Este informe de Alexey Milovidov, Jefe del equipo de desarrollo de ClickHouse, es una descripción general de los pocos DBMS conocidos. Algunos de ellos están desactualizados, otros han detenido su desarrollo y son abandonados. Alexey llama la atención sobre soluciones arquitectónicas interesantes en los ejemplos enumerados, comprende su destino y explica qué requisitos debe cumplir su proyecto de código abierto.
- Mi informe será sobre bases de datos. Déjame preguntarte de inmediato, ¿qué mapa del metro se muestra en esta diapositiva? Todas las líneas van en un sentido.
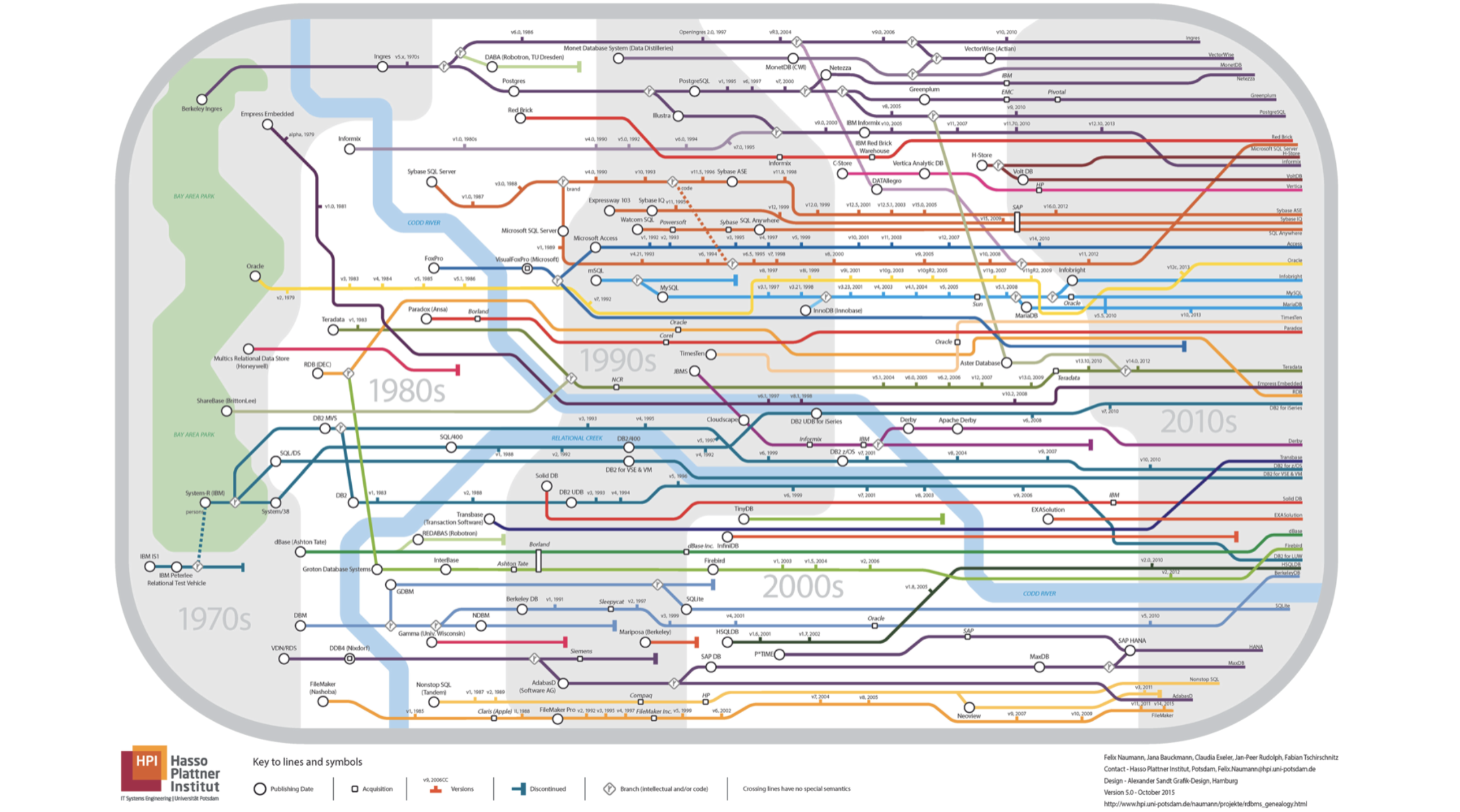
Todo está mal, no es subterráneo en absoluto, es el pedigrí de las bases de datos relacionales. Si miras de cerca, verás que el río es el río
Kodda .
No hablaré de ellos. ¿Qué podría ser más aburrido que hablar de MySQL, PostgreSQL o algo así? En cambio, hablaré sobre la creación de bases de datos.

