El 22 de septiembre, celebramos nuestro primer mitap no estándar para desarrolladores de sistemas altamente cargados. Fue genial, recibió muchos comentarios positivos sobre los informes y, por lo tanto, decidió no solo subirlos, sino también descifrarlos para Habr. Hoy publicamos un discurso de Ivan Bubnov, DevOps de BIT.GAMES. Habló sobre la implementación del servicio de descubrimiento de Cónsul en un proyecto de alta carga que ya funciona para la posibilidad de escalar rápidamente y conmutar por error los servicios con estado. Y también sobre la organización de un espacio de nombres flexible para aplicaciones de backend y dificultades. Ahora una palabra para Ivan.Administro la infraestructura de producción en el estudio BIT.GAMES y cuento la historia de la implementación del cónsul de Hashicorp en nuestro proyecto "Guild of Heroes" - RPG de fantasía con pvp asíncrono para dispositivos móviles. Disponible en Google Play, App Store, Samsung, Amazon. DAU alrededor de 100,000, en línea de 10 a 13 mil. Creamos el juego en Unity, por lo que escribimos el cliente en C # y usamos nuestro propio lenguaje de secuencias de comandos BHL para la lógica del juego. Escribimos la parte del servidor en Golang (cambiado desde PHP). Lo siguiente es la arquitectura esquemática de nuestro proyecto.
 De hecho, hay muchos más servicios, solo hay lo básico de la lógica del juego.
De hecho, hay muchos más servicios, solo hay lo básico de la lógica del juego.Entonces lo que tenemos. De los servicios apátridas, estos son:
- nginx, que usamos como frontend y balanceadores de carga y distribuimos clientes a nuestros backends por coeficientes de peso;
- gamed: backends, aplicaciones compiladas de Go. Este es el eje central de nuestra arquitectura, realizan la mayor parte del trabajo y se comunican con todos los demás servicios de back-end.
De los servicios de Stateful, los principales que tenemos son:
- Redis, que utilizamos para almacenar en caché la información activa (también la utilizamos para organizar chat en el juego y almacenar notificaciones para nuestros jugadores);
- Percona Server para Mysql es un repositorio de información persistente (probablemente la más grande y lenta de cualquier arquitectura). Usamos la bifurcación de MySQL y aquí hablaremos de ello con más detalle hoy.
Durante el proceso de diseño, nosotros (como todos los demás) esperamos que el proyecto tenga éxito y proporcione un mecanismo de fragmentación. Se compone de dos entidades de base de datos MAINDB y los propios fragmentos.

MAINDB es un tipo de tabla de contenido: almacena información sobre qué datos de fragmentos particulares sobre el progreso del jugador se almacenan. Por lo tanto, la cadena completa de recuperación de información se ve más o menos así: el cliente accede a la interfaz, que a su vez la redistribuye por peso a uno de los backends, el backend va a MAINDB, localiza el fragmento del jugador y luego selecciona los datos directamente del fragmento en sí.
Pero cuando diseñamos, no éramos un gran proyecto, por lo que decidimos hacer fragmentos de fragmentos solo nominalmente. Todos estaban ubicados en el mismo servidor físico y muy probablemente particionando la base de datos dentro del mismo servidor.
Para la copia de seguridad, utilizamos la réplica clásica de esclavo maestro. No fue una muy buena solución (diré por qué un poco más tarde), pero el principal inconveniente de esa arquitectura fue que todos nuestros backends sabían sobre otros servicios de backend exclusivamente por direcciones IP. Y en el caso de otro accidente ridículo en el centro de datos del tipo "lo
siento, nuestro ingeniero golpeó el cable de su servidor mientras reparaba otro y nos tomó mucho tiempo descubrir por qué su servidor no se pone en contacto ". En primer lugar, esta es la reconstrucción y preinstalación de backends desde el servidor de respaldo IP para el lugar del que falló. En segundo lugar, después del incidente, es necesario restaurar a nuestro maestro del respaldo de la reserva, porque estaba en un estado inconsistente y llevarlo a un estado coordinado utilizando la misma replicación. Luego volvimos a montar backends y volvimos a cargar. Todo esto, por supuesto, causó tiempo de inactividad.
Llegó un momento en que nuestro director técnico (por lo que le agradezco mucho) dijo: "Chicos, dejen de sufrir, tenemos que cambiar algo, busquemos salidas". En primer lugar, queríamos lograr un proceso de escalado y migración simple, comprensible y, lo que es más importante, fácil de administrar, de un lugar a otro de nuestras bases de datos si es necesario. Además, queríamos lograr una alta disponibilidad mediante la automatización de la conmutación por error.
