
Desde el principio, planificamos soluciones de ingeniería y productos para que Discord sea adecuado para el chat de voz mientras juegas con amigos. Estas soluciones permitieron escalar en gran medida el sistema, teniendo un equipo pequeño y recursos limitados.
Este artículo analiza las diversas tecnologías que Discord usa para chats de audio / video.
Para mayor claridad, llamaremos a todo el grupo de usuarios y canales al "grupo" (gremio); en el cliente se les llama "servidores". En cambio, el término "servidor" se refiere a nuestra infraestructura de servidores.Principios fundamentales
Cada chat de audio / video en Discord es compatible con muchos participantes. Vimos a miles de personas chatear por turnos en grandes grupos de chat. Tal soporte requiere una arquitectura cliente-servidor, porque una red punto a punto se vuelve prohibitivamente costosa con un aumento en el número de participantes.
El enrutamiento del tráfico de red a través de los servidores Discord también garantiza que su dirección IP nunca sea visible, y nadie lanzará un ataque DDoS. El enrutamiento a través de servidores tiene otras ventajas: por ejemplo, moderación. Los administradores pueden apagar rápidamente el sonido y el video a los intrusos.
Arquitectura del cliente
Discord se ejecuta en muchas plataformas.
- Web (Chrome / Firefox / Edge, etc.)
- Aplicación independiente (Windows, MacOS, Linux)
- Teléfono (iOS / Android)
Podemos admitir todas estas plataformas de una sola manera: a través de la reutilización del código
WebRTC . Esta especificación para comunicaciones en tiempo real incluye componentes de red, audio y video. El estándar es adoptado
por el Consorcio World Wide Web y el
Grupo de Ingeniería de Internet . WebRTC está disponible en todos los navegadores modernos y como una biblioteca nativa para implementación en aplicaciones.
El audio y el video en Discord se ejecutan en WebRTC. Por lo tanto, la aplicación del navegador se basa en la implementación de WebRTC en el navegador. Sin embargo, las aplicaciones para computadoras de escritorio, iOS y Android utilizan un único motor multimedia C ++ construido sobre su propia biblioteca WebRTC, que está especialmente adaptada a las necesidades de nuestros usuarios. Esto significa que algunas funciones en la aplicación funcionan mejor que en el navegador. Por ejemplo, en nuestras aplicaciones nativas podemos:
- Omitir Windows Volume Mute de forma predeterminada, cuando todas las aplicaciones se silencian automáticamente cuando se usan auriculares . Esto no es deseable cuando tú y tus amigos van a una redada y coordinan las actividades de chat de Discord.
- Use su propio control de volumen en lugar del mezclador global del sistema operativo.
- Procese los datos de audio originales para detectar la actividad de voz y transmitir audio y video en los juegos.
- Reduzca el ancho de banda de la CPU y el consumo de la CPU durante los períodos de silencio, incluso en los chats de voz más numerosos en un momento dado, solo unas pocas personas hablan al mismo tiempo.
- Proporcione funcionalidad en todo el sistema para el modo push to talk.
- Envíe junto con los paquetes de audio y video información adicional (por ejemplo, un indicador de prioridad en el chat).
Tener su propia versión de WebRTC significa actualizaciones frecuentes para todos los usuarios: este es un proceso lento que estamos tratando de automatizar. Sin embargo, este esfuerzo vale la pena gracias a las características específicas para nuestros jugadores.
En Discord, la comunicación de voz y video se inicia al ingresar un canal de voz o una llamada. Es decir, la conexión siempre es iniciada por el cliente; esto reduce la complejidad de las partes del cliente y del servidor, y también aumenta la tolerancia a errores. En caso de una falla en la infraestructura, los participantes pueden simplemente reconectarse al nuevo servidor interno.
Bajo nuestro control
El control de la biblioteca nativa le permite implementar algunas funciones de manera diferente que en la implementación del navegador de WebRTC.
