studio). En el ejemplo, se espera que los datos se transmitan desde el socket en el puerto 8087, luego los mensajes recibidos se escriben en la consola. Puede usar un cliente, como netcat o putty, para conectarse al puerto 8087. Envíe un mensaje en minúscula y vea cómo funciona.
Actualmente, la tubería se ejecuta en Kestrel y SignalR, y esperamos que encuentre una aplicación más amplia en muchas bibliotecas de red y componentes de la comunidad .NET en el futuro.