En el mundo del aprendizaje automático, uno de los tipos de modelos más populares es el árbol decisivo y los conjuntos basados en ellos. Las ventajas de los árboles son: facilidad de interpretación, no hay restricciones sobre el tipo de dependencia inicial, requisitos flexibles sobre el tamaño de la muestra. Los árboles también tienen un defecto importante: la tendencia a la reentrenamiento. Por lo tanto, casi siempre los árboles se combinan en conjuntos: bosque aleatorio, aumento de gradiente, etc. Las tareas teóricas y prácticas complejas son componer árboles y combinarlos en conjuntos.
En el mismo artículo, se considerará el procedimiento para generar predicciones a partir de un modelo de conjunto de árboles ya entrenado, las características de implementación en las populares
XGBoost aumento de gradiente
XGBoost y
LightGBM . Y también el lector se familiarizará con la biblioteca de
leaves para Go, que le permite hacer predicciones para conjuntos de árboles sin usar la API C de las bibliotecas originales.
¿De dónde crecen los árboles?
Considere primero las disposiciones generales. Suelen trabajar con árboles, donde:
- La partición en un nodo ocurre de acuerdo con una característica
- árbol binario: cada nodo tiene un descendiente izquierdo y derecho
- en el caso de un atributo material, la regla de decisión consiste en comparar el valor del atributo con un valor umbral
Tomé esta ilustración de la
documentación de XGBoost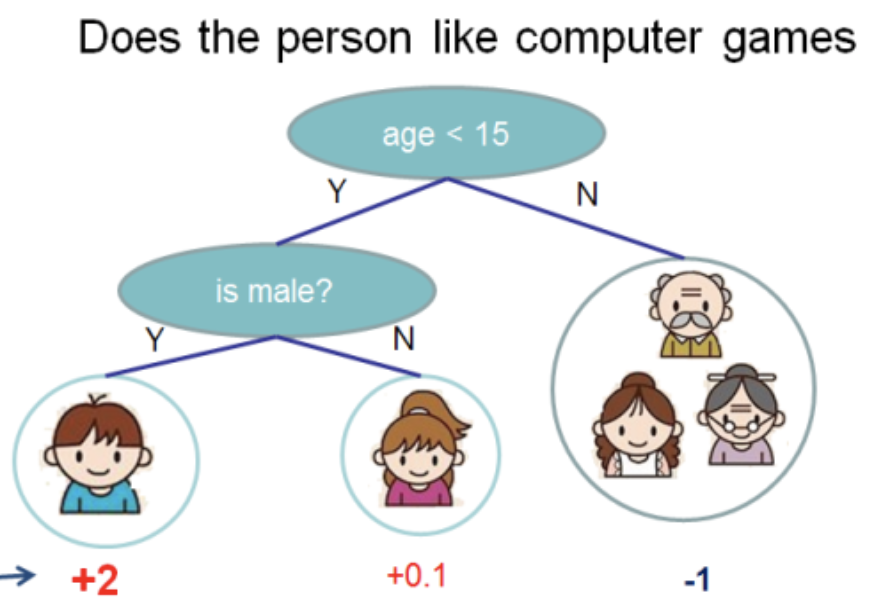
En este árbol tenemos 2 nodos, 2 reglas de decisión y 3 hojas. Debajo de los círculos, se indican los valores: el resultado de aplicar el árbol a algún objeto. Por lo general, se aplica una función de transformación al resultado de calcular un árbol o conjunto de árboles. Por ejemplo, un
sigmoide para un problema de clasificación binaria.
Para obtener predicciones del conjunto de árboles obtenido mediante el aumento de gradiente, debe agregar los resultados de las predicciones de todos los árboles:
double pred = 0.0; for (auto& tree: trees) pred += tree->Predict(feature_values);
En adelante, habrá
C++ , como Es en este lenguaje donde se
XGBoost y
LightGBM . Omitiré detalles irrelevantes e intentaré dar el código más conciso.
Luego, considere lo que está oculto en
Predict y cómo está estructurada la estructura de datos del árbol.
