Parecería que el tema está trillado: se ha dicho y escrito mucho sobre el respaldo, por lo que no hay nada que reinventar la rueda, solo tómalo y hazlo. Sin embargo, cada vez que el administrador del sistema de un proyecto web se enfrenta a la tarea de configurar copias de seguridad, para muchos queda suspendido en el aire con un gran signo de interrogación. ¿Cómo recopilar la copia de seguridad de datos correctamente? ¿Dónde almacenar las copias de seguridad? ¿Cómo proporcionar el nivel necesario de almacenamiento retrospectivo de copias? ¿Cómo unificar el proceso de copia de seguridad para todo el zoológico de varios software?

Por nosotros mismos, resolvimos este problema por primera vez en 2011. Luego nos sentamos y escribimos nuestros scripts de respaldo. A lo largo de los años, solo los utilizamos, y proporcionaron con éxito un proceso confiable para recopilar y sincronizar copias de seguridad de proyectos web de nuestros clientes. Las copias de seguridad se almacenaron en nuestro almacenamiento externo o en otro, con la posibilidad de realizar un ajuste para un proyecto específico.
Debo decir que estos guiones funcionaron al máximo. Pero cuanto más crecíamos, más teníamos diversos proyectos con diferentes softwares y repositorios externos que nuestros scripts no admitían. Por ejemplo, no teníamos soporte para Redis y las copias de seguridad de MySQL y PostgreSQL que aparecieron más tarde. El proceso de copia de seguridad no fue monitoreado, solo hubo alertas por correo electrónico.
Otro problema fue el proceso de soporte. Con los años, nuestros scripts que alguna vez fueron compactos han crecido y se han convertido en un enorme monstruo incómodo. Y cuando nos reunimos y lanzamos una nueva versión, valió la pena desplegar la actualización para esa parte de los clientes que usaban la versión anterior con algún tipo de personalización.
Como resultado, a principios de este año, tomamos una decisión decidida: reemplazar nuestros viejos scripts de respaldo con algo más moderno. Por lo tanto, al principio nos sentamos y escribimos toda la lista de deseos para una nueva solución. Resultó aproximadamente lo siguiente:
- Haga una copia de seguridad de los datos del software utilizado con más frecuencia:
- Archivos (copia discreta e incremental)
- MySQL (copias de seguridad en frío / en caliente)
- PostgreSQL (copias de seguridad en frío / en caliente)
- Mongodb
- Redis
- Almacene copias de seguridad en repositorios populares:
- Local
- FTP
- Ssh
- SMB
- Nfs
- Webdav
- S3
- Reciba alertas en caso de cualquier problema durante el proceso de respaldo
- Tenga un único archivo de configuración que le permita administrar las copias de seguridad de forma centralizada
- Agregue soporte para nuevo software conectando módulos externos
- Especificar opciones adicionales para recolectar volcados
- Tener la capacidad de restaurar copias de seguridad por medios regulares
- Fácil configuración inicial
Analizamos las soluciones disponibles.
Analizamos las soluciones de código abierto que ya existen:
- Bacula y sus tenedores, por ejemplo, Bareos
- Amanda
- Borg
- Duplicidad
- Duplicidad
- Rsnapshot
- Rdiff-backup
Pero cada uno de ellos tenía sus inconvenientes. Por ejemplo, Bacula está sobrecargado con funciones que no necesitamos, la configuración inicial es una tarea bastante laboriosa debido a la gran cantidad de trabajo manual (por ejemplo, para escribir / buscar scripts de copia de seguridad de la base de datos), y para recuperar copias es necesario utilizar utilidades especiales, etc.
Al final, llegamos a dos conclusiones importantes:
- Ninguna de las soluciones existentes nos satisfizo completamente;
- Parece que nosotros mismos teníamos suficiente experiencia y locura para comenzar a escribir nuestra decisión.
Entonces lo hicimos.
El nacimiento de nxs-backup
Python fue elegido como el lenguaje para la implementación: es fácil de escribir y mantener, flexible y conveniente. Se decidió describir los archivos de configuración en formato yaml.
Para la comodidad de admitir y agregar copias de seguridad del nuevo software, se eligió una arquitectura modular donde el proceso de recopilación de copias de seguridad de cada software específico (por ejemplo, MySQL) se describe en un módulo separado.
Soporte para archivos, bases de datos y almacenamiento remoto.
