 Recientemente hablamos sobre por qué se nos ocurrió nuestro propio segmentador RFM, que ayuda a hacer análisis RFM en 20 segundos , y mostramos cómo usar sus resultados en marketing.
Recientemente hablamos sobre por qué se nos ocurrió nuestro propio segmentador RFM, que ayuda a hacer análisis RFM en 20 segundos , y mostramos cómo usar sus resultados en marketing.
Ahora contamos cómo está organizado.
Tarea: escribir un nuevo algoritmo de análisis RFM
No estábamos satisfechos con los enfoques disponibles para el análisis RFM. Por lo tanto, decidimos hacer nuestro propio segmentador, que:
- Funciona de forma completamente automática.
- Construye de 3 a 15 segmentos.
- Se adapta a cualquier campo de actividad del cliente (no importa de qué se trate: una tienda de flores o herramientas eléctricas).
- Determina el número y la ubicación de los segmentos en función de los datos disponibles y no de parámetros predefinidos que no pueden ser universales.
- Selecciona segmentos para que siempre tengan consumidores (a diferencia de algunos enfoques cuando algunos segmentos están vacíos).
¿Cómo resolver el problema?
Cuando nos dimos cuenta de la tarea, nos dimos cuenta de que estaba más allá del poder del hombre y pedimos ayuda a la inteligencia artificial. Para enseñarle al automóvil a dividir a los consumidores en segmentos, decidimos usar métodos de agrupamiento .
Los métodos de agrupamiento se utilizan para buscar una estructura en los datos y seleccionar grupos de objetos similares en ellos, justo lo que necesita para el análisis RFM.
La agrupación se refiere a los métodos de aprendizaje automático de la clase " aprender sin un maestro ". Una clase se llama así porque hay datos, pero nadie sabe qué hacer con ellos, por lo tanto, no puede enseñar una máquina.
No pudimos encontrar empresas que utilizan este enfoque en el mercado. Aunque encontraron un artículo en el que el autor realiza investigaciones científicas sobre este tema. Pero, como entendimos por nuestra propia experiencia, de la ciencia a la empresa no es en absoluto un paso.
Etapa 1. Procesamiento de datos
Los datos deben estar preparados para la agrupación.
Primero, los verificamos en busca de valores incorrectos: valores negativos, etc.
Luego eliminamos las emisiones: consumidores con características inusuales. Hay pocos de ellos, pero pueden afectar en gran medida el resultado, y no para mejor. Para separarlos, utilizamos un método especial de aprendizaje automático: Factor de valor atípico local .

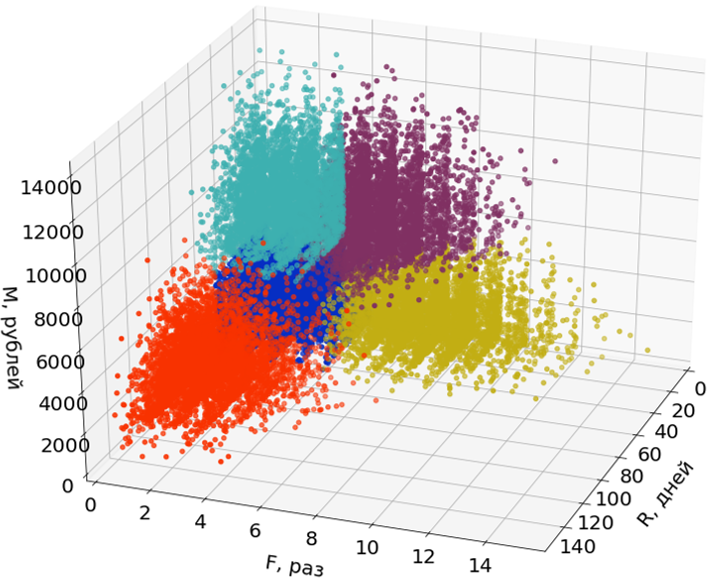
Aquí en las imágenes utilizo solo dos de las tres dimensiones (R y M) de tres para facilitar la percepción.
Las emisiones no participan en la construcción de segmentos, pero se les asignan después de que se forman los segmentos.
Etapa 2. Agrupación de consumidores
Aclararé la terminología: por conglomerados me refiero a grupos de objetos que se obtienen como resultado del uso de algoritmos de conglomeración y segmentos como el resultado final, es decir, el resultado del análisis RFM.
Hay varias docenas de algoritmos de agrupamiento. Se pueden encontrar ejemplos de algunos de ellos en la documentación del paquete scikit-learn .
Probamos ocho algoritmos con varias modificaciones. La mayoría no tenía suficiente memoria. O el tiempo de su trabajo tendió al infinito. Casi todos los algoritmos que técnicamente lograron hacer frente a la tarea dieron resultados terribles: por ejemplo, el popular DBSCAN consideró el 55% de los objetos como ruido y dividió el resto en grupos de 4302.
