
Hace poco más de un año,
revisamos la aplicación
Splunk Machine Learning Toolkit , con la que puede analizar los datos de la máquina en la plataforma Splunk utilizando varios algoritmos de aprendizaje automático.
Hoy queremos hablar sobre las actualizaciones que han aparecido durante el año pasado. Se han lanzado muchas versiones nuevas, se han agregado varios algoritmos y visualizaciones que permitirán llevar el análisis de datos en Splunk a un nuevo nivel.
Nuevos algoritmos
Antes de hablar sobre algoritmos, debe tenerse en cuenta que existe una
API ML-SPL con la que puede cargar cualquier algoritmo de código abierto de más de 300 algoritmos Python. Sin embargo, para esto necesita poder programar hasta cierto punto en Python.
Por lo tanto, prestaremos atención a aquellos algoritmos que antes solo estaban disponibles después de manipular Python, pero que ahora están integrados en la aplicación y pueden ser utilizados fácilmente por todos.
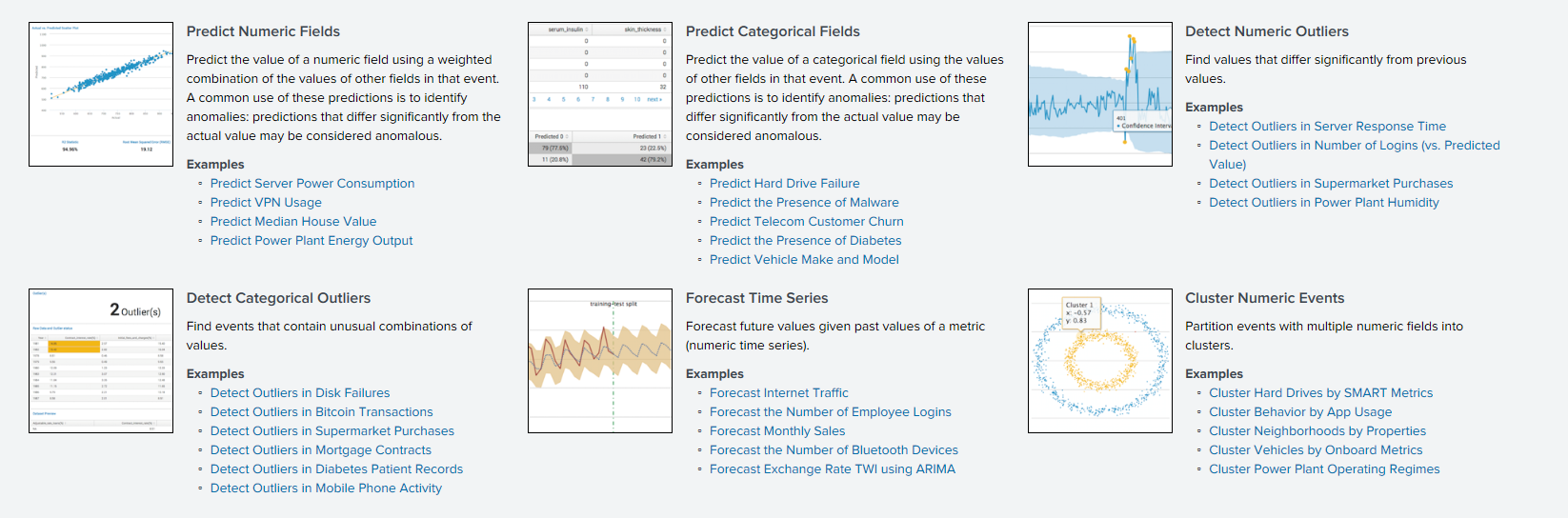 ACF (función de autocorrelación)
ACF (función de autocorrelación)Una función de autocorrelación muestra la relación entre una función y su copia desplazada por la cantidad de cambio de tiempo. ACF lo ayuda a encontrar secciones duplicadas o determinar la frecuencia de la señal, oculta debido a la superposición de ruidos y vibraciones en otras frecuencias.
PACF (función de autocorrelación parcial)La función de autocorrelación privada muestra la correlación entre las dos variables, menos el efecto de todos los valores internos de autocorrelación. La autocorrelación privada en un cierto retraso es similar a la autocorrelación ordinaria, pero su cálculo excluye la influencia de la autocorrelación con retrasos más pequeños. En la práctica, la autocorrelación privada proporciona una imagen más "limpia" de las dependencias periódicas.
