
Muchos desarrolladores de pruebas de IU de iOS probablemente estén familiarizados con el problema del tiempo de ejecución de la prueba. Badoo ejecuta más de 1,400 pruebas de extremo a extremo para aplicaciones iOS para cada ejecución de regresión. Estas son más de 40 horas de pruebas que pasan en 30 minutos reales.
Nikolai Abalov de Badoo compartió cómo logró acelerar la ejecución de la prueba de 1.5 horas a 30 minutos; cómo desentrañan las pruebas estrechamente relacionadas y la infraestructura de iOS yendo al servidor del dispositivo; cómo facilitó la ejecución de pruebas en paralelo y facilitó el soporte y la escala de las pruebas y la infraestructura.
Aprenderá lo fácil que es ejecutar pruebas en paralelo con herramientas como fbsimctl, y cómo separar las pruebas y la infraestructura puede facilitar el alojamiento, el soporte y la escala de sus pruebas.
Inicialmente, Nikolai presentó un informe en la conferencia de Heisenbug (puede ver el
video ), y ahora para Habr hicimos una versión de texto del informe. El siguiente es un relato en primera persona:
Hola a todos, hoy hablaré sobre las pruebas de escala para iOS. Mi nombre es Nicholas, principalmente trato con la infraestructura de iOS en Badoo. Antes de eso, trabajó para 2GIS durante tres años, participó en el desarrollo y la automatización, en particular, escribió Winium.Mobile, una implementación de WebDriver para Windows Phone. Me llevaron a Badoo para trabajar en la automatización de Windows Phone, pero después de un tiempo la empresa decidió suspender el desarrollo de esta plataforma. Y me ofrecieron tareas interesantes para la automatización de iOS, sobre esto les contaré hoy.
¿De qué vamos a hablar? El plan es el siguiente:
- Una declaración informal del problema, una introducción a las herramientas utilizadas: cómo y por qué.
- Pruebas paralelas en iOS y cómo se desarrolló (en particular, de acuerdo con la historia de nuestra empresa, desde que comenzamos a trabajar en él en 2015).
- El servidor del dispositivo es la parte principal del informe. Nuestro nuevo modelo para pruebas de paralelización.
- Los resultados que logramos con el servidor.
- Si no tiene 1500 pruebas, es posible que realmente no necesite un servidor de dispositivo, pero aún puede obtener cosas interesantes y hablaremos de ellas. Se pueden aplicar si tiene 10-25 pruebas, y esto aún dará aceleración o estabilidad adicional.
- Y finalmente, un informe.
Las herramientas
El primero es un poco sobre quién usa qué. Nuestra pila es un poco no estándar, porque usamos Calabash y WebDriverAgent (que nos da velocidad y puertas traseras Calabash cuando automatizamos nuestra aplicación y al mismo tiempo acceso completo al sistema y otras aplicaciones a través de WebDriverAgent). WebDriverAgent es una implementación de Facebook de WebDriver para iOS que Appium utiliza internamente. Y Calabash es un servidor integrado para la automatización. Nosotros mismos escribimos las pruebas en forma legible por humanos usando Pepino. Es decir, en nuestra empresa pseudo-BDD. Y debido a que usamos pepino y calabaza, heredamos Ruby, todo el código está escrito en él. Hay mucho código y debes seguir escribiendo en Ruby. Para ejecutar pruebas en paralelo, utilizamos
parallel_cucumber , una herramienta escrita por uno de mis colegas de Badoo.
Comencemos con lo que teníamos. Cuando comencé a preparar el informe, había 1200 pruebas. Cuando se completaron, eran 1300. Mientras llegué aquí, ya había 1400 pruebas. Estas son pruebas de extremo a extremo, no pruebas de unidad y pruebas de integración. Ellos componen 35-40 horas de tiempo de computadora en un simulador. Pasaron antes en una hora y media. Te diré cómo comenzaron a pasar en 30 minutos.
Tenemos un flujo de trabajo en nuestra empresa con sucursales, revisiones y pruebas en ejecución en estas sucursales. Los desarrolladores crean aproximadamente 10 solicitudes al repositorio principal de nuestra aplicación. Pero también tiene componentes que se comparten con otras aplicaciones, por lo que a veces hay más de diez. Como resultado, 30 ejecuciones de prueba por día, al menos. Dado que los desarrolladores presionan, se dan cuenta de que comenzaron con errores, recargan y todo esto inicia una regresión completa, simplemente porque podemos ejecutarlo. En la misma infraestructura, lanzamos proyectos adicionales, como Liveshot, que toma capturas de pantalla de la aplicación en los principales scripts de usuario en todos los idiomas, para que los traductores puedan verificar la corrección de la traducción, ya sea que se ajuste a la pantalla, etc. Como resultado, salen aproximadamente una y media mil horas de tiempo de máquina en este momento.
En primer lugar, queremos que los desarrolladores y evaluadores confíen en la automatización y confíen en ella para reducir la regresión manual. Para que esto suceda, es necesario lograr una operación rápida y, lo más importante, estable y confiable desde la automatización. Si las pruebas pasan en una hora y media, el desarrollador se cansará de esperar los resultados, comenzará a hacer otra tarea, su enfoque cambiará. Y cuando caen algunas pruebas, no estará muy contento de tener que regresar, cambiar su atención y reparar algo. Si las pruebas no son confiables, con el tiempo, las personas comienzan a percibirlas solo como una barrera. Caen constantemente, aunque no hay errores en el código. Estas son pruebas escamosas, algún tipo de obstáculo. En consecuencia, estos dos puntos se han revelado en estos requisitos:
- Las pruebas deben tomar 30 minutos o más rápido.
- Deben ser estables.
- Deben ser escalables para que podamos agregar media hora para agregar otras cien pruebas.
- La infraestructura debe mantenerse y desarrollarse fácilmente.
- En simuladores y dispositivos físicos, todo debería comenzar de la misma manera.
Principalmente ejecutamos pruebas en simuladores, y no en dispositivos físicos, porque es más rápido, más estable y más fácil. Los dispositivos físicos se usan solo para pruebas que realmente requieren esto. Por ejemplo, cámara, notificaciones push y similares.
¿Cómo satisfacer estos requisitos y hacer todo bien? La respuesta es muy simple: ¡eliminamos dos tercios de las pruebas! Esta solución se ajusta en 30 minutos (porque solo queda un tercio de las pruebas), se escala fácilmente (se pueden eliminar más pruebas) y aumenta la confiabilidad (porque lo primero que eliminamos son las pruebas más poco confiables). Eso es todo para mí. Preguntas?
Pero en serio, hay algo de verdad en cada broma. Si tiene muchas pruebas, debe revisarlas y comprender cuáles brindan beneficios reales. Teníamos una tarea diferente, así que decidimos ver qué se puede hacer.
El primer enfoque consiste en filtrar las pruebas en función de la cobertura o los componentes. Es decir, seleccione las pruebas apropiadas en función de los cambios de archivo en la aplicación. No hablaré sobre esto, pero esta es una de las tareas que estamos resolviendo en este momento.
Otra opción es acelerar y estabilizar las pruebas por sí mismas. Realiza una prueba específica, observa qué pasos requieren más tiempo y si se pueden optimizar de alguna manera. Si algunos de ellos son muy inestables con mucha frecuencia, los corrige, porque reduce los reinicios de prueba y todo va más rápido.
Y, finalmente, una tarea completamente diferente: paralelizar pruebas, distribuirlas en una gran cantidad de simuladores y proporcionar una infraestructura escalable y estable para que haya mucho que paralelizar.
En este artículo hablaremos principalmente sobre los últimos dos puntos y al final, en consejos y trucos, tocaremos el punto sobre velocidad y estabilización.
Pruebas paralelas para iOS
Comencemos con el historial de pruebas paralelas para iOS en general y Badoo en particular. Para comenzar, aritmética simple, aquí, sin embargo, hay un error en la fórmula si comparamos las dimensiones:

