 Traducción del artículo: Reglas prácticas de los experimentadores
Traducción del artículo: Reglas prácticas de los experimentadoresLos propietarios de portales web, desde los más pequeños hasta los más grandes, como Amazon, Facebook, Google, LinkedIn, Microsoft y Yahoo, están tratando de mejorar sus sitios optimizando varias métricas, desde el número de tiempos de reutilización hasta su tiempo e ingresos. Nos han atraído miles de experimentos en Amazon, Booking.com, LinkedIn y Microsoft, y queremos compartir las siete reglas generales que dedujimos de estos experimentos y sus resultados. Creemos que estas reglas son ampliamente aplicables tanto al optimizar la web como durante el análisis fuera de los experimentos de control. Aunque hay excepciones.
Para que estas reglas sean más significativas, daremos ejemplos reales de nuestro trabajo, la mayoría de los cuales se publicarán por primera vez. Algunas reglas se expresaron anteriormente (por ejemplo, "La velocidad importa"), pero las complementamos con suposiciones que se pueden usar en el diseño de experimentos, y compartimos ejemplos adicionales que mejoraron nuestra comprensión de dónde la velocidad es especialmente importante y en qué áreas de la web páginas no es crítico.
Este artículo tiene dos propósitos.
Primero : enseñe a los experimentadores las reglas del buen gusto, lo que ayudará a optimizar los sitios.
Segundo : proporcionar a la comunidad KDD nuevos temas para explorar la aplicabilidad de estas reglas, su mejora y la existencia de excepciones.
Introduccion
Los propietarios de portales web desde los gigantes más pequeños hasta los más grandes están tratando de mejorar sus sitios. Las empresas líderes utilizan pruebas de evaluación comparativa (como las pruebas A / B) para evaluar los cambios. Esto lo hacen Amazon [1], Ebay, Etsy [2], Facebook [3], Google [4], Groupon, Intuit [5], LinkedIn [6], Microsoft [7], Netflix [8], ShopDirect [9] , Yahoo y Zynga [10].
Hemos adquirido experiencia en la optimización de sitios web, trabajando con muchas empresas, incluidas Amazon, Booking.com, LinkedIn y Microsoft. Por ejemplo, Bing y LinkedIn realizan cientos de experimentos paralelos en un momento dado [6; 11] Debido a la variedad y multiplicidad de experimentos en los que participamos, se han desarrollado reglas generales, que discutiremos aquí. Están confirmados por proyectos reales, pero hay excepciones a cualquier regla (también hablaremos de ellos). Por ejemplo, la regla de 72 es un buen ejemplo de una regla práctica útil en el campo financiero. Afirma que necesita multiplicar el porcentaje de crecimiento anual por 72 para determinar aproximadamente cuántos años duplicará su inversión. En situaciones normales, la regla es muy útil (cuando la tasa de interés fluctúa entre 4 y 12%), pero en otras áreas no funciona.
Dado que estas reglas se formularon de acuerdo con los resultados de los experimentos de control, son muy aplicables para la optimización del sitio y el análisis simple, incluso si los experimentos de control no se llevan a cabo en los sitios (aunque en este caso no será posible evaluar con precisión el efecto de los cambios realizados).
Lo que encontrarás en este artículo:
- Reglas útiles para experimentar con sitios web. Todavía se están desarrollando, y necesitamos evaluar adicionalmente la amplitud de su aplicación y descubrir si hay nuevas excepciones a estas reglas. La importancia de usar experimentos de control se discutió en el artículo "Experimentos controlados en línea a gran escala" [11]
- Mejora a las reglas anteriores. Observaciones como "la velocidad importa" ya han sido expresadas por otros autores [12; 13] y nosotros [14]. Pero hicimos algunas suposiciones al diseñar el experimento, y hablaremos sobre estudios que demuestran que en algunas áreas de la página, la velocidad es especialmente crítica, y en otras no. También mejoramos la antigua regla de "miles de usuarios", que responde a la pregunta de cuántas personas se necesitan para realizar un experimento de control.
- Se publican ejemplos reales de experimentos de control por primera vez. En Amazon, Bing y LinkedIn, los experimentos de control se utilizan como parte del proceso de desarrollo [7; 11]. Muchas empresas que aún no utilizan experimentos de control pueden beneficiarse enormemente de ejemplos adicionales de trabajo con cambios con la introducción de nuevos paradigmas de desarrollo [7, 15]. Las empresas que ya usan experimentos de control se beneficiarán de los conocimientos descritos.
Controle los experimentos, los datos y el proceso de extracción de conocimiento de los datos.
Discutiremos aquí los experimentos de control en línea en los que los usuarios se dividen en grupos al azar (por ejemplo, para mostrar varias opciones de sitio). Además, la división se realiza de forma continua, es decir, cada usuario tendrá la misma experiencia durante todo el experimento (siempre se le mostrará la misma versión del sitio). Se registra la interacción del usuario con el sitio (clics, visitas a la página, etc.), y las métricas clave (CTR, número de sesiones por usuario, ingresos del usuario) se calculan sobre la base. Se realizan pruebas estadísticas para analizar las métricas calculadas. Y si la diferencia entre las métricas del grupo de control (que vio la versión anterior del sitio) y la experimental (que vio la nueva versión) del grupo es estadísticamente significativa, entonces también podemos decir con alta probabilidad que los cambios realizados afectarán las métricas observadas en el experimento. Los detalles se describen en "Experimentos controlados en la web: encuesta y guía práctica" [16].
Participamos en muchos experimentos cuyos resultados fueron incorrectos, y dedicamos mucho tiempo y esfuerzo a comprender las razones y encontrar formas de solucionarlo. Muchas trampas se describen en los artículos [17] y [18]. Queremos resaltar algunas preguntas sobre los datos utilizados en la realización de experimentos de control en línea y sobre el proceso para obtener conocimiento de estos datos:
- La fuente de datos son los sitios reales de los que hablamos anteriormente. No habrá información generada artificialmente. Todos los ejemplos se basan en la interacción real del usuario, y las métricas se calculan después de eliminar los bots [16].
- Los grupos de usuarios en los ejemplos se toman al azar de la distribución uniforme de la audiencia objetivo (es decir, usuarios que, por ejemplo, deben hacer clic en el enlace para ver los cambios que se están estudiando) [16]. El método de identificación del usuario depende del sitio: si el usuario no ha iniciado sesión, se usan cookies, y si está conectado, se usa su inicio de sesión.
