Comenzamos
a estudiar los Grupos de control (Cgroups) en Red Hat Enterprise Linux 7, un mecanismo a nivel de núcleo que le permite controlar el uso de los recursos del sistema, examinó brevemente los fundamentos teóricos y ahora pasa a la práctica de administrar recursos de CPU, memoria y E / S.
Sin embargo, antes de cambiar cualquier cosa, siempre es útil averiguar cómo está todo organizado ahora.
Hay dos herramientas con las que puede ver el estado de los cgroups activos en el sistema. En primer lugar, se trata de systemd-cgls, un comando que muestra una lista en forma de árbol de cgroups y procesos en ejecución. Su salida se parece a esto:
Aquí vemos los cgroups de nivel superior: user.slice y system.slice. No tenemos máquinas virtuales, por lo tanto, bajo carga, estos grupos de nivel superior reciben el 50% de los recursos de la CPU (ya que el segmento de la máquina no está activo). Hay dos segmentos secundarios en user.slice: user-1000.slice y user-0.slice. Los segmentos de usuario se identifican mediante la ID de usuario (UID), por lo que identificar al propietario puede ser difícil, excepto para ejecutar procesos. En nuestro caso, las sesiones ssh muestran que el usuario 1000 es más rico y que el usuario 0 es root, respectivamente.
El segundo comando que usaremos es systemd-cgtop. Muestra una imagen del uso de recursos en tiempo real (la salida de systemd-cgls, por cierto, también se actualiza en tiempo real). En la pantalla, se ve así:
Hay un problema con systemd-cgtop: muestra estadísticas solo para aquellos servicios y sectores para los que está habilitada la contabilidad de uso de recursos. La contabilidad se habilita creando archivos conf de inserción en los subdirectorios apropiados en / etc / systemd / system. Por ejemplo, el menú desplegable en la siguiente captura de pantalla permite el uso de CPU y memoria para el servicio sshd. Para hacerlo usted mismo, simplemente cree el mismo menú desplegable en un editor de texto. Además, la contabilidad también se puede habilitar con la propiedad set-systemctl sshd.service CPUAccounting = true comando MemoryAccounting = true.
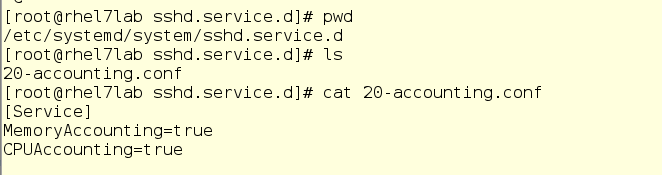
Después de crear el menú desplegable, debe ingresar el comando systemctl daemon-reload, así como el comando systemctl restart <service_name> para el servicio correspondiente. Como resultado, verá estadísticas sobre el uso de los recursos, pero esto creará una carga adicional, ya que los recursos también se gastarán en contabilidad. Por lo tanto, la contabilidad debe incluirse cuidadosamente y solo para aquellos servicios y grupos que necesitan ser monitoreados de esta manera. Sin embargo, a menudo en lugar de systemd-cgtop, puede hacerlo con los comandos top o iotop.
Cambie las bolas de CPU para divertirse y ser útil
Ahora veamos cómo un cambio en la bola del procesador (recursos compartidos de la CPU) afecta el rendimiento. Por ejemplo, tendremos dos usuarios sin privilegios y un servicio del sistema. El usuario con el inicio de sesión mrichter tiene un UID de 1000, que se puede verificar utilizando el archivo / etc / passwd.
Esto es importante porque los segmentos de usuario se nombran por UID y no por nombre de cuenta.
Ahora, repasemos el directorio desplegable y veamos si ya hay algo para su segmento.
No hay nada Aunque hay algo más, eche un vistazo a las cosas relacionadas con foo.service:
Si está familiarizado con los archivos de unidad systemd, verá aquí un archivo de unidad completamente ordinario que ejecuta el comando / usr / bin / sha1sum / dev / zero como un servicio (en otras palabras, un demonio). Para nosotros, lo importante es que foo tomará literalmente todos los recursos del procesador que el sistema le permitirá usar. Además, aquí tenemos un ajuste directo para el servicio foo, el valor de las bolas de CPU es igual a 2048. De forma predeterminada, como recordará, se usa con el valor 1024, por lo que bajo carga foo recibirá una doble participación de los recursos de la CPU dentro del sistema. , su segmento principal de nivel superior (ya que foo es un servicio).
Ahora ejecuta foo a través de systemctl y mira lo que nos muestra el comando superior:
Como prácticamente no hay otras cosas que funcionen en el sistema, el servicio foo (pid 2848) consume casi todo el tiempo de procesador de una CPU.
Ahora vamos a introducir mrichter en la ecuación del usuario. Primero, le cortamos una bola de CPU hasta 256, luego inicia sesión e inicia foo.exe, en otras palabras, el mismo programa, pero como un proceso de usuario.
