
Este es el último artículo de una serie de artículos de capacitación para desarrolladores en el campo de la inteligencia artificial. Discute los pasos para crear un modelo de aprendizaje profundo para la generación de música, elegir el modelo correcto y el preprocesamiento de datos, y describe los procedimientos para configurar, entrenar, probar y modificar BachBot.
Generación de música: pensar en una tarea
El primer paso para resolver muchos problemas usando la inteligencia artificial (IA) es reducir el problema a un problema básico que pueda resolverse por medio de la IA. Uno de estos problemas es la predicción de secuencia, que se utiliza en aplicaciones de traducción y procesamiento de lenguaje natural. Nuestra tarea de generar música puede reducirse al problema de predecir una secuencia, y la predicción se realizará para una secuencia de notas musicales.
Selección de modelo
Existen varios tipos diferentes de redes neuronales que pueden considerarse modelos: redes neuronales de distribución directa, redes neuronales recurrentes y redes neuronales de memoria a largo plazo.
Las neuronas son los elementos abstractos básicos que se combinan para formar redes neuronales. Esencialmente, una neurona es una función que recibe datos en la entrada y genera el resultado.
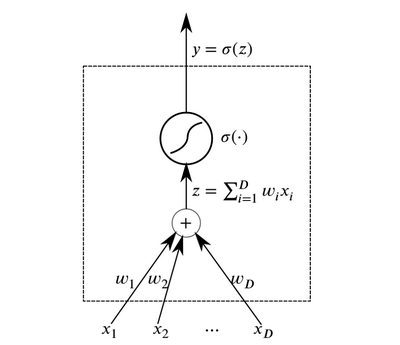 Neurona
NeuronaLas capas de neuronas que reciben los mismos datos en la entrada y tienen salidas conectadas se pueden combinar para construir una
red neuronal con propagación directa . Dichas redes neuronales demuestran altos resultados debido a la composición de funciones de activación no lineal al pasar datos a través de varias capas (el llamado aprendizaje profundo).
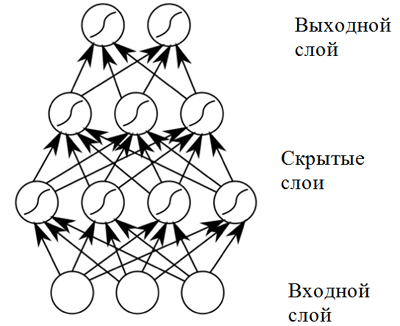 Red neuronal de distribución directa.
Red neuronal de distribución directa.Una red neuronal de distribución directa muestra buenos resultados en una amplia gama de aplicaciones. Sin embargo, dicha red neuronal tiene un inconveniente que no permite su uso en una tarea relacionada con la composición musical (predicción de secuencia): tiene una dimensión fija de datos de entrada y las composiciones musicales pueden tener diferentes longitudes. Además,
las redes neuronales de distribución directa no tienen en cuenta las entradas de los pasos de tiempo anteriores, ¡lo que las hace poco útiles para resolver el problema de predicción de secuencias! Un modelo llamado
red neuronal recurrente es más adecuado para esta tarea.
Las redes neuronales recursivas resuelven ambos problemas mediante la introducción de enlaces entre nodos ocultos: en este caso, en el siguiente paso de tiempo, los nodos pueden recibir información sobre los datos en el paso de tiempo anterior.
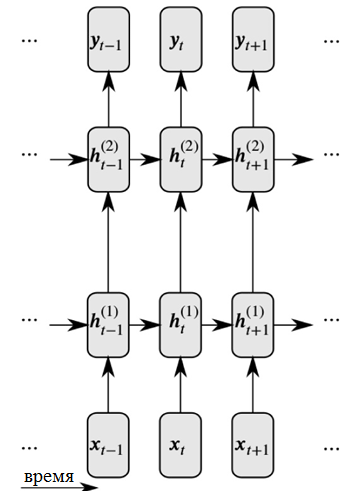 Representación detallada de una red neuronal recurrente.
Representación detallada de una red neuronal recurrente.Como puede ver en la figura, cada neurona ahora recibe información de la capa neural anterior y la hora anterior.
