Amigos, buenas tardes.
Existe un claro entendimiento de que la mayoría de los proyectos de ICO son esencialmente un activo intangible. El proyecto ICO no es un automóvil Mercedes-Benz: se conduce independientemente de quién lo ame o no. Y la influencia principal en el ICO proviene del estado de ánimo de las personas, tanto la actitud hacia el fundador / fundador del ICO como el proyecto en sí.
Sería bueno medir de alguna manera la actitud de las personas hacia el fundador del ICO y / o el proyecto ICO. Lo cual fue hecho. El informe está abajo.
El resultado fue una herramienta para recopilar estados de ánimo positivos / negativos de Internet, en particular de Twitter.
Mi entorno es Windows 10 x64, utilicé el lenguaje Python 3 en el editor Spyder en Anaconda 5.1.0, una conexión de red cableada.
Recogida de datos
Me emocionarán las publicaciones de Twitter. Primero, averiguaré qué está haciendo el fundador de la ICO ahora y qué tan positivamente responden al respecto con el ejemplo de un par de personalidades famosas.
Usaré la biblioteca tweepy de Python. Para trabajar con Twitter, debe registrarse como desarrollador en él, ver twitter / . Obtenga criterios de acceso a Twitter.
El código es el siguiente:
import tweepy API_KEY = "vvvvEXQWhuF1fhAqAtoXRrrrr" API_SECRET = "vvvv30kspvqiezyPc26JafhRjRiZH3K12SGNgT0Ndsqu17rrrr" ACCESS_TOKEN = "vvvv712098-WBn6rZR4lXsnZCwcuU0aOsRkENSGpw2lppArrrr" ACCESS_TOKEN_SECRET = "vvvvlG7APRc5yGiWY5xFKfIGpqkHnXAvuwwVzMwyyrrrr" auth = tweepy.OAuthHandler(API_KEY, API_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) api = tweepy.API(auth)
Ahora podemos recurrir a la API de Twitter y obtener algo de ella, o viceversa, publicarla. La cosa se hizo a principios de agosto. Necesita obtener algunos tweets para encontrar el proyecto actual del fundador. Buscado así:
import pandas as pd searchstring = searchinfo+' -filter:retweets' results = pd.DataFrame() coursor = tweepy.Cursor(api.search, q=searchstring, since="2018-07-07", lang="en", count = 500) for tweet in coursor.items(): my_series = pd.Series([str(tweet.id), tweet.created_at, tweet.text, tweet.retweeted], index=['id', 'title', 'text', 'retweeted']) result = pd.DataFrame(my_series).transpose() results = results.append(result, ignore_index = True) results.to_excel('results.xlsx')
En searchinfo sustituimos el nombre necesario y reenviamos. El resultado se guardó en results.xlsx excel.
Creativo
Entonces decidí hacer una creatividad. Necesitamos encontrar los proyectos del fundador. Los nombres de los proyectos son nombres propios y están en mayúscula. Supongamos que esto también parece ser cierto que con una letra mayúscula en cada tweet se escribirá: 1) el nombre del fundador, 2) el nombre de su proyecto, 3) la primera palabra del tweet y 4) palabras extrañas. Las palabras 1 y 2 se encontrarán con frecuencia en los tweets, y 3 y 4 son raras, en frecuencia somos 3 y 4 y eliminamos. Sí, también resultó que los enlaces a menudo aparecen en tweets, 5) también los eliminaremos.
Resultó así:
import re import nltk nltk.download('stopwords') from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer corpus = [] for i in range(0, len(results.index)): review1 = [] mystr = results['text'][i]
Análisis de datos creativos
En la variable de nombres tenemos las palabras, y en la variable X, los lugares donde se mencionan. "Apagar" la tabla X: obtenga el número de referencias. Eliminamos palabras que rara vez se mencionan. Guardar en Excel. Y en Excel hacemos un hermoso gráfico de barras con información sobre con qué frecuencia se mencionan las palabras en cada consulta.