- Los tamaños de los grupos de usuarios, después de borrar los bots, varían de cientos de miles a millones (los valores exactos se indican en los ejemplos). En la mayoría de los experimentos, esto es necesario para que pequeñas diferencias en las métricas tengan una alta significación estadística.
- Los resultados observados fueron estadísticamente significativos con un valor de p <0.05, y usualmente incluso menos. Los resultados sorprendentes (en la regla 1) se reprodujeron al menos una vez más, de modo que el valor p acumulativo basado en la prueba de probabilidad acumulativa de Fisher tenía un valor mucho menor que el necesario.
- Cada experimento es nuestra experiencia personal, verificada por al menos uno de los autores por la presencia de dificultades estándar. Cada experimento se realizó durante al menos una semana. La participación de la audiencia que demostró las opciones del sitio fue estable durante todo el período del experimento (para evitar el efecto de la paradoja de Simpson) y las proporciones entre la audiencia que observamos durante el experimento coincidieron con las proporciones que establecimos cuando se lanzó el experimento [17].
Reglas prácticas para la experimentación.
Las primeras tres reglas se relacionan con el impacto de los cambios en las métricas clave:
- pequeños cambios pueden tener un gran impacto;
- el cambio rara vez tiene un gran efecto positivo;
- Es más probable que sus intentos de repetir los éxitos estelares anunciados por otros sean menos exitosos.
Las siguientes 4 reglas son independientes entre sí, pero cada una de ellas es muy útil.
Regla n. ° 1: los pequeños cambios pueden tener un GRAN impacto en las métricas clave
Cualquiera que se haya encontrado con la vida de los sitios sabe que cualquier pequeño cambio puede tener un gran impacto negativo en las métricas clave. Un pequeño error de JavaScript puede hacer que el pago sea imposible, y pequeños errores que destruyen la pila pueden hacer que el servidor se bloquee. Pero nos centraremos en los cambios positivos en las métricas clave. La buena noticia es que hay muchos ejemplos en los que un pequeño cambio ha llevado a una mejora en las métricas clave. Bryan Eisenberg escribió que eliminar el campo de entrada del cupón en el formulario de compra aumentó la conversión en un 1000% en el sitio web de Doctor Footcare [20]. Jared Spool escribió que eliminar el requisito de registrarse en el momento de la compra le valía a un gran minorista $ 300 millones por año [21].
Sin embargo, no vimos cambios tan significativos en el proceso de experimentos realizados personalmente. Pero vimos mejoras significativas de pequeños cambios con un rendimiento sorprendentemente alto de la inversión (alta relación de ganancia al costo del esfuerzo invertido).
También queremos señalar que estamos discutiendo un efecto estabilizado, no un "destello en el sol" o una característica con un efecto viral / noticioso especial. Un ejemplo de algo que no estamos buscando se describió en el libro ¡Sí!: 50 formas científicamente comprobadas de ser persuasivo [22]. Collen Szot, autor de un programa de televisión que rompió un récord de ventas de 20 años en el canal de televisión Couch Store, reemplazó tres palabras en la barra de información estándar, lo que condujo a un gran salto en el número de compras. En lugar de la frase "Los operadores están esperando, llame ahora", Collen dedujo "si los operadores están ocupados, vuelva a llamar". Los autores explican esto con la siguiente evidencia sociológica: los televidentes piensan que si la línea está ocupada, entonces las personas como ellos que ven el canal de noticias también llaman.
Si se usan regularmente trucos como el mencionado anteriormente, entonces su efecto se nivela, porque los usuarios se acostumbran. En experimentos de control en tales casos, el efecto desaparece rápidamente. Por lo tanto, le recomendamos que realice un experimento durante al menos dos semanas y controle la dinámica. Aunque en la práctica, tales cosas son raras [11; 18] Las situaciones en las que observamos un efecto positivo del impacto de tales cambios se asociaron con los sistemas de recomendación cuando el cambio en sí mismo produce un efecto a corto plazo o cuando los recursos finales se utilizan para el procesamiento.
Por ejemplo, cuando LinkedIn cambió el algoritmo de la función "personas que podría conocer", generó solo un aumento de una sola vez en las métricas de clics. Además, incluso si el algoritmo funcionó mucho mejor, entonces cada usuario conoce un número finito de personas, y después de contactar a sus conocidos principales, el efecto de cualquier algoritmo nuevo disminuirá.
Ejemplo: abrir enlaces en una nueva pestaña. Una serie de tres experimentos.
En agosto de 2008, MSN UK realizó un experimento para más de 900,000 usuarios, en el que el enlace a HotMail se abrió en una nueva pestaña (o una nueva ventana en navegadores antiguos). Anteriormente informamos [7] que este cambio mínimo (una línea de código) condujo a un aumento en la participación de los usuarios de MSN. El compromiso, medido en el número de clics por usuario en la página de inicio, creció un 8,9% entre los usuarios que hicieron clic en HotMail.
En junio de 2010, reprodujimos el experimento en una audiencia de 2.7 millones de usuarios de MSN en los Estados Unidos, y los resultados fueron similares. De hecho, este también es un ejemplo de una característica con el efecto de novedad. El primer día de implementación para todos los usuarios, el 20% de las revisiones fueron negativas. En la segunda semana, la proporción de insatisfechos cayó al 4%, y durante la tercera y cuarta semana, al 2%. La mejora en las métricas clave ha sido estable durante todo este tiempo.
En abril de 2011, MSN en los Estados Unidos realizó un experimento muy grande con más de 12 millones de usuarios que abrieron una página con resultados de búsqueda en una nueva pestaña. El compromiso, medido en clics en el usuario, creció un enorme 5%. Esta fue una de las mejores características relacionadas con la participación del usuario que MSN ha implementado, y fue un cambio trivial en el código.
Todos los principales motores de búsqueda experimentan con la apertura de enlaces en nuevas pestañas / ventanas, pero los resultados de la "página de resultados de búsqueda" no son tan impresionantes.
