
Cada una de las tecnologías creadas desde el momento en que una persona levanta una piedra está obligada a mejorar la vida de una persona, desempeñando sus funciones principales. Sin embargo, cualquier tecnología puede tener "efectos secundarios", es decir, afectar a una persona y al mundo que la rodea de una manera que nadie en el momento de crear esta tecnología pensó o quiso pensar. Un ejemplo vívido: se crearon máquinas y una persona podía moverse largas distancias a una velocidad más rápida que antes. Pero al mismo tiempo comenzó la contaminación.
Hoy hablaremos sobre el "efecto secundario" de Internet, que afecta no a la atmósfera de la Tierra, sino a las mentes y almas de las personas mismas. El hecho es que la World Wide Web se ha convertido en una excelente herramienta para la difusión e intercambio de información, para la comunicación entre personas físicamente distantes entre sí y para mucho más. Internet ayuda en diversas áreas de la sociedad, desde la medicina hasta la preparación banal para el examen de la historia. Sin embargo, el lugar donde se reúnen muchas, a veces sin nombre, voces y opiniones, desafortunadamente, está lleno de lo que es tan inherente al odio al hombre.
En el estudio de hoy, los científicos dividen en pedazos varios algoritmos cuya tarea principal es identificar mensajes ofensivos, groseros y hostiles. Se las arreglaron para romper todos estos algoritmos, demostrando así su bajo nivel de eficiencia y señalando los errores que deberían corregirse. Cómo los científicos rompieron lo que supuestamente funcionó, por qué lo hicieron y qué conclusiones debemos sacar todos: buscaremos respuestas a estas y otras preguntas en el informe de los investigadores. Vamos
Antecedentes del estudio.Las redes sociales y otras formas de interacción de Internet entre las personas se han convertido en una parte integral de nuestras vidas. Desafortunadamente, muchos de los usuarios de tales servicios también entienden literalmente algo como "libertad de expresión, pensamiento y expresión", cubriendo esto con su derecho a un comportamiento indecente, familiar y grosero en la red. Cada uno de nosotros de una forma u otra se enfrentó con la "actividad" de tales individuos. Muchos incluso se convirtieron en el objeto de tales discursos. Por supuesto, no se puede negar que una persona tiene todo el derecho de decir lo que piensa. Sin embargo, expresar tus pensamientos es una cosa, e insultar a alguien es otra. Además de la libertad de expresión, también se explota el anonimato, porque puedes decir cualquier cosa a cualquiera, mientras permaneces de incógnito. Como resultado, no será castigado por su comportamiento inapropiado.
No vale la pena explicar que las frases "No me gustó" y "esto es una mierda completa **, el autor mata contra la pared" (esta es una opción aún más o menos decente) tienen colores emocionales completamente diferentes, aunque tienen una esencia común, para el comentarista No me gusta lo que vio / leyó / escuchó, etc. Pero si prohíbe que una persona exprese su insatisfacción de esta manera, ¿se considera esto una violación de sus derechos? Muchos dirán que sí. Por otro lado, ¿vale la pena seguir haciendo la vista gorda ante el creciente odio exponencial en Internet, que en la mayoría de los casos no está justificado? El odio, como tal, tiene un lugar para estar. Por supuesto, esta es una emoción muy fuerte e increíblemente negativa. Sin embargo, si una persona odia a quien hizo algo terrible (asesinato, violación y otros actos inhumanos), esto aún puede justificarse de alguna manera. Pero cuando el odio se manifiesta en la dirección de una persona completamente extraña que no cometió nada inmoral o inhumano, esta es una historia completamente diferente.
Ahora, muchas compañías y grupos de investigación han decidido crear sus propios algoritmos que pueden analizar cualquier texto y decir dónde
está presente el
lenguaje de hostilidad * y en qué medida se expresa. Los héroes de hoy decidieron probar estos algoritmos, en particular, el muy promocionado API de Google Perspective, que determina la "acidez" de la frase, es decir. cuánto puede considerarse esta frase como un insulto.
Discurso de odio * : como queda claro por el nombre mismo de este término, es una combinación de medios de lenguaje destinados a expresar una vívida hostilidad entre los interlocutores. Las formas más comunes de discurso de odio son: racismo, sexismo, xenofobia, homofobia y otras formas de hostilidad hacia otra cosa.
