El tiempo se acaba y pronto no quedará casi nada de este desarrollo, pero todavía no tuve tiempo para describirlo.
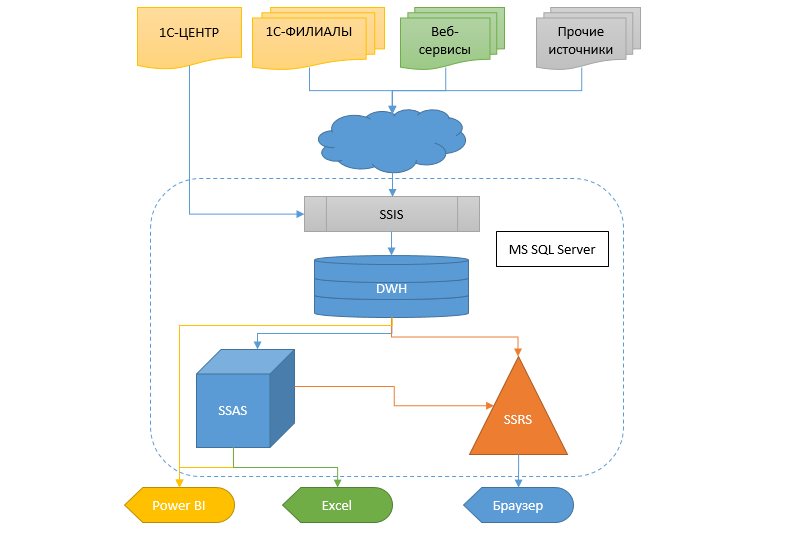
Se tratará de una empresa a nivel federal con una gran cantidad de sucursales y sub-sucursales. Pero, como de costumbre, todo comenzó hace mucho tiempo con una pequeña tienda. Con los años, se produjo un desarrollo bastante rápido y espontáneo, aparecieron sucursales, divisiones y otras oficinas, y la infraestructura de TI no recibió la debida atención en esos días, y esto también es un hecho frecuente. Por supuesto, el 1C77 se usó en todas partes, sin ninguna reserva para ninguna replicación y escala, por lo tanto, al final llegamos a la conclusión de que un Sprut-Frankenstein se generó con tentáculos atados con cinta aislante: en cada rama había un mutante autónomo que se intercambiaba con la base central. en el modo "hasta la rodilla", solo unos pocos libros de referencia, sin los cuales, bueno, era imposible en absoluto, y el resto es autónomo. Durante algún tiempo se contentaron con copias (¡docenas de ellas!) De bases de sucursales en la oficina central, pero los datos en ellas se retrasaron durante varios días.
La realidad, sin embargo, requiere obtener información de manera más rápida y flexible, y hay que hacer algo más con esto. La transferencia de un sistema contable a otro a tal escala sigue siendo un pantano. Por lo tanto, se decidió crear un almacén de datos (DX), en el que la información fluiría desde diferentes bases de datos, para que luego otros servicios y el sistema analítico en forma de cubos, informes SSRS y fugas pudieran recibir datos de este CD.
Mirando hacia el futuro, diré que la transición a un nuevo sistema de contabilidad casi ha sucedido y que la mayor parte del proyecto descrito aquí se cortará en un futuro próximo como innecesario. Lo siento, por supuesto, pero no se puede hacer nada.
El siguiente es un artículo largo, pero antes de comenzar a leer, permítanme señalar que en ningún caso apruebo esta decisión como estándar, pero tal vez alguien encuentre algo útil en ella.
Comenzaré con un enfoque general del proyecto, para el cual se eligió SSDT como entorno de desarrollo, con la posterior publicación del proyecto en Git. Creo que hoy hay suficientes artículos y tutoriales que describen los puntos fuertes de esta herramienta. Pero hay algunos puntos cuyo problema se encuentra fuera de este entorno.
Almacenamiento de enumeraciones y versiones de bases de datos.
En cuanto a las versiones y enumeraciones, los requisitos para el proyecto significaban:
- Conveniencia de editar y rastrear cambios en la versión de la base de datos dentro del proyecto
- Conveniencia de ver la versión de la base de datos a través de SSMS para administradores
- Guardar el historial de cambios de versión en la base de datos (quién y cuándo realizó la implementación)
- Almacenar enumeraciones en un proyecto
- Facilidad de edición y seguimiento de cambios en transferencias
- Bloqueo de implementación de base de datos encima de uno existente si no hubiera una versión incremental
- La instalación de una nueva versión, el historial de grabación, las transferencias y la reestructuración deben realizarse en una transacción y revertirse por completo en caso de falla en cualquier etapa
Porque las transferencias a menudo contienen lógica y son valores básicos, sin los cuales es imposible agregar registros a otras tablas (debido a las claves externas FK), en esencia son parte de la estructura de la base de datos, junto con los metadatos. Por lo tanto, un cambio en cualquier elemento de enumeración conduce a un incremento de la versión de la base de datos y, junto con esta versión, se debe garantizar que los registros se actualicen durante la implementación.
Creo que todas las ventajas de bloquear la implementación sin incrementar la versión son obvias, una de las cuales es la imposibilidad de volver a ejecutar el script de publicación si ya se ha ejecutado con éxito anteriormente.
Aunque a menudo se propone que la red para bases de datos use solo la versión principal (sin fracciones), decidimos usar versiones en el formato XY, donde Y es el parche cuando se corrigió un error tipográfico en la descripción de la tabla, columna, nombre del elemento de la lista, o algo más pequeño, como agregar un comentario a un procedimiento almacenado, etc. En todos los demás casos, la versión principal se acumula.
Quizás para alguien no hay nada de
eso y todo es obvio. Pero, a su debido tiempo, tomé bastantes nervios y energía en disputas internas sobre cómo almacenar transferencias en el proyecto de base de datos, de modo que era feng shui (
de acuerdo con mi idea ) y que era conveniente trabajar con ellos, mientras minimiza la probabilidad de errores.
