Esta nota es una versión escrita de mi informe "Cómo arruinar el rendimiento con código ineficiente" de la conferencia JPoint 2018. Puede ver videos y diapositivas en la página de la conferencia . En el calendario, el informe está marcado con un vaso ofensivo de batidos, por lo que no habrá nada súper complicado, esto es más probable para los principiantes.
Asunto del informe:
- cómo mirar el código para encontrar cuellos de botella
- antipatrones comunes
- rastrillo no obvio
- rastrillo de derivación
Al margen, señalaron algunas imprecisiones / omisiones en el informe, se mencionan aquí. Los comentarios también son bienvenidos.
Impacto en el rendimiento en el rendimiento
Hay una clase de usuario:
class User { String name; int age; }
Necesitamos comparar los objetos entre sí, por lo que declaramos los métodos equals y hashCode :
import lombok.EqualsAndHashCode; @EqualsAndHashCode class User { String name; int age; }
El código es viable, la pregunta es diferente: ¿será el mejor rendimiento de este código? Para responderlo, recordemos las características del método Object::equals : devuelve un resultado positivo solo cuando todos los campos que se comparan son iguales; de lo contrario, el resultado será negativo. En otras palabras, una diferencia ya es suficiente para un resultado negativo.
Después de mirar el código generado para @EqualsAndHashCode veremos algo como esto:
public boolean equals(Object that) {
El orden de verificación de los campos corresponde al orden de su declaración, que en nuestro caso no es la mejor solución, porque comparar objetos usando equals "más difícil" que comparar tipos simples.
Ok, intentemos crear métodos equals/hashCode usando la Idea:
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(name, that.name); }
Una idea crea un código más inteligente que conoce la complejidad de comparar diferentes tipos de datos. Bueno, @EqualsAndHashCode y escribiremos explícitamente equals/hashCode . Ahora veamos qué sucede cuando la clase se extiende:
class User { List<T> props; String name; int age; }
Recreando equals/hashCode :
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(props, that.props)
Las listas se comparan antes de comparar cadenas, lo que no tiene sentido cuando las cadenas son diferentes. A primera vista, no hay mucha diferencia, porque las cadenas de igual longitud se comparan mediante signos (es decir, el tiempo de comparación crece junto con la longitud de la cadena):
Hubo una inexactitudEl método java.lang.String::equals es intrusivo , por lo que no hay comparación de inicio de sesión en la ejecución.
Ahora considere comparar dos ArrayList (como la implementación de lista más utilizada). Examinando ArrayList , nos sorprende descubrir que no tiene su propia implementación de equals , sino que usa una implementación heredada:
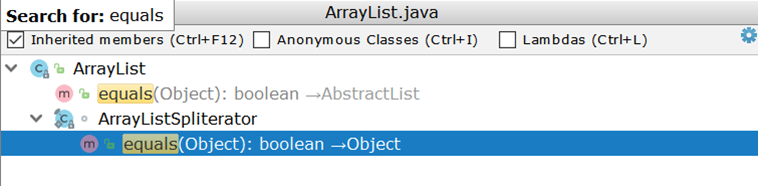
Importante aquí es la creación de dos iteradores y el paso por pares a través de ellos. Supongamos que hay dos ArrayList :
- en un número del 1 al 99
- en el segundo número del 1 al 100
Idealmente, sería suficiente comparar los tamaños de las dos listas y, si no coinciden, devolverá inmediatamente un resultado negativo (como lo hace AbstractSet ), en realidad, se realizarán 99 comparaciones y solo en la centésima parte quedará claro que las listas son diferentes.
¿Qué hay con los kotlinitas?
data class User(val name: String, val age: Int);
Aquí todo es como un Lombok: el orden de comparación corresponde al orden del anuncio:
public boolean equals(Object o) { if (this == o) { return true; } if (o instanceof User) { User u = (User) o; if (Intrinsics.areEqual(name, u.name) && age == u.age) {
Como solución alternativa, puede organizar manualmente las declaraciones de campo.
Vamos a complicar la tarea.
void check(Dto dto) { SomeEntity entity = jpaRepository.findOne(dto.getId()); boolean valid = dto.isValid(); if (valid && entity.hasGoodRating()) {
El código implica acceder a la base de datos incluso cuando el resultado de verificar las condiciones indicadas por la flecha es predecible de antemano. Si el valor de la variable valid es falso, entonces el código en el bloque if nunca se ejecutará, lo que significa que puede prescindir de una solicitud:
void check(Dto dto) { boolean valid = dto.isValid(); if (valid && hasGoodRating(dto)) {
Nota desde el margenEl hundimiento puede ser insignificante cuando la entidad devuelta desde JpaRepository::findOne ya JpaRepository::findOne en el caché del primer nivel, entonces no habrá ninguna solicitud.