Hubo 1300 pruebas para un simulador, resultaron 40 horas. Entonces Satish, mi líder, viene y dice que necesita media hora. Tienes que inventar algo. X aparece en la fórmula: cuántos simuladores se deben ejecutar, de modo que todo transcurra en media hora. La respuesta es 80 simuladores. Y de inmediato surge la pregunta, dónde colocar estos 80 simuladores, porque no caben en ningún lado.
Hay varias opciones: puede ir a nubes como SauceLabs, Xamarin o AWS Device Farm. Y puedes pensar en todo en casa y hacerlo bien. Dado que este artículo existe, hicimos todo bien en casa. Decidimos que sí, porque una nube con tal escala sería bastante costosa, y también hubo una situación en la que salió iOS 10 y Appium lanzó soporte por casi un mes. Esto significa que en SauceLabs durante un mes no pudimos probar automáticamente iOS 10, lo que no nos convenía en absoluto. Además, todas las nubes están cerradas y no puede afectarlas.
Entonces, decidimos hacer todo internamente. Comenzamos en algún lugar en 2015, luego Xcode no pudo ejecutar más de un simulador. Resultó que no puede ejecutar más de un simulador bajo un mismo usuario en la misma máquina. Si tiene muchos usuarios, puede ejecutar simuladores tanto como desee. A mi colega Tim Bawerstock se le ocurrió un modelo en el que vivimos lo suficiente.