Con las transferencias, en general, todo es simple: creamos un archivo PostDeploy en el proyecto y escribimos código para llenar las tablas. Con fusiones o trankates: así es como te gusta. Preferimos parpadear, verificando previamente si el número de registros en la tabla de destino excede el número de registros que están en la fuente (proyecto). Si excede, entonces se lanza una excepción para llamar la atención, porque es extraño. ¿Por qué hay menos registros en la fuente? ¿Porque uno es superfluo? ¿Por qué de repente? ¿Y si la base de datos ya tiene enlaces? Aunque utilizamos claves externas (FK), que no le permitirán eliminar el registro, si hay enlaces a él, aún preferimos dejar esta opción. Como resultado, PostDeploy se convirtió en una hoja ilegible, porque para cada tabla que se debe completar, además de los valores en sí, también hay un código de verificación, una fusión, etc.
Sin embargo, si usa PostDeploy en modo SQLCMD, es posible extraer bloques de código en archivos separados, como resultado, solo queda una lista estructurada de nombres de archivos para completar las enumeraciones en PostDeploy.
Hay algunos matices con las versiones de la base de datos. Internet ha estado debatiendo durante mucho tiempo sobre dónde almacenar la versión de la base de datos, cómo debería verse y, en general, si necesita almacenarse en algún lugar. Supongamos que decidimos que lo necesitamos, ¿en qué lugar del proyecto almacenarlo? ¿En algún lugar en la naturaleza de un script PostDeploy, o ponerlo en una variable que se declara en la primera línea del script?
En mi opinión, ni lo uno ni lo otro. Es más conveniente cuando se almacena en un archivo separado y no hay nada más allí.
Alguien dirá: hay dacpac en las propiedades del proyecto y puede configurar la versión en él. Por supuesto, incluso puede incluir esta versión en su script, como se describe
aquí , pero esto es un inconveniente: para cambiar la versión de la base de datos, debe ir a algún lugar lejos, hacer clic en un grupo de botones. No entiendo la lógica de Microsoft: la escondieron en una esquina lejana, junto con parámetros de la base de datos como clasificación, nivel de compatibilidad, etc., porque la versión de la base de datos cambia tan "a menudo" como los parámetros de clasificación, ¿verdad? Cuando hay un desarrollo constante, la versión se acumula con cada nueva implementación, y la conveniencia de realizar un seguimiento de los cambios también juega un papel importante, porque cuando se enciende un archivo modificado con un nombre descriptivo, esto es una cosa, y cuando se enciende el archivo de proyecto .sqlproj, en el que hay muchas líneas en formato XML , y entre ellos, en algún lugar del centro de la línea, se resalta un dígito modificado, de alguna manera no muy.
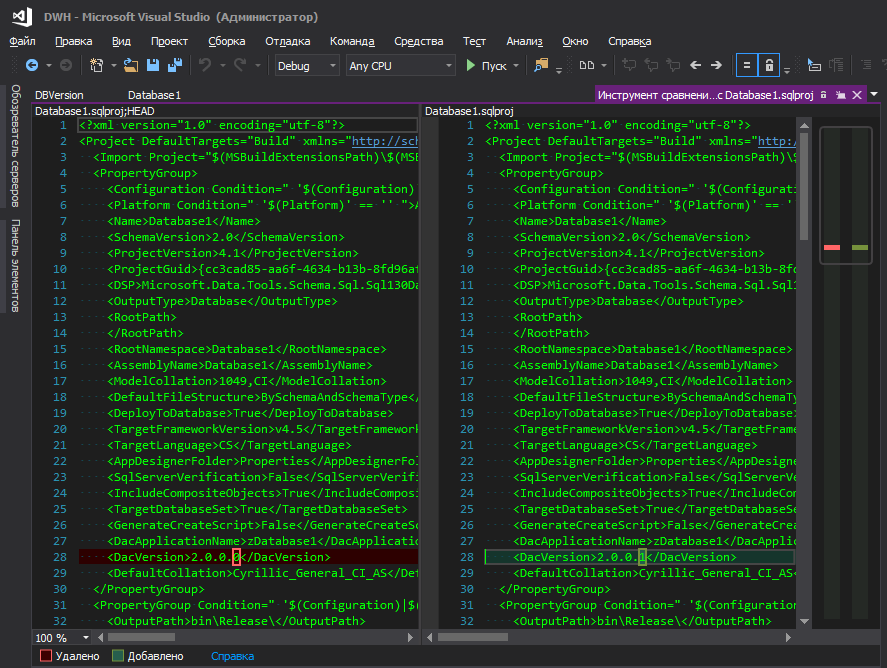
Eso es mejor
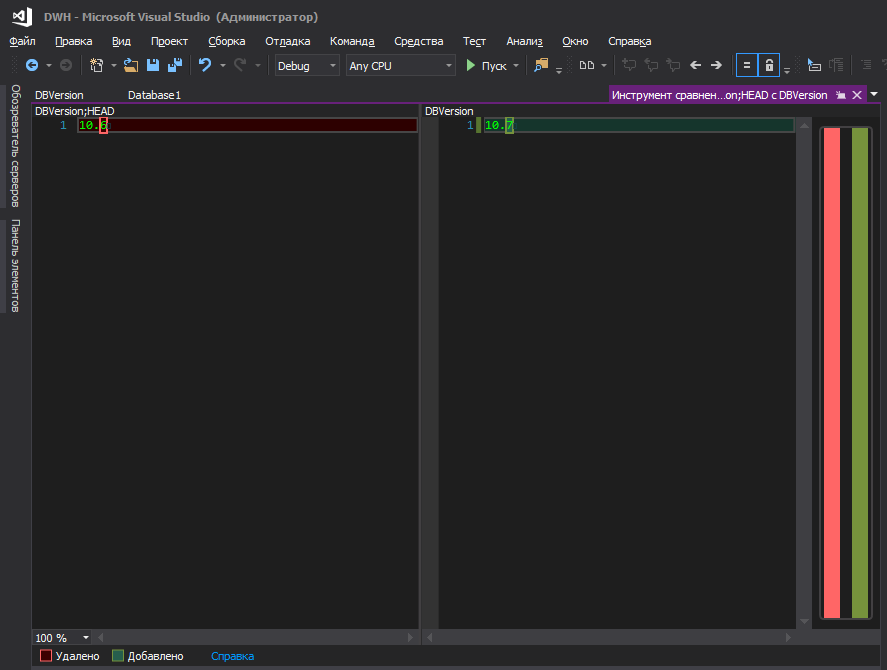
Sin embargo, tal vez estas son solo mis cucarachas y no debes prestarles atención.