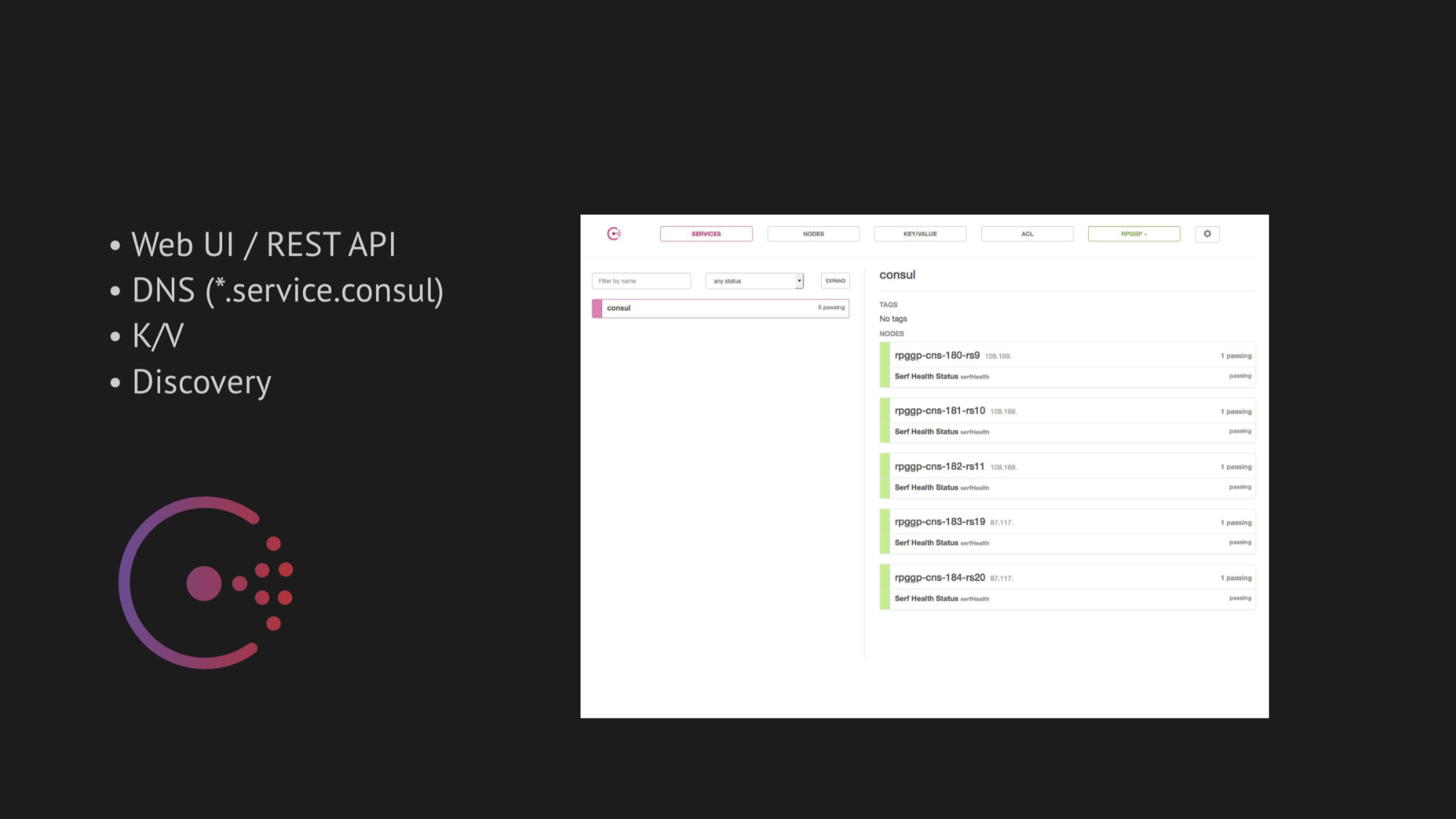
El eje central de nuestra investigación se ha convertido en Cónsul de Hashicorp. En primer lugar, nos aconsejaron, y en segundo lugar, nos atrajo su simplicidad, amabilidad y excelente tecnología en una caja: servicio de descubrimiento con verificación de salud, almacenamiento de valor clave y lo más importante que queríamos usar era DNS que nos resuelve direcciones del dominio service.consul.
Consul también proporciona excelentes interfaces de usuario web y API REST para administrar todo esto.
