
Escalar un DBMS es un futuro que avanza continuamente. Los DBMS mejoran y escalan mejor en plataformas de hardware, mientras que las plataformas de hardware aumentan la productividad, la cantidad de núcleos y la memoria: Aquiles se está poniendo al día con la tortuga, pero aún no lo ha hecho. El problema de escalar DBMS está en pleno apogeo.
Postgres Professional tuvo un problema con el escalado no solo teóricamente, sino también prácticamente: con sus clientes. Y más de una vez. Uno de esos casos será discutido en este artículo.
PostgreSQL escala bien en sistemas NUMA si es una placa base única con múltiples procesadores y múltiples buses de datos. Algunas optimizaciones se pueden leer
aquí y
aquí . Sin embargo, hay otra clase de sistemas, tienen varias placas base, el intercambio de datos entre ellas se realiza mediante interconexión, mientras que una instancia del sistema operativo está trabajando en ellas y para el usuario este diseño parece una sola máquina. Y aunque formalmente tales sistemas también pueden atribuirse a NUMA, en esencia están más cerca de las supercomputadoras, como El acceso a la memoria local del nodo y el acceso a la memoria del nodo vecino difieren radicalmente. La comunidad PostgreSQL cree que la única instancia de Postgres que se ejecuta en tales arquitecturas es una fuente de problemas, y aún no existe un enfoque sistemático para resolverlos.
Esto se debe a que la arquitectura de software que usa memoria compartida está diseñada fundamentalmente por el hecho de que el tiempo de acceso de los diferentes procesos a su propia memoria remota es más o menos comparable. En el caso de que trabajemos con muchos nodos, la apuesta por la memoria compartida como un canal de comunicación rápido deja de justificarse, porque debido a la latencia es mucho más "barato" enviar una solicitud de una determinada acción al nodo (nodo) donde se encuentra datos interesantes que enviar estos datos en el bus. Por lo tanto, para las supercomputadoras y, en general, los sistemas con muchos nodos, las soluciones de clúster son relevantes.
Esto no significa que sea necesario poner fin a la combinación de sistemas de múltiples nodos y la arquitectura típica de memoria compartida de Postgres. Después de todo, si los procesos postgres pasan la mayor parte de su tiempo haciendo cálculos complejos localmente, entonces esta arquitectura será incluso muy eficiente. En nuestra situación, el cliente ya había comprado un poderoso servidor de múltiples nodos, y tuvimos que resolver los problemas de PostgreSQL en él.
Pero los problemas eran graves: las solicitudes de escritura más simples (cambiar varios valores de campo en un registro) se ejecutaron en un período de varios minutos a una hora. Como se confirmó más tarde, estos problemas se manifestaron en todo su esplendor precisamente por la gran cantidad de núcleos y, en consecuencia, el paralelismo radical en la ejecución de solicitudes con un intercambio relativamente lento entre nodos.
Por lo tanto, el artículo resultará, por así decirlo, con dos propósitos:
- Comparta experiencia: qué hacer si en un sistema de múltiples nodos la base de datos se ralentiza en serio. Por dónde empezar, cómo diagnosticar dónde moverse.
- Describa cómo se pueden resolver los problemas del propio DBMS PostgreSQL con un alto nivel de concurrencia. Incluyendo cómo el cambio en el algoritmo para tomar bloqueos afecta el rendimiento de PostgreSQL.
Servidor y DB
El sistema constaba de 8 cuchillas con 2 enchufes en cada una. En total, más de 300 núcleos (excluyendo hypertreading). Un neumático rápido (tecnología patentada por el fabricante) conecta las cuchillas. No es que sea una supercomputadora, pero para una instancia del DBMS, la configuración es impresionante.
La carga también es bastante grande. Más de 1 terabyte de datos. Alrededor de 3000 transacciones por segundo. Más de 1000 conexiones a postgres.
Habiendo comenzado a lidiar con las expectativas de grabación por hora, lo primero que hicimos fue escribir en el disco como causa de demoras. Tan pronto como comenzaron los retrasos incomprensibles, las pruebas comenzaron a hacerse exclusivamente en
tmpfs . La imagen no ha cambiado. El disco no tiene nada que ver con eso.
