Sí, también soy un imbécil. Pero esto no me lo esperaba. Parece que "no es el primer año de casados". Parece estar leyendo un montón de artículos inteligentes sobre tolerancia a fallas, redundancia, etc., algo razonable que incluso una vez escribió aquí mismo. Durante más de 10 años, he sido CEO de un proveedor de alojamiento que opera bajo la marca
ua-hosting.company y brinda servicios de alojamiento y alquiler de servidores en los Países Bajos, EE. UU., Y hace solo una semana en el Reino Unido (no pregunte por qué el nombre ua, la respuesta se puede encontrar
en nuestro artículo autobiográfico ), brindamos a los clientes soluciones de diversos grados de complejidad, a veces de tal manera que incluso a nosotros mismos nos resulta difícil entender lo que hicimos.
Pero maldita sea ... Hoy me superé. Nosotros mismos demolimos completamente el sitio y la facturación, con todas las transacciones, los datos de los clientes sobre los servicios y otras cosas, y fue mi culpa, dije "eliminar" yo mismo. Algunos de ustedes ya lo han notado. Sucedió hoy, viernes a las 11:20 hora estándar del este (EST). Además, nuestro sitio y facturación no estaban alojados en el mismo servidor, y ni siquiera en la nube, dejamos la nube del centro de datos hace 2 meses a favor de nuestra propia solución. Todo esto se ubicó en un geoclúster tolerante a fallas de dos servidores virtuales: nuestro nuevo producto,
VPS (KVM) con unidades dedicadas , VPS
INDEPENDIENTE , que se ubicaron en dos continentes, en Europa y EE. UU. Uno en Amsterdam, y el otro en Manassas, cerca de Washington, por el hecho de que DC en dos centros de datos confiables. Contenido en el que se duplicaba constantemente y en tiempo real, y la tolerancia a fallas se basa en un clúster DNS normal, las solicitudes podrían llegar a cualquiera de los servidores, cualquiera de ellos sirvió como MAESTRO, y en caso de inaccesibilidad, asumió las tareas del segundo.
Pensé que esto solo puede matar un meteorito, bueno, o algo similar al global, que puede desactivar dos centros de datos al mismo tiempo. Pero todo resultó ser más simple.
Podemos ser nosotros mismos, nosotros, si somos idiotas. En el mundo solo hay dos cosas ilimitadas: el Universo y la estupidez humana, y si la primera es controvertida, la segunda se ha vuelto obvia.
Siempre me he adherido al principio de la redundancia de sonido, no soy una de esas personas que gritarán "pierdo $ 1000 por una hora de inactividad", pero al mismo tiempo pago $ 15 por toda mi infraestructura. No, ciertamente no pierdo tanto. Aunque, quizás, a veces pierdo. La mayoría de los idiotas que gritan sobre esto ni siquiera piensan que a veces el tiempo de inactividad por segundo puede costar $ 1,000, $ 10,000 o incluso un millón de dólares en ganancias a largo plazo. Como? Es muy simple, en este momento puede venir un cliente que hará su primer pedido, y en el futuro le traerá estos millones de dólares, porque siempre tiene la oportunidad de demostrarle su singularidad y obtener su recomendación. Y si ve el error 504 o "Lo siento, pero el servidor no está disponible actualmente", es posible que la transacción no tenga lugar. Esto nos sucedió, no, no un error 504 durante la llamada de un visitante importante, sino el primero. Por pura casualidad, me encontré en el lugar correcto en el momento adecuado, cuando grandes clientes, como Dmitry Sukhanov, el creador de Kinopoisk, visitaron nuestro sitio, aunque este no es un muy buen ejemplo, porque trabajó con nosotros solo 2 años, hasta Yandex no lo compró por $ 60 millones o cuánto hay allí. Entonces, fue Dmitry en lugar de nosotros quien consiguió los millones aquí, pero nos alegramos de cooperar con un proyecto tan interesante y útil, y esto, a su vez, nos hizo un anuncio y proporcionó muchos clientes nuevos y satisfechos.
