Hola a todos!
Hoy les diré cómo en
hh.ru consideramos estadísticas manuales sobre experimentos. Veremos de dónde provienen los datos, cómo los procesamos y qué dificultades encontramos. En este artículo compartiré una arquitectura y un enfoque comunes, habrá un mínimo de scripts y códigos reales. La audiencia principal son analistas novatos que están interesados en la estructura de la infraestructura de análisis de datos en hh.ru. Si este tema será interesante, escriba en los comentarios, podemos profundizar en el código en los siguientes artículos.
Puede leer sobre cómo se consideran las métricas automáticas para los experimentos A / B en nuestro
otro artículo .

¿Qué datos analizamos y de dónde provienen?
Analizamos los registros de acceso y cualquier registro personalizado que escribamos nosotros mismos.
95.108.213.12 - - [13 / agosto / 2018: 04: 00: 02 +0300] 200 "GET / empleador / 2574971 HTTP / 1.1" 12012 "-" "Mozilla / 5.0 (compatible; YandexBot / 3.0; + http: / /yandex.com/bots) "" - "" gardabani.headhunter.ge "" 0.063 "-" "1534122002.858" - "" 192.168.2.38:1500 "" [0.064] "{15341220027959c8c01c51a6e01b682f} 200 https 1 -" - "- - [35827] [0,000 0]
178.23.230.16 - - [13 / agosto / 2018: 04: 00: 02 +0300] 200 "GET / vacante / 24266672 HTTP / 1.1" 24229 " hh.ru/vacancy/24007186?query=bmw " "Mozilla / 5.0 ( Macintosh; Intel Mac OS X 10_10_5) AppleWebKit / 603.3.8 (KHTML, como Gecko) Versión / 10.1.2 Safari / 603.3.8 "-" "hh.ru" "0.210" "last_visit = 1534111115966 :: 1534121915966; hhrole = anónimo; regiones = 1; tmr_detect = 0% 7C1534121918520; total_searches = 3; unique_banner_user = 1534121429.273825242076558 "" 1534122002.859 "" - "" 192.168.2.239:1500 "" [0.208] "{1534122002649b7eef2e901d8c9c0469} 200 https 1 -" - "- - [35927] [0.001 0]
En nuestra arquitectura, cada servicio escribe registros localmente, y luego a través de los registros auto-escritos de cliente-servidor (incluidos los registros de acceso nginx) se recopilan en un repositorio central (en adelante, el registro). Los desarrolladores tienen acceso a esta máquina y pueden registrar manualmente los registros si es necesario. Pero, ¿cómo, en un tiempo razonable, puede engullir varios cientos de gigabytes de troncos? Por supuesto, ¡viértelos en hadoop!
¿De dónde provienen los datos en hadoop?
Hadoop no solo almacena registros de servicio, sino que también carga la base de datos de productos. Todos los días en hadoop cargamos algunas de las tablas necesarias para el análisis.
Los registros de servicio entran en hadoop de tres maneras.
- Camino a la frente : cron se inicia desde el almacenamiento de registros por la noche y rsync carga registros sin formato en hdfs.
- El camino está de moda : los registros de los servicios se vierten no solo en el almacenamiento común, sino también en kafka, donde el canal los lee, procesa previamente y los guarda en archivos hdf.
- El camino está pasado de moda : en los días previos a kafka, escribimos nuestro propio servicio, que lee los registros sin procesar del almacenamiento, lo hace desde el preprocesamiento y lo carga en hdfs.
Consideremos cada enfoque con más detalle.
Camino de la frente
Cron ejecuta un script bash regular.
Como recordamos, en el repositorio de registros todos los registros están en forma de archivos normales, la estructura de carpetas es aproximadamente la siguiente: /logging/java/2018/08/10/{service_nameasure/*.log
Hadoop almacena sus archivos en aproximadamente la misma estructura de carpetas hdfs-raw / banner-versiones / año = 2018 / mes = 08 / día = 10
año, mes, día que usamos como particiones.
Por lo tanto, solo necesitamos formar los caminos correctos (líneas 3-4), y luego seleccionar todos los registros necesarios (línea 6) y usar rsync para llenarlos en hadoop (línea 8).
