Los editores de texto modernos no solo pueden emitir pitidos y no abandonar el programa. Resulta que un metabolismo muy complejo hierve dentro de ellos. Desea saber qué trucos se están haciendo para recalcular rápidamente las coordenadas, cómo se adjuntan los estilos, los pliegues y los softwraps al texto y cómo se actualiza todo, qué tiene que ver con la estructura de datos funcional y la cola de prioridad, y cómo engañar al usuario: ¡bienvenido al gato!

El artículo se basa en el
informe de Alexei Kudryavtsev con Joker 2017. Alexei ha estado escribiendo Intellij IDEA en JetBrains durante aproximadamente 10 años. Debajo del corte, encontrará la transcripción de video y texto del informe.
Estructuras de datos dentro de editores de texto
Para entender cómo funciona el editor, escribámoslo.

Eso es todo, nuestro editor más simple está listo.
Dentro del editor, el texto es más fácil de almacenar en una variedad de caracteres o, lo que es lo mismo (en términos de organización de la memoria), en la clase Java StringBuffer. Para obtener algunos caracteres por desplazamiento, llamamos al método StringBuffer.charAt (i). Y para insertar en él el carácter que escribimos en el teclado, llamamos al método StringBuffer.insert (), que inserta el carácter en algún lugar en el medio.
Lo más interesante, a pesar de toda la simplicidad e idiotez de este editor, es la mejor idea que puede inventar. Es a la vez simple y casi siempre rápido.
Desafortunadamente, surge un problema de escala con este editor. Imagine que imprimimos mucho texto en él y vamos a insertar otra letra en el medio. Lo siguiente sucederá. Necesitamos urgentemente liberar algo de espacio para esta letra moviendo todas las otras letras un carácter hacia adelante. Para hacer esto, cambiamos esta letra por una posición, luego la siguiente y así sucesivamente, hasta el final del texto.
Así es como se vería en la memoria:
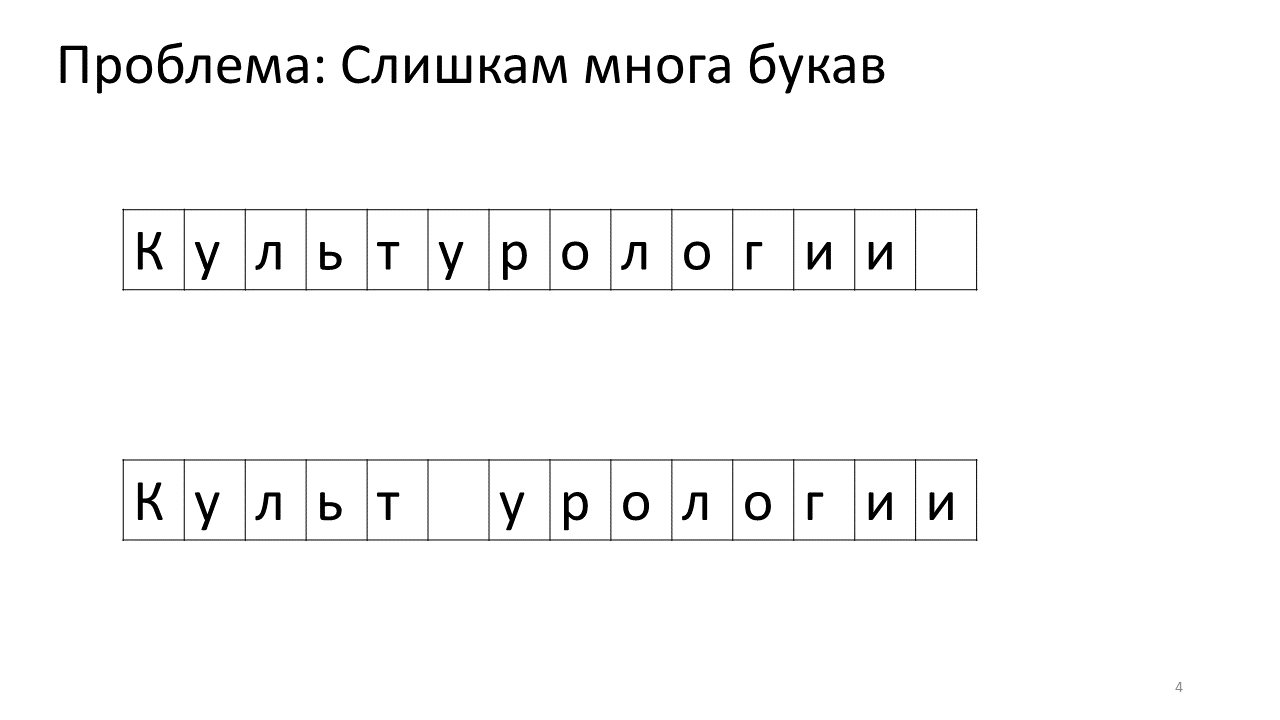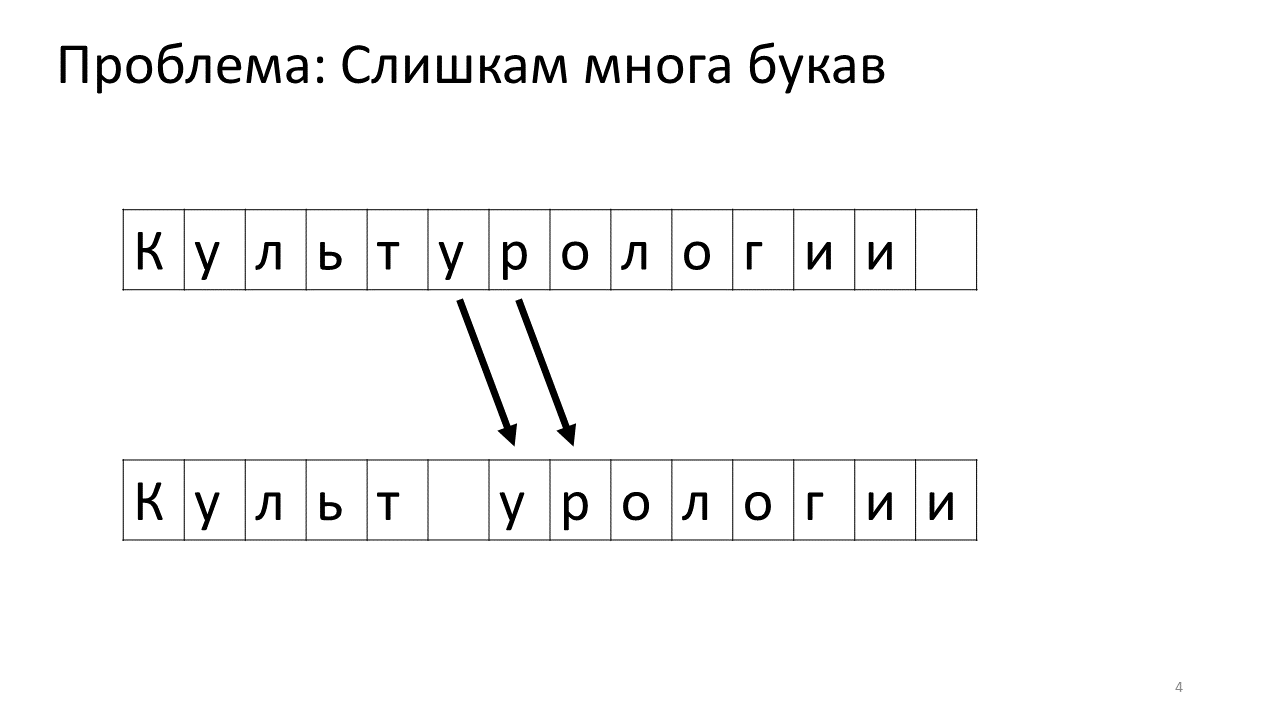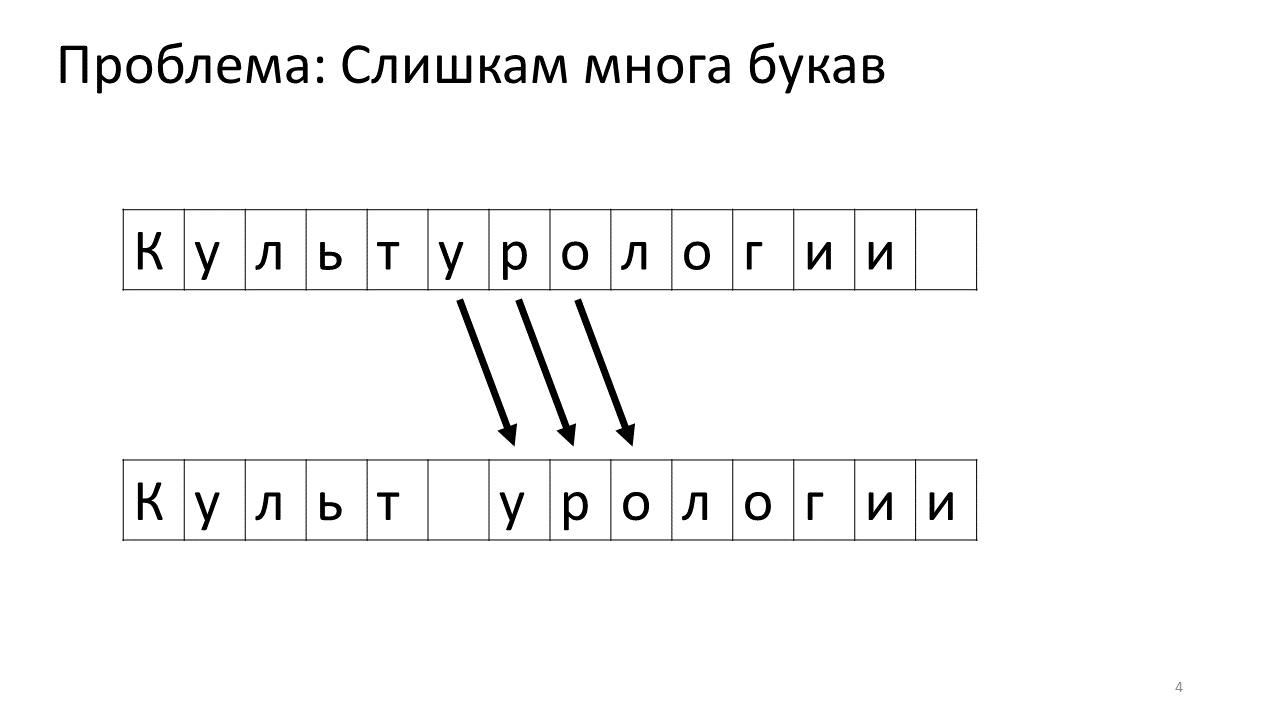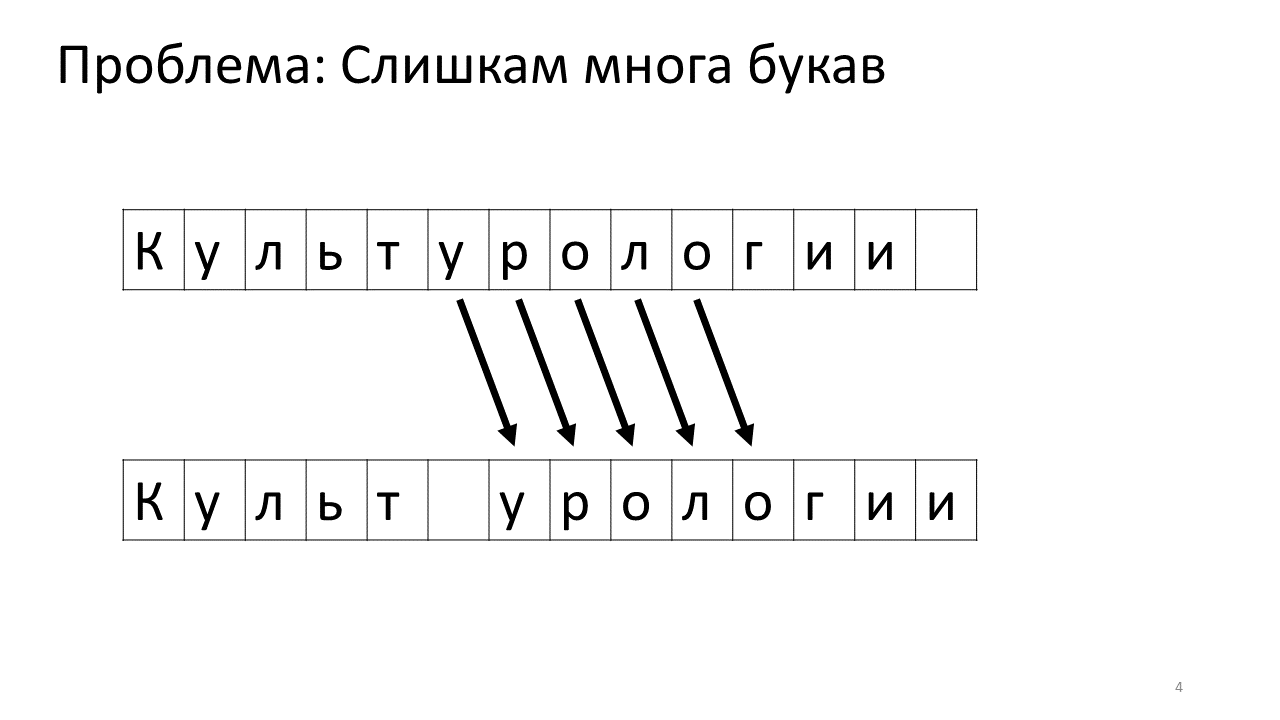
Cambiar todos estos megabytes no es muy bueno: es lento. Por supuesto, para una computadora moderna, este es un asunto insignificante: algún tipo de megabytes patéticos para moverse de un lado a otro. Pero para un cambio de texto muy activo, esto puede ser notable.
Para resolver este problema de insertar un personaje en el medio, hace mucho tiempo surgió una solución llamada "Gap Buffer".
Gap buffer
La brecha es la brecha. El búfer es, como te puedes imaginar, un búfer. La estructura de datos de Gap Buffer es un buffer tan vacío que mantenemos en el medio de nuestro texto, por si acaso. Si necesitáramos imprimir algo, utilizamos este pequeño buffer de texto para escribir rápidamente.