Ejemplo: color de fuente
En 2013, Bing realizó una serie de experimentos con colores de fuente. La opción ganadora se muestra en la Figura 1 a la derecha. Así es como se cambiaron los tres colores:
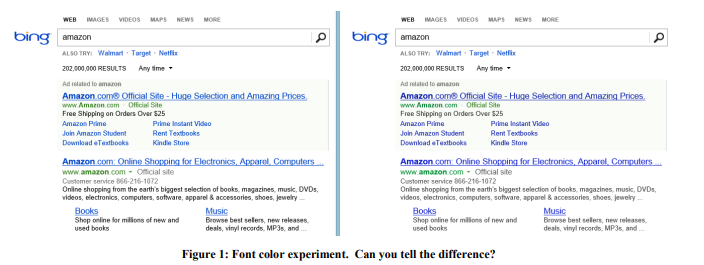
El costo de tal cambio? Barato: simplemente reemplace varios colores en el archivo CSS. Y el resultado del experimento mostró que los usuarios logran sus objetivos (una definición estricta de éxito es un secreto comercial) más rápido, y la monetización de esta revisión aumentó en más de $ 10 millones por año. Nos mostramos escépticos ante resultados tan sorprendentes, por lo que reproducimos este experimento en una muestra mucho mayor de 32 millones de usuarios, y los resultados se confirmaron.

Ejemplo: la oferta correcta en el momento adecuado
En 2004, la página de inicio de Amazon contenía dos espacios, cuyo contenido se probó automáticamente, de modo que el contenido que mejora mejor la métrica objetivo se muestra con mayor frecuencia. La oferta de obtener una tarjeta de crédito de Amazon llegó a la cima, lo cual fue sorprendente desde Esta oferta tenía muy pocos clics por impresión. Pero el hecho es que esta aplicación era muy rentable, por lo tanto, a pesar del pequeño CTR, el valor esperado era muy alto. ¿Pero si se eligió un lugar para tal anuncio? No! Como resultado, la propuesta, junto con un simple ejemplo del beneficio, se trasladó al carrito de compras que el usuario ve después de agregar el producto. Por lo tanto, la ventaja de esta propuesta se enfatizó en el ejemplo de cada producto. Si el usuario ha agregado productos a la cesta, esta es una intención clara de hacer una compra y es hora de tal oferta.

Un experimento de control mostró que un cambio tan simple traía decenas de millones de dólares al año.
Ejemplo: antivirus
La publicidad es un negocio rentable, y el software "gratuito" instalado por los usuarios a menudo contiene una parte maliciosa que obstruye las páginas con anuncios. Por ejemplo, la Figura 2 muestra cómo se ve la página de resultados de Bing para un usuario con un programa malicioso que ha agregado muchos anuncios a la página (resaltados en rojo).
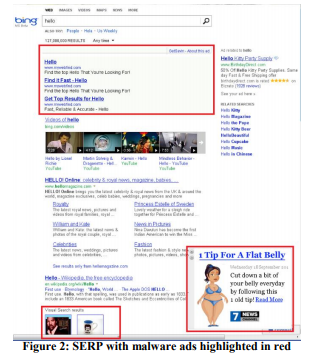
Los usuarios generalmente ni siquiera se dan cuenta de que tanta publicidad no se muestra en el sitio que visitan, sino en el código malicioso que instalaron accidentalmente. El experimento fue difícil de implementar, pero ideológicamente relativamente simple: cambiar los procedimientos básicos que modifican el DOM y limitar las aplicaciones que pueden modificar la página. El experimento se realizó a más de 3.8 millones de usuarios cuyas computadoras tenían código de terceros que editaba el DOM. En el grupo de prueba, estos cambios fueron bloqueados. Los resultados mostraron una mejora en todas las métricas clave, incluida una guía como el número de sesiones por usuario, es decir la gente vino al sitio más a menudo. Además, los usuarios completaron sus tareas con más éxito y más rápido, y los ingresos anuales aumentaron en varios millones de dólares. La velocidad de carga de la página, que discutiremos en la regla No. 4, ha disminuido en cientos de milisegundos para las páginas afectadas por el experimento.
Otros dos pequeños cambios en Bing, que son estrictamente confidenciales, tardaron días en desarrollarse, y cada uno condujo a un aumento en los ingresos por publicidad de casi $ 100 millones al año. En un informe trimestral de Microsoft en octubre de 2013, dijo: "Los ingresos por publicidad de la búsqueda han crecido un 47% debido a las mayores ganancias de cada búsqueda y cada página". Esos dos cambios hicieron una contribución significativa al mencionado crecimiento de ganancias.
Después de estos ejemplos, puede pensar que las organizaciones deberían centrarse en muchos pequeños cambios. Pero a continuación verá que este no es el caso en absoluto. Sí, los brotes ocurren sobre la base de pequeños cambios, pero son muy raros e inesperados: en Bing, probablemente uno de cada 500 experimentos logra un ROI tan alto y un resultado positivo reproducible. No afirmamos que estos resultados sean reproducibles en otros dominios, solo queremos transmitir la idea: vale la pena realizar experimentos simples y, en última instancia, puede conducir a un gran avance.
El peligro que surge al enfocarse en pequeños cambios es el incrementalismo: una organización que se respete a sí misma debe tener un conjunto de cambios con un ROI potencialmente alto, pero al mismo tiempo, debe haber varios cambios importantes para alcanzar el gran premio [23].
Regla número 2: los cambios rara vez tienen un gran impacto positivo en las métricas clave
Como dijo Al Pacino en la película Todos los domingos, la victoria se da centímetro a centímetro. Cientos y miles de experimentos se realizan anualmente en sitios como Bing. La mayoría falla y los que tienen éxito afectan la métrica clave en un 0.1% -1.0%, agregando una caída al impacto general. Los pequeños cambios con gran efecto descritos en la regla anterior suceden, pero son raros.
Es importante tener en cuenta dos cosas:
- Las métricas clave no son algo específico relacionado con una característica individual que se puede mejorar fácilmente, sino una métrica que es importante para toda la organización: por ejemplo, el número de sesiones por usuario [18] o el tiempo para alcanzar el objetivo del usuario [24].
