La primera edición del CTP de SQL Server 2019 se presentó el 24 de septiembre, y permítanme decir que está llena de todo tipo de mejoras y nuevas características (muchas de las cuales se pueden encontrar en el formulario de vista previa en la base de datos SQL de Azure). Tuve una oportunidad excepcional de conocer esto un poco antes, lo que me permitió ampliar mi comprensión de los cambios, incluso superficialmente. También puede leer las
últimas publicaciones del equipo de SQL Server y la
documentación actualizada .
Sin entrar en detalles, voy a discutir las siguientes características nuevas del kernel: rendimiento, solución de problemas, seguridad, disponibilidad y desarrollo. Por el momento, tengo un poco más de detalles que otros, y algunos de ellos ya están preparados para su publicación. Regresaré a esta sección, así como a muchos otros artículos y documentación, y los publicaré. Me apresuro a informarle que esta no es una revisión exhaustiva, sino solo una parte de la funcionalidad que logré “tocar”, hasta CTP 2.0. Todavía hay mucho de qué hablar.
Rendimiento
Variables de la tabla: construcción del plan retrasado
Las variables de la tabla tienen una reputación no muy buena, principalmente en el campo de la estimación de costos. De forma predeterminada, SQL Server supone que una variable de tabla puede contener solo una fila, lo que a veces conduce a una elección inadecuada del plan cuando la variable contendrá muchas más filas. OPTION (RECOMPILE) generalmente se usa como una solución alternativa, pero esto requiere cambios de código y es un desperdicio, en relación con los recursos, realizar la reconstrucción cada vez, mientras que el número de líneas suele ser el mismo. Para emular la reconstrucción, se introdujo el
indicador de traza 2453 , pero también requiere un lanzamiento con el indicador, y solo funciona cuando se produce un cambio significativo en las líneas.
En el nivel de compatibilidad 150, la construcción diferida se realiza si las variables de la tabla están presentes y el plan de consulta no se construye hasta que la variable de la tabla se complete una vez. El costo se estimará en función de los resultados del primer uso de la variable de tabla, sin más reconstrucción. Este es un compromiso entre la reconstrucción constante para obtener el costo exacto y la ausencia total de reconstrucción con un costo constante 1. Si el número de filas permanece relativamente constante, este es un buen indicador (y aún mejor si el número excede 1), pero puede ser menos rentable si Hay una gran variación en el número de filas.
Presenté un análisis más profundo en un artículo reciente
Variables tabulares: compilación demorada en SQL Server , y Brent Ozar también habló sobre esto en el artículo
Variables tabulares rápidas (y nuevos problemas de análisis de parámetros) .
Comentarios de asignación de memoria en modo de cadena
SQL Server 2017 tiene comentarios de asignación de memoria por lotes, que se describe en detalle
aquí . Esencialmente, para cualquier asignación de memoria asociada con un plan de consulta que incluya declaraciones de modo por lotes, SQL Server evaluará la memoria utilizada por la consulta y la comparará con la memoria solicitada. Si la memoria solicitada es demasiado pequeña o demasiado, lo que provocará drenajes en tempdb o un desperdicio de memoria, en el próximo inicio se ajustará la memoria asignada para el plan de consulta correspondiente. Este comportamiento reducirá el volumen asignado y expandirá la concurrencia, o lo aumentará, para mejorar el rendimiento.
Ahora obtenemos el mismo comportamiento para las consultas en modo de cadena, bajo el nivel de compatibilidad 150. Si la consulta se vio obligada a fusionar datos en el disco, para lanzamientos posteriores se aumentará la memoria asignada. Si al completar la solicitud se requería la mitad de la memoria de la asignada, entonces, para solicitudes posteriores, se ajustará hacia abajo. Bretn Ozar describe esto con más detalle en su artículo
Asignación de memoria condicional .
Modo por lotes para almacenamiento línea por línea
A partir de SQL Server 2012, las tablas de consulta con índices de columna se han beneficiado del rendimiento mejorado del modo por lotes. Las mejoras de rendimiento se deben a un procesador de consultas que realiza un procesamiento por lotes en lugar de un procesamiento por filas. Las líneas también son procesadas por el núcleo de almacenamiento en paquetes, lo que evita las declaraciones de intercambio de concurrencia. Paul White (
@SQL_Kiwi ) me recordó que si usa una tabla vacía con almacenamiento de columna para hacer posibles las operaciones por lotes, las filas procesadas se recopilarán en paquetes mediante una declaración invisible. Sin embargo, esta muleta puede negar cualquier mejora recibida del procesamiento por lotes. Alguna información sobre esto está en la
respuesta a Stack Exchange .
