Hoy hablaremos sobre DevOps, o más bien, principalmente sobre Ops. Dicen que hay muy pocas personas que estén satisfechas con el nivel de automatización de sus operaciones. Pero la situación parece ser reparable. En este artículo, Nikolai Ryzhikov hablará sobre su experiencia con la expansión de Kubernetes.

El material fue preparado sobre la base del discurso de Nikolai en la conferencia de otoño DevOops 2017. Bajo el corte: transcripción de video y texto del informe.
Actualmente, Nikolai Ryzhikov está trabajando en el sector de TI de Salud para crear sistemas de información médica. Miembro de la comunidad de programadores funcionales de San Petersburgo FPROG. Miembro activo de la comunidad Online Clojure, miembro del estándar de intercambio de información médica HL7 FHIR. Ha estado programando durante 15 años.
¿Qué lado tenemos para DevOps? Durante 10 años, nuestra fórmula DevOps ha sido bastante simple: los desarrolladores son responsables de las operaciones, los desarrolladores se implementan, los desarrolladores se mantienen. Con este arreglo, que se ve un poco duro, en cualquier caso, se convertirá en DevOps. Si desea implementar DevOps de forma rápida y dolorosa, haga que los desarrolladores sean responsables de su producción. Si los muchachos son inteligentes, comenzarán a salir y entender todo.

Nuestra historia: hace mucho tiempo, cuando no había Chef y automatización, ya implementamos Capistrano automático. Luego comenzaron a aburrirlo, para que él hiciera moda. Pero entonces apareció Chef. Nos cambiamos a él y nos fuimos a la nube: estábamos cansados de nuestros centros de datos. Entonces apareció Ansible, Docker se levantó. Después de eso, nos mudamos a Terraform con el supervisor de estibador de condominios escrito a mano en Camel. Y ahora nos estamos mudando a Kubernetes.

¿Qué es lo peor de las operaciones? Muy pocas personas están satisfechas con el nivel de automatización de sus operaciones. Esto es aterrador, confirmo: gastamos muchos recursos y esfuerzos para recolectar todas estas pilas para nosotros, y el resultado es insatisfactorio.
Existe la sensación de que con el advenimiento de Kubernetes, algo puede cambiar. Estoy comprometido con la fabricación ajustada y, desde su punto de vista, las operaciones generalmente no son útiles. Las operaciones ideales son la ausencia o el mínimo de operaciones en un proyecto. El valor se crea cuando un desarrollador hace un producto. Cuando está listo, la entrega no agrega valor. Pero necesita reducir costos.

Para mí, el ideal siempre fue heroku. Lo usamos para aplicaciones simples, donde el desarrollador para implementar su servicio, fue suficiente para decir git push y configurar heroku. Toma un minuto

Como ser Puedes comprar NoOps, también heroku. Y le aconsejo que compre, de lo contrario existe la posibilidad de gastar más dinero en el desarrollo de operaciones normales.
Hay muchachos Deis, están tratando de hacer algo como heroku en Kubernetes. Hay fundición en la nube, que también proporciona una plataforma en la que trabajar.

Pero si te molestas con algo más complejo o grande, puedes hacerlo tú mismo. Ahora, junto con Docker y Kubernetes, se convierte en una tarea que se puede completar en un tiempo razonable y a un costo razonable. Solía ser demasiado duro.

Un poco sobre Docker y Kubernetes
Uno de los problemas de las operaciones es la repetibilidad. La gran cosa que trajo el acoplador es de dos fases. Tenemos una fase de construcción.
El segundo punto que agrada en la ventana acoplable es una interfaz universal para lanzar servicios arbitrarios. Alguien ensambló Docker, colocó algo dentro y las operaciones son suficientes para decir que Docker corre y comienza.