Las redes neuronales recursivas que se ocupan de grandes secuencias de entrada encuentran el llamado
problema del gradiente de fuga : esto significa que la influencia de los pasos de tiempo anteriores desaparece rápidamente. Este problema es característico de la tarea de composición musical, ya que hay importantes dependencias a largo plazo en las obras musicales que deben tenerse en cuenta.
Para resolver el problema de un gradiente de fuga
, se puede utilizar una modificación de la red recurrente, que se denomina
red neuronal con memoria a largo plazo (o red neuronal LSTM) . Este problema se resuelve introduciendo celdas de memoria, que son monitoreadas cuidadosamente por tres tipos de "compuertas". Haga clic en el siguiente enlace para obtener más información:
Información general sobre redes neuronales LSTM .
Por lo tanto, BachBot utiliza un modelo basado en la red neuronal LSTM.
Pretratamiento
La música es una forma de arte muy compleja e incluye varias dimensiones: tono, ritmo, tempo, sombras dinámicas, articulación y más. Para simplificar la música para los propósitos de este proyecto
, solo se consideran el tono y la duración de los sonidos . Además, todos los corales se
transpusieron a la clave en do mayor o en menor, y las duraciones de las notas se
cuantificaron en el tiempo (redondeadas) al múltiplo más cercano de la semicorchea. Estas acciones se tomaron para reducir la complejidad de las composiciones y aumentar el rendimiento de la red, mientras que el contenido básico de la música se mantuvo sin cambios. Las operaciones para normalizar las tonalidades y la duración de las notas se realizaron utilizando la biblioteca music21.
def standardize_key(score): """Converts into the key of C major or A minor. Adapted from https://gist.github.com/aldous-rey/68c6c43450517aa47474 """
El código utilizado para estandarizar los caracteres clave en los trabajos recopilados, las claves en Do mayor o A menor se usan en la salidaLa cuantificación del tiempo al múltiplo más cercano de la semicorchea se realizó utilizando la función
Stream.quantize () de la biblioteca
music21 . La siguiente es una comparación de las estadísticas asociadas con un conjunto de datos antes y después de su procesamiento preliminar:
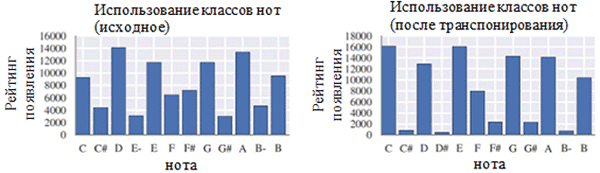 Usando cada clase de notas antes (izquierda) y después del preprocesamiento (derecha). Una clase de nota es una nota independientemente de su octava.
Usando cada clase de notas antes (izquierda) y después del preprocesamiento (derecha). Una clase de nota es una nota independientemente de su octava.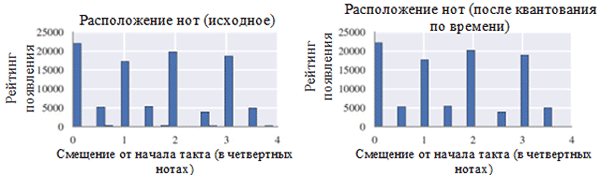 Ubicación de las notas antes (izquierda) y después del preprocesamiento (derecha)
Ubicación de las notas antes (izquierda) y después del preprocesamiento (derecha)Como puede ver en la figura anterior, la transposición de la clave original de los corales a la clave de Do mayor o Do menor (A menor) influyó significativamente en la clase de notas utilizadas en los trabajos recopilados. En particular, el número de ocurrencias para notas en teclas en teclas principales (Do mayor) y A menor (A menor) (C, D, E, F, G, A, B) aumentó. También puede observar pequeños picos para las notas F # y G # debido a su presencia en la secuencia ascendente de la melódica A menor (A, B, C, D, E, F # y G #).
Por otro lado, la cuantización del tiempo tuvo un efecto mucho menor. Esto puede explicarse por la alta resolución de cuantización (similar al redondeo a muchos dígitos significativos).