Actualmente, se admiten los siguientes tipos de copias de seguridad de archivos, bases de datos y repositorios remotos:
DB:
- MySQL (copias de seguridad en caliente / en frío)
- PostgreSQL (copias de seguridad en caliente / en frío)
- Redis
- Mongodb
Archivos:
- Copia discreta
- Copia incremental
Repositorios remotos:
- Local
- S3
- SMB
- Nfs
- FTP
- Ssh
- Webdav
Copia de seguridad discreta
Para diferentes tareas, las copias de seguridad discretas o incrementales son adecuadas, por lo tanto, implementaron ambos tipos. Puede especificar qué método usar a nivel de archivos y directorios individuales.
Para copias discretas (archivos y bases de datos), puede establecer una retrospectiva en el formato de días / semanas / meses.
Copia de seguridad incremental
Las copias incrementales de los archivos se realizan de la siguiente manera:
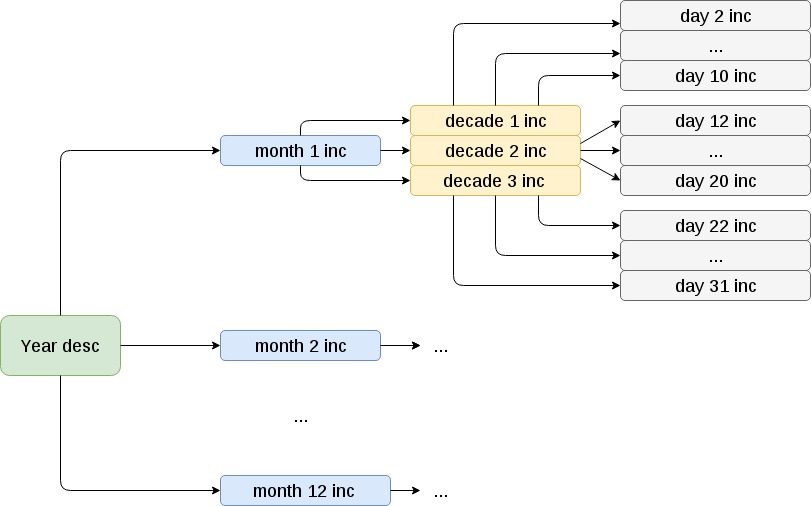
A principios de año, se realizará una copia de seguridad completa. A continuación, al comienzo de cada mes, una copia mensual incremental en relación con la anual. Dentro de la menstruación: decenal incremental en relación con el mensual. Dentro de cada día incremental de diez días en relación con el período de diez días.
Cabe señalar que si bien existen algunos problemas al trabajar con directorios que contienen una gran cantidad de subdirectorios (decenas de miles). En tales casos, la recopilación de copias se ralentiza significativamente y puede llevar más de un día. Estamos abordando activamente esta deficiencia.
Nos recuperamos de las copias de seguridad incrementales
No hay problemas con la recuperación de copias de seguridad discretas: solo tome una copia para la fecha requerida e impleméntela con el tar habitual de la consola. Las copias incrementales son un poco más complicadas. Para recuperarse, por ejemplo, el 24 de julio de 2018, debe hacer lo siguiente:
- Expanda una copia de seguridad de un año, incluso si en nuestro caso comienza desde el 1 de enero de 2018 (en la práctica, puede ser cualquier fecha, dependiendo de cuándo se decidió implementar copias de seguridad incrementales)
- Tira sobre él un respaldo mensual para julio
- Enrollar el respaldo de la década del 21 de julio
- Roll up backup diario para el 24 de julio
Al mismo tiempo, para realizar 2-4 puntos, debe agregar el interruptor -G al comando tar, lo que indica que se trata de una copia de seguridad incremental. Por supuesto, este no es el proceso más rápido, pero cuando considera que a menudo no es necesario recuperarse de las copias de seguridad y la rentabilidad es importante, tal esquema resulta ser bastante efectivo.
Excepciones
A menudo, debe excluir archivos o directorios individuales de las copias de seguridad, por ejemplo, directorios con caché. Esto se puede hacer especificando las reglas de excepción apropiadas:
ejemplo de archivo de configuración- target: - /var/www/*/data/ excludes: - exclude1/exclude_file - exclude2 - /var/www/exclude_3
Rotación de respaldo
En nuestras antiguas secuencias de comandos, la rotación se implementaba para que la copia anterior se eliminara solo después de que la nueva se ensamblara correctamente. Esto llevó a problemas en proyectos en los que el espacio para copias de seguridad, en principio, se asignó exactamente para una copia; no se pudo recopilar una copia nueva allí debido a la falta de espacio.