Montaje manual. Sistemas que son casi desconocidos para cualquiera. Están diseñados por una persona o abandonados hace mucho tiempo.

El primer ejemplo es EventQL. Levanta la mano si alguna vez has oído hablar de este sistema. Ni una sola persona, excepto aquellos que trabajan en Yandex y ya han escuchado mi informe. Entonces, no fue en vano que incluí este sistema en mi revisión.

Este es un motor de base de datos de columnas distribuidas diseñado para el procesamiento de eventos y análisis. Realiza consultas SQL muy rápidas, de código abierto desde el 26 de julio de 2016, escrito en C ++, ZooKeeper se utiliza para la coordinación, no hay dependencias además de él. Me recuerda a algo. Nuestro maravilloso sistema, todos ya conocen el nombre. EventQL es algo así como ClickHouse, pero mejor. Distribuido, masivamente paralelo, orientado a columnas, escalas a petabytes, solicitudes de rango rápido: todo está claro, lo tenemos todo. Soporte casi completo para SQL 2009, inserciones y actualizaciones en tiempo real, distribución automática de datos en el clúster e incluso el lenguaje ChartSQL para describir gráficos. ¡Qué asombroso! Esto es lo que prometemos a todos y lo que no tenemos.
Sin embargo, la última confirmación hace casi un año, hay un sitio que no se carga, tienes que mirar a través de web.archive.org.
Pregunta en GitHub: ¿cuáles son tus planes de desarrollo, qué pasará después? Nadie respondió
El sistema tiene dos desarrolladores. Uno es un desarrollador de backend, el segundo es un frontend. No mostraré cuál de ellos, quizás, adivinará por ti mismo. Hecho por DeepCortex. El nombre parece familiar, pero hay muchas compañías con la palabra Deep y la palabra Cortex. DeepCortex es una compañía desconocida de Berlín. El sistema se ha desarrollado desde 2014, se desarrolló internamente durante mucho tiempo, luego se lanzó en código abierto y se abandonó un año después.

Se parece a esto: la arrojaron al aire y pensaron, de repente alguien se daría cuenta de ella o ella se iría volando a algún lado. Lamentablemente no.
Otra desventaja es la licencia AGPL, que es relativamente inconveniente. Incluso si no presenta restricciones serias para su compañía, a menudo se teme, el departamento legal puede tener algunos puntos en contra.
Comencé a buscar lo que sucedió, por qué no se está desarrollando. Miré la cuenta del desarrollador, en principio todo está bien, la persona vive, continúa comprometiéndose, sin embargo, todas las confirmaciones en el repositorio privado. No está claro lo que sucedió.

O la persona se mudó a otra compañía y perdió interés en el apoyo, o las prioridades de la compañía cambiaron, o algunas circunstancias de la vida. Quizás la compañía en sí no se sintió muy mal, y el código abierto se hizo por si acaso. O simplemente cansado. No sé la respuesta exacta. Si alguien lo sabe, por favor dime.

Pero todo esto no se hizo en vano. En primer lugar, ChartSQL para la descripción declarativa de gráficos. Ahora se usa algo similar en el sistema de visualización de datos Tabix para ClickHouse. EventQL tiene un blog, sin embargo, actualmente no está disponible, debe buscar en web.archive.org, hay archivos .txt. El sistema se implementa de manera muy competente y, si está interesado, puede leer el código y ver soluciones arquitectónicas interesantes.
Eso es todo sobre ella por ahora. Y el próximo sistema gana a todos, lo cual consideraré, porque tiene el mejor y más delicioso nombre. Sistema Alenka.
Quería agregar una foto del empaque de chocolate, pero me temo que habrá problemas de derechos de autor. Que es Alenka

Este es un DBMS analítico que ejecuta consultas en aceleradores gráficos. Openors, licencia Apache 2, 1103 estrellas, escrito en CUDA, un pequeño C ++, un desarrollador de Minsk. Incluso hay un controlador JDBC. Puertas abiertas desde 2012. Sin embargo, desde 2016, el sistema por alguna razón ya no se desarrolla.

