El prototipo del sistema de archivo Olive le permite ejecutar código antiguo en computadoras modernas

A principios de 2010, los economistas de Harvard Carmen Reinhart y Kenneth Rogov publicaron un análisis de datos económicos de diferentes países y concluyeron que si la deuda supera el 90% del PIB, esto amenazará el crecimiento económico del país. Con tanta deuda, en su opinión, el crecimiento debería volverse negativo.
Su análisis se realizó poco después de la recesión de 2008, por lo que estaba directamente relacionado con el trabajo de los legisladores, muchos de los cuales confiaban en la necesidad de aumentar la deuda para estimular las economías nacionales. Al mismo tiempo, políticos conservadores como Olli Rehn, entonces
comisionado europeo , y el congresista estadounidense Paul Ryan, utilizaron los descubrimientos de Reinhart y Rogov para hacer campaña en favor de la abstinencia financiera.
Tres años más tarde, Thomas Herndon, graduado de la Universidad de Massachusetts, encontró un error en la hoja de cálculo de Excel que Reinhart y Rogov usaron para sus cálculos. Su importancia fue enorme: con un análisis adecuado, Herndon mostró que el nivel de deuda del 90% del PIB se correlacionó con un crecimiento positivo de la economía del 2.2%, y no con un crecimiento negativo del -0.1%, como escribieron Reinhart y Rogov.
Herndon pudo verificar fácilmente las conclusiones de los economistas de Harvard, ya que tenía acceso al software con el que trabajaban: Microsoft Excel. ¿Qué pasa con los descubrimientos más antiguos que usaban software antiguo que es difícil de encontrar hoy en día?
Podemos decidir que la solución a este problema, mantener un software importante para futuros investigadores, no debería ser complicado. Después de todo, el software es solo una colección de archivos, y estos archivos son fáciles de almacenar en su disco duro o en cinta en forma digital. El código del programa de algunos programas puede incluso reproducirse en papel, para evitar problemas con la obsolescencia de los medios digitales para los que fue escrito.
Los programas se almacenan de esta manera de forma continua, incluso para programas que tienen varias décadas de antigüedad. En línea, por ejemplo, puede encontrar el código fuente de la computadora de orientación Apollo, que ayudó a llevar a los astronautas a la luna en la década de 1960. Fue reescrito en papel y subido a GitHub en 2016.
Y aunque a un programador incondicional le guste un estudio cuidadoso de ese código antiguo, la mayoría de las personas no están interesadas. Están interesados en usar software. Pero mantener el software listo para ejecutarse durante largos períodos de tiempo es extremadamente difícil, porque para ejecutar la mayoría de los programas antiguos, se necesitan computadoras y sistemas operativos antiguos.
Es posible que haya encontrado estos problemas mientras intentaba jugar juegos de computadora de su juventud. Pero en el campo de la investigación científica y técnica, la incapacidad de iniciar un programa antiguo puede tener consecuencias mucho más graves.
Además de los economistas, muchos otros investigadores, por ejemplo, físicos, químicos, biólogos e ingenieros, utilizan constantemente programas para el procesamiento de datos y la visualización de resultados de análisis. Se dedican a la simulación de fenómenos utilizando modelos informáticos escritos en varios lenguajes de programación y utilizando una gran cantidad de bibliotecas de software que respaldan su trabajo y enlaces a conjuntos de datos. Tales investigaciones y el software en el que confían juegan un papel importante en los descubrimientos y los informes de resultados de búsqueda.
Imagine que usted es un investigador que quiere verificar los cálculos de otro científico, realizados hace 25 años. ¿Todavía estará disponible ese viejo software? La compañía que lo lanzó ya podría cerrar. Incluso si hay una versión moderna, ¿aceptará los datos en el formato original? ¿Todos los cálculos, por ejemplo, trabajarán con errores de redondeo, serán idénticos a los antiguos realizados en la computadora hace una generación? Probablemente no.
La dependencia de los investigadores de las computadoras está creciendo, y las dificultades para tratar de ejecutar software antiguo están aumentando, y esto les impide verificar los resultados publicados anteriormente. El problema del software obsoleto niega el concepto de reproducibilidad que subyace en la ciencia.