Primeros pasos con los diagnósticos: vistas
Dado que los problemas surgieron probablemente debido a la alta competencia de los procesos que "tocan" los mismos objetos, lo primero que debe verificar son los bloqueos. En PostgreSQL, hay una vista
pg.catalog.pg_locks y
pg_stat_activity para tal verificación. El segundo, ya en la versión 9.6, agregó información sobre lo que el proceso está esperando (
Amit Kapila, Ildus Kurbangaliev ) -
wait_event_type . Los valores posibles para este campo se describen
aquí .
Pero primero, solo cuenta:
postgres=
Estos son números reales. Alcanzó hasta 200,000 cerraduras.
Al mismo tiempo, tales bloqueos colgaban de la solicitud desafortunada:
SELECT COUNT(mode), mode FROM pg_locks WHERE pid =580707 GROUP BY mode; count | mode —
Al leer el búfer, el DBMS usa el bloqueo
share , mientras escribe,
exclusive . Es decir, los bloqueos de escritura representaron menos del 1% de todas las solicitudes.
En la vista
pg_locks , los tipos de bloqueo no siempre se ven como se describe
en la documentación del usuario.
Aquí está la placa del partido:
AccessShareLock = LockTupleKeyShare RowShareLock = LockTupleShare ExclusiveLock = LockTupleNoKeyExclusive AccessExclusiveLock = LockTupleExclusive
La consulta SELECT mode FROM pg_locks mostró que CREATE INDEX (sin CONCURRENTLY) esperaría 234 INSERTs y 390 INSERTs para el
buffer content lock . Una posible solución es "enseñar" INSERTs de diferentes sesiones para cruzarse menos en buffers.
Es hora de usar perf
La utilidad
perf recopila mucha información de diagnóstico. En modo de
record ... escribe estadísticas de eventos del sistema en archivos (de manera predeterminada están en
./perf_data ), y en modo de
report analiza los datos recopilados, por ejemplo, puede filtrar eventos que conciernen solo
postgres o un
pid dado:
$ perf record -u postgres $ perf record -p 76876 , $ perf report > ./my_results
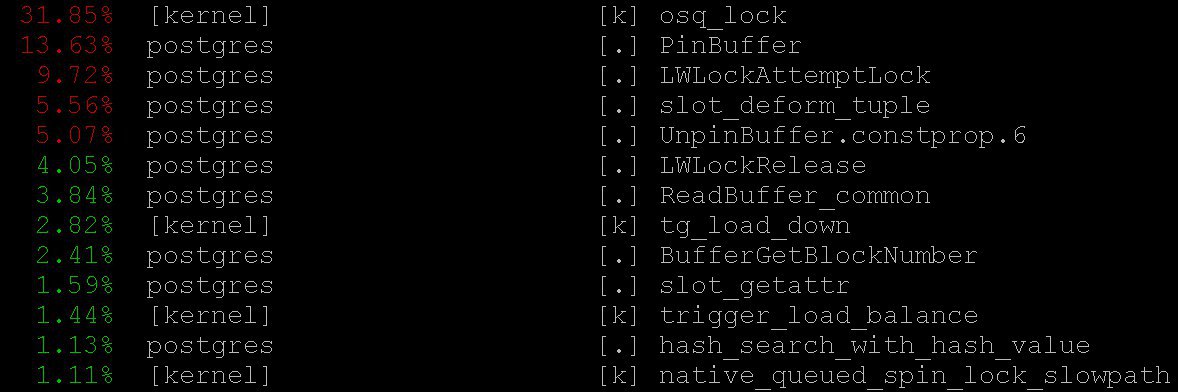
Como resultado, veremos algo como
Cómo usar
perf para diagnosticar PostgreSQL se describe, por ejemplo,
aquí , así como en la
página de wiki .
En nuestro caso, incluso el modo más simple proporcionó información importante:
perf top , que funciona, por supuesto, en el espíritu del sistema operativo
top . Con
perf top vimos que la mayoría de las veces el procesador pasa en los
PinBuffer() centrales, así como en las
PinBuffer() y
LWLockAttemptLock(). .