¿Qué es kubernetes? Así que creamos Docker y necesitamos lanzarlo, integrarlo, configurarlo y conectarlo con otros en algún lugar. Kubernetes te permite hacer esto. Introduce una serie de abstracciones, que se denominan "recurso". Los revisaremos rápidamente e incluso intentaremos crear.
Abstracción
La primera abstracción es un POD o un conjunto de contenedores. Bien hecho, qué es exactamente un
conjunto de contenedores, y no uno. Los conjuntos pueden revolver entre ellos volúmenes que se ven a través de localhost. Esto le permite usar un patrón como el sidecar (esto es cuando lanzamos el contenedor principal, y hay contenedores auxiliares cercanos que lo ayudan).
Por ejemplo, el enfoque de embajador. Esto es cuando no desea que el contenedor piense dónde se encuentran algunos servicios. Pones un contenedor al lado que sabe dónde están estos servicios. Y están disponibles para el contenedor principal en localhost. Por lo tanto, el entorno comienza a parecer que está trabajando localmente.

Levantemos el POD y veamos cómo se describe. Localmente puedes desarrollar minikube. Consume un montón de CPU, pero le permite levantar un pequeño clúster de Kubernetes en una caja virtual y trabajar con él.
Implementemos POD. Dije que Kubernetes se aplicó e inundó el POD. Puedo ver qué POD tengo: veo que un POD está implementado. Esto significa que Kubernetes ha lanzado estos contenedores.
Incluso puedo entrar en este contenedor.
Desde esta perspectiva, Kubernetes está hecho para personas. De hecho, lo que hacemos constantemente en las operaciones, en el enlace de Kubernetes, por ejemplo, usando la utilidad kubectl, se puede hacer fácilmente.
Pero POD es mortal. Comienza como una ejecución de Docker: si alguien lo detiene, nadie lo levantará. Además de esta abstracción, Kubernetes comienza a construir lo siguiente, por ejemplo, un conjunto de réplicas. Este es un supervisor que monitorea los POD, monitorea su número, y si los POD caen, los levanta. Este es un importante concepto de autocuración en Kubernetes que le permite dormir tranquilo por la noche.
Sobre el conjunto de réplicas hay una abstracción de la implementación, también un recurso que le permite realizar una implementación de tiempo cero. Por ejemplo, un conjunto de réplicas funciona. Cuando implementamos y cambiamos la versión del contenedor, por ejemplo el nuestro, dentro de la implementación, se eleva otro conjunto de réplicas. Esperamos hasta que estos contenedores comiencen, pasamos por sus comprobaciones de estado y luego cambiamos rápidamente al nuevo conjunto de réplicas. También clásico y buenas prácticas.

Tomemos un servicio simple. Por ejemplo, tenemos una implementación. En el interior, describe el patrón de POD que recogerá. Podemos aplicar esta implementación, ver lo que tenemos. Buena característica de Kubernetes: todo se encuentra en la base de datos y podemos ver lo que sucede en el sistema.
Aquí vemos una implementación. Si tratamos de mirar los POD, vemos que algunos POD han aumentado. Podemos tomar y eliminar este POD. ¿Qué les sucede a los POD? Uno es destruido, y el segundo se levanta inmediatamente. Este controlador de réplica no encontró el POD deseado y lanzó otro.
Además, si se trata de algún tipo de servicio web, o dentro de nuestros servicios debe comunicarse, necesitamos un descubrimiento de servicio. Debe dar al servicio un nombre y un punto de entrada. Kubernetes ofrece un recurso llamado servicio para esto. Puede manejar el equilibrio de carga y ser responsable del descubrimiento del servicio.

Veamos un servicio simple. Lo conectamos con la implementación y los POD a través de etiquetas: un enlace tan dinámico. Un concepto muy importante en Kubernetes: el sistema es dinámico. No importa en qué orden se creará todo esto. El servicio intentará encontrar POD con tales etiquetas y comenzará su equilibrio de carga.
Aplica el servicio, mira qué servicios tenemos. Entramos en nuestro POD de prueba, que se planteó, y hacemos nslookup. Kubernetes nos proporciona un DNS-ku a través del cual los servicios pueden verse y descubrirse entre sí.
El servicio es más bien una interfaz. Hay varias implementaciones diferentes, porque las tareas de equilibrio de carga y servicio son bastante complicadas: de una manera, trabajamos con bases de datos ordinarias, en la otra con las cargadas, y algunas simples se hacen bastante simples. Este es también un concepto importante en Kubernetes: algunas cosas pueden llamarse interfaces en lugar de implementaciones. No están fijados rígidamente y son diferentes, por ejemplo, los proveedores de la nube ofrecen implementaciones diferentes. Es decir, por ejemplo, hay un volumen persistente de recursos, que ya está implementado en cada nube en particular por sus medios regulares.
A continuación, generalmente queremos sacar el servicio web. Kubernetes tiene una abstracción de entrada. Por lo general, se agrega SSL allí.