En el nivel de compatibilidad 150, SQL Server 2019 seleccionará automáticamente el modo por lotes como un punto medio en ciertos casos, incluso cuando no hay índices de columnas. Podrías pensar que ¿por qué no simplemente crear un índice de columna y un sombrero? ¿O seguir usando la muleta mencionada anteriormente? Este enfoque también se extendió a los objetos tradicionales con almacenamiento de filas, porque los índices de columna, por varias razones, no siempre son posibles, incluidas las limitaciones funcionales (por ejemplo, los desencadenantes), la sobrecarga durante las operaciones de actualización o eliminación altamente cargadas, y la falta de soporte de fabricantes externos. Y no se puede esperar nada bueno de esa muleta.
Creé una tabla muy simple con 10 millones de filas y un índice agrupado en una columna entera y ejecuté esta consulta:
SELECT sa5, sa2, SUM(i1), SUM(i2), COUNT(*) FROM dbo.FactTable WHERE i1 > 100000 GROUP BY sa5, sa2 ORDER BY sa5, sa2;
El plan muestra claramente búsquedas de índice agrupadas y concurrencia, pero ni una palabra sobre el índice de columna (como
lo muestra
SentryOne Plan Explorer ):
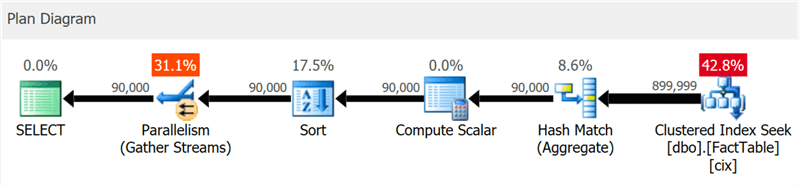
Pero si profundiza un poco más, puede ver que casi todos los operadores se ejecutaron en modo por lotes, incluso la clasificación y los cálculos escalares:

Puede deshabilitar esta función manteniéndose en un nivel de compatibilidad más bajo cambiando la configuración de la base de datos o utilizando el indicador DISALLOW_BATCH_MODE en la consulta:
SELECT … OPTION (USE HINT ('DISALLOW_BATCH_MODE'));
En este caso, aparece un operador de intercambio adicional, todos los operadores se ejecutan en modo línea por línea y el tiempo de ejecución de la consulta casi se triplica.

Hasta cierto nivel, puede ver esto en el diagrama, pero en el árbol de detalles del plan también puede ver la influencia de una condición de selección que no puede excluir filas hasta que se haya ordenado:

La elección del modo por lotes no siempre es un buen paso: la heurística incluida en el algoritmo de toma de decisiones tiene en cuenta la cantidad de líneas, los tipos de operadores propuestos y los beneficios esperados del modo por lotes.
APPROX_COUNT_DISTINCT
Esta nueva función agregada está diseñada para escenarios de almacenamiento de datos y es el equivalente de COUNT (DISTINCT ()). Sin embargo, en lugar de realizar clasificaciones costosas para determinar la cantidad real, la nueva función se basa en estadísticas para obtener datos relativamente precisos. Debe comprender que el error se encuentra dentro del 2% de la cantidad exacta, y en el 97% de los casos que son la norma para el análisis de alto nivel, estos son los valores que se muestran en los indicadores o se usan para estimaciones rápidas.