Un ejemplo similar sin ramificación explícita:
boolean checkChild(Dto dto) { Long id = dto.getId(); Entity entity = jpaRepository.findOne(id); return dto.isValid() && entity.hasChild(); }
Un retorno rápido le permite retrasar la solicitud:
boolean checkChild(Dto dto) { if (!dto.isValid()) { return false; } return jpaRepository.findOne(dto.getId()).hasChild(); }
Una adición bastante obvia que no apareció en el informeImagine que un cierto cheque usa una entidad similar:
@Entity class ParentEntity { @ManyToOne(fetch = LAZY) @JoinColumn(name = "CHILD_ID") private ChildEntity child; @Enumerated(EnumType.String) private SomeType type;
Si la verificación utiliza la misma entidad, debe asegurarse de que la llamada a las entidades / colecciones secundarias "perezosas" se realice después de la llamada a los campos que ya están cargados. A primera vista, una solicitud adicional no tendrá un impacto significativo en la imagen general, pero todo puede cambiar cuando una acción se realiza en un bucle.
Conclusión: las cadenas de acciones / verificaciones deben ordenarse en orden de complejidad creciente de las operaciones individuales, quizás algunas de ellas no tendrán que realizarse.
Ciclos y procesamiento a granel
El siguiente ejemplo no necesita explicaciones especiales:
@Transactional void enrollStudents(Set<Long> ids) { for (Long id : ids) { Student student = jpaRepository.findOne(id);
Debido a las múltiples consultas de la base de datos, el código es lento.
ObservaciónEl rendimiento puede enrollStudents aún más si el método enrollStudents ejecuta fuera de una transacción: entonces cada llamada a osdjrJpaRepository::findOne se ejecutará en una nueva transacción (ver SimpleJpaRepository ), lo que significa recibir y devolver una conexión a la base de datos, así como crear y vaciar el caché de primer nivel.
Arreglo:
@Transactional void enrollStudents(Set<Long> ids) { if (ids.isEmpty()) { return; } for (Student student : jpaRepository.findAll(ids)) { enroll(student); } }
Midamos el tiempo de ejecución (en microsegundos) para una colección de claves (10 y 100 piezas) Punto de referencia
ObservaciónSi usa Oracle y pasa más de 1000 claves para findAll , obtendrá la excepción ORA-01795: maximum number of expressions in a list is 1000 .
Además, realizar una gran cantidad de consultas (con muchas claves) puede ser peor que n consultas. Todo depende de la aplicación específica, por lo que el reemplazo mecánico del ciclo para el procesamiento en masa puede degradar el rendimiento.
Un ejemplo más complejo sobre el mismo tema.
for (Long id : ids) { Region region = jpaRepository.findOne(id); if (region == null) {
En este caso, no podemos reemplazar el bucle con JpaRepository::findAll , JpaRepository::findAll esto romperá la lógica: todos los valores obtenidos de JpaRepository::findAll no serán null y el bloque if no funcionará.
El hecho de que para cada clave de base de datos nos ayudará a resolver esta dificultad
devuelve el valor real o su ausencia. Es decir, en cierto sentido, una base de datos es un diccionario. Java desde el cuadro nos da una implementación lista para usar del diccionario, HashMap , sobre la cual construiremos la lógica para reemplazar la base de datos:
Map<Long, Region> regionMap = jpaRepository.findAll(ids) .stream() .collect(Collectors.toMap(Region::getId, Function.identity())); for (Long id : ids) { Region region = map.get(id); if (region == null) { region = new Region(); region.setId(id); } use(region); }
Ejemplo inverso
Este código siempre crea una nueva transacción para guardar una lista de entidades. La flacidez comienza con múltiples llamadas a un método que abre una nueva transacción:
Solución: aplique el método Saver::save inmediatamente para todo el conjunto de datos:
@Transactional public void audit(List<AuditDto> inserts) { List<AuditEntity> bulk = inserts .map(this::toEntities) .flatMap(List::stream)
Muchas transacciones se fusionan en una sola, lo que da un aumento tangible (tiempo en microsegundos): Punto de referencia
Es difícil formalizar un ejemplo con transacciones múltiples, lo que no se puede decir acerca de llamar a JpaRepository::findOne en un bucle.