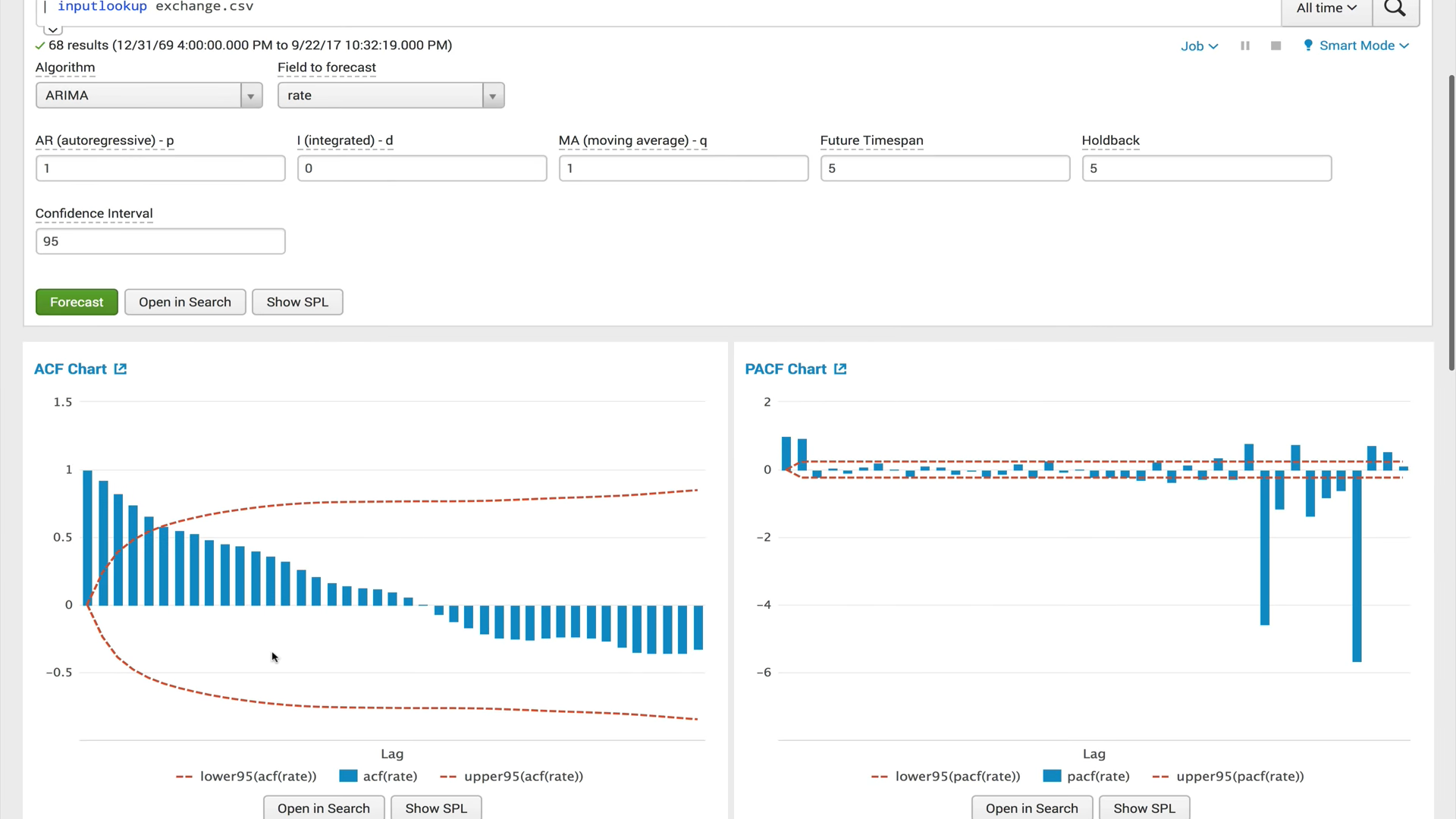
ARIMA (proceso integrado de autorregresión y media móvil)El modelo ARIMA es uno de los modelos más populares para construir pronósticos a corto plazo. Los valores autorregresivos expresan la dependencia del valor actual de las series temporales con los anteriores, y el promedio móvil del modelo determina el efecto de los errores de pronóstico anteriores (también llamados ruido blanco) en el valor actual.