La estructura de datos ha cambiado un poco: la matriz se ha mantenido en su lugar, pero han aparecido dos punteros: al principio del búfer y al final. Para tomar un carácter del editor en algún desplazamiento, necesitamos entender si está antes o después de este búfer y corregir ligeramente el desplazamiento. Y para insertar un personaje, primero debemos mover el Gap Buffer a este lugar y llenarlo con estos personajes. Y, por supuesto, si fuimos más allá de nuestro búfer, recrearlo de alguna manera. Así es como se ve en la imagen.

Como puede ver, primero nos movemos durante mucho tiempo en un pequeño espacio intermedio (rectángulo azul) a la ubicación de edición (simplemente intercambiando los caracteres de sus bordes izquierdo y derecho a su vez). Luego usamos este búfer, escribiendo caracteres allí.
Como puede ver, no hay movimiento de megabytes de caracteres, el inserto es muy rápido, por un tiempo constante, y parece que todos están contentos. Todo parece estar bien, pero si nuestro procesador es muy lento, se desperdicia un tiempo bastante notable moviendo el espacio intermedio y el texto de un lado a otro. Esto fue especialmente notable en el momento de megahercios muy pequeños.
Mesa de piezas
Justo en ese momento, una corporación llamada Microsoft escribió un editor de texto Word. Decidieron aplicar otra idea para acelerar la edición llamada "Tabla de piezas", es decir, "Tabla de piezas". Y propusieron guardar el texto del editor en el mismo conjunto de caracteres más simple, que no cambiará, y colocar todos sus cambios en una tabla separada de estas piezas muy editadas.