Hay un agente (TeamCity, Jenkins Node y similares), ejecuta parallel_cucumber, que simplemente va a máquinas remotas a través de ssh. La imagen muestra dos autos para dos usuarios. Todos los archivos necesarios, como las pruebas, se copian y se ejecutan en máquinas remotas a través de ssh. Y las pruebas ya ejecutan el simulador localmente en el escritorio actual. Para que esto funcione, primero debe ir a cada máquina, crear, por ejemplo, 5 usuarios, si desea 5 simuladores, hacer que un usuario inicie sesión automáticamente, abrir la pantalla compartida para el resto, para que siempre tengan un escritorio. Y configure el demonio ssh para que tenga acceso a los procesos en el escritorio. De una manera tan simple, comenzamos a ejecutar pruebas en paralelo. Pero hay varios problemas en esta imagen. En primer lugar, las pruebas controlan el simulador, están en el mismo lugar que el simulador. Es decir, siempre deben ejecutarse con amapolas, consumen recursos que podrían gastarse en ejecutar simuladores. Como resultado, tiene menos simuladores en la máquina y cuestan más. Otro punto es que debe ir a cada máquina, configurar usuarios. Y luego te topas con el límite global. Si hay cinco usuarios y generan muchos procesos, en algún momento los descriptores terminarán en el sistema. Una vez alcanzado el límite, las pruebas comenzarán a caer al intentar abrir nuevos archivos e iniciar nuevos procesos.

En 2016-2017, decidimos cambiar a un modelo ligeramente diferente. Vimos un
informe de Lawrence Lomax de Facebook: presentaron fbsimctl y explicaron parcialmente cómo funciona la infraestructura en Facebook. También hubo un
informe de Viktor Koronevich sobre este modelo. La imagen no es muy diferente de la anterior: acabamos de deshacernos de los usuarios, pero este es un gran paso adelante, ya que ahora solo hay un escritorio, se inician menos procesos y los simuladores se han vuelto más baratos. Hay tres simuladores en esta imagen, no dos, ya que se han liberado recursos para lanzar uno adicional. Vivimos con este modelo durante mucho tiempo, hasta mediados de octubre de 2017, cuando comenzamos a cambiar a nuestro servidor de dispositivos remotos.

Entonces parecía hierro. A la izquierda hay una caja con macbooks. Por qué realizamos todas las pruebas en ellos es una gran historia separada. No fue una buena idea ejecutar las pruebas en los macbooks que insertamos en la caja de hierro, porque en algún momento de la tarde comenzaron a sobrecalentarse, ya que el calor no sale bien cuando están en la superficie. Las pruebas se volvieron inestables, especialmente cuando los simuladores comenzaron a fallar al cargar.
Lo decidimos simplemente: colocamos las computadoras portátiles "en carpas", el área de flujo de aire aumentó y la estabilidad de la infraestructura aumentó repentinamente.

Entonces, a veces no tiene que lidiar con el software, sino dar vueltas a las computadoras portátiles.
Pero si miras esta imagen, hay un montón de cables, adaptadores y, en general, estaño. Esta es la parte de hierro, y todavía estaba bien. En el software, se estaba produciendo una combinación completa de pruebas con la infraestructura, y era imposible continuar viviendo así.
Identificamos los siguientes problemas:
- El hecho de que las pruebas estaban estrechamente relacionadas con la infraestructura, lanzaron simuladores y gestionaron todo su ciclo de vida.
- Esto dificultó el escalado, porque agregar un nuevo nodo implicaba configurarlo tanto para pruebas como para ejecutar simuladores. Por ejemplo, si desea actualizar Xcode, debe agregar una solución alternativa directamente a las pruebas, ya que se ejecutan en diferentes versiones de Xcode. Algunos si montones parecen ejecutar el simulador.
- Las pruebas están vinculadas a la máquina donde se encuentra el simulador, y esto cuesta un centavo, ya que deben ejecutarse con amapolas en lugar de * nix, que son más baratas.
- Y siempre fue muy fácil profundizar en el simulador. En algunas pruebas, fuimos al sistema de archivos del simulador, eliminamos algunos archivos allí o los cambiamos, y todo estuvo bien hasta que se hizo de tres maneras diferentes en tres pruebas diferentes, y luego, inesperadamente, el cuarto comenzó a fallar si no tuvo la suerte de comenzar después esos tres
- Y el último momento: los recursos no fueron rebuscados de ninguna manera. Por ejemplo, había cuatro agentes de TeamCity, cinco máquinas estaban conectadas a cada una y las pruebas solo podían ejecutarse en sus cinco máquinas. No existía un sistema de administración de recursos centralizado, debido a esto, cuando solo se presenta una tarea, se ejecuta en cinco máquinas y las otras 15 están inactivas. Debido a esto, las construcciones tomaron mucho tiempo.
Nuevo modelo
Decidimos cambiarnos a una hermosa modelo nueva.

