¿Con qué frecuencia escucha la declaración de que las reglas de correlación proporcionadas por el fabricante
SIEM no funcionan y se eliminan o deshabilitan inmediatamente después de instalar el producto? En los eventos de seguridad de la información, cualquier sección dedicada a SIEM aborda este problema de una forma u otra.
Aprovechemos la oportunidad e intentemos encontrar una solución al problema.
Muy a menudo, el problema principal se llama que las reglas de correlación del fabricante SIEM no se adaptan inicialmente a la infraestructura particular de un cliente en particular.
Analizando los problemas expresados en diferentes sitios, uno tiene la sensación de que el problema no tiene solución. La implementación de SIEM aún tendrá que refinar mucho lo que suministra el fabricante o desechar todas las reglas y escribir las suyas desde cero, mientras que este problema es inherente a todas las soluciones de cualquier parte del cuadrante de Gartner.
Involuntariamente, te preguntas si todo es realmente tan malo y si este nudo gordiano no se puede cortar. ¿Es la expresión "Reglas de correlación que funcionan fuera de la caja" es solo un eslogan de marketing que no cuesta nada?
Un artículo puede interesarle si:
- Ya está trabajando con algún tipo de solución SIEM.
- Solo estoy planeando implementarlo.
- Decidimos construir nuestro SIEM con blackjack y correlaciones basadas en la pila ELK, o algo más.
¿De qué se tratarán los artículos?
En el marco de esta serie de artículos, enumeramos los principales problemas que impiden la implementación del concepto de "Reglas de correlación que funcionan de forma inmediata", y también intentamos describir un enfoque sistemático para resolverlos.
Debo decir de inmediato que este artículo puede ser caracterizado por expertos técnicos como "agua", "sobre nada". Todo es así, pero no del todo. Antes de enfrentar cualquier tarea difícil, primero quiero averiguar por qué surgió y qué nos brinda su solución.
Para una mejor comprensión de toda la gama de temas que se presentarán, daré la estructura general de toda la serie de artículos:
- Artículo 1: este artículo. Hablemos sobre el enunciado del problema e intentemos entender por qué generalmente necesitamos las reglas "Reglas de correlación que funcionan de forma inmediata". El artículo será de naturaleza ideológica y, si se vuelve completamente aburrido, puede omitirlo. Pero, no aconsejo hacer esto, porque en futuros artículos a menudo me referiré a él. Aquí discutiremos los principales problemas que se interponen en nuestro camino y los métodos para resolverlos.
- Artículo 2: ¡Hurra! Aquí es donde llegamos a los primeros detalles del enfoque propuesto para resolver el problema. Describamos cómo nuestro sistema de información SIEM seguro debe "ver". Hablemos sobre cuál debería ser el conjunto de campos necesarios para normalizar eventos.
- Artículo 3: Describimos el papel de categorizar eventos y cómo se construye la metodología para normalizar eventos en base a esto. Mostramos cómo los eventos de TI difieren de los eventos de IS y por qué deberían tener diferentes principios de categorización. Damos ejemplos en vivo del trabajo de esta metodología.
- Artículo 4: Eche un vistazo de cerca a los activos que componen nuestro sistema automatizado y vea cómo afectan el cumplimiento de las reglas. Nos aseguraremos de que tampoco sea tan simple con ellos: deben identificarse y mantenerse actualizados constantemente.
- Artículo 5: Aquello para lo cual todo comenzó. Describimos el enfoque para escribir las reglas de correlación, en base a todo lo que se indicó en artículos anteriores.
Enunciado del problema y por qué es importante
Tratemos de resumir, en palabras simples, nuestra tarea: "Yo, como cliente que compró una solución SIEM, se suscribe para actualizar la base de reglas y paga al fabricante (y a veces al integrador) por asistencia, quiero que me proporcionen de inmediato las reglas de correlación establecidas sería útil en mi SIEM ". En cuanto a mí, es un deseo bastante bueno, no cargado con ninguna limitación técnica arquitectónica o estructural.
Y ahora, atención, supongamos que ya hemos resuelto todos los problemas y nuestra tarea ya se ha completado. ¿Qué nos da esto?
- En primer lugar , ahorramos los costos laborales de nuestros especialistas. Ahora no tienen que pasar tiempo estudiando la lógica de cada nueva regla y adaptándola a las realidades de un sistema automatizado en particular.
- En segundo lugar , ahorramos el presupuesto ya que no le pedimos al integrador ni a otra persona que escriba o adapte las reglas por una tarifa.
- En tercer lugar , todos los actores importantes del mercado SIEM tienen unidades y departamentos de investigación que se centran en analizar las amenazas a la seguridad de la información. Es importante utilizar su experiencia, especialmente si la pagamos.