Ahora la pregunta es: dónde almacenar esta versión ya en la base de datos desplegada. Nuevamente, parece que dacpac lo hace maravillosamente: escribe todo en las placas del sistema, pero para ver la versión, debe ejecutar la solicitud (¿o puede ser de otra manera, pero no sé cómo cocinarlos? Parece que en versiones anteriores de SSMS había una interfaz para esto, y ahora no)
select * from msdb.dbo.sysdac_instances_internal
para el administrador (y no solo) no es muy conveniente. Es mucho más lógico que la versión se muestre directamente en las propiedades de la base de datos.

O no?
Para hacer esto, debe agregar un archivo al proyecto, incluido en la compilación, que describa las propiedades avanzadas
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = '';
Sí, están vacíos y se ve feo en un script de publicación, pero no puedes prescindir de ellos. Si no se describen en el proyecto y estarán en la base de datos, el estudio intentará eliminarlos cada vez que se implemente. (Ha habido muchos intentos de solucionar esto de manera sucinta y sin opciones de implementación innecesarias, pero fue en vano)
Estableceremos los valores para ellos en el script PostDeploy.
declare @username varchar(256) = suser_sname() ,@curdatetime varchar(20) = format(getdate(),'dd.MM.yyyy HH:mm:ss') EXECUTE sp_updateextendedproperty @name = N'DeployerName', @value = @username; EXECUTE sp_updateextendedproperty @name = N'DBVersion', @value = [$(DBVersion)]; EXECUTE sp_updateextendedproperty @name = N'DeploymentDate', @value = @curdatetime;
sp_updateextendedproperty sin ninguna comprobación, porque para cuando se inició el bloque desde PostDeploy, todas las propiedades ya se habían creado si no estaban allí.
Bueno, sería bueno mantener el historial, sobre el tema de quién y cuándo desplegó la base de datos.
La implementación de los cambios de metadatos se puede realizar en la transacción utilizando herramientas estándar marcando la casilla
Habilitar scripts de transacción en la ventana
Opciones de publicación avanzadas . Pero este indicador no afecta a la implementación de scripts (Pre / Post) y continúan ejecutándose sin una transacción. Por supuesto, nada impide que la transacción comience al comienzo del script PostDeploy, pero será una transacción separada de los metadatos, y tenemos la tarea de revertir los cambios de metadatos si se produjo una excepción en PostDeploy.
La solución es simple: inicie la transacción en PreDeploy, y confírmela en PostDeploy, y no use ninguna marca de verificación en la configuración de publicación para estos fines.
Para almacenar convenientemente la versión de la base de datos en el proyecto y registrarla en los lugares deseados durante la implementación, puede recurrir a las variables SQLCMD. Sin embargo, no quiero almacenar la versión en algún lugar del código, quiero que esté en la superficie.
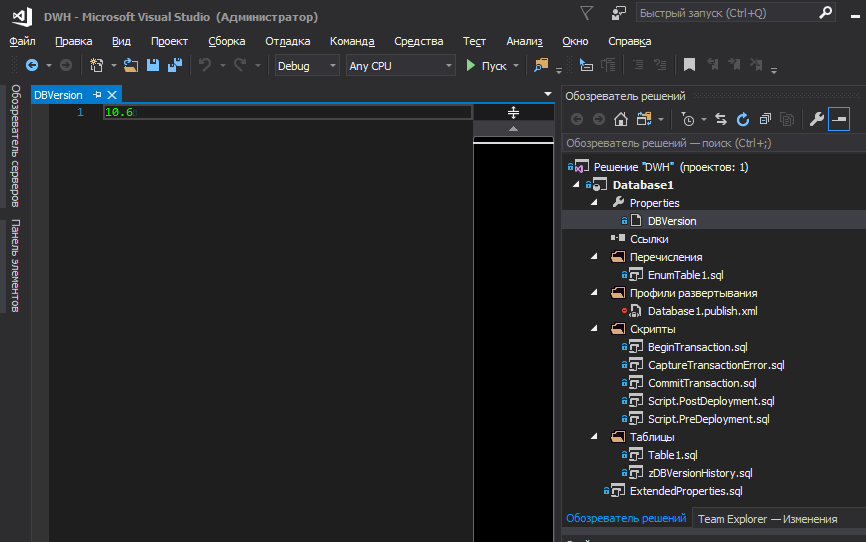
Para colocar la versión de la base de datos en un archivo separado y administrar la versión desde allí a nivel de proyecto, agregamos el siguiente bloque a .sqlproj:
<Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\Properties\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)" Overwrite="true" /> </Target> </Target>
Esta es una instrucción para que MSBuild lea una línea de un archivo antes de compilar y crear un archivo temporal basado en los datos leídos. MSBuild creará un archivo temporal
SetPreDepVarsTmp.sql , que
:setvar DBVersion $(ExtDBVersion) línea
:setvar DBVersion $(ExtDBVersion) , donde
$(ExtDBVersion) es el valor leído de nuestro archivo que almacena la versión de la base de datos.