PinBuffer() es una función que aumenta el contador de referencias al búfer (mapeando una página de datos a la RAM), gracias a que los procesos de postgres saben qué búferes se pueden forzar y cuáles no.
LWLockAttemptLock() -
LWLock de captura de
LWLock .
LWLock es un tipo de bloqueo con dos niveles de
shared y
exclusive , sin definir
deadlock , los bloqueos se asignan previamente a la
shared memory , los procesos de espera están esperando en una cola.
Estas funciones ya se han optimizado bastante en PostgreSQL 9.5 y 9.6. Los spinlocks dentro de ellos fueron reemplazados por el uso directo de operaciones atómicas.
Gráficos de llamas
Es imposible sin ellos: incluso si fueran inútiles, todavía valdría la pena contarlos: son inusualmente hermosos. Pero son útiles. Aquí hay una ilustración de
github , no de nuestro caso (ni nosotros ni el cliente estamos listos para revelar detalles aún).

Estas bellas imágenes muestran muy claramente lo que toman los ciclos del procesador. El mismo
perf puede recopilar datos, pero el
flame graph visualiza de manera inteligente los datos y construye árboles en función de las pilas de llamadas recopiladas. Puede leer más sobre la creación de perfiles con gráficos de llama, por ejemplo,
aquí , y descargar todo lo que necesita
aquí .
En nuestro caso, una gran cantidad de
nestloop era visible en los gráficos de llamas. Aparentemente, las uniones de una gran cantidad de tablas en numerosas solicitudes de lectura concurrentes causaron una gran cantidad de bloqueos de
access share .
Las estadísticas recopiladas por
perf muestran dónde van los ciclos del procesador. Y aunque vimos que la mayor parte del tiempo del procesador pasa por las cerraduras, no vimos qué conduce exactamente a expectativas tan largas de las cerraduras, ya que no vemos exactamente dónde ocurren las expectativas de las cerraduras, porque El tiempo de CPU no se pierde esperando.
Para ver las expectativas en sí mismas, puede crear una solicitud para la vista del sistema
pg_stat_activity .
SELECT wait_event_type, wait_event, COUNT(*) FROM pg_stat_activity GROUP BY wait_event_type, wait_event;
reveló que:
LWLockTranche | buffer_content | UPDATE ************* LWLockTranche | buffer_content | INSERT INTO ******** LWLockTranche | buffer_content | \r | | insert into B4_MUTEX | | values (nextval('hib | | returning ID Lock | relation | INSERT INTO B4_***** LWLockTranche | buffer_content | UPDATE ************* Lock | relation | INSERT INTO ******** LWLockTranche | buffer_mapping | INSERT INTO ******** LWLockTranche | buffer_content | \r
(los asteriscos aquí simplemente reemplazan los detalles de la solicitud que no revelamos).
Puede ver los valores
buffer_content (bloqueando el contenido de los buffers) y
buffer_mapping (bloqueando los componentes de la placa hash
shared_buffers ).
Para ayuda a gdb
Pero, ¿por qué hay tantas expectativas para este tipo de cerraduras? Para obtener información más detallada sobre las expectativas, tuve que usar el depurador
GDB . Con
GDB podemos obtener una pila de llamadas de procesos específicos. Mediante la aplicación de muestreo, es decir Después de recopilar un cierto número de pilas de llamadas aleatorias, puede hacerse una idea de qué pilas tienen las expectativas más largas.
Considere el proceso de compilación de estadísticas. Consideraremos la recopilación “manual” de estadísticas, aunque en la vida real se utilizan scripts especiales que lo hacen automáticamente.