En mi sistema, creé una tabla con columnas enteras que incluían valores únicos en el rango de 100 a 1,000,000, y columnas de fila, con valores únicos en el rango de 100 a 100,000. No tenía índices excepto la clave primaria agrupada en la primera columna entera Estos son los resultados de ejecutar COUNT (DISTINCT ()) y APPROX_COUNT_DISTINCT () en estas columnas, desde las cuales puede ver ligeras discrepancias (pero siempre dentro del 2%):
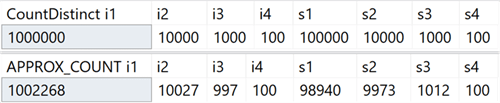
La ganancia es enorme si hay limitaciones de memoria, lo que se aplica a la mayoría de nosotros. Si observa los planes de consulta, en este caso particular, puede ver una gran diferencia en el consumo de memoria por parte del operador de coincidencia hash:

Tenga en cuenta que generalmente solo notará mejoras significativas en el rendimiento si ya está vinculado a la memoria. En mi sistema, la ejecución duró un poco más debido a la alta utilización de la CPU de la nueva función:

Quizás la diferencia sería más significativa si tuviera tablas más grandes, menos memoria disponible para SQL Server, mayor concurrencia o alguna combinación de lo anterior.
Consejos para usar el nivel de compatibilidad dentro de una consulta
¿Tiene una consulta especial que funciona mejor bajo un cierto nivel de compatibilidad, diferente de la base de datos actual? Esto ahora es posible gracias a las nuevas sugerencias de consulta que admiten seis niveles diferentes de compatibilidad y cinco modelos diferentes para estimar el número de elementos. Los siguientes son los niveles de compatibilidad disponibles, una sintaxis de ejemplo y un modelo de nivel de compatibilidad que se utiliza en cada caso. Vea cómo esto afecta las calificaciones, incluso para las vistas del sistema:

En resumen: ya no es necesario recordar las marcas de rastreo, o preguntarse si debe preocuparse si el parche TF 4199 para el optimizador de consultas está distribuido o si fue cancelado por algún otro paquete de servicios. Tenga en cuenta que estos consejos adicionales también se han agregado recientemente para SQL Server 2017 en la actualización acumulativa # 10 (consulte
el blog de Pedro López para más detalles). Puede ver todas las sugerencias disponibles con el siguiente comando:
SELECT name FROM sys.dm_exec_valid_use_hints;
Pero no olvide que las sugerencias son una medida excepcional, a menudo son adecuadas para salir de una situación difícil, pero no deben planificarse para su uso a largo plazo, ya que su comportamiento puede cambiar con las actualizaciones posteriores.
Solución de problemas
Perfiles predeterminados simplificados
Comprender esta mejora requiere algunos puntos para recordar. SQL Server 2014 introdujo la vista DMV sys.dm_exec_query_profiles, que permite al usuario que ejecuta la consulta recopilar información de diagnóstico sobre todas las declaraciones en todas las partes de la consulta. La información recopilada está disponible después de completar la consulta y le permite determinar qué operadores realmente gastaron los recursos principales y por qué. Cualquier usuario que no cumplió una solicitud específica podría recibir estos datos para cualquier sesión en la que se incluyera la declaración ESTADÍSTICAS XML o ESTADÍSTICA PERFIL, o para todas las sesiones, utilizando el evento query_post_execution_showplan extendido, aunque este evento, en particular, puede afectar el rendimiento general.
En Management Studio 2016, se ha agregado una funcionalidad que le permite mostrar flujos de datos que pasan por el plan de consulta en tiempo real en función de la información recopilada del DMV, lo que lo hace aún más potente para la resolución de problemas. Plan Explorer también ofrece la capacidad de visualizar datos que pasan a través de la consulta, tanto en tiempo real como en modo de reproducción.
A partir de SQL Server 2016 Service Pack 1 (SP1), también puede habilitar una versión ligera de la recopilación de estos datos para todas las sesiones utilizando el indicador de seguimiento 7412 o la propiedad query_thread_profile avanzada, que le permite obtener información actualizada sobre cualquier sesión, sin necesidad de nada. incluirlo explícitamente (en particular, cosas que afectan negativamente el rendimiento). Esto se describe
con más detalle en el
blog de Pedro López .
En SQL Server 2019, esta característica está habilitada de manera predeterminada, por lo que no necesita ejecutar ninguna sesión con eventos extendidos ni usar ningún indicador de seguimiento o declaraciones ESTADÍSTICAS en ninguna consulta. Simplemente mire los datos del DMV en cualquier momento para todas las sesiones concurrentes. Pero es posible deshabilitar este modo usando LIGHTWEIGHT_QUERY_PROFILING, sin embargo, esta sintaxis no funciona en CTP 2.0 y se solucionará en futuras ediciones.
