Hace unos meses, en una de las retrospectivas, decidimos intentar leer juntos.
Nuestro formato:
- Elige un libro.
- Determinamos la parte que debe leerse en una semana. Elige un pequeño volumen.
- El viernes, discutimos lo que leemos.
- Leemos durante el horario no laboral, discutimos durante el horario laboral.
- Después de terminar el libro, elegimos conjuntamente lo siguiente.
Lo que da:
- Motivación para leer y leer.
- Desarrollo de habilidades (incluso para el futuro).
- Alineamiento de mentalidad y terminología en un equipo.
- El crecimiento de la confianza.
- Otra razón para hablar.
Uno de los libros recientes que leemos es
Diseño de aplicaciones intensivas en datos . Sí, ese mismo libro con un cerdo. Y a todos les gustó tanto este libro que decidí revisarlo aquí para que más personas lo lean.
 Mapa en calidad original
Mapa en calidad originalHay una traducción de este libro al ruso del editor Peter. Pero leemos en el original, por lo que no prometo que las traducciones de los términos coincidan. Además, deliberadamente no tradujimos parte de los términos.
La parte inicial del libro está dedicada a los conceptos básicos de los sistemas de procesamiento de datos.
El primer capítulo indica que las propiedades importantes de tales sistemas son la confiabilidad, la escalabilidad y la facilidad de mantenimiento.
El segundo capítulo describe varios modelos de datos. Se describen los DBMS relacionales y orientados a documentos habituales, así como las bases de datos de columnas y gráficos menos conocidos.
Los primeros capítulos están actualizados, establecen el alcance del libro. En muchos lugares a continuación, el autor se refiere a los primeros capítulos. Para ser justos, podemos decir que el libro está lleno de referencias cruzadas.
Lo sorprendente de los primeros capítulos es la cantidad de fuentes (hay una bibliografía después de cada capítulo). Los enlaces a docenas de artículos (tanto blogs como científicos) y libros están escrupulosamente organizados en todos los capítulos. El número de fuentes para algunos capítulos supera los cien.
El tercer capítulo comienza con el código fuente del almacén de valores clave más simple:
Incluso funcionará, muy bueno para escribir, pero, por supuesto, no sin problemas de lectura.
E inmediatamente, se ofrecen opciones para mejorar el rendimiento. Describe los índices hash, SSTable, b-tree y LSM-tree. Todo esto se explica con los dedos, pero se muestra cómo se usa esta o aquella estructura en las bases de datos familiares.
Centrarse en la práctica es otro sello distintivo del libro. La mayoría de los ejemplos y recetas son tan prácticos que me encontré con casi todo lo relevante.
El
cuarto capítulo describe la codificación: desde JSON y XML regulares hasta Protobuf y AVRO. No siempre elegimos el formato conscientemente, generalmente lo impone una u otra tecnología en su conjunto. Pero es genial entender cómo funciona dentro, cuáles son las fortalezas y debilidades del formato.
El autor no utilizó específicamente el término serialización, ya que este término tiene un significado más en las bases de datos.
El contenido de los capítulos es mucho más rico que mi breve presentación. La primera parte también describe las diferencias entre OLTP y OLAP, cómo se organizan la búsqueda de texto completo y la búsqueda en bases de datos de columnas, REST y corredores de mensajes.
La segunda parte del libro habla sobre los sistemas de procesamiento de datos distribuidos. Casi todos los sistemas modernos que están más o menos cargados tienen varias réplicas o subsistemas (microservicios).
Cuando comenzamos a practicar la lectura juntos, simplemente discutimos nuestras notas, lugares interesantes y pensamientos. En algún momento, nos dimos cuenta de que simplemente no teníamos suficientes conversaciones, después de la discusión todo se olvida rápidamente. Luego decidimos fortalecer nuestra práctica y agregamos un mapa mental. La innovación tenía solo este libro. A partir de la segunda parte, comenzamos a mantener un mapa mental para cada capítulo. Por lo tanto, más adelante cada capítulo estará con nuestro mapa mental. Utilizamos coggle.it
El quinto capítulo describe la replicación.