Por lo tanto, si necesitamos encontrar algún carácter por desplazamiento, necesitamos encontrar esta pieza que hemos editado y extraer este carácter, y si no está allí, vaya al texto original. Insertar un símbolo se vuelve más fácil, solo necesitamos crear y agregar esta nueva pieza a la tabla. Así es como se ve en la imagen:
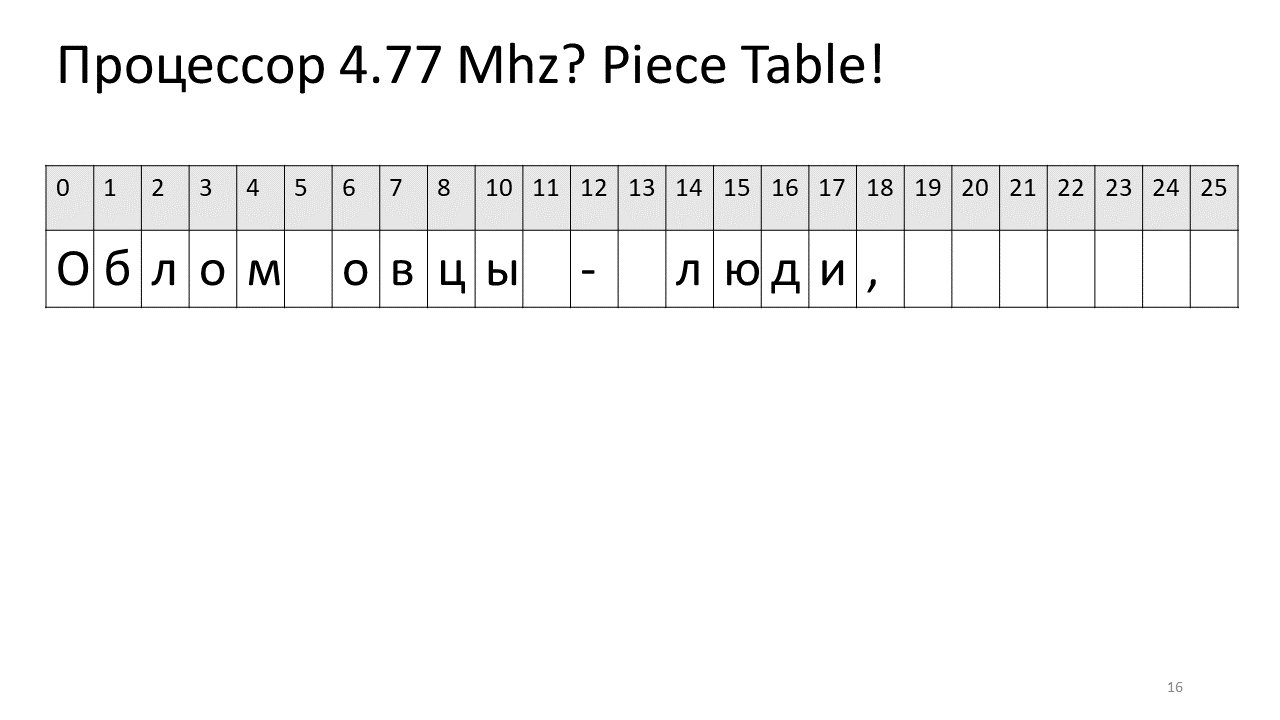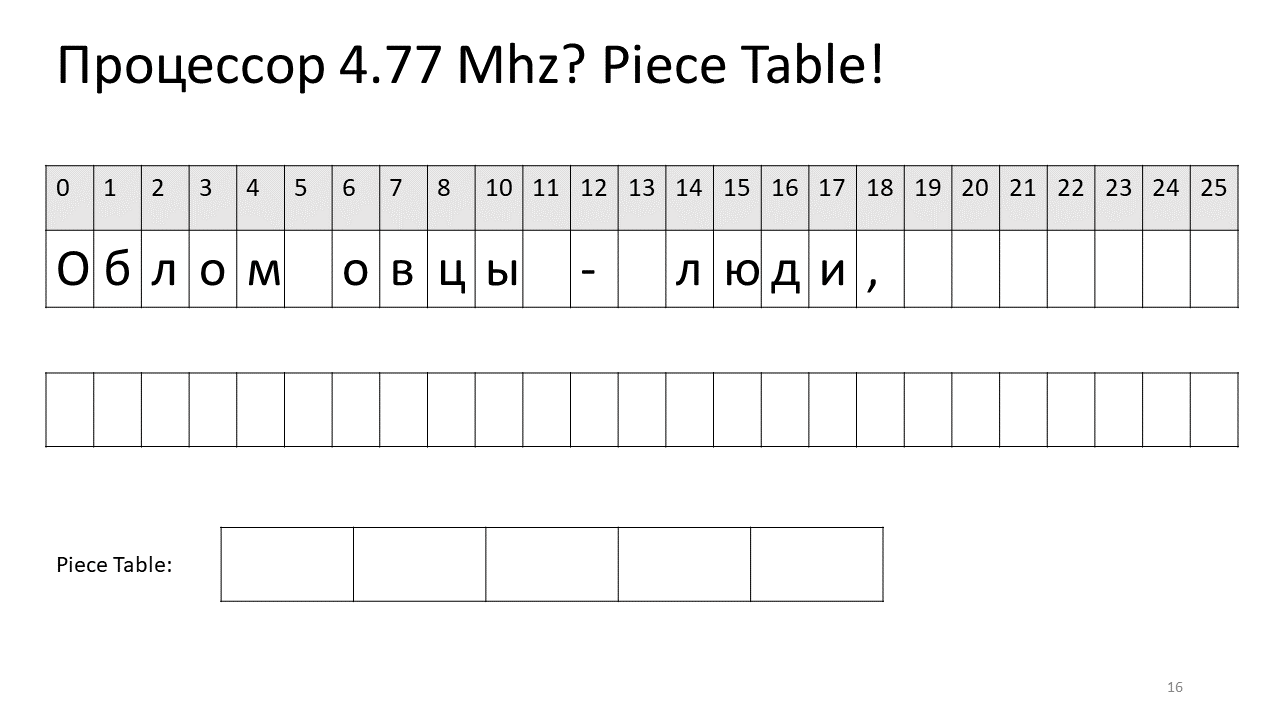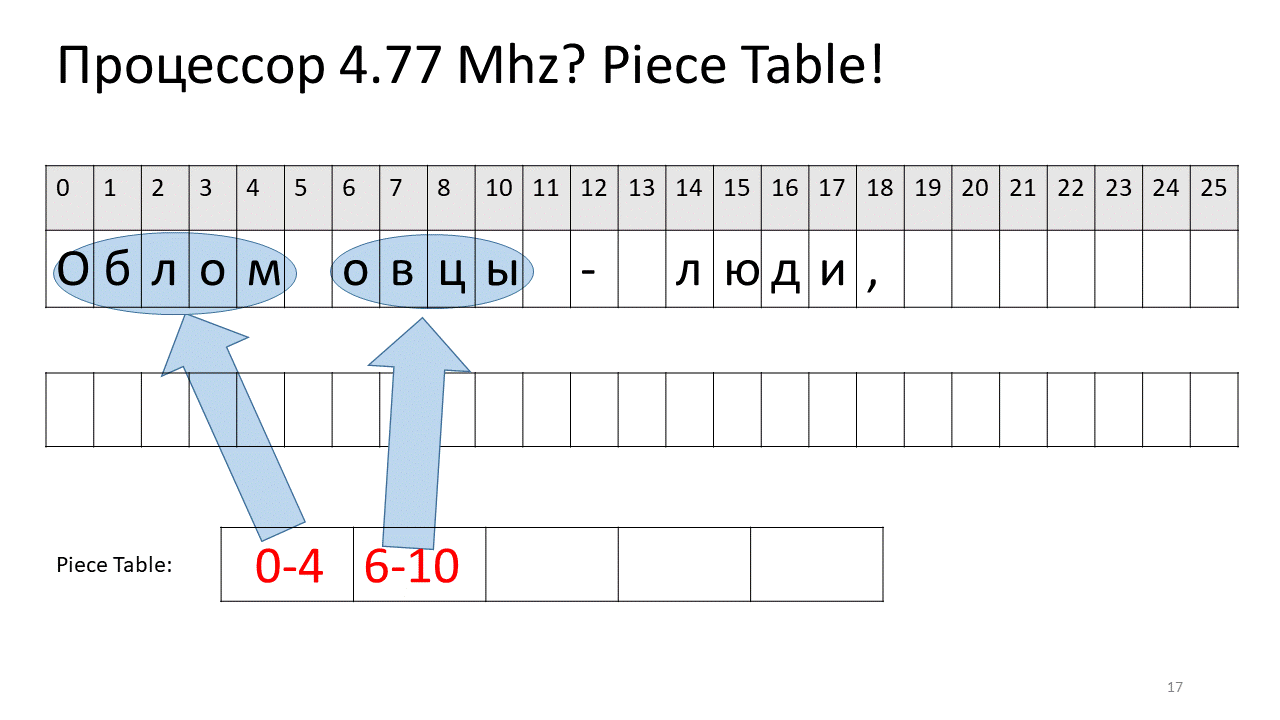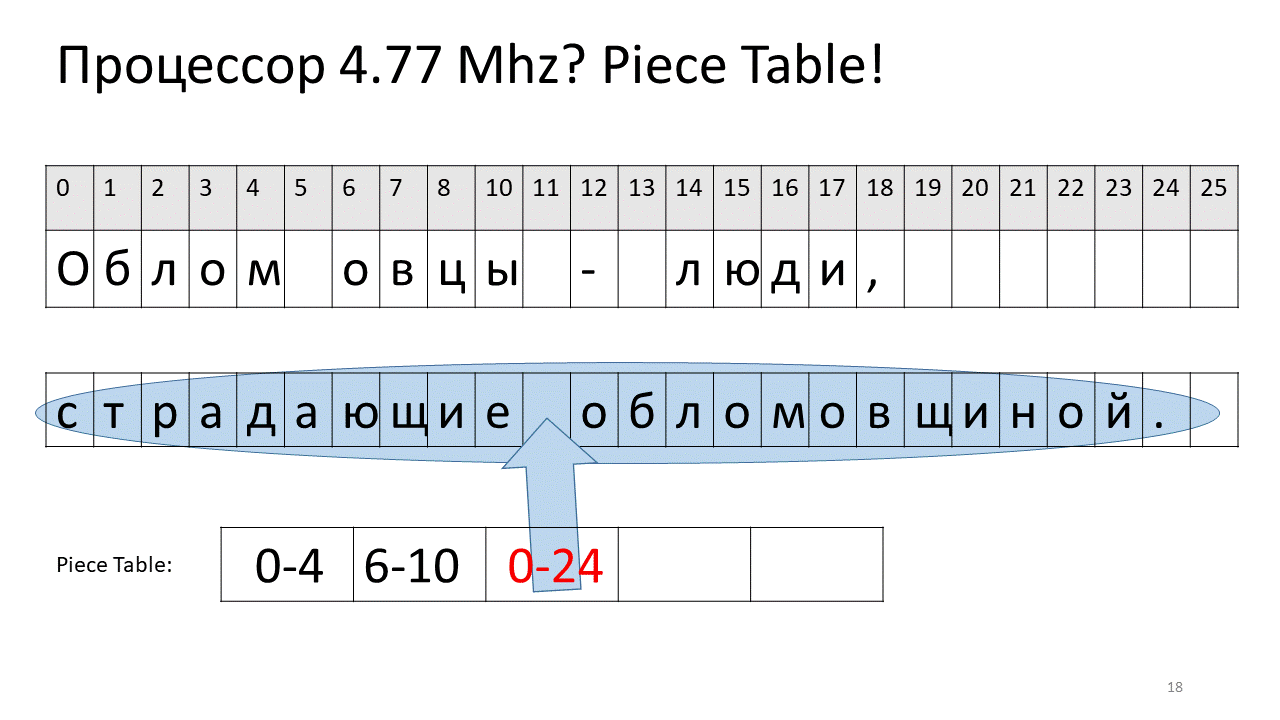
Aquí queríamos eliminar el espacio en el desplazamiento 5. Para hacer esto, agregamos dos piezas nuevas a la tabla de sectores: una indica el primer fragmento ("Bummer") y la segunda indica el fragmento después de la edición ("oveja"). Resulta que la brecha de ellos desaparece, estas dos piezas se pegan y obtenemos un nuevo texto sin espacio: "Oblomovtsy". Luego agregamos el nuevo texto ("sufriendo de Oblomovismo") hasta el final. Use un búfer adicional y agregue una nueva división a la tabla de piezas que apunte a este nuevo texto agregado.
Como puede ver, no hay movimiento de ida y vuelta, todo el texto permanece en su lugar. La mala noticia es que cada vez es más difícil llegar al símbolo, porque clasificar todas estas piezas es bastante difícil.
Para resumir.
Lo bueno de
Piece Table :
- Incrustar rápidamente;
- Fácil de deshacer;
- Solo anexar.
Lo que es malo:
- Es terriblemente difícil acceder a un documento;
- Es terriblemente difícil de implementar.
Veamos a quién usamos generalmente para qué.
NetBeans, Eclipse y Emacs usan Gap Buffer - ¡bien hecho! Vi no molesta y usa solo una lista de líneas. Word usa la Tabla de piezas (recientemente presentaron sus géneros antiguos y allí incluso puedes entender algo).
Atom es más interesante. Hasta hace poco, no se molestaban y usaban una lista de líneas de JavaScript. Y luego decidieron reescribir todo en C ++ y acumularon una estructura bastante complicada, que parece ser similar a la Tabla de piezas. Pero estas piezas no se almacenan en la lista, sino en el árbol, y en el llamado árbol de separación: este es un árbol que se autoajusta cuando se inserta en él, de modo que las inserciones recientes son más rápidas. Hicieron algo muy complicado.
¿Qué usa Intellij IDEA?
No, no gap-buffer. No, también te equivocas, no una mesa de piezas.
Sí, muy bien, tu propia bicicleta.
El hecho es que los requisitos del IDE para almacenar texto son ligeramente diferentes a los de un editor de texto normal. El IDE necesita soporte para varias cosas difíciles como la competitividad, es decir, el acceso paralelo al texto desde el editor. Por ejemplo, para que muchos productos horneados diferentes puedan leerlo y hacer algo. (La inspección es un pequeño fragmento de código que analiza el programa de una forma u otra, por ejemplo, buscando lugares que arrojen una NullPointerException). IDE también necesita soporte de versión de texto editable. Varias versiones están simultáneamente en la memoria mientras trabaja con un documento para que estos largos procesos continúen analizando la versión anterior.
Los problemas
Competitividad / Versionado
Para mantener el paralelismo, las operaciones de texto generalmente se envuelven en "sincronizado" o en bloqueos de lectura / escritura. Desafortunadamente, esto no escala muy bien. Otro enfoque es el texto inmutable, es decir, un repositorio de texto inmutable.

Así es como se ve un editor con un documento inmutable como estructura de datos de soporte.
¿Cómo funciona la estructura de datos?
En lugar de una matriz de caracteres, tendremos un nuevo objeto de tipo ImmutableText, que almacena texto en forma de árbol, donde se almacenan pequeñas subcadenas en las hojas. Cuando accede a algún desplazamiento, intenta alcanzar la hoja inferior de este árbol, y ya se le preguntará el símbolo al que nos referíamos. Y cuando inserta texto, crea un nuevo árbol y lo guarda en el lugar anterior.

Por ejemplo, tenemos un documento con el texto "Sin calorías". Se implementa como un árbol con dos hojas de sustituciones "Demonio" y "alto en calorías". Cuando queremos insertar la línea "bonita" en el medio, se crea una nueva versión de nuestro documento. Y precisamente, se crea una nueva raíz, a la que ya se adjuntan tres hojas: "Demonio", "suficiente" y "alto en calorías". Además, dos de estas nuevas hojas pueden referirse a la primera versión de nuestro documento. Y para la hoja en la que insertamos la línea "bonita", se asigna un nuevo vértice. Aquí, tanto la primera versión como la segunda versión están disponibles al mismo tiempo y todas son inmutables, inmutables. Todo se ve bien.
¿Quién usa qué estructuras difíciles?