En la nueva implementación, decidimos cambiar este enfoque: primero elimine el anterior y solo luego recopile una nueva copia. Y el proceso de recopilación de copias de seguridad debe ser monitoreado para descubrir cualquier problema.
Para las copias de seguridad discretas, un archivo se considera una copia antigua que va más allá del esquema de almacenamiento especificado en el formato de días / semanas / meses. En el caso de las copias de seguridad incrementales, las copias de seguridad se almacenan de forma predeterminada durante un año, y las copias antiguas se eliminan al comienzo de cada mes, mientras que los archivos del mismo mes del año pasado se consideran copias de seguridad antiguas. Por ejemplo, antes de recopilar una copia de seguridad mensual el 1 de agosto de 2018, el sistema verificará si hay copias de seguridad para agosto de 2017 y, de ser así, las eliminará. Esto permite un uso óptimo del espacio en disco.
Registro
En cualquier proceso, y especialmente en las copias de seguridad, es importante mantenerse al día y saber si algo salió mal. El sistema mantiene un registro de su trabajo y captura el resultado de cada paso: inicio / detención de fondos, inicio / finalización de una tarea específica, el resultado de recopilar una copia en un directorio temporal, el resultado de copiar / mover una copia de un directorio temporal a una ubicación permanente, el resultado de la rotación de respaldo, etc. ..
Los eventos se dividen en 2 niveles:
- Información : nivel de información: el vuelo es normal, la siguiente etapa se completó con éxito, se ingresa la información correspondiente en el registro
- Error : nivel de error: algo salió mal, la siguiente etapa falló, se realiza un registro de error correspondiente en el registro
Notificaciones por correo electrónico
Al final de la recopilación de copias de seguridad, el sistema puede enviar notificaciones por correo electrónico.
Se admiten 2 listas de destinatarios:
- Los administradores son aquellos que sirven al servidor. Solo reciben notificaciones de errores; no están interesados en notificaciones de operaciones exitosas
- Usuarios comerciales : en nuestro caso, estos son clientes que a veces desean recibir notificaciones para asegurarse de que todo esté bien con las copias de seguridad. O, por el contrario, no realmente. Pueden elegir recibir un registro completo o solo un registro con errores.
Estructura del archivo de configuración
La estructura de los archivos de configuración es la siguiente:
ejemplo de estructura /etc/nxs-backup ├── conf.d │ ├── desc_files_local.conf │ ├── external_clickhouse_local.conf │ ├── inc_files_smb.conf │ ├── mongodb_nfs.conf │ ├── mysql_s3.conf │ ├── mysql_xtradb_scp.conf │ ├── postgresql_ftp.conf │ ├── postgresql_hot_webdav.conf │ └── redis_local_ftp.conf └── nxs-backup.conf
Aquí /etc/nxs-backup/nxs-backup.conf es el archivo de configuración principal en el que se indican las configuraciones globales:
archivo de configuración main: server_name: SERVER_NAME admin_mail: project-tech@nixys.ru client_mail: - '' mail_from: backup@domain.ru level_message: error block_io_read: '' block_io_write: '' blkio_weight: '' general_path_to_all_tmp_dir: /var/nxs-backup cpu_shares: '' log_file_name: /var/log/nxs-backup/nxs-backup.log jobs: !include [conf.d
La matriz de tareas (trabajos) contiene una lista de tareas (trabajos), que son una descripción de qué exactamente respaldar, dónde almacenar y en qué cantidad. Como regla general, se mueven a archivos separados (un archivo por trabajo), que se conectan mediante incluir en el archivo de configuración principal.
También se encargaron de optimizar el proceso de preparación de estos archivos tanto como sea posible y escribieron un generador simple. Por lo tanto, el administrador no necesita pasar tiempo buscando la plantilla de configuración para algún servicio, por ejemplo, MySQL, sino simplemente ejecutar el comando:
nxs-backup generate --storage local scp --type mysql --path /etc/nxs-backup/conf.d/mysql_local_scp.conf
La salida genera el archivo /etc/nxs-backup/conf.d/mysql_local_scp.conf :
Contenido del archivo - job: PROJECT-mysql type: mysql tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp sources: - connect: db_host: '' db_port: '' socket: '' db_user: '' db_password: '' auth_file: '' target: - all excludes: - information_schema - performance_schema - mysql - sys gzip: no is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' storages: - storage: local enable: yes backup_dir: /var/nxs-backup/databases/mysql/dump store: days: '' weeks: '' month: '' - storage: scp enable: yes backup_dir: /var/nxs-backup/databases/mysql/dump user: '' host: '' port: '' password: '' path_to_key: '' store: days: '' weeks: '' month: ''
En el que solo queda sustituir algunos valores necesarios.
