Hace un par de años, completé un proyecto de migración en la red de uno de nuestros clientes, la tarea era cambiar la plataforma, que distribuye la carga entre los servidores. El plan de servicio al cliente ha evolucionado durante casi 10 años junto con los nuevos desarrollos en la industria del centro de datos, por lo que el cliente "exigente", en el buen sentido de la palabra, esperaba una solución que satisficiera no solo los requisitos de tolerancia a fallas de equipos de red, equilibradores de carga y servidores , pero también poseería propiedades tales como escalabilidad, flexibilidad, movilidad y simplicidad. En este artículo trataré de presentar, de manera simple y compleja, los principales ejemplos del uso de equilibradores de carga sin referencia al fabricante, sus características y métodos de emparejamiento con la red de entrega de datos.
Los equilibradores de carga ahora se denominan cada vez más Controladores de entrega de aplicaciones (ADC). Pero si las aplicaciones se ejecutan en el servidor, ¿por qué deberían entregarse en algún lugar? Por razones de tolerancia a fallas o escalado, la aplicación se puede ejecutar en más de un servidor, en este caso necesita un tipo de servidor proxy inverso que oculte la complejidad interna de los consumidores, seleccione el servidor deseado, le entregue una solicitud y se asegure de que el servidor devuelva el correcto , desde el punto de vista del protocolo, el resultado, de lo contrario, seleccionará otro servidor y enviará una solicitud allí. Para implementar estas funciones, el ADC debe comprender la semántica del protocolo de capa de aplicación con el que funciona; esto le permite configurar reglas específicas de aplicación para la entrega de tráfico, el análisis del resultado y la verificación del estado del servidor. Por ejemplo, una comprensión de la semántica de HTTP hace posible la configuración cuando HTTP solicita
GET /docs/index.html HTTP/1.1 Host: www.company.com Accept-Language: en-us Accept-Encoding: gzip, deflate
se envían a un grupo de servidores con la posterior compresión de los resultados y el almacenamiento en caché, y las solicitudes
POST /api/object-put HTTP/1.1 HOST: b2b.company.com X-Auth: 76GDjgtgdfsugs893Hhdjfpsj Content-Type: application/json
procesado de acuerdo con reglas completamente diferentes.
Comprender la semántica del protocolo le permite organizar la sesión al nivel de los objetos del protocolo de la aplicación, por ejemplo, usando encabezados HTTP, cookie RDP o solicitudes multiplex para llenar una sesión de transporte con muchas solicitudes de usuario si el nivel de aplicación del protocolo lo permite.
El alcance de la aplicación de ADC a veces se imagina irrazonablemente solo sirviendo el tráfico HTTP, de hecho, la lista de protocolos compatibles para la mayoría de los fabricantes es mucho más amplia. Incluso trabajando sin comprender la semántica del protocolo de la capa de aplicación, ADC puede ser útil para resolver varias tareas, por ejemplo, participé en la construcción de una granja virtual autosuficiente de servidores SMTP, durante los ataques de spam, el número de instancias aumenta usando el control de retroalimentación a lo largo de la cola de mensajes para proporcionar un tiempo satisfactorio para verificar mensajes con algoritmos de uso intensivo de recursos. Durante la activación, el servidor se registró con ADC y recibió su parte de las nuevas sesiones TCP. En el caso de SMTP, dicho esquema de operación estaba justificado debido a la alta entropía de las conexiones en la red y los niveles de transporte; para una distribución uniforme de la carga durante los ataques de spam ADC, solo se requiere soporte TCP. Se puede usar un esquema similar para construir una granja de servidores de bases de datos, DNS, DHCP, AAA o grupos de servidores de acceso remoto altamente cargados cuando los servidores pueden considerarse equivalentes en el dominio y cuando sus características de rendimiento no difieren demasiado entre sí. No profundizaré en el tema de las características del protocolo, este aspecto es demasiado extenso para indicarlo en la introducción, si algo parece interesante, escriba, tal vez sea una ocasión para un artículo con una presentación más profunda de alguna aplicación, y ahora vamos al grano.