El enfoque es aplicable no solo a la base de datos, por lo que Tagir lany Valeev fue más allá. Y si antes escribimos así:
List<Long> list = new ArrayList<>(); for (Long id : items) { list.add(id); }
y todo estaba bien, ahora la "Idea" sugiere corregirse a sí misma:
List<Long> list = new ArrayList<>(); list.addAll(items);
Pero incluso esta opción no siempre lo satisface, porque puede hacerlo aún más corto y más rápido:
List<Long> list = new ArrayList<>(items);
Comparar (tiempo en ns)Para ArrayList, esta mejora proporciona un aumento notable:
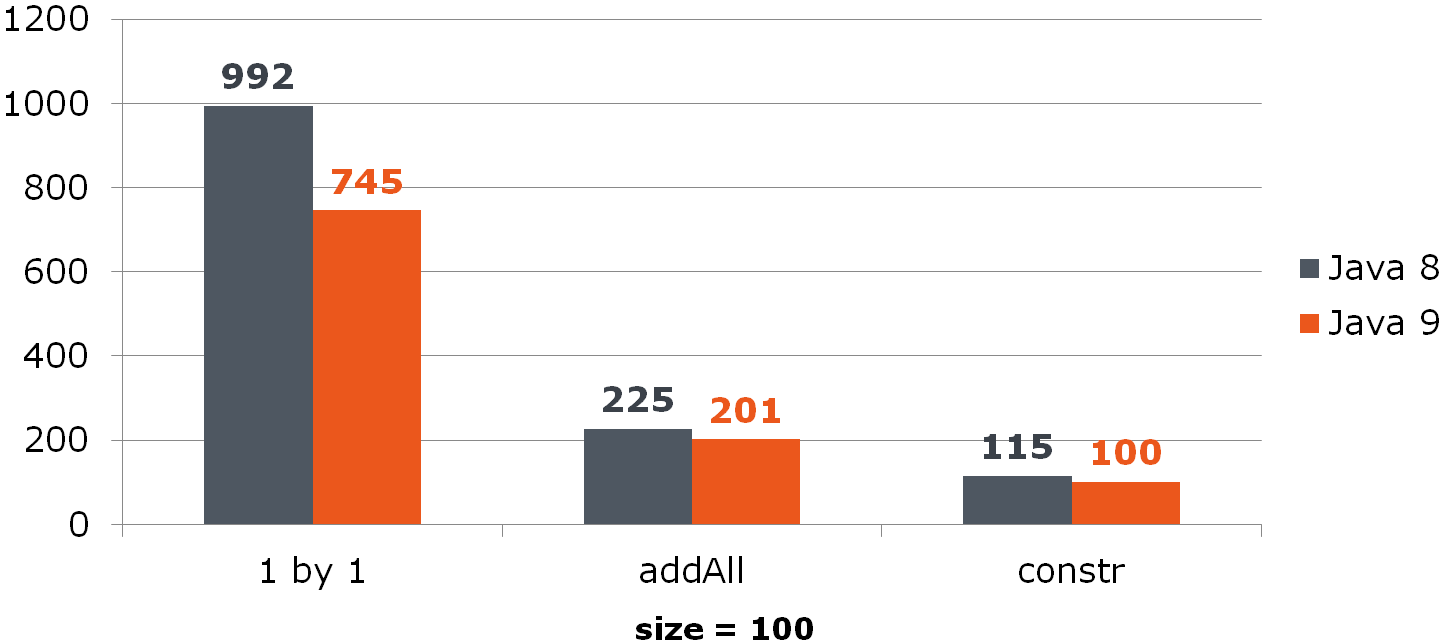
Para HashSet, no es tan color de rosa:

Punto de referencia
Eliminar de ArrayList
for (int i = from; i < to; i++) { list.remove(from); }
El problema está en implementar el método List::remove :
public E remove(int index) { Objects.checkIndex(index, size); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { System.arraycopy(array, index + 1, array, index, numMoved);
Solución:
list.subList(from, to).clear();
Pero, ¿qué pasa si el valor remoto se usa en el código fuente?
for (int i = from; i < to; i++) { E removed = list.remove(from); use(removed); }
Ahora primero debe pasar por la lista limpia:
List<String> removed = list.subList(from, to); removed.forEach(this::use); removed.clear();
Si realmente desea eliminar en el ciclo, un cambio en la dirección de paso por la lista ayudará a aliviar el dolor. Su significado es cambiar un número menor de elementos después de limpiar la celda:
Compare los tres métodos (debajo de las columnas hay% de elementos eliminados de una lista de tamaño 100):
Por cierto, ¿alguien notó la anomalía?