 Gradient Boosting Classifier y Gradient Boosting Regressor
Gradient Boosting Classifier y Gradient Boosting RegressorEl aumento de gradiente es un método de aprendizaje automático utilizado para problemas de regresión y clasificación que crea un modelo de predicción en forma de un conjunto de modelos débiles, generalmente árboles de decisión. Construye el modelo en etapas, cuando cada algoritmo posterior busca compensar las deficiencias de la composición de todos los algoritmos anteriores. Inicialmente, el concepto de impulso surgió en los trabajos en relación con la cuestión de si es posible, teniendo muchos algoritmos de aprendizaje malos (ligeramente diferentes de la definición aleatoria), obtener uno bueno. En los últimos 10 años, impulsar ha seguido siendo uno de los métodos de aprendizaje automático más populares, junto con las redes neuronales. Las razones principales son la simplicidad, la versatilidad, la flexibilidad (la capacidad de construir varias modificaciones) y, lo más importante, la alta capacidad de generalización.
X-significaEl algoritmo de agrupación X-means es un algoritmo avanzado de k-means que determina automáticamente el número de clusters en función del criterio de información bayesiano (BIC). Este algoritmo es conveniente de usar cuando no hay información preliminar sobre el número de grupos en los que se pueden dividir estos datos.
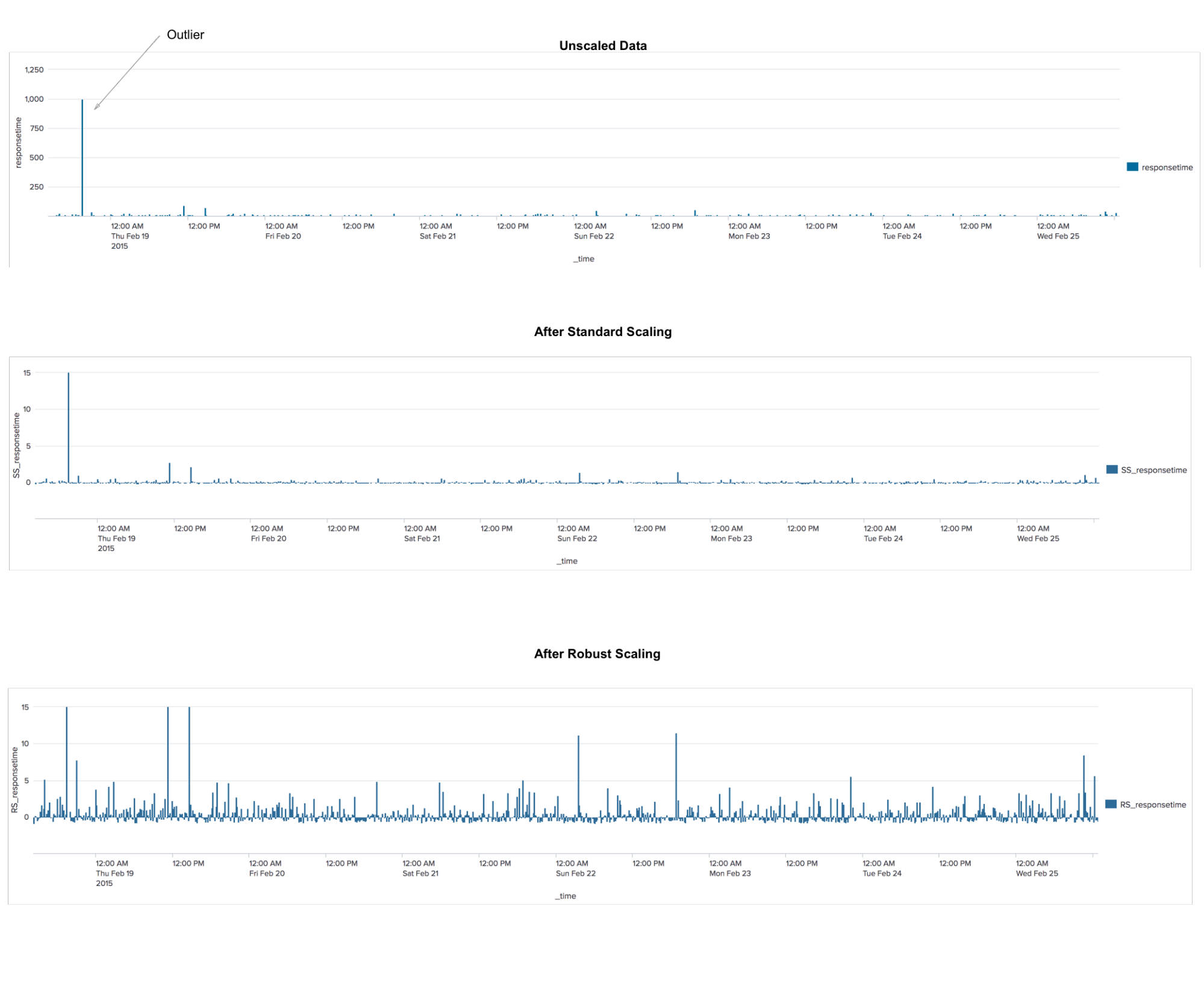
RobustscalerEste es un algoritmo de preprocesamiento de datos. La aplicación es similar al algoritmo StandardScaler, que transforma los datos para que para cada característica el promedio sea 0 y la varianza sea 1, lo que da como resultado que todas las características tengan la misma escala. Sin embargo, esta escala no garantiza la recepción de ningún valor mínimo y máximo específico de los atributos. RobustScaler