Por ejemplo, en GNOME, algunos de sus widgets estándar usan una estructura llamada Rope. Xi-Editor, el nuevo y brillante editor de
Raf Levien , usa Persistent Rope. E Intellij IDEA usa este árbol inmutable. Detrás de todos estos nombres, de hecho, hay más o menos la misma estructura de datos con una representación del texto en forma de árbol. Excepto que GtkTextBuffer usa una cuerda mutable, es decir, un árbol con vértices mutables, e Intellij IDEA y Xi-Editor - Inmutable.
Lo siguiente a considerar al desarrollar un repositorio de caracteres en IDEs modernos se llama multicats. Esta característica le permite imprimir en varios lugares a la vez, utilizando varios carros.

Podemos imprimir algo y, al mismo tiempo, en varios lugares del documento, insertamos lo que imprimimos allí. Si observamos cómo nuestras estructuras de datos, que examinamos, reaccionan a los multicarets, veremos algo interesante.
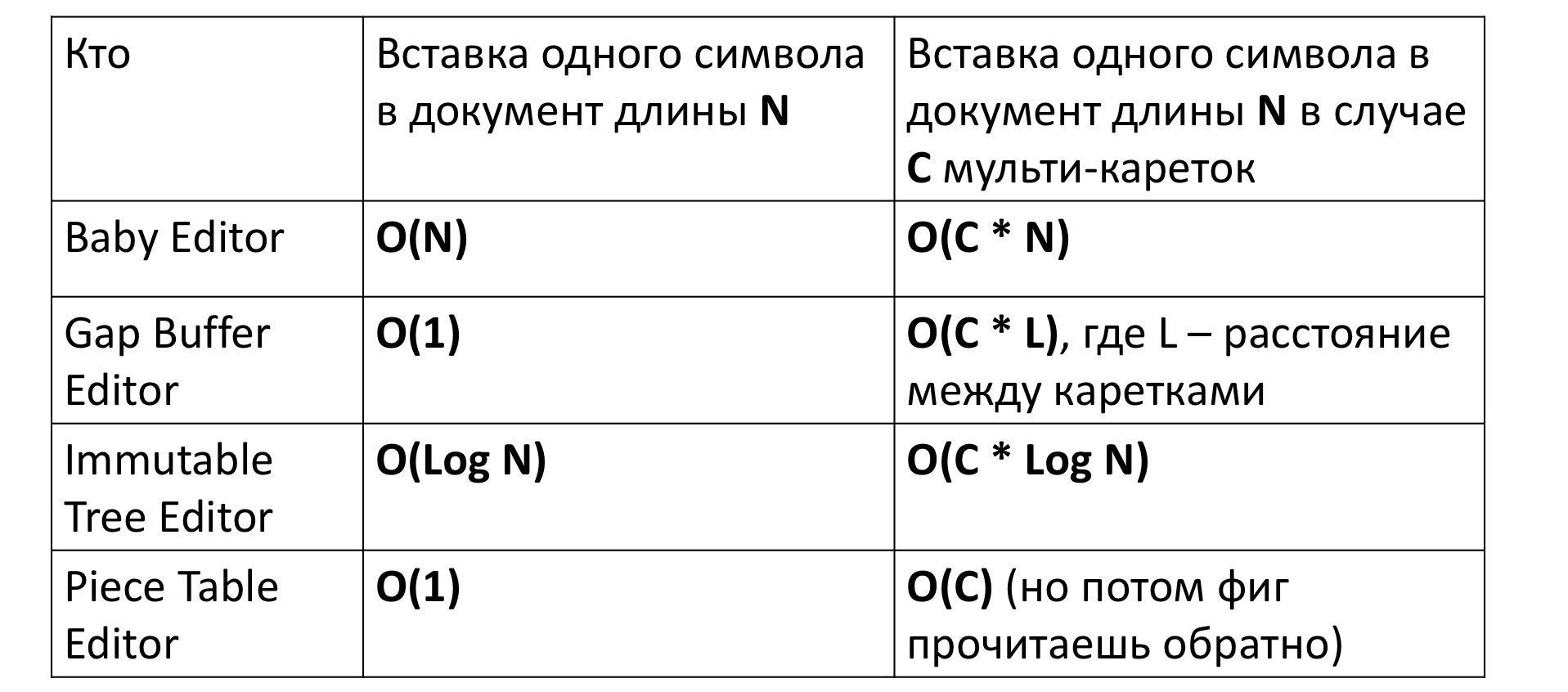
Si insertamos un personaje en nuestro primer editor primitivo, naturalmente tomará una cantidad lineal de tiempo mover un montón de caracteres de un lado a otro. Esto se escribe como O (N). Para el editor basado en Gap Buffer, a su vez, se requiere tiempo constante, para lo cual fue acuñado.
Para un árbol inmutable, el tiempo depende logarítmicamente del tamaño, porque primero debe ir desde la parte superior del árbol hasta su hoja, este es el logaritmo, y luego, para todos los vértices en el camino, crear nuevos vértices para el nuevo árbol, este es nuevamente el logaritmo. La tabla de piezas también requiere una constante.
Pero todo cambia un poco si intentamos medir el tiempo de inserción de un personaje en un editor con carros múltiples, es decir, insertar simultáneamente en varios lugares. A primera vista, el tiempo parece aumentar proporcionalmente por un factor de C: el número de lugares donde se inserta el símbolo. Esto es exactamente lo que sucede, con la excepción de Gap Buffer. En su caso, el tiempo, en lugar de C veces, aumenta inesperadamente algunas veces C * L incomprensibles, donde L es la distancia promedio entre los carros. ¿Por qué está pasando esto?