Después de tales manipulaciones, puede consultar este archivo temporal desde el script PreDeploy e iniciar la transacción global en él:
:r .\SetPreDepVarsTmp.sql go :r ".\BeginTransaction.sql"
Versión intermediaInicialmente, al archivo ExtendedProperties.sql no se le asignaron valores vacíos, sino valores de variables
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = [$(DeployerName)]; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = [$(DeploymentDate)]; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = [$(DBVersion)];
Las variables, a su vez, fueron registradas en el archivo SetPreDepVarsTmp.sql automáticamente por MSBuild así:
<PropertyGroup> <CurrentDateTime>$([System.DateTime]::Now.ToString(dd.MM.yyyy HH:mm:ss))</CurrentDateTime> </PropertyGroup> <PropertyGroup> <NewLine> -- </NewLine> </PropertyGroup> <Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)$(NewLine):setvar DeploymentDate "$(CurrentDateTime)"$(NewLine):setvar DeploymentUser $(UserDomain)\$(UserName)" Overwrite="true" /> </Target>
Con este enfoque, no necesita reinstalar estas propiedades en PostDeploy, pero el problema es que SetPreDepVarsTmp.sql contenía valores estáticos y si el script de publicación se generó ahora, pero se implementó después de una hora, o peor aún, al día siguiente (el desarrollador lo comprobó durante mucho tiempo) visualmente, por ejemplo), la fecha de publicación especificada en las propiedades diferirá de la fecha de publicación real y no coincidirá con la fecha en el historial.
Contenido del archivo BeginTransaction.sqlEn esencia, esto es solo copiar y pegar desde el bloque de inicio de transacción estándar que el estudio genera cuando la casilla de verificación
Habilitar scripts de transacción está
seleccionada , pero la usamos a nuestra manera. En el script, solo se ha cambiado el nombre de la tabla temporal de
#tmpErrors a
#tmpErrorsManual para que no haya conflicto de nombres si alguien activa la casilla de verificación.
IF (SELECT OBJECT_ID('tempdb..#tmpErrors')) IS NOT NULL DROP TABLE
Script PostDeploy declare @TableName VarChar(255) = null
La variable SkipEnumDeploy, como ya ha quedado clara, le permite omitir la etapa de actualización de las listas; esto puede ser útil para cambios cosméticos menores. Aunque, desde el punto de vista de la religión, esto puede no ser cierto, sin embargo, definitivamente es útil en la etapa de desarrollo.
Los
CaptureTransactionError.sql y
CommitTransaction.sql también se copian y pegan (con pequeños cambios) del algoritmo de transacción estándar que el estudio genera cuando se establece el indicador anterior, y que ahora jugamos por nuestra cuenta.
Content CaptureTransactionError.sql IF @@ERROR <> 0 AND @@TRANCOUNT > 0 BEGIN ROLLBACK; END IF @@TRANCOUNT = 0 BEGIN INSERT INTO
Contenido CommitTransaction.sql Contenido EnumTable1.sql set @TableName = N'Table1' PRINT N' '+@TableName+'...' begin try set nocount on drop table if exists
Al implementar
Publish script tendrá la siguiente estructura
Idealmente, por supuesto, me gustaría que la versión se muestre al momento de la publicación

Pero no puede extraer el valor del archivo en esta ventana, aunque MSBuild lo lee y lo coloca en la propiedad ExtDBVersion con la ayuda de instrucciones adicionales en el archivo .sqlproj, como en el ejemplo anterior, pero la construcción
<SqlCmdVariable Include="DBVersion"> <DefaultValue> </DefaultValue> <Value>$(ExtDBVersion)</Value> </SqlCmdVariable>
no rueda
Los desarrolladores de secuelas en su
diario web escriben cómo se hace esto. Según su versión, la magia reside en la instrucción
SqlCommandVariableOverride , que es simple: agregue un par de líneas al archivo de proyecto .sqlproj
<ItemGroup> <SqlCommandVariableOverride Include="DBVersion=$(ExtDBVersion)" /> </ItemGroup>
y listo Buen intento, pero no. Tal vez cuando se publicó esta publicación de blog, todo funcionó, pero desde entonces en estos Estados Unidos ha tenido tres elecciones presidenciales y nadie sabe qué instrucciones pueden dejar de funcionar mañana.

Y
aquí un compañero probó todas las opciones, pero ninguna de ellas despegó.
Por lo tanto, tome la versión de dacpac o almacénela en PostDeploy, o en un archivo separado, o _________ (ingrese su versión).
Integración con 1C
El primer problema fue que 1C77 no tiene un servidor de aplicaciones u otro demonio que le permita interactuar con él sin iniciar la plataforma. Quienes trabajaron con 1C77 saben que ella no tiene un modo de consola completa. Puede ejecutar la plataforma con parámetros e incluso hacer algo basado en ellos, pero hay muy pocos parámetros de consola y su propósito era diferente. Pero incluso con su ayuda, puede nakolkhozit una cosechadora completa. Sin embargo, puede volar de manera impredecible, puede mostrar una ventana modal y esperar a que alguien haga clic en Aceptar y otros encantos. Y, tal vez, el mayor problema: la velocidad de la plataforma deja mucho que desear ... Por lo tanto, solo hay una solución: consultas directas a la base de datos 1C. Dada la estructura, no puede simplemente tomar y escribir estas consultas, sino que el beneficio es que hay una comunidad entera que en un momento desarrolló una herramienta maravillosa: 1C ++ (1cpp.dll), lo cual es increíble para ellos. ¡GRACIAS! La biblioteca le permite escribir consultas en términos de 1C, que luego se convierten en nombres reales de tablas y campos. Si alguien no lo sabe, la solicitud se puede escribir utilizando un seudónimo y se verá así
select from $.
Dicha solicitud es comprensible para los humanos, pero no existe tal tabla y campo en el servidor, hay otros nombres, por lo que 1C ++ lo convertirá en
select SP5278 from SC2235
y tal solicitud ya es entendida por el servidor. Todos están felices, nadie jura, ni una persona ni un servidor. Aquí, al parecer, el problema ha sido resuelto.