Se eliminaron todas las pruebas en una máquina, donde el agente TeamCity. Esta máquina ahora puede estar en * nix o incluso en Windows si así lo desea. Se comunicarán a través de HTTP con algo que llamaremos servidor del dispositivo. Todos los simuladores y dispositivos físicos se ubicarán en algún lugar allí, y las pruebas se ejecutarán aquí, solicitarán el dispositivo a través de HTTP y continuarán trabajando con él. El diagrama es muy simple, solo hay dos elementos en el diagrama.

En realidad, por supuesto, ssh y más quedaron detrás del servidor. Pero ahora no molesta a nadie, porque los chicos que escriben las pruebas están en la parte superior de este diagrama, y tienen algún tipo de interfaz específica para trabajar con un simulador local o remoto, por lo que están bien. Y ahora trabajo a continuación, y tengo todo como estaba. Tenemos que vivir con eso.
Que da
- Primero, la división de la responsabilidad. En algún momento de las pruebas de automatización, debe considerarlo como un desarrollo normal. Emplea los mismos principios y enfoques que usan los desarrolladores.
- El resultado es una interfaz estrictamente definida: no puede hacer algo directamente con el simulador, para esto necesita abrir un ticket en el servidor del dispositivo, y descubriremos cómo hacerlo de manera óptima sin romper otras pruebas.
- El entorno de prueba se ha vuelto más barato porque lo aumentamos en * nix, que son mucho más baratos que las amapolas de servicio.
- Y apareció el intercambio de recursos, porque hay una sola capa con la que todos se comunican, puede planificar la distribución de máquinas ubicadas detrás de ella, es decir. compartir recursos entre agentes.
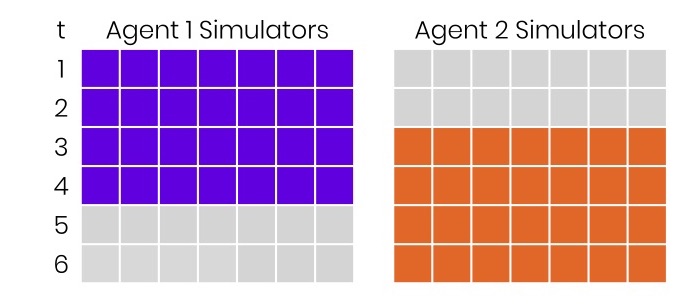
Arriba se representa, como era antes. A la izquierda hay unidades convencionales de tiempo, digamos, decenas de minutos. Hay dos agentes, 7 simuladores están conectados a cada uno, en el momento en que entra la construcción 0 y toma 40 minutos. Después de 20 minutos, llega otro y toma el mismo tiempo. Todo parece genial. Pero allí, y hay cuadrados grises. Significan que perdimos dinero porque no utilizamos los recursos disponibles.
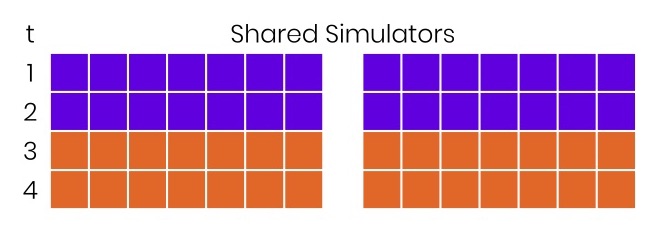
Puede hacer esto: la primera compilación entra y ve todos los simuladores gratuitos, se distribuye y las pruebas se aceleran dos veces. No habia nada que hacer. En realidad, esto sucede a menudo porque los desarrolladores rara vez empujan sus brunches en el mismo momento. Aunque a veces esto sucede, y comienzan las "damas", las "pirámides" y similares. Sin embargo, en la mayoría de los casos, se puede obtener aceleración libre dos veces simplemente instalando un sistema de gestión centralizado para todos los recursos.
Otras razones para pasar a esto:
- Boxeo negro, es decir, ahora el servidor del dispositivo es un cuadro negro. Cuando escribe pruebas, solo piensa en las pruebas y piensa que este cuadro negro siempre funcionará. Si no funciona, simplemente ve y llama a quien sea que lo haga, es decir, a mí. Y tengo que arreglarlo. No solo yo, de hecho, hay varias personas involucradas en toda la infraestructura.
- No puede estropear el interior del simulador.
- No tiene que poner un millón de utilidades en la máquina para que todo comience; solo tiene que poner una utilidad que oculta todo el trabajo en el servidor del dispositivo.
- Se ha vuelto más fácil actualizar la infraestructura, de la que hablaremos en algún momento al final.
Una pregunta razonable: ¿por qué no Selenium Grid? En primer lugar, teníamos mucho código heredado, 1,500 pruebas, 130 mil líneas de código para diferentes plataformas. Y todo esto fue controlado por parallel_cucumber, que creó el ciclo de vida del simulador fuera de la prueba. Es decir, había un sistema especial que cargaba el simulador, esperaba que estuviera listo y lo entregaba a prueba. Para no reescribir todo, decidimos intentar no utilizar Selenium Grid.
También tenemos muchas acciones no estándar, y rara vez usamos WebDriver. La parte principal de las pruebas en Calabash y WebDriver son solo auxiliares. Es decir, no usamos selenio en la mayoría de los casos.
Y, por supuesto, queríamos que todo fuera flexible, fácil de crear prototipos. Debido a que todo el proyecto comenzó simplemente con una idea que decidieron probar, implementado en un mes, todo comenzó y se convirtió en la decisión principal de nuestra empresa. Por cierto, primero escribimos en Ruby, y luego reescribimos el servidor del dispositivo a Kotlin. Las pruebas resultaron en Ruby y el servidor en Kotlin.
Servidor de dispositivo
Ahora más sobre el servidor del dispositivo en sí, cómo funciona. Cuando comenzamos a investigar este problema, utilizamos las siguientes herramientas:
- xcrun simctl y fbsimctl: utilidades de línea de comandos para administrar simuladores (el primero es oficialmente de Apple, el segundo de Facebook, es un poco más conveniente de usar)
- WebDriverAgent, también de Facebook, para lanzar aplicaciones fuera del proceso cuando llegue la notificación push o algo así
- ideviceinstaller, - .
, device server, . , fbsimctl , xcrun simctl ideviceinstaller, , fbsimctl WebDriverAgent. - . : - , Facebook . , fbsimctl . :