Codificación
Una vez que los datos han sido preprocesados, es necesario codificar los corales en un formato que pueda procesarse fácilmente utilizando una red neuronal recurrente. El formato requerido es una
secuencia de tokens . Para el proyecto BachBot, la codificación se eligió a nivel de notas (cada token representa una nota) en lugar del nivel de acordes (cada token representa un acorde). Esta solución redujo el tamaño del diccionario de 128
4 acordes posibles a 128 notas posibles, lo que permitió aumentar la eficiencia del trabajo.
Se creó un esquema de codificación original para composiciones musicales para el proyecto BachBot. El coral se divide en pasos de tiempo correspondientes a las semicorcheas. Estos pasos se llaman marcos. Cada cuadro contiene una secuencia de tuplas que representan el valor del tono de una nota en el formato de una interfaz de instrumento musical digital (MIDI) y un signo de unión de esta nota a una nota anterior de la misma altura (nota, signo de unión). Las notas dentro del marco están numeradas en orden descendente de altura (soprano → alt → tenor → bajo). Cada cuadro también puede tener un cuadro que marca el final de una frase; Fermata se representa con un símbolo de punto (.) Sobre la nota. Los símbolos
START y
END se agregan al principio y al final de cada coral. Estos símbolos provocan la inicialización del modelo y permiten al usuario determinar cuándo termina la composición.
START
(59, True)
(56, True)
(52, True)
(47, True)
|||
(59, True)
(56, True)
(52, True)
(47, True)
|||
(.)
(57, False)
(52, False)
(48, False)
(45, False)
|||
(.)
(57, True)
(52, True)
(48, True)
(45, True)
|||
ENDUn ejemplo de codificación de dos acordes. Cada acorde dura un octavo tiempo de una medida, el segundo acorde está acompañado por una granja. La secuencia "|||" marca el final del marco def encode_score(score, keep_fermatas=True, parts_to_mask=[]): """ Encodes a music21 score into a List of chords, where each chord is represented with a (Fermata :: Bool, List[(Note :: Integer, Tie :: Bool)]). If `keep_fermatas` is True, all `has_fermata`s will be False. All tokens from parts in `parts_to_mask` will have output tokens `BLANK_MASK_TXT`. Time is discretized such that each crotchet occupies `FRAMES_PER_CROTCHET` frames. """ encoded_score = [] for chord in (score .quantize((FRAMES_PER_CROTCHET,)) .chordify(addPartIdAsGroup=bool(parts_to_mask)) .flat .notesAndRests):
Código utilizado para codificar la tonalidad music21 usando un esquema de codificación especialTarea modelo
En la parte anterior, se dio una explicación que muestra que la tarea de composición automática puede reducirse a la tarea de predecir una secuencia. En particular, un modelo puede predecir la próxima nota más probable basándose en notas anteriores. Una red neuronal con memoria a largo plazo (LSTM) es la más adecuada para resolver este tipo de problema. Formalmente, el modelo debe predecir P (x
t + 1 | x
t , h
t-1 ), la distribución de probabilidad para las siguientes notas posibles (x
t + 1 ) en función del token actual (x
t ) y el estado oculto anterior (h
t-1 ) . Curiosamente, los modelos de lenguaje basados en redes neuronales recurrentes realizan la misma operación.
En el modo de composición, el modelo se inicializa con el token
START , luego de lo cual selecciona el siguiente token más probable a seguir. Después de eso, el modelo continúa seleccionando el siguiente token más probable utilizando la nota anterior y el estado oculto anterior hasta que se genere un token END. El sistema contiene elementos de temperatura que agregan cierto grado de aleatoriedad para evitar que BachBot componga la misma pieza una y otra vez.
Función de pérdida
Al entrenar un modelo para la predicción, generalmente hay alguna función que debe minimizarse (llamada función de pérdida). Esta función describe la diferencia entre la predicción del modelo y la propiedad de la verdad fundamental. BachBot minimiza la pérdida de entropía cruzada entre la distribución prevista (x
t + 1 ) y la distribución real de la función objetivo. Usar la entropía cruzada como una función de pérdida es un buen punto de partida para una amplia gama de tareas, pero en algunos casos puede usar su propia función de pérdida. Otro enfoque aceptable es tratar de usar varias funciones de pérdida y aplicar un modelo que minimice la pérdida real durante la verificación.