- Cuarto , estamos acortando nuestra respuesta a las nuevas amenazas. No escribiré sobre la eternidad que transcurre entre la aparición de una amenaza, el desarrollo de reglas de correlación para su detección e implementación en un producto específico para un cliente en particular, ya se han escrito muchos artículos sobre este tema.
- En quinto lugar , esto nos acerca a la posibilidad de compartir entre nosotros reglas unificadas que funcionarán para cualquier cliente, en el marco de una solución SIEM específica, por supuesto.
Muchos expertos técnicos que han encontrado una solución al problema y leen hasta este punto objetarán de inmediato: "Sí, por supuesto que hay ventajas, pero esto no es técnicamente factible". Personalmente, creo que la tarea es bastante "difícil" y ahora, tanto en el mercado occidental como en el ruso, hay SIEM que contienen todos los elementos necesarios para resolverlo. Quiero centrar su atención en esto: los productos no le permiten resolver el problema, sino que solo contienen todos los bloques necesarios desde los cuales, desde el diseñador, puede armar la solución que estamos buscando.
Creo que esto es muy importante porque todo lo que se describirá más adelante se puede implementar en casi cualquier SIEM existente y maduro.
Basta de letras, luego hablaremos con más detalle sobre los problemas que surgen al resolver nuestro problema.
Los desafíos que enfrentamos
En busca de una solución al problema anterior, veamos qué problemas tenemos que enfrentar. Destacar los problemas principales permitirá una mejor comprensión de los problemas, así como desarrollar un enfoque sistemático para resolverlos.
Los problemas que enfrentamos son una bola de nieve, cada uno de los cuales exacerba dramáticamente la situación. Muchos de estos problemas conducen a la creación de "Reglas de correlación que funcionan de forma inmediata" es extremadamente difícil.
En general, los problemas se dividen en los siguientes cuatro grandes bloques:
- Pérdida de datos durante la normalización asociada con la transformación de modelos del "mundo".
- Falta de reglas claras y universalmente aceptadas para normalizar eventos.
- La constante "mutación" del objeto de protección: nuestro sistema automatizado.
- Falta de reglas para escribir reglas de correlación.
Examinemos ahora estos problemas con más detalle.
Transformación del modelo mundial
Este problema se describe más fácilmente utilizando la siguiente analogía.
El mundo que nos rodea es diverso y multifacético, pero nuestra audición y visión solo reparan un espectro limitado de radiación. Después de haber visto o escuchado algún tipo de fenómeno, construimos en nuestras cabezas la imagen de este evento, utilizando su modelo truncado ya. Por ejemplo, nuestro ojo no ve en el espectro infrarrojo y el oído no capta vibraciones por debajo de 16 Hz. Esta es la primera transformación del fenómeno original. Sucede en este modelo que nuestra imaginación trae algo que no estaba en el fenómeno original. Podemos decirle al interlocutor sobre este fenómeno utilizando el habla oral con todas sus limitaciones y características. Esta es la segunda transformación del modelo. Finalmente, el interlocutor, en nuestras palabras, decide escribir sobre este fenómeno a su colega en el mensajero. Esta es la tercera y, muy probablemente, la transformación más dramática del modelo en términos de pérdida de información.
En el ejemplo descrito anteriormente, observamos un problema clásico, en el cual el "modelo conceptual" original (
Sovetov B. Ya., Yakovlev S. A., Modelado del sistema ) por simplificación se transforma en otro modelo mientras se pierde en detalle.
Exactamente lo mismo sucede en el mundo de los eventos generados por software o hardware.
Una explicación que puede servir aquí es una imagen tan simplificada ya de nuestra área temática:
- La primera transformación del modelo. Se cargó un archivo ejecutable en la RAM, el sistema operativo comenzó a ejecutar las instrucciones descritas en él. El sistema operativo pasa cierta información sobre esta operación al servicio daemon / logging (auditado, registro de eventos, etc.). Si no habilita una auditoría extendida de acciones, parte de la información no se incluye en este demonio. Pero incluso en una auditoría extendida, parte de la información seguirá descartándose, porque Los desarrolladores de sistemas operativos decidieron que tal volumen de información es suficiente para comprender lo que está sucediendo.
- La segunda transformación del modelo. Y ahora el servicio / daemon crea un evento, escribe información en el disco, y aquí entendemos que la longitud de la línea del evento puede estar limitada por un cierto número de bytes. Si el demonio / servicio mantiene un registro estructurado, entonces contiene algún esquema del evento con ciertos campos. ¿Qué hacer si hay tanta información que no cabe en un esquema "cableado"? Correctamente, lo más probable es que esta información simplemente se descarte.