En cuanto a la alta disponibilidad, elegimos dos utilidades para la conmutación por error automática:
- MHA para MySQL
- Redis-centinela

En el caso de MHA para MySQL, vertimos agentes en nodos con bases de datos, y esos monitorearon su estado. Hubo un cierto tiempo de espera con la falla del maestro, después de lo cual se hizo una detención de esclavo para mantener la coherencia y nuestro maestro de respaldo del maestro aparecido en un estado inconsistente no tomó los datos. Y agregamos un enlace web a estos agentes, que registraron allí la nueva IP del maestro de respaldo en el propio Cónsul, luego de lo cual se introdujo la emisión de DNS.
Con Redis-sentinel, todo es aún más simple. Como él mismo lleva a cabo la mayor parte del trabajo, todo lo que nos quedaba por hacer era tener en cuenta en el chequeo de salud que Redis-centinela debería tener lugar exclusivamente en el nodo maestro.
Al principio todo funcionó perfectamente, como un reloj. No tuvimos problemas en el banco de pruebas. Pero valió la pena pasar al entorno natural de transferencia de datos de un centro de datos cargado, recordando algunas muertes de OOM (esto está fuera de la memoria, en el que el núcleo del sistema mata el proceso) y restaurando el servicio o cosas más sofisticadas que afectan la disponibilidad del servicio. ¿Cómo obtuvimos inmediatamente un riesgo grave de falsos positivos o ninguna respuesta garantizada (si intenta torcer algunas comprobaciones en un intento de escapar de los falsos positivos)?

En primer lugar, todo depende de la dificultad de escribir el chequeo de salud correcto. Parece que la tarea es bastante trivial: compruebe que el servicio se esté ejecutando en su servidor y puerto pingani. Pero, como lo ha demostrado la práctica posterior, escribir un chequeo de salud al implementar Consul es un proceso extremadamente complejo y lento. Debido a que no se pueden prever tantos factores que afectan la disponibilidad de su servicio en el centro de datos, se detectan solo después de un cierto tiempo.
Además, el centro de datos no es una estructura estática con la que está inundado y funciona según lo previsto. Pero nosotros, desafortunadamente (o afortunadamente), descubrimos esto solo más tarde, pero por ahora estábamos inspirados y llenos de confianza de que implementaríamos todo en la producción.

En cuanto a la escala, diré brevemente: tratamos de encontrar una bicicleta terminada, pero todas están diseñadas para arquitecturas específicas. Y, como en el caso de Jetpants, no pudimos cumplir con las condiciones que impuso a la arquitectura de un almacenamiento persistente de información.
Por lo tanto, pensamos en nuestro propio guión vinculante y pospusimos esta pregunta. Decidimos actuar consistentemente y comenzar con la implementación de Consul.

Consul es un clúster descentralizado y distribuido que funciona según el protocolo de chismes y el algoritmo de consenso Raft.
Tenemos un equorum independiente de cinco servidores (cinco para evitar la situación de cerebro dividido). Para cada nodo, derramamos el agente Cónsul en modo agente y derramamos todas las comprobaciones de estado (es decir, no hubo tal forma de cargar una comprobación de estado a un servidor específico y otras a servidores específicos). Healthcheck se escribió para que pasen solo donde hay un servicio.
También utilizamos otra utilidad para no tener que aprender nuestro backend para resolver direcciones de un dominio específico en un puerto no estándar. Utilizamos Dnsmasq: proporciona la capacidad de resolver de forma completamente transparente las direcciones en los nodos del clúster que necesitamos (que en el mundo real, por así decirlo, no existen, sino que existen exclusivamente dentro del clúster). Preparamos un script automático para llenar Ansible, lo subimos todo a producción, ajustamos el espacio de nombres y nos aseguramos de que todo estuviera completo. Y, cruzando los dedos, volvimos a cargar nuestros backends, a los que se accedió no por direcciones IP, sino por estos nombres del dominio server.consul.
Todo comenzó la primera vez, nuestra alegría no conocía límites. Pero era demasiado temprano para alegrarnos, porque en una hora notamos que en todos los nodos donde se encuentran nuestros backends, el indicador de carga promedio aumentó de 0.7 a 1.0, que es un indicador bastante gordo.