Nuestras súper estrellas de ICO son Le Minh Tam y Mike Novogratz. Gráficos:
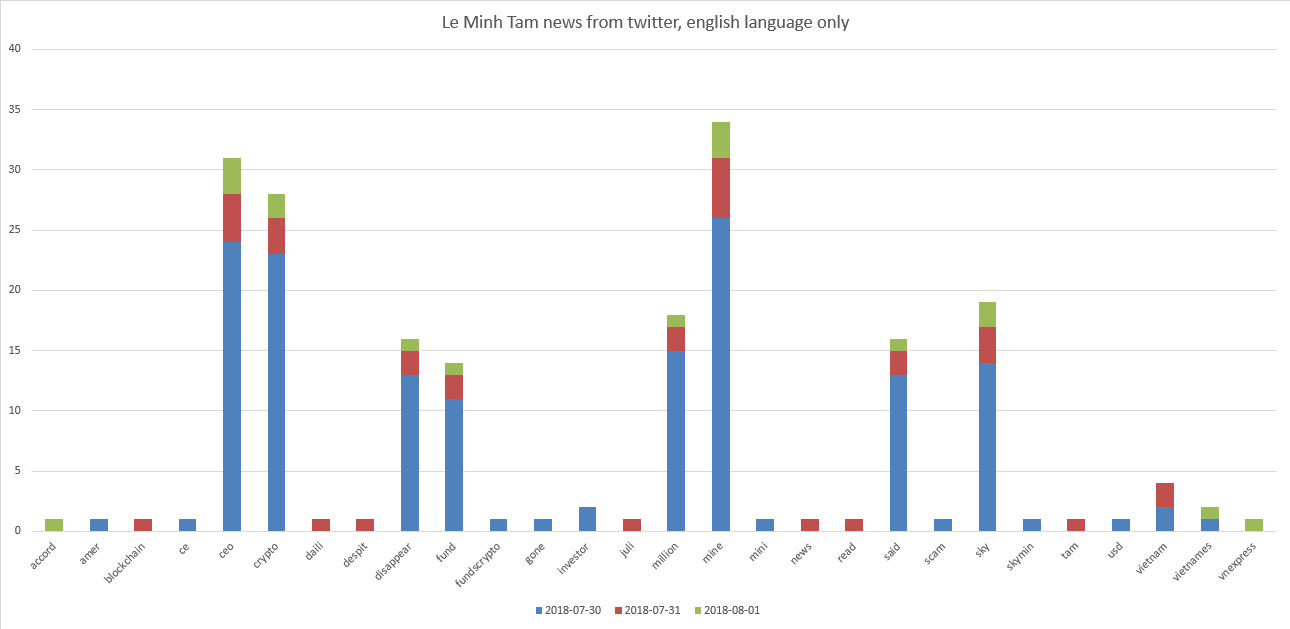
Se puede ver que Le Minh Tam está relacionado con "ceo, crypto, mine, sky". Y un poco para "desaparecer, fondo, millones".
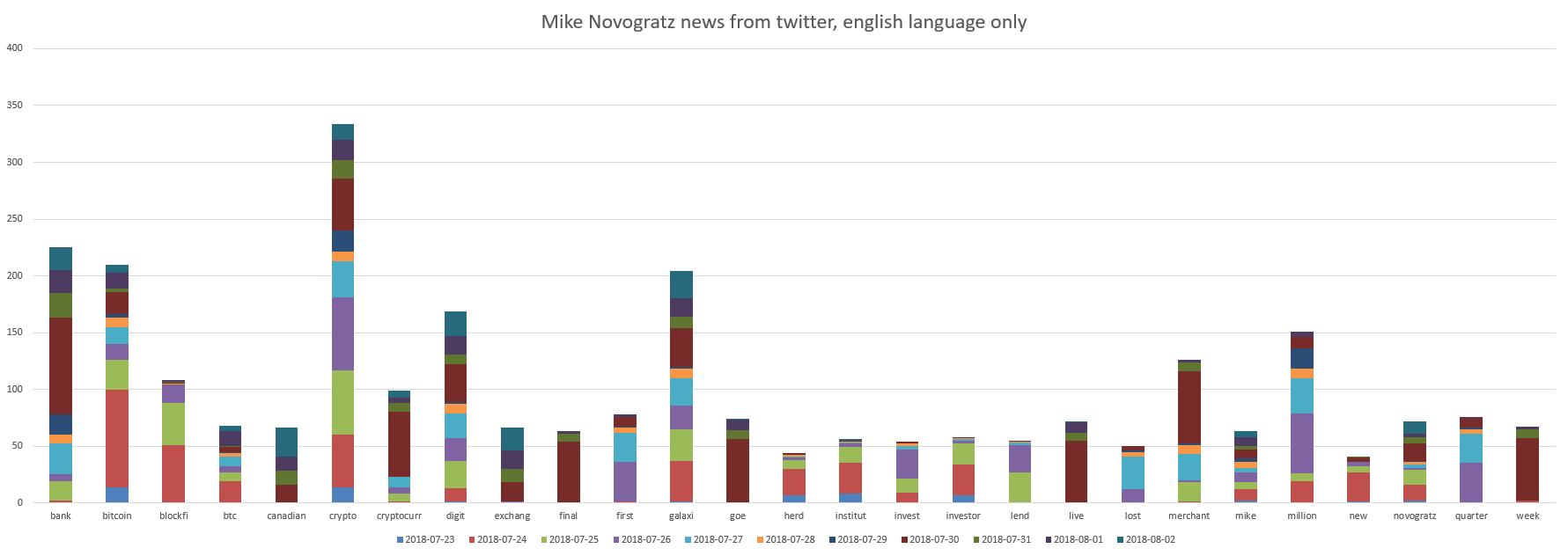
Se puede ver que Mike Novogratz está relacionado con "banco, bitcoin, criptografía, dígito, galaxia".