Ahora lo que parece como parte de nuestra tarea.
Ya tenemos un modelo simplificado (que ya ha perdido muchos detalles) de algún fenómeno representado por un registro en un archivo de registro: un evento. SIEM lee este evento, lo normaliza mediante la distribución de datos entre los campos de su esquema. El número de campos en el esquema a priori no puede contenerlos tanto como sea necesario para cubrir toda la semántica posible de todos los eventos de todas las fuentes, es decir, en este paso el modelo se transforma y los datos se pierden.

Es importante entender que debido a este problema, el experto, analizando los registros en SIEM o describiendo la regla de correlación, no ve el evento inicial en sí, sino su modelo al menos dos veces distorsionado, que ha perdido mucha información. Y, si la información perdida es extremadamente importante en la investigación del incidente y, como consecuencia de escribir la regla, tendrá que extraerse de alguna parte. Es posible que un experto encuentre la información que falta, ya sea refiriéndose a la fuente original (evento sin procesar, volcado de memoria, etc.) o modelando los datos faltantes en su cabeza en función de su propia experiencia, que es prácticamente imposible de hacer directamente a partir de las reglas de correlación.
Un buen indicador de este problema es, si no es extraño, campos como la cadena del dispositivo del Cliente, Datafield u otra cosa. Estos campos representan un tipo de "volcado" donde colocan datos que no saben dónde poner, o cuando todos los demás campos adecuados simplemente se inundan.
El conjunto de campos de taxonomía, como regla, refleja el modelo del "mundo" como el desarrollador de SIEM ve el área temática. Si el modelo es muy "angosto", entonces hay una pequeña cantidad de campos en él y, tras la normalización de algunos eventos, simplemente se perderán. SIEM con un conjunto de campos inicialmente fijo y dinámicamente no expandible a menudo tiene este problema.
Por otro lado, si hay demasiados campos, surgen problemas debido a la falta de comprensión en qué campo debe colocar ciertos datos del evento original. Esta situación conlleva la posibilidad de la aparición de duplicación semántica, cuando semánticamente los mismos datos del evento inicial encajan inmediatamente en varios campos. Esto se observa a menudo en soluciones en las que el conjunto de campos de esquema puede expandirse dinámicamente mediante cualquier módulo de normalización con el soporte de una nueva fuente.
Si tienes a mano un SIEM de "combate", mira tus eventos. ¿Con qué frecuencia durante la normalización utiliza campos adicionales reservados (cadena de dispositivo personalizada, campo de datos, etc.)? Muchos tipos de eventos con campos adicionales completados indican que está observando el primer problema. Ahora recuerde, o pregunte a sus colegas, ¿con qué frecuencia con el apoyo de una nueva fuente tuvieron que agregar un nuevo campo, ya que no había suficientes reservas? La respuesta a esta pregunta es un indicador del segundo problema.
Metodología de normalización de eventos
Es importante recordar quién y cómo normaliza los eventos, porque Juega un papel importante. Una parte de las fuentes es respaldada directamente por el desarrollador de soluciones SIEM, otra parte es el integrador que implementó SIEM por usted y otra parte es suya. Aquí es donde nos espera el siguiente problema: cada uno de los participantes interpreta el significado de los campos del esquema del evento a su manera y, por lo tanto, lleva a cabo la normalización de diferentes maneras. Por lo tanto, diferentes participantes pueden descomponer datos semánticamente idénticos en diferentes campos. Por supuesto, hay una serie de campos, cuyo nombre no permite una doble interpretación. Supongamos src_ip o dst_ip, pero incluso con ellos hay dificultades. Por ejemplo, en eventos de red, ¿es necesario cambiar src_ip a dst_ip al normalizar las conexiones entrantes y salientes dentro de la misma sesión?
Con base en lo anterior, existe la necesidad de crear una metodología clara para las fuentes de apoyo, en cuyo marco se indicaría claramente:
- ¿Cuáles son los campos del circuito para lo que se necesita?
- Qué tipos de datos corresponden a qué campos.
- Qué información es importante para nosotros en el marco de cada tipo de evento.
- ¿Cuáles son las reglas para completar los campos?
El modelo del objeto de protección y su mutación.
Como parte de la solución de la tarea, el objeto de protección es nuestro sistema automatizado (AS). Sí, es la AU en la definición de
GOST 34.003-90 , con todos sus procesos, personas y tecnologías. Este es un punto importante, volveremos más adelante en los siguientes artículos.