Este problema puede afectar la realización de exámenes forenses. Supongamos que los cálculos del ingeniero muestran que el edificio debe estar en pie, y después de eso se cae el techo del edificio. ¿El ingeniero cometió un error o el software no funcionaba correctamente? Si muchos años después no se puede iniciar el software, será muy difícil verificarlo.
Por lo tanto, mis colegas de la Universidad Carnegie Mellon y yo hemos desarrollado una forma de archivar programas de tal manera que puedan iniciarse fácilmente hoy y en el futuro. Mis colegas, los informáticos Benjamin Gilbert e Ian Harks, escribieron la mayor parte del código. El archivero de software Daniel Ryan y las bibliotecarias Gloriana Saint-Claire, Erica Linke y Kif Webster, quienes, por razones obvias, tienen un gran interés en preservar esta parte de la cultura moderna, también participaron en la colaboración.
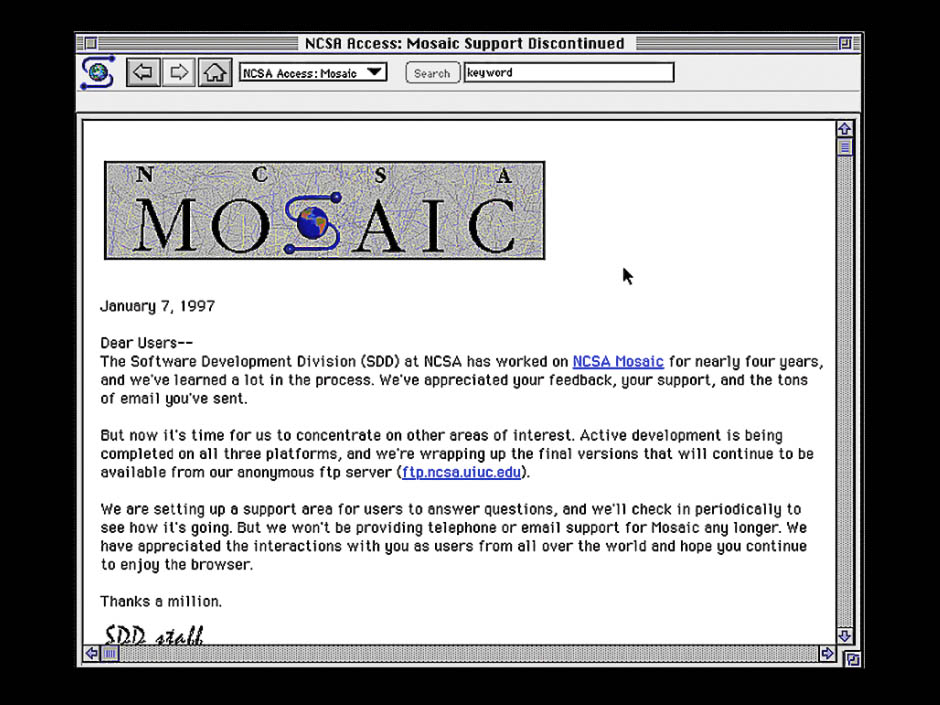 NCSA Mosaic 1.0, uno de los primeros navegadores con Macintosh, 1993
NCSA Mosaic 1.0, uno de los primeros navegadores con Macintosh, 1993 Chaste (Cáncer, corazón y entorno de tejidos blandos) 3.1 para Linux, 2013