Las ventajas de este enfoque:- Desarrollo rápido
- Todo es transparente y claro.
Contras:Manera de moda
Como cargamos los registros en el repositorio con una secuencia de comandos autoescrita, era lógico arruinar la capacidad de subirlos no solo al servidor, sino también a kafka.
Pros- Registros en línea (los registros en hadoop aparecen a medida que completa kafka)
- Puedes hacer preprocesamiento
- Sostiene bien la carga y puede cargar registros grandes
Contras- Configuración más difícil
- Tengo que escribir codigo
- Más partes del proceso de fundición
- Monitoreo y análisis de incidentes más complicados.
Manera antigua
Se diferencia de la moda solo en ausencia de kafka. Por lo tanto, hereda todas las desventajas y solo algunas de las ventajas del enfoque anterior. Un servicio separado (ustats-uploader) en java lee periódicamente los archivos necesarios, los procesa previamente y los carga en hadoop.
Pros- Puedes hacer preprocesamiento
Contras- Configuración más difícil
- Tengo que escribir codigo
Y así, los datos entraron en hadoop y listos para el análisis. Detengámonos un poco y recordemos qué es el hadoop y por qué se pueden consumir cientos de gigabytes mucho más rápido que el grep normal.
Hadoop
Hadoop es un almacén de datos distribuido. Los datos no se encuentran en ningún servidor separado, sino que se distribuyen entre varias máquinas, y también se almacenan no en una instancia, sino en varias, esto se hizo para garantizar la confiabilidad. La base de la velocidad de procesamiento de datos radica en un cambio de enfoque en comparación con las bases de datos convencionales.
En el caso de una base de datos regular, extraemos datos de ella y la enviamos al cliente, quien realiza algún tipo de análisis y devuelve el resultado al analista. Por lo tanto, para contar más rápido, necesitamos tener muchos clientes y paralelizar las solicitudes (por ejemplo, dividir los datos por meses, y cada cliente puede leer los datos de su mes).
En hadoop, lo contrario es cierto. Enviamos el código (exactamente lo que queremos calcular) a los datos, y este código se ejecuta en el clúster. Como sabemos, los datos se encuentran en muchas máquinas, por lo que cada máquina solo ejecuta código en sus datos y devuelve el resultado al cliente.
Muchos probablemente han oído hablar de
map-reduce , pero escribir código para análisis no es muy conveniente y rápido, mientras que escribir en SQL es mucho más simple. Por lo tanto, aparecieron servicios que pueden convertir SQL en reducción de mapa transparente para el usuario, y el analista puede no sospechar cómo se considera realmente su solicitud.
En hh.ru usamos colmena y presto para esto. La colmena fue la primera, pero nos estamos moviendo gradualmente a presto, porque es mucho más rápido para nuestras solicitudes. Como GUI, usamos hue y zeppelin.
Es más conveniente para mí considerar el análisis en Python en Jupyter, esto nos permite leerlo con un solo clic y obtener tablas de Excel correctamente formateadas en la salida, lo que ahorra mucho tiempo. Escriba en los comentarios, este tema se basa en un artículo separado.
Volvamos a la analítica en sí.
¿Cómo entender lo que queremos considerar?
El gerente de producto vino con la tarea de calcular los resultados del experimento.
Enviamos un boletín informativo por correo electrónico en el que enviamos las vacantes adecuadas para el solicitante (¿a todos les gustan esos correos?). Decidimos cambiar un poco el diseño de la carta y queremos entender si mejoró. Para esto consideraremos:
- el número de transiciones a vacantes de la carta;
- retroalimentación después de la transición
Permítame recordarle que todo lo que tenemos es el registro de acceso y la base de datos. Necesitamos formular nuestras métricas en términos de clics en enlaces.
Número de transiciones a una vacante de una carta
La transición es una solicitud GET a
hh.ru/vacancy/26646861 . Para entender de dónde vino la transición, agregamos etiquetas utm del formulario? Utm_source = email_campaign_123. Para las solicitudes GET en el registro de acceso, habrá información sobre los parámetros, y podemos filtrar las transiciones solo desde nuestra lista de correo.