Tomemos un ejemplo. Supongamos que en nuestro servidor en el directorio / var / www hay dos sitios de la tienda en línea 1C-Bitrix (bitrix-1.ru, bitrix-2.ru), cada uno de los cuales funciona con su propia base de datos en diferentes instancias de MySQL (puerto 3306 para bitrix_1_db y puerto 3307 para bitrix_2_db).
La estructura de archivos de un proyecto típico de Bitrix es aproximadamente la siguiente:
├── ... ├── bitrix │ ├── .. │ ├── admin │ ├── backup │ ├── cache │ ├── .. │ ├── managed_cache │ ├── .. │ ├── stack_cache │ └── .. ├── upload └── ...
Como regla general, el directorio de carga pesa mucho y solo crece con el tiempo, por lo que se realizará una copia de seguridad incremental. Todos los demás directorios son discretos, con la excepción de los directorios con caché y copias de seguridad recopilados por herramientas nativas de Bitrix. Deje que el esquema de almacenamiento de respaldo para estos dos sitios sea el mismo, mientras que las copias de los archivos deben almacenarse localmente y en el almacenamiento remoto de ftp, y la base de datos debe almacenarse solo en el almacenamiento remoto de smb.
Los archivos de configuración resultantes para tal configuración se verán así:
bitrix-desc-files.conf (archivo de configuración con descripción del trabajo para copia de seguridad discreta) - job: Bitrix-desc-files type: desc_files tmp_dir: /var/nxs-backup/files/desc/dump_tmp sources: - target: - /var/www/*/ excludes: - bitrix/backup - bitrix/cache - bitrix/managed_cache - bitrix/stack_cache - upload gzip: yes storages: - storage: local enable: yes backup_dir: /var/nxs-backup/files/desc/dump store: days: 6 weeks: 4 month: 6 - storage: ftp enable: yes backup_dir: /nxs-backup/databases/mysql/dump host: ftp_host user: ftp_usr password: ftp_usr_pass store: days: 6 weeks: 4 month: 6
bitrix-inc-files.conf (archivo de configuración con descripción del trabajo para copia de seguridad incremental) - job: Bitrix-inc-files type: inc_files sources: - target: - /var/www/*/upload/ gzip: yes storages: - storage: ftp enable: yes backup_dir: /nxs-backup/files/inc host: ftp_host user: ftp_usr password: ftp_usr_pass - storage: local enable: yes backup_dir: /var/nxs-backup/files/inc
bitrix-mysql.conf (archivo de configuración con descripción del trabajo para copias de seguridad de MySQL) - job: Bitrix-mysql type: mysql tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp sources: - connect: db_host: localhost db_port: 3306 db_user: bitrux_usr_1 db_password: password_1 target: - bitrix_1_db excludes: - information_schema - performance_schema - mysql - sys gzip: no is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' - connect: db_host: localhost db_port: 3307 db_user: bitrix_usr_2 db_password: password_2 target: - bitrix_2_db excludes: - information_schema - performance_schema - mysql - sys gzip: yes is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' storages: - storage: smb enable: yes backup_dir: /nxs-backup/databases/mysql/dump host: smb_host port: smb_port share: smb_share_name user: smb_usr password: smb_usr_pass store: days: 6 weeks: 4 month: 6
Opciones para comenzar a recopilar copias de seguridad
En el ejemplo anterior, preparamos archivos de configuración de trabajo para recopilar copias de seguridad de todos los elementos a la vez: archivos (discretos e incrementales), dos bases de datos y almacenarlos en almacenes locales y externos (ftp, smb).
Queda por ejecutar todo el asunto. El lanzamiento se realiza mediante el comando
nxs-backup start $JOB_NAME -c $PATH_TO_MAIN_CONFIG
Hay varios nombres de trabajo reservados:
- archivos : ejecución arbitraria de todos los trabajos con tipos desc_files , inc_files (es decir, en esencia, solo se respaldan los archivos)
- bases de datos : ejecución aleatoria de todos los trabajos con los tipos mysql , mysql_xtradb , postgresql , postgresql_hot , mongodb , redis (es decir , respalde solo la base de datos)
- externo : ejecutar aleatoriamente todos los trabajos con el tipo externo (ejecutando solo scripts personalizados adicionales, más sobre esto a continuación)
- all : imitación de ejecutar el comando uno por uno con archivos de trabajo, bases de datos , externos (valor predeterminado)
Dado que necesitamos obtener copias de seguridad de los datos de ambos archivos y la base de datos al mismo tiempo (o con una diferencia mínima) en la salida, se recomienda ejecutar nxs-backup con el trabajo all , lo que garantizará la ejecución coherente del trabajo descrito (Bitrix-desc- archivos, Bitrix-inc_files, Bitrix-mysql).