Las principales tareas que los investigadores se propusieron son estudiar los algoritmos más populares para identificar el discurso de odio, comprender sus métodos de trabajo e intentar sortearlos.
Algoritmos de investigaciónLos científicos han elegido varios algoritmos cuyas bases de datos son diferentes entre sí, lo que nos permite determinar también la mejor base de datos. Algunos algoritmos dependen más de la identificación de
connotaciones sexuales
* , otros, religiosos. La fuente de su conocimiento es común a todos los algoritmos: Twitter. Según los investigadores, esto está lejos de ser perfecto, ya que este servicio tiene ciertas limitaciones (por ejemplo, el número de caracteres en un mensaje). Por lo tanto, la base de un algoritmo efectivo debe llenarse desde diferentes redes y servicios sociales.
Connotación * : un método para colorear una palabra o frase con tonos semánticos o emocionales adicionales. Puede variar según la forma lingüística, cultural u otra forma de separación social. Ejemplo: ventoso - "el día era ventoso" (el significado directo de la palabra), "siempre fue una persona ventosa" (en este caso, significa inconstancia y frivolidad).
Lista de algoritmos y su funcionalidad:
Desintoxicación : proyecto de Wikipedia para identificar lenguaje inapropiado en comentarios editoriales. Funciona sobre la base de
la regresión logística * y un
perceptrón multicapa * , utilizando modelos
N-gram * a nivel de letras y palabras. El tamaño de los N-gramos de una palabra varía de 1 a 3, y las letras, de 1 a 5.
La regresión logística * es un modelo para predecir la probabilidad de un evento ajustando los datos a una curva logística.
Un perceptrón multicapa * es un modelo de percepción de información, que consta de tres capas principales: S: sensores (que reciben una señal), A: elementos asociativos (procesamiento) y elementos de reacción R (respuesta a una señal), así como una capa adicional A.
N-gram * es una secuencia de n elementos.
Los datos para la base del algoritmo fueron recopilados por terceros, y cada uno de los comentarios fue evaluado por diez evaluadores.
T1 : un algoritmo con una base dividida en tres tipos de comentarios de Twitter (discurso de odio, insultos sin discurso de odio y neutral). Los investigadores dicen que esta es la única base con una categorización similar. Se detectó el discurso de odio buscando en Twitter patrones dados. Además, los resultados encontrados fueron evaluados por tres empleados de CrowdFlower (ahora Figure Eight Inc., un estudio de aprendizaje automático e inteligencia artificial). La mayor parte de la base (76%) son frases ofensivas, mientras que el lenguaje hostil ocupa solo el 5%.
T2 : un algoritmo que utiliza redes neuronales profundas. El énfasis principal se puso en la memoria a corto plazo a largo plazo (LSTM). La base de este algoritmo se divide en tres categorías: racismo, sexismo y nada. Los investigadores combinaron las dos primeras categorías en una, formando una categoría integral de lenguaje hostil. La base de la base fue de 16,000 tweets.
T1 * ,
T3 : un algoritmo basado en la red neuronal convolucional (CNN) y las unidades de recurrencia controlada (GRU), utilizando la base de conocimiento T1, que lo complementa con categorías separadas dirigidas a refugiados y musulmanes (T3).
Algoritmo de rendimientoEl rendimiento de los algoritmos se probó mediante dos métodos. En el primero, trabajaron como se pretendía originalmente. Y en el segundo, los algoritmos fueron entrenados a través de las bases de datos de cada uno de ellos, una especie de intercambio de experiencias.
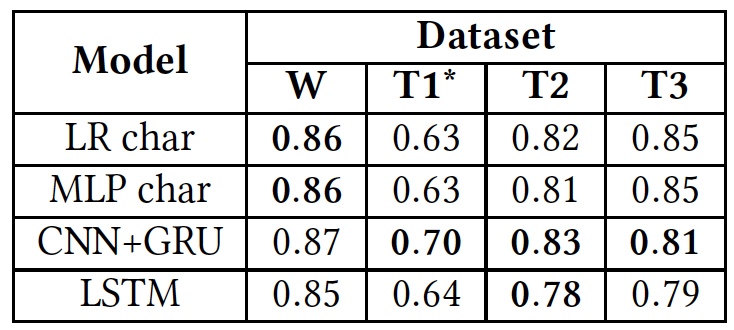 Resultados de la prueba (los resultados del uso de bases de datos originales están en negrita).