Las estadísticas de índice de columnas agrupadas ahora están disponibles en bases de datos clonadas
En las versiones actuales de SQL Server, cuando se clona una base de datos, solo se usan las estadísticas del objeto original de los índices de columnas agrupadas, excluyendo las actualizaciones realizadas en la tabla después de su creación. Si usa un clon para configurar consultas y otras pruebas de rendimiento, que se basan en clasificaciones de potencia, entonces estos ejemplos pueden no funcionar. Parikshit Savyani describió las limitaciones
en esta publicación y proporcionó una solución temporal: antes de crear el clon, debe crear un script que ejecute DBCC SHOW_STATISTICS ... WITH STATS_STREAM para cada objeto. Es caro y, por supuesto, fácil de olvidar.
En SQL Server 2019, estas estadísticas actualizadas estarán disponibles automáticamente en el clon, por lo que puede probar varios escenarios de consulta y obtener planes objetivos basados en estadísticas reales, sin ejecutar STATS_STREAM manualmente para todas las tablas.
Pronóstico de compresión para almacenamiento de columnas
En las versiones actuales, el procedimiento sys.sp_estimate_data_compression_savings tiene la siguiente verificación:
if (@data_compression not in ('NONE', 'ROW', 'PAGE'))
Esto significa que le permite verificar la compresión de una línea o página (o ver el resultado de eliminar la compresión actual). En SQL Server 2019, esta verificación ahora se ve así:
if (@data_compression not in ('NONE', 'ROW', 'PAGE', 'COLUMNSTORE', 'COLUMNSTORE_ARCHIVE'))
Esta es una gran noticia porque le permite predecir aproximadamente el efecto de agregar un índice de columna a una tabla que no lo tiene, o convertir tablas o particiones a un formato de almacenamiento de columna aún más comprimido, sin tener que restaurar la tabla a otro sistema. Tenía una tabla con 10 millones de líneas, para lo cual realicé un procedimiento almacenado con cada uno de los cinco parámetros:
EXEC sys.sp_estimate_data_compression_savings @schema_name = N'dbo', @object_name = N'FactTable', @index_id = NULL, @partition_number = NULL, @data_compression = N'NONE';
Resultados:

Al igual que con otros tipos de compresión, la precisión depende completamente de las filas disponibles y la representatividad del resto de los datos. Sin embargo, esta es una forma bastante poderosa de obtener resultados predecibles sin mucha dificultad.
Nueva función para obtener información de la página.
Durante mucho tiempo, DBCC PAGE y DBCC IND se utilizaron para recopilar información sobre páginas que contienen una sección, índice o tabla. Pero no están documentados ni tienen soporte, y puede ser tedioso automatizar la solución de tareas asociadas con múltiples índices o páginas.
Más tarde, apareció una función administrativa dinámica (DMF) sys.dm_db_database_page_allocations, que devuelve un conjunto que representa todas las páginas del objeto especificado. Todavía no está documentado y tiene fallas que pueden convertirse en un problema real en tablas grandes: incluso para obtener información sobre una página, debe leer toda la estructura, lo que puede ser bastante costoso.
En SQL Server 2019, apareció otro DMF: sys.dm_db_page_info. Básicamente, devuelve toda la información de la página, sin la sobrecarga de la distribución DMF. Sin embargo, para usar la función en las compilaciones actuales, necesita saber de antemano el número de la página que está buscando. Quizás este paso fue tomado intencionalmente, porque Esta es la única forma de garantizar el rendimiento. Entonces, si está tratando de identificar todas las páginas en un índice o tabla, entonces todavía necesita usar la distribución DMF. En el próximo artículo describiré esta pregunta con más detalle.
Seguridad
Cifrado permanente utilizando un entorno seguro (enclave)
Por el momento, el cifrado permanente protege los datos confidenciales durante la transmisión y en la memoria mediante el cifrado / descifrado en cada extremo del proceso. Desafortunadamente, esto a menudo conlleva serias limitaciones cuando se trabaja con datos, como la imposibilidad de realizar cálculos y filtros, por lo que debe transferir todo el conjunto de datos al lado del cliente para realizar, por ejemplo, una búsqueda de rango.