Al desarrollar una función, es muy fácil mejorar significativamente el número de clics en esta función (u otra métrica de función) simplemente resaltándola o haciéndola más grande. Pero para aumentar el CTR de toda la página o toda la experiencia del usuario, aquí es donde está el desafío. La mayoría de las funciones solo generan clics en la página, redistribuyéndolas entre diferentes áreas. - Las métricas deben dividirse en pequeños segmentos, por lo que son mucho más fáciles de optimizar. Por ejemplo, ¿puede un equipo mejorar fácilmente las métricas para consultas climáticas en Bing o comprar programas de televisión en Amazon? agregando una buena herramienta de comparación. Sin embargo, una mejora del 10 por ciento en las métricas clave se disolverá en las métricas de todo el producto debido al tamaño del segmento. Por ejemplo, una mejora del 10 por ciento en un segmento del 1 por ciento afectará a todo el proyecto en aproximadamente un 0,1% (aproximadamente, porque si las métricas del segmento son diferentes del promedio, entonces el efecto también puede ser diferente).
La importancia de esta regla es grande porque ocurren errores falsos positivos durante los experimentos. Tienen dos tipos de razones:
- Los primeros son causados por las estadísticas. Si realizamos miles de experimentos por año, entonces la probabilidad de un error falso positivo de 0.05 lleva al hecho de que para una métrica fija obtendremos un resultado falso positivo cientos de veces. Y si usamos varias métricas que no están correlacionadas entre sí, entonces este resultado solo se intensifica. Incluso los sitios grandes como Bing no tienen suficiente tráfico para aumentar la sensibilidad y sacar conclusiones con un valor p más bajo para métricas como el número de sesiones por usuario.
- , , .
[11]. [25;26]. , , p-value 0,05 - .
:
Si tenemos una probabilidad preliminar de éxito igual a ⅓ (como dijimos en [7], este es el valor promedio entre los experimentos en Microsoft), entonces la probabilidad posterior de un experimento estadísticamente significativo verdaderamente positivo es del 89%. Y si el experimento es uno de los que mencionamos en la primera regla, cuando solo 1 de cada 500 contiene una solución innovadora, entonces la probabilidad cae al 3.1%.
Una consecuencia divertida de esta regla es el hecho de que aferrarse a alguien es mucho más fácil que desarrollarse solo. Las decisiones tomadas en una empresa que se centra en la significación estadística tienen más probabilidades de tener un efecto positivo. Por ejemplo, si tenemos una tasa de éxito de experimentos del 10-20%, entonces si tomamos las pruebas de aquellas características que tuvieron éxito y se lanzaron a la batalla en otros motores de búsqueda, entonces nuestro nivel de éxito será mayor. Lo contrario también es cierto: otros motores de búsqueda también deben probar y poner en práctica las cosas que Bing ha implementado.
Con experiencia, hemos aprendido a no confiar en resultados que parecen demasiado buenos para ser verdad. Las personas reaccionan de manera diferente a diferentes situaciones. Sospechan que algo andaba mal y estudian los resultados negativos de los experimentos con sus excelentes características nuevas, hacen preguntas y profundizan en la búsqueda de las razones de este resultado. Pero si el resultado es simplemente positivo, la sospecha retrocede y las personas comienzan a celebrar, y no estudian más profundamente y no buscan anomalías.
Cuando los resultados son excepcionalmente excepcionales, estamos acostumbrados a seguir la ley de Twyman [27]: todo lo que parece interesante o diferente suele ser falso.
La ley de Twyman puede explicarse con inferencia bayesiana. En nuestra experiencia, sabíamos que un avance es una ocurrencia rara. Por ejemplo, varios experimentos mejoraron significativamente nuestra métrica guía, el número de sesiones por usuario. Imagine que la distribución que encontramos en los experimentos es normal, centrada en el punto 0 y con una desviación estándar de 0.25%. Si el experimento mostró + 2% al valor de la métrica clave, entonces llamamos a la ley de Twyman y decimos que este es un resultado muy interesante, que está a una distancia de 8 desviaciones estándar del promedio y tiene una probabilidad de
10-15 , excluyendo otros factores. Incluso con significación estadística, la expectativa preliminar es tan fuerte que pospondremos la celebración del éxito y profundizaremos en la búsqueda de la causa del error falso positivo del segundo tipo. La ley de Twyman a menudo se aplica para demostrar que
=NP . Hoy, ningún editor del sitio estará contento si recibe tal evidencia. Lo más probable es que responda de inmediato con una respuesta de plantilla: "en su prueba de que P = NP, se cometió un error en la página X".
Ejemplo: métrica en línea de la oficina sustituta
Cook y su equipo [17] hablaron sobre un experimento interesante que realizaron con Microsoft Office Online. El equipo probó un nuevo diseño de página en el que un botón destacaba fuertemente, llamando a pagar por el producto. La métrica clave que el equipo quería medir: la cantidad de compras por usuario. Pero el seguimiento de las compras reales requería modificar el sistema de facturación, y en ese momento era difícil de hacer. Luego, el equipo decidió utilizar la métrica "clics que conducen a una compra" y aplicar la fórmula
( ) * = , donde se realiza la conversión de clics a compra.
Para su sorpresa, en el experimento, el número de clics disminuyó en un 64%. Tales resultados impactantes forzaron un análisis más profundo de los datos, y resultó que la suposición de una conversión estable de clic a compra es falsa. La página experimental, que mostró el costo del producto, atrajo menos clics, pero los usuarios que hicieron clic en ella estaban mejor calificados y tuvieron una conversión mucho mayor de clic a compra.
Ejemplo: más clics desde una página lenta
Se ha agregado JavaScript a la página de resultados de búsqueda de Bing. Este script generalmente ralentizaba la página, por lo que todos esperaban ver un ligero impacto negativo en las métricas de interacción clave, como la cantidad de clics en un usuario. Pero los resultados mostraron lo contrario, ¡hubo más clics! [18] A pesar de la dinámica positiva, seguimos la ley de Twyman y resolvimos el enigma. Los registradores de clics se basan en balizas web y algunos navegadores no realizan una llamada si el usuario abandona la página. [28] Por lo tanto, JavaScript afectó la precisión del recuento de clics.