Primero, WebRTC se basa en el Protocolo de descripción de sesión (
SDP ) para negociar audio / video entre los participantes (hasta 10 KB por intercambio de paquetes). En su propia biblioteca, la API de nivel inferior de WebRTC (
webrtc::Call ) se utiliza para crear ambos flujos, entrantes y salientes. Cuando se conecta a un canal de voz, hay un intercambio mínimo de información. Esta es la dirección y el puerto del servidor de fondo, el método de cifrado, las claves, el códec y la identificación del flujo (aproximadamente 1000 bytes).
webrtc::AudioSendStream* createAudioSendStream( uint32_t ssrc, uint8_t payloadType, webrtc::Transport* transport, rtc::scoped_refptr<webrtc::AudioEncoderFactory> audioEncoderFactory, webrtc::Call* call) { webrtc::AudioSendStream::Config config{transport}; config.rtp.ssrc = ssrc; config.rtp.extensions = {{"urn:ietf:params:rtp-hdrext:ssrc-audio-level", 1}}; config.encoder_factory = audioEncoderFactory; const webrtc::SdpAudioFormat kOpusFormat = {"opus", 48000, 2}; config.send_codec_spec = webrtc::AudioSendStream::Config::SendCodecSpec(payloadType, kOpusFormat); webrtc::AudioSendStream* audioStream = call->CreateAudioSendStream(config); audioStream->Start(); return audioStream; }
Además, WebRTC utiliza el Establecimiento de conectividad interactiva (
ICE ) para determinar la mejor ruta entre los participantes. Como tenemos cada cliente conectado al servidor, no necesitamos ICE. Esto le permite proporcionar una conexión mucho más confiable si está detrás de NAT, y también mantener su dirección IP en secreto de otros participantes. Los clientes hacen ping periódicamente para que el firewall mantenga una conexión abierta.