Este es un proyecto personal, no propiedad de la empresa, sino realmente un proyecto de una persona. Este es un prototipo de investigación para explorar las posibilidades de cómo procesar rápidamente los datos en la GPU. Hay pruebas interesantes de Mark Litvinchik, si está interesado, puede consultar el blog. Probablemente, muchos ya han visto sus pruebas allí de que ClickHouse es el más rápido.

No tengo respuesta por qué se abandona el sistema, solo adivinanzas. Ahora una persona trabaja para nVidia, probablemente esto sea solo una coincidencia.

Este es un gran ejemplo, porque aumenta el interés, los horizontes, puede ver y comprender cómo puede hacerlo, cómo puede funcionar el sistema en la GPU.
Pero si está interesado en este tema, hay muchas otras opciones. Por ejemplo, el sistema MapD.
¿Quién escuchó sobre MapD? Ofender. Esta es una startup atrevida, que también desarrolla una base de datos de GPU. Lanzado recientemente en código abierto bajo la licencia Apache 2. No sé para qué sirve, bueno o viceversa. Este inicio es tan exitoso que se presenta en código abierto o viceversa, se cerrará pronto.
Hay una PGStorm. Si está versado en PostgreSQL, debería escuchar sobre PGStorm. También de código abierto, desarrollado por una persona. De los sistemas cerrados, están BrytlytDB, Kinetica y la compañía rusa Polymatic, que fabrica el sistema Business Intelligence. Análisis, visualización y todo eso. Y para el procesamiento de datos, también puede usar aceleradores gráficos, puede ser interesante de ver.

¿Es posible hacer algo más genial que una GPU? Por ejemplo, había un sistema que procesaba datos en un FPGA. Esto es Kickfire. Ella entregó su solución en forma de hierro con el software de inmediato. Es cierto que la compañía cerró hace mucho tiempo, esta solución era bastante costosa y no podía competir con otros gabinetes de este tipo cuando algún proveedor le ofrece este gabinete, y todo funciona mágicamente.
Además, hay procesadores que contienen instrucciones para acelerar SQL - SQL en Silicon en los nuevos modelos de procesadores SPARC. Pero no necesita pensar que escribe unirse en Assembler, no está allí. Hay instrucciones simples que hacen la descompresión usando algunos algoritmos simples y un poco de filtrado. En principio, no solo puede acelerar SQL. Por ejemplo, los procesadores Intel tienen un conjunto de instrucciones SSE 4.2 para procesar cadenas. Cuando apareció en algún momento en 2008, el sitio web de Intel tenía un artículo titulado "Uso de nuevas instrucciones del procesador Intel para acelerar el procesamiento XML". Es casi lo mismo aquí. También se pueden usar instrucciones útiles para acelerar una base de datos.
Otra opción muy interesante es transferir la tarea de filtrar datos parcialmente a SSD. Ahora los SSD se han vuelto bastante potentes, esta es una computadora pequeña con un controlador, y básicamente puedes cargar tu código si realmente lo intentas. Sus datos se leerán del SSD, pero se filtrarán de inmediato y transferirán solo los datos necesarios a su programa. Muy bueno, pero todo esto todavía está en la etapa de investigación. Aquí hay un artículo sobre VLDB, leer.
Además, un cierto ViyaDB.

Fue inaugurado hace solo un mes. "Base de datos analítica para datos sin clasificar". Por qué se pone "sin clasificar" en el nombre, no está claro por qué se debe hacer tanto énfasis. ¿Qué, en otras bases de datos solo con ordenadas puedes trabajar?
Todo está bien, el código fuente en GitHub, la licencia Apache 2.0, escrito en el C ++ más moderno, todo está bien. Un desarrollador, pero nada.