Muy a menudo, ADC cierra la capa de transporte, por lo que la sesión TCP de extremo a extremo entre el consumidor y el servidor se vuelve compuesta, el consumidor establece una sesión con ADC y ADC con uno de los servidores.
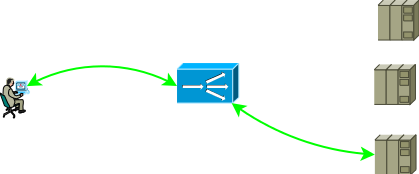 Fig. 1
Fig. 1La configuración de red y la configuración de direccionamiento deben proporcionar tal avance de tráfico para que dos partes de la sesión TCP pasen por el ADC. La opción más fácil para hacer que el tráfico de la primera parte llegue al ADC es asignar una dirección de servicio a una de las direcciones de la interfaz ADC, con la segunda parte son posibles las siguientes opciones:
- ADC como la puerta de enlace predeterminada para la red del servidor;
- Transmitir a direcciones de consumidores ADC en una de sus direcciones de interfaz.
De hecho, una vista un poco más realista del primer esquema de aplicación se ve así, esta es la base a partir de la cual comenzaremos:
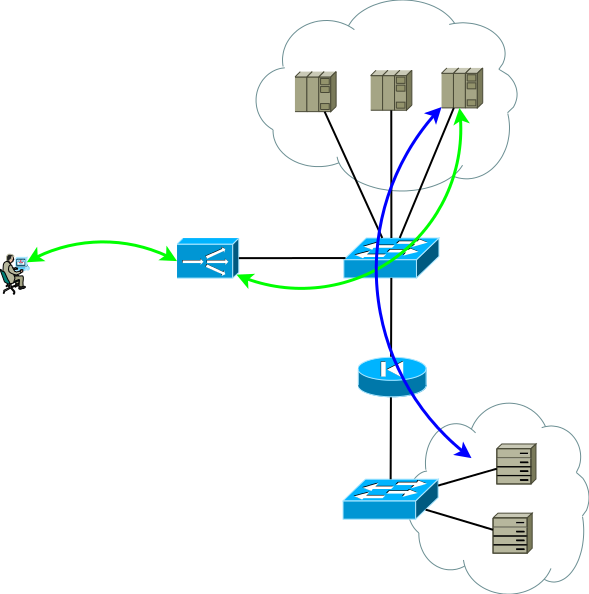 Fig.2
Fig.2El segundo grupo de servidores puede ser bases de datos, back-end de aplicaciones, almacenamiento en red o front-end para otro conjunto de servicios en el caso de descomposición de una aplicación clásica en microservicios. Este grupo de servidores puede ser un dominio de enrutamiento separado, con sus propias políticas, ubicado en otro centro de datos, o incluso puede estar aislado por razones de seguridad. Los servidores rara vez se ubican en un segmento; más a menudo se colocan en segmentos para su propósito previsto con políticas de acceso claramente reguladas, la figura muestra esto como un firewall.
Los estudios muestran que las aplicaciones modernas de varios niveles generan más tráfico de oeste a este, y es poco probable que desee que todo el tráfico intracódigo / entre segmentos pase a través del ADC. Los conmutadores de la Figura 2 no son necesariamente físicos: los dominios de enrutamiento se pueden implementar utilizando entidades virtuales, que se denominan enrutador virtual, vrf, vr, instancia vpn o una tabla de enrutamiento virtual para diferentes fabricantes.