Chaste (Cáncer, corazón y entorno de tejidos blandos) 3.1 para Linux, 2013 The Oregon Trail 1.1, juego para Macintosh, 1990
The Oregon Trail 1.1, juego para Macintosh, 1990 Wanderer, un juego para MS-DOS, 1988
Wanderer, un juego para MS-DOS, 1988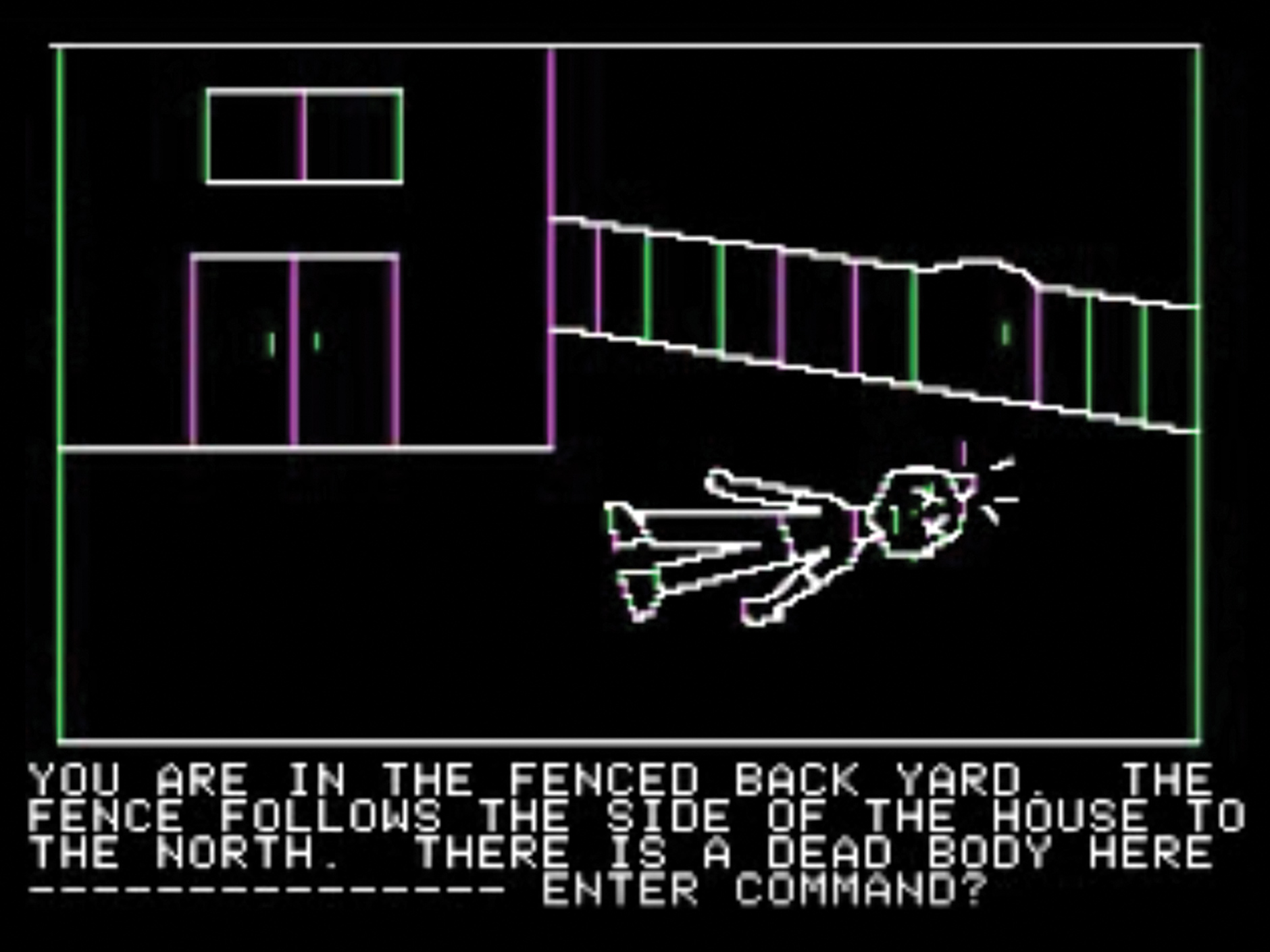 Mystery House, juego para Apple II, 1982
Mystery House, juego para Apple II, 1982 The Great American History Machine, un atlas educativo interactivo para Windows 3.1, 1991
The Great American History Machine, un atlas educativo interactivo para Windows 3.1, 1991 Microsoft Office 4.3 para Windows 3.1, 1994
Microsoft Office 4.3 para Windows 3.1, 1994 ChemCollective, software de química educativa para Linux, 2013
ChemCollective, software de química educativa para Linux, 2013Dado que este proyecto está relacionado con la preservación del software, y no con la informática popular, no recaudamos fondos de agencias estatales ordinarias, sino de la Fundación Alfred Sloan y el Instituto de Servicios de Museos y Bibliotecas. Con su ayuda, demostramos la restauración de sistemas informáticos olvidados hace mucho tiempo y los pusimos a disposición de todos en línea, para que cualquier usuario de la computadora pudiera retroceder en el tiempo con un solo clic.