Entonces mrichter lanzó foo. Y aquí está lo que muestra el comando superior:
Extraño, ¿eh? El usuario mrichter parece obtener aproximadamente el 10 por ciento del tiempo del procesador, ya que tiene = 256 bolas, y foo.service tiene hasta 2048, ¿no?
Ahora introducimos dorf en la ecuación. Este es otro usuario normal con una bola de CPU estándar igual a 1024. También ejecutará foo, y nuevamente veremos cómo cambiará la distribución del tiempo del procesador.
dorf es un usuario de la vieja escuela, solo comienza el proceso, sin ningún script inteligente ni nada más. Y de nuevo nos fijamos en la salida de arriba:
Entonces ... echemos un vistazo al árbol de cgroups e intentemos averiguar qué es qué:
Si recuerda, generalmente en un sistema hay tres cgroups de nivel superior: Sistema, Usuario y Máquina. Como no hay máquinas virtuales en nuestro ejemplo, solo quedan segmentos del sistema y del usuario. Cada uno de ellos tiene una bola de CPU de 1024 y, por lo tanto, bajo carga recibe la mitad del tiempo del procesador. Como foo.service vive en el sistema y no hay otros candidatos para el tiempo de CPU en este segmento, foo.service recibe el 50% de los recursos de la CPU.
Además, los usuarios dorf y mrichter viven en la sección Usuario. La primera bola es 1024, la segunda - 256. Por lo tanto, dorf obtiene cuatro veces más tiempo de procesador que mrichter. Ahora veamos qué muestra la parte superior: foo.service - 50%, dorf - 40%, mrichter - 10%.
Traduciendo esto a un lenguaje de casos de uso, podemos decir que dorf tiene una prioridad más alta. En consecuencia, los cgroups están configurados para que el usuario mrichter reduzca los recursos por el tiempo que necesitan dorf'u. De hecho, después de todo, mientras mrichter estaba solo en el sistema, recibió el 50% del tiempo del procesador, ya que en el segmento de Usuario nadie más compitió por los recursos de la CPU.
De hecho, las bolas de CPU son una forma de proporcionar un cierto "mínimo garantizado" de tiempo de procesador, incluso para usuarios y servicios con menor prioridad.
Además, tenemos una manera de establecer una cuota fija para los recursos de la CPU, un cierto límite en números absolutos. Haremos esto para el usuario mrichter y veremos cómo cambia la distribución de recursos.
Ahora eliminemos las tareas del usuario dorf, y esto es lo que sucede:
Para mrichter, el límite absoluto de la CPU es del 5%, por lo que foo.service obtiene el resto del tiempo del procesador.
Continúe intimidando y detenga foo.service:
Lo que vemos aquí: mrichter tiene el 5% del tiempo del procesador, y el 95% restante del sistema está inactivo. Burla formal, sí.
De hecho, este enfoque le permite pacificar de manera efectiva los servicios o aplicaciones que les gusta cambiar repentinamente y utilizar todos los recursos del procesador en detrimento de otros procesos.
Entonces, aprendimos a controlar la situación actual con cgroups. Ahora profundizamos un poco más y vemos cómo se implementa cgroup en el nivel del sistema de archivos virtual.
El directorio raíz para todos los cgroups en ejecución se encuentra en / sys / fs / cgroup. Cuando el sistema arranca, se llena cuando comienzan los servicios y otras tareas. Al iniciar y detener servicios, sus subdirectorios aparecen y desaparecen.
En la siguiente captura de pantalla, fuimos a un subdirectorio para el controlador de la CPU, es decir, en el segmento del sistema. Como puede ver, el subdirectorio para foo aún no está aquí. Ejecute foo y verifique un par de cosas, a saber, su PID y su bola de CPU actual:
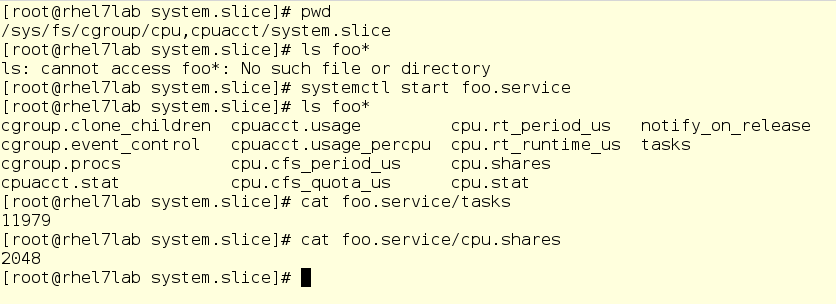
Advertencia importante: aquí puede cambiar los valores sobre la marcha. Sí, en teoría se ve genial (y en realidad también), pero puede convertirse en un gran desastre. Por lo tanto, antes de cambiar algo, sopesa todo cuidadosamente y nunca juegues en servidores de batalla. Pero de todos modos, un sistema de archivos virtual es algo para profundizar a medida que aprende cómo funcionan los cgroups.