En general, ¿por qué soy todo esto? Las pérdidas y la redundancia necesaria deben evaluarse con sensatez. Aunque existe el riesgo de perder más de un millón de dólares, debe tener en cuenta la probabilidad de tal evento. Lo más probable es que si Dmitry viera el error 504 1 vez, no hubiera pasado nada crítico, y volvió a nosotros nuevamente. Por qué En ese momento, probablemente éramos uno de los pocos que podían ofrecer conectividad de 1+ Gb / s en Ucrania con alta calidad y latencia mínima a bajo costo, lo que era extremadamente importante para sus recursos en ese momento, a fin de garantizar un acceso de alta calidad para la audiencia ucraniana. portal, ya que el tráfico extranjero era de baja calidad y aún caro. Por lo tanto, es importante garantizar la singularidad de la solución, entonces el tiempo de actividad no será muy crítico para usted. Y como somos únicos, podemos permitirnos (incluso ahora), tener miles de clientes de servidor, estar inactivos durante varias horas o incluso más. No necesitamos nubes tolerantes a mega fallas que proporcionen un tiempo de actividad del 99.9999% por mucho dinero, porque incluso caen, y si caen, la práctica los ha demostrado durante mucho tiempo, ya que el problema que causó la inaccesibilidad probablemente no sea común. Y no ayudarán en caso de vulnerabilidad. No ayudarán.
Así que construimos nuestra decisión por nosotros mismos es muy simple. Tomamos dos VPS (KVM) en los nodos Dell R730xd, el mismo VPS (KVM) que ofrecemos a nuestros clientes, porque este es nuestro principio inicial: dar a las personas lo que usamos nosotros mismos:
VPS (KVM) - 2 x Intel Dodeca-Core Xeon E5-2650 v4 (24 núcleos) / 40GB / 4x240GB SSD RAID10 / Datatraffic - 40TB - desde $ 99 / mes, y puede
obtener un descuento del 30% en el primer pago si encuentra una promoción código en nuestro
artículo publicitario .
Uno en los Países Bajos y otro en los Estados Unidos. Sí, en estos nodos, además de nuestro sitio y facturación, hay 2 clientes reales más, cada uno de los cuales puede influir en el funcionamiento de nuestro sitio en teoría y no puede hacerlo en la práctica. Por qué: está escrito en un artículo publicitario, no voy a entrar en detalles aquí por segunda vez. Ahora esto no se trata de eso. En general, la solución no es peor que los servidores de nivel de entrada dedicados y puede manejar una carga muy grande.
Entre otras cosas, es tolerante a fallas, los datos se replican constantemente en tiempo real. Y si un servidor no está disponible, el segundo tomará el rol de MAESTRO. Idealmente, puede hacerlo para que el tráfico del continente americano sea procesado por el servidor estadounidense, y desde Europa, Rusia y Asia, el servidor en los Países Bajos.
Vinculamos los servidores a nuestra cuenta en nuestro WHMCS de facturación, un producto con licencia pública, pero adaptado para nosotros, que es utilizado por muchos proveedores de hosting en todo el mundo, incluidos nosotros, ya que escribir nuestro propio sistema de contabilidad es una debilidad franca (en nuestro caso) . Especialmente en los casos en que la función deseada se implementa escribiendo su propio módulo en la facturación existente, lo que aumenta su tolerancia a fallas, ya que reduce el riesgo de vulnerabilidades críticas. Después de todo, solo o incluso con un equipo pequeño, no podrá escribir un sistema más confiable que el existente, que fue escrito a lo largo de los años por un grupo de desarrolladores, donde miles de errores ya han sido eliminados y que ahora los desarrolladores solicitan tan solo $ 30 / mes por una licencia y reciben millones de dólares al año. que puede gastarse incluso en mejoras adicionales.
Hablando de vulnerabilidades críticas, nuestro programador recientemente cometió un error al escribir uno de los módulos de servicio, que tenía acceso a una base de datos de facturación de solo lectura, que fue descubierta por un pentester independiente y nos pidió que paguemos $ 550 por un error encontrado, ya que era una vulnerabilidad de SQL -inyección:
La inyección SQL se encuentra entre los 10 mejores OWASP, le escribí sobre la cantidad de $ 550, esta es la cantidad mínima, ya que la base de datos sufre, lo que compromete los datos del usuario.
Pero algunas cantidades ascienden a $ 10,000 como recompensa, como es el caso de vk.com.