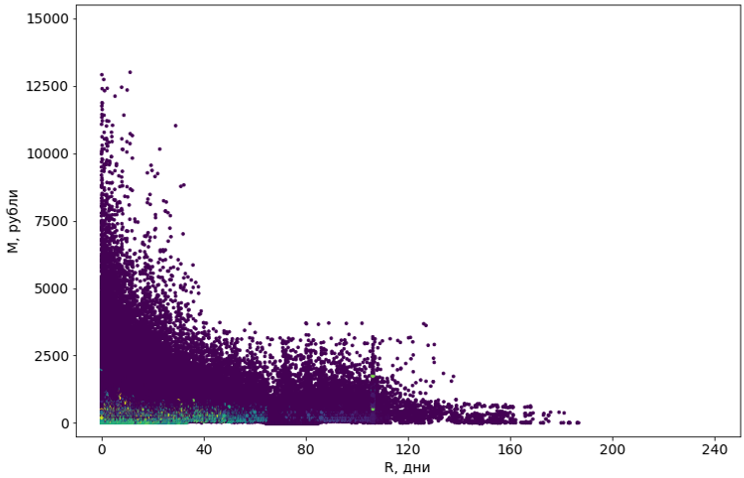
Los objetos violetas se definen como "ruido"
Como resultado, elegimos el algoritmo K-medias (K-medias) porque no busca grupos de puntos, sino que simplemente agrupa los puntos alrededor de los centros. Al final resultó que, esta fue la decisión correcta.
Pero primero, resolvimos algunos problemas:
Inestabilidad Este es un problema conocido con la mayoría de los algoritmos de agrupación, incluidos los K-Means. La inestabilidad radica en el hecho de que con lanzamientos repetidos, los resultados pueden ser diferentes, ya que se utiliza un elemento de aleatoriedad.
Por lo tanto, agrupamos muchas veces, y luego agrupamos de nuevo, pero ya los centros de los grupos. Como centros finales de los grupos, tomamos los centros de los grupos resultantes (es decir, grupos formados por los centros de los primeros grupos).
El número de grupos. Los datos pueden ser diferentes y la cantidad de clústeres también debe ser diferente.
Para encontrar el número óptimo de clústeres para cada base de clientes, realizamos clústeres con un número diferente de clústeres y luego seleccionamos el mejor resultado .
Velocidad. El algoritmo K-means no es muy rápido, pero sí aceptable (unos minutos para una base promedio de varios cientos de miles de consumidores). Sin embargo, lo ejecutamos muchas veces: en primer lugar, para aumentar la estabilidad y, en segundo lugar, para seleccionar el número de clústeres. Y el tiempo de funcionamiento está aumentando mucho.
Para la aceleración, utilizamos una modificación del Mini Batch K-Means . Recalcula los centros de clúster en cada iteración no para todos los objetos, sino solo para una pequeña submuestra. La calidad cae bastante, pero el tiempo se reduce significativamente.
Tan pronto como resolvimos estos problemas, la agrupación comenzó a proceder con éxito.
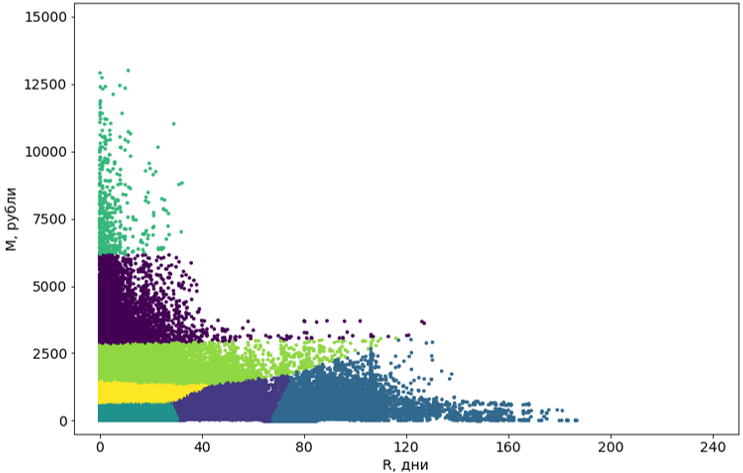
Etapa 3. Post-procesamiento de clusters
Los grupos obtenidos usando el algoritmo deben llevarse a una forma que sea conveniente para la percepción.
Primero, convertimos estos grupos de curvas en rectangulares. En realidad, esto los convierte en segmentos. La rectangularidad de los segmentos es un requisito de nuestro sistema y, además, agrega comprensibilidad a los segmentos mismos. Para convertir, utilizamos otro algoritmo de aprendizaje automático: el árbol de decisión .