Por cierto, existe una variante de emparejamiento con la red, sin requerir simetría de los flujos de tráfico del consumidor al ADC y del ADC a los servidores, es muy demandado en casos de sesiones de larga duración, en las que se transmite una gran cantidad de tráfico en una dirección, por ejemplo, transmisión o transmitir contenido de video. En este caso, el ADC solo ve el flujo del cliente a los servidores, este flujo se entrega a la dirección de la interfaz del ADC y después de un procesamiento simple, que consiste en reemplazar la dirección MAC con la interfaz MAC de uno de los servidores, la solicitud se envía al servidor donde la dirección de servicio se asigna a una de las interfaces lógicas. El tráfico inverso del servidor al consumidor pasa por alto el ADC de acuerdo con la tabla de enrutamiento del servidor. Admitir un solo dominio de difusión para todos los front-end puede ser muy difícil, además, la capacidad de ADC para analizar respuestas y admitir la capacidad de sesión en este caso es muy limitada, de hecho, es solo un cambio, por lo que esta opción no se considera más, aunque algunas limitaciones Se pueden utilizar tareas.
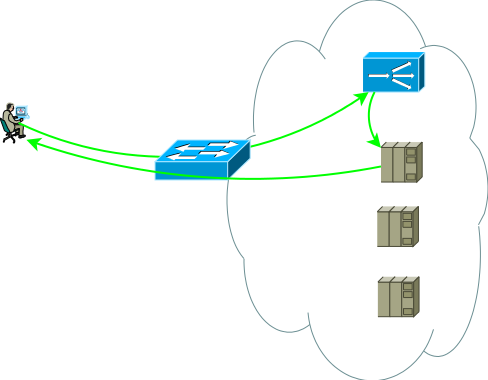 Fig.3
Fig.3Entonces, tenemos un centro de datos básicos, que se muestra en la Figura 2, pensemos en qué problemas pueden llevar el centro de datos básicos a la evolución, veo dos temas para el análisis:
- Supongamos que el subsistema de conmutación está completamente reservado, no pensemos cómo ni por qué, el tema es demasiado extenso. Las aplicaciones se ejecutan en varios servidores y se respaldan con ADC, pero ¿cómo reservo el propio ADC?
- Si el análisis muestra que la próxima carga máxima estacional puede exceder las capacidades de ADC, usted, por supuesto, piensa en la escalabilidad.
Estas tareas son similares en que, en el proceso de resolverlas, la cantidad de instancias de ADC seguramente aumentará. Al mismo tiempo, la tolerancia a fallos se puede organizar de acuerdo con el esquema Activo / Respaldo y Activo / Activo, y el escalado solo se puede realizar de acuerdo con el esquema Activo / Activo. Tratemos de resolverlos individualmente y veamos qué propiedades tienen las diferentes soluciones.
Los ADC de muchos fabricantes se pueden considerar como elementos de una infraestructura de red, RIP, OSPF, BGP: todo esto está ahí, lo que significa que puede construir un esquema trivial de respaldo activo / de respaldo. El ADC activo pasa los prefijos de servicio al enrutador ascendente y recibe la ruta predeterminada para completar su tabla y transferirla al centro de datos a la tabla de enrutamiento virtual correspondiente. El ADC de respaldo hace lo mismo, pero, utilizando la semántica del protocolo de enrutamiento seleccionado, genera anuncios menos atractivos. Con este enfoque, los servidores pueden ver la dirección IP real del consumidor, ya que no hay razón para usar la traducción de direcciones. Este esquema también funciona correctamente si hay más de un enrutador ascendente, pero para evitar una situación en la que el ADC activo pierde el valor predeterminado y la conectividad con el enrutador, mientras sigue recibiendo el valor predeterminado del ADC de respaldo y continúa anunciando hacia el centro de datos, trate de evitar la proximidad entre ADC y el uso de rutas estáticas.