Imagine que necesitamos insertar la línea ", en" en dos lugares en nuestro documento.
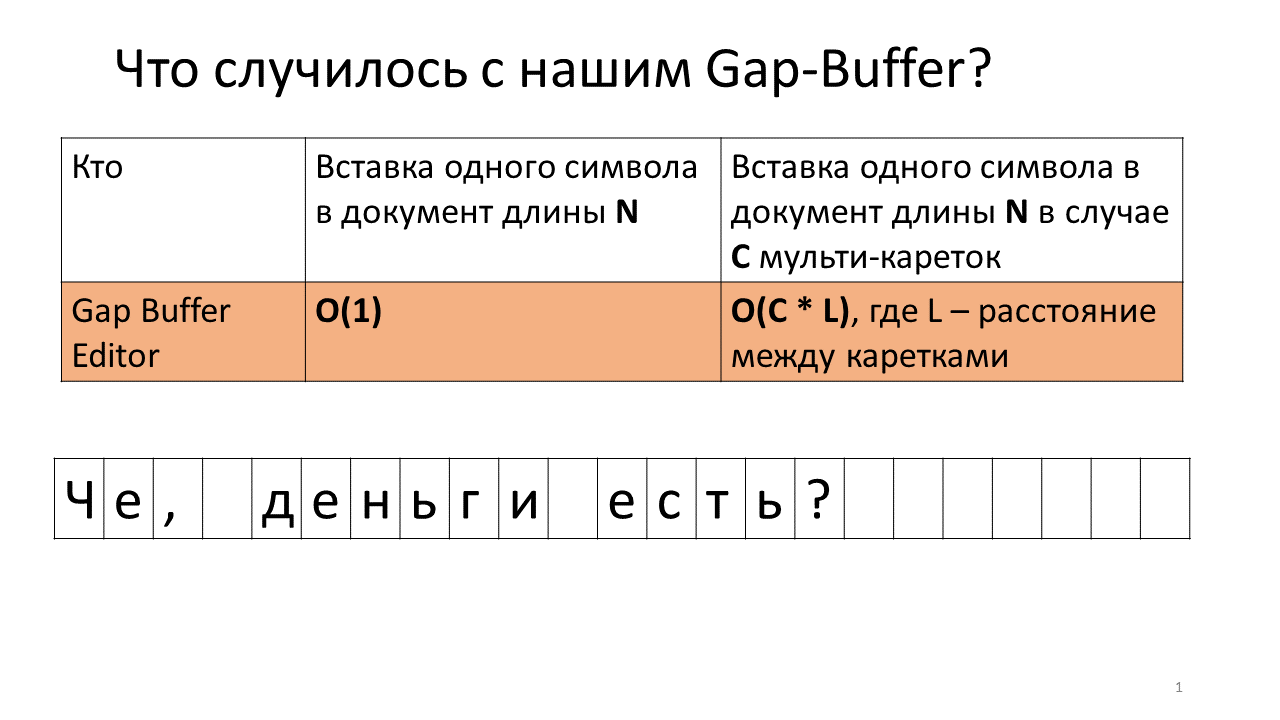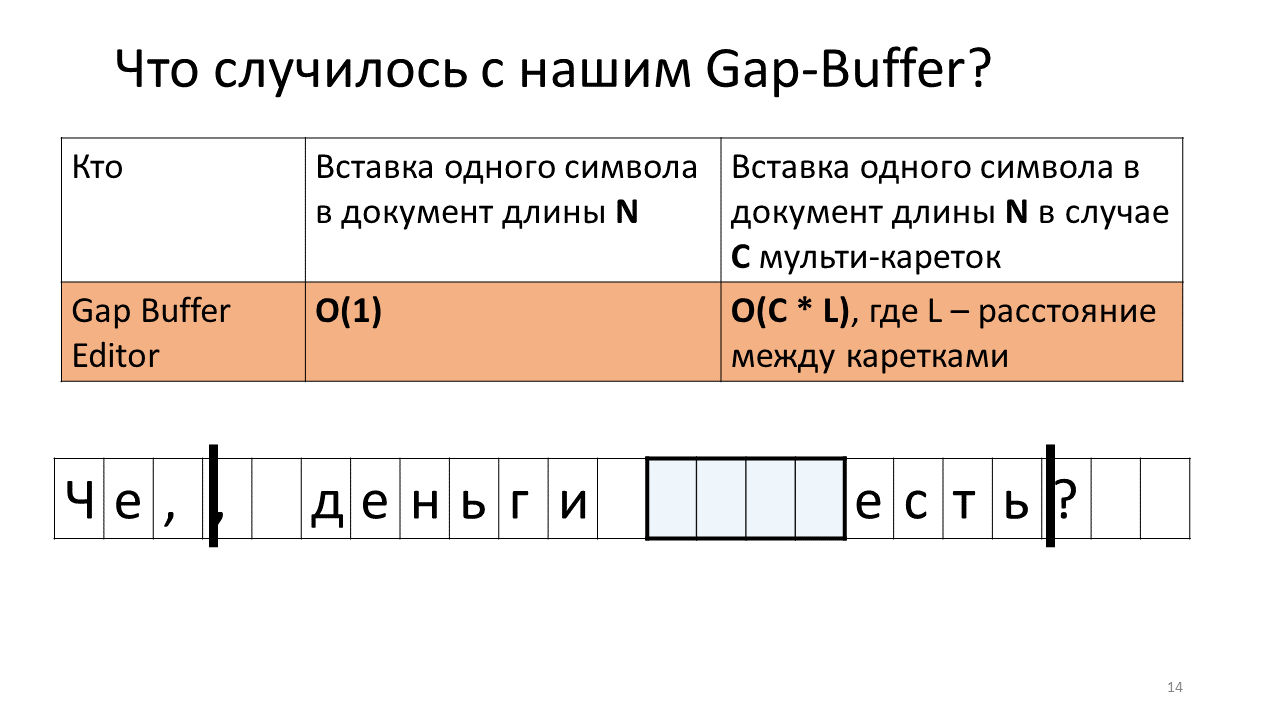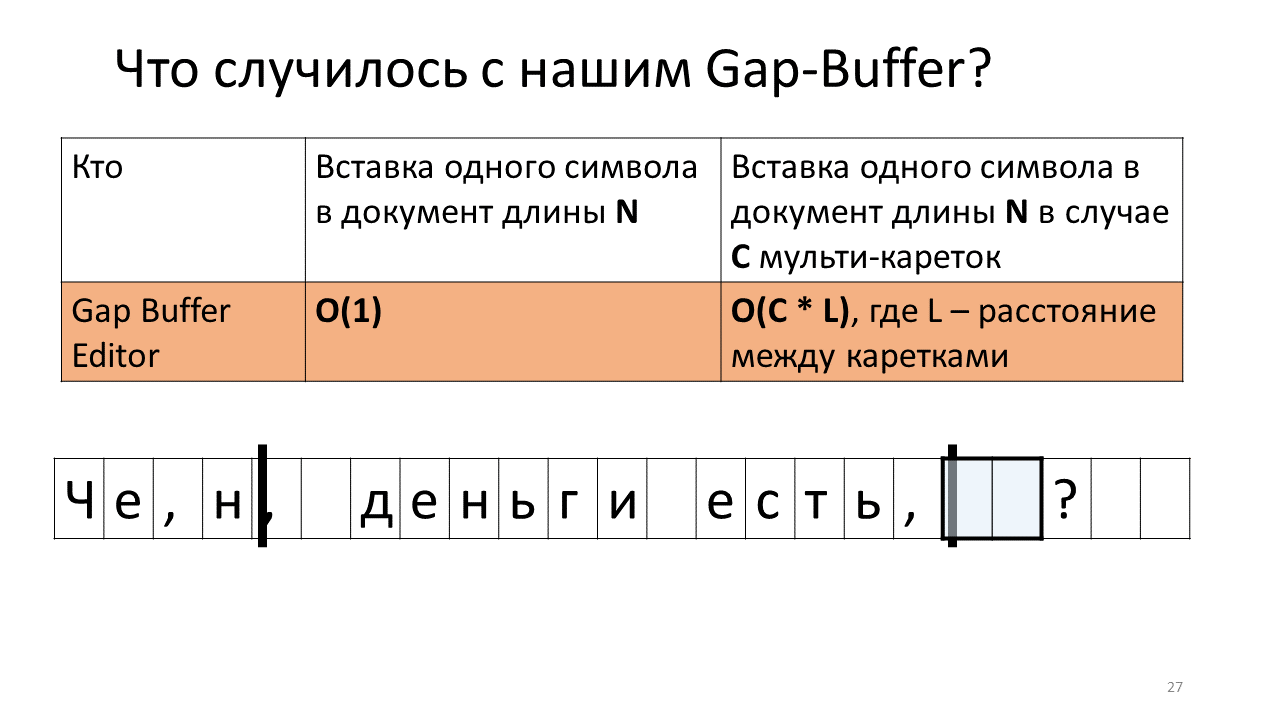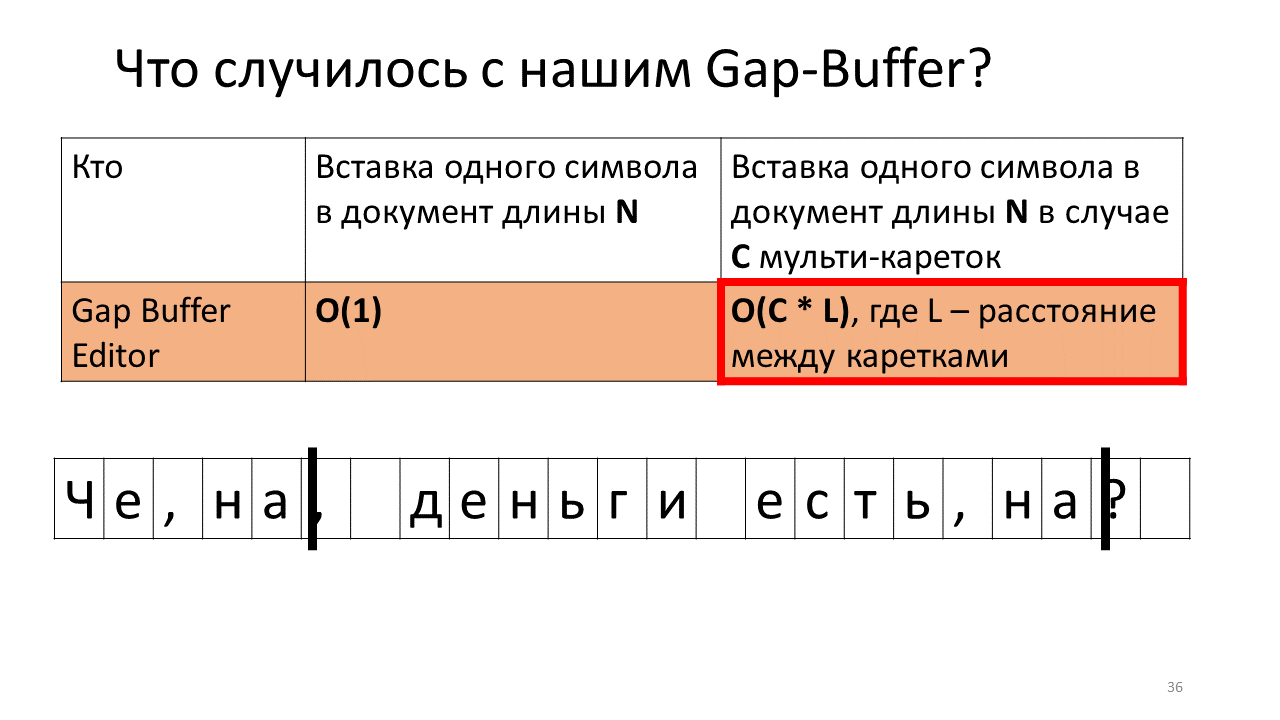
Esto es lo que sucede en el editor en este momento.
- Cree un espacio intermedio en el editor (un pequeño rectángulo azul en la imagen);
- Comenzamos dos carruajes (líneas verticales negras en negrita);
- Estamos intentando imprimir;
- Inserte una coma en nuestro Gap Buffer;
- Ahora debe insertarlo en el lugar del segundo carro;
- Para hacer esto, necesitamos mover nuestro Gap Buffer a la posición del próximo carro;
- Imprima una coma en segundo lugar;
- Ahora debe insertar el siguiente carácter en la posición del primer carro;
- Y tenemos que empujar nuestro Gap Buffer hacia atrás;
- Inserte la letra "n";
- Y trasladamos nuestro tampón sufrido al lugar del segundo carro;
- Insertamos nuestra "n" allí;
- Mueva el búfer hacia atrás para insertar el siguiente carácter.
¿Sientes a dónde va todo?
Sí, resulta que debido a estos numerosos movimientos del búfer de ida y vuelta, nuestro tiempo total aumenta. Honestamente, no es que esté directamente horrorizado a medida que ha aumentado: mover megabytes patéticos, gigabytes de un lado a otro para una computadora moderna no es un problema, pero es interesante que esta estructura de datos funcione de manera radicalmente diferente en el caso de multicats.
¿Demasiadas líneas? LineSet!
¿Qué otros problemas hay en un editor de texto normal? El problema más difícil es desplazarse, es decir, volver a dibujar el editor mientras se mueve el carro a la siguiente línea.