La entrada más simple se parece a esto. Allí escribimos las reglas: para qué URL, para qué hosts, a qué servicio interno redirigir la solicitud. Del mismo modo, podemos aumentar nuestra entrada.
Después de lo cual, habiéndose registrado localmente en los hosts, puede ver este servicio desde aquí.
Esta es una tarea tan regular: implementamos un determinado servicio web, nos reunimos un poco con Kubernetes.
Lo limpiaremos todo, eliminaremos el ingreso y veremos todos los recursos.
Hay una serie de recursos, como configmap y secret. Estos son recursos de información pura que puede montar en un contenedor y transferir allí, por ejemplo, la contraseña de postgres. Puede asociar esto con variables de entorno que se inyectarán en el contenedor al inicio. Puedes montar el sistema de archivos. Todo es bastante conveniente: tareas estándar, buenas soluciones.
Hay un volumen persistente, una interfaz que se implementa de manera diferente por diferentes proveedores de la nube. Se divide en dos partes: hay un reclamo de volumen persistente (solicitud), y luego se crea algo de EBS que se arrastra al contenedor. Puede trabajar con un servicio con estado.

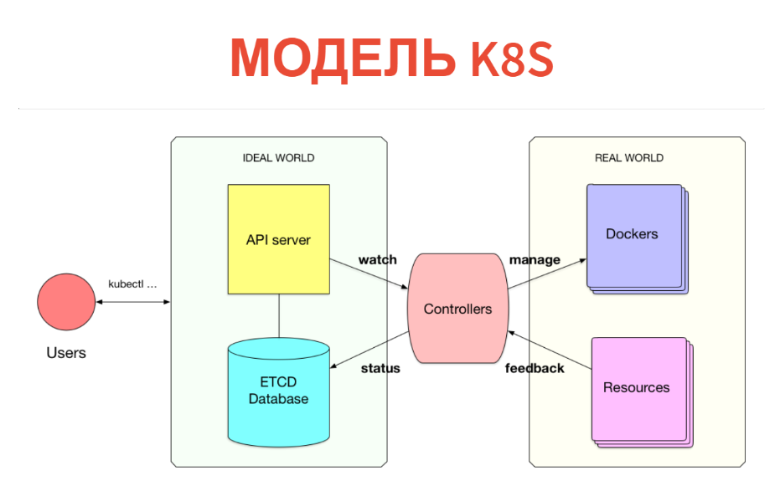
¿Pero cómo funciona adentro? El concepto en sí es muy simple y transparente. Kubernetes tiene dos partes. Una es solo una base de datos en la que tenemos todos estos recursos. Los recursos pueden considerarse tabletas: específicamente, estas instancias son simplemente registros en tabletas. Además de Kubernetes, se configura un servidor API. Es decir, cuando tiene un clúster de Kubernetes, generalmente se comunica con el servidor API (más precisamente, el cliente se comunica con él).
En consecuencia, lo que creamos (POD, servicios, etc.) simplemente se escribe en la base de datos. ETCD implementa esta base de datos, es decir para que sea estable en el nivel de alta disponibilidad.
¿Qué viene después? Además, debajo de cada tipo de recursos hay un cierto controlador. Este es solo un servicio que monitorea su tipo de recurso y hace algo en el mundo exterior. Por ejemplo, se ejecuta un Docker. Si tenemos POD, para cada nodo hay un servicio de kubelet que monitorea los POD que están conectados a este nodo. Y todo lo que hace es ejecutar Docker después de la próxima verificación periódica si este POD no está allí.
Además, lo cual es muy importante: todo sucede en tiempo real, por lo que la potencia de este controlador es superior al mínimo. A menudo, el controlador aún toma las métricas y mira lo que comenzó. Es decir elimina los comentarios del mundo real y los escribe en la base de datos, para que usted u otros controladores puedan verlos. Por ejemplo, el mismo estado de POD se volverá a escribir en ETCD.
Por lo tanto, todo se implementa en Kubernetes. Es genial que el modelo de información esté separado de la sala de operaciones. En la base de datos a través de la interfaz CRUD habitual, declaramos lo que debería ser. Entonces el conjunto de controladores intenta hacer que todo esté bien. Es cierto que esto no siempre sucede.
Este es un modelo cibernético. Tenemos un cierto preajuste, hay algún tipo de máquina que está tratando de dirigir el mundo real o la máquina al lugar que se necesita. No siempre sucede de esta manera: deberíamos tener un ciclo de retroalimentación. A veces una máquina no puede hacer esto y debe recurrir a una persona.
En los sistemas reales, pensamos en abstracciones del siguiente nivel: tenemos algunos servicios, bases de datos y todos lo conectamos. No pensamos en PODs e Ingresss, y queremos construir un próximo nivel de abstracción.