Primero,
gdb necesita estar adjunto al proceso PostgreSQL. Para hacer esto, encuentre el
pid proceso
pid servidor, digamos de
$ ps aux | grep postgres
Digamos que encontramos:
postgres 2025 0.0 0.1 172428 1240 pts/17 S 23 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data
y ahora inserte el
pid en el depurador:
igor_le:~$gdb -p 2025
Una vez dentro del depurador, escribimos
bt [es decir,
backtrace ] o
where . Y obtenemos mucha información sobre este tipo:
(gdb) bt #0 0x00007fbb65d01cd0 in __write_nocancel () from /lib64/libc.so.6 #1 0x00000000007c92f4 in write_pipe_chunks ( data=0x110e6e8 "2018‐06‐01 15:35:38 MSK [524647]: [392‐1] db=bp,user=bp,app=[unknown],client=192.168.70.163 (http://192.168.70.163) LOG: relation 23554 new block 493: 248.389503\n2018‐06‐01 15:35:38 MSK [524647]: [393‐1] db=bp,user=bp,app=["..., len=409, dest=dest@entry=1) at elog.c:3123 #2 0x00000000007cc07b in send_message_to_server_log (edata=0xc6ee60 <errordata>) at elog.c:3024 #3 EmitErrorReport () at elog.c:1479
Una vez recopiladas las estadísticas, incluidas las pilas de llamadas de todos los procesos de postgres, recopiladas repetidamente en diferentes puntos en el tiempo, vimos que el
buffer partition lock del
buffer partition lock dentro del
relation extension lock la
relation extension lock duró 3706 segundos (aproximadamente una hora), es decir, se bloquea en un trozo de la tabla hash del búfer manager, que era necesario suplantar el búfer antiguo, para luego reemplazarlo por uno nuevo correspondiente a la parte extendida de la tabla. También se notó un cierto número de bloqueos del
buffer content lock del
buffer content lock , lo que correspondía a la expectativa de bloquear las páginas del índice del
B-tree para su inserción.

Al principio, llegaron dos explicaciones para un tiempo de espera tan monstruoso:
- Alguien más tomó este
LWLock y se atascó. Pero esto es poco probable. Porque no ocurre nada complicado dentro del bloqueo de la partición del búfer. - Encontramos algún comportamiento patológico de
LWLock . Es decir, a pesar de que nadie tomó la cerradura demasiado tiempo, su expectativa duró demasiado.
Parches de diagnóstico y tratamiento de árboles
Al reducir el número de conexiones simultáneas, probablemente descargaríamos el flujo de solicitudes a las cerraduras. Pero eso sería como rendirse. En cambio,
Alexander Korotkov , el arquitecto jefe de Postgres Professional (por supuesto, ayudó a preparar este artículo), propuso una serie de parches.
En primer lugar, era necesario obtener una imagen más detallada del desastre. No importa cuán buenas sean las herramientas terminadas, los parches de diagnóstico de su propia fabricación también serán útiles.
Se escribió un parche que agrega un registro detallado del tiempo dedicado a la
relation extension , lo que está sucediendo dentro de la función
RelationAddExtraBlocks() . Entonces descubrimos qué tiempo pasa dentro de
RelationAddExtraBlocks().Y en apoyo de él, se escribió otro parche informando en
pg_stat_activity sobre lo que estamos haciendo ahora en
relation extension . Se hizo de esta manera: cuando la
relation expande,
application_name convierte en
RelationAddExtraBlocks . Este proceso ahora se analiza convenientemente con los máximos detalles utilizando
gdb bt y
perf .
En realidad, los parches médicos (y no diagnósticos) se escribieron dos. El primer parche cambió el comportamiento de los bloqueos de la hoja del
B‐tree : antes, cuando se le pedía que se insertara, la hoja se bloqueó como recurso
share , y después de eso se volvió
exclusive . Ahora inmediatamente se vuelve
exclusive . Ahora este parche
ya se ha confirmado para
PostgreSQL 12 . Afortunadamente, este año
Alexander Korotkov recibió el
estado de un committer : el segundo committer PostgreSQL en Rusia y el segundo en la compañía.
El valor
NUM_BUFFER_PARTITIONS también se aumentó de 128 a 512 para reducir la carga en los bloqueos de mapeo: la tabla hash del administrador de búfer se dividió en partes más pequeñas, con la esperanza de que la carga en cada parte específica se redujera.