Es decir, un punto importante: las copias de seguridad no se recopilarán en paralelo, sino de forma secuencial, una tras otra, con una diferencia de tiempo mínima. Además, en el próximo inicio, el software mismo verifica el proceso que ya se está ejecutando en el sistema y, si se detecta, finalizará automáticamente su trabajo con la marca correspondiente en el registro. Este enfoque reduce significativamente la carga en el sistema. Menos: las copias de seguridad de elementos individuales se recopilan no de una vez, sino con alguna diferencia horaria. Pero mientras nuestra práctica muestra que esto no es crítico.
Módulos externos
Como se mencionó anteriormente, gracias a la arquitectura modular, las capacidades del sistema se pueden ampliar utilizando módulos de usuario adicionales que interactúan con el sistema a través de una interfaz especial. El objetivo es poder agregar en el futuro soporte para copias de seguridad de software nuevo sin la necesidad de reescribir nxs-backup.
ejemplo de archivo de configuración - job: TEST-external type: external dump_cmd: '' storages: ….
Se debe prestar especial atención a la clave dump_cmd , donde el valor es el comando completo para ejecutar un script externo. Además, al completar este comando, se espera que:
- Se recopilará un archivo de datos de software listo para usar.
- Los datos se enviarán a stdout en formato json, de la forma:
{ "full_path": "ABS_PATH_TO_ARCHIVE", "basename": "BASENAME_ARCHIVE", "extension": "EXTERNSION_OF_ARCHIVE", "gzip": true/false }
- En este caso, las claves basename , extension , gzip son necesarias exclusivamente para la formación del nombre de la copia de seguridad final.
- En caso de completar con éxito el script, el código de retorno debe ser 0 y cualquier otro en caso de algún problema.
Por ejemplo, supongamos que tenemos un script para crear una instantánea, etcd /etc/nxs-backup-ext/etcd.py :
La configuración para ejecutar este script es la siguiente:
archivo de configuración - job: etcd-external type: external dump_cmd: '/etc/nxs-backup-ext/etcd.py' storages: - storage: local enable: yes backup_dir: /var/nxs-backup/external/dump store: days: 6 weeks: 4 month: 6
En este caso, el programa cuando ejecuta el trabajo, etcd-external :
- Ejecute el script /etc/nxs-backup-ext/etcd.py sin parámetros
- Una vez que se complete el script, verificará el código de finalización y la disponibilidad de los datos necesarios en stdout
- Si todas las comprobaciones son exitosas, se usa el mismo mecanismo que con los módulos ya integrados, donde el valor de la clave full_path se usa como tmp_path. De lo contrario, completará esta tarea con la marca correspondiente en el registro.
Soporte y actualización
El proceso de desarrollo y soporte del nuevo sistema de respaldo se ha implementado con todos los cánones de CI / CD. No más actualizaciones y ediciones de script en servidores de batalla. Todos los cambios pasan a través de nuestro repositorio central de git en Gitlab, donde el ensamblaje de nuevas versiones de paquetes deb / rpm se registra en la tubería, que luego se cargan en nuestros repositorios deb / rpm. Y después de eso, a través del administrador de paquetes, se entregan a los servidores del cliente final.
¿Cómo descargar nxs-backup?
Realizamos un proyecto de código abierto nxs-backup. Cualquiera puede descargarlo y usarlo para organizar el proceso de copia de seguridad en sus proyectos, así como modificarlo según sus necesidades, escribir módulos externos.
El código fuente de nxs-backup se puede descargar desde el repositorio de Github en este enlace . También hay instrucciones de instalación y configuración.
También preparamos una imagen de Docker y la publicamos en DockerHub .
Si tiene alguna pregunta durante el proceso de configuración o uso, escríbanos. Le ayudaremos a comprender y finalizar las instrucciones.
Conclusión
En un futuro cercano, implementaremos la siguiente funcionalidad:
- Integración de monitoreo
- Cifrado de respaldo
- Interfaz basada en web para administrar la configuración de respaldo
- Implementación de copias de seguridad con nxs-backup
- Y mucho mas