Un entorno seguro (enclave) es un área protegida de memoria donde se pueden delegar tales cálculos y filtros (Windows usa
seguridad basada en virtualización ): los datos permanecen cifrados en el núcleo, pero se pueden descifrar o cifrar de forma segura en un entorno seguro. Solo necesita agregar el parámetro ENCLAVE_COMPUTATIONS a la clave primaria usando SSMS, por ejemplo, marcando la casilla "Permitir cálculos en un entorno seguro":
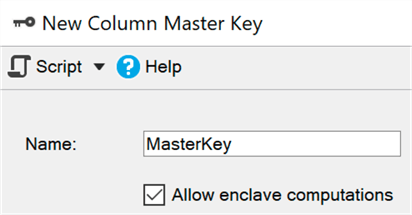
Ahora puede cifrar datos casi instantáneamente, en comparación con el método anterior (en el que el asistente, el cmdlet Set-SqlColumnEncyption o su aplicación, tendría que obtener completamente el conjunto completo de la base de datos, cifrarlo y enviarlo de vuelta):
ALTER TABLE dbo.Patients ALTER COLUMN SSN char(9)
Creo que para muchas organizaciones esta mejora será la principal noticia, pero en el CTP actual algunos de estos subsistemas todavía se están mejorando, por lo tanto, están desactivados de forma predeterminada, pero
aquí puede ver cómo activarlos.
Gestión de certificados en Configuration Manager
La administración de certificados SSL y TLS siempre ha sido una tarea difícil, y muchas personas se han visto obligadas a realizar el tedioso trabajo de crear sus propios scripts para implementar y mantener sus certificados empresariales. El Administrador de configuración actualizado para SQL Server 2019 lo ayudará a ver y verificar rápidamente los certificados de cualquier instancia, encontrar los certificados que vencen pronto y sincronizar las implementaciones de certificados en todas las réplicas en el grupo de disponibilidad o en todos los nodos en la instancia del clúster de conmutación por error.
No he intentado todas estas operaciones, pero deberían funcionar para versiones anteriores de SQL Server si la administración proviene del Administrador de configuración de SQL Server 2019.
Clasificación y auditoría de datos incorporados.
El equipo de desarrollo de SQL Server ha agregado la capacidad de clasificar datos en SSMS 17.5, lo que le permite identificar cualquier columna que pueda contener información confidencial o que contradiga varios estándares (HIPAA, SOX, PCI y GDPR, por supuesto). El asistente utiliza un algoritmo que ofrece columnas que se supone que causan problemas, pero puede ajustar su oración eliminando estas columnas de la lista o agregar la suya propia. Para almacenar la clasificación, se utilizan propiedades avanzadas; El informe SSMS incorporado utiliza la misma información para mostrar sus datos. Fuera del informe, estas propiedades no son tan obvias.
SQL Server 2019 introdujo una nueva declaración para estos metadatos, ya disponible en la Base de datos SQL de Azure, y se llamó AÑADIR CLASIFICACIÓN DE SENSIBILIDAD. Le permite hacer lo mismo que el asistente en SSMS, pero la información ya no se almacena en la propiedad extendida, y cualquier acceso a estos datos se muestra automáticamente en la auditoría como una nueva columna XML data_sensitivity_information. Contiene todo tipo de información que se vio afectada durante la auditoría.
Como ejemplo rápido, supongamos que tengo una tabla para contratistas externos:
CREATE TABLE dbo.Contractors ( FirstName sysname, LastName sysname, SSN char(9), HourlyRate decimal(6,2) );
Al observar dicha estructura, queda claro que las cuatro columnas son potencialmente vulnerables a las fugas o deberían ser accesibles solo para un círculo limitado de personas. Aquí puede pasar con permisos, pero al menos debe centrarse en ellos. Por lo tanto, podemos clasificar estas columnas de diferentes maneras:
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.FirstName, dbo.Contractors.LastName WITH (LABEL = 'Confidential – GDPR', INFORMATION_TYPE = 'Personal Info'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.SSN WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'National ID'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.HourlyRate WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'Financial');
Ahora, en lugar de mirar sys.extended_properties, puede verlos en sys.sensitivity_classifications:

Y si llevamos a cabo un muestreo de auditoría (o DML) para esta tabla, no necesitamos cambiar específicamente nada; después de crear la clasificación,
SELECT * registrará en el registro de auditoría un registro de este tipo de información en una nueva columna data_sensitivity_information:
<sensitivity_attributes> <sensitivity_attribute label="Confidential - GDPR" information_type="Personal Info" /> <sensitivity_attribute label="Highly Confidential" information_type="National ID" /> <sensitivity_attribute label="Highly Confidential" information_type="Financial" /> </sensitivity_attributes>
Por supuesto, esto no resuelve todos los problemas de cumplimiento de las normas, pero puede dar una ventaja real. El uso del asistente para identificar columnas automáticamente y traducir las llamadas de propiedad sp_addextended a los comandos AGREGAR CLASIFICACIÓN DE SENSIBILIDAD puede simplificar enormemente la tarea de cumplir con los estándares. Más tarde, escribiré un artículo separado sobre esto.