Lo que más me gustó, donde puedes tomar un ejemplo, es la excelente preparación del lanzamiento. Por lo tanto, me sorprende que nadie haya escuchado. Hay un sitio maravilloso, hay documentación, hay un artículo sobre Habré, hay un artículo sobre Medium, LinkedIn, Hacker News. ¿Y qué? ¿Es todo esto en vano? No has mirado nada de esto. Aquí dicen, Habr no es un pastel. Bueno, tal vez, pero una gran cosa.
¿Cómo es este sistema?

Datos en RAM, el sistema está trabajando con datos agregados. La preagregación está en curso. Sistema de consultas analíticas. Existe cierto soporte inicial de SQL, pero recién comienza a desarrollarse, inicialmente las consultas tenían que escribirse en algún tipo de JSON. De las características interesantes, usted le hace una solicitud, y ella escribe el código C ++ a su solicitud, este código se genera, compila, carga dinámicamente y procesa sus datos. ¿Cómo se procesaría su solicitud de la manera más óptima posible? Idealmente código C ++ especializado escrito para su solicitud. Hay escala, y el cónsul se utiliza para la coordinación. Esto también es una ventaja, como saben, es más genial que ZooKeeper. O no No estoy seguro, pero parece que sí.
Algunas de las premisas de las cuales procede este sistema son algo contradictorias. Soy un gran entusiasta de las diversas tecnologías y no quiero regañar a nadie. Esta es solo mi opinión, tal vez me equivoque.
La premisa es que para registrar constantemente nuevos datos en el sistema, incluso retroactivamente, hace una hora, hace un día, un evento hace una semana. Y al mismo tiempo, ejecute inmediatamente consultas analíticas sobre estos datos.

El autor afirma que para esto el sistema debe estar necesariamente en memoria. Esto no es asi. Si está interesado en por qué, puede leer el artículo "Evolución de las estructuras de datos en Yandex.Metrica". Una persona en la sala estaba leyendo.
No es necesario almacenar datos en la RAM. No diré qué debe hacerse y qué sistema instalar si está interesado en resolver este problema.

¿Qué bien puedes aprender? Una solución arquitectónica interesante es la generación de código en C ++. Si está interesado en este tema, puede prestar atención a dicho proyecto de investigación DBToaster. EPFL Institute Research, disponible en GitHub, Apache 2.0. Scala code, le da una consulta SQL allí, este código genera fuentes C ++ para usted, que leerá y procesará datos desde algún lugar de la manera más óptima. Probablemente, pero no estoy seguro.

Este es solo un enfoque para la generación de código, para el procesamiento de consultas. Existe un enfoque aún más popular: la generación de código LLVM. La conclusión es que su programa, por así decirlo, escribe código dinámicamente en Assembler. Bueno, no realmente, en LLVM. Hay MemSQL como ejemplo. Originalmente es una base de datos OLTP, pero también es una buena opción para el análisis. Cerrado, patentado, C ++ se utilizó originalmente allí para la generación de código. Luego cambiaron a LLVM. Por qué Escribiste código C ++, tienes que compilarlo, y lleva cinco segundos precioso hacer esto. Y bueno, si sus solicitudes son más o menos iguales, puede generar el código una vez. Pero cuando se trata de análisis, tiene solicitudes ad hoc allí, y es muy posible que cada vez no solo sean diferentes, sino que incluso tengan una estructura diferente. Si la generación del código está en LLVM, lleva milisegundos o decenas de milisegundos, de manera diferente, a veces más.
Otro ejemplo es Impala. También usa LLVM. Pero si hablamos de ClickHouse, también hay generación de código allí, pero principalmente ClickHouse se basa en el procesamiento de solicitudes vectoriales. Un intérprete, pero que funciona en matrices, por lo que funciona muy rápido, como sistemas como kdb +.
Otro ejemplo interesante. El mejor logo en mi reseña.

El primer y único sistema de gestión de bases de datos de código abierto relacional diseñado específicamente para el almacenamiento de datos y la inteligencia empresarial. Disponible en GitHub, la licencia de Apache 2. Solía haber una GPL, pero se cambió y se realizó correctamente. Está escrito en Java. Último compromiso hace seis años. Inicialmente, el sistema fue desarrollado por la organización sin fines de lucro Eigenbase, el objetivo de la organización era desarrollar un marco, la base de código más ampliable para las bases de datos, que no son solo OLTP, sino, por ejemplo, una para análisis, LucidDB y la otra StreamBase para procesar datos de transmisión.