Árboles XGBoost
XGBoost tiene varias clases (en el sentido de OOP) de árboles. Hablaremos sobre
RegTree (ver
include/xgboost/tree_model.h ), que, según la documentación, es el principal. Si deja solo los detalles importantes para las predicciones, los miembros de la clase se ven lo más simples posible:
class RegTree {
La regla de
GetNext se implementa en la función
GetNext . El código se modifica ligeramente, sin afectar el resultado de los cálculos:
Dos cosas siguen a partir de aquí:
RegTree solo funciona con atributos reales (tipo float )- los valores característicos omitidos son compatibles
La pieza central es la clase
Node . Contiene la estructura local del árbol, la regla de decisión y el valor de la hoja:
class Node { public:
Se pueden distinguir las siguientes características:
- las hojas se representan como nodos para los cuales
cleft_ = -1 - el campo
info_ representa como union , es decir dos tipos de datos (en este caso el mismo) comparten una pieza de memoria dependiendo del tipo de nodo - el bit más significativo en
sindex_ es responsable de dónde se omite el objeto cuyo valor de atributo
Para poder rastrear la ruta desde llamar al método
RegTree::Predict hasta recibir la respuesta, le daré las dos funciones que faltan:
float RegTree::Predict(const RegTree::FVec& feat, unsigned root_id) const { int pid = this->GetLeafIndex(feat, root_id); return nodes_[pid].leaf_value; } int RegTree::GetLeafIndex(const RegTree::FVec& feat, unsigned root_id) const { auto pid = static_cast<int>(root_id); while (!nodes_[pid].IsLeaf()) { unsigned split_index = nodes_[pid].SplitIndex(); pid = this->GetNext(pid, feat.Fvalue(split_index), feat.IsMissing(split_index)); } return pid; }
En la función
GetLeafIndex bajamos los nodos del árbol en un bucle hasta que llegamos a la hoja.
LightGBM Trees
LightGBM no tiene una estructura de datos para el nodo. En cambio, la estructura de datos del
Tree Tree (
include/LightGBM/tree.h ) contiene matrices de valores, donde el número de nodo se usa como índice. Los valores en las hojas también se almacenan en matrices separadas.
class Tree {
LightGBM admite características categóricas. El soporte se proporciona utilizando un campo de bits, que se almacena en
cat_threshold_ para todos los nodos. En
cat_boundaries_ almacena a qué nodo corresponde la parte del campo de bits. El campo de
threshold_ para el caso categórico se convierte en
int y corresponde al índice en
cat_boundaries_ para buscar el comienzo del campo de bits.
Considere la regla decisiva para un atributo categórico:
int CategoricalDecision(double fval, int node) const { uint8_t missing_type = GetMissingType(decision_type_[node]); int int_fval = static_cast<int>(fval); if (int_fval < 0) { return right_child_[node];; } else if (std::isnan(fval)) {
Se puede ver que, dependiendo del
missing_type valor
NaN reduce automáticamente la solución a lo largo de la rama derecha del árbol. De lo contrario,
NaN se reemplaza por 0. La búsqueda de un valor en un campo de bits es bastante simple:
bool FindInBitset(const uint32_t* bits, int n, int pos) { int i1 = pos / 32; if (i1 >= n) { return false; } int i2 = pos % 32; return (bits[i1] >> i2) & 1; }
es decir, por ejemplo, para el atributo categórico
int_fval=42 verifica si el bit 41 (numeración desde 0) está configurado en la matriz.
Este enfoque tiene un inconveniente significativo: si un atributo categórico puede tomar valores grandes, por ejemplo 100500, entonces para cada regla de decisión para este atributo se creará un campo de bits de hasta 12564 bytes de tamaño.
Por lo tanto, es conveniente renumerar los valores de los atributos categóricos para que vayan continuamente de 0 al valor máximo .
Por mi parte, hice cambios explicativos a
LightGBM y los
acepté .