El segundo problema radica en el plano de las configuraciones: una configuración se usó en las sucursales, otra en la oficina central y la tercera en las sucursales. Clase? !! 1 Yo también lo creo. Además, no son patrimonio típico ni siquiera típico, sino que están completamente escritos desde cero durante los vikingos y, desafortunadamente, no los mejores arquitectos sentaron las bases de estas conf ... La implementación de documentos, por ejemplo, en cada configuración tiene un conjunto diferente de detalles. Pero no solo difieren los nombres de algunos campos, lo que es mucho más divertido cuando los nombres de los detalles son los mismos, sino que el significado de los datos almacenados en ellos es DIFERENTE.

En las configuraciones casi no se utilizan registros, todo se basa en las complejidades de los documentos. Por lo tanto, a veces tenía que escribir una hoja completa en una transacción limpia, con un montón de casos y combinaciones, para repetir la lógica de algún procedimiento desde la configuración, que muestra información en el campo de texto del formulario.
Debemos rendir homenaje al equipo de desarrollo, que durante todos estos años apoyó lo que heredaron de los "implementadores", es un trabajo enorme: apoyar esto e incluso optimizar algo. Hasta que vea, no comprende, yo mismo no creía al principio que todo podría ser tan complicado. Pregunte: ¿por qué no reescribir desde cero? Falta banal de recursos. La compañía se estaba desarrollando tan rápido que, a pesar de un gran equipo de programadores, simplemente no podían mantenerse al día con las necesidades del negocio, sin mencionar la reescritura de todo el concepto.
Continuamos la historia de las solicitudes. Obviamente, todos los bloques para la extracción de datos se convirtieron en almacenamientos para que luego se pudieran lanzar en el lado del servidor sin pasar por la plataforma 1C. La regla era esta: un almacenamiento es responsable de recuperar una entidad. Porque La lista de deseos en la etapa de inicio ya se ha acumulado mucho, porque se ha vuelto doloroso a lo largo de los años, y luego han resultado docenas de archivos de almacenamiento.
El tercer problema es cómo aumentar la velocidad y la calidad del desarrollo, y cómo apoyar a todo este monstruo. ¿Escribir una solicitud para 1C ++ y copiar y pegar el resultado de su conversión a un almacenamiento? Es muy inconveniente y tedioso, además, hay una alta probabilidad de errores: copie el incorrecto o el incorrecto o no seleccione la última línea de la consulta y copie sin ella. Esto es especialmente cierto cuando se trata de consultas directas 1C, porque no hay un
seudónimo como
Directorio, Nomenclatura, Artículo, solo nombres reales
SC2235.SP5278 y, por lo tanto, copiar una solicitud del directorio de productos a una tienda que recupera clientes es muy simple. Por supuesto, la solicitud probablemente caerá debido a la falta de coincidencia de tipos y número de campos en la tabla de destino, pero hay placas idénticas, como enumeraciones, donde solo dos columnas son ID y Nombre. En general, solo queda aplicar algún tipo de automatización. Bueno, suficientes letras, ¡vamos al grano!
Quería que el proceso de desarrollo del almacenamiento se redujera a algo como esto:
- Arreglamos la consulta SQL con pseudonombres y la guardamos
- Presionamos un botón mágico y a la salida recibimos el procedimiento almacenado corregido en el SQL convertido, lo borramos al servidor
Algunos detalles
Para resolver el tercer problema, se escribió el procesamiento externo (.ert). Hay una serie de procedimientos en el procesamiento, cada uno de los cuales contiene el texto de la consulta para extraer una entidad utilizando un pseudonombre, como
select * from $.
En el formulario de procesamiento, hay un campo para mostrar el resultado de un procedimiento particular, es decir, solicitud convertida a un formulario que sea comprensible para el servidor para que pueda probarlo rápidamente. Además, siempre se agrega un
bloque de depuración a esta solicitud, con la declaración de variables, los nombres de bases de datos de prueba, servidores y más. Solo queda copiar y pegar en SSMS y presionar F5. Por supuesto, puede ejecutar esta solicitud desde el procesamiento en sí, pero el plan de solicitud y todo eso, bueno, usted comprende ... En general, así es como se realiza la depuración. Porque Hay varias configuraciones; en el procesamiento, es posible convertir los mismos textos de consulta con seudónimos de objetos en consultas finales para diferentes configuraciones. De hecho, en una confe Nomenclatura, la referencia es SC123, y en otra, SC321. Pero 1C ++ le permite cargar diferentes configuraciones en tiempo de ejecución y generar una salida individual para cada una de ellas de acuerdo con el diccionario.
A continuación, se agregó el modo de ejecución por lotes al procesamiento, cuando inicia automáticamente cada uno de los procedimientos para cada configuración, y la salida de cada uno de ellos se escribe en archivos .sql (en adelante, los archivos básicos). Por lo tanto, obtenemos un montón de combinaciones de archivos básicos, que posteriormente deberían convertirse automáticamente en procedimientos almacenados usando VS. Vale la pena señalar que los archivos base incluyen
un bloque de depuración .
Parecería, ¿por qué no hacer una conclusión inmediata a los archivos finales de los procedimientos almacenados y mantener todo en este procesamiento? El hecho es que para algunas pruebas es necesario ejecutar versiones de depuración de consultas en lotes en los que se declaran todas las variables, además quería que los nombres de los procedimientos almacenados se administraran desde VS, sin pasar por 1C, porque esto es lógico, ¿no?
Por cierto, los archivos básicos también se almacenan en el proyecto, bueno, los archivos de los procedimientos almacenados ya preparados, por supuesto. En cualquier momento, sin iniciar 1C, puede abrir el archivo base en SSMS y ejecutarlo sin molestarse con declaraciones variables.
En el procesamiento, todos los procedimientos con solicitudes también son plantillas, que tienen el mismo conjunto de parámetros, pero en este o aquel procedimiento solo se utilizan los parámetros necesarios. En algunos, todo está involucrado, y en algunos, dos son suficientes. Por lo tanto, agregar un nuevo procedimiento se reduce a copiar la plantilla y completar los parámetros con las consultas mismas.