, .

, .
? , curl list, :

JSON, , . , .

, approve — , . open deep links . , , fbsimctl. , :

, . - . : . , , .
- — . liveshot' iPhone X, iPhone 5S, iPhone 6s. .
- - WebDriverAgent XCUI- , .
- . - iOS 8 , , . device server iOS 8, , , - . fbsimctl.
- , cookies , , , .
- — . , device server , , , , . , . , .

, - , . — , . — , , , .

: Test Runner, ; Device Provider, Device Server, ; Remote Device — ; Device Server — -. , - - fbsimctl WebDriverAgent.
? Test Runner capability, iPhone 6. Device Provider, device server, , - , , , . Device Server . RemoteDevice .
, fbsimctl. , , headless-. , , headless-. - , . , , , syslog SpringBoard .
, XCTest, WebDriverAgent, healthCheck, WebDriverAgent , . , «ready» . healthCheck. , .
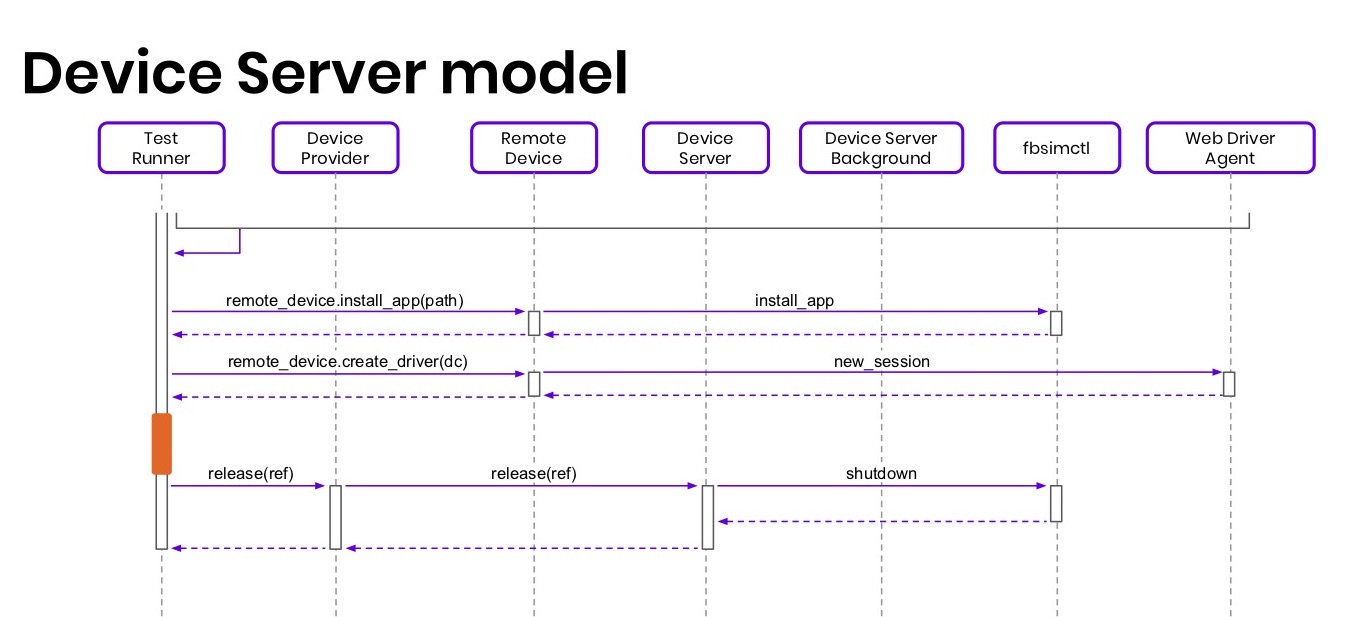
fbsimctl. . , WebDriverAgent, . .
— , device server, , , . (release), , , . . , device server , Test Runner . , -, , - .
— . . 30 60. , . , 30 . : , ?
. — . , .
. , , . Separation of Concerns — , , .
. , , Xcode 9, . Xcode 9.2, , — . , - .
Simplificamos enormemente el Test Runner, que incluía rsync, ssh y otra lógica. Ahora todo esto se descarta y funciona en algún lugar en * nix, en contenedores Docker.Próximos pasos: preparar el servidor del dispositivo para código abierto (después del informe que se alojó en GitHub ) , y estamos pensando en eliminar ssh, porque requiere una configuración adicional en las máquinas y en la mayoría de los casos complica la lógica y el soporte de todo el sistema. Pero ahora puede tomar el servidor del dispositivo, habilitarlo en todas las máquinas ssh, y las pruebas realmente funcionarán en ellos sin problemas.
Consejos y trucos
Ahora lo más importante es todo tipo de trucos y cosas útiles que encontramos al crear un servidor de dispositivos y esta infraestructura.
El primero es el más simple. Como recordarán, teníamos un MacBook Pro, todas las pruebas se ejecutaron en computadoras portátiles. Ahora los lanzamos en Mac Pro.