Cuando el editor se desplaza, necesitamos entender desde qué línea, desde qué símbolo necesitamos comenzar a dibujar el texto en nuestra pequeña ventana. Para hacer esto, necesitamos entender rápidamente qué línea corresponde a qué desplazamiento.
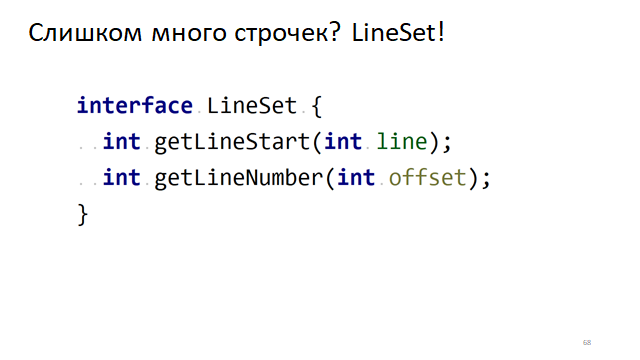
Hay una interfaz obvia para esto, cuando necesitamos entender su desplazamiento en el texto por número de línea. Y viceversa, por el desplazamiento en el texto para entender en qué línea se encuentra. ¿Cómo se puede hacer esto rápidamente?
Por ejemplo, así:
Organice estas líneas en un árbol y marque cada vértice de este árbol cambiando el comienzo de la línea y el final de la línea. Y luego, para entender por el desplazamiento en qué línea se encuentra, solo necesita ejecutar una búsqueda logarítmica en este árbol y encontrarlo.
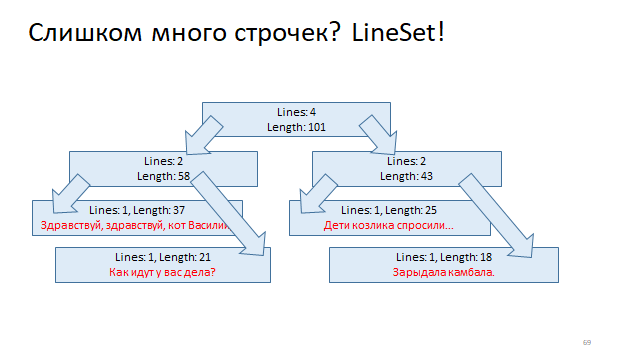
Otra forma es aún más fácil.
Escriba en la tabla el desplazamiento del principio de las líneas y el final de las líneas. Y luego, para encontrar el desplazamiento del principio y el final por el número de línea, deberá acceder al índice.
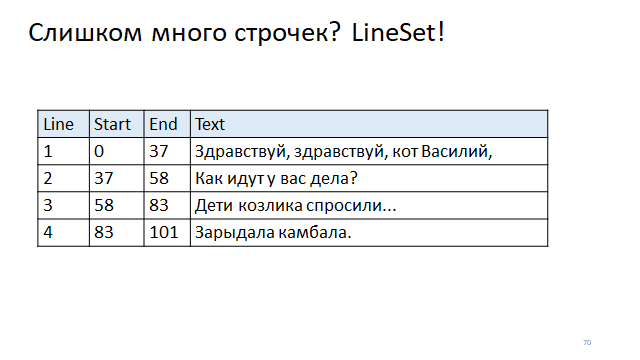
Curiosamente, en el mundo real, se utilizan ambos métodos.