Por supuesto, apoyamos este comienzo y pagamos una compensación sin dudas. Dado que nuestro programador examinó los datos proporcionados y confirmó la existencia de un problema, la justificación del pentester. Después de todo, todavía no mantenemos nuestro propio pentester en el estado, y este trabajo requiere un considerable conocimiento y tiempo, ya que incluye una serie de estudios:
Auditoría de seguridad de todo el recurso, y esta es una verificación de acuerdo con los siguientes parámetros, y nuestro informe al final de la auditoría incluye:
• Inyección de código A1
• A2 Autenticación incorrecta y gestión de sesión
• secuencias de comandos A3 Crossite
• Infracción de acceso A4
• Configuración insegura A5
• Pérdida de datos confidenciales A6
• A7 Protección de ataque insuficiente
• Falsificación de solicitud entre sitios A8
• A9 Uso de componentes con vulnerabilidades conocidas
• A10 Registro y monitoreo inadecuados.
Porque sí, la decisión se tomó de manera inequívoca y rápida. Además, como señaló Pentester, tales estudios aumentan la seguridad de la web en su conjunto:
Este es mi pasatiempo, si todos los desarrolladores como tú tuvieran un diálogo con los cazadores de errores, Internet sería un 80% seguro.
Por lo tanto, en general, pagamos bastante, especialmente si dividimos la cantidad por la cantidad de meses que el empleado responsable de las pruebas de penetración no se mantuvo en el personal. Muchas gracias al Pentester por el error encontrado y el hecho de que se tomó el tiempo para nosotros, estamos realmente agradecidos con él. Si alguien necesita sus servicios, comuníquese con nosotros, le proporcionaremos contactos con su permiso.
Pero esta vez no fue la vulnerabilidad lo que nos mató. Fuimos nosotros y la característica del producto WHMCS. En cada nota, hemos instalado un conveniente producto de administración de contenedores virtuales, VM Manager, que WHMCS tiene acceso para crear, pausar y eliminar, así como clientes, para administrar el contenedor virtual creado.
Todos los días en WHMCS recibimos docenas o incluso cientos de pedidos que deben ser aceptados (aceptados), eliminados o marcados como Fraude si el cliente está tratando de pagar un pedido con una tarjeta de crédito robada. A veces hay un auge de tales órdenes y no podemos determinar de inmediato qué estado asignarle, ya que llevamos a cabo nuestra verificación interna o exigimos que el usuario se identifique correctamente si encontramos que su orden es sospechosa, y dichos usuarios, por supuesto, no siempre responden o aprueban identificación exitosa. Por lo tanto, de vez en cuando se acumulan mil o dos pedidos no activados u pedidos con un estado desconocido, que son más fáciles de eliminar que de procesar. ¿Quién realmente necesita reordenar?
Hace dos meses, decidimos abandonar por completo el producto del centro de datos basado en la nube, ya que comenzamos a proporcionar nuestra propia solución con VM Manager, que le permite poner el sistema en un solo clic o incluso desde su imagen:

E incluso lo ofrecieron en SSD PCIe NVMe, que son un orden de magnitud más rápido que los SSD normales para lectura y hasta 3 veces para escribir, la solución, como la nube, necesita actualizarse, los servidores cuestan desde $ 15 e incluyen un conveniente panel de control de VM Manager y ISP Manager 5 a pedido de forma gratuita, actualización de soporte con un paso mínimo de 5 GB de RAM DDR4, SSD PCIe NVMe de 60 GB y E5-2650 v4 de 3 núcleos
a un plan de tarifas más altas en Amsterdam, Manassas y Londres:
VPS (KVM) - E5-2650 v4 (3 núcleos) / 5GB DDR4 / 60GB NVMe SSD / 1Gbps 5TB - $ 15 / mes
VPS (KVM) - E5-2650 v4 (6 núcleos) / 10GB DDR4 / 120GB NVMe SSD / 1Gbps 10TB - $ 30 / mes
VPS (KVM) - E5-2650 v4 (9 núcleos) / 15GB DDR4 / 180GB NVMe SSD / 1Gbps 15TB - $ 45 / mes
...
VPS (KVM) - E5-2650 v4 (24 núcleos) / 40GB DDR4 / 480GB NVMe SSD / 1Gbps 40TB - $ 120 / mes
...