Resultados de la prueba (los resultados del uso de bases de datos originales están en negrita).Como se puede ver en la tabla anterior, todos los algoritmos mostraron aproximadamente los mismos resultados cuando se aplicaron a diferentes textos (bases de datos). Esto sugiere que todos estudiaron usando el mismo tipo de texto.
La única desviación significativa se ve en T1 *. Esto se debe al hecho de que la base de datos de este algoritmo está extremadamente desequilibrada, según los científicos. El discurso de odio toma solo un 5%, como ya sabemos. La división inicial en tres categorías de textos se transformó en una división en dos, cuando los "insultos, pero sin un lenguaje hostil" y los textos "neutros" se combinaron en un grupo, ocupando aproximadamente el 80% de toda la base.
Además, los investigadores volvieron a entrenar los algoritmos. Al principio, se usaron las bases originales. Después de eso, cada uno de los algoritmos tuvo que funcionar con la base de otro algoritmo, en lugar del propio.
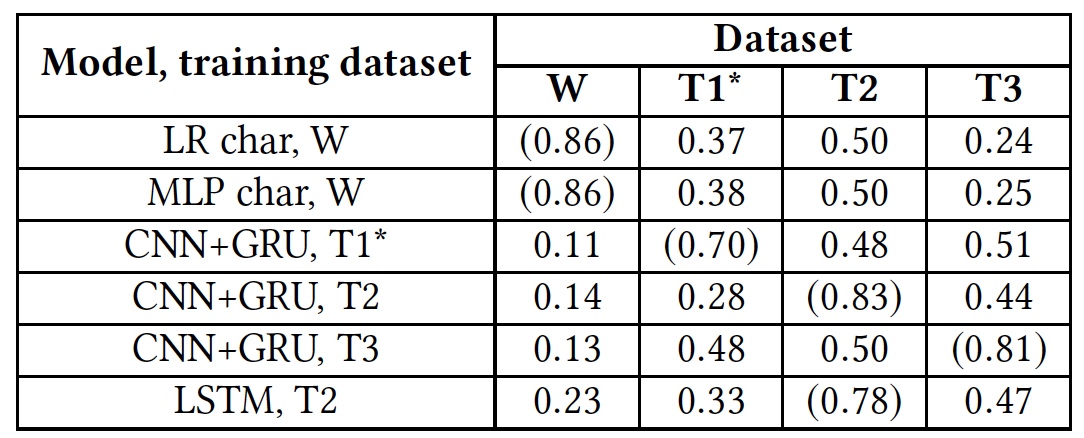 Volver a entrenar los resultados de la prueba (los resultados usando bases de datos nativas se muestran entre paréntesis).
Volver a entrenar los resultados de la prueba (los resultados usando bases de datos nativas se muestran entre paréntesis).Esta prueba mostró que todos los algoritmos no estaban preparados para trabajar con bases de datos extranjeras. Esto sugiere que los indicadores lingüísticos del discurso de odio no se cruzan en diferentes bases de datos, lo que puede deberse al hecho de que en diferentes bases de datos hay muy pocas palabras coincidentes, o debido a imprecisiones en la interpretación de ciertas frases.
Insultos y discursos de odioLos investigadores decidieron prestar especial atención a dos categorías de textos: ofensivos y hostiles. La conclusión es que algunos algoritmos los combinan en un montón, mientras que otros intentan separarlos como grupos independientes. Por supuesto, los insultos son claramente un fenómeno negativo y se pueden atribuir con seguridad a una categoría con hostilidad. Sin embargo, definir insultos es un proceso mucho más complicado que identificar el odio aparente en el texto.
Para probar los algoritmos para la capacidad de detectar insultos, se utilizó la base T1. Pero el algoritmo T1 * no participó en esta prueba, debido a que ya está preparado para dicho trabajo, lo que hace que los resultados de su verificación sean sesgados.