es similar a StandardScaler en que, como resultado de su aplicación, las características tendrán la misma escala. Sin embargo, RobustScaler utiliza la mediana y los cuartiles en lugar de la media y la varianza. Esto permite que RobustScaler ignore los valores atípicos o los errores de medición, lo que puede ser un problema para otros métodos de escalado.
 TFIDF
TFIDFUna medida estadística utilizada para evaluar la importancia de una palabra en el contexto de un documento que forma parte de una colección de documentos. El principio es este: si una palabra se encuentra a menudo en un documento, mientras que rara vez se encuentra en todos los demás documentos, por lo tanto, esta palabra es de gran importancia para el documento en sí.
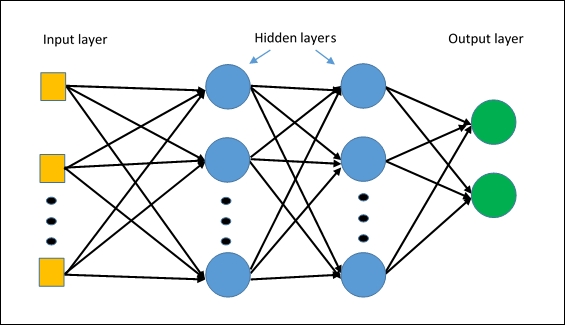
MLPClassifierEl primer algoritmo de red neuronal en Splunk. El algoritmo se construye sobre la base de un
perceptrón multicapa , que capturará relaciones no lineales en los datos.
Administración
En nuevas versiones, la administración de la aplicación ha cambiado significativamente.
En primer lugar, se ha agregado un
modelo a seguir de acceso a varios modelos y experimentos.
En segundo lugar,
se ha introducido una nueva interfaz para
gestionar modelos . Ahora puede ver fácilmente qué tipos de modelos tiene, verificar la configuración de cada modelo (por ejemplo, qué variables se usaron para entrenarlo) y ver o actualizar la configuración de uso compartido de cada modelo.
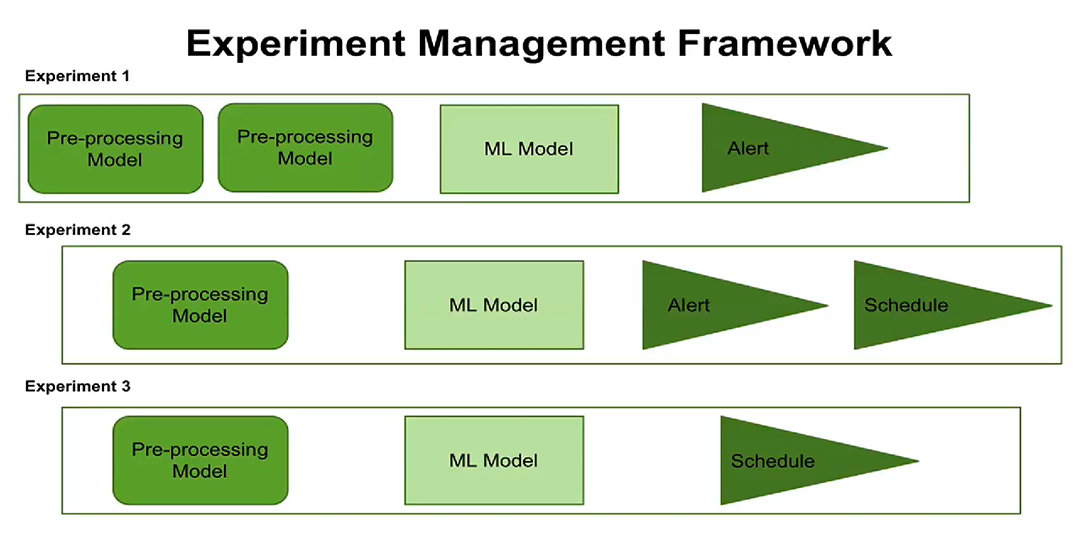
En tercer lugar, la aparición del concepto de gestión de experimentos. Ahora puede
configurar la ejecución de experimentos en un horario, configurar alertas. Los usuarios pueden ver cuándo cada experimento está programado para ejecutarse, qué pasos de procesamiento y parámetros están configurados para cada experimento.