Entrenamiento / prueba
Al entrenar una red neuronal recursiva, BachBot usó la corrección de tokens con el valor x
t + 1 en lugar de aplicar la predicción del modelo. Este proceso, conocido como aprendizaje obligatorio, se utiliza para garantizar la convergencia, ya que las predicciones del modelo producirán naturalmente malos resultados al comienzo de la capacitación. Por el contrario, durante la validación y la composición, la predicción del modelo x
t + 1 debe reutilizarse como entrada para la próxima predicción.
Otras consideraciones
Para aumentar la eficiencia en este modelo, se usaron los siguientes métodos prácticos que son comunes a las redes neuronales LSTM: truncamiento de gradiente normalizado, método de eliminación, normalización de paquetes y método de propagación por error de tiempo truncado (BPTT).
El método de truncamiento de gradiente normalizado elimina el problema del crecimiento incontrolado del valor del gradiente (lo inverso del problema del gradiente de fuga, que se resolvió utilizando la arquitectura de las celdas de memoria LSTM). Con esta técnica, los valores de gradiente que exceden un cierto umbral se truncan o escalan.
El método de exclusión es una técnica en la que algunas neuronas
seleccionadas al azar se desconectan (excluyen) durante el entrenamiento de la red. Esto evita el sobreajuste y mejora la calidad de la generalización. El problema del sobreajuste surge cuando el modelo se optimiza para el conjunto de datos de entrenamiento y, en menor medida, se aplica a muestras fuera de este conjunto. El método de exclusión a menudo empeora la pérdida durante el entrenamiento, pero la mejora en la etapa de verificación (más sobre esto a continuación).
El cálculo del gradiente en una red neuronal recurrente para una secuencia de 1000 elementos es equivalente en costo a los pasos hacia adelante y hacia atrás en la red neuronal de distribución directa de 1000 capas.
El método de
propagación de error truncada (BPTT) a lo largo del tiempo se usa para reducir el costo de actualizar los parámetros durante el entrenamiento. Esto significa que los errores se propagan solo durante un número fijo de pasos contados desde el momento actual. Tenga en cuenta que las dependencias de aprendizaje a largo plazo todavía son posibles con el método BPTT, ya que los estados latentes ya se han revelado en muchos pasos anteriores.
Parámetros
La siguiente es una lista de parámetros relevantes para modelos de redes neuronales recurrentes / redes neuronales con memoria a largo plazo a corto plazo:
- El número de capas . Aumentar este parámetro puede aumentar la eficiencia del modelo, pero llevará más tiempo entrenarlo. Además, demasiadas capas pueden conducir a un sobreajuste.
- La dimensión del estado latente . El aumento de este parámetro puede aumentar la complejidad del modelo, sin embargo, esto puede conducir a un sobreajuste.
- Dimensión de las comparaciones de vectores
- La longitud de secuencia / número de tramas antes de truncar la propagación hacia atrás del error a lo largo del tiempo.
- Probabilidad de exclusión de neuronas . La probabilidad con la que una neurona será excluida de la red durante cada ciclo de actualización.
La metodología para seleccionar el conjunto óptimo de parámetros se discutirá más adelante en este artículo.
Implementación, entrenamiento y pruebas.
Selección de plataforma
Actualmente, hay muchas plataformas que le permiten implementar modelos de aprendizaje automático en varios lenguajes de programación (¡incluso JavaScript!). Las plataformas populares incluyen
scikit-learn ,
TensorFlow y
Torch .
La biblioteca Torch fue seleccionada como la plataforma para el proyecto BachBot. Al principio, se probó la biblioteca TensorFlow, pero en ese momento utilizó redes neuronales recurrentes extensas, lo que condujo a un desbordamiento de la RAM de la GPU. Torch es una plataforma de computación científica impulsada por el rápido lenguaje de programación LuaJIT *. La plataforma Torch contiene excelentes bibliotecas para trabajar con redes neuronales y optimización.