Finalmente, WebRTC utiliza el Protocolo
seguro de transporte en tiempo real (
SRTP ) para encriptar los medios. Las claves de cifrado se configuran utilizando el protocolo Datagram Transport Layer Security (
DTLS ) basado en el TLS estándar. La biblioteca incorporada de WebRTC le permite implementar su propia capa de transporte utilizando la API
webrtc::Transport .
En lugar de DTLS / SRTP, decidimos usar un
cifrado Salsa20 más
rápido . Además, no enviamos datos de audio durante períodos de silencio, una ocurrencia común, especialmente en salas de chat grandes. Esto conduce a ahorros significativos en el ancho de banda y los recursos de la CPU, sin embargo, tanto el cliente como el servidor deben estar listos en cualquier momento para dejar de recibir datos y reescribir los números de serie de los paquetes de audio / video.
Dado que la aplicación web utiliza la implementación basada en navegador de la
API WebRTC , SDP, ICE, DTLS y SRTP no se pueden abandonar. El cliente y el servidor intercambian toda la información necesaria (menos de 1200 bytes al intercambiar paquetes), y la sesión SDP se establece sobre la base de esta información para los clientes. El backend es responsable de resolver las diferencias entre las aplicaciones de escritorio y navegador.
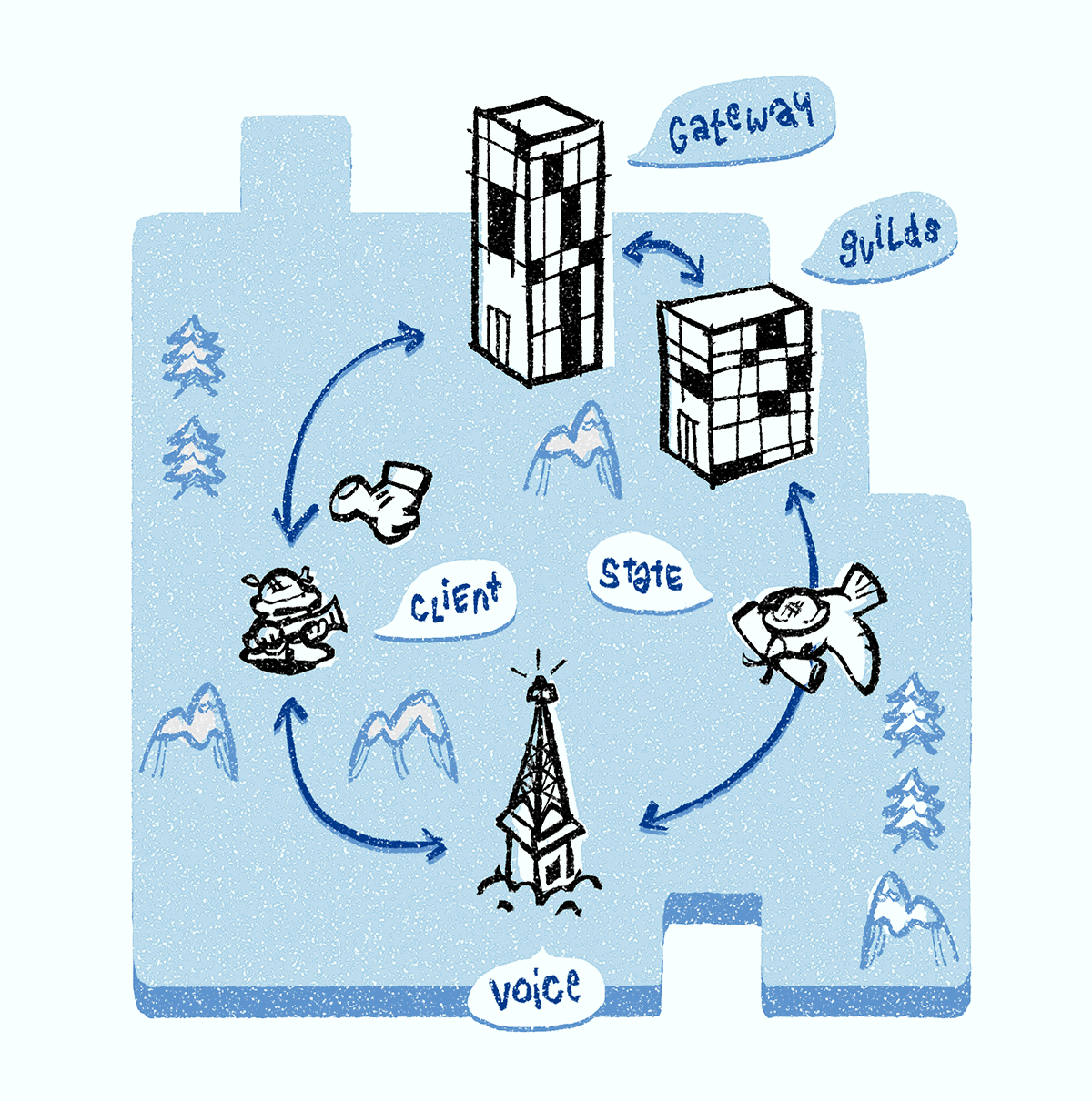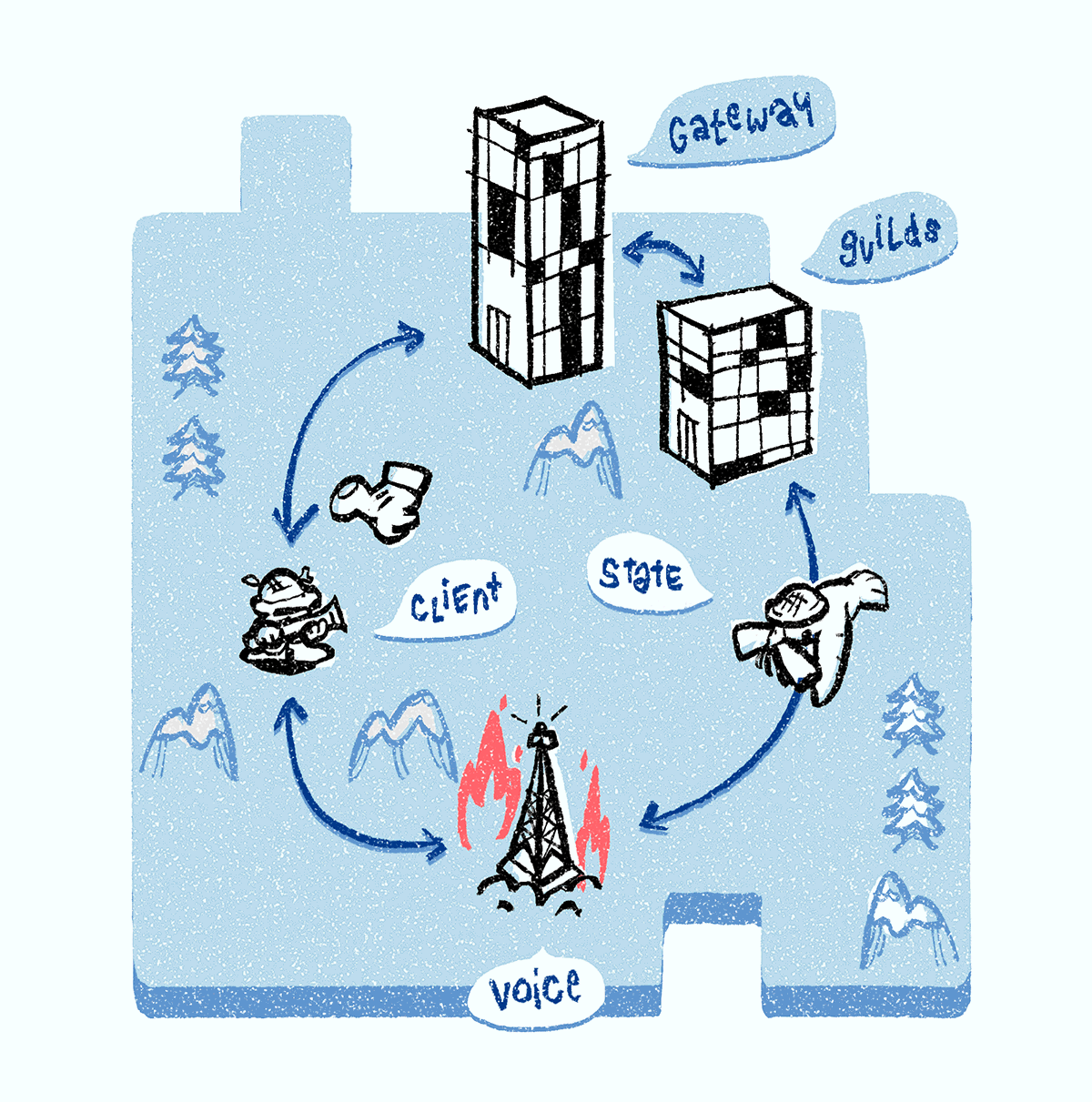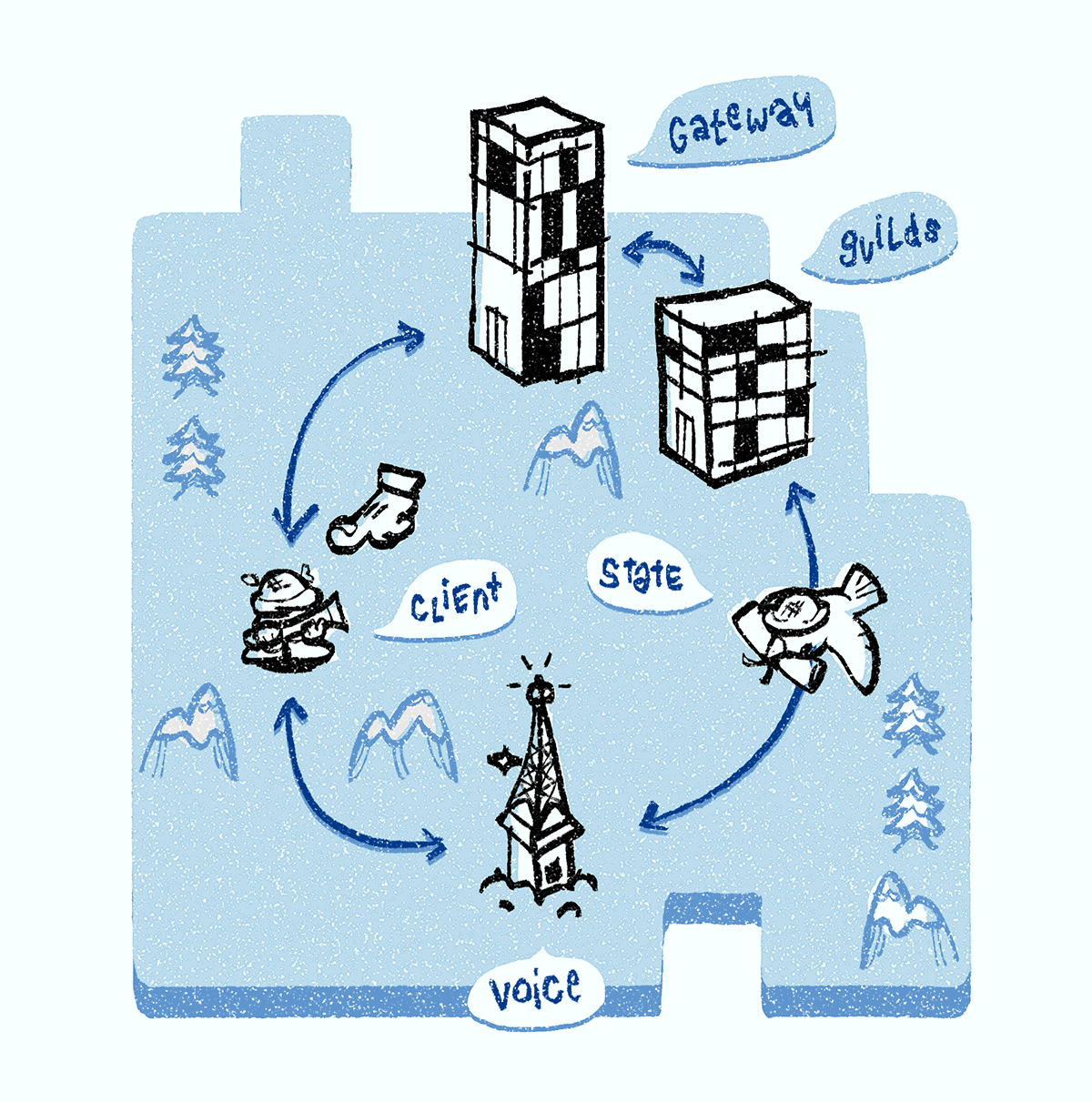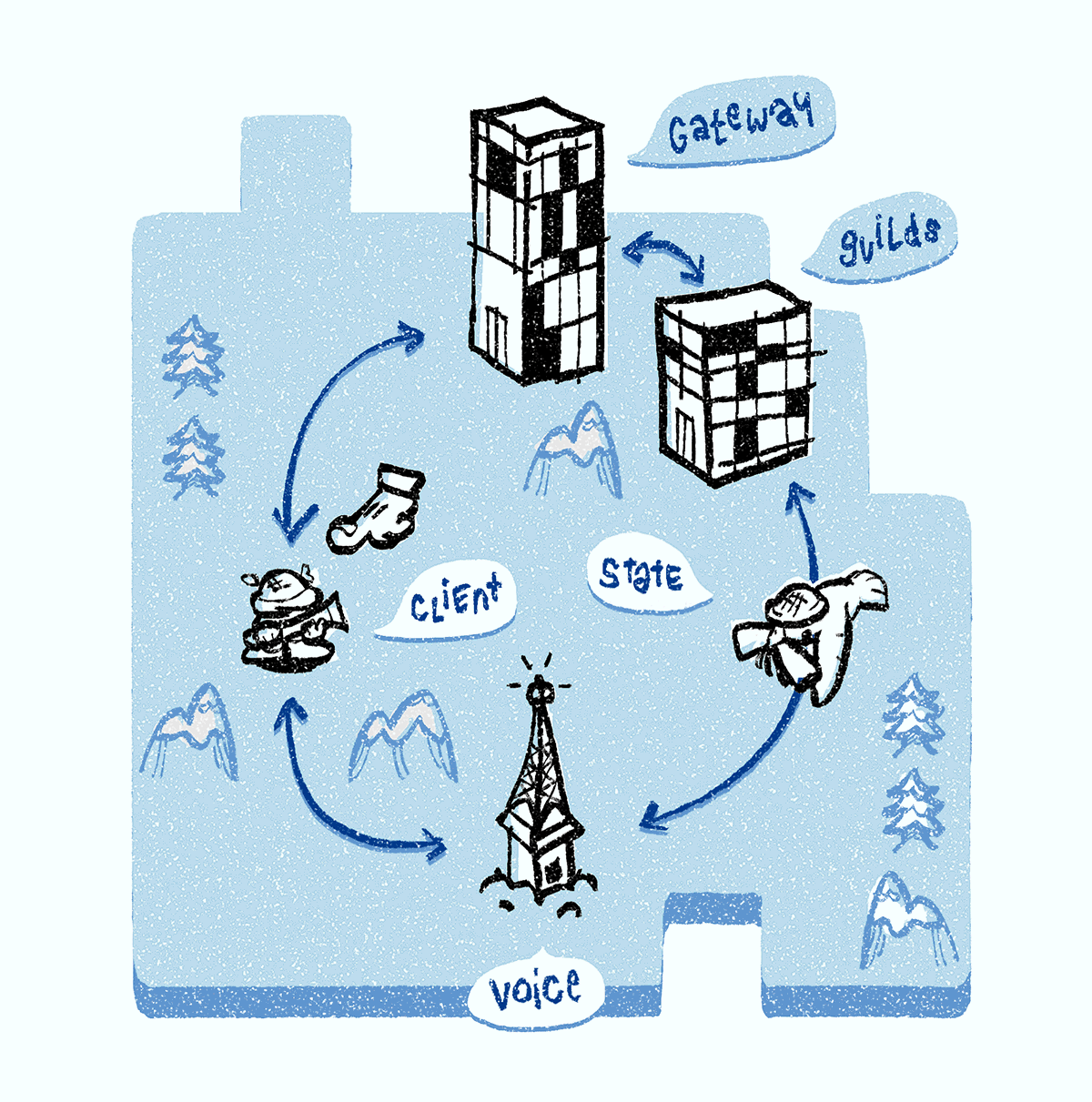
Arquitectura de backend
Hay varios servicios de chat de voz en el backend, pero nos centraremos en tres: Discord Gateway, Discord Guilds y Discord Voice. Todos nuestros servidores de señales están escritos en
Elixir , lo que nos permite reutilizar el código repetidamente.