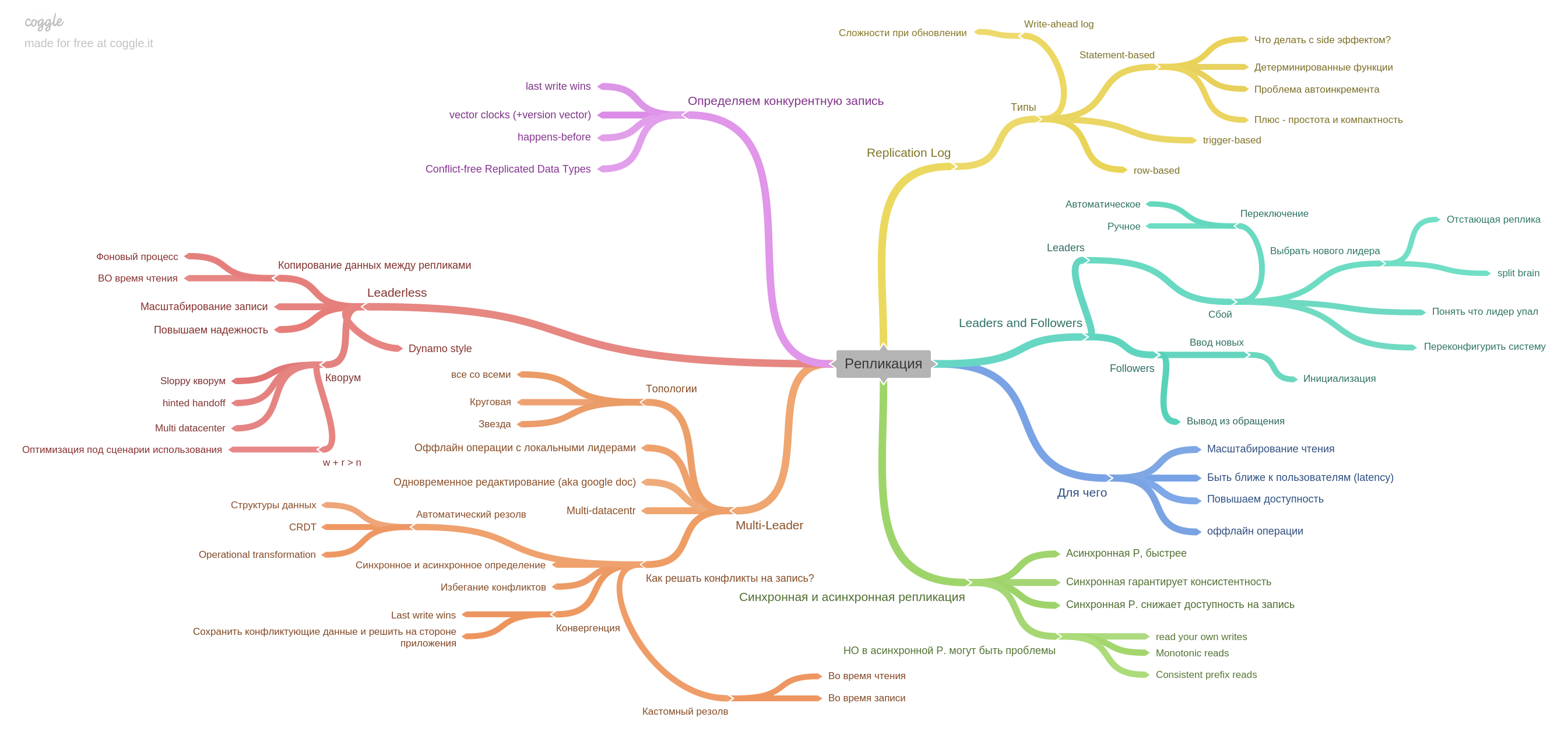
Aquí se recopila toda la información básica sobre las réplicas: registro de replicación de maestro único, multimaestro y cómo vivir con un registro competitivo en sistemas sin líderes.
El sexto capítulo describe el particionamiento (también conocido como fragmentación y muchos otros términos).
