Hola Habr! Les presento la traducción del artículo "
Aprendizaje del modelo morfoble de cara en 3D a partir de imágenes en 2D ".

El modelo tridimensional de la cara transformable (Modelo 3D Morphable, en adelante 3DMM) es un modelo estadístico de la estructura y textura de la cara, que se utiliza por visión por computadora, gráficos por computadora, en el análisis del comportamiento humano y en la cirugía plástica.
La singularidad de cada característica facial hace que modelar un rostro humano sea una
tarea no trivial . 3DMM se crea para obtener un modelo de cara en un espacio de correspondencias explícitas. Esto significa una correspondencia puntual entre el modelo resultante y otros modelos que permiten la transformación. Además, las transformaciones de bajo nivel, como las diferencias entre un rostro masculino y una expresión facial neutra femenina de una sonrisa, deben reflejarse en 3DMM.

Investigadores de la Universidad de Michigan ofrecen el último método 3DMM de aprendizaje profundo. Utilizando la alta eficiencia de las redes neuronales profundas para implementar mapeos no lineales, su método permite obtener 3DMM basado en una imagen 2D capturada en un entorno arbitrario.
Enfoques anteriores
Típicamente, los 3DMM se obtienen usando un conjunto de escaneos faciales 3D y un conjunto de imágenes 2D de las mismas caras. El enfoque generalmente aceptado es utilizar la reducción dimensional en la enseñanza con un maestro, que se realiza utilizando el Análisis de componentes principales (PCA) en un conjunto de datos de capacitación que consiste en escaneos 3D de caras y las imágenes 2D correspondientes. Cuando se utilizan modelos lineales como PCA, las transformaciones no lineales y las variaciones faciales no se pueden reflejar en 3DMM. Además, para modelar texturas 3D precisas de caras, se necesita una gran cantidad de "información 3D". Por lo tanto, el uso de este enfoque es ineficaz.
Método propuesto
La idea del
método propuesto es utilizar redes neuronales profundas o, más específicamente,
redes neuronales convolucionales (que se adaptan mejor al problema en consideración y son menos costosas en términos de tiempo computacional que los perceptrones multicapa) para obtener 3DMM. Una red neuronal de codificación (codificador) toma una imagen de la cara como entrada y genera la textura de la cara y los parámetros de albedo con los que dos redes neuronales de decodificación (decodificadores) evalúan la textura y el albedo.