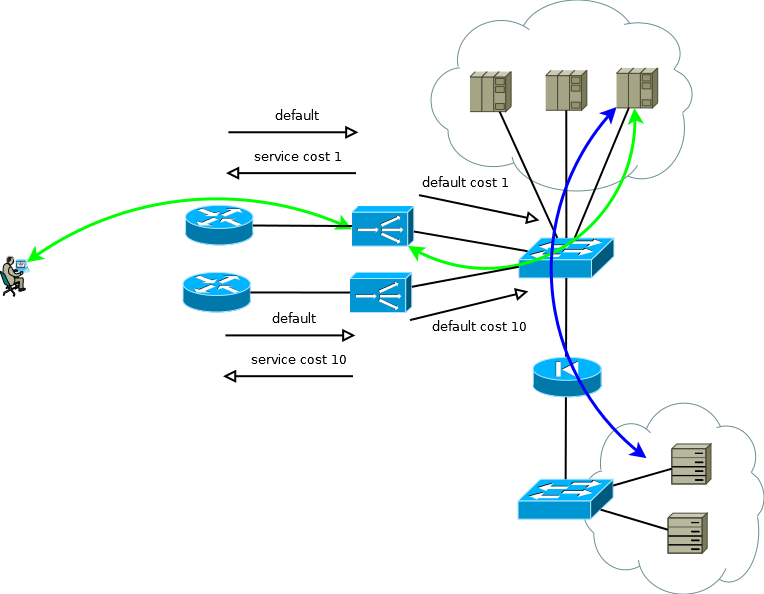 Fig. 4
Fig. 4Si los servidores no necesitan operar con direcciones IP de consumo reales, o el protocolo de la capa de aplicación le permite incrustarlo en encabezados, como HTTP, el esquema se convierte en Activo / Activo con una dependencia casi lineal del rendimiento en la cantidad de ADC. En el caso de más de un enrutador ascendente, debe asegurarse de que el tráfico entrante venga en porciones más o menos uniformes. Esta tarea se puede resolver fácilmente si en el dominio de enrutamiento ECMP la transferencia comienza a estos enrutadores, si es difícil o si el dominio de enrutamiento no es atendido por usted, puede usar conexiones de malla completa entre ADX y los enrutadores para que la transferencia ECMP comience directamente a ellos.
 Fig.5
Fig.5Al comienzo de esta parte, escribí que la tolerancia a fallas y la escala son dos grandes diferencias. Las soluciones a estos problemas tienen diferentes niveles de utilización de recursos, si está diseñando un esquema Activo / En espera, debe soportar el hecho de que la mitad de los recursos estarán inactivos. Y si sucede que necesita dar el siguiente paso cuantitativo, prepárese para multiplicar los recursos requeridos por dos más en el futuro.
Los beneficios de Active / Active comienzan a aparecer cuando opera con más de dos dispositivos. Suponga que necesita garantizar el rendimiento de 8 unidades arbitrarias (8 mil conexiones por segundo u 8 millones de sesiones simultáneas) y proporcionar un solo escenario de falla del dispositivo, en la versión Active / Active solo necesita tres instancias ADC con una capacidad de 4, en el caso de Active / Standby: dos por 8. Si traduce estos números en recursos que están inactivos, obtendrá un tercio a la mitad. Se puede usar el mismo principio de cálculo para estimar la proporción de conexiones rotas durante un período de falla parcial. Con el aumento en el número de instancias Activo / Activo, las matemáticas se vuelven aún más agradables, y el sistema obtiene la capacidad de aumentar gradualmente la productividad en lugar de Active / Standby paso a paso.
Será correcto mencionar otra forma de esquemas de trabajo Activo / Activo o Activo / En espera: agrupamiento. Pero no será muy correcto dedicar mucho tiempo a esto, ya que intenté escribir sobre enfoques y no sobre las características de los fabricantes. Al elegir esta solución, debe comprender claramente las siguientes cosas:
- La arquitectura de clúster a veces impone restricciones sobre esta o aquella funcionalidad, en algunos proyectos esto es fundamental, en algunos puede volverse importante en el futuro, todo depende del fabricante y cada solución debe ser resuelta individualmente;
- El clúster es a menudo un dominio de falla; habrá errores en el software.
- El clúster es fácil de montar, pero muy difícil de desmontar. La tecnología tiene menos movilidad: no puede controlar partes del sistema.
- Caes en el abrazo tenaz de tu fabricante.
Sin embargo, hay cosas positivas:
- El clúster es fácil de instalar y fácil de operar.