¿Qué pasó hace seis años? Buena arquitectura, base de código bien extensible, más de un desarrollador. Gran documentación Ahora no se está cargando nada, pero puede verlo a través de WebArchive. Gran soporte de SQL.

Pero algo está mal. La idea es buena, pero esto fue hecho por una organización sin fines de lucro para algunas donaciones, y un par de nuevas empresas estaban cerca. Por alguna razón, todo estaba doblado. No pudieron encontrar financiación, no hubo entusiastas y todas estas startups cerraron hace mucho tiempo.
Pero no tan simple. Todo esto no fue en vano.

Existe dicho marco: Apache Calcita. Es una especie de interfaz para bases de datos SQL. Puede analizar consultas, analizar, realizar todo tipo de transformaciones de optimización, elaborar un plan de ejecución de consultas y proporciona un controlador JDBC listo para usar.
Imagine que de repente se despertó, estaba de buen humor y decidió desarrollar su DBMS relacional. Nunca se sabe, sucede. Ahora puede tomar Apache Calcite, solo tiene que agregar almacenamiento de datos, lectura de datos, procesamiento de consultas, replicación, tolerancia a fallas, fragmentación, todo es simple. Apache Calcite se basa en la base de código LucidDB, que era un sistema tan avanzado que tomaron toda la interfaz desde allí, que ahora se usa de forma adaptada en casi todos los productos Apache, Hive, Drill, Samza, Storm e incluso MapD, a pesar de que está escrito en C ++, de alguna manera conectó este código en Java.

Todos estos sistemas interesantes usan Apache Calcita.
El siguiente sistema es InfiniDB. De estos nombres mareados.

Hubo Calpont, originalmente InfiniDB, un sistema patentado, y fue tal que los gerentes de ventas contactaron a nuestra compañía y nos vendieron este sistema. Fue interesante participar en esto. Dicen que un DBMS analítico, maravilloso, más rápido que Hadoop, orientado a columnas, naturalmente, todas las consultas funcionarán rápidamente. Pero luego no tenían un clúster, el sistema no escalaba. Digo que no hay clúster: no podemos comprar. Miro, después de medio año se lanzó la versión de InfiniDB 4.0, agregamos integración con Hadoop, escalado, todo está bien.
Han pasado seis meses y el código fuente está disponible en código abierto. Entonces pensé en lo que estaba sentado, desarrollando algo, debemos tomarlo, hay algo listo.
Comenzaron a ver cómo adaptarse, usar. Un año después, la empresa se declaró en quiebra. Pero el código fuente está disponible.
Esto se llama código abierto post-mortem. Y eso está bien. Si alguna empresa no se siente muy bien, es necesario que al menos quede algo de legado para que otros puedan usarlo.

Todo fue en vano. Basado en la fuente InfiniDB, MariaDB ahora tiene un motor de tabla llamado ColumnStore. De hecho, esto es InfiniDB. La compañía ya no está allí, la gente ahora trabaja en otros lugares, pero el legado permanece, y esto es maravilloso. Todo el mundo sabe sobre MariaDB. Si lo usa y necesita sujetar el motor analítico orientado a columnas rápidamente, puede tomar ColumnStore. En secreto, diré que esta no es la mejor solución. Si necesita la mejor solución, entonces sabe a quién acudir y qué usar.
Otro sistema con la palabra Infini en el nombre. Tienen un logotipo extraño, esta línea parece estar doblada. Y otra fuente incomprensible, por alguna razón no hay antialias, como pintada en Paint. Y todas las letras son grandes, probablemente para intimidar a los competidores.

Soy un entusiasta de todo tipo de tecnologías, muy respetuoso de todo tipo de soluciones interesantes. No estoy bromeando, no hay necesidad de pensar.
¿Cómo era este sistema? Esto ya no es un sistema analítico, es OLTP. Un sistema para procesar transacciones en escalas extremas. Hay un sitio, las ventajas de este sistema es que el sitio se está cargando. Porque cuando miro a todos los demás, estoy acostumbrado al hecho de que habrá estacionamiento de dominio u otra cosa. Las fuentes están disponibles. Ahora la GPL. Solía ser AGPL, pero afortunadamente, el autor lo cambió rápidamente. Escrito en C ++, más de un desarrollador, publicado en código abierto en noviembre de 2013, y ya abandonado en enero de 2014. Un mes y medio. Por qué Cual es el punto? ¿Por qué hacer esto?