Ejemplo: Bing Edge
Durante varios meses en 2013, Bing cambió su Content Delivery Network de Akamai a su propia Bing Edge. Cambiar el tráfico a Bing Edge se ha combinado con muchas otras mejoras. Varios equipos informaron que mejoraron las métricas clave: el CTR de la página de inicio de Bing aumentó, las funciones comenzaron a usarse con más frecuencia y el flujo de salida comenzó a disminuir. Y resultó que todas estas mejoras estaban relacionadas con conteos de clics limpios: Bing Edge mejoró no solo la velocidad de la página, sino también la capacidad de entrega de clics. Para evaluar el efecto, lanzamos un experimento en el que el enfoque del faro para el seguimiento de clics fue reemplazado por un enfoque con una recarga de la página. Esta técnica se utiliza en publicidad y conduce a una ligera pérdida de clics, lo que ralentiza el efecto de cada clic. ¡Los resultados mostraron que el porcentaje de clics perdidos se redujo en más del 60%! Y la mayoría de los logros anunciados durante ese período fueron el resultado de una mejor entrega de clics.
Ejemplo: MSN Bing Search
La finalización automática es una lista desplegable que ofrece opciones para completar una solicitud mientras una persona la escribe. MSN planeó mejorar esta función con un algoritmo nuevo y mejorado (los equipos de desarrollo de funciones siempre están listos para explicar por qué su nuevo algoritmo es a priori mejor que el anterior, pero a menudo se frustran cuando ven los resultados de los experimentos). El experimento fue un gran éxito; el número de búsquedas que llegaron a Bing con MSN aumentó significativamente. Siguiendo nuestras reglas, comenzamos a comprender y descubrimos que cuando el usuario hacía clic en el mensaje, el nuevo código realizaba dos consultas de búsqueda (una de las cuales el navegador cerró de inmediato tan pronto como aparecieron los resultados de la búsqueda).
Por lo tanto, la explicación de muchos resultados positivos puede no ser tan emocionante. Y nuestra tarea es encontrar un impacto real en el usuario, y la regla de Twyman realmente ayudó en esto y en comprender muchos de los resultados experimentales.
Regla número 3. Su beneficio variará.
Hay muchos ejemplos documentados de experimentos de control exitosos. Por ejemplo, "
¿Qué prueba ganó? " Contiene cientos de ejemplos de pruebas A / B, y la lista se actualiza cada semana.
Aunque este es un gran generador de ideas, estos ejemplos tienen varios problemas:
- La calidad varía En estos estudios, alguien de una empresa habla sobre el resultado de una prueba A / B. ¿Hubo una evaluación experta? ¿Se realizó correctamente? ¿Hubo emisiones? ¿El valor p era lo suficientemente pequeño (vimos pruebas A / B publicadas con un valor p mayor que 0.05, que generalmente se considera estadísticamente insignificante)? ¿Hubo dificultades de las que hablamos antes y que los autores de las pruebas no verificaron correctamente?
- Lo que funciona en un dominio puede no funcionar en otro. Por ejemplo, Neil Patel [29] recomienda usar la palabra "gratis" en los anuncios que ofrecen una versión de prueba de 30 días en lugar de una "garantía de devolución de dinero de 30 días". Esto puede funcionar con un producto y una audiencia, pero sospechamos que el resultado dependerá en gran medida del producto y la audiencia. Joshua Porter [30] afirma que "el rojo es mejor que el verde" para los botones que llaman a unirse a "Comenzar ahora". Pero como no hemos visto muchos sitios con un botón rojo de llamado a la acción, aparentemente, este resultado no se reproduce tan bien.
- El efecto de novedad y primera vez. Logramos estabilidad en nuestros experimentos, y muchos experimentos en muchos ejemplos no se han llevado a cabo el tiempo suficiente para verificar tales efectos.
- Interpretación incorrecta de los resultados. Alguna razón oculta o factor específico puede no ser reconocido o mal entendido. Damos dos ejemplos. Uno de ellos es el primer experimento de control documentado.
Ejemplo 1 El escorbuto es una enfermedad causada por una deficiencia de vitamina C. Mató a más de 100,000 personas en los siglos 16-18, la mayoría de ellos marineros que hicieron largos viajes y se quedaron en el mar más tiempo del que las frutas y verduras podrían sobrevivir. En 1747, el Dr. James Lind señaló que el escorbuto se ve menos afectado en los barcos en el Mediterráneo. Comenzó a dar limones y naranjas a algunos marineros, dejando a otros a la dieta habitual. El experimento fue muy exitoso, pero el médico no entendió la razón. En el Royal Maritime Hospital en el Reino Unido, trató a pacientes con escorbuto con jugo concentrado de limón, al que llamó rob. El médico lo concentró calentando, lo que destruyó la vitamina C. Lind perdió la fe y a menudo recurrió a la sangría. En 1793, se realizaron pruebas reales. y el jugo de limón se ha convertido en parte de la dieta diaria de los marineros. El escorbuto desapareció rápidamente, y los marineros británicos todavía se llaman limoncillo.
Ejemplo 2 Marissa Mayer habló sobre un experimento en el que Google aumentó el número de resultados en una página de búsqueda de 10 a 30. El tráfico y las ganancias de los usuarios que buscaron en Google cayeron un 20%. ¿Y cómo explicó ella esto? Como, la página requirió medio segundo más para ser generada. Por supuesto, la productividad es un factor importante, pero sospechamos que esto solo afectó una pequeña fracción de las pérdidas. Aquí está nuestra visión de las causas:
- Bing realizó experimentos aislados de desaceleración [11], durante los cuales solo cambió el rendimiento. Un retraso de respuesta del servidor de 250 milisegundos afectó los ingresos en aproximadamente un 1,5% y el CTR en un 0,25%. Esta es una gran influencia, y se puede suponer que 500 milisegundos afectarán los ingresos y el CTR en un 3% y un 0,5% respectivamente, pero no en un 20% (supongamos que aquí se aplica una aproximación lineal). Las pruebas anteriores en Bing [32] mostraron un efecto similar en los clics y menos impacto en los ingresos con un retraso de 2 segundos.
- Jake Brutlag de Google escribió en una publicación de blog sobre un experimento [12] que muestra que ralentizar los resultados de búsqueda de 100 milisegundos a 400 tiene un efecto significativo en el número específico de búsquedas y rangos entre 0.2% y 0.6%, que funciona muy bien con nuestros experimentos, pero muy lejos de los resultados de Marissa Mayer.