Creamos el sistema
Olive , un acrónimo de Open Library of Images for Virtualized Execution. Olive le permite obtener a través de Internet la misma impresión que tendría al iniciar una aplicación, sistema operativo o computadora del pasado. Al instalar Olive, puede trabajar con software muy antiguo como si fuera moderno. Este es un poco del archivo de Internet de
Wayback Machine para programas ejecutables.
Para comprender cómo Olive puede revivir un entorno informático antiguo, debe pasar por varias capas de abstracciones de software. En la base misma se encuentra la base común de la mayoría de las tecnologías informáticas modernas: una computadora de escritorio o portátil estándar con uno o más microprocesadores x86. En él, ejecutamos el sistema operativo Linux, que forma la segunda capa en la pila.
Encima del sistema operativo se encuentra el software VMNetX, escrito en mi laboratorio, que ejecuta una máquina virtual a través de una red [Virtual Machine Network Execution]. Una máquina virtual es un entorno informático que imita el entorno de una computadora que existía en un tipo diferente de computadora. VMNetX le permite almacenar máquinas virtuales en un servidor central y ejecutarlas de forma remota a pedido. La ventaja es que su computadora no necesita descargar todo el disco y el estado de la memoria del servidor para iniciar la máquina virtual. La información almacenada en el disco y en la memoria se descarga en partes, si es necesario, para organizar la siguiente capa: el monitor de máquina virtual (hipervisor), que puede admitir la operación de varias máquinas simultáneamente.
Un emulador de hardware funciona en cada una de las máquinas virtuales: este es el siguiente nivel en la pila de Olive. El emulador finge que está ejecutando una computadora que ha estado en desuso durante mucho tiempo, por ejemplo, la antigua Macintosh Quadra con la CPU Motorola 68040 de los años 90. Si el software archivado puede ejecutarse en una computadora basada en x86, esta capa de virtualización puede omitirse.
La siguiente capa es el sistema operativo antiguo, que puede ejecutar software de archivo. Ella tiene acceso a un disco virtual que simula una unidad de disco y un sistema de archivos, necesarios para que funcionen las siguientes capas de este pastel de abstracción del programa.
Por encima del viejo sistema operativo ya está el programa en sí. Puede ser la parte superior del montón, o puede tener otra capa que consiste en datos que el programa necesita alimentar para obtener lo que desea de él.
Las capas superiores de Olive son diferentes para cada uno de los programas de archivo y se almacenan en un servidor central. Las capas inferiores se instalan en la computadora del usuario como parte del cliente. Al iniciar el programa de archivo, el cliente Olive descarga las partes necesarias de las capas superiores a pedido del servidor central.

Esto es lo que el sistema tiene debajo del capó. ¿Pero qué puede hacer Olive? Hoy contiene 17 máquinas virtuales diferentes que pueden ejecutar una variedad de sistemas operativos y aplicaciones. La elección de qué incluir en el sistema se basó en una mezcla de curiosidad, accesibilidad e intereses personales. Por ejemplo, un miembro de nuestro equipo recordó con cariño cómo jugó en The Oregon Trail mientras asistía a la escuela a principios de la década de 1990. Como resultado, encontramos una versión antigua del juego para Mac y logramos lanzarlo a través de Olive. Después de que esto se supiera, muchas personas comenzaron a acudir a nosotros con preguntas sobre la posibilidad de revivir su software favorito del pasado.
La aplicación más antigua que hemos restaurado es Mystery House, un juego gráfico de principios de la década de 1980 para una computadora Apple II. Otro programa es el mosaico NCSA, que, como pueden recordar personas de cierta edad, les dio maravillas de WWW.
Olive tiene una versión de Mosaic escrita en 1993 para el Sistema Macintosh 7.5. Este sistema operativo se ejecuta en el emulador de CPU Motorola 68040, creado utilizando un software que se ejecuta en una computadora basada en x86 que ejecuta Linux. A pesar de toda esta virtualización, el rendimiento no es malo, ya que las computadoras modernas funcionan mucho más rápido que el hardware original de Apple.
Es bastante interesante dirigir el mosaico restaurado de Olive a sitios modernos. Apareció antes que las tecnologías web modernas como JavaScript, HTTP 1.1, Cascading Style Sheets y HTML 5, y por lo tanto no puede mostrar la mayoría de los sitios. Pero es posible que le interese buscar
sitios que hayan sido visibles
desde hace tanto tiempo en este navegador.