Por ejemplo, Eclipse utiliza una estructura de madera que, como puede ver, funciona en un tiempo logarítmico tanto para leer como para actualizar. E IDEA usa una estructura de tabla, para la cual la lectura es una constante rápida, es una inversión de índice en una tabla, pero la reconstrucción es bastante lenta, porque necesita reconstruir toda la tabla al cambiar la longitud de una fila.
Todavía demasiadas líneas? Plegamientos!
¿Qué otra cosa es mala que tropieza con los editores de texto? Por ejemplo, pliegues. Estos son fragmentos de texto que puede "colapsar" y mostrar algo más en su lugar.

Estos puntos sobre un fondo verde en la imagen ocultan muchos símbolos detrás de nosotros, pero si no estamos interesados en mirarlos (como en el caso de, por ejemplo, los documentos Java más aburridos o las listas de importación), los ocultamos, los colapsamos puntos suspensivos
Y aquí, nuevamente, debe comprender cuándo termina y cuándo comienza la región que debemos mostrar, y cómo actualizar todo rápidamente. Cómo se organiza esto, lo contaré un poco más tarde.
¿Demasiadas colas? Envoltura suave!

Además, los editores modernos no pueden vivir sin Soft wrap. La imagen muestra que el desarrollador abrió el archivo JavaScript después de la minimización e inmediatamente lo lamentó. Esta enorme línea de JavaScript, cuando intentamos mostrarla en el editor, no cabe en ninguna pantalla. Por lo tanto, una envoltura suave lo rompe a la fuerza en varias líneas y lo empuja hacia la pantalla.
Cómo está organizado, más tarde.
Muy poca belleza

Y finalmente, también quiero aportar belleza a los editores de texto. Por ejemplo, resalte algunas palabras. En la imagen de arriba, las palabras clave se resaltan en negrita azul, algunos métodos estáticos en cursiva, algunas anotaciones, también en un color diferente.
Entonces, ¿cómo almacena y procesa los pliegues, envolturas suaves y reflejos?
Resulta que todo esto, en principio, es una y la misma tarea.
¿Muy poca belleza? Marcadores de rango!

Para admitir todas estas características, todo lo que debemos poder hacer es pegar algunos atributos de texto en un desplazamiento dado en el texto, por ejemplo, color, fuente o texto para plegar. Además, estos atributos de texto deben actualizarse todo el tiempo en este lugar para que sobrevivan a todo tipo de inserciones y eliminaciones.
¿Cómo se implementa esto generalmente? Naturalmente, en forma de árbol.
Problema: ¿demasiada belleza? Árbol de intervalos!

Por ejemplo, aquí tenemos varios resaltados amarillos que queremos mantener en el texto. Agregamos los intervalos de estos aspectos destacados en un árbol de búsqueda, el llamado árbol de intervalos. Este es el mismo árbol de búsqueda, pero un poco más complicado porque necesitamos almacenar intervalos en lugar de números.
Y dado que hay intervalos saludables y pequeños, cómo clasificarlos, compararlos entre sí y ponerlos en un árbol es una tarea bastante trivial. Aunque muy conocido en informática. Luego, mire de alguna manera cómo funciona. Entonces, tomamos y ponemos todos nuestros intervalos en un árbol, y luego cada cambio en el texto en algún lugar en el medio conduce a un cambio logarítmico en este árbol. Por ejemplo, insertar un carácter debería resultar en la actualización de todos los intervalos a la derecha de ese carácter. Para hacer esto, encontramos todos los vértices dominantes para este símbolo e indicamos que todos sus vértices deben moverse un símbolo a la derecha.
¿Aún quieres belleza? Ligaduras!

Todavía hay algo tan terrible: las ligaduras, que también me gustaría apoyar. Estas son bellezas diferentes, como el signo "! =" Se dibuja en forma de un glifo grande "no igual" y así sucesivamente. Afortunadamente, aquí contamos con un mecanismo de oscilación para soportar estas ligaduras. Y, según nuestra experiencia, aparentemente trabaja de la manera más simple. Dentro de la fuente, se almacena una lista de todos estos pares de caracteres que, cuando se combinan, forman algún tipo de ligadura complicada. Luego, al dibujar la línea, Swing simplemente itera sobre todos estos pares, encuentra los necesarios y los dibuja en consecuencia. Si tiene muchas ligaduras en la fuente, al parecer, mostrarla disminuirá proporcionalmente.
Frenos de vuelco
— , , — , , .

Intellij IDEA , - , , , :
- , completion popup', completion', , , - «Enter».
- , - , Perforce, - .
- , - , , - .
- , , , .
- injected-, , , - .
- auto popup handler, , , .
- info , , . selection remove, selection , . selection , .
- typed handler, , .
- .
- Ejecute deshacer, cuente espacios virtuales y ejecute la acción de escritura.
- Finalmente, inserte el personaje en nuestro documento.
¡Hurra!
Demonios no, eso no es todo. Eliminar el carácter si nuestro búfer está lleno. Por ejemplo, en la consola, llame al oyente para que todos sepan que algo ha cambiado. Vista del editor de desplazamiento. Llama a otros oyentes estúpidos.¿Y qué sucede en el editor ahora cuando descubre que el documento ha cambiado y se llama a DocumentListener?En Editor.documentChanged (), esto es lo que sucede:- Actualizar raya de error;
- Vuelva a calcular el tamaño de la canaleta, vuelva a dibujar;
- Vuelva a calcular el tamaño del componente del editor, envíe eventos al cambiar;
- Cuente las líneas cambiadas y sus coordenadas;
- recalcular la envoltura suave si el cambio lo afecta;
- Llamar a repintar ().
repaint() — Swing, . , Repaint Swing.
- , repaint , :

paint-, , .
, , ?

, , . Intellij IDEA .

, - - , , , . ! , , , - — ! , - . . «Zero latency typing».
— .
Que es esto , — , Google Docs - - .
:
, , .
- . , , . . — , «intention preservation». , - , , , . — . , - , .
Operation transformation
, , «operation transformation». . , - : , . Operation transformation . , , , - . , . , - . , , .
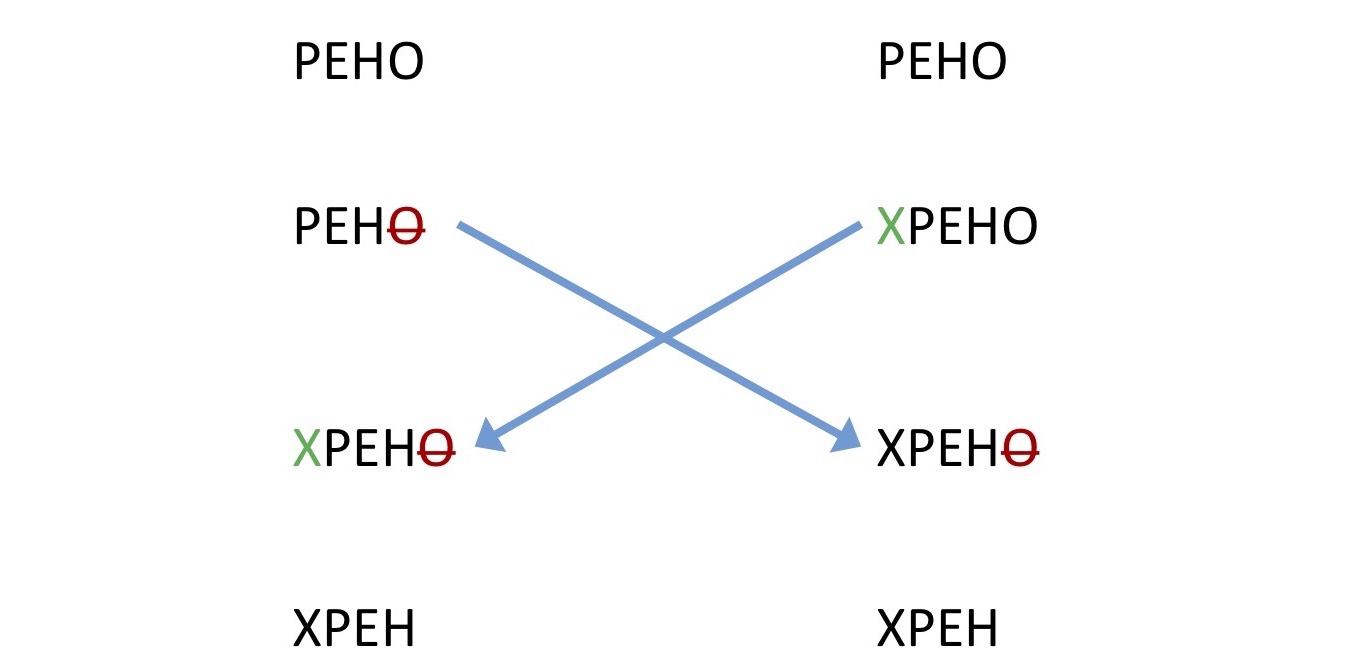
Cuando comenzaron a aparecer las primeras implementaciones de este marco, los desarrolladores asombrados descubrieron que existe un ejemplo universal que lo rompe todo. Este desafortunado ejemplo se llamó "rompecabezas TP2".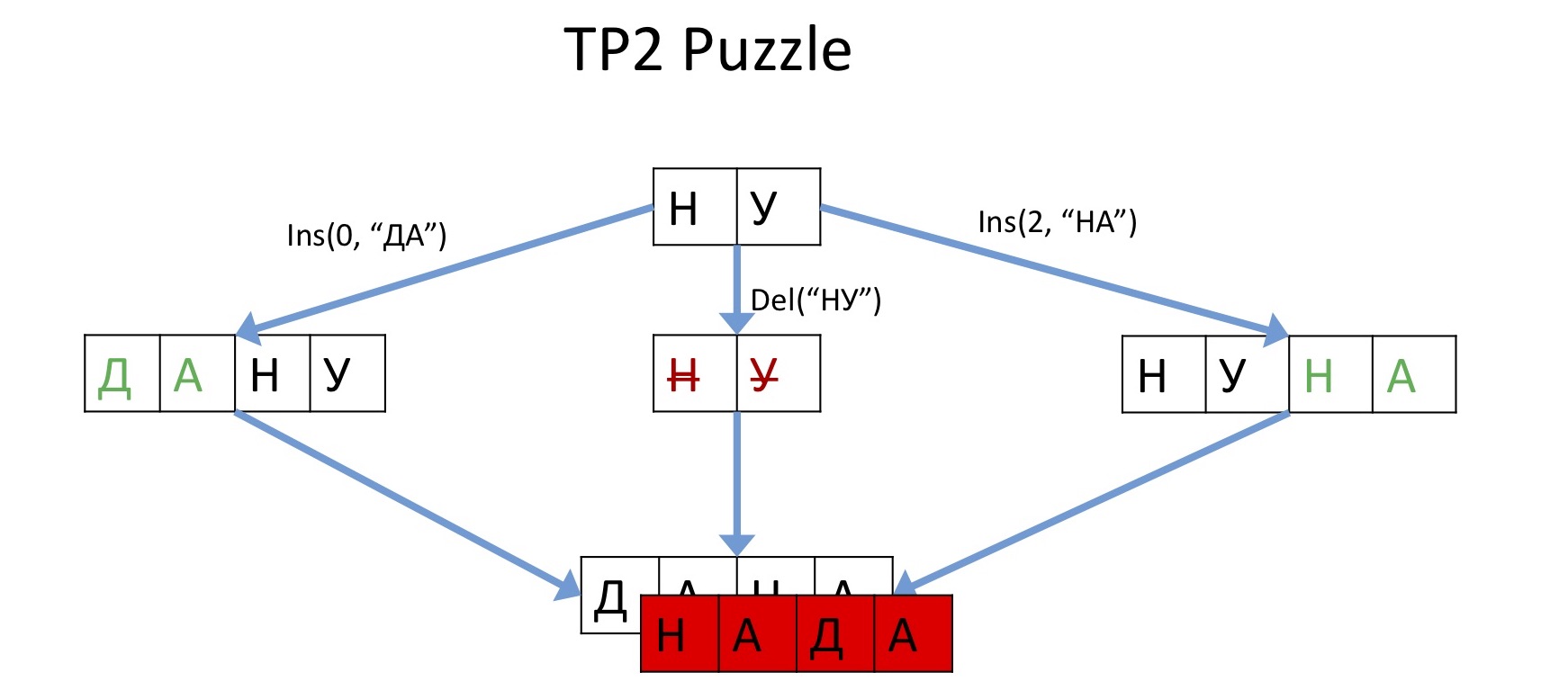 Un usuario dibuja algunos caracteres al comienzo de la línea, otro elimina todo esto y el tercero dibuja al final. Después de que toda esta transformación de la Operación intente fusionarse en la misma cosa, entonces, en teoría, esta línea ("DANA") debería resultar. Sin embargo, algunas implementaciones hicieron esto ("NADA"). Porque no está claro dónde insertarlo. En la imagen de arriba puedes ver en qué nivel se encuentra toda esta ciencia sobre la transformación de la Operación, si todo se ha roto debido a un ejemplo tan primitivo.
Un usuario dibuja algunos caracteres al comienzo de la línea, otro elimina todo esto y el tercero dibuja al final. Después de que toda esta transformación de la Operación intente fusionarse en la misma cosa, entonces, en teoría, esta línea ("DANA") debería resultar. Sin embargo, algunas implementaciones hicieron esto ("NADA"). Porque no está claro dónde insertarlo. En la imagen de arriba puedes ver en qué nivel se encuentra toda esta ciencia sobre la transformación de la Operación, si todo se ha roto debido a un ejemplo tan primitivo., Google Docs, Google Wave - Etherpad. Operation transformation .
Conflict-free replicated data type
: « , OT!» , , . , , , , 100% . «CRDT» (Conflict-free replicated data type).