- BIng realizó un experimento con 20 resultados de búsqueda en lugar de 10. La pérdida de ganancias eliminó por completo la adición de publicidad adicional (lo que hizo que la página fuera un poco más lenta). Creemos que la relación entre los algoritmos publicitarios y de búsqueda es mucho más importante que el rendimiento.
Somos escépticos de los muchos resultados notables de las pruebas A / B publicadas en varias fuentes. Cuando verifique los resultados de los experimentos, pregúntese qué nivel de confianza tiene en ellos. Y recuerde, incluso si la idea funcionó en un sitio, no es necesario que funcione en otro. Lo mejor que podemos hacer es hablar sobre la reproducción de experimentos y su éxito o fracaso. Será más beneficioso para la ciencia.
Regla número 4: velocidad significa mucho
Los desarrolladores web que prueban sus características mediante experimentos de control rápidamente se dieron cuenta de que el rendimiento o la velocidad del sitio son parámetros críticos [13; 14; 33]. Incluso un ligero retraso en el funcionamiento del sitio puede afectar las métricas clave del grupo de prueba.
La mejor manera de evaluar los efectos del rendimiento es realizar un experimento de desaceleración aislado, es decir solo con agregar retraso. La Figura 3 muestra un gráfico estándar de la relación entre el rendimiento y la métrica que se prueba (CTR, tasa de éxito de la unidad e ingresos). Por lo general, cuanto más rápido sea el sitio, mejor (más alto en este gráfico). Al ralentizar el trabajo del grupo de prueba en relación con el grupo de control, puede medir el impacto del rendimiento en la métrica que le interesa. Es importante tener en cuenta:
- El efecto de la desaceleración en el grupo de prueba se mide aquí y ahora (línea discontinua en el gráfico) y depende del sitio y la audiencia. Si el sitio o la audiencia cambian, la degradación del rendimiento puede afectar las métricas clave de manera diferente.
- El experimento muestra el efecto de la desaceleración en las métricas clave. Esto puede ser muy útil cuando intenta medir el efecto de una nueva función cuya primera implementación no es efectiva. Suponga que mejora la métrica de M en un X%, y al mismo tiempo ralentiza el sitio en un T%. Usando el experimento con la desaceleración, podemos evaluar el efecto de la desaceleración en la métrica M, corregir el efecto de la característica y obtener el efecto predicho X '% (es lógico suponer que estos efectos tienen la propiedad de la aditividad). Y entonces podemos responder la pregunta: "¿Cómo afectará la métrica clave si se implementa de manera efectiva?".
- Podemos suponer cómo el hecho de que el sitio comenzará a funcionar más rápido y ayudar a calcular el ROI de los esfuerzos de optimización afectará la métrica clave. Usando una aproximación lineal (el primer término de la serie Taylor), podemos suponer que el efecto sobre la métrica es el mismo en ambas direcciones. Suponemos que el delta vertical es el mismo en ambas direcciones y solo diferente en el signo. Por lo tanto, al experimentar con la desaceleración en varios valores, podemos imaginar aproximadamente cómo la aceleración afectará estos mismos valores. Realizamos tales pruebas en Bing y nuestra teoría ha sido completamente confirmada.
¿Qué tan importante es el rendimiento? Críticamente importante En Amazon, una desaceleración de 100 milisegundos conduce a una caída del 1% en las ventas, como dijo Greg Linded [34 p.10]. Y los oradores de Bing y Google [32] muestran un impacto significativo del rendimiento en las métricas clave.
Ejemplo: experimento de ralentización del servidor
Realizamos un experimento de dos semanas en Bing para ralentizar el servicio en 100 milisegundos para el 10% de los usuarios, en 250 milisegundos para el otro 10% de los usuarios. Resultó que cada 100 milisegundos de aceleración del servicio aumentaron los ingresos en un 0.6%. A partir de aquí, incluso apareció una frase que refleja bien la esencia de nuestra organización:
un ingeniero que mejorará el rendimiento del servidor en 10 milisegundos (1/30 de la velocidad de parpadeo de nuestros ojos) le ganará a su empresa más de un año de ganancias. Cada milisegundo importa.
En el experimento descrito, ralentizamos el tiempo de respuesta del servidor, luego ralentizamos el tiempo de funcionamiento de todos los elementos en la página. Pero la página tiene partes más importantes, y hay partes menos importantes. Por ejemplo, los usuarios pueden no saber que los elementos fuera del alcance de la pantalla aún no se han cargado. Pero, ¿hay elementos visualizados de inmediato que puedan ralentizarse sin dañar al usuario? Como verá a continuación, hay tales elementos.
Ejemplo: el rendimiento del panel derecho no es tan crítico
En Bing, algunos elementos llamados instantáneas se encuentran en el panel derecho y se cargan tarde (después del evento window.onload). Recientemente realizamos un experimento: los elementos del panel derecho se ralentizaron 250 milisegundos. Si esto afectó las métricas clave, es tan insignificante que no notamos nada. Y el experimento involucró a casi 20 millones de usuarios.
El tiempo de carga de la página (PLT) a menudo se calcula utilizando el evento window.onload, como un signo de la finalización de la actividad útil del navegador. Pero hoy, esta métrica tiene un serio defecto cuando se trabaja con navegadores modernos. Como mostró Steve Souders [32], la parte superior de la página de Amazon se muestra en 2 segundos, mientras que windows.onload se dispara en 5,2 segundos. Schurman [32] declaró que podían renderizar la página dinámicamente, por lo que era importante que mostraran el encabezado muy rápidamente. Lo contrario también es cierto: en Gmail, windows.onload se dispara después de 3.3 segundos, mientras que en ese momento solo aparece la barra de descarga en la pantalla, y todo el contenido se mostrará en 4.8 segundos.
Hay métricas relacionadas con el tiempo, por ejemplo: tiempo hasta el primer resultado (por ejemplo, tiempo hasta el primer tweet en Twitter, primer resultado de búsqueda en la página de resultados). Pero el término "rendimiento percibido" siempre se usa para describir la velocidad de la página de modo que el usuario la perciba lo suficientemente llena. El concepto de "rendimiento percibido" es más fácil de describir intuitivamente que estrictamente formulado, por lo tanto, ninguno de los navegadores tiene planes para implementar el evento
perception.ready() . Para resolver este problema, se utilizan muchos supuestos y supuestos, por ejemplo:
- Tiempo de inicio de página (AFT) [37]. Medido como el momento en que se muestran todos los píxeles superiores de la página. La implementación se basa en heurísticas que son especialmente complejas cuando se trata de videos, gifs, galerías de desplazamiento y otro contenido dinámico que cambia la parte superior de la página. Los umbrales se pueden establecer en "porcentaje de píxeles dibujados" para evitar la influencia de elementos pequeños e insignificantes que pueden aumentar la métrica medida.