Base de datos OLTP con soporte inicial de SQL, un proyecto personal, ninguna compañía lo respalda. El propio autor de Hackers News dice que publicó en código abierto con la esperanza de atraer a los entusiastas que trabajarán en este producto.

Esta esperanza siempre está condenada al fracaso. Tienes una idea, eres genial, eres un entusiasta. Entonces tienes que hacer esta idea. Es poco probable que alguien más se inspire en esto. O tendrá que trabajar duro para inspirar a alguien. Por lo tanto, es difícil esperar que de la nada al otro lado del mundo aparezca una persona que comenzará a agregar el código de otra persona en GitHub.
En segundo lugar, quizás subestimando la complejidad. El desarrollo de DBMS no es una aventura por 20 minutos. Es difícil, largo, costoso.
Este es un caso muy interesante, muchos han escuchado RethinkDB. Este ejemplo no es una base analítica, no OLTP, sino orientada a documentos.

Este sistema ha cambiado su concepto muchas veces. Repensado Digamos, en 2011, se escribió que este es un motor para MySQL, que es cien veces más rápido en SSD, como se escribió en el sitio web oficial. Luego se dijo que este es un sistema con protocolo memcached, también optimizado para SSD. Y después de un tiempo, es una base de datos para aplicaciones en tiempo real. Es decir, para suscribirse a los datos y recibir actualizaciones directamente en tiempo real. Digamos todo tipo de chats interactivos, juegos en línea. Un intento de encontrar un nicho.
Sistema orientado a documentos, modelo de datos JSON. En este sentido, este sistema a menudo se compara con MongoDB. Aunque esto es injusto. ¿Qué piensan los desarrolladores que se comportaron bien sobre MongoDB? MongoDB debe morir. Estas no son mis palabras, no deseo daño a nadie, como dijo Oleg de PostgreSQL Professional.Y en general, ¿qué piensan estos desarrolladores? Mongo: están haciendo todo mal. No pudieron implementar adecuadamente el protocolo de consenso e incluso el sistema no se las arregla muy bien con la tarea de guardar datos. Parece que en nuevas versiones con esto mejor, no fue especialmente anterior.RethinkDB? , RAFT. , , , . JSON, - LINQ . ReQL, ++, , ++.

. . , , , , . , , . 20938 GitHub. - .

, , , , , . Por qué ?

, 2009 , , , . , , 2016 . , , , . , , RethinkDB, , , The Linux Foundation. AGPL Apache 2, . , — .

, , , , , , . , .
, , . , - , , , , .
. , , . , XML 15 .
- , 2000-, . , XML . - - , . , .

, Sedna. XML , . , . , . , Sedna, , , , . , .
2013, , . XML , , .
— .
— , , . garret.ru, , . , . , , , . .

. 2014 — IMCS, PostgreSQL, . PostgreSQL, SQL, , . select, . -, . , , , . , . , , , - . , .
, - ? .

, , ? , — . : , - , . , . .
— . , , . , , .
— . , -. - , — , , , -.
, , , .
— , ? , - .
, , . . , , , .
— - - . -, KPHP.
— . , , , .

, , : , , , ? — . , . , . ? : , .
. , , . , .
. , - , , multimodel DB, , , OLTP, , , , . , ? , , - . - -, , , , . , .
Soporte confiable de la empresa matriz. No hay comentarios No es una licencia restrictiva, por lo que otras compañías no asustan al departamento legal, estas personas tienen miedo de todo. Los beneficios de su sistema deben provenir de razones fundamentales. Digamos que si tiene una base de datos para el procesamiento de XML, de alguna manera esto no es muy bueno. Quizás nadie más necesite almacenar datos en XML. Y si tiene una base de datos orientada a documentos, esa es otra. Todos necesitan guardar documentos, y no importa exactamente qué. Además, el apoyo al desarrollo de la comunidad es muy importante para un buen código abierto. Esto significa no solo que necesita retener solicitudes de extracción. Esto significa que necesita que las personas sientan que usted es, que usted existe, que responde preguntas, que el producto se está desarrollando. Esto es lo que hará un código abierto bueno y en vivo. Eso es todo, gracias.