Cuando está en línea, su cliente admite una conexión WebSocket a un Discord Gateway (lo llamamos una conexión de
portal WebSocket). A través de esta conexión, su cliente recibe eventos relacionados con grupos y canales, mensajes de texto, paquetes de presencia, etc.
Cuando se conecta a un canal de voz, el
objeto de estado de voz muestra el estado de la conexión. El cliente actualiza este objeto a través de la conexión de la puerta de enlace.
defmodule VoiceStates.VoiceState do @type t :: %{ session_id: String.t(), user_id: Number.t(), channel_id: Number.t() | nil, token: String.t() | nil, mute: boolean, deaf: boolean, self_mute: boolean, self_deaf: boolean, self_video: boolean, suppress: boolean } defstruct session_id: nil, user_id: nil, token: nil, channel_id: nil, mute: false, deaf: false, self_mute: false, self_deaf: false, self_video: false, suppress: false end
Cuando se conecta a un canal de voz, se le asigna uno de los servidores de Discord Voice. Es responsable de transmitir el sonido a cada participante en el canal. Todos los canales de voz en un grupo se asignan a un servidor. Si eres el primero en chatear, el servidor de Discord Guilds es responsable de asignar el servidor de Discord Voice a todo el grupo mediante el proceso que se describe a continuación.
Destino del servidor de voz Discord
Cada servidor de Discord Voice informa periódicamente sobre su estado y carga. Esta información se coloca en un sistema de descubrimiento de servicios (usamos
etcd ), como se discutió en un
artículo anterior .
El servidor de Discord Guilds monitorea el sistema de descubrimiento de servicios y asigna al grupo el servidor de Discord Voice menos utilizado en la región. Cuando se selecciona, todos los objetos de estado de voz (también compatibles con el servidor de Discord Guilds) se transfieren al servidor de Discord Voice para que pueda configurar el reenvío de audio / video. Los clientes son notificados del servidor de Discord Voice seleccionado. Luego, el cliente abre la
segunda conexión WebSocket con el servidor de voz (lo llamamos la conexión de
voz WebSocket), que se utiliza para configurar el reenvío multimedia y la indicación de voz.
Cuando el cliente muestra el estado
Esperando punto final , esto significa que el servidor de Discord Guilds está buscando el servidor óptimo de Discord Voice. Un mensaje de
Voice Connected indica que el cliente ha intercambiado con éxito paquetes UDP con el servidor Discord Voice seleccionado.
El servidor Discord Voice contiene dos componentes: un módulo de señal y una unidad de retransmisión multimedia, llamada unidad de reenvío selectivo (
SFU ). El módulo de señal controla completamente la SFU y es responsable de generar identificadores de flujo y claves de cifrado, redirigir indicadores de voz, etc.
Nuestra SFU (en C ++) es responsable de dirigir el tráfico de audio y video entre canales. Se desarrolla por sí solo: para nuestro caso particular, SFU proporciona el máximo rendimiento y, por lo tanto, el mayor ahorro. Cuando los moderadores violan (silencian el servidor), sus paquetes de audio no se procesan. SFU también funciona como un puente entre las aplicaciones nativas y las basadas en el navegador: implementa el transporte y el cifrado tanto para el navegador como para las aplicaciones nativas, convirtiendo paquetes durante la transmisión. Finalmente, la SFU es responsable del procesamiento del protocolo
RTCP , que se utiliza para optimizar la calidad del video. SFU recopila y procesa informes RTCP de los destinatarios, y notifica a los remitentes qué banda está disponible para la transmisión de video.