Para ver
Si eliminamos la mitad de todos los datos que se mueven desde el final, entonces el último elemento siempre se elimina y no hay desplazamiento:
Punto de referencia
Conclusión: las operaciones en masa son a menudo más rápidas que las operaciones individuales.
Alcance y rendimiento
Este código no necesita ninguna explicación especial:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); List<Student> underAchieving = repository.findUnderAchieving();
Limitamos el alcance, lo que da menos 1 consulta:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); if (Settings.leaveBothCategories()) { List<Student> underAchieving = repository.findUnderAchieving();
Y aquí el atento lector debería preguntarse: ¿qué pasa con el análisis estático? ¿Por qué Idea no nos contó sobre la mejora que yace en la superficie?
El hecho es que las posibilidades de análisis estático son limitadas: si el método es complejo (especialmente interactuando con la base de datos) y afecta el estado general, la transferencia de su ejecución puede interrumpir la aplicación. El analizador estático puede informar ejecuciones muy simples, cuya transferencia, por ejemplo, dentro del bloque no interrumpirá nada.
Puede usar el resaltado variable como un error, pero nuevamente, úselo con cuidado, ya que los efectos secundarios siempre son posibles. Puede usar la anotación @org.jetbrains.annotations.Contract(pure = true) , disponible en la biblioteca de jetbrains-annotations para indicar métodos que no cambian de estado:
Conclusión: la mayoría de las veces, el exceso de trabajo solo empeora el rendimiento.
Ejemplo más inusual
@Service public class RemoteService { private ContractCounter contractCounter; @Transactional(readOnly = true)
Esta implementación abre una transacción incluso cuando la transacción no es necesaria (retorno rápido -1 del método).
Todo lo que necesita hacer es eliminar la transaccionalidad dentro del ContractCounter::countContracts , donde sea necesario, y eliminarla del método "externo".
Compare el tiempo de ejecución para el caso cuando se devuelve -1 (ns): Comparar el consumo de memoria (bytes): Punto de referencia
Conclusión: los controladores y los servicios de aspecto "externo" necesitan ser liberados de la transaccionalidad (esto no es su responsabilidad) y la lógica completa de la verificación de datos de entrada, que no requiere acceso a la base de datos y componentes transaccionales, debe ser implementada.
Convertir fecha / hora en cadena
Una de las tareas eternas es convertir la fecha / hora en una cadena. Antes del G8, hicimos esto:
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.yyyy"); String dateAsStr = formatter.format(date);
Con el lanzamiento de JDK 8, obtuvimos LocalDate/LocalDateTime y, en consecuencia, DateTimeFormatter
DateTimeFormatter formatter = ofPattern("dd.MM.yyyy"); String dateAsStr = formatter.format(localDate);
Midamos su rendimiento:
Date date = new Date(); LocalDate localDate = LocalDate.now(); SimpleDateFormat sdf = new SimpleDateFormat("dd.MM.yyyy"); DateTimeFormatter dtf = DateTimeFormatter.ofPattern("dd.MM.yyyy"); @Benchmark public String simpleDateFormat() { return sdf.format(date); } @Benchmark public String dateTimeFormatter() { return dtf.format(localDate); }
Pregunta: supongamos que nuestro servicio recibe datos del exterior y no podemos rechazar java.util.Date . ¿Sería beneficioso para nosotros convertir Date a LocalDate si este último se convierte más rápidamente en una cadena? Calcular:
@Benchmark public String measureDateConverted(Data data) { LocalDate localDate = toLocalDate(data.date); return data.dateTimeFormatter.format(localDate); } private LocalDate toLocalDate(Date date) { return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate(); }
Por lo tanto, la Date conversión -> LocalDate beneficiosa cuando se usan los "nueve". En G8, los costos de conversión engullirán todos los beneficios de DateTimeFormatter -a.
Punto de referencia
Conclusión: aproveche las nuevas soluciones.