Para que el desarrollador fuera lo más fácil posible: para que simplemente dijera: "Quiero comenzar tal o cual servicio", y todo lo demás sucedió en el interior.
Existe tal cosa como HELM. Esta es la manera incorrecta: plantillas de estilo ansible, donde solo estamos tratando de generar un conjunto de recursos configurados y colocarlos en un clúster de Kubernetes.
El problema, en primer lugar, es que esto solo se hace en el momento del rodaje. Es decir, no puede implementar mucha lógica. En segundo lugar, en tiempo de ejecución esta abstracción desaparece. Cuando voy a mirar mi clúster, solo veo POD y servicios. No veo que tal y tal servicio se implemente, que tal y tal base con replicación se plantee allí. Acabo de ver docenas de hogares allí. La abstracción desaparece como en una matriz.

Modelo de solución interna
Por otro lado, Kubernetes ya proporciona un modelo de extensión muy interesante y simple en su interior. Podemos declarar nuevos tipos de recursos, por ejemplo, implementación. Este es un recurso creado sobre POD o conjunto de réplicas. Podemos escribir un controlador en este recurso, poner este recurso en la base de datos y ejecutar nuestro bucle cibernético para que todo funcione. Esto suena interesante, y me parece que esta es la forma correcta de extender Kubernetes.

Me gustaría poder escribir un manifiesto para mi servicio de estilo heroku. Un ejemplo muy simple: quiero implementar algún tipo de aplicación en mi entorno real. Ya tiene acuerdos, SSL, dominios comprados. Solo me gustaría darles a los desarrolladores la interfaz más simple posible. El manifiesto me dice qué contenedor levantar, qué recursos aún necesita este contenedor. Lanza este anuncio al clúster y todo comienza a funcionar.