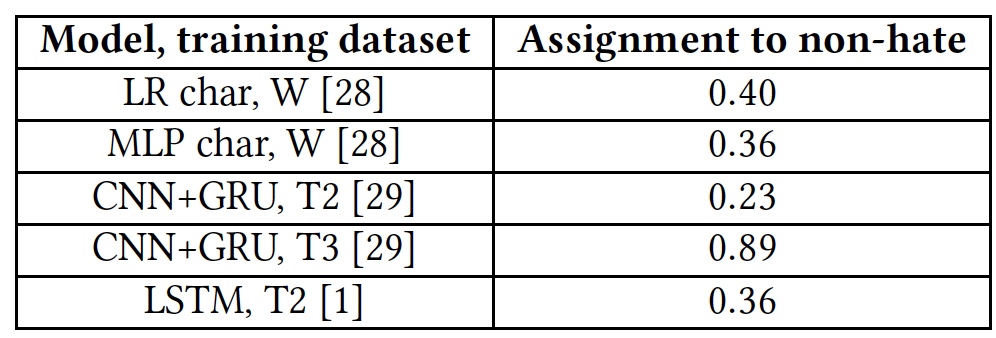 Resultados de la prueba para la capacidad de detectar textos ofensivos.
Resultados de la prueba para la capacidad de detectar textos ofensivos.Todos los algoritmos mostraron resultados bastante mediocres. La excepción fue T3, pero no a expensas de sus talentos. El hecho es que las palabras que no son familiares para el algoritmo están marcadas con la etiqueta
unk . Casi el 40% de las palabras en cada oración fueron marcadas con esta etiqueta, y el algoritmo las contó automáticamente como insultos. Y esto, por supuesto, estaba lejos de ser siempre correcto. En otras palabras, el algoritmo T3 tampoco hizo frente a la tarea en vista de su breve vocabulario.
Uno de los principales problemas de los algoritmos, los científicos consideran el factor humano. La mayoría de las bases de datos de cada uno de los algoritmos son recopiladas, analizadas y evaluadas por personas. Y aquí, son posibles grandes diferencias de resultados. La misma frase puede parecer ofensiva para algunas personas o neutral para otras.
Además, la falta de algoritmos para comprender frases no estándar que pueden contener con calma lenguaje grosero, pero sin insultos ni lenguaje de hostilidad, también tiene un efecto negativo.
Para demostrar esto, se realizó una prueba con varias frases. Luego se repitió la prueba, pero en cada una de las frases se agregó la palabra muy obscena "
f * ck " (marcada con la letra
F en la tabla).
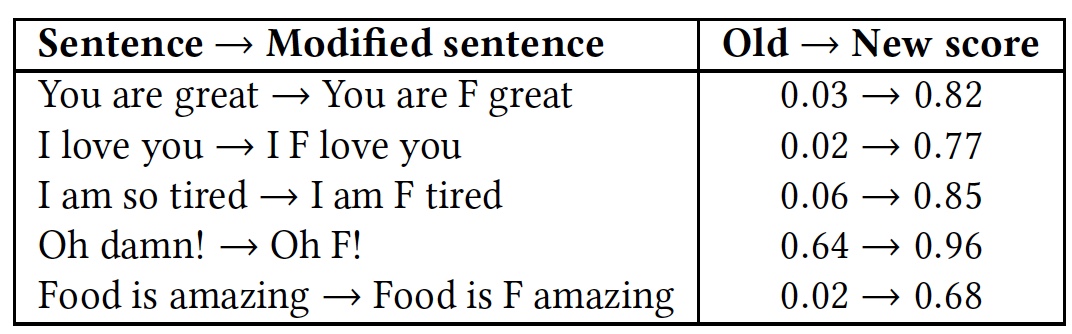 Resultados de reconocimiento comparativo de frases con y sin la palabra "f * ck".
Resultados de reconocimiento comparativo de frases con y sin la palabra "f * ck".Como se puede ver en la tabla, valió la pena agregar una palabra con la letra F, ya que todos los algoritmos inmediatamente tomaron la frase como un lenguaje de hostilidad. Aunque la esencia de las frases permaneció igual, amigable, pero el color emocional cambió a uno más pronunciado.
Las pruebas de API de Google Perspective descritas anteriormente muestran resultados similares. Este algoritmo tampoco puede distinguir el lenguaje hostil de los insultos, y el insulto de un simple epíteto utilizado para embellecer emocionalmente una frase.
¿Cómo engañar al algoritmo?Como suele suceder, si alguien rompe algo, entonces esto no siempre es malo. Y todo porque cuando rompemos, revelamos la falta de un sistema, su punto débil, que debería mejorarse evitando la repetición del colapso. Los modelos anteriores no fueron una excepción, y los investigadores decidieron ver cómo su trabajo podría verse afectado. Al final resultó que, no fue tan difícil como pensaban los creadores de estos algoritmos.