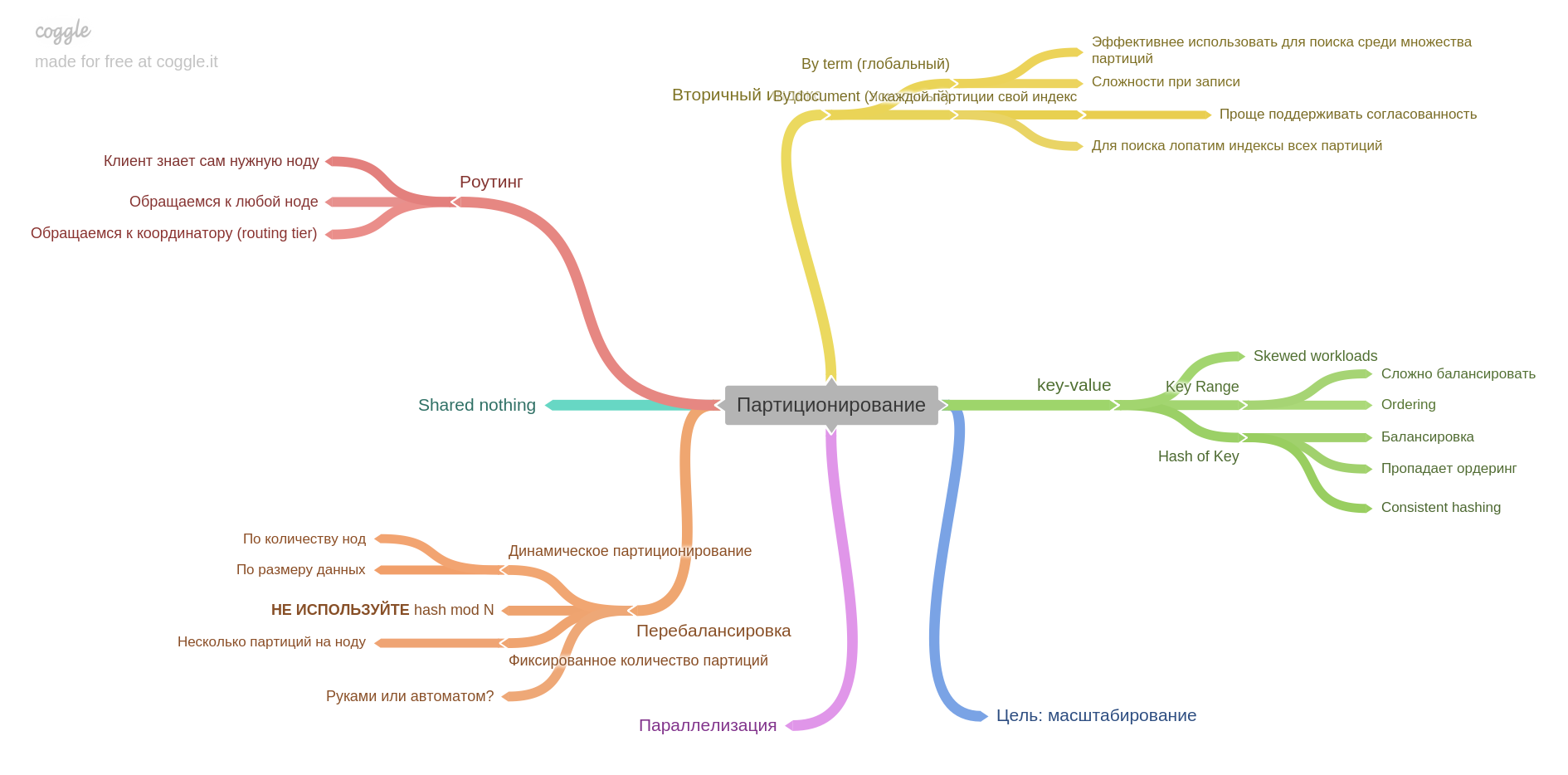
Aprenderá cómo dividir los datos en fragmentos, qué problemas se pueden resolver y cuáles obtener, cómo construir índices y equilibrar datos.
Séptimo capítulo : transacciones.
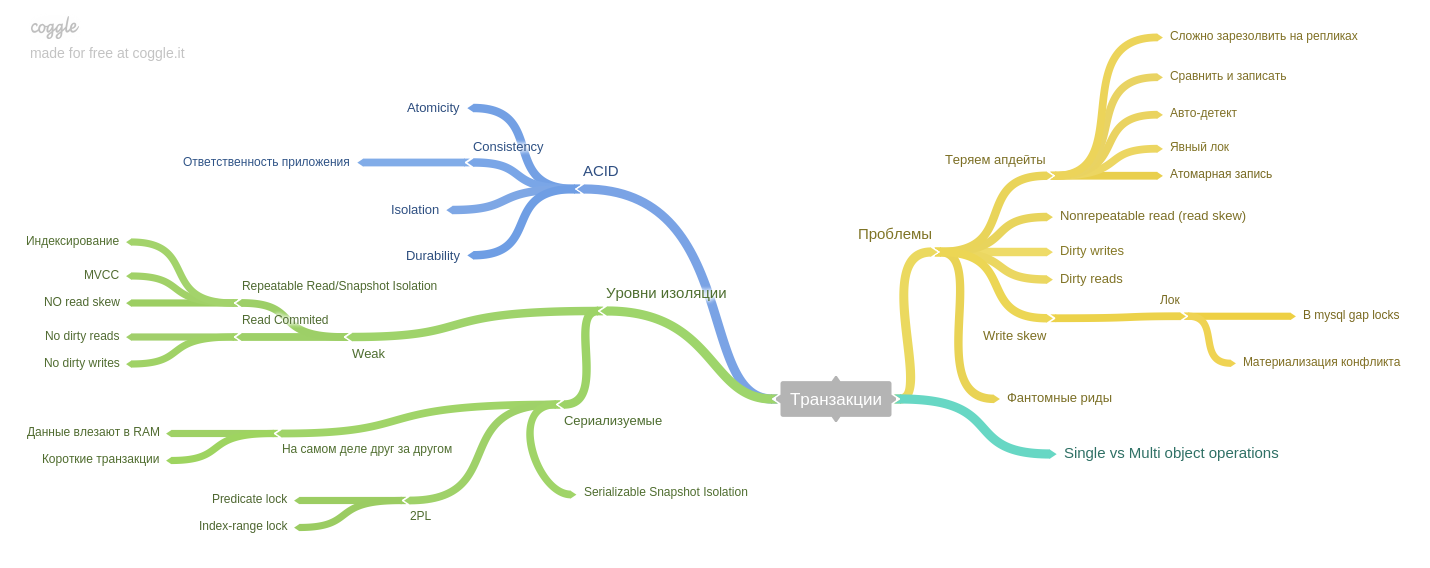
Se describen los fenómenos (lectura asimétrica, escritura asimétrica, lecturas fantasmas, etc.) y cómo los niveles de aislamiento de las bases de datos estilo ACID ayudan a evitar problemas.