También puede automatizar la creación (o actualización) de permisos en función de la etiqueta en los metadatos: la creación de un script SQL dinámico que prohíbe el acceso a todas las columnas confidenciales (GDPR), lo que le permitirá administrar usuarios, grupos o rolesb. Trabajaré en este tema en el futuro.
Disponibilidad
Creación de índice renovable en tiempo real
En SQL Server 2017, fue posible suspender y reanudar la reconstrucción del índice en tiempo real, lo que puede ser muy útil si necesita cambiar la cantidad de procesadores utilizados, continuar desde el momento de la suspensión después de una falla o simplemente cerrar la brecha entre las ventanas de servicio. Hablé sobre esta característica en un
artículo anterior .
En SQL Server 2019, puede usar la misma sintaxis para crear índices en tiempo real, pausar y continuar, y también para limitar el tiempo de ejecución (establecer el tiempo de pausa):
CREATE INDEX foo ON dbo.bar(blat) WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 10 MINUTES);
Si esta consulta funciona durante demasiado tiempo, para hacer una pausa, puede ejecutar ALTER INDEX en otra sesión (incluso si el índice aún no existe físicamente):
ALTER INDEX foo ON dbo.bar PAUSE;
En las compilaciones actuales, el grado de paralelismo durante la renovación no se puede reducir, como es el caso con la reconstrucción. Al intentar reducir la DOP:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 2);
Obtenemos lo siguiente:
Msg 10666, Level 16, State 1, Line 3 Cannot resume index build as required DOP 4 (DOP operation was started with) is not available. Please ensure sufficient DOP is available or abort existing index operation and try again. The statement has been terminated.
De hecho, si intenta hacer esto y luego ejecuta el comando sin parámetros adicionales, obtendrá el mismo error, al menos en las compilaciones actuales. Creo que el intento de renovación se grabó en alguna parte y el sistema quería usarlo nuevamente. Para continuar, debe especificar el valor DOP correcto (o superior):
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 4);
Para que quede claro: puede aumentar la DOP al reanudar una creación de índice en pausa, pero no disminuirla.
Un beneficio adicional de todo esto es que puede configurar la creación y / o renovación de índices en tiempo real como el modo predeterminado utilizando las cláusulas ELEVATE_ONLINE y ELEVATE_RESUMABLE para la nueva base de datos.
Creación / reconstrucción en tiempo real de índices de columnas agrupadas
Además de la creación de índices renovables, también tenemos la oportunidad de crear o reconstruir índices de columnas agrupadas en tiempo real. Este es un cambio significativo, que le permite no pasar más tiempo de las ventanas de servicio en el mantenimiento de dichos índices o (para mayor certeza) para convertir los índices de fila a columna:
CREATE TABLE dbo.splunge ( id int NOT NULL ); GO CREATE UNIQUE CLUSTERED INDEX PK_Splunge ON dbo.splunge(id); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (DROP_EXISTING = ON, ONLINE = ON);
Una advertencia: si se creó un índice agrupado tradicional existente en tiempo real, entonces su conversión a un índice de columna agrupada también es posible solo en este modo. Si es parte de la clave primaria, incorporada o no ... CREATE TABLE dbo.splunge ( id int NOT NULL CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED (id) ); GO
Recibimos el siguiente error: Msg 1907, Level 16 Cannot recreate index 'PK_Splunge'. The new index definition does not match the constraint being enforced by the existing index.