Implementación y capacitación de modelos.
La implementación, obviamente, variará según el idioma y la plataforma que elija. Para saber cómo BachBot implementa redes neuronales con memoria a corto y largo plazo utilizando Torch, consulte los scripts utilizados para entrenar y establecer los parámetros de BachBot. Estas secuencias de comandos están disponibles en el sitio web de
Feynman Lyang GitHub.Un buen punto de partida para navegar por el repositorio es el
script 1-train.zsh . Con él, puede encontrar la ruta al archivo
bachbot.py .
Más precisamente, el script principal para configurar los parámetros del modelo es el archivo
LSTM.lua . El script para entrenar el modelo es el archivo
train.lua .
Optimización de hiperparámetros
Para buscar los valores óptimos de los hiperparámetros, se utilizó el método de búsqueda de cuadrícula utilizando la siguiente cuadrícula de parámetros.
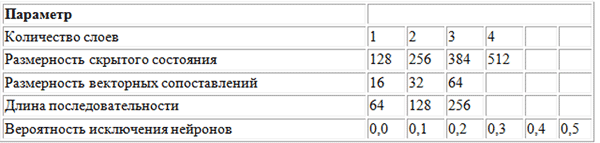 Cuadrícula de parámetros utilizados por BachBot en la búsqueda de cuadrícula
Cuadrícula de parámetros utilizados por BachBot en la búsqueda de cuadrículaUna búsqueda de cuadrícula es una búsqueda completa de todas las combinaciones posibles de parámetros. Otros métodos sugeridos para optimizar los hiperparámetros son la búsqueda aleatoria y la optimización bayesiana.
El conjunto óptimo de hiperparámetros detectados como resultado de una búsqueda de cuadrícula es el siguiente: número de capas = 3, dimensión del estado oculto = 256, dimensión de las comparaciones de vectores = 32, longitud de secuencia = 128, probabilidad de eliminación de neuronas = 0.3.
Este modelo alcanzó una pérdida de entropía cruzada de 0.324 durante el entrenamiento y 0.477 en la etapa de verificación. El gráfico de la curva de aprendizaje demuestra que el proceso de aprendizaje converge después de 30 iteraciones (≈28.5 minutos cuando se usa una sola GPU).
Los gráficos de pérdida durante el entrenamiento y durante la fase de verificación también pueden ilustrar el efecto de cada hiperparámetro. De particular interés para nosotros es la probabilidad de eliminar neuronas:
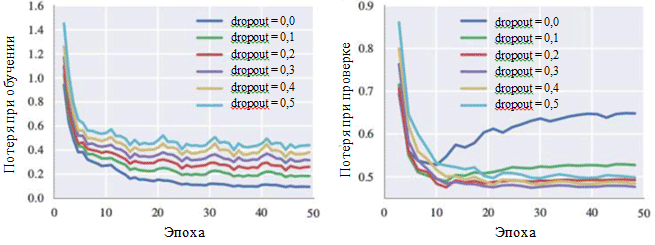 Curvas de aprendizaje para varias configuraciones de métodos de exclusión
Curvas de aprendizaje para varias configuraciones de métodos de exclusiónSe puede ver en la figura que el método de eliminación realmente evita la aparición de sobreajuste. Aunque con una probabilidad de exclusión de 0.0, la pérdida durante el entrenamiento es mínima, en la etapa de verificación, la pérdida tiene un valor máximo. Grandes valores de probabilidad conducen a un aumento de las pérdidas durante el entrenamiento y una disminución de las pérdidas en la etapa de verificación. El valor mínimo de la pérdida durante la fase de verificación cuando se trabaja con BachBot se corrigió con una probabilidad de excepción de 0.3.
Métodos de evaluación alternativos (opcional)
Para algunos modelos, especialmente para aplicaciones creativas como componer música, la pérdida puede no ser una medida adecuada del éxito del sistema. En cambio, la percepción humana subjetiva puede ser el mejor criterio.
