TL; DR : el autor ha compilado un colector NetFlow / sFlow de GoFlow , Kafka , ClickHouse , Grafana y una muleta en Go.
Hola, soy un explotador y realmente me encanta saber qué está pasando en la infraestructura. Y también me gusta meterme en los asuntos de otras personas, y esta vez entré en la red.
Suponga que tiene su propio equipo de red y una bolsa de monolitos, microservicios y monolitos de microservicios adheridos a Internet con sus dependencias en forma de bases de datos, cachés y servidores FTP. Y a veces algunos habitantes de esta bolsa comienzan a jugar mal en una red.
Estos son solo algunos ejemplos de tales bromas:
- copia de seguridad fuera de la ventana prescrita en 40 transmisiones;
- errores de configuración al enviar una aplicación en un DC al caché de otro DC;
- preguntas de la aplicación en el siguiente rack al mismo caché "dame este objeto de medio megabyte del caché" doscientas veces por segundo.
Los contadores SNMP de puertos de conmutador o máquinas virtuales solo darán una comprensión aproximada de lo que está sucediendo, pero quiero precisión y rapidez en el análisis de problemas. Los protocolos NetFlow / IPFIX y sFlow vienen al rescate, que generan abundante información de tráfico directamente desde el equipo de red. Queda por ponerlo en algún lugar y procesarlo de alguna manera.
De los colectores NetFlow disponibles, se han considerado los siguientes:
- herramientas de flujo: no me gustó el almacenamiento en archivos (tomó mucho tiempo hacer selecciones, especialmente las operativas durante la reacción al incidente) o MySQL (tener una tabla de miles de millones de filas allí parece una idea bastante sombría);
- Elasticsearch + Logstash + Kibana es un grupo muy intensivo en recursos, hasta 6 núcleos de la CPU de 2.2 GHz para recibir 5000 flujos por segundo. Sin embargo, Kibana le permite pegar cualquier tipo de filtro en el navegador, lo cual es valioso;
- vflow : no me gustó el formato de salida (JSON, que sin modificación no se puede agregar al mismo Elasticsearch);
- soluciones en caja: no me gustó ni el alto precio ni la pequeña diferencia con el seleccionado.
Y fue elegido descrito en la presentación de Louis Poinsignon en el RIPE 75 . El esquema general de un colector simple es el siguiente:
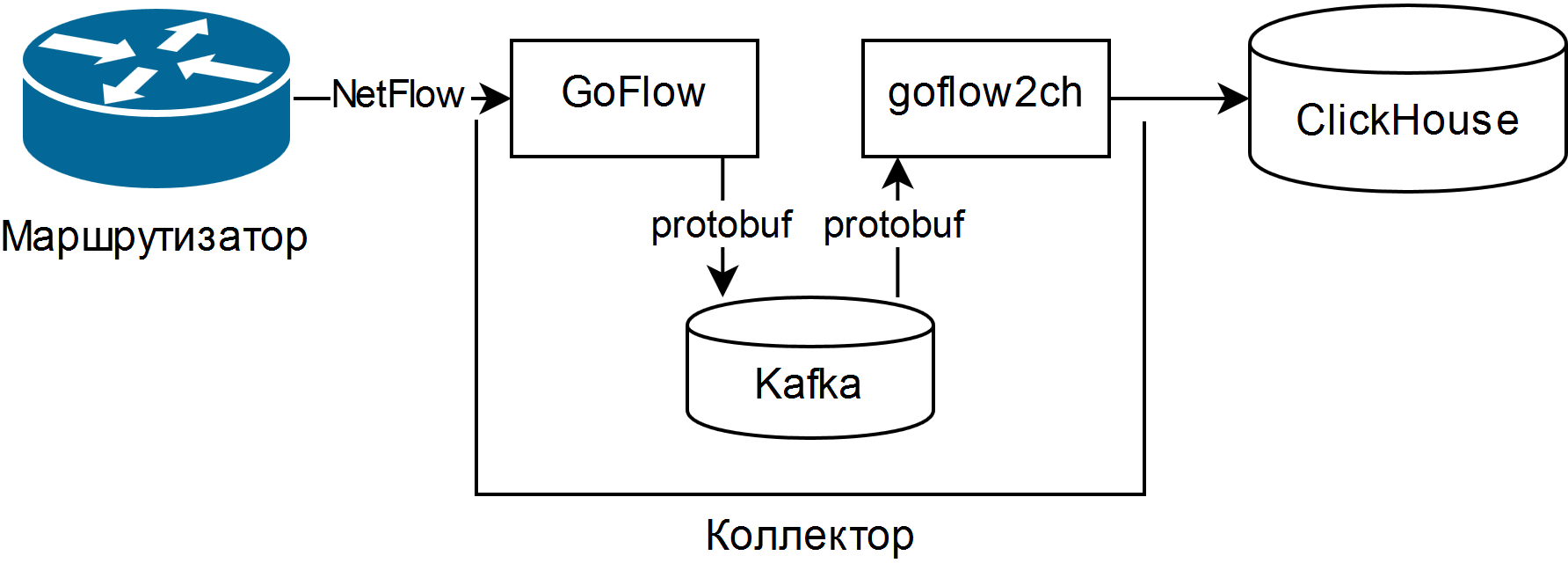
GoFlow analiza los paquetes NetFlow / sFlow y los coloca en un Kafka local en formato protobuf. La "pala" autoescrita goflow2ch toma mensajes de Kafka y los transfiere a Clickhouse en lotes para una mayor productividad. El esquema no aborda en absoluto el problema de la alta disponibilidad, pero para cada componente existen formas externas regulares o más o menos simples de proporcionarlo.