Aquí hay dos configuraciones. Estas son en realidad las mejores versiones de cada uno de los dispositivos. En el MacBook, podríamos ejecutar de manera estable 6 simuladores en paralelo. Si intenta cargar más al mismo tiempo, los simuladores comienzan a fallar debido al hecho de que cargan mucho el procesador, tienen bloqueos mutuos, etc. Puede ejecutar 18 en Mac Pro: es muy fácil de calcular, porque en lugar de 4 hay 12 núcleos. Multiplicamos por tres: obtienes alrededor de 18 simuladores. De hecho, puede intentar correr un poco más, pero de alguna manera deben estar separados en el tiempo, no puede, por ejemplo, correr en un minuto. Aunque habrá un truco con estos 18 simuladores, no es tan simple.

Y este es su precio. No recuerdo cuánto es en rublos, pero está claro que cuestan mucho. El costo de cada simulador para el MacBook Pro cuesta casi £ 400, y para el Mac Pro casi £ 330. Esto ya representa alrededor de £ 70 de ahorro en cada simulador.
Además, estos macbooks tenían que instalarse de cierta manera, tenían que cargarse en imanes, que tenían que estar pegados a la cinta, porque a veces se caían. Y tuvo que comprar un adaptador para conectar Ethernet, porque tantos dispositivos cercanos en la caja de hierro con Wi-Fi en realidad no funcionan, se vuelve inestable. El adaptador también cuesta alrededor de £ 30, cuando divides entre 6, obtendrás otros £ 5 por cada dispositivo. Pero, si no necesita esta súper paralelización, solo tiene 20 pruebas y 5 simuladores, en realidad es más fácil comprar un MacBook, porque puede encontrarlo en cualquier tienda, y tendrá que pedir y esperar el Mac Pro de gama alta. Por cierto, nos costaron un poco más barato, porque los tomamos a granel y había algún tipo de descuento. También puede comprar una Mac Pro con poca memoria y luego actualizarse, ahorrando aún más.
Pero con Mac Pro hay un truco. Tuvimos que dividirlos en tres máquinas virtuales, poner ESXi allí. Esta es la virtualización básica, es decir, un hipervisor que está instalado en una máquina simple y no en el sistema host. Él mismo es el anfitrión, por lo que podemos ejecutar tres máquinas virtuales. Y si instala algún tipo de virtualización normal en macOS, por ejemplo, Parallels, podrá ejecutar solo 2 máquinas virtuales debido a las restricciones de licencia de Apple. Tuve que romperlo porque CoreSimulator, el servicio principal que administra los simuladores, resultó tener bloqueos internos y, al mismo tiempo, más de 6 simuladores simplemente no estaban cargados, comenzaron a esperar algo en la cola y el tiempo de carga total de 18 simuladores se volvió inaceptable. Por cierto, ESXi cuesta £ 0, siempre es bueno cuando algo no vale nada, pero funciona bien.
¿Por qué no hicimos pooling? En parte porque aceleramos el reinicio del simulador. Suponga que la prueba falla y desea limpiar completamente el simulador para que el siguiente no se bloquee debido a que quedan archivos oscuros en el sistema de archivos. La solución más simple es apagar el simulador, borrar explícitamente (borrar) y arrancar (arrancar).