- El índice de velocidad [38] es una generalización de AFT que promedia el tiempo durante el cual los elementos visibles de la página aparecen en la pantalla. La velocidad no sufre de elementos pequeños que aparecen tarde, pero aún se ve afectada por el contenido dinámico que cambia la parte superior de la página.
- Tiempo de fase de página y tiempo de disponibilidad del usuario [39]. Tiempo de fase de página: el tiempo requerido para cada fase de representación de página individual. , . — , .
W3C- , HTML, , , . , , , .
Bing , « » (TTS) [24] . — . , 30 . — «Perceived performance». , ; , , . , , , . , . , , , , — .
№5: — , —
, Bing — , , . , — , , . , , . , , .
:
Bing . , «data mining», Bing «Examples of data mining», «Advantages of Data Mining», «definition of data mining», «Data mining companies»,«data mining software» .. . 10 . , (p-value 0,64).
:
Bing , , , , . . 17 %, (p-value 0,71).
:
Bing , 10 . , :
- , , «ebay», CTR 75 %. 10 . : 8 , , 4 . (p-value 0,92), production.
- , «» , Bing (14 ). , 3 «» , : 1,8 % , 30 , 18 % ( ), (p-value 0,93). .
:
. 10 , 12 % ( $150 , ). , (p-value 0,83)
, , . , , .
, ( Microsoft, Amazon .), CTR. , , . , . , . «» . : — , — .
№6: ,
. .. [40]: « , , . , — ». , online-, , [17;41], , , . , . LinkedIn.
: LinkedIn
LinkedIn . 2013 , , , , — LinkedIn, . , : , . , , , . . : . , , , . , , - , , - . .
: LinkedIn
LinkedIn . , . , . , . , , . , . , , , . , , , . , , . , . , .
offline- , , online, , , [4;11]. (Mullty-Variable) , MV-. ( /B/C/D) .
— Agile, MVP [15]: MVT, , . , . , , .. MV- - .
: 1 % , . Agile- Knight Capital, 2012 440 Knights 75 %.
№7:
. , , . , , . , . , [42] , , n > 30, . , . — , Neil Patel , .
, ( ) [16], , . , , .
,
355 * s^2 , , .
s — , :
$$s = \frac{E (XE (X))^3}{\Var (X)^{3/2}}$$, 1. , , Bing:
|
|
|
|
Revenue/User
| 17,9
| 114 .
| 4,4 %
|
Revenue/User (capped)
| 5.2
| 9,7 .
| 10,5 %
|
Sessions/User
| 3,6
| 4,7 .
| 5,4 %
|
Time To Success
| 2,1
| 1,55 .
| 12,3 %
|
, « » 10, « » — 30. 95 % , , 0,025, 0,3 0,2. Boos Hughes-Oliver [43]. , . , 18,2, 114 . . 4 , 100 1000 , QQ. 95- , , 5 %. 100 000 , -2 2.

, - , . , « » , , 18 5, . , 30 % , .
, , . , , , , 0. , 1.
, [16]. bootstrap [44].
Conclusión
7 , , . , , , , . , Twyman' , , . , , , , . — — . , , , , — . , , (, ). , , . — , , , . , : , . , , . , . Agile. — , . , , . , — . , , , .
, , . Mujtaba Khambatti, John Psaroudakis, Sreenivas Addagatke, . Juan Lavista Ferres, Urszula Chajewska, Greben Langendijk, Lukas Vermeer, Jonas Alves. Eytan Bakshy, Brooks Bell Colin McFarland.
Literatura- Kohavi, Ron and Round, Matt. Front Line Internet Analytics at Amazon.com. [ed.] Jim Sterne. Santa Barbara, CA: sn, 2004. ai.stanford.edu/~ronnyk/emetricsAmazon.pdf .
- McKinley, Dan. Design for Continuous Experimentation: Talk and Slides. [Online] Dec 22, 2012. mcfunley.com/designfor-continuous-experimentation .
- Bakshy, Eytan and Eckles, Dean. Uncertainty in Online Experiments with Dependent Data: An Evaluation of Bootstrap Methods. KDD 2013: Proceedings of the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2013
- Tang, Diane, et al. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. Proceedings 16th Conference on Knowledge Discovery and Data Mining. 2010
- Moran, Mike. Multivariate Testing in Action: Quicken Loan's Regis Hadiaris on multivariate testing. Biznology Blog by Mike Moran. [Online] December 2008. www.biznology.com/2008/12/multivariate_testing_in_action .
- Posse, Christian. Key Lessons Learned Building LinkedIn Online Experimentation Platform. Slideshare. [Online] March 20, 2013. www.slideshare.net/HiveData/googlecontrolledexperimentationpanelthe-hive .
- Kohavi, Ron, Crook, Thomas and Longbotham, Roger. Online Experimentation at Microsoft. Third Workshop on Data Mining Case Studies and Practice Prize. 2009. http://expplatform.com/expMicrosoft.aspx .
- Amatriain, Xavier and Basilico, Justin. Netflix Recommendations: Beyond the 5 stars. [Online] April 2012. techblog.netflix.com/2012/04/netflix-recommendationsbeyond-5-stars.html .
- McFarland, Colin. Experiment!: Website conversion rate optimization with A/B and multivariate testing. sl: New Riders, 2012. 978-0321834607.
- Smietana, Brandon. Zynga: What is Zynga's core competency? Quora. [Online] Sept 2010. www.quora.com/Zynga/What-is-Zyngas-corecompetency/answer/Brandon-Smietana .
- Kohavi, Ron, et al. Online Controlled Experiments at Large Scale. KDD 2013: Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 2013. bit.ly/ExPScale .
- Brutlag, Jake. Speed Matters. Google Research blog. [Online] June 23, 2009. googleresearch.blogspot.com/2009/06/speed-matters.html .
- Sullivan, Nicole. Design Fast Websites. Slideshare. [Online] Oct 14, 2008. www.slideshare.net/stubbornella/designingfast-websites-presentation .