El código de uno de los procedimientos de procesamiento, que luego se convertirá en un procedimiento almacenado
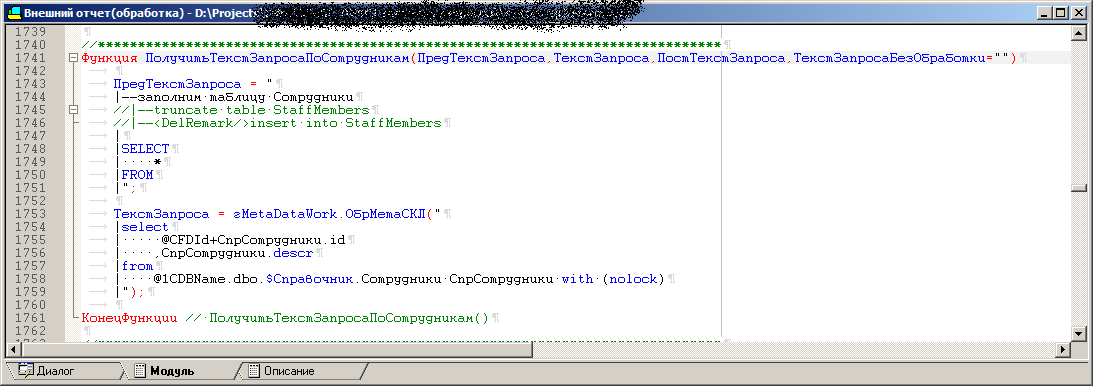
La consulta final va más o menos así:
++"("+OPENQUERY()+")"+
Apariencia del procesamiento

Al cambiar las configuraciones, la lista de elementos disponibles (necesarios) para descargar elementos en la lista de datos cambia. Si es posible, el código de procedimiento en 1C fue lo más unificado posible. Si se extraen las contrapartes y estos directorios son inconsistentes en diferentes configuraciones, entonces dentro del procedimiento de generación hay diferentes casos, tales como: este bloque se repara para todos, este se agrega a la solicitud final solo para dicha configuración, y hay uno para el otro. Resulta que en los procedimientos almacenados para una entidad pero las configuraciones diferentes pueden diferir no solo por los nombres de las tablas, sino también por bloques enteros de combinaciones presentes en una y ausentes en otra. El conjunto de campos de salida, por supuesto, es el mismo y corresponde a la tabla del receptor o al contenedor del paquete SSIS, algunos campos están obstruidos con stubs para configuraciones en las que estos detalles no son, en principio.
Botón mágicoVisual Studio tiene herramientas como MSbuild y las impresionantes plantillas T4. Por lo tanto, como botón mágico, se escribió un script en C # para T4, que:
- Registra una configuración vacía en el registro (de lo contrario, 1C mostrará una ventana modal con una sugerencia para registrar una conf y esperar las acciones del usuario)
- Crea una base de datos vacía para este konf en el servidor SQL, porque sin ella 1C dará un error
- Lanza 1C y a través de OLE le dice que ejecute el procesamiento (el mismo .ert), también transfiere un GUID único a 1C
- El resultado es una serie de archivos con solicitudes ya hechas (convertidas) y un archivo marcador, en el que se escribe el GUID recibido al inicio
- El registro de la conf se elimina del registro y una base de datos vacía temporal se elimina del servidor
- Comprueba el contenido del archivo de token. Si el archivo de marcador contiene el GUID que pasamos a 1C cuando se inició, significa que funcionó hasta el final, no se bloqueó, etc., vaya al siguiente paso o mostraremos un error
- Creamos almacenes.
- Descompilamos el archivo .ert con gcomp para obtener los textos del módulo y los formularios de procesamiento, bueno, lo convertimos a Unicode, para su posterior envío a Git y mostrarlo correctamente allí. Para aquellos que no trabajaron con 1C: el archivo .ert es binario y el estudio, junto con el git, dice que el archivo .ert ha cambiado, pero no está claro qué ha cambiado exactamente, tal vez alguien movió el botón un píxel a la izquierda (que inaceptable sin justificación)
Antes de crear almacenamientos, el script T4 extrae textos de consulta de los archivos base regularmente para excluir piezas de depuración (se enfoca en una etiqueta especial que marca el final del bloque de depuración) y lo envuelve en una única plantilla unificada para el procedimiento almacenado. Todos los almacenamientos tienen el mismo conjunto de parámetros, pero en este o aquel procedimiento solo se utilizan los parámetros necesarios. La lista de comparación de los nombres de los archivos básicos y los nombres de los procedimientos almacenados en los que deberían convertirse se realiza en el proyecto como un archivo separado, por lo que sería conveniente trabajar con esto sin buscar la línea necesaria en el paño y nuevamente, evitando el lanzamiento de 1C.También quería que el desarrollador que se unió al proyecto pudiera escribir solicitudes y convertirlas sin ningún problema, sin molestarse en registrar una configuración vacía, implementar una base de datos vacía y otros detalles desagradables y tediosos. Por lo tanto, todo se almacena en el proyecto: las configuraciones necesarias de 1C, los scripts para el correcto funcionamiento de 1C, el convertidor de procesamiento en sí y otros archivos.Como resultado, el escenario de las acciones del desarrollador es: ¿Necesita un nuevo almacenamiento o necesita reparar el existente?- Escribimos un nuevo procedimiento en el procesamiento / corregimos el anterior;
- Agregue una línea en el proyecto VS al archivo de configuración para las asignaciones si se ha agregado un nuevo procedimiento;
- Ejecute el script T4;
Ganancia Listo
Pista?Porque
los archivos básicos se presentan procesándolos en una carpeta específica y el proyecto no sabe nada acerca de los archivos nuevos, por lo que aparecerán automáticamente en el proyecto; debe ajustar el archivo .sqlproj y reemplazarlo. <ItemGroup> <None Include=" \1.sql"> <None Include=" \2.sql"> <None Include=" \3.sql"> </ItemGroup>
En <ItemGroup> <Content Include=" \*.sql" /> </ItemGroup>
« ». , , , :)
, , (, ) . ( ), , - - - , .