Muy simple, una línea, pero lleva 18 segundos. Y hace seis meses o un año, tomó casi un minuto. Gracias a Apple por optimizar esto, pero puedes hacerlo más complicado. Descargue el simulador y copie sus directorios de trabajo en la carpeta de respaldo. Y luego apaga el simulador, elimina el directorio de trabajo y copia la copia de seguridad, inicia el simulador.

Resulta 8 segundos: la descarga se aceleró más de dos veces. Al mismo tiempo, no había nada complicado que hacer, es decir, en el código Ruby, toma literalmente dos líneas. En la imagen, doy un ejemplo en un bash para que pueda traducirse fácilmente a otros idiomas.
El siguiente truco. Hay una aplicación Bumble, es similar a Badoo, pero con un concepto ligeramente diferente, mucho más interesante. Allí debe iniciar sesión a través de Facebook. En todas nuestras pruebas, dado que usamos un nuevo usuario del grupo cada vez, tuvimos que cerrar sesión en el anterior. Para hacer esto, usando WebDriverAgent, abrimos Safari, fuimos a Facebook, hicimos clic en Cerrar sesión. Parece ser bueno, pero lleva casi un minuto en cada prueba. Cien pruebas. Cien minutos extra.
Además, a Facebook a veces le gusta hacer pruebas A / B, para que puedan cambiar los localizadores, el texto en los botones. De repente, caerán un montón de pruebas, y todos serán extremadamente infelices. Por lo tanto, a través de fbsimctl creamos list_apps, que encuentra todas las aplicaciones.
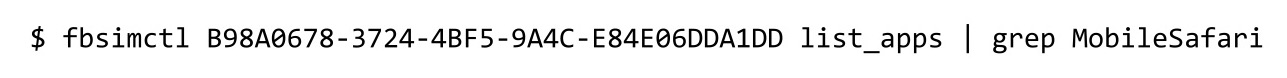
Encuentra MobileSafari:

Y hay una ruta al DataContainer, y tiene un archivo binario con cookies:

Simplemente lo eliminamos, tarda 20 ms. Las pruebas comenzaron a pasar 100 minutos más rápido, se volvieron más estables, porque no pueden caer debido a Facebook. Entonces, la paralelización a veces no es necesaria. Puede encontrar lugares para la optimización, es fácil menos 100 minutos, no es necesario hacer nada. En el código, estas son dos líneas.
A continuación: ¿cómo preparamos las máquinas host para ejecutar simuladores?

Con el primer ejemplo, muchos de los que lanzaron Appium están familiarizados con la desactivación del teclado duro. El simulador tiene la costumbre de conectar el teclado de hardware en la computadora al ingresar texto en el simulador, y ocultar completamente el virtual. Y Appium usa un teclado virtual para ingresar texto. En consecuencia, después de una depuración local de las pruebas de entrada, otras pruebas pueden comenzar a fallar debido a la falta de un teclado. Con este comando puede deshabilitar el teclado duro, y lo hacemos antes de levantar cada nodo de prueba.

El siguiente párrafo es más relevante para nosotros, porque la aplicación está relacionada con la geolocalización. Y muy a menudo necesita ejecutar pruebas para que inicialmente esté deshabilitado. Puede configurar 3101 en LocationMode. ¿Por qué? Solía haber un artículo en la documentación de Apple, pero luego lo eliminaron por alguna razón. Ahora es solo una constante mágica en el código por el que todos rezamos y esperamos que no se rompa. Porque tan pronto como se rompa, todos los usuarios estarán en San Francisco, porque fbsimctl coloca dicha ubicación al cargar. Por otro lado, lo descubriremos fácilmente, porque todos estarán en San Francisco.

Lo siguiente es deshabilitar Chrome, un marco alrededor del simulador que tiene varios botones. Cuando se ejecutan pruebas automáticas, no es necesario. Anteriormente, desactivarlo le permitía colocar más simuladores de izquierda a derecha para ver cómo funciona todo en paralelo. Ahora no hacemos eso, porque todo no tiene cabeza. Cuantos no entran al auto, los simuladores no serán visibles. Si esto es necesario, puede transmitir desde el simulador deseado.