¿Cómo se verá esto en términos de recursos y controladores personalizados? Aquí tendremos una aplicación de recursos en la base de datos. Y el controlador de la aplicación generará tres recursos. Es decir, escribirá las reglas al ingresar sobre cómo dirigirse a este servicio, comenzará el servicio para el equilibrio de carga y lanzará la implementación con algún tipo de configuración.
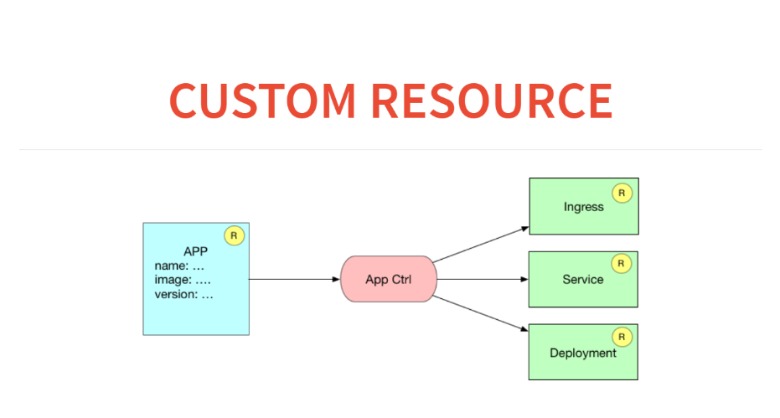
Antes de crear un recurso personalizado en Kubernetes, debemos declararlo. Para esto, hay un meta recurso llamado CustomResourceDefinition.
Para declarar un nuevo recurso en Kubernetes, es suficiente para nosotros publicar dicho anuncio. Considere esta tabla de creación.
Creó una mesa. Después de eso, podemos mirar a través del kubectl obtener esos recursos de terceros que tenemos. Tan pronto como lo anunciamos, también recibimos un banner. Podemos hacer, por ejemplo, kubeclt obtener aplicaciones. Pero hasta ahora no hay aplicación.
Escribamos alguna aplicación. Después de eso, podemos hacer una instancia de recurso personalizada. Miremos en YAML y creémoslo publicando en una URL específica.
Si corremos y miramos a través de kubectl, aparece una aplicación. Pero aunque no pasa nada, simplemente se encuentra en la base de datos. Puede, por ejemplo, tomar y solicitar todos los recursos de la aplicación.
Podemos crear un segundo recurso a partir de la misma plantilla simplemente cambiando el nombre. Aquí está el segundo recurso.
Además, nuestro controlador debe hacer plantillas, similar a lo que hace HELM. Es decir, después de recibir una descripción de nuestra aplicación, debo generar una implementación de recursos y un servicio de recursos, así como hacer una entrada en el ingreso. Esta es la parte más fácil: aquí en clojure está erlmacro. Paso la estructura de datos, tira de la función de implementación, pasa a depurar, que es la tubería. Y esta es una función pura: plantillas simples. En consecuencia, en la forma más ingenua, pude crearlo de inmediato, convertirlo en una utilidad de consola y comenzar a distribuirlo.
Hacemos lo mismo para el servicio: la función de servicio acepta la declaración y genera el recurso de Kubernetes para nosotros.
Hacemos lo mismo para la línea de entrada.
¿Cómo funcionará todo esto? Habrá algo en el mundo real y habrá lo que queramos. Lo que queremos: tomamos el recurso de la aplicación y generamos en él lo que debería ser. Y ahora necesitamos ver qué es. Lo que solicitamos a través de la API REST. Podemos obtener todos los servicios, todas las implementaciones.
¿Cómo funcionará nuestro controlador personalizado? Recibirá lo que queremos y lo que es, tomar de este div y aplicar a Kubernetes. Esto es similar a Reaccionar. Se me ocurrió un DOM virtual cuando algunas funciones simplemente generan un árbol de objetos JS. Y luego un cierto algoritmo calcula el parche y lo aplica al DOM real.
Haremos lo mismo aquí. Esto se hace en 50 líneas de código. Quiero, todo está en Github. Al final, deberíamos obtener la función de reconciliar acciones.
Tenemos una función de acciones de reconciliación que no hace nada y solo calcula este div. Ella toma lo que es, más lo que se necesita. Y luego da lo que hay que hacer para llevar el primero al segundo.
Vamos a tirar de ella. No hay nada malo en ella; puede ser debatida. Ella dice que necesita crear un servicio de ingreso, hacer dos entradas en él, crear una implementación 1 y 2, crear un servicio 1 y 2.
En este caso, ya debería haber un solo servicio. Vemos por ingreso que solo queda una entrada.
Entonces todo lo que queda es escribir una función que aplique este parche al clúster de Kubernetes. Para hacer esto, simplemente pasamos las acciones de reconciliación a la función de reconciliación, y todo se aplicará. Y ahora vemos que el POD ha aumentado, la implementación se ha convertido y el servicio ha comenzado.
Agreguemos otro servicio: ejecute la función reconciliar-acciones nuevamente. Veamos que pasó. Todo comenzó, todo está bien.