- A veces puede esperar una utilización de recursos casi óptima.
Por lo tanto, nuestro centro de datos de la Figura 5 continúa creciendo, la tarea que debe resolver es aumentar la cantidad de servidores. No siempre es posible hacer esto en un centro de datos existente, así que supongamos que aparece una nueva ubicación espaciosa con servidores adicionales.
 Fig.6
Fig.6Un nuevo sitio puede no estar muy lejos, entonces resolverá el problema con éxito renovando los dominios de enrutamiento. Un caso más general, que no excluye la apariencia del sitio en otra ciudad o en otro país, planteará nuevos desafíos para el centro de datos:
- Utilización de canales entre sitios;
- La diferencia en el tiempo de procesamiento de las solicitudes que ADC envió para su procesamiento a servidores cercanos y distantes.
Mantener un amplio canal entre sitios puede ser una tarea muy costosa, y elegir una ubicación ya no será una tarea trivial: un sitio sobrecargado con un tiempo de respuesta corto o gratuito con uno grande. Pensar en esto lo empujará a construir una configuración de centro de datos distribuida geográficamente. Esta configuración, por un lado, es amigable para los consumidores, ya que le permite recibir el servicio en un punto cercano a usted, por otro lado, puede reducir significativamente los requisitos para la banda del canal entre sitios.
Para el caso cuando las direcciones IP reales no tienen que ser accesibles para los servidores, o cuando el protocolo de la capa de aplicación permite que se transmitan en los encabezados, el dispositivo de un centro de datos distribuido geográficamente no es muy diferente de lo que llamé el centro de datos base. ADC en cualquier sitio puede enviar solicitudes de procesamiento a servidores locales o enviarlas para su procesamiento a uno vecino, la transmisión de la dirección del consumidor lo hace posible. Se debe prestar cierta atención al monitoreo del volumen de tráfico entrante para mantener la cantidad de ADC dentro del sitio adecuada a la proporción de tráfico que recibe el sitio. La traducción de la dirección del consumidor le permite aumentar / disminuir el número de ADC o incluso mover instancias entre sitios de acuerdo con los cambios en la matriz de tráfico entrante, o durante la migración / lanzamiento. A pesar de su simplicidad, el esquema es bastante flexible, tiene características de operación agradables y se replica fácilmente en más de dos sitios.
 Fig. 7
Fig. 7Si trabaja con un protocolo que permite reenviar solicitudes, como en el caso de HTTP Redirect, esta característica se puede usar como una palanca adicional para controlar la carga del canal entre sitios, como un mecanismo para realizar el mantenimiento de rutina en los servidores o como un método para construir granjas de servidores Active / Backup en diferentes sitios. En el momento requerido, automáticamente o después de algunos eventos desencadenantes, ADC puede eliminar el tráfico de los servidores locales y trasladar a los consumidores a un sitio vecino. Vale la pena prestar mucha atención al desarrollo de este algoritmo para que el trabajo coordinado de ADC excluya la posibilidad de reenvío mutuo de solicitudes o resonancia.
De particular interés es el caso cuando los servidores necesitan direcciones IP de consumidor reales, y el protocolo de la capa de aplicación no tiene la capacidad de transmitir encabezados adicionales, o cuando los ADC funcionan sin comprender la semántica del protocolo de la capa de aplicación. En este caso, no es posible proporcionar una conexión consistente entre segmentos de sesión TCP simplemente declarando una ruta en el valor predeterminado de ADC. Si hace esto, los servidores del primer sitio comenzarán a usar el ADC local como la puerta de enlace predeterminada para las sesiones que provienen del segundo sitio, la sesión TCP no se establecerá en este caso porque el ADC del primer sitio verá solo un hombro de la sesión.