Como se mencionó anteriormente, el 3DMM lineal tiene una serie de problemas, como la necesidad de escaneos faciales en 3D, la incapacidad de usar imágenes tomadas desde un ángulo arbitrario y la precisión limitada de la presentación debido al uso de PCA lineal. A su vez, el método propuesto permite obtener un modelo 3DMM no lineal basado en imágenes 2D de caras de alta resolución,
tomadas desde un ángulo arbitrario .
Vista plana
En su enfoque, los investigadores usan un mapa detallado de caras en 2D para representar su textura y albedo. Argumentan que tener en cuenta la información espacial juega un papel importante, ya que utilizan redes neuronales convolucionales, y las imágenes frontales de la cara contienen poca información sobre los lados. Es por eso que su elección recayó en la representación plana.
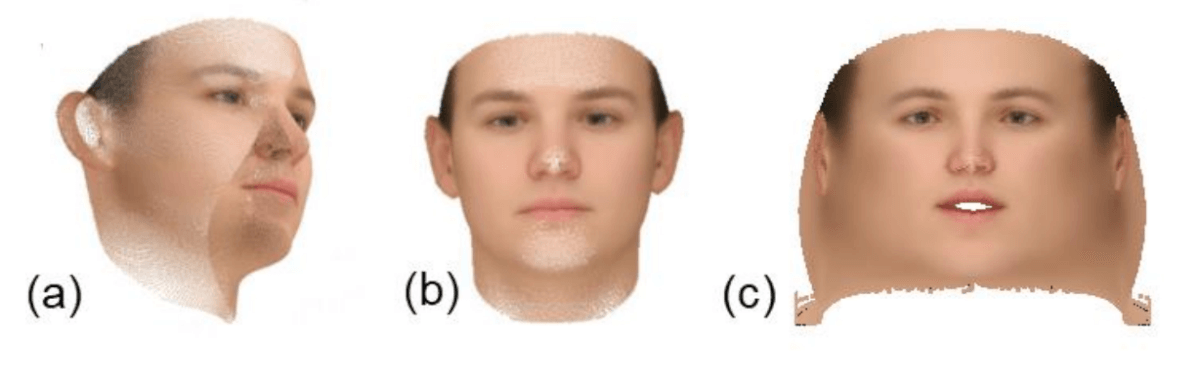
Tres vistas diferentes de albedo. (a) - representación 3D, (c) - albedo como una imagen frontal 2D de una cara, (c) - representación plana.
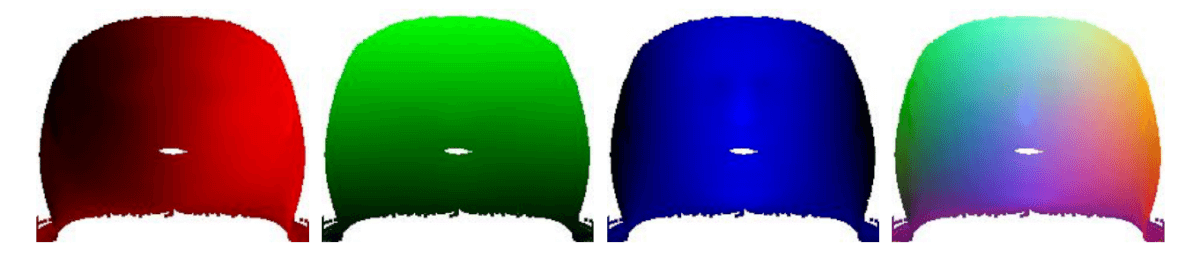
Vista plana Representación x, y, z y resumen de la textura.
Arquitectura de red neuronal
Los investigadores diseñaron una red neuronal que, tomando una imagen como entrada, la codifica en un vector de textura, albedo e iluminación. Los vectores ocultos codificados para albedo y textura se decodifican utilizando dos decodificadores, que se utilizan redes neuronales convolucionales. En la salida, los decodificadores dan el resplandor de la cara, su albedo y la textura de la cara en 3D. Usando estos parámetros, una capa de renderizado diferenciable genera un modelo de rostro al combinar la textura 3D, el albedo, la iluminación y los parámetros de ubicación de la cámara obtenidos por el codificador. La arquitectura se presenta en el siguiente diagrama.
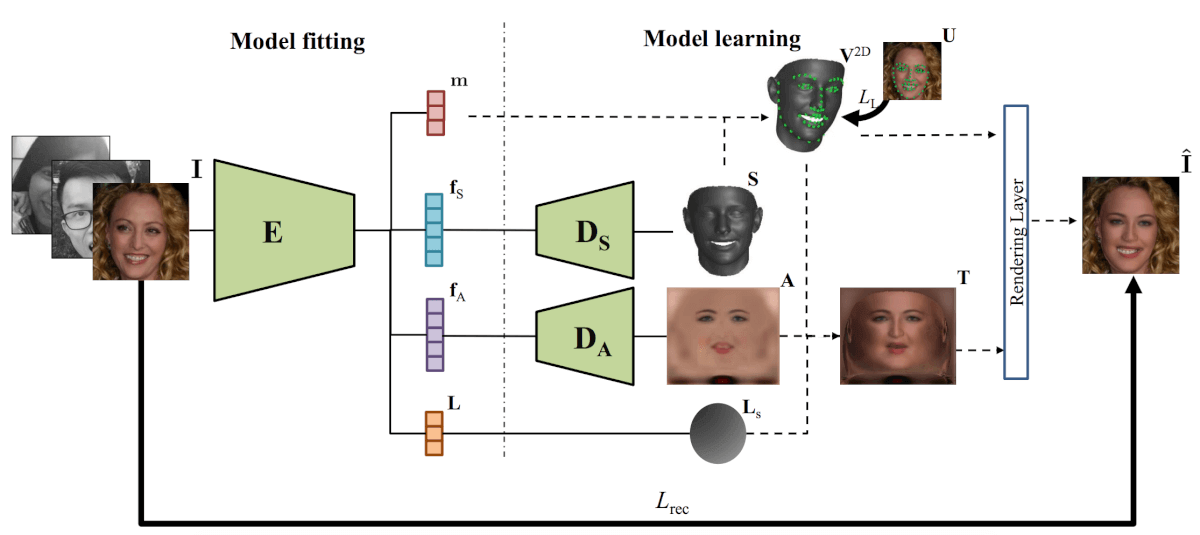
La arquitectura del método propuesto para obtener 3DMM no lineal
El 3DMM no lineal estable resultante puede usarse para la superposición de caras 2D y resolver el problema de la reconstrucción facial tridimensional.
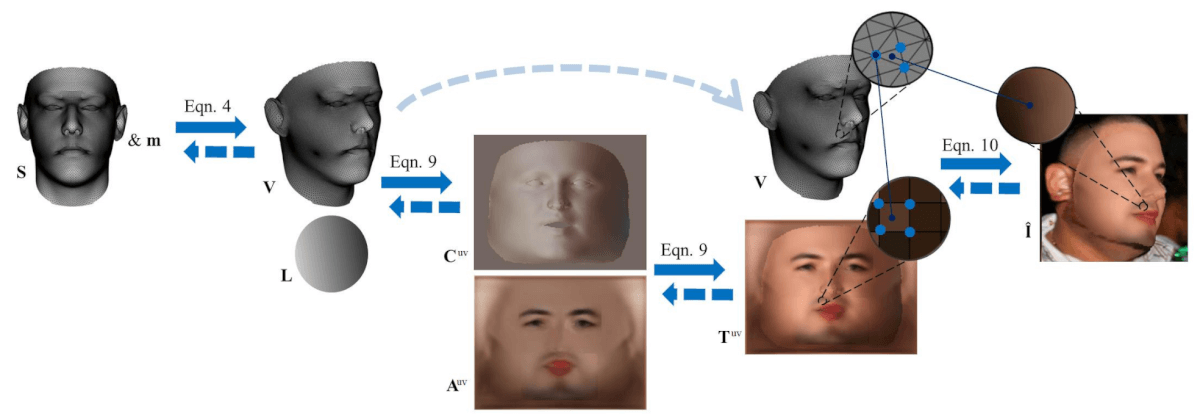
Diseño de capa de representación
Comparación con otros métodos.
El método considerado se comparó con otros métodos utilizando las siguientes tareas como ejemplo:
superposición 2D, reconstrucción y edición de caras en 3D . El método propuesto es superior a otros enfoques modernos para resolver estos problemas. Los resultados de la comparación se presentan a continuación.
Superposición de caras 2D
Una de las aplicaciones del método es la superposición de caras, que debería mejorar significativamente el análisis de caras en una serie de tareas (por ejemplo, reconocimiento de caras). La imposición facial no es una tarea fácil, pero el método en consideración muestra altos resultados al resolverlo.