El octavo capítulo: sobre problemas específicos de los sistemas distribuidos.
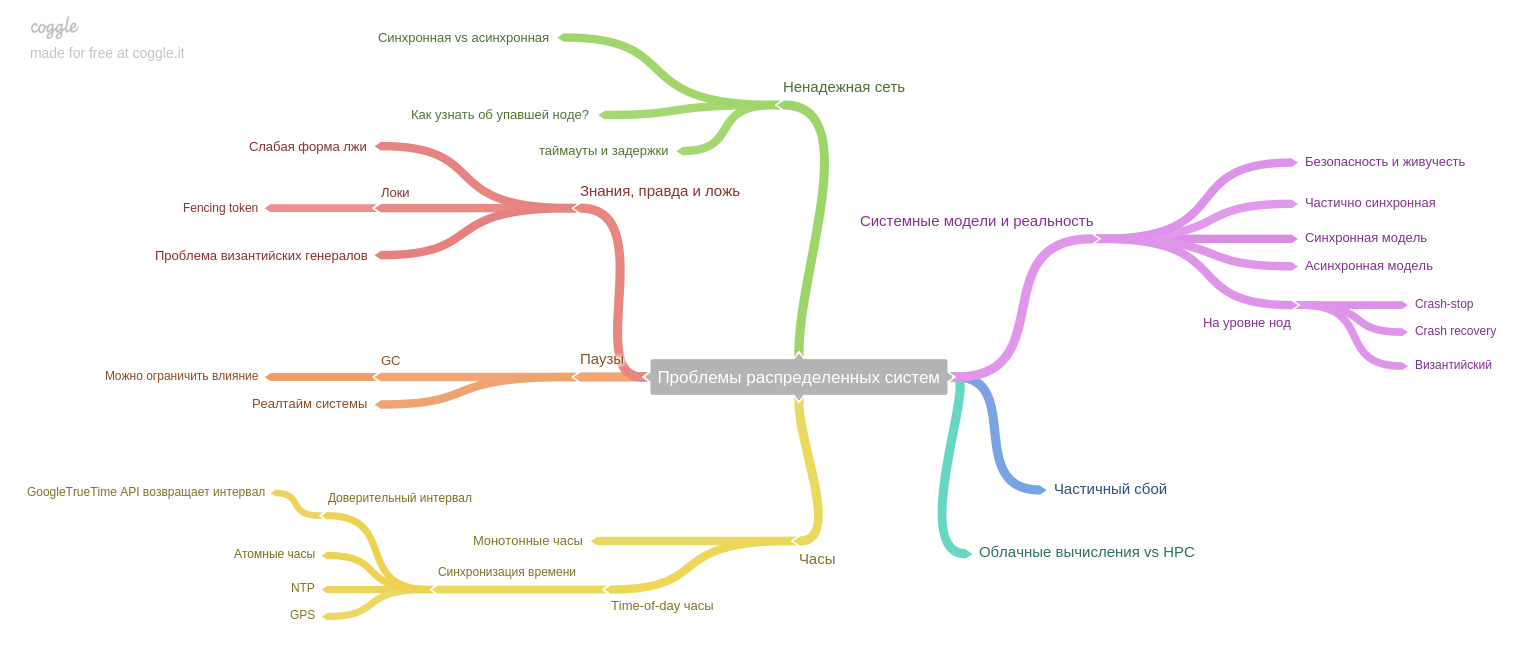
El autor enfatiza una idea importante: si antes el sistema funcionaba en una máquina, y en caso de falla, todo el sistema dejaba de funcionar (y aceptaba cualquier dato nuevo). Por lo tanto, los datos después de las fallas se mantuvieron en un estado constante, pero hoy, en la era de las réplicas y los microservicios, solo una parte del sistema se está cerrando. Por lo tanto, nos enfrentamos a un nuevo problema: garantizar la coherencia de los datos en condiciones de falla parcial, problemas persistentes con una red poco confiable, etc.