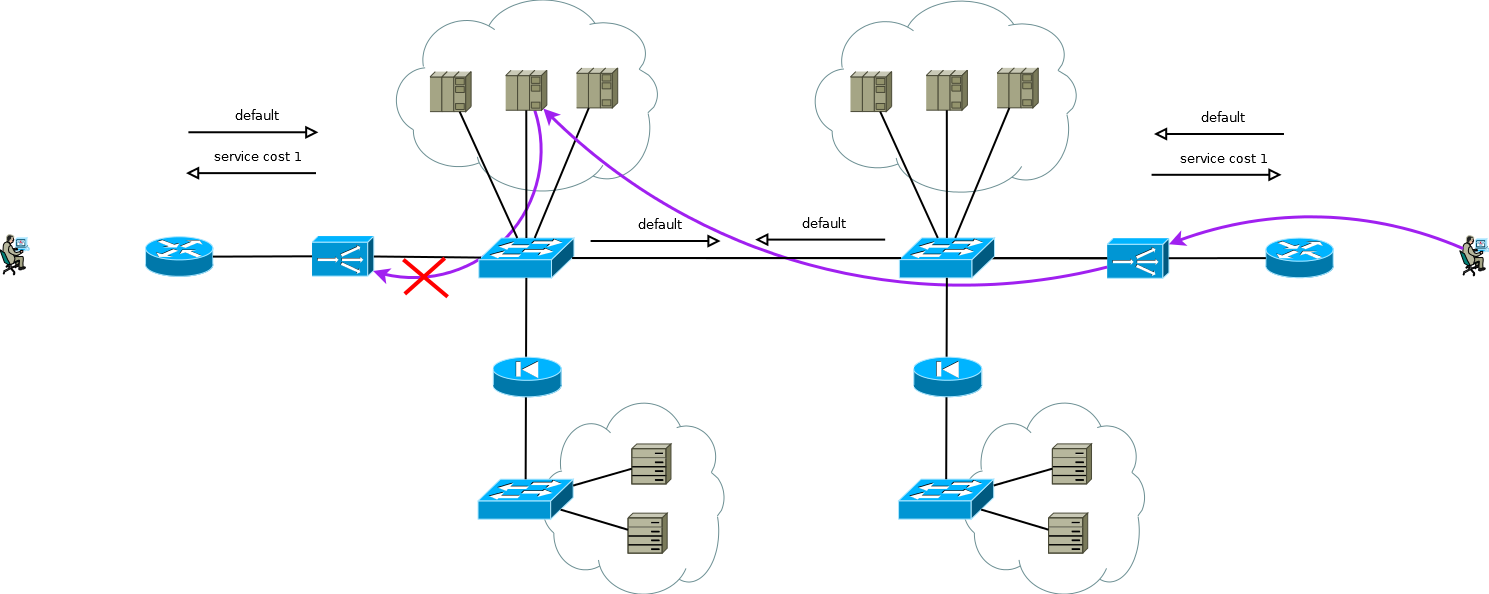 Fig. 8
Fig. 8Hay un pequeño truco que aún le permite ejecutar Active / Active ADC en combinación con granjas de servidores Active / Active en diferentes sitios (no considero el caso de Active / Backup en dos sitios, una lectura cuidadosa de lo anterior le permitirá resolver este problema sin más discusión). El truco es usar en el ADC del segundo sitio, no las direcciones de la interfaz del servidor, sino la dirección lógica del ADC, que corresponde a la granja de servidores en el primer sitio. Al mismo tiempo, los servidores reciben tráfico como si viniera del ADC local y usan la puerta de enlace predeterminada local. Para mantener este modo de operación en el ADC, debe activar la función de memoria de la interfaz de la que proviene el primer paquete para configurar la sesión TCP. Diferentes fabricantes llaman a esta función de manera diferente, pero la esencia es la misma: recuerde la interfaz en la tabla de estado de la sesión y úsela para el tráfico de respuesta sin prestar atención a la tabla de enrutamiento. El esquema es completamente funcional y le permite distribuir de manera flexible la carga en todos los servidores disponibles donde sea que se encuentren. En el caso de dos o más sitios, la falla de un ADC no afecta la disponibilidad del servicio en su conjunto, pero excluye completamente la posibilidad de procesar el tráfico en los servidores del sitio con ADC fallidos, esto debe recordarse al predecir el comportamiento y la carga durante fallas parciales.