VPS (KVM) - E5-2650 v4 (24 núcleos) / 65GB DDR4 / 780GB NVMe SSD / 1Gbps 65TB - $ 195 / mes
VPS (KVM) - E5-2650 v4 (24 núcleos) / 70GB DDR4 / 840GB NVMe SSD / 1Gbps 70TB - $ 210 / mes
VPS (KVM) - E5-2650 v4 (24 núcleos) / 75GB DDR4 / 900GB NVMe SSD / 1Gbps 75TB - $ 225 / mes
Por lo tanto, no tiene sentido alquilar una gran parte de la nube del centro de datos y ofrecer a los clientes los antiguos procesadores E3-1230, aunque desde $ 3.99 por mes para nosotros se ha agotado. Creemos que los clientes deben recibir la más alta calidad y el máximo rendimiento, al precio más bajo, sí, no podemos ofrecer el producto por $ 3.99 y tal vez no cubramos las necesidades de algunos desarrolladores que necesitan recursos mínimos y cualquier rendimiento, pero el costo del nodo supera 7,000 euros y no podemos permitirnos, al menos por ahora, colocar más de 15 clientes en él, ya que estamos listos para garantizar la calidad. Y la calidad implica no solo estabilidad, sino también la máxima relación rendimiento / precio, y luego rentabilidad.
Para celebrar, cancelamos toda la infraestructura de la nube (que son miles de VPS), ordenamos 2 servidores virtuales independientes para nosotros (sí, nos pagamos por nuestros servidores), implementamos un sitio y facturamos hace 2 meses en una nueva solución, ya que describimos todo arriba, se incorporó al grupo de protección, para que el sistema no se detenga solo, si de repente se olvidó de pagar a tiempo ... Parece que ha hecho todo.
Y hoy, después de 2 meses, decidimos "Cancelar" (no eliminar, ese botón también está allí, pero tratamos de nunca eliminar nada, para que siempre haya un historial) Más de 1000 pedidos pendientes que aún no tienen asignado un estado en la facturación de WHMCS . Adivinado? Si, eso es. Me preguntaron: ¿puedo cancelar? Confirmé "eliminar".
A veces, a pesar de la gran cantidad de recursos, dado que el muestreo de datos es grande y algunos procesos no se ajustan al límite de tiempo asignado, WHMCS da un error 504, todo está hecho y la facturación continúa funcionando, pero aquí no tenemos disponibilidad. La facturación y el sitio ya no están disponibles. No entendimos de inmediato la razón. Pero luego se dieron cuenta. El pedido de nuestros 2 VPS no fue aceptado (sí, ¡no aceptamos nuestro pedido!) Y, como resultado, fue "cancelado" por el sistema, lo que condujo al lanzamiento del módulo y la eliminación de dos contenedores a la vez, supuestamente no creados, pero creados por los virtuales, utilizando nuestro amado VM Manager. Habiendo ingresado a uno de los nodos, como se esperaba, nuestros administradores vieron la imagen "Adiós":
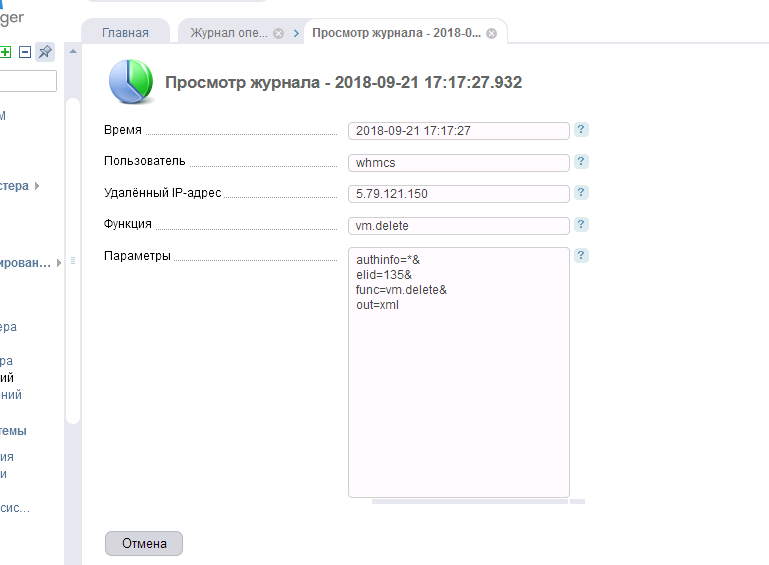
Qué es esto: una falla en los desarrolladores de WHMCS, que lleva a la eliminación de pedidos no aceptados, y en realidad creados con su ID de VPS, cuando se cancelan, o nuestra estupidez (del departamento de ventas) ya no es importante. El resultado fue uno: “Adiós al sitio con facturación. El panel simplemente los borró. Y los administradores solo tenían una pregunta para nosotros (ventas):
Naher crea un servicio con su sitio principal y facturación.
Y luego también matarla al infierno.