El noveno capítulo describe la coherencia y el consenso e introduce un concepto importante: la linealización. Recuerdo que la cabeza entró duro y encajó en mi cabeza)
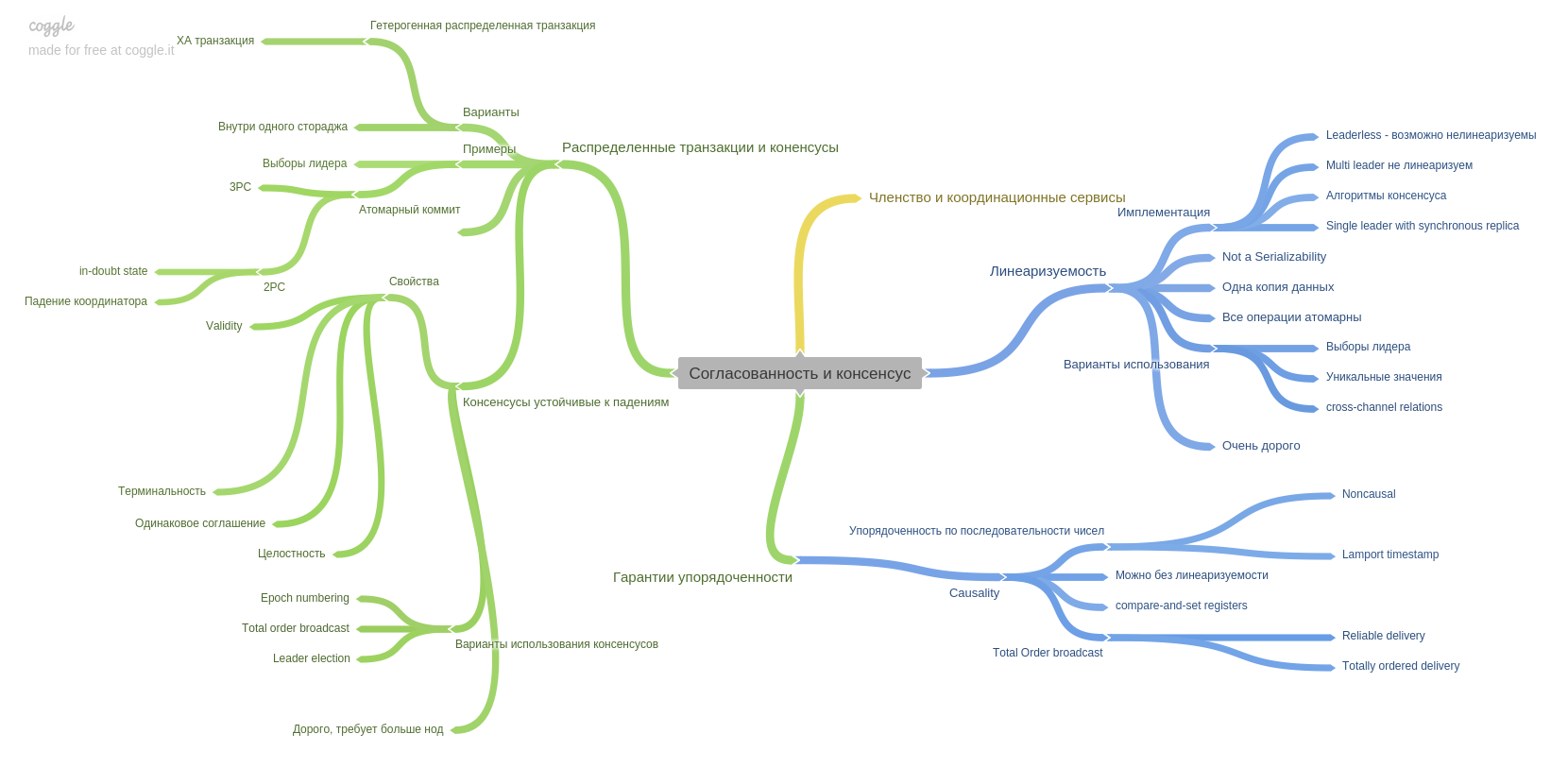
Este capítulo también describe la técnica de confirmación en dos fases y sus puntos débiles. También en este capítulo leerá acerca de las garantías de orden. Cómo y qué sistemas modernos pueden proporcionarle.