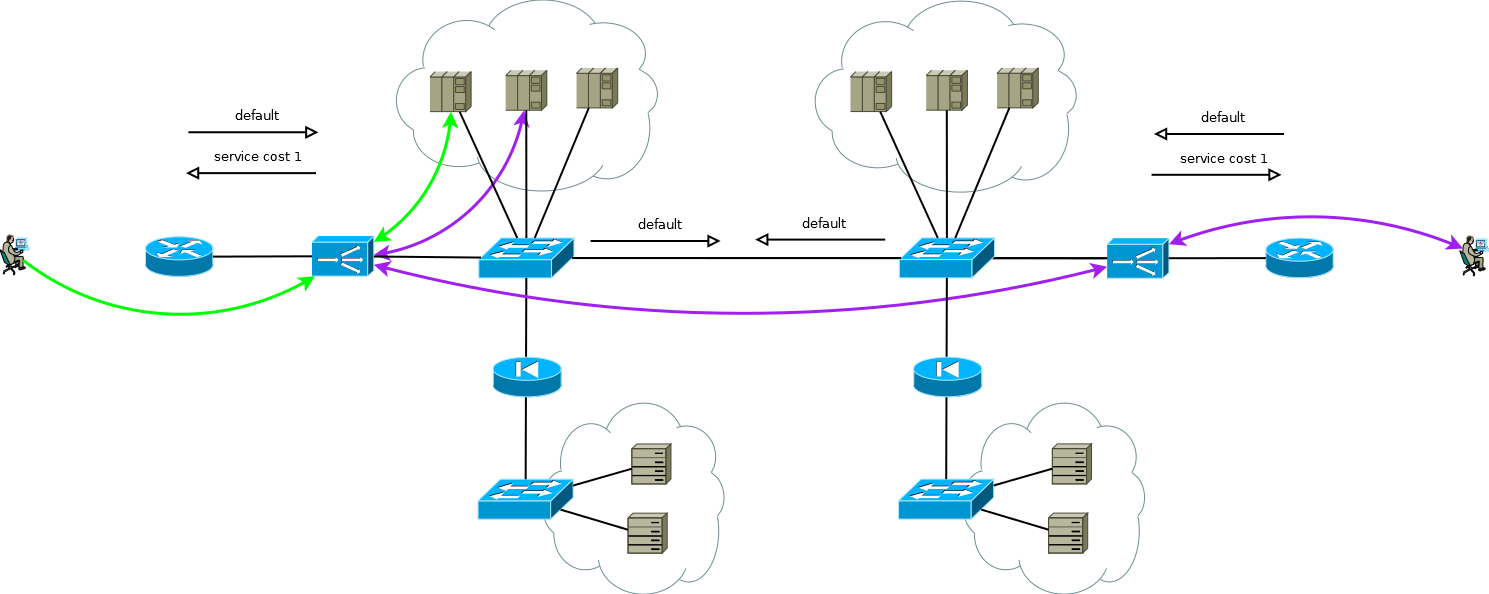 Fig. 9
Fig. 9Los servicios de nuestro cliente funcionaban aproximadamente de la misma manera cuando comencé a trabajar en un proyecto de migración a la nueva plataforma ADC. No fue difícil recrear simplemente el comportamiento de los dispositivos de la plataforma anterior en la nueva dentro del marco de un esquema comprobado y amigable para el cliente, esto es lo que esperaban de nosotros.
Pero mira nuevamente la Figura 9, ¿ves lo que se puede optimizar allí?