Los datos de X se pueden verter en una red neuronal y se puede aprender a determinar cualquier cosa, pero usted puede:
Análisis de datos
Y luego nos detenemos perder el tiempo Sea creativo y comience a usar la biblioteca Python TextBlob . La biblioteca es un milagro que bueno.
Las personas inteligentes dicen que ella puede:
- Frases destacadas
- hacer marcado parcial
- analizar estados de ánimo (esto nos es útil a continuación),
- hacer clasificación (ingenuo bayes, árbol de decisión),
- traducir y definir el idioma usando Google Translate,
- hacer tokenización (dividir el texto en palabras y oraciones),
- Identificar las frecuencias de palabras y frases,
- analizar
- detectar n-gramos
- do \ revelar inflexión \ declinación \ conjugación de palabras (pluralización y singularización) y lematización,
- ortografía correcta
La biblioteca le permite agregar nuevos modelos o idiomas a través de extensiones y tiene integración de WordNet. En una palabra, PNL es un niño prodigio .
Guardamos los resultados de búsqueda en el archivo results.xlsx anterior. Descárguelo y repáselo con la biblioteca TextBlob para fines de evaluación del estado de ánimo:
from textblob import TextBlob results = pd.read_excel('results.xlsx') polarity = 0 for i in range(0, len(results.index)): polarity += TextBlob(results['text'][i]).sentiment.polarity print(polarity/i)
Genial Un par de líneas de código y un resultado explosivo.
Resumen de resultados
Resulta que a principios de agosto de 2018, los tweets encontrados en la consulta "Le Minh Tam" muestran algo que se reflejó negativamente en los tweets con una calificación promedio de todos los tweets menos 0.13 . Si miramos los tweets en sí, entonces veremos, por ejemplo, "Se dice que el CEO de Crypto Mining desaparece con $ 35 millones en fondos. El CEO de Crypto Mining, Sky Minining, Le Minh Tam tiene r ...".
Y el amigo de Mike Novogratz hizo algo que se reflejó positivamente en los tweets con una calificación promedio de todos los tweets más 0.03 . Puedes interpretarlo para que todo avance con calma.
Plan de ataque
A los fines de la evaluación de la ICO, vale la pena monitorear la información sobre los fundadores de la ICO y sobre la misma desde varias fuentes. Por ejemplo:
Plan para monitorear una ICO:
- Cree una lista de los nombres de los fundadores de la ICO y la propia ICO,
- Creamos una lista de recursos para el monitoreo,
- Creamos un robot que recopila datos para cada fila de 1, para cada recurso de 2, el ejemplo anterior,
- Hacemos un robot que evalúa cada 3, el ejemplo anterior,
- Guarde los resultados 4 (y 3),
- Repita los pasos 3-5 cada hora, de manera automatizada, los resultados de la evaluación se pueden publicar / enviar / guardar en algún lugar,
- Monitoreamos automáticamente los saltos en la evaluación en el párrafo 6. Si hay saltos en la evaluación en el párrafo 6, esta es una ocasión para realizar un estudio adicional de lo que está sucediendo de manera experta. Y levanta el pánico, o viceversa, regocíjate.
Bueno, algo por el estilo.
PD: Bueno, o compre esta información, por ejemplo, aquí Thomsonreuters