La tercera parte del libro está dedicada a los datos derivados (no hay una traducción establecida). Como resultado, el autor expresa la idea de que todos los índices, tablas y vistas materializadas son solo un caché sobre el registro. Solo el registro contiene los datos más relevantes, todo lo demás llega tarde y se utiliza por conveniencia.
El décimo capítulo.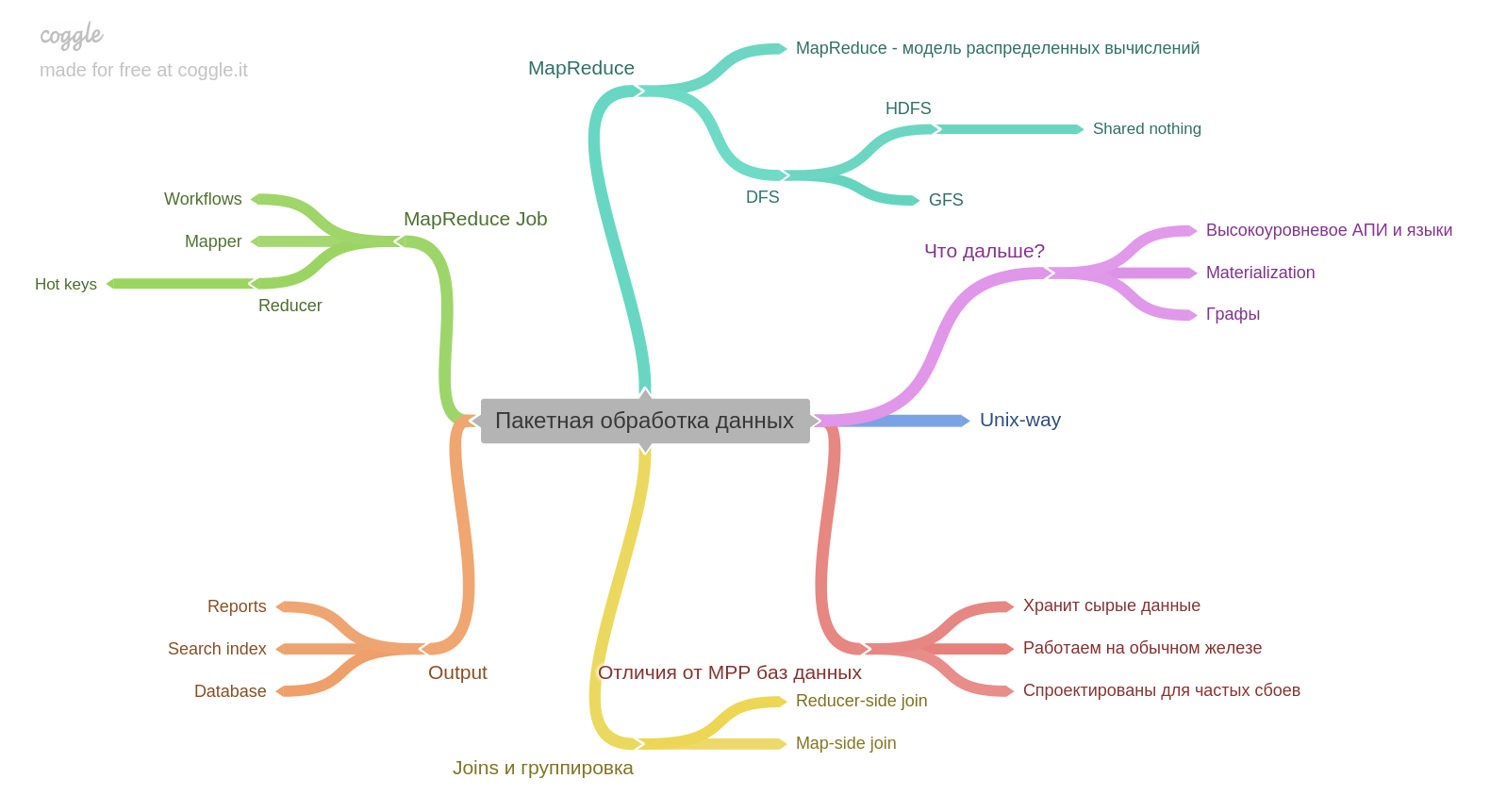
Si tienes experiencia con Hadoop o MapReduce, quizás aprendas algo nuevo. Pero no trabajé y fue muy interesante. Un punto importante para mí: el resultado del procesamiento por lotes en sí mismo puede convertirse en la base de otra base de datos.