El nuevo concepto de administración de experimentos ahora le brinda la oportunidad de crear y administrar varios experimentos a la vez, para registrar cuándo se realizaron estos experimentos y qué resultados se obtuvieron.
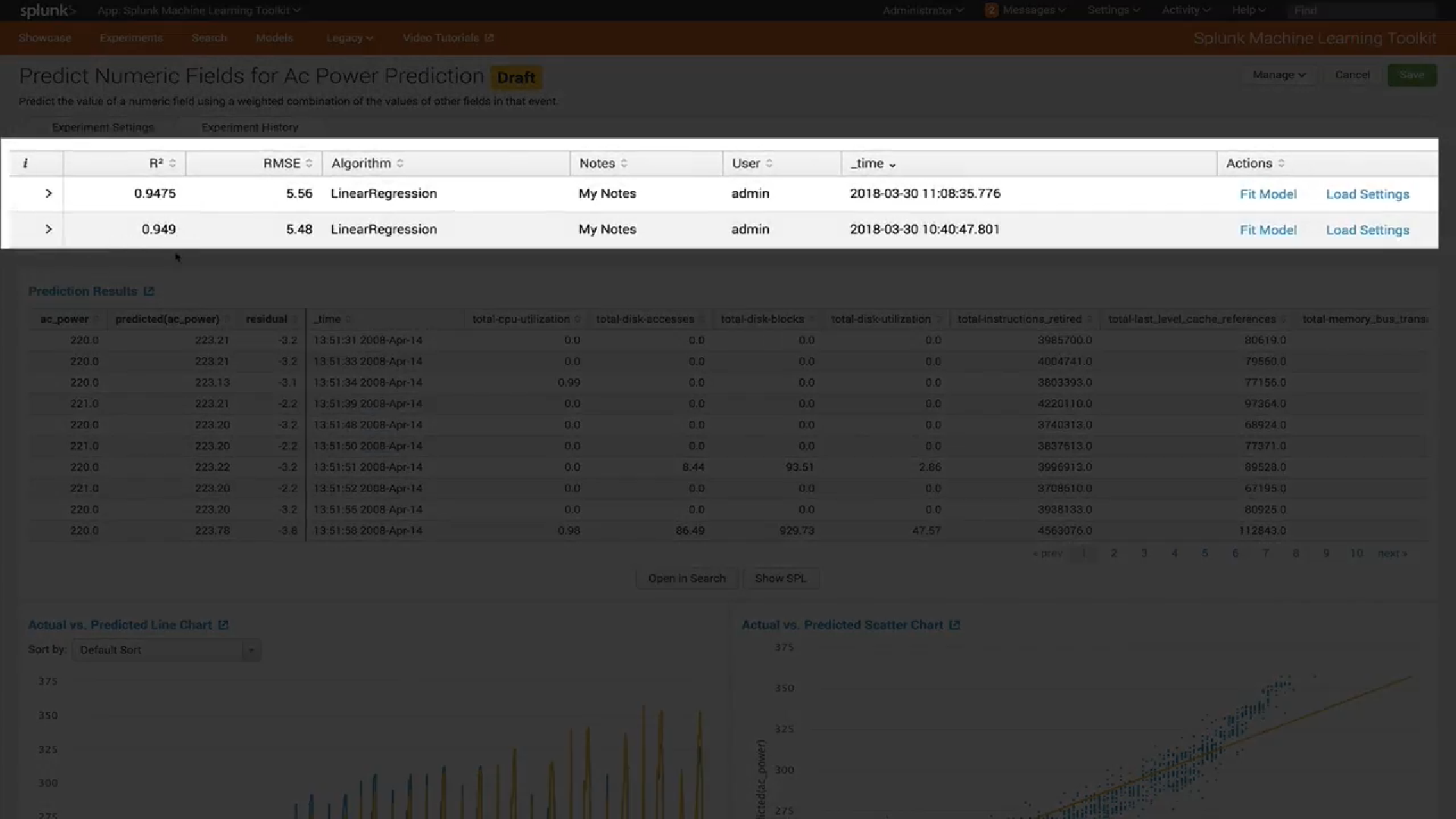
Visualización
En la última versión de MLTK 3.4, se ha agregado un nuevo tipo de visualización. El famoso
Box Plot o, como también lo llamamos, "Cajas con bigote".