Resultados de superposición 2D. Las marcas invisibles están marcadas en rojo. El método considerado refleja posturas inusuales, iluminación y expresiones faciales.
Reconstrucción facial 3D
El método en consideración también se comparó utilizando la reconstrucción facial 3D y mostró resultados sobresalientes en comparación con otros métodos.

Comparación cuantitativa de resultados de reconstrucción 3D

Los resultados de la reconstrucción 3D en comparación con el método de Sela et al. El método propuesto salva el vello facial y otras características de la cara mucho mejor que este método.

Los resultados de la reconstrucción 3D en comparación con VRN de Jackson y otros en el ejemplo del famoso conjunto de datos CelebA.

Los resultados de la reconstrucción 3D en comparación con el método de Tewari y otros. Como puede ver, el método propuesto resuelve el problema de comprimir la cara en presencia de varias texturas (como el vello facial).
Edición de rostros
El método discutido divide la imagen de la cara en elementos separados y le permite cambiar la cara al manipularlos. Los resultados de este método al editar caras se evaluaron en el ejemplo de tareas tales como cambiar la iluminación y agregar elementos de cara adicionales.

Los resultados de agregar una barba. La primera columna contiene la imagen original, la siguiente: diferentes grados de cambio en la barba.

Comparación con el método de Shu et al. (Segunda línea). Como puede ver, el método propuesto ofrece imágenes más realistas y, además, la identidad de la cara se conserva mejor.
Conclusión
El método propuesto, presumiblemente, será ampliamente utilizado, ya que le permite obtener 3DMM preciso y estable. Aunque 3DMM estuvo muy extendido desde su inicio, hasta el advenimiento del método en cuestión, no había una forma efectiva de obtener este modelo utilizando imágenes 2D desde un ángulo arbitrario.
El método propuesto utiliza redes neuronales profundas como un aproximador para el modelado sostenible de rostros humanos con todas sus características. Una forma tan inusual de obtener 3DMM le permite manipular la imagen y puede usarse en muchas tareas, algunas de las cuales se presentaron al artículo.
Traducción - Boris Rumyantsev.