- Kohavi, Ron, Henne, Randal M and Sommerfield, Dan. Practical Guide to Controlled Experiments on the Web: Listen to Your Customers not to the HiPPO. The Thirteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2007). August 2007, pp. 959-967. www.expplatform.com/Documents/GuideControlledExperiments.pdf .
- Ries, Eric. The Lean Startup: How Today's Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses. sl: Crown Business, 2011. 978-0307887894.
- Kohavi, Ron, et al. Controlled experiments on the web: survey and practical guide. Data Mining and Knowledge Discovery. February 2009, Vol. 18, 1, pp. 140-181. www.exp-platform.com/Pages/hippo_long.aspx .
- Crook, Thomas, et al. Seven Pitfalls to Avoid when Running Controlled Experiments on the Web. [ed.] Peter Flach and Mohammed Zaki. KDD '09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 2009, pp. 1105-1114. www.expplatform.com/Pages/ExPpitfalls.aspx .
- Kohavi, Ron, et al. Trustworthy online controlled experiments: Five puzzling outcomes explained. Proceedings of the 18th Conference on Knowledge Discovery and Data Mining. 2012, www.expplatform.com/Pages/PuzzingOutcomesExplained.aspx .
- Wikipedia contributors. Fisher's method. Wikipedia. [Online] Jan 2014. http://en.wikipedia.org/wiki/Fisher %27s_method .
- Eisenberg, Bryan. How to Increase Conversion Rate 1,000 Percent. ClickZ. [Online] Feb 28, 2003. www.clickz.com/showPage.html?page=1756031 .
- Spool, Jared. The $300 Million Button. USer Interface Engineering. [Online] 2009. www.uie.com/articles/three_hund_million_button .
- Goldstein, Noah J, Martin, Steve J and Cialdini, Robert B. Yes!: 50 Scientifically Proven Ways to Be Persuasive. sl: Free Press, 2008. 1416570969.
- Collins, Jim and Porras, Jerry I. Built to Last: Successful Habits of Visionary Companies. sl: HarperBusiness, 2004. 978- 0060566104.
- Badam, Kiran. Looking Beyond Page Load Times – How a relentless focus on Task Completion Times can benefit your users. Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/32 820.
- Why Most Published Research Findings Are False. Ioannidis, John P. 8, 2005, PLoS Medicine, Vol. 2, p. e124. www.plosmedicine.org/article/info :doi/10.1371/journal.pme d.0020124.
- Wacholder, Sholom, et al. Assessing the Probability That a Positive Report is False: An Approach for Molecular Epidemiology Studies. Journal of the National Cancer Institute. 2004, Vol. 96, 6. jnci.oxfordjournals.org/content/96/6/434.long .
- Ehrenberg, ASC The Teaching of Statistics: Corrections and Comments. Journal of the Royal Statistical Society. Series A, 1974, Vol. 138, 4.
- Ron Kohavi, David Messner,Seth Eliot, Juan Lavista Ferres, Randy Henne, Vignesh Kannappan,Justin Wang. Tracking Users' Clicks and Submits: Tradeoffs between User Experience and Data Loss. Redmond: sn, 2010.
- Patel, Neil. 11 Obvious A/B Tests You Should Try. QuickSprout. [Online] Jan 14, 2013. http://www.quicksprout.com/2013/01/14/11-obvious-ab-tests-youshould-try/ .
- Porter, Joshua. The Button Color A/B Test: Red Beats Green. Hutspot. [Online] Aug 2, 2011. blog.hubspot.com/blog/tabid/6307/bid/20566/The-ButtonColor-AB-Test-Red-Beats-Green.aspx .
- Linden, Greg. Marissa Mayer at Web 2.0. Geeking with Greg. [Online] Nov 9, 2006. glinden.blogspot.com/2006/11/marissa-mayer-at-web20.html .
- Performance Related Changes and their User Impact. Schurman, Eric and Brutlag, Jake. sl: Velocity 09: Velocity Web Performance and Operations Conference, 2009.
- Souders, Steve. High Performance Web Sites: Essential Knowledge for Front-End Engineers. sl: O'Reilly Media, 2007. 978-0596529307.
- Linden, Greg. Make Data Useful. [Online] Dec 2006. sites.google.com/site/glinden/Home/StanfordDataMining.20 06-11-28.ppt.
- Wikipedia contributors. Above the fold. Wikipedia, The Free Encyclopedia. [Online] Jan 2014. en.wikipedia.org/wiki/Above_the_fold .
- Souders, Steve. Moving beyond window.onload (). High Performance Web Sites Blog. [Online] May 13, 2013. www.stevesouders.com/blog/2013/05/13/moving-beyondwindow-onload .
- Brutlag, Jake, Abrams, Zoe and Meenan, Pat. Above the Fold Time: Measuring Web Page Performance Visually. Velocity: Web Performance and Operations Conference. 2011. en.oreilly.com/velocitymar2011/public/schedule/detail/18692 .
- Meenan, Patrick. Speed Index. WebPagetest. [Online] April 2012. sites.google.com/a/webpagetest.org/docs/usingwebpagetest/metrics/speed-index .
- Meenan, Patrick, Feng, Chao (Ray) and Petrovich, Mike. Going Beyond onload — How Fast Does It Feel? Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/31 344.
- Fisher, Ronald A. Presidential Address. Sankhyā: The Indian Journal of Statistics. 1938, Vol. 4, 1. www.jstor.org/stable/40383882 .
- Kohavi, Ron and Longbotham, Roger. Unexpected Results in Online Controlled Experiments. SIGKDD Explorations. 2010, Vol. 12, 2. www.exp-platform.com/Documents/2010- 12 %20ExPUnexpectedSIGKDD.pdf.
- Montgomery, Douglas C. Applied Statistics and Probability for Engineers. 5th. sl: John Wiley & Sons, Inc, 2010. 978- 0470053041.
- Boos, Dennis D and Hughes-Oliver, Jacqueline M. How Large Does n Have to be for Z and t Intervals? The American Statistician. 2000, Vol. 54, 2, pp. 121-128.
- Efron, Bradley and Robert J. Tibshirani. An Introduction to the Bootstrap. New York: Chapman & Hall, 1993. 0-412-04231- 2.