Las pruebas han demostrado que los costos de CPU para analizar y mantener los mismos 5000 subprocesos por segundo constituyen aproximadamente una cuarta parte del núcleo de la CPU, y el espacio en disco utilizado es de 11-14 bytes por flujo ligeramente truncado.
Para mostrar información, se usa la interfaz de usuario web para ClickHouse llamada Tabix o el complemento para Grafana .
Las ventajas del esquema:
- la capacidad de hacer preguntas arbitrarias sobre el estado de la red usando el dialecto SQL;
- bajos requisitos de recursos y escalabilidad horizontal. Los procesadores viejos / lentos y los discos duros magnéticos funcionarán;
- si es necesario, se recopila una tubería de datos completa para analizar eventos de red, incluso en tiempo real utilizando Kafka Streams, Flink o análogos;
- la capacidad de cambiar el almacenamiento a cualquier medio mínimo.
Los inconvenientes también son decentes:
- para hacer preguntas, necesita conocer bien SQL y su dialecto ClickHouse; no hay informes y gráficos ya preparados;
- muchas piezas móviles nuevas en forma de Kafka, Zookeeper y ClickHouse. Los dos primeros están en Java, lo que puede causar rechazo religioso. Para mí personalmente, esto no fue un problema, ya que todo esto ya se usaba de alguna manera en la organización;
- Hay que escribir el código. Ya sea una "pala" que transfiere datos de Kafka a ClickHouse, o un adaptador para grabar directamente desde GoFlow.
Características cumplidas:
- Asegúrese de ajustar la rotación de acuerdo con el tamaño de los datos en Kafka y ClickHouse, y luego verifique que realmente funcione. En Kafka hay un límite en el tamaño de la partición de registro, y en ClickHouse: partición mediante una clave arbitraria. Una nueva partición cada hora y la eliminación de particiones innecesarias cada 10 minutos funcionan bien para la supervisión operativa y se hacen un script desde solo unas pocas líneas;
- "Pala" se beneficia del uso de grupos de consumidores , lo que le permite agregar más "palas" para la escala y la tolerancia a fallas;
- Kafka le permite no perder datos cuando la "pala" o ClickHouse se cuelga (por ejemplo, por una gran solicitud y / o recursos limitados incorrectamente), pero es mejor, por supuesto, configurar cuidadosamente la base de datos;
- si va a recolectar sFlow, recuerde que algunos conmutadores cambian de manera predeterminada la frecuencia de muestreo de paquetes sobre la marcha, y se indica para cada flujo.
Como resultado, se obtuvo una herramienta para monitorear la situación de la red, tanto en el más o menos del tiempo real, como en la perspectiva histórica, a partir de componentes de código abierto y cinta aislante azul. A pesar de la profundidad de sus rodillas, ya ha ayudado a reducir el tiempo para resolver varios incidentes a veces.