Capítulo 11. Proceso de transmisión de datos.
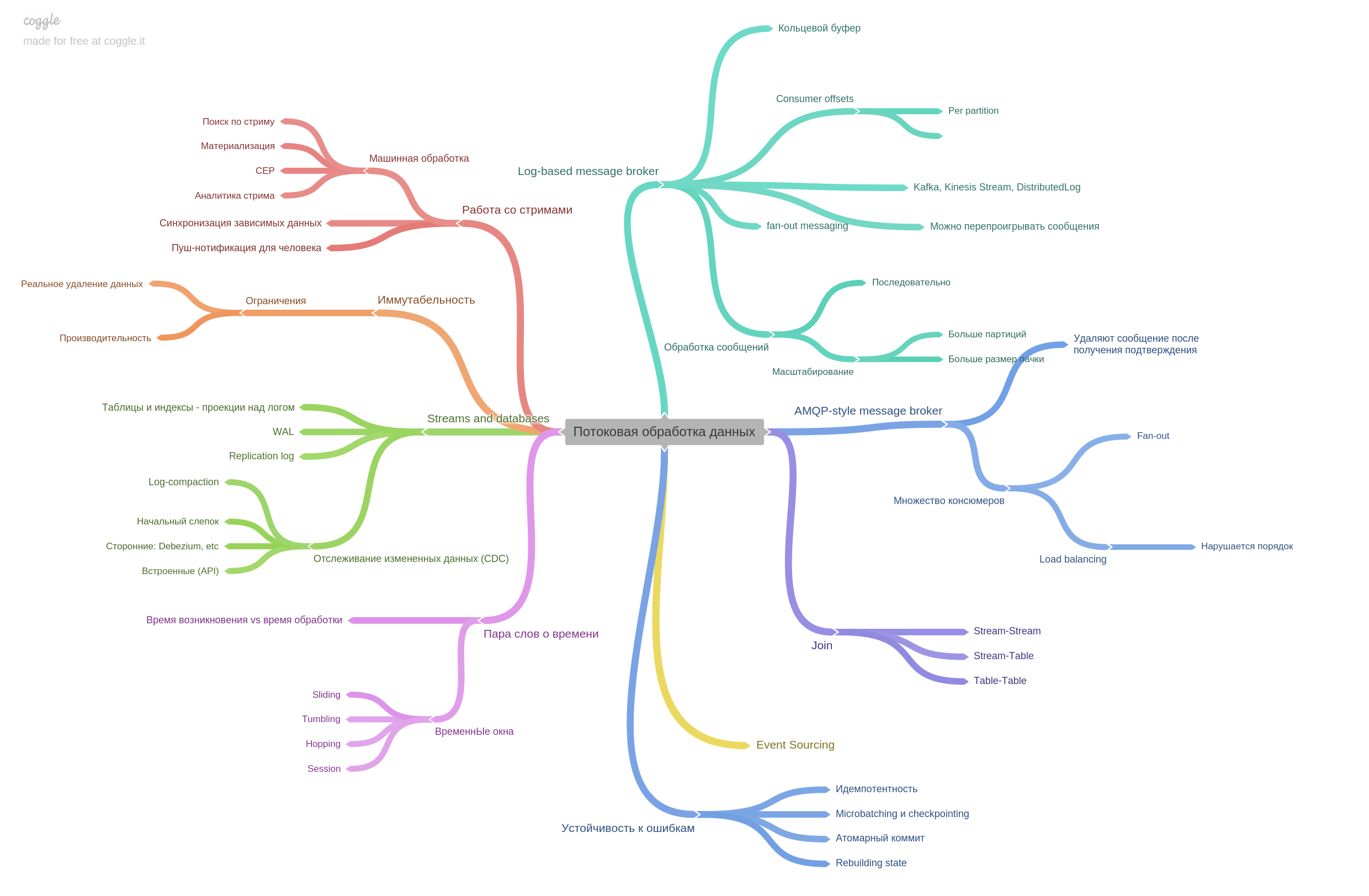
Los intermediarios de mensajes se describen y cómo el estilo AMPQ difiere del basado en registros. De hecho, el capítulo contiene mucha otra información. Fue muy interesante de leer.
El último capítulo es sobre el futuro. Qué esperar, con qué están ocupados los pensamientos de los investigadores e ingenieros.