Otro "ocho"
En este código, vemos una redundancia obvia:
Iterator<Long> iterator = items
Lo quitamos:
Iterator<Long> iterator = items
Veamos cuánto ha mejorado el rendimiento: Increíble verdad? He argumentado anteriormente que el exceso de trabajo degrada el rendimiento. Pero aquí eliminamos el exceso, y (de repente) empeora. Para comprender lo que está sucediendo, tome dos iteradores y mírelos bajo una lupa:
Revelar Iterator iterator1 = items.stream().collect(toList()).iterator(); Iterator iterator2 = items.stream().iterator();

El primer iterador es el ArrayList$Itr regular ArrayList$Itr .
El paso a través de él es simple: public boolean hasNext() { return cursor != size; } public E next() { checkForComodification(); int i = cursor; if (i >= size) { throw new NoSuchElementException(); } Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } cursor = i + 1; return (E) elementData[lastRet = i]; }
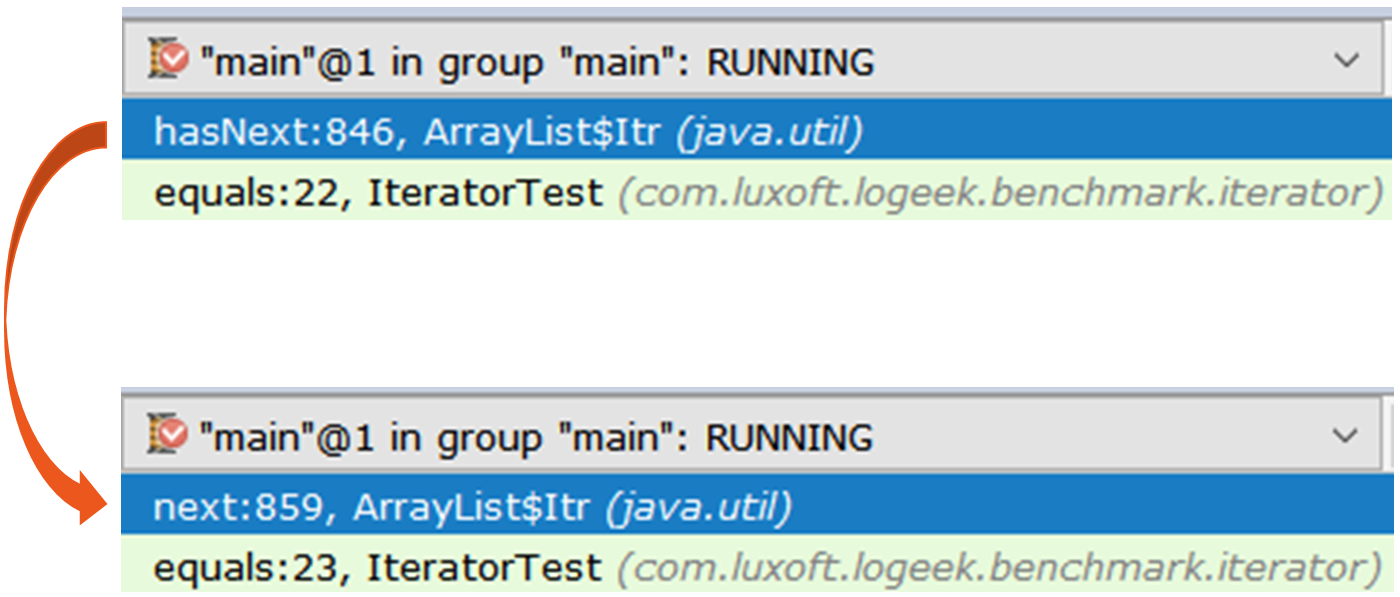
El segundo es más interesante, es Spliterators$Adapter , que se basa en ArrayList$ArrayListSpliterator .
Veamos la iteración del iterador a través de async-profiler :
15.64% juArrayList$ArrayListSpliterator.tryAdvance 10.67% jusSpinedBuffer.clear 9.86% juSpliterators$1Adapter.hasNext 8.81% jusStreamSpliterators$AbstractWrappingSpliterator.fillBuffer 6.01% oojiBlackhole.consume 5.71% jusReferencePipeline$3$1.accept 5.57% jusSpinedBuffer.accept 5.06% cllbir.IteratorFromStreamBenchmark.iteratorFromStream 4.80% jlLong.valueOf 4.53% cllbiIteratorFromStreamBenchmark$$Lambda$8.885721577.apply
Se puede ver que la mayor parte del tiempo se pasa pasando por el iterador, aunque en general, no lo necesitamos, porque la búsqueda se puede hacer así:
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Stream::forEach claramente un ganador, pero esto es extraño: todavía se basa en ArrayListSpliterator , pero su uso ha mejorado significativamente.