La principal desventaja de trabajar con la cadena ADC es que consume los recursos de dos ADC para procesar parte de las sesiones. En el caso de este cliente, la elección fue absolutamente consciente, se debió a los detalles de las aplicaciones y la necesidad de poder redistribuir muy rápidamente (de 20 a 50 segundos) la carga entre servidores de diferentes sitios. En diferentes períodos de tiempo, el doble procesamiento tomó un promedio de 15 a 30 por ciento de los recursos de ADC, esto es suficiente para pensar en la optimización. Habiendo discutido este punto con los ingenieros del cliente, propusimos reemplazar el soporte para la tabla de sesión ADC con enlace de interfaz con enrutamiento de origen en servidores que usan PBR en la pila IP de Linux. Como clave, consideramos opciones como:
- dirección IP adicional en servidores en una interfaz común para cada ADC;
- interfaz de dirección IP en servidores en un 802.1q separado para cada ADC;
- Red de túnel de superposición separada en servidores para cada ADC.
La primera y la segunda opción afectarían de alguna manera a la red en su conjunto. Entre los efectos secundarios de la opción uno, nos pareció inaceptable que un aumento que fuera un múltiplo del número de ADC, tablas ARP en los conmutadores, y la segunda opción requeriría un aumento en el número de dominios de transmisión de extremo a extremo entre sitios o instancias individuales de tablas de enrutamiento virtual. La naturaleza local de la tercera opción nos pareció muy atractiva, y nos pusimos a trabajar, lo que resultó en un controlador simple que automatiza la configuración de túneles en servidores y ADC, así como la configuración PBR en la pila IP de servidores Linux.
 Fig. 10
Fig. 10Como escribí, la migración se completó, el cliente obtuvo lo que quería: una nueva plataforma, simplicidad, flexibilidad, escalabilidad y, como resultado de cambiar a una superposición, simplificar la configuración del equipo de red como parte del servicio de estos servicios, en lugar de varias copias de tablas virtuales y grandes dominios de transmisión, resultó que - IP .
Colegas que trabajan con fabricantes de ADC, este párrafo se centra más en usted. Algunos de sus productos son buenos, pero trate de prestar atención a una integración más estrecha con las aplicaciones en los servidores, la automatización de su configuración y la organización de todo el proceso de desarrollo y operación. Esto me parece en la forma de una interacción clásica controlador-agente, haciendo cambios en el ADC, el usuario inicia la apelación del controlador a los agentes registrados, esto es lo que hicimos con el cliente, pero "fuera de la caja".Además, algunos clientes pueden considerar conveniente cambiar de un modelo PULL de interacción con servidores a un modelo PUSH. Las capacidades de la aplicación en los servidores son muy amplias, por lo que a veces es más fácil organizar una verificación específica de la aplicación del servicio en el propio agente. Si la verificación arroja un resultado positivo, el agente transmite información, por ejemplo, en una forma similar a la Comunidad de Costo BGP, para usar en algoritmos de cálculo ponderados.A menudo, diferentes departamentos de la organización realizan el mantenimiento del servidor y el ADC; cambiar a un modelo de interacción PUSH puede ser interesante porque este modelo elimina la necesidad de coordinación entre los departamentos en una interfaz de persona a persona. Los servicios en los que participa el servidor se pueden transferir directamente del agente al ADC en forma de algo similar a las especificaciones avanzadas de flujo de BGP.Hay mucho más para escribir. ¿Por qué soy todo esto? Al estar en una opción libre, tomamos una decisión a favor de una opción más conveniente, más adecuada o en favor de una opción que amplíe la ventana de oportunidad para minimizar nuestros riesgos. Los grandes jugadores en la industria de Internet inventan algo completamente innovador para resolver sus problemas, algo que mañana dicta, los jugadores más pequeños y las empresas con experiencia en el desarrollo de software utilizan cada vez más tecnologías y productos que les permiten una personalización profunda. Muchos fabricantes de equilibradores de carga notan una disminución en la demanda de sus productos. En otras palabras, los servidores y aplicaciones que se ejecutan en ellos, conmutadores y enrutadores hace algún tiempo, ya han cambiado cualitativamente y han entrado en la era SDN. Los balanceadores están en el umbral.dé este paso mientras la puerta está abierta, de lo contrario corre el riesgo de perder ventaja competitiva y mudarse a la periferia.