Primero debe eliminar la restricción para convertirla en un índice de columna agrupada, pero ambas operaciones se pueden realizar en tiempo real: ALTER TABLE dbo.splunge DROP CONSTRAINT PK_Splunge WITH (ONLINE = ON); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (ONLINE = ON);
Esto funciona, pero es probable que las tablas grandes tarden más que si la clave principal se implementara como un índice agrupado único. No puedo decir con certeza si se trata de una restricción intencional o simplemente una limitación del CTP actual.Redireccionar una conexión de replicación de un servidor secundario a uno primario
Esta función le permite configurar la redirección sin escuchar, por lo que puede cambiar la conexión al servidor primario, incluso si el secundario se especifica directamente en la cadena de conexión. Esta función se puede usar cuando la tecnología de agrupación en clúster no admite la escucha, cuando se utilizan AG sin un clúster o cuando hay un esquema de redireccionamiento complejo en un escenario con múltiples subredes. Esto evitará que la conexión, por ejemplo, intente escribir operaciones para la replicación en modo de solo lectura (y fallas, respectivamente).Desarrollo
Características adicionales del gráfico.
Las relaciones de gráficos ahora admiten la instrucción MERGE para un nodo o tablas de límites que utilizan predicados MERGE; Ahora un operador puede actualizar un borde existente o insertar uno nuevo. La nueva restricción de borde le permite determinar qué nodos puede conectar el borde.Utf-8
SQL Server 2012 agregó soporte para UTF-16 y caracteres adicionales al configurar la clasificación especificando un nombre con el sufijo _SC, como Latin1_General_100_CI_AI_SC, para usar columnas Unicode (nchar / nvarchar). En SQL Server 2017, puede importar y exportar datos UTF-8 desde y hacia estas columnas utilizando herramientas como BCP y BULK INSERT .En SQL Server 2019, hay nuevas opciones de intercalación para admitir la retención forzada de datos UTF-8 en su forma original. Por lo tanto, puede crear fácilmente columnas char o varchar y almacenar datos UTF-8 correctamente utilizando la nueva clasificación con el sufijo _SC_UTF8, como Latin1_General_100_CI_AI_SC_UTF8. Esto puede ayudar a mejorar la compatibilidad con aplicaciones externas y DBMS, sin el costo de procesar y almacenar nvarchar.Huevo de pascua que encontré
Hasta donde recuerdo, los usuarios de SQL Server se quejan de este vago mensaje de error: Msg 8152 String or binary data would be truncated.
En las compilaciones de CTP con las que experimenté, se notó un mensaje de error interesante que no estaba allí antes: Msg 2628 String or binary data would be truncated in table '%.*ls', column '%.*ls'. Truncated value: '%.*ls'
No creo que se necesite nada más aquí; Esta es una gran mejora (aunque muy tardía) y promete hacer felices a muchos. Sin embargo, esta funcionalidad no estará disponible en CTP 2.0; Solo te doy la oportunidad de mirar un poco más adelante. Brent Ozar enumeró todos los mensajes nuevos que encontró en el CTP actual y los sazonó con algunos comentarios útiles en su artículo sys.messages: descubriendo características adicionales .Conclusión
SQL Server 2019 ofrece buenas características adicionales que ayudarán a mejorar el trabajo con su plataforma de base de datos relacional favorita, y hay una serie de cambios de los que no he hablado. La memoria de bajo consumo de energía, la agrupación para servicios de aprendizaje automático, la replicación y las transacciones distribuidas en Linux, Kubernetes, los conectores para Oracle / Teradata / MongoDB, las replicaciones sincronizadas de AG han aumentado para admitir Java (la implementación es similar a Python / R) y, lo que es más importante, un nuevo salto, titulado Big Data Cluster. Para usar algunas de estas características, debe registrarse utilizando este formulario EAP .El próximo libro de Bob Ward, Pro SQL Server en Linux: incluida la implementación basada en contenedores con Docker y Kubernetes, puede dar algunas pistas sobre una serie de otras cosas que vendrán pronto. Y esta publicación de Brent Ozar habla sobre una posible solución para una función escalar definida por el usuario.Pero incluso en este primer CTP público, hay algo significativo para casi todos, ¡y te insto a que lo pruebes tú mismo!