El modelo de derivación del algoritmo es simple: el cracker sabe que sus textos están verificados, puede cambiar los datos de entrada (texto) de tal manera que evite la detección. El cracker no tiene acceso al algoritmo ni a su estructura. En pocas palabras, el atacante rompe el algoritmo exclusivamente a nivel de usuario.
La omisión del algoritmo (llamémosla la buena palabra antigua "piratería") se divide en tres tipos:
- Cambiar la palabra: errores tipográficos intencionales y Leet, es decir, reemplazar algunas letras con números (por ejemplo: ¡Te ves genial hoy! - Y0U 100K 6r347 70D4Y!);
- Cambia el espacio entre palabras: agrega y elimina espacios;
- Agregue palabras al final de una frase.
El primer programa de piratería, el cambio de palabras, debe completar con éxito tres tareas: reducir el grado de reconocimiento de una palabra por un algoritmo, evitar correcciones ortográficas y mantener la legibilidad de las palabras para una persona.
El programa intercambia las dos letras en la palabra. Se da preferencia a las letras más cercanas al medio de la palabra y entre sí. Solo se excluyen la primera y la última letra de la palabra. Además, las palabras se modifican con un ojo en Leet, donde algunas letras se reemplazan por números: a - 4, e - 3, l - 1, o - 0, s - 5.
Con el fin de hacer frente a tales trucos, los algoritmos se mejoraron ligeramente mediante la introducción de la corrección ortográfica y la transformación estocástica de la base de conocimientos de entrenamiento. Es decir, no solo las palabras principales estaban presentes en la base de datos, sino que también cambiaron al reorganizar las letras del formulario.
Sin embargo, cuanto más larga sea la palabra, más opciones existen para reorganizar las letras, lo que amplía las capacidades del programa de craqueo.
El método de eliminar o agregar espacios también tiene sus propias características. Eliminar espacios es más adecuado para algoritmos opuestos que analizan palabras enteras. Pero los algoritmos que analizan cada letra pueden hacer frente fácilmente a la ausencia de espacios.
Agregar espacios puede parecer un método muy ineficiente, pero aún puede engañar a algunos algoritmos. Los modelos que consideran las palabras como un todo llevan a cabo un análisis léxico de la frase, dividiéndola en componentes (tokens). En este caso, el espacio sirve como un separador de palabras, es decir, un elemento importante del análisis de frases. Si hay más huecos de los necesarios, las palabras entre ellos se vuelven irreconocibles para el algoritmo. Al mismo tiempo, este método de derivación conserva un alto grado de legibilidad de las frases para una persona. El método funciona de manera simple: se selecciona una letra aleatoria en la palabra, luego se coloca un espacio. Como resultado, una palabra que el algoritmo conocía anteriormente deja de serlo. Ejemplo: "Odio" - "odio". Si elimina todos los espacios en el texto, entonces la frase completa se convertirá para el algoritmo en una palabra incomprensible para él. Como en la historia donde la hija le dio a su madre un teléfono nuevo, y ella le escribió un SMS con el texto: "Quería dejar un espacio en blanco en este teléfono". Podemos leer esta frase, pero el algoritmo la percibirá como una palabra, que, por supuesto, él no sabe.
Sin embargo, si el algoritmo analiza las letras por separado, podrá reconocer la frase, por lo tanto, este método de piratería no es adecuado en tales casos.
Para contrarrestar tales ataques, los algoritmos también fueron reentrenados. Para combatir la adición de espacios, la base del algoritmo pasó por un programa de introducción aleatoria de espacios: una palabra de n letras se puede separar por un espacio de n-1 formas. Sin embargo, esto condujo a una explosión combinatoria, cuando la complejidad del algoritmo aumenta bruscamente debido al aumento en el tamaño de los datos de entrada. Como resultado, aprender el algoritmo basado en el método conocido de agregar espacios es un ejercicio extremadamente difícil e ineficiente.
Eliminar espacios también es difícil. Si la base del algoritmo se repone con frases que él conoce, pero sin espacios, esto funcionará de manera efectiva solo cuando se aplique dicha frase. Vale la pena reemplazar un par de letras o una palabra, y el algoritmo no reconoce nada.