¿De qué más es capaz Olive? Quizás se pregunte qué herramientas se usaron en los negocios justo después de que apareciera el procesador Intel Pentium. Olive puede ayudar con esto. Inicie Microsoft Office 4.3 desde 1994 (que, afortunadamente, salió antes de que apareciera el molesto asistente de clip).
Es posible que desee pasar una velada nostálgica jugando Doom para DOS, o ver por qué los tiradores en primera persona se hicieron tan populares a principios de la década de 1990. O tal vez necesite rehacer sus impuestos a partir de 1997, y no puede encontrar un disco con esa versión de TurboTax en el ático. No te preocupes, Olive te cuidará.
Si hablar de cosas más serias, entonces en Olive
Chaste 3.1 se almacena. Esto es la abreviatura de Cáncer, corazón y tejido blando (cáncer, corazón y tejido blando). Esta es una simulación desarrollada en la Universidad de Oxford, que permite resolver problemas computacionales en biología y fisiología. La versión 3.1 estaba relacionada con un trabajo de investigación publicado en marzo de 2013. Sin embargo, dos años después de la publicación, el código fuente de Chaste 3.1 dejó de compilarse en nuevas versiones de Linux. Este es un gran ejemplo de los problemas de reproducibilidad científica que el sistema Olive debería resolver.

Para mantener Chaste 3.1 funcionando, Olive ofrece un entorno Linux atemporal. Re-creado en Olive Chaste también contiene ejemplos de datos publicados con un trabajo de 2013. El procesamiento de estos datos ofrece una visualización del trabajo de los músculos. Los futuros investigadores de fisiología que quieran estudiar estas visualizaciones, o hacer correcciones al software publicado, podrán usar Olive para editar código en una máquina virtual y ejecutarlo.
Actualmente, Olive está disponible para un número limitado de usuarios. Debido a restricciones de licencia, el paquete de software antiguo de Olive solo está disponible para las personas que ayudaron en el desarrollo del proyecto. Las empresas relacionadas con el software deben otorgar permiso para presentar programas revividos a un público amplio.
No estamos solos en nuestra búsqueda de oportunidades para mantener la vida en el software antiguo. Internet Archive guarda miles de programas antiguos con un emulador de MS-DOS basado en navegador. En Yale, están desarrollando el proyecto EaaSI (infraestructura de emulación como servicio), con la esperanza de que todos tengan acceso a miles de emulaciones de entornos de software del pasado. Científicos y bibliotecarios del proyecto Software Preservation Network están trabajando en este y otros proyectos. También están trabajando para resolver los problemas de derechos de autor que aparecen al iniciar software antiguo de esta manera.
Olive ya está bien desarrollada, pero todavía está lejos de ser un sistema completamente terminado. Además del problema de la licencia, ella tiene que superar algunos obstáculos técnicos.
Uno de los obstáculos es la importación de nuevos datos para su procesamiento por el antiguo programa. Hasta ahora, dichos datos deben ingresarse manualmente, y este método es difícil y propenso a errores. Este método también limita la cantidad de datos que se pueden analizar. Incluso si agregamos un mecanismo de importación de datos, la cantidad de datos almacenados estaría limitada por el tamaño del disco virtual de la máquina virtual. Esto puede parecer un pequeño problema, pero debe recordar que los sistemas de archivos de las computadoras antiguas a veces tenían limitaciones en el volumen que ahora se perciben como extrañas.
Otro obstáculo es la emulación de GPU. Desde hace bastante tiempo, los científicos han estado utilizando la computación paralela para acelerar varios cálculos. Para archivar el software ejecutable que utiliza una GPU, el sistema Olive tendrá que recrear versiones virtuales de dichos chips, y esta es una tarea difícil. Esto se debe a que las interfaces de la GPU (lo que pueden ingresar y lo que generan) no están estandarizadas.
Obviamente, todavía queda mucho trabajo por hacer antes de anunciar la solución de problemas con el archivo de programas ejecutables. Pero Olive es un buen comienzo para crear los sistemas que se requerirán para garantizar que los programas antiguos se mantengan en un estado tal que puedan estudiarse, probarse y usarse durante mucho tiempo.