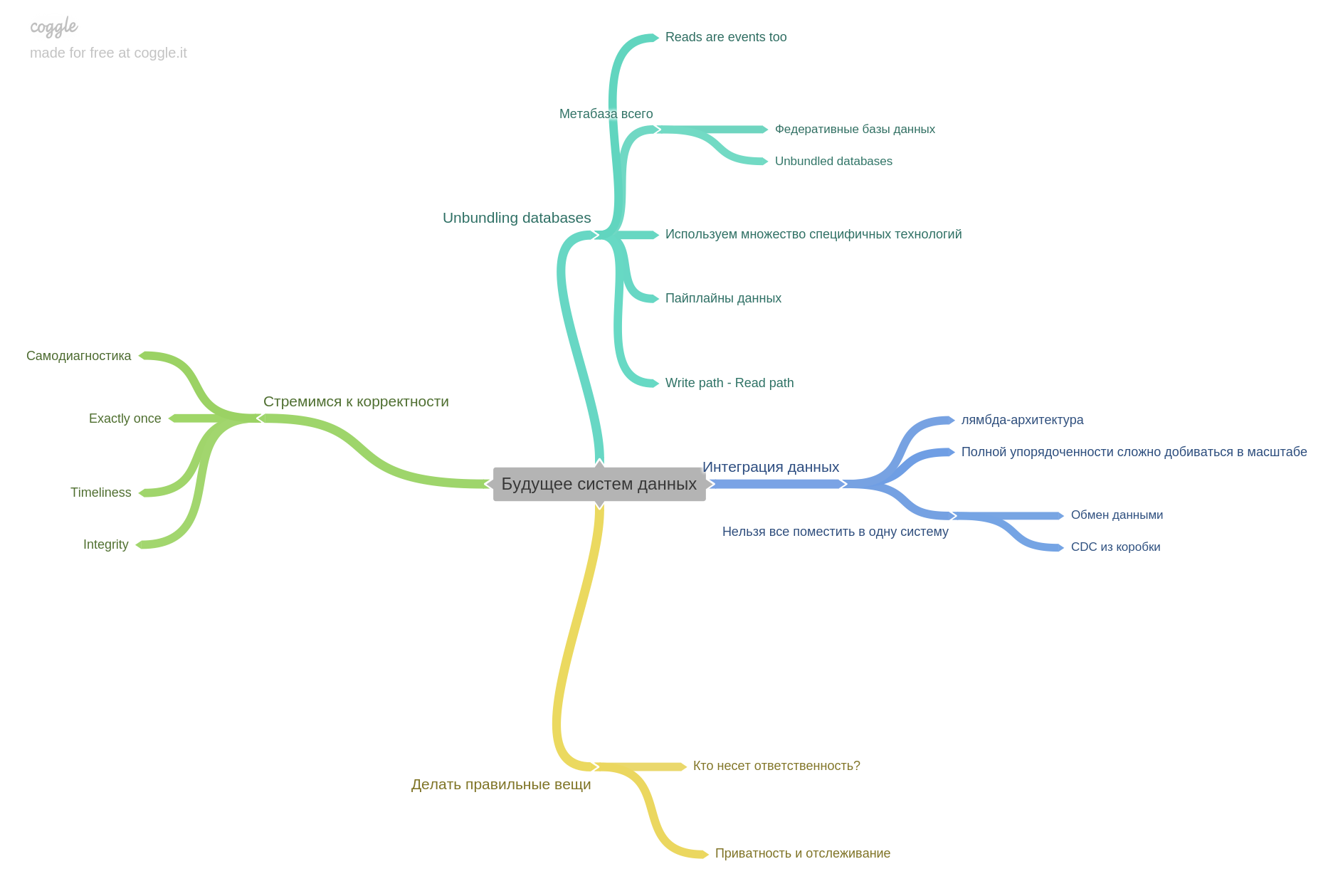
Esto concluye mi revisión. Es importante entender que hice solo una parte de las tesis para cada capítulo. El libro tiene un contenido tan denso que no es posible contarlo brevemente, pero volver a contarlo por completo.
Personalmente, creo que este libro es el mejor técnico de los últimos años. Recomiendo leerlo. Y no solo leer, sino trabajar duro. Siga los enlaces de la bibliografía, juegue con DBMS reales.
Después de leer este libro, puede responder fácilmente muchas preguntas en una entrevista técnica de base de datos. Pero este no es el punto. Como desarrollador, se volverá más genial, conocerá la estructura interna, las fortalezas y debilidades de varias bases de datos y pensará en los problemas de los sistemas distribuidos.
Estoy listo para discutir en los comentarios tanto el libro en sí como nuestra práctica de leer juntos.
¡Lee libros!