En el método de piratería agregando palabras, la esencia principal es cómo funciona el algoritmo de reconocimiento. Él divide las palabras en categorías, decir "bueno" y "malo". Si la frase tiene más "buenas", lo más probable es que el algoritmo determine la frase completa como "buena". Y viceversa. Si agrega una palabra aleatoria "buena" a la frase "mala" en el significado, puede engañar al algoritmo, y el significado de la frase para la persona que lo lee seguirá siendo el mismo. El programa de hack genera números aleatorios (del 10 al 50) o palabras al final de cada frase. Se eligió una lista de las palabras comunes en inglés más comunes proporcionadas por Google como fuente de palabras aleatorias.
 Una tabla de los resultados de la aplicación de los métodos anteriores de pirateo y reacción de algoritmos a esto (A - ataque, AT - entrenamiento basado en el principio de un programa de ataque, SC - corrección ortográfica, RW - eliminación de espacios).
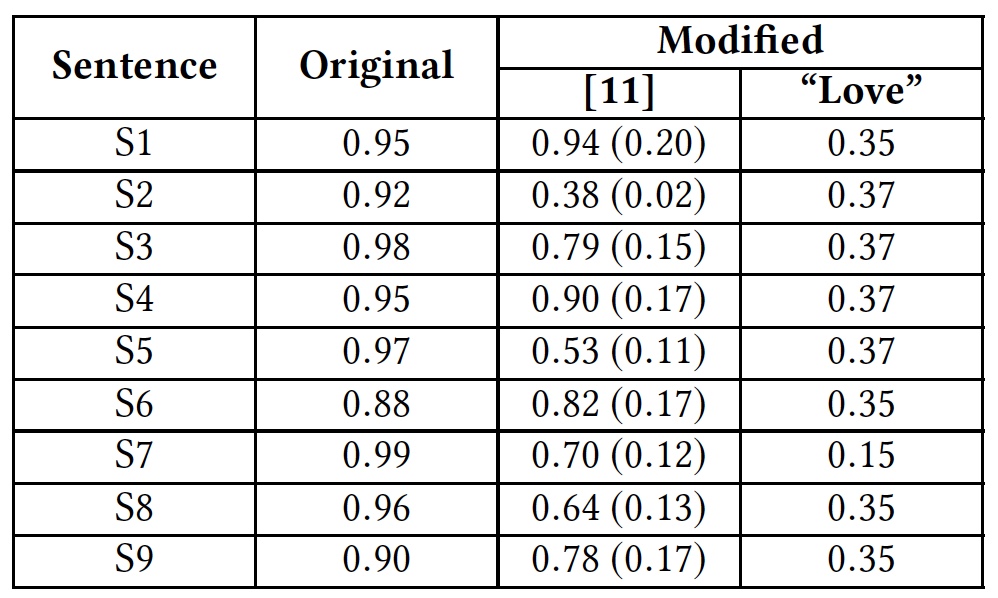
Una tabla de los resultados de la aplicación de los métodos anteriores de pirateo y reacción de algoritmos a esto (A - ataque, AT - entrenamiento basado en el principio de un programa de ataque, SC - corrección ortográfica, RW - eliminación de espacios).Para ilustrar la solución introduciendo palabras adicionales, los investigadores realizaron una prueba con la palabra "amor". Esta palabra fue agregada al final de las frases ofensivas.
 Resultados de la prueba con la palabra "amor".
Resultados de la prueba con la palabra "amor".La tabla muestra que este método fue capaz de engañar a todos los algoritmos que analizan la palabra completa. Los algoritmos que analizan las letras por separado también sufrieron, pero no tanto.
Google Perspective API , .
( ):S1: Climate change is happening and it's not changing in our favor. If you think differently you're an idiot.
S2: They're stupid, it's getting warmer, we should enjoy it while it lasts
S3: They are liberal idiots who are uneducated
S4: idiots. backward thinking people. nationalists. not accepting facts. susceptible to lies.
S5: They are stupid and ignorant with no class
S6: It's stupid and wrong
S7: If they voted for Hilary they are idiots
S8: Anyone who voted for Trump is a moron
S9: Screw you trump supporters
. , , Google Perspective API . «love» .
 Google Perspective API: «» () .
Google Perspective API: «» () ., Google Perspective API.
,
.
, , , .
, , . ? ? , ? : , , , . , , ? . , , . , — ?
, . ? ? ,
30% entry-level , : VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps $20 ? ( RAID1 RAID10, 24 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
.
Dell R730xd 2 ? 2 Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 $249 ! . c Dell R730xd 5-2650 v4 9000 ?