Y aunque teníamos copias de seguridad, también en dos regiones distribuidas geográficamente, me sentí incómodo. Como no estaba seguro acerca de la frescura de las copias de seguridad, no estaba seguro de que nuestros administradores hicieran todo bien, como se prescribió originalmente en ellos. la tarea de que la base de datos en realidad se respaldaba cada hora o con más frecuencia, y los datos se actualizaban y se almacenaban varias versiones anteriores de archivos. Las copias de seguridad de algún error de software no dejaron de realizarse (después de todo, personalmente no lo controlé, ¿por qué debería estar seguro de que nuestros administradores estarán preocupados por nuestros datos si califico este control?). Un montón de pensamientos negativos ... ¡No dejes que el universo sobreviva a esto!
Ya tenía la idea de que al menos 1 hora, o incluso peor, no habría transacciones, y tendría que restaurar los pagos de los clientes manualmente, comparar datos sobre transacciones anteriores y escribir a los titulares de cuentas que habíamos recreado la cuenta y pagada por ella. , para mostrarnos desde el lado equivocado, para enviar una notificación de que somos tontos e hicimos un mal funcionamiento del software ... Y si no hay una copia de seguridad nueva, esto generalmente es una tubería, tendría que ser muy largo y triste para restaurar todo ...
Para este caso, tenemos una tabla interna donde muchos datos principales se duplican manualmente y que nosotros actualizamos, lo que elimina una falla del software y la reescritura de datos incorrectos. A pesar de la disponibilidad de copias de seguridad, todavía utilizamos este método. Después de todo, nadie cancela la posibilidad de un zvezdets global.
Afortunadamente, todo resultó no ser tan malo, e incluso eso. un especialista que tuvo que resolver un problema y que al principio anunció:
La noche fue un éxito, gracias a todos.
Fui a recogerlo.
Sin embargo, la noche fue un éxito. Como inicialmente la solución preveía el uso de lvm y aún no se había creado un nuevo contenedor virtual, fue posible restaurar los datos reales, aunque con un baile con una pandereta:
Todo a través de la utilidad lvm, usando sus comandos, restauró el grupo de volumen virtual, luego el virtual, luego activó la partición, la montó en la carpeta izquierda, creó el servidor y colocó los datos allí. Era posible de otras maneras, pero esta opción en nuestro caso fue la más rápida + específica de la configuración del servidor virtual, que tiene su propia incursión.
¿Qué conclusiones se hacen? La redundancia y la redundancia deben incluir la contabilidad de vulnerabilidades y el escenario de desarrollo más tonto cuando todo, incluso las copias de seguridad, pueden destruirse. No sufrimos ni sufrimos grandes pérdidas solo por el hecho de que los datos no se eliminaron por completo. Si es necesario restaurar desde copias de seguridad, habrá una pérdida de transacciones por hora y una pérdida significativa de tiempo de trabajo. Nos pareció que la probabilidad de que las copias de seguridad sean útiles cuando se usa un geocluster es mínima: nos equivocamos. No tomamos en cuenta que es posible eliminar ambos servidores a la vez y que no eliminaremos los servidores, sino nosotros.
Siempre es necesario tener un almacenamiento externo independiente de su sistema, con acceso, preferiblemente solo por algún código, que también está reservado, para garantizar que los datos no se perderán. Por el momento, a pesar de la presencia de copias de seguridad en nuestra infraestructura en dos regiones, considero seriamente la posibilidad de usar algo como Amazon Glacier, aunque esta última es muy costosa. Según los administradores, todo está bien solo en términos de marketing, pero cuando comienzas a usarlo, te enfrentas al hecho de que la solución es bastante costosa, porque tienes que pagar por cada solicitud y cada archivo que se considera muy interesante como su aplicación aws-cli, especialmente si Los datos deben ser restaurados. Recientemente, un cliente de Gran Bretaña solicitó establecer una reserva allí, después de unos meses de uso, se negó, resultó ser muy costoso. Pero aún así, necesitamos determinar qué es más caro. — . — , , . , .
, — , , , . , , , , , .
PS , ( , EST ). , , . , - . , , . , — , . . !
.
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
, 30% VPS , ,
.
Dell R730xd 2 veces más barato? Solo tenemos
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV desde $ 249 en los Países Bajos y los EE. UU. Lea sobre
Cómo construir un edificio de infraestructura. clase utilizando servidores Dell R730xd E5-2650 v4 que cuestan 9,000 euros por un centavo?