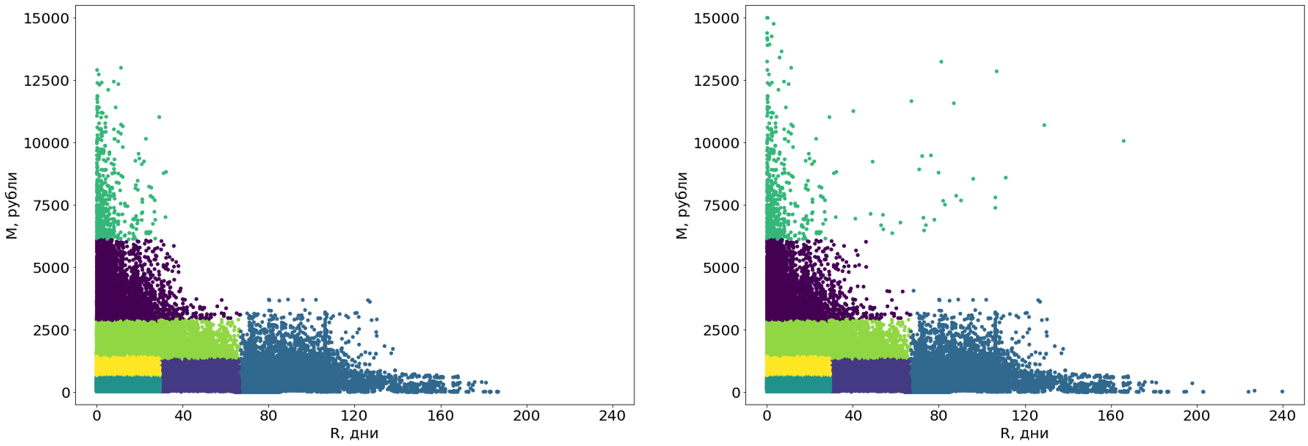
El árbol de decisión se basa en datos libres de valores atípicos, y los valores atípicos se asignan a los segmentos terminados.
En segundo lugar, hicimos otra cosa interesante: la descripción de los segmentos. Un algoritmo especial, que usa un diccionario, describe cada segmento en ruso en vivo, para que las personas no sientan anhelo al mirar números sin alma.

Resultados de prueba
El producto esta listo. Pero antes de comenzar a vender, debe probarse. Es decir, verifique si el análisis de RFM se realiza según lo previsto.
Sabemos que la mejor manera de entender si hemos hecho algo que vale la pena es descubrir qué tan útil es el análisis para nuestros clientes. Y lo haremos. Pero esto es mucho tiempo, y los resultados serán más tarde, y queremos saber qué tan exitosamente enfrentamos la tarea, ahora.
Por lo tanto, como una métrica más simple y rápida, utilizamos el método del "grupo de control histórico".
Para hacer esto, tomamos varias bases de datos y las segmentamos usando análisis RFM en diferentes puntos en el pasado: una base de datos para el estado hace seis meses, la otra hace un año, etc.
Con base en cada segmentación para cada base, creamos nuestro pronóstico de las acciones del cliente desde el momento seleccionado hasta el presente. Luego compararon estos pronósticos con el comportamiento real de los clientes.

Ejemplo de prueba en un grupo de control histórico con un período de control de seis meses.
En la imagen:
- Las columnas R, F y M indican convencionalmente los límites de los segmentos a lo largo de cada eje. Este es el resultado de la segmentación de bases en la forma en que era hace medio año.
- La columna "Tamaño" muestra el tamaño del segmento hace seis meses en relación con el tamaño total de la base de datos.
- Las columnas "Probabilidad de compra" y "Cantidad" son datos sobre el comportamiento real del consumidor durante los próximos seis meses.
- La probabilidad de compra se define como la relación entre el número de consumidores del segmento que realizó una compra y el número total de consumidores en el segmento.
- Cantidad: la cantidad total gastada por los consumidores del segmento en relación con la cantidad gastada por los consumidores de todos los segmentos.
Los resultados son consistentes. Por ejemplo, los clientes de segmentos para los que predijimos una alta frecuencia de compras realmente compraron con más frecuencia.
Aunque no podemos garantizar el funcionamiento correcto del algoritmo en un 100 por ciento basado en tales pruebas, decidimos que fue exitoso.
Que entendemos
El aprendizaje automático es realmente capaz de ayudar a una empresa a resolver problemas irresolubles o muy poco resueltos.
Pero el verdadero desafío no es la competencia de Kaggle. Aquí, además de lograr una mejor calidad en una métrica dada, debe pensar en cuánto funcionará el algoritmo, si será conveniente para las personas y, en general, si es necesario resolver el problema usando ML o puede encontrar una forma más simple.
Y finalmente, la falta de una métrica formal de calidad complica la tarea varias veces, porque es difícil evaluar correctamente el resultado.