Tratar con atributos físicos no es muy diferente de
XGBoost , y
XGBoost esto por brevedad.
hojas - biblioteca para predicciones en Go
XGBoost y
LightGBM bibliotecas muy potentes para construir modelos de
LightGBM gradiente en árboles de decisión. Para usarlos en un servicio de back-end, donde se necesitan algoritmos de aprendizaje automático, es necesario resolver las siguientes tareas:
- Entrenamiento periódico de modelos fuera de línea
- Entrega de modelos en el servicio de backend
- Modelos de encuestas en línea
Para escribir un servicio de back-end cargado,
Go es un idioma popular.
XGBoost o
LightGBM través de la API de C y cgo no es la solución más fácil: la compilación del programa es complicada, debido a un manejo descuidado, puede detectar
SIGTERM , problemas con la cantidad de subprocesos del sistema (OpenMP dentro de las bibliotecas frente a subprocesos de tiempo de ejecución).
Así que decidí escribir una biblioteca en
Go puro para predicciones usando modelos construidos en
XGBoost o
LightGBM . Se llama
leaves .

Características clave de la biblioteca:
- Para modelos
LightGBM
- Lectura de modelos desde un formato estándar (texto)
- Soporte para atributos físicos y categóricos.
- Soporte de valores perdidos
- Optimización del trabajo con variables categóricas.
- Optimización de predicciones con estructuras de datos solo de predicciones
- Para modelos
XGBoost
- Lectura de modelos desde un formato estándar (binario)
- Soporte de valores perdidos
- Optimización de predicciones
Aquí hay un programa
Go mínimo que carga un modelo desde el disco y muestra una predicción:
package main import ( "bufio" "fmt" "os" "github.com/dmitryikh/leaves" ) func main() {
La biblioteca API es mínima. Para usar el modelo
XGBoost simplemente llame al método
leaves.XGEnsembleFromReader lugar del anterior. Se pueden hacer predicciones en lotes llamando a los
model.PredictCSR PredictDense o
model.PredictCSR . Se pueden encontrar más escenarios de uso en las
pruebas de hojas .
A pesar del hecho de que
Go funciona más lento que
C++ (principalmente debido a un mayor tiempo de ejecución y verificaciones de tiempo de ejecución), gracias a una serie de optimizaciones, fue posible lograr una velocidad de predicción comparable a llamar a la API C de las bibliotecas originales.
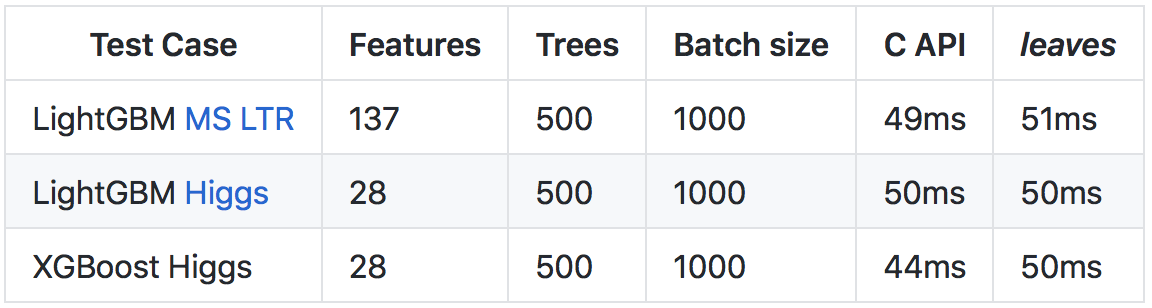
Más detalles sobre los resultados y el método de comparación se encuentran en el
repositorio de github .
Ver la raíz
Espero que este artículo abra la puerta a la implementación de árboles en las
LightGBM XGBoost y
LightGBM . Como puede ver, las construcciones básicas son bastante simples, y animo a los lectores a aprovechar el código abierto para estudiar el código cuando haya preguntas sobre cómo funciona.
Para aquellos que estén interesados en el tema del uso de modelos de aumento de gradiente en sus servicios en el idioma Go, les recomiendo que se familiaricen con la biblioteca de
hojas . Usando
leaves puede usar con bastante facilidad soluciones de vanguardia en aprendizaje automático en su entorno de producción, casi sin perder velocidad en comparación con las implementaciones originales de C ++.
Buena suerte