, , . , , , . , . - ( ), () ( ).

?
Si , G-counter', , . , . «+1» , «+1» , , — «2». , , . G-counter, , . G-counter, . , , . . — . , CRDT. , .
Conflict-free replicated inserts
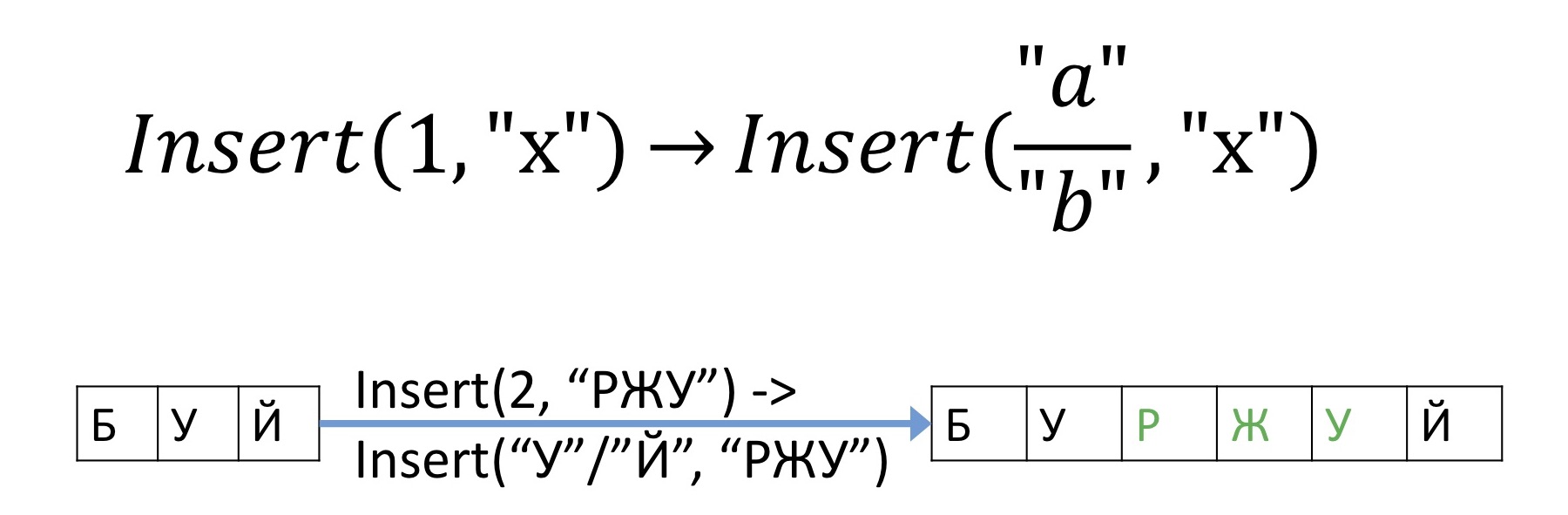
, , , . , , .
, , - - , , , , . , , , , . , , , , 2 «», , «» «» «».
Conflict-free replicated deletes
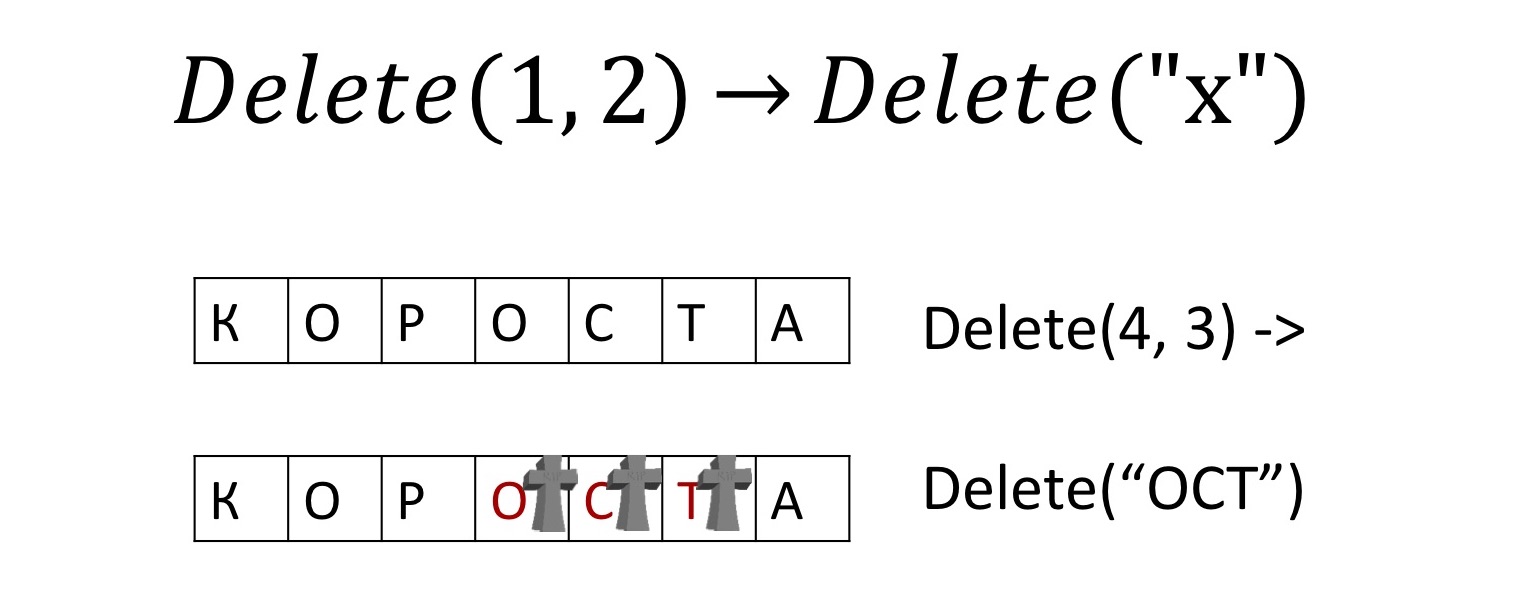
. , , , - . , , . , , , .
, .
Conflict-free replicated edits
, , CRDT - , , Xi-Editor, Fuchsia. , , .
Zipper
También me gustaría hablar sobre lo que se usa en este nuevo mundo inmutable llamado "Cremallera". Después de que hicimos nuestras estructuras inmutables, aparecieron algunos matices de trabajar con ellas. Aquí, por ejemplo, tenemos nuestro árbol inmutable con texto. Queremos cambiarlo (por "cambiar" aquí, como entiendes, quiero decir "crear una nueva versión"). Además, queremos cambiarlo en algún lugar específico y de forma bastante activa. En los editores, esto es bastante común cuando en la ubicación del cursor imprimimos, pegamos y eliminamos algo constantemente. Para hacer esto, a los funcionarios se les ocurrió una estructura llamada Zipper.Tiene el concepto de un supuesto cursor o lugar actual para la edición, mientras se mantiene la inmutabilidad total. Aquí te explicamos cómo hacerlo.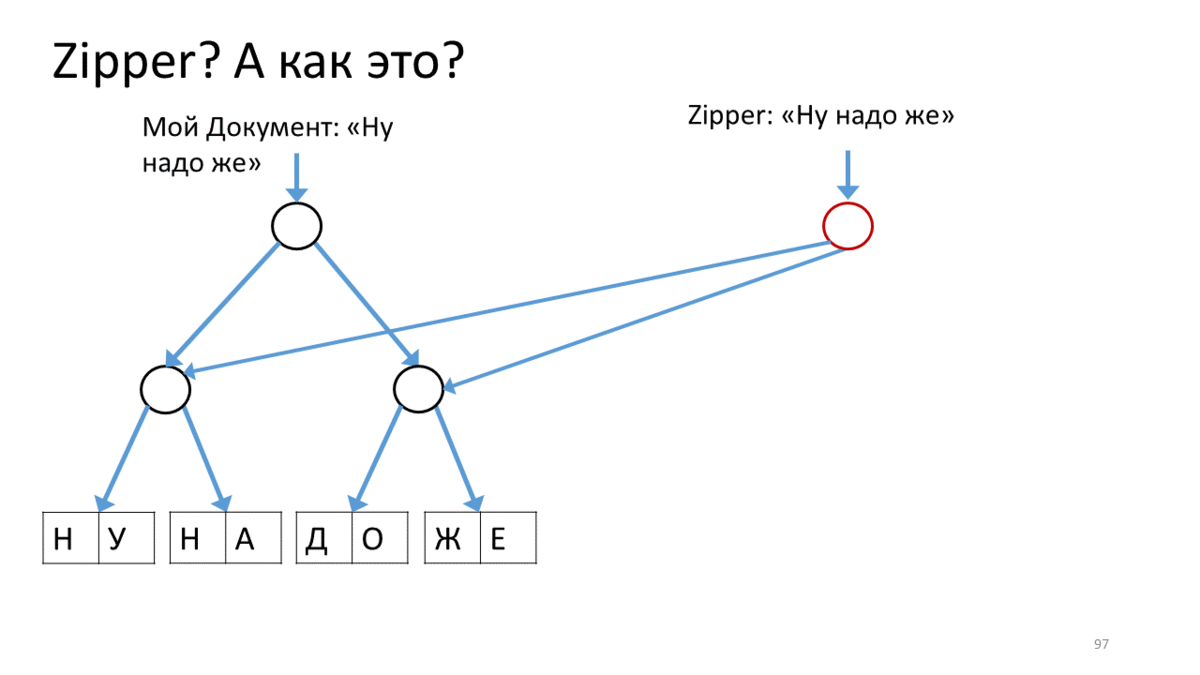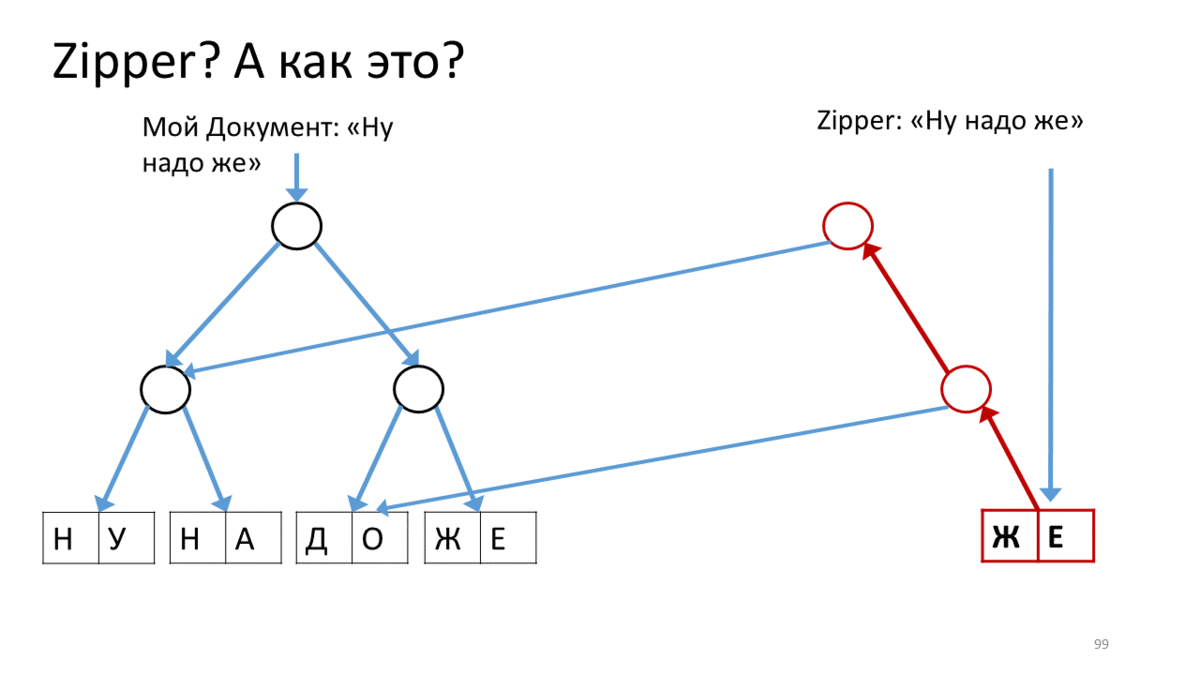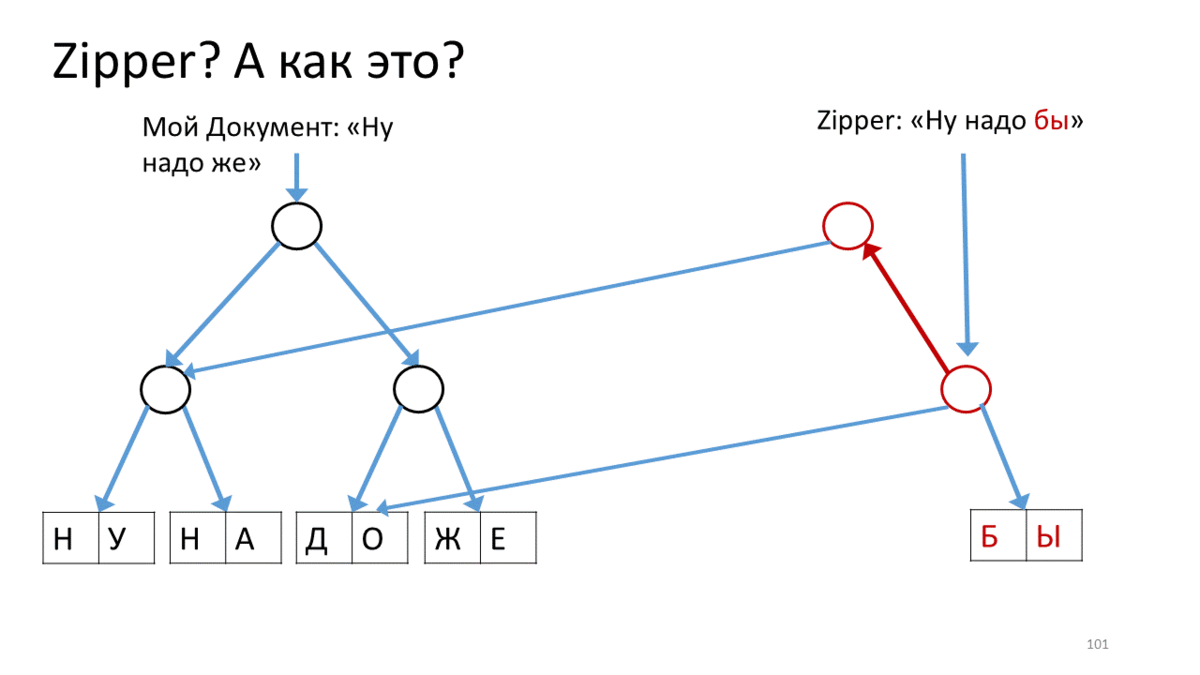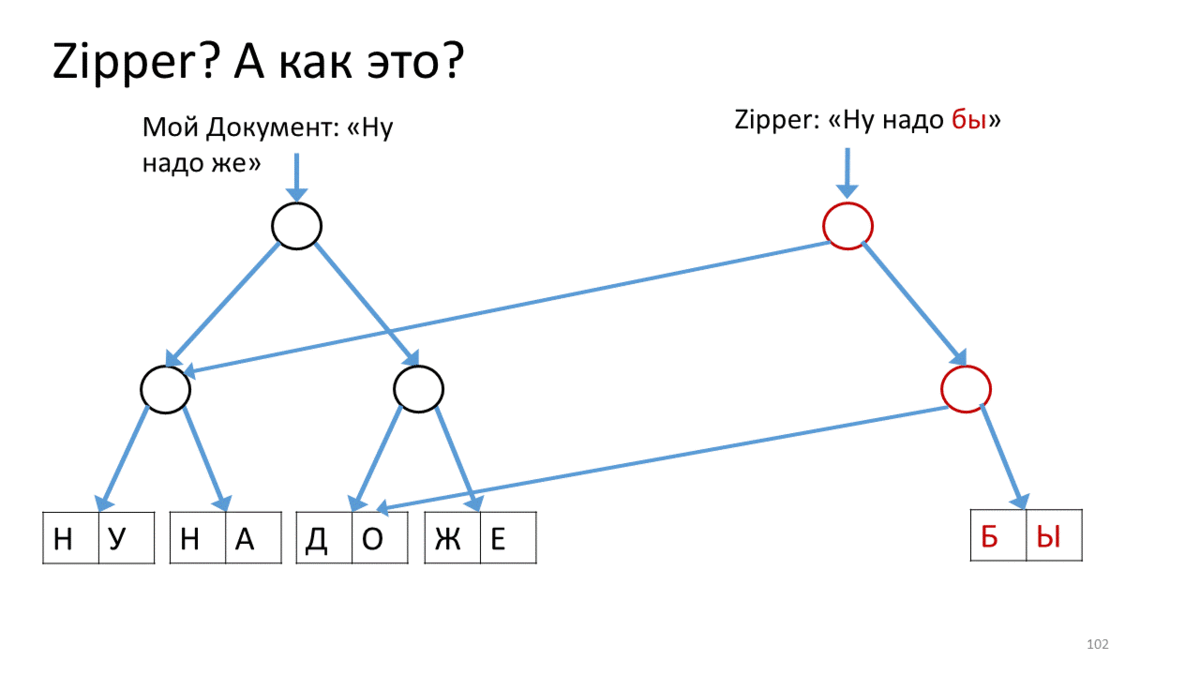
Zipper , (« »). Zipper' . — . (), , . , Zipper, - , . , , , ( ). , ( ). , . , .
, .
? -, , , , . , , . -, , . . Gracias
→
→
Referencias
Zipper data structureCRDT in Xi Editor,
Visual Studio Code editor Piece Table .
, -
.
¿Desea informes aún más potentes, incluido Java 11? Entonces te esperamos en Joker 2018 . Oradores este año: Josh Long, John McClean, Marcus Hirth, Robert Scholte y otros oradores igualmente geniales. Quedan 17 días antes de la conferencia. Entradas en el sitio.