Después de aplicar este parche, los bloqueos en el contenido de los búferes desaparecieron, pero a pesar del aumento en
NUM_BUFFER_PARTITIONS , el
buffer_mapping permaneció, es decir, le recordamos las piezas bloqueadas de la tabla hash del administrador de búfer:
locks_count | active_session | buffer_content | buffer_mapping ----‐‐‐--‐‐‐+‐------‐‐‐‐‐‐‐‐‐+‐‐‐------‐‐‐‐‐‐‐+‐‐------‐‐‐ 12549 | 1218 | 0 | 15
E incluso eso no es mucho. B - el árbol ya no es un cuello de botella. La extensión del
heap- llegó a primer plano.
Tratamiento de la conciencia
A continuación, Alexander presentó la siguiente hipótesis y solución:
Esperamos mucho tiempo en el
buffer parittion lock del
buffer parittion lock al
buffer parittion lock búfer. Quizás, en el mismo
buffer parittion lock hay una página muy demandada, por ejemplo, la raíz de algún
B‐tree En este punto, hay un flujo continuo de solicitudes de
shared lock de las solicitudes de lectura.
La línea de espera en
LWLock "no es justa". Dado que
shared lock se pueden tomar tantos como sea necesario a la vez, entonces si el
shared lock ya
shared lock , los
shared lock posteriores pasan sin hacer cola. Por lo tanto, si la secuencia de bloqueos compartidos es de suficiente intensidad para que no haya "ventanas" entre ellos, entonces esperar un
exclusive lock casi al infinito.
Para solucionar esto, puede intentar ofrecer un parche de comportamiento "caballeroso" de las cerraduras. Despierta la conciencia de
shared locker y honestamente hacen cola cuando ya hay un
exclusive lock (curiosamente, los candados pesados,
hwlock , no tienen problemas con la conciencia: siempre hacen cola honestamente)
locks_count | active_session | buffer_content | buffer_mapping | reladdextra | inserts>30sec ‐‐‐‐‐‐-‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐--‐-‐+‐‐‐‐‐‐-‐‐‐‐‐‐+‐‐‐‐------ 173985 | 1802 | 0 | 569 | 0 | 0
Todo esta bien! No hay
insert largas. Aunque las cerraduras en las piezas de las placas hash permanecieron. Pero qué hacer, estas son las propiedades de los neumáticos de nuestra pequeña supercomputadora.
Este parche también se
ofreció a la comunidad . Pero no importa cómo se desarrolle el destino de estos parches en la comunidad, nada les impide acceder a las próximas versiones de
Postgres Pro Enterprise , que están diseñadas específicamente para clientes con sistemas muy cargados.
Moraleja
Los bloqueos
share ligeros de alta moralidad (bloques
exclusive se saltan la cola) han resuelto el problema de los retrasos por hora en un sistema de múltiples nodos. La etiqueta hash
buffer manager no funcionó debido a un flujo de
share lock demasiado, lo que no dejaba la posibilidad de que los bloqueos necesarios suplantaran los viejos búferes y cargaran otros nuevos. Los problemas con la extensión del búfer para las tablas de la base de datos fueron solo una consecuencia de esto. Antes de esto, era posible expandir el cuello de botella con acceso a la raíz del
B-treePostgreSQL no fue diseñado para arquitecturas y supercomputadoras NUMA. Adaptarse a tales arquitecturas de Postgres es un trabajo enorme que requeriría (y posiblemente requeriría) los esfuerzos coordinados de muchas personas e incluso empresas. Pero las consecuencias desagradables de estos problemas arquitectónicos pueden mitigarse. Y tenemos que hacerlo: los tipos de carga que provocaron retrasos similares a los descritos son bastante típicos, las señales de socorro similares de otros lugares continúan llegando a nosotros. Problemas anteriores aparecieron antes: en sistemas con menos núcleos, solo las consecuencias no fueron tan monstruosas y los síntomas se trataron con otros métodos y otros parches. Ahora ha aparecido otro medicamento, no universal, pero claramente útil.
Entonces, cuando PostgreSQL funciona con la memoria de todo el sistema como local, ningún bus de alta velocidad entre nodos puede compararse con el tiempo de acceso a la memoria local. Las tareas surgen debido a esto difícil, a menudo urgente, pero interesante. Y la experiencia de resolverlos es útil no solo para los decisivos, sino también para toda la comunidad.