En la salida, obtenemos el archivo del módulo modificado y los formularios de procesamiento, el nuevo archivo base y el almacenamiento en sí. El estudio destaca perfectamente todas las líneas cambiadas. Por supuesto, tomó mucho tiempo para todas estas bellezas para que el procesamiento no recreara los archivos básicos, si nada ha cambiado en el código de procesamiento, de lo contrario brillarían como cambiados (porque la fecha del archivo ha cambiado), pero no hay diferencia con la comparación línea por línea. Por cierto, se escribe un comentario en el archivo base (en la parte que posteriormente irá al procedimiento almacenado) con información sobre la fecha y hora en que se generó el archivo, la versión de la configuración en función de la cual se creó y quién lo realizó. Por lo tanto, en cualquier procedimiento almacenado, siempre puede ver quién generó el código ubicado en él. El procesamiento, antes de sobrescribir un archivo base existente, compara su texto útil conque está previsto que se escriba en él, si no hay diferencias, el archivo permanece intacto (todo esto para evitar el resaltado falso de los cambios al cambiar la configuración 1C, por ejemplo, cuando la versión del archivo MD ha cambiado).También tuve que atormentarme con los textos de consulta, porque se ejecutan en servidores remotos a través de OPENQUERY , y los nombres de la base de datos 1C en las ramas son diferentes, al igual que los nombres de los servidores, por lo que el texto de la consulta se recopila dinámicamente de la cadena, con la sustitución de estos valores de los parámetros de almacenamiento, colocados en variable y se lanza al final a través de EXEC . OPENQUERY se agudizó originalmente para ejecutar una cadena, por lo que ya obtenemos una cadena en una cadena, una comilla entre comillas, escape y más.Y 177 (en la versión básica) opera en SQL2000, y allí varchar (max) no funciona, varchar máximo (8000), y el texto de consulta general es 9k, por ejemplo ... Entonces, necesitamos definir dos variables y ejecutarlas en EXEC (@ SQL1 + @ SQL2). A pesar de que los procedimientos se almacenan y ejecutan en SQL2016, sus partes se verificaron en SQL2000. Las manos no querían determinar las variables, quería minimizar la cantidad de gestos innecesarios, para que todo fuera automático.En el procesamiento, el texto de la consulta se ve así select ... from ( select ... from @1CDBName.dbo.$. join @1CDBName.dbo.$. join ... where xxx = 'hello!' ^
Y el texto del almacenamiento es el siguiente CREATE PROCEDURE [dbo].[SP1] @LinkedServerName varchar(24) ,@1CDBName varchar(24) AS BEGIN Declare @TSQL0 varchar(8000), @TSQL1 varchar(8000), @TSQL2 varchar(8000) set @TSQL0=' select ... from OPENQUERY('+@LinkedName+','' select ... from '+@1CDBName+'.dbo.DH123. join '+@1CDBName+'.SC123. ... where '; set @TSQL1=' xxx = ''''hello!'''' join ... join ... )'' join ... '''; set @TSQL2=' ... EXEC(@TSQL0+@TSQL1+@TSQL2) END
Como puede ver en el código, el procedimiento almacenado no tiene formato. Al crear un archivo base, se elimina todo el formato (espacios, pestañas) a la izquierda y a la derecha, que estaban en la solicitud original con pseudonombres, porque al servidor no le importa el formateo, y tiene sentido directo guardar, porque puede generar cualquier número de variables, y OPENQUERY tiene un límite de 8k personajesEl procesamiento de .ert determina la duración de la solicitud final, teniendo en cuenta el formato remoto, y calcula el número de variables en las que debe encajar todo esto, etc. En general, este tratamiento bebió mucha sangre.Manualmente, nunca se realizan cambios en los procedimientos almacenados, solo a través de las correcciones de procesamiento.ETL