Tolerancia a fallos
Dado que solo los servidores de Discord Voice están disponibles directamente desde Internet, hablaremos de ellos.
El módulo de señal monitorea continuamente la SFU. Si se bloquea, se reinicia instantáneamente con una pausa mínima en el servicio (varios paquetes perdidos). El estado de SFU es restaurado por el módulo de señal sin ninguna interacción con el cliente. Aunque los bloqueos de SFU son poco frecuentes, utilizamos el mismo mecanismo para actualizar las SFU sin interrupciones en el servicio.
Cuando el servidor Discord Voice se bloquea, no responde al ping, y se elimina del sistema de descubrimiento de servicios. El cliente también nota un bloqueo del servidor debido a una conexión de voz WebSocket interrumpida, luego solicita el
ping del servidor de voz a través de la conexión de puerta de enlace WebSocket. El servidor de Discord Guilds confirma la falla, consulta el sistema de descubrimiento de servicios y asigna un nuevo servidor de Discord Voice al grupo. Los Discord Guilds envían todos los objetos de estado de voz al nuevo servidor de voz. Todos los clientes reciben una notificación sobre el nuevo servidor y se conectan a él para iniciar la configuración multimedia.
Muy a menudo, los servidores de Discord Voice caen bajo DDoS (vemos esto por el rápido aumento en los paquetes IP entrantes). En este caso, realizamos el mismo procedimiento que cuando el servidor falla: lo eliminamos del sistema de descubrimiento de servicios, seleccionamos un nuevo servidor, le transferimos todos los objetos de estado de comunicación de voz y notificamos a los clientes sobre el nuevo servidor. Cuando el ataque DDoS disminuye, el servidor regresa al sistema de descubrimiento de servicios.
Si el propietario del grupo decide elegir una nueva región para la votación, seguimos un procedimiento muy similar. Discord Guilds Server selecciona el mejor servidor de voz disponible en una nueva región en consulta con un sistema de descubrimiento de servicios. Luego traduce todos los objetos del estado de la comunicación de voz y notifica a los clientes sobre el nuevo servidor. Los clientes interrumpen la conexión WebSocket actual con el antiguo servidor Discord Voice y crean una nueva conexión con el nuevo servidor Discord Voice.
Escalamiento
Toda la infraestructura de Discord Gateway, Discord Guilds y Discord Voice admite escala horizontal. Discord Gateway y Discord Guilds funcionan en Google Cloud.
Tenemos más de 850 servidores de voz en 13 regiones (ubicadas en más de 30 centros de datos) en todo el mundo. Esta infraestructura proporciona una mayor redundancia en caso de fallas en los centros de datos y DDoS. Trabajamos con varios socios y utilizamos nuestros servidores físicos en sus centros de datos. Más recientemente, se ha agregado la región sudafricana. Gracias a los esfuerzos de ingeniería en las arquitecturas de cliente y servidor, Discord ahora puede servir simultáneamente a más de 2.6 millones de usuarios de chat de voz con tráfico saliente de más de 220 Gbit / sy 120 millones de paquetes por segundo.
Que sigue
Supervisamos constantemente la calidad de las comunicaciones de voz (las métricas se envían desde el lado del cliente a los servidores de fondo). En el futuro, esta información ayudará en la detección automática y la eliminación de la degradación.
Aunque lanzamos video chat y screencasts hace un año, ahora solo se pueden usar en mensajes privados. En comparación con el audio, el video requiere significativamente más potencia de CPU y ancho de banda. El desafío es equilibrar la cantidad de ancho de banda y los recursos de CPU / GPU utilizados para garantizar la mejor calidad de video, especialmente cuando un grupo de jugadores en un canal está en diferentes dispositivos.
La tecnología de
codificación de video escalable (SVC), una extensión del estándar AVC H.264 / MPEG-4, puede convertirse en una solución al problema.
Los screencasts necesitan incluso más ancho de banda que el video, debido a la mayor resolución y FPS que las cámaras web convencionales. Actualmente estamos trabajando en soporte para codificación de video basada en hardware en una aplicación de escritorio.