¿Cómo lidiar con esto? Empacamos todo esto en un contenedor Docker. Después de eso, escribimos una función que periódicamente se despierta, se reconcilia y se duerme. La velocidad no es muy importante, puede dormir durante cinco segundos y realizar acciones de reconciliación con poca frecuencia.
Nuestro controlador personalizado es solo un servicio que se activará y calculará periódicamente el parche.
Ahora tenemos dos servicios zaddeloino, eliminemos una de las aplicaciones. Veamos cómo reaccionó nuestro clúster: todo está bien. Eliminamos el segundo: todo se borra.
Veamos a través de los ojos del desarrollador. Solo necesita decir que Kubernetes se postula y nombra el nuevo servicio. Hacemos esto, nuestro controlador recogió todo y lo creó.
Luego recopilamos todo esto en un servicio de implementación y lanzamos este controlador personalizado al clúster utilizando las herramientas estándar de Kubernetes. Creamos una abstracción para 200 líneas de código.
Todo se parece a HELM, pero en realidad es más poderoso. El controlador funciona en un clúster: ve la base, ve el mundo exterior y puede ser lo suficientemente inteligente.
CI propio
Considere los ejemplos de extensión de Kubernetes. Decidimos que CI debería ser parte de la infraestructura. Esto es bueno, es conveniente desde el punto de vista de la seguridad: un repositorio privado. Intentamos usar jenkins, pero es una herramienta obsoleta. Quería un hacker CI.
No necesitamos interfaces, nos encantan los ChatOps: déjenos decir en el chat si la compilación se ha caído o no. Además, quería depurar todo localmente. Nos sentamos y escribimos nuestro CI en una semana. Solo como una extensión de Kubernetes. Si piensa en CI, entonces esta es solo una herramienta que ejecuta algún tipo de trabajo. Como parte de este trabajo, creamos algo, ejecutamos pruebas y, a menudo, lo implementamos.¿Cómo funciona todo? Se basa en el mismo concepto de controladores personalizados. Primero, colocamos en Kubernetes una descripción de los repositorios que estamos siguiendo. El controlador solo va a github y agrega web-hook. Todavía tenemos introspección.Luego viene web-hook, cuya única tarea es procesar el JSON entrante y soltarlo en un recurso de compilación personalizado, que también se suma a la base de datos de Kubernetes. El controlador de compilación supervisa el recurso de compilación, que lee el manifiesto dentro del proyecto y lanza el POD. En este POD, se lanzan todos los servicios necesarios.En POD, un agente muy simple que lee una declaración al estilo de travis o circleci, y en YAML un conjunto de pasos. Él comienza a cumplirlos. Luego, al final de la construcción, arroja su resultado en Telegram.Otra característica que obtuvimos con Kubernetes es que uno de los comandos en la ejecución de su CI o entrega continua se puede configurar simplemente mientras duerme verdadero 10, y su POD se congelará en este paso. Haces kubectl exec, te encuentras dentro de tu build y puedes debutar.Otra característica: todo está construido en las ventanas acoplables y puede depurar el script localmente iniciando la ventana acoplable. Todo tomó dos semanas y 300 líneas de código.
Nos sentamos y escribimos nuestro CI en una semana. Solo como una extensión de Kubernetes. Si piensa en CI, entonces esta es solo una herramienta que ejecuta algún tipo de trabajo. Como parte de este trabajo, creamos algo, ejecutamos pruebas y, a menudo, lo implementamos.¿Cómo funciona todo? Se basa en el mismo concepto de controladores personalizados. Primero, colocamos en Kubernetes una descripción de los repositorios que estamos siguiendo. El controlador solo va a github y agrega web-hook. Todavía tenemos introspección.Luego viene web-hook, cuya única tarea es procesar el JSON entrante y soltarlo en un recurso de compilación personalizado, que también se suma a la base de datos de Kubernetes. El controlador de compilación supervisa el recurso de compilación, que lee el manifiesto dentro del proyecto y lanza el POD. En este POD, se lanzan todos los servicios necesarios.En POD, un agente muy simple que lee una declaración al estilo de travis o circleci, y en YAML un conjunto de pasos. Él comienza a cumplirlos. Luego, al final de la construcción, arroja su resultado en Telegram.Otra característica que obtuvimos con Kubernetes es que uno de los comandos en la ejecución de su CI o entrega continua se puede configurar simplemente mientras duerme verdadero 10, y su POD se congelará en este paso. Haces kubectl exec, te encuentras dentro de tu build y puedes debutar.Otra característica: todo está construido en las ventanas acoplables y puede depurar el script localmente iniciando la ventana acoplable. Todo tomó dos semanas y 300 líneas de código.