El objetivo del proyecto BachBot es componer automáticamente música que no se pueda distinguir de las propias composiciones de Bach. Para evaluar el éxito de los resultados, se realizó una encuesta de usuarios en Internet. La encuesta recibió la forma de un concurso en el que se pidió a los usuarios que determinaran qué obras pertenecen al proyecto BachBot y cuáles a Bach.
Los resultados de la encuesta mostraron que los participantes de la encuesta (759 personas con diferentes niveles de capacitación) pudieron distinguir con precisión entre dos muestras en solo el 59 por ciento de los casos. ¡Esto es solo un 9 por ciento más alto que el resultado de suposiciones aleatorias! ¡Pruebe la
encuesta BachBot usted mismo!
Adaptando el modelo a la armonización
Ahora BachBot puede calcular P (x
t + 1 | x
t , h
t-1 ), la distribución de probabilidad para las siguientes notas posibles en función de la nota actual y el estado oculto anterior. Este modelo de predicción secuencial puede adaptarse posteriormente para armonizar la melodía. Tal modelo adaptado es necesario para armonizar la melodía, modulada con la ayuda de las emociones, como parte de un proyecto musical con una presentación de diapositivas.
Cuando se trabaja con la armonización del modelo, se proporciona una melodía predefinida (por lo general, esta es una parte soprano), y luego el modelo debe componer música para el resto de las piezas. Para llevar a cabo esta tarea, se utiliza una búsqueda codiciosa de "mejor primero" con la restricción de que las notas de la melodía son fijas. Los algoritmos codiciosos implican decisiones que son óptimas desde un punto de vista local. Entonces, a continuación se muestra una estrategia simple utilizada para la armonización:
Suponga que x t son tokens en la armonización propuesta. En el paso de tiempo t, si la nota corresponde a la melodía, entonces x t es igual a la nota dada. De lo contrario, x t es igual a la siguiente nota más probable de acuerdo con las predicciones del modelo. El código para esta adaptación del modelo se puede encontrar en el sitio web de Feynman Lyang GitHub: HarmModel.lua , harmonize.lua .
El siguiente es un ejemplo de armonización de la canción de cuna Twinkle, Twinkle, Little Star con BachBot, utilizando la estrategia anterior.
 Armonización de la canción de cuna de Twinkle, Twinkle, Little Star con BachBot (en la parte soprano). Partes de viola, tenor y bajo también se rellenaron con BachBot
Armonización de la canción de cuna de Twinkle, Twinkle, Little Star con BachBot (en la parte soprano). Partes de viola, tenor y bajo también se rellenaron con BachBotEn este ejemplo, la melodía de la canción de cuna Twinkle, Twinkle, Little Star se da en la parte soprano. Después de eso, las partes de viola, tenor y bajo se llenaron usando BachBot usando una estrategia de armonización. Y así
es como suena .
A pesar de que BachBot ha demostrado un buen rendimiento en la realización de esta tarea, existen ciertas limitaciones asociadas con este modelo. Más precisamente, el algoritmo
no mira hacia la melodía y usa solo la nota actual de la melodía y el contexto pasado para generar notas posteriores. Cuando las personas armonizan una melodía, pueden cubrir toda la melodía, lo que simplifica la derivación de armonizaciones adecuadas. El hecho de que este modelo no sea capaz de hacer esto puede generar
sorpresas debido a restricciones en el uso de información posterior que causan errores. Para resolver este problema, se puede utilizar la llamada
búsqueda de haz .
Cuando se usa la búsqueda de haz, se verifican varias líneas de movimiento. Por ejemplo, en lugar de usar solo una, la nota más probable, que se está haciendo actualmente, se pueden considerar cuatro o cinco notas más probables, después de lo cual el algoritmo continúa su trabajo con cada una de estas notas. Examinar las diversas opciones puede ayudar al modelo a
recuperarse de los errores . La búsqueda de haces se usa comúnmente en aplicaciones de procesamiento de lenguaje natural para crear oraciones.
Las melodías moduladas con la ayuda de las emociones ahora se pueden pasar a través de un modelo de armonización para completarlas.