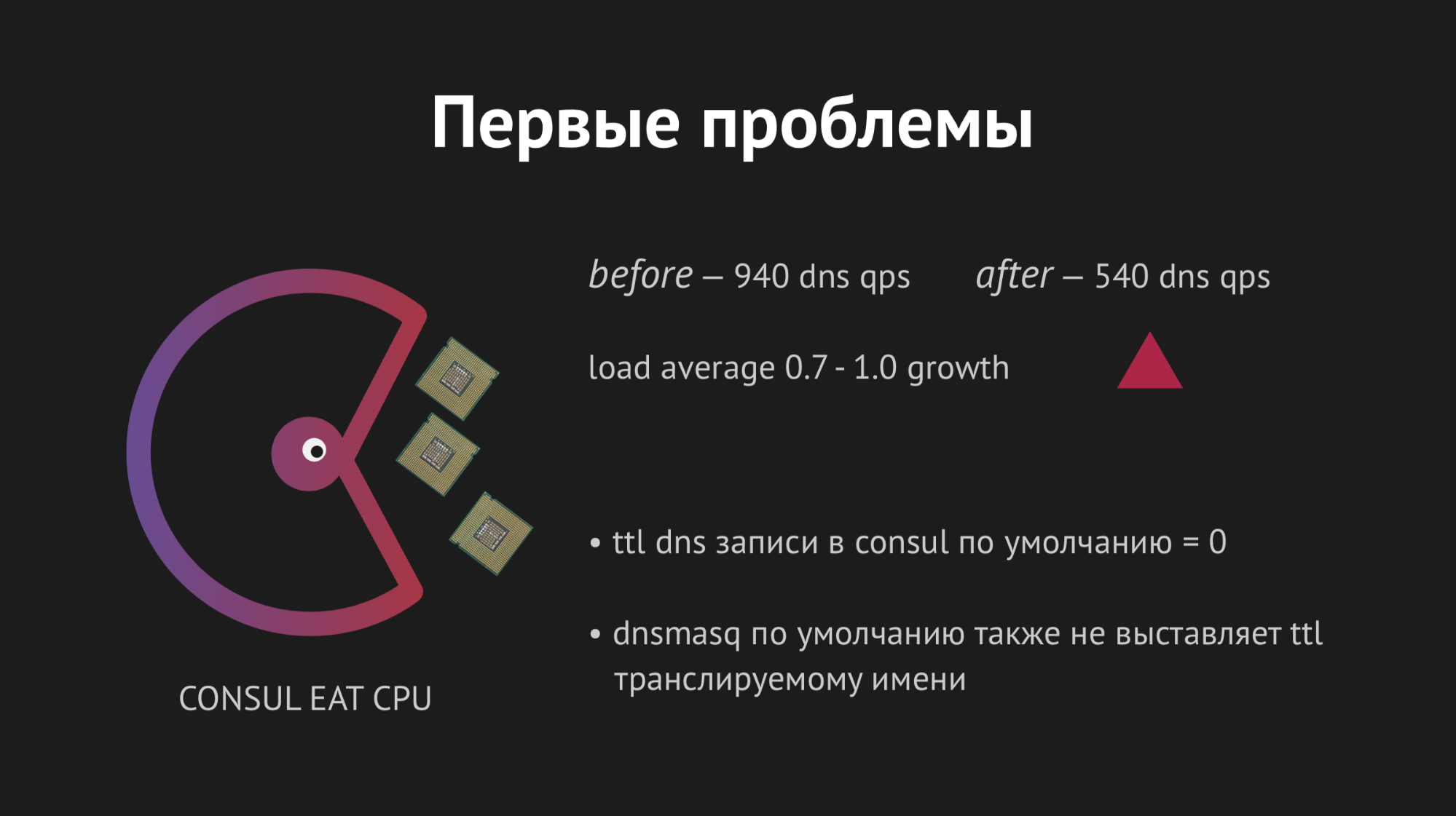
Me subí al servidor para ver qué estaba pasando y se hizo evidente que la CPU se estaba comiendo Consul. Aquí comenzamos a resolverlo, comenzamos a chamanizar con strace (una utilidad para sistemas unix que le permite rastrear qué syscall se está ejecutando el proceso), volcando las estadísticas de Dnsmasq para comprender lo que está sucediendo en este nodo, y resultó que perdimos un punto muy importante. Al planear la integración, nos perdimos el almacenamiento en caché de los registros DNS y resultó que nuestro backend sacó Dnsmasq para cada uno de sus movimientos, y que, a su vez, recurrió al Cónsul y todo esto resultó en 940 consultas DNS por segundo.
La salida parecía obvia: solo gire ttl y todo mejorará. Pero aquí era imposible ser fanático, porque queríamos implementar esta estructura con el fin de obtener un espacio de nombres dinámico, fácil de controlar y que cambiara rápidamente (por lo tanto, no pudimos establecer, por ejemplo, 20 minutos). Cambiamos ttl a los valores óptimos máximos para nosotros, logramos reducir la tasa de consulta por segundo a 540, pero esto no afectó el indicador de consumo de CPU.
Luego decidimos salir de una manera complicada, usando un archivo de host personalizado.