Veamos el perfil: 29.04% oojiBlackhole.consume 22.92% juArrayList$ArrayListSpliterator.forEachRemaining 14.47% jusReferencePipeline$3$1.accept 8.79% jlLong.valueOf 5.37% cllbiIteratorFromStreamBenchmark$$Lambda$9.617691115.accept 4.84% cllbiIteratorFromStreamBenchmark$$Lambda$8.1964917002.apply 4.43% jusForEachOps$ForEachOp$OfRef.accept 4.17% jusSink$ChainedReference.end 1.27% jlInteger.longValue 0.53% jusReferencePipeline.map
En este perfil, la mayor parte del tiempo se gasta "tragando" los valores dentro del Blackhole . En comparación con un iterador, una parte significativamente mayor del tiempo se dedica directamente a la ejecución de código Java. Se puede suponer que la razón es el menor peso específico de la recolección de basura, en comparación con la fuerza bruta del iterador. Comprobar:
forEach:·gc.alloc.rate.norm 100 avgt 30 216,001 ± 0,002 B/op iteratorFromStream:·gc.alloc.rate.norm 100 avgt 30 416,004 ± 0,006 B/op
De hecho, Stream::forEach proporciona la mitad del consumo de memoria.
¿Por qué es más rápido?La cadena de llamadas desde el principio hasta el agujero negro se ve así:
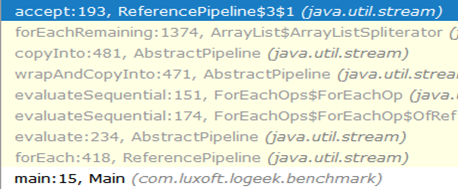
Como puede ver, la llamada a ArrayListSpliterator::tryAdvance desapareció de la cadena, y ArrayListSpliterator::forEachRemaining apareció en su ArrayListSpliterator::forEachRemaining :
ArrayListSpliterator::forEachRemaining alta velocidad ArrayListSpliterator::forEachRemaining logra mediante el uso de un pase a través de toda la matriz en 1 llamada al método. Cuando se usa un iterador, el pasaje se limita a un elemento, por lo que siempre descansamos en ArrayListSpliterator::tryAdvance .
ArrayListSpliterator::forEachRemaining tiene acceso a toda la matriz e ArrayListSpliterator::forEachRemaining sobre ella con un ciclo de conteo sin llamadas adicionales.
Aviso importanteTenga en cuenta que el reemplazo mecánico
Iterator<Long> iterator = items .stream() .map(Long::valueOf) .collect(toList()) .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); }
en
items .stream() .map(Long::valueOf) .forEach(bh::consume);
No siempre es equivalente, porque en el primer caso usamos una copia de los datos para el pasaje sin afectar la transmisión en sí, y en el segundo caso los datos se toman directamente de la transmisión.
Punto de referencia
Conclusión: cuando se trata de representaciones complejas de datos, prepárese para el hecho de que incluso las reglas de "hierro" (daños adicionales al trabajo) dejan de funcionar. El ejemplo anterior muestra que la lista intermedia aparentemente superflua ofrece la ventaja de una implementación más rápida de la enumeración.
Dos trucos
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays .asList(trace) .subList(0, depth) .toArray(new StackTraceElement[newDepth]);
Lo primero que llama la atención es una "mejora" podrida, es decir, pasar una matriz de longitud distinta de cero al método Collection::toArray . Explica con gran detalle por qué esto es dañino.
El segundo problema no es tan obvio, y para su comprensión podemos establecer un paralelismo entre el trabajo del revisor y el del historiador.
Esto es lo que Robin Collingwood escribe sobre esto: . :
1)
2)
3)
, :
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays.copyOf(trace, depth);
List<T> list = getList(); Set<T> set = getSet(); return list.stream().allMatch(set::contains);
, , :
List<T> list = getList(); Set<T> set = getSet(); return set.containsAll(list);
:
interface FileNameLoader { String[] loadFileNames(); }
:
private FileNameLoader loader; void load() { for (String str : asList(loader.loadFileNames())) {
, forEach , :
private FileNameLoader loader; void load() { for (String str : loader.loadFileNames()) {
: :
, , , . , : "" ( ), "" ( ), .
→
→