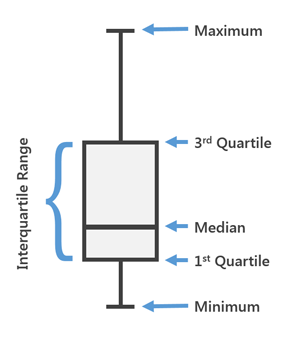
El diagrama de caja se usa en estadísticas descriptivas, usándolo puede ver convenientemente la mediana (o, si es necesario, el promedio), los cuartiles inferior y superior, los valores mínimos y máximos de la muestra y los valores atípicos. Varios de estos cuadros se pueden dibujar uno al lado del otro para comparar visualmente una distribución con otra. Las distancias entre las diferentes partes del cuadro le permiten determinar el grado de dispersión (dispersión) y la asimetría de los datos e identificar valores atípicos.
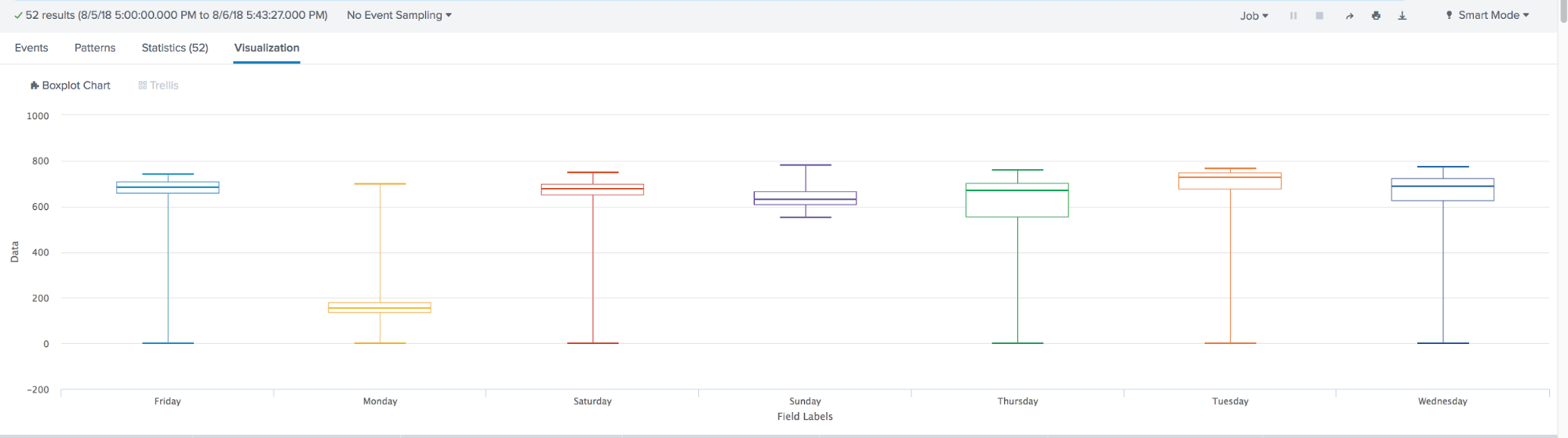
En resumen, durante el año, el aprendizaje automático en Splunk ha dado un gran paso adelante. Aparecido:
- Muchos algoritmos nuevos incorporados, como: ACF, PACF, ARIMA, Gradient BoostingClassifier, Gradient Boosting Regressor, X-means, RobustScaler, TFIDF, MLPClassifier;
- Modelo de acceso basado en roles y la capacidad de gestionar modelos y experimentos;
- Gráfico de caja de visualización