El número de respuestas después de la transición.
Aquí podríamos simplemente calcular el número de respuestas a las vacantes del boletín, pero luego las estadísticas serían incorrectas, porque las respuestas podrían verse afectadas por algo más, excepto por nuestra carta, por ejemplo, se compró un anuncio en ClickMe para una vacante, y por lo tanto el número de respuestas muy crecido
Tenemos dos opciones sobre cómo formular el número de respuestas:
- La respuesta es una POST en hh.ru/applicant/vacancy_response/popup?vacancy_id=26646861 , que tiene un árbitro hh.ru/vacancy/26646861?utm_source=email_campaign_123 .
- El matiz de este enfoque es que si el usuario cambió a una vacante, y luego caminó un poco por el sitio y luego respondió a una vacante, entonces no lo contaremos.
- Podemos recordar la identificación del usuario que cambió a hh.ru/vacancy/26646861 , y calcular sobre la base el número de revisiones de la vacante durante el día.
La elección del enfoque está determinada por los requisitos del negocio, por lo general, la primera opción es suficiente, pero todo depende de lo que el gerente de producto esté esperando.
Errores que pueden ocurrir
- No todos los datos están en hadoop, debe agregar datos de la base de datos de productos. Por ejemplo, en los registros generalmente solo se identifica, y si necesita un nombre, entonces está en la base de datos. A veces necesita buscar un usuario por resume_id, y esto también se almacena en la base de datos. Para hacer esto, descargamos parte de la base de datos en hadoop para que la unión sea más simple.
- Los datos pueden ser curvas. Esto generalmente es un desastre para hadoop y la forma en que cargamos datos en él. Dependiendo de los datos, un valor vacío puede ser nulo, Ninguno, ninguno, una cadena vacía, etc. Debe tener cuidado en cada caso, porque los datos son realmente diferentes, cargados de diferentes maneras y para diferentes propósitos.
- Cuenta larga para todo el período. Por ejemplo, necesitamos calcular nuestras transiciones y respuestas para el mes. Esto es aproximadamente 3 terabytes de registros. Incluso hadoop tomará esto por bastante tiempo. Por lo general, escribir una solicitud de trabajo al 100% la primera vez es bastante difícil, por lo que lo escribimos por prueba y error. Cada vez que espere 20 minutos es mucho tiempo. Formas de resolver:
- Depuración de la solicitud en los registros en 1 día. Como teníamos datos particionados en hadoop, es bastante rápido calcular algo para 1 día de registros.
- Cargue los registros necesarios en la tabla temporal. Como regla general, entendemos en qué URL estamos interesados, y podemos hacer una tabla temporal para los registros de estas URL.
Personalmente, la primera opción es más conveniente para mí, pero, a veces, necesito hacer una tabla temporal, depende de la situación. - Distorsiones en las métricas finales
- Es mejor filtrar los registros. Debe prestar atención, por ejemplo, al código de respuesta, redireccionar, etc. Mejor menos datos, pero más precisos, de los que está seguro.
- Tan pocos pasos intermedios como sea posible en la métrica. Por ejemplo, cambiar a una vacante es un paso (solicitud GET para / vacante / 123). La respuesta es dos (transición a vacante + POST). Cuanto más corta es la cadena, menos errores y más exactamente la métrica. A veces sucede que los datos entre las transiciones se pierden y generalmente es imposible calcular algo. Para resolver este problema, debemos pensar en lo que consideraremos y cómo antes de desarrollar un experimento. Su registro separado de eventos necesarios ayuda mucho. Podemos filmar los eventos necesarios y, por lo tanto, la cadena de eventos será más precisa y el conteo es más fácil.
- Los bots pueden generar un montón de transiciones. Debe comprender dónde pueden ir los bots (por ejemplo, en páginas donde se requiere autorización, no deberían estar) y filtrar estos datos.
- Grandes golpes: por ejemplo, en uno de los grupos puede haber un solicitante, que genera el 50% de todas las respuestas. Habrá un sesgo de estadísticas, tales datos también necesitan ser filtrados.