También hay un conjunto de opciones diferentes que puede activar / desactivar. De estos, solo mencionaré SlowMotionAnimation, porque tuve un segundo o tercer día muy interesante en el trabajo. Ejecuté las pruebas, y todas comenzaron a caer en tiempos de espera. No encontraron los elementos en el inspector, aunque él sí. Resultó que en ese momento comencé Chrome, presioné cmd + T para abrir una nueva pestaña. En este punto, el simulador se activó e interceptó al equipo. Y para él, cmd + T es una ralentización de todas las animaciones de 10 veces para depurar la animación. Esta opción también debe desactivarse automáticamente si desea ejecutar pruebas en máquinas a las que las personas tienen acceso, porque pueden interrumpir accidentalmente las pruebas al ralentizar las animaciones.
Probablemente lo más interesante para mí, ya que hice esto no hace mucho tiempo, es la administración de toda esta infraestructura. 60 hosts virtuales (en realidad, 64 + 6 agentes de TeamCity) que nadie quiere implementar manualmente. Encontramos la utilidad
xcversion : ahora es parte de fastlane, una gema de Ruby que se puede usar como una utilidad de línea de comando: automatiza parcialmente la instalación de Xcode. Luego tomamos Ansible, escribimos playbooks, para rodar fbsimctl en todas partes de la versión deseada, Xcode e implementar configuraciones para el servidor del dispositivo. Y Ansible para eliminar y actualizar simuladores. Cuando cambiamos a iOS 11, dejamos iOS 10. Pero cuando el equipo de pruebas dice que abandona por completo las pruebas automáticas en iOS 10, simplemente pasamos por Ansible y limpiamos los viejos simuladores. De lo contrario, ocupan mucho espacio en disco.

Como funciona Si solo toma xcversion y lo llama en cada una de las 60 máquinas, tomará mucho tiempo, ya que va al sitio web de Apple y descarga todas las imágenes. Para actualizar las máquinas que se encuentran en el parque, debe seleccionar una máquina que funcione, ejecutar xcversion install con la versión necesaria de Xcode, pero no instale nada ni elimine nada. El paquete de instalación se descargará en la memoria caché. Lo mismo se puede hacer para cualquier versión del simulador. El paquete de instalación se coloca en ~ / Library / Caches / XcodeInstall. Luego carga todo con Ceph, y si no está allí, inicie algún tipo de servidor web en este directorio. Estoy acostumbrado a Python, así que ejecuto un servidor Python Python en máquinas.

Ahora, en cualquier otra máquina del desarrollador o probador, puede hacer que xcversion instale y especificar el enlace al servidor generado. Descargará xip de la máquina especificada (si la red de área local es rápida, esto sucederá casi instantáneamente), desempaquetará el paquete, confirmará la licencia; en general, hará todo por usted. Habrá un Xcode completamente funcional en el que será posible ejecutar simuladores y pruebas. Desafortunadamente, no lo hicimos convenientemente con simuladores, por lo que debe hacer curl o wget, descargar un paquete de ese servidor a su máquina local en el mismo directorio, ejecutar simuladores de xcversion - instalar. Colocamos estas llamadas dentro de los scripts de Ansible y actualizamos 60 máquinas en un día. El tiempo principal fue ocupado por la copia de archivos de red. Además, nos estábamos moviendo en ese momento, es decir, algunos de los autos estaban apagados. Reiniciamos Ansible dos o tres veces para alcanzar a los autos que estuvieron ausentes durante el traslado.
Un pequeño interrogatorio. En la primera parte: me parece que las prioridades son importantes. Es decir, primero debe tener estabilidad y confiabilidad de las pruebas, y luego velocidad. Si solo busca la velocidad, comience a paralelizar todo, las pruebas funcionarán rápidamente, pero nadie las mirará, simplemente reiniciarán todo hasta que todo pase de repente. O incluso anotar en las pruebas y empujar al maestro.
El siguiente punto: la automatización es el mismo desarrollo, por lo que puede tomar los patrones que ya pensó para nosotros y usarlos. Si ahora su infraestructura está estrechamente relacionada con las pruebas y se planifica el escalado, entonces este es un buen momento para dividir primero y luego escalar.
Y el último punto: si la tarea es acelerar las pruebas, lo primero que viene a la mente es agregar más simuladores para que sea más rápido por algún factor. De hecho, muy a menudo no es necesario agregar, sino analizar cuidadosamente el código y optimizar todo con un par de líneas, como en el ejemplo con las cookies. Esto es mejor que la paralelización, ya que se guardaron 100 minutos con dos líneas de código, y para la paralelización tendrá que escribir mucho código y luego admitir la parte de hierro de la infraestructura. Por dinero y recursos costará mucho más.
Quienes estén interesados en este informe de la conferencia de Heisenbug también pueden estar interesados en el siguiente Heisenbug : se llevará a cabo en Moscú del 6 al 7 de diciembre, y el sitio web de la conferencia ya contiene descripciones de una serie de informes (y, por cierto, la aceptación de solicitudes de informes aún está abierta).