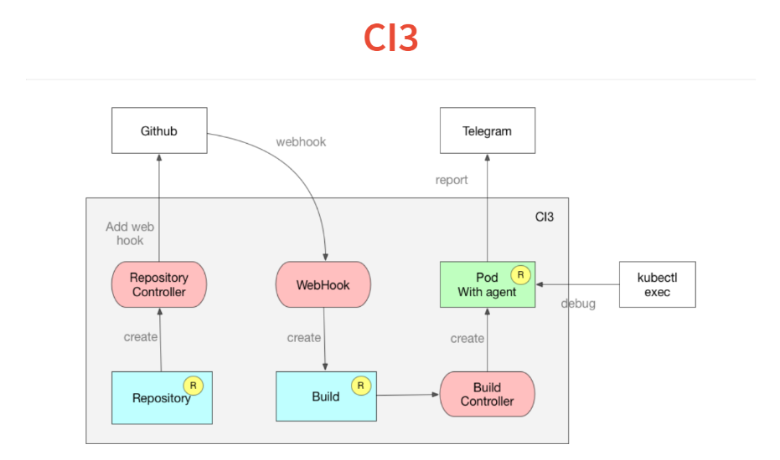
Trabaja con postgres
Nuestro producto está construido sobre postgres, utilizamos todo tipo de características interesantes. Incluso escribimos una serie de extensiones. Pero no podemos usar RDS ni nada más.Ahora estamos en el proceso de desarrollar un operador para un postgres indestructible. Voy a sonar arquitectura. Quiero decir: "Cluster, dame un postgres que no pueda ser asesinado". Agregue a esto que necesito dos réplicas asíncronas, una sincrónica, copias de seguridad diarias y hasta un terabyte. Lo tiro todo, luego mi controlador de clúster comienza a hacer orquestación y expandir mi contenedor. Crea recursos de instancia que son responsables de cada postgreso de istance. Esto será postgres de clúster.Más controlador de pginstance, bastante simple, solo tratando de ejecutar POD o implementación allí con este postgres. El corazón es volumen persistente. Toda esta máquina toma el control total de postgres. Le das un contenedor Docker, que solo tiene postgres binarios. Todo lo demás: el controlador mismo realiza la configuración y creación del clúster de inicio de postgres. Hace esto para que podamos reconfigurarlo más tarde, y para que pueda configurar la replicación, los niveles de registro, etc. Al principio, el POD temporal se ejecuta sobre el volumen persistente y crea un clúster de postgres para el maestro allí.A continuación, además de esto, la implementación comienza con master. Luego se crea un volumen persistente de la misma manera. Otro POD pasa, realiza una copia de seguridad básica, lo extrae y, además, la implementación comienza con un esclavo.A continuación, el controlador del clúster crea un recurso de respaldo (después de que se haya descrito con los respaldos). Y el controlador de respaldo ya lo toma y lo arroja a algún S3.
Que sigue
Permítanos presentarle el futuro cercano con usted. Puede suceder que tarde o temprano tengamos recursos personalizados tan interesantes, controladores personalizados que diré "Dame postgres, dame kafka, déjame CI y comienza todo". Todo será simple.Si no estamos hablando del futuro cercano, entonces yo, como programador declarativo, creo que solo la programación lógica o relacional es más alta que la programación funcional. Allí, nuestra semántica de operaciones está completamente separada de la semántica de información. Si observamos de cerca nuestros controladores personalizados que teníamos, entonces tenemos, por ejemplo, una aplicación de recursos en nuestra base de datos. Y derivamos de ello tres recursos adicionales más. Esto es muy similar a la vista de la base de datos. Este es un hallazgo de hechos. Esta es una vista lógica o de relación.El siguiente paso para Kubernetes es dar una cierta ilusión de una base relacional o lógica en lugar de una API REST cortada, donde simplemente puede escribir una regla. Como tarde o temprano todo se acumula en la base de datos, incluidos los comentarios, las reglas pueden sonar así: "Si la carga ha aumentado así, entonces aumente la replicación de esa manera". Tendremos una pequeña sql o regla lógica. Todo lo que necesitas es un motor genérico que seguirá esto. Pero este es un futuro brillante.
— DevOops 2018 ! — .
«The DevOps Handbook» , «Learning Chef: A Guide to Configuration Management and Automation» , «How to containerize your Go code» «Liquid Software: How to Achieve Trusted Continuous Updates in the DevOps World» — . - .
: !
: 1 Puede reservar un boleto para DevOops 2018 con un descuento.