- Es difícil formular qué considerar en términos de registro de acceso. Esto ayuda a conocer la base de código, la experiencia y las herramientas de desarrollo de Chrome. Leemos la descripción de la métrica del producto, la repetimos con nuestras manos en el sitio y vemos qué transiciones se generan.
Finalmente, hablemos sobre cómo debería verse el resultado de los cálculos.
Resultado del cálculo
En nuestro ejemplo, hay 2 grupos y 2 métricas que forman un embudo.
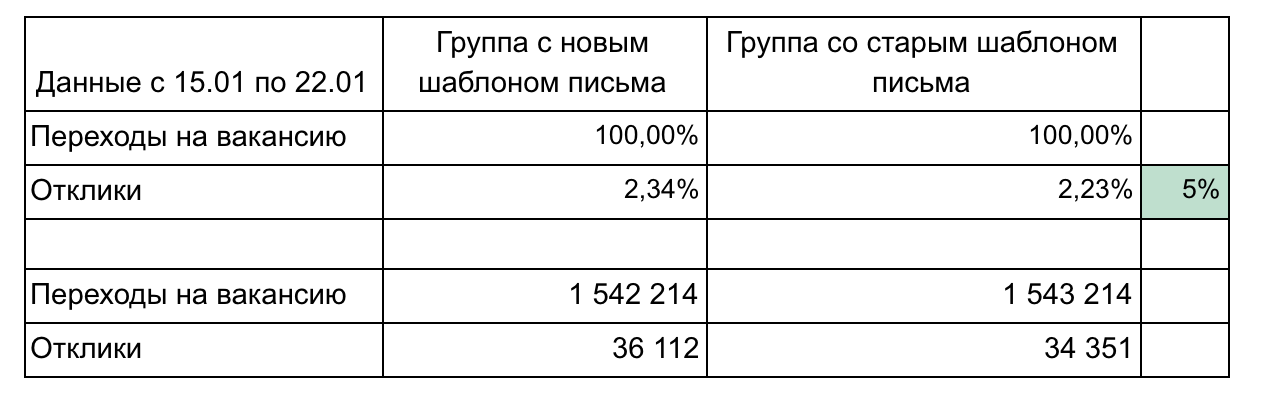
Recomendaciones para informar resultados:
- No sobrecargue las piezas hasta que sea necesario. Simple y más pequeño es mejor (por ejemplo, aquí podríamos mostrar cada vacante por separado o clics por día). Concéntrate en una cosa.
- Es posible que se necesiten detalles durante los resultados de la demostración, así que piense en las preguntas que podría hacer y prepare los detalles. (En nuestro ejemplo, los detalles pueden estar de acuerdo con la velocidad de transición después de enviar el correo electrónico: 1 día, 3 días, una semana, agrupando las vacantes por área profesional)
- Recuerde acerca de la significación estadística. Por ejemplo, un cambio del 1% con 100 clics y 15 clics es insignificante y podría ser aleatorio. Usa calculadoras
- Automatice tanto como sea posible, ya que tendrá que contar varias veces. Por lo general, en medio de un experimento, uno ya quiere entender cómo van las cosas. Después del experimento, pueden surgir preguntas y tendrá que aclarar algo. Por lo tanto, será necesario contar 3-4 veces, y si cada cálculo es una secuencia de 10 consultas y luego una copia manual para sobresalir, dolerá y pasará mucho tiempo. Aprenda Python, le ahorrará mucho tiempo.
- Use una representación gráfica de los resultados cuando esté justificado. Las herramientas de colmena y zeppelin incorporadas le permiten crear gráficos simples desde el primer momento.
Es necesario considerar varias métricas con bastante frecuencia, porque emitimos casi todas las tareas como parte de un experimento A / B. No hay nada complicado en los cálculos, después de 2-3 experimentos se llega a comprender cómo hacer esto. Recuerde que los registros de acceso almacenan una gran cantidad de información útil que puede ahorrar dinero a las empresas, ayudarlo a promover su idea y probar cuál de las opciones de cambio es mejor. Lo principal es poder obtener esta información.