La palabra "mutación" no se elige por casualidad aquí. Recordemos que en biología la mutación se entiende como cambios persistentes en el genoma. ¿Qué es el genoma AC? En el marco de esta serie de artículos, bajo el genoma AS, comprenderé su arquitectura y estructura. Y los "cambios duraderos" no son más que el resultado del trabajo diario de los administradores de sistemas, ingenieros de redes, ingenieros de seguridad de la información. Bajo la influencia de estos cambios, el AC cambia de un estado a otro cada minuto. Algunos estados se caracterizan por un alto nivel de seguridad, otros menos. Pero, ahora para nosotros no importa.
Es importante comprender que el modelo de CA no es estático, cuyos parámetros se describen en la documentación técnica y de trabajo, sino un objeto vivo y en constante mutación. SIEM, al construir el modelo del objeto de protección dentro de sí mismo, debe tener esto en cuenta y poder actualizarlo de manera oportuna y eficiente, manteniendo el ritmo de la mutación. Y, si queremos que las reglas de correlación "funcionen de fábrica", es necesario que tengan en cuenta estas mutaciones y siempre operen con la imagen más relevante del "mundo".
Metodología para desarrollar reglas de correlación
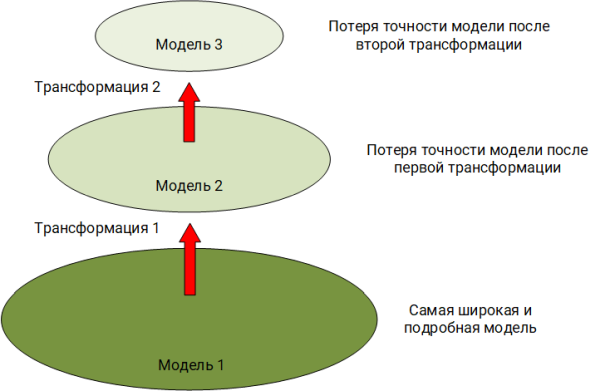
De la
"pirámide" presentada anteriormente
, está claro que al desarrollar reglas de correlación, nos vemos obligados a luchar por todos los problemas que se encuentran en los niveles inferiores. Al tratar con estos problemas, las reglas están dotadas de lógica adicional: filtrado adicional de eventos, verificación de valores vacíos, conversión de tipos de datos y transformación de estos datos (por ejemplo, extracción de un nombre de dominio del nombre de usuario de dominio completo), aislando información sobre quién interactúa con quién y con quién marco de eventos.
Después de todo esto, las reglas están rodeadas por una cantidad tan grande de expresiones de captura, búsqueda de subcadenas y expresiones regulares que la lógica de su trabajo se vuelve clara solo para sus autores y eso, hasta sus próximas vacaciones. Además, los cambios constantes en el sistema automatizado: las mutaciones requieren una actualización periódica de las reglas contra el fraude. ¿Una foto familiar?
Al final
Como parte de esta serie de artículos, trataremos de comprender cómo hacer que las reglas de correlación funcionen de forma inmediata.
Para resolver el problema tenemos que enfrentar los siguientes problemas:
- Pérdida de datos durante la transformación del modelo "mundial" en la etapa de normalización.
- La falta de una definición clara de una metodología de normalización.
- Mutación permanente del objeto de protección bajo la influencia de personas y procesos.
- Falta de metodología para escribir reglas de correlación.
Muchos de estos problemas se encuentran en el plano de construir el esquema de eventos correcto (un conjunto de campos y el proceso de normalización de eventos), la base de las reglas de correlación. Otra parte de los problemas se resuelve con métodos organizativos y metodológicos. Si logramos encontrar una solución a estos problemas, entonces el concepto de trabajar fuera de las reglas de la caja tendrá un amplio efecto positivo y elevará la experiencia establecida por los fabricantes de SIEM a un nuevo nivel.
Que sigue En el próximo artículo, trataremos de lidiar con la pérdida de datos durante la transformación del modelo "mundial" y pensaremos cómo debería ser el conjunto de campos necesarios para nuestra tarea: un diagrama.
Serie de artículos:Profundidades SIEM: correlaciones listas para usar. Parte 1: ¿marketing puro o un problema sin solución? (
Este artículo )
Profundidades SIEM: correlaciones listas para usar. Parte 2. Esquema de datos como reflejo del modelo del "mundo"Profundidades SIEM: correlaciones listas para usar. Parte 3.1. Categorización de eventosProfundidades SIEM: correlaciones listas para usar. Parte 3.2. Metodología de normalización de eventosProfundidades SIEM: correlaciones listas para usar. Parte 4. Modelo del sistema como contexto de reglas de correlaciónProfundidades SIEM: correlaciones listas para usar. Parte 5. Metodología para desarrollar reglas de correlación