Quizás, en esta parte no hay nada especial (en mi opinión). El esquema clásico con una base de datos intermedia (Stage). Solo se puede notar que ETL se implementa utilizando paquetes SSIS, que, a su vez, realizan los mismos procedimientos almacenados que se discutieron en la sección anterior. Hay un paquete principal y varios niños. Para permitir la ejecución de subprocesos múltiples, el paquete principal lanza simultáneamente varias instancias del mismo paquete secundario con diferentes parámetros (para diferentes ramas), como resultado, es posible obtener datos de servidores vinculados en el menor tiempo posible.Si en el proceso de recibir datos, una o más instancias del paquete secundario no pudieron conectarse a los servidores remotos, entonces se recuerda la lista de dichos servidores (con un intento de conexión fallido), y después de que finaliza la ejecución de todos los flujos de los paquetes secundarios (es decir, después de unos minutos) , el paquete principal inicia nuevamente los flujos de los servidores de la lista con un intento fallido, tratando de alcanzarlo y a veces lo consigue.Si no fue posible obtener datos de una o varias sucursales, entonces este no es un error crítico, el sistema funcionará sin ellos. Por supuesto, el paquete le notifica de tales situaciones. En nuestro caso, a través de zabbix.Todos los datos recibidos se vuelcan en una base de datos intermedia desde la cual ya se vierte en la principal.Porque
En las configuraciones de 1C utilizadas, no existen mecanismos para registrar los cambios, y ni siquiera debe recordar acerca de la integración de eventos, cada vez que tiene que volver a consultar datos de todas las bases de datos en los últimos meses. Para no perder tiempo eliminando, se utiliza el particionamiento de tablas, que permite la ejecución truncatede la sección.Por supuesto, con el tiempo, el paquete principal comenzó a crecer (cubierto de paquetes secundarios) y se le agregaron interacciones con servicios web, varias bases de datos "no 1C" y otras fuentes.Controle el flujo de uno de los paquetes SSIS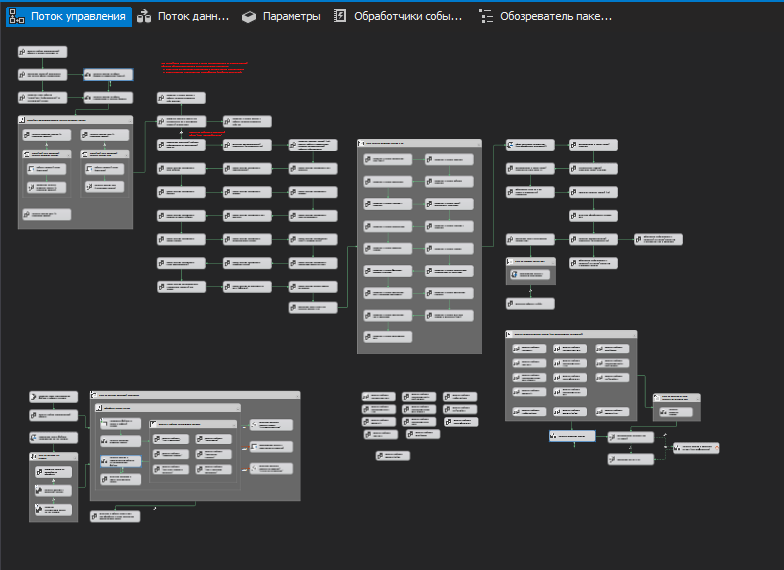 Uno de los flujos de datos de paquetes
Uno de los flujos de datos de paquetes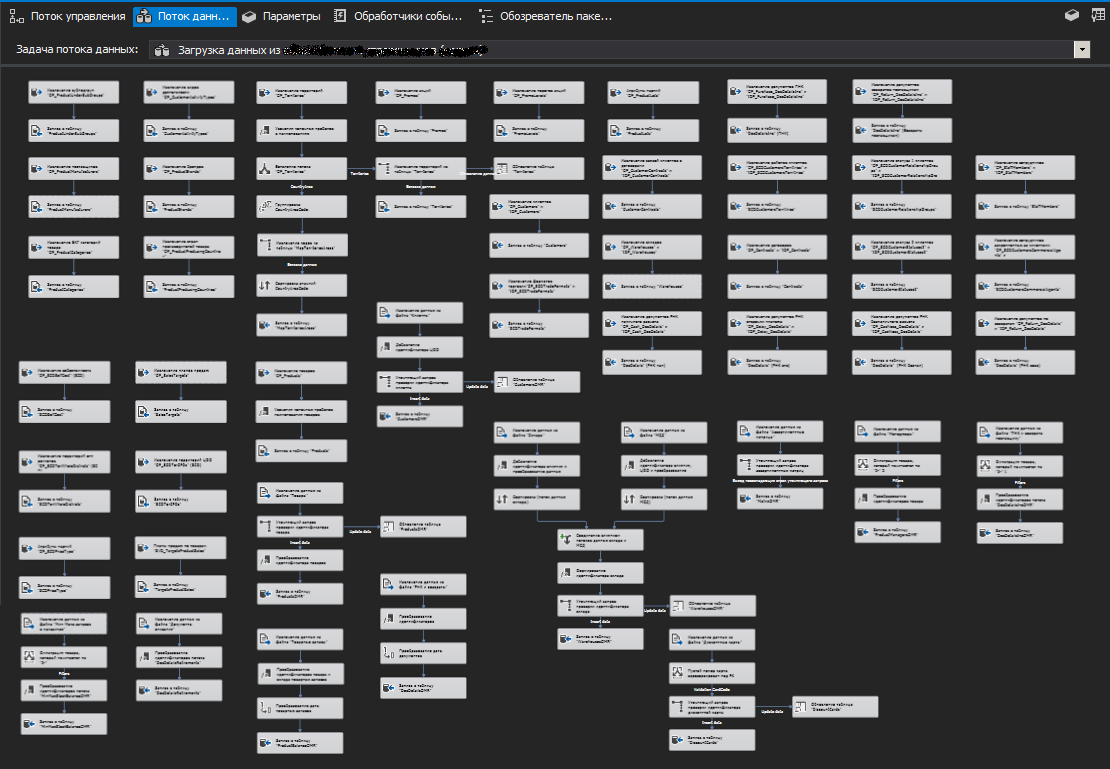
Algunos consejos si puedes
SSIS
SQL Server (SQL Server Destination), ,
OLE DB (OLE DB Destination).
, , , . , , . (, )
Nunca corrija manualmente los datos en la base de datos. Solo guiones y asegúrese de guardar cada uno de ellos con un nombre adecuado, fecha y comentarios en el interior, de lo que debe quedar claro quién, cuándo y sobre qué base lo hizo (error / servicio, etc.).Realice una comprobación de bloques de la versión de la base de datos dentro de dichos scripts y no permita la ejecución en caso de desajuste de versión en el script y en la base de datos de destino.Y también recomendaría que tenga una tabla especial en la base de datos que almacene el historial de lanzamientos de dichos scripts (del párrafo anterior). Es decir
el script no solo realiza cambios en los datos, sino que también registra el hecho de su lanzamiento en el registro. Tiene sentido no solo registrar el lanzamiento, sino también bloquear su reinicio en caso de que el registro ya contenga información sobre la ejecución anterior. Y si por alguna razón necesita ejecutar el mismo script nuevamente, haga una copia y asígnele una nueva fecha y número. Esto facilitará enormemente la vida y eliminará reclamos innecesarios durante la sesión informativa.Establezca las cadenas y rutas de conexión que no sean rutas productivas y nombres como la configuración predeterminada para la implementación, de modo que para las publicaciones en el producto haya tenido que elegir a propósito (es decir, conscientemente) una configuración específica.No seas perezoso para hacer todo tipo de protección contra los tontos, nunca son superfluos, sin importar cuán altamente calificados y responsables sean los desarrolladores.PS
No pretendo ser cierto, todos deciden por sí mismos, en función de su experiencia y preferencias, si todo lo que se ha descrito es útil. Todos los ejemplos son solo ejemplos rápidos. El artículo fue escrito durante varios meses con docenas de enfoques e intervalos largos debido a la falta de tiempo, por lo que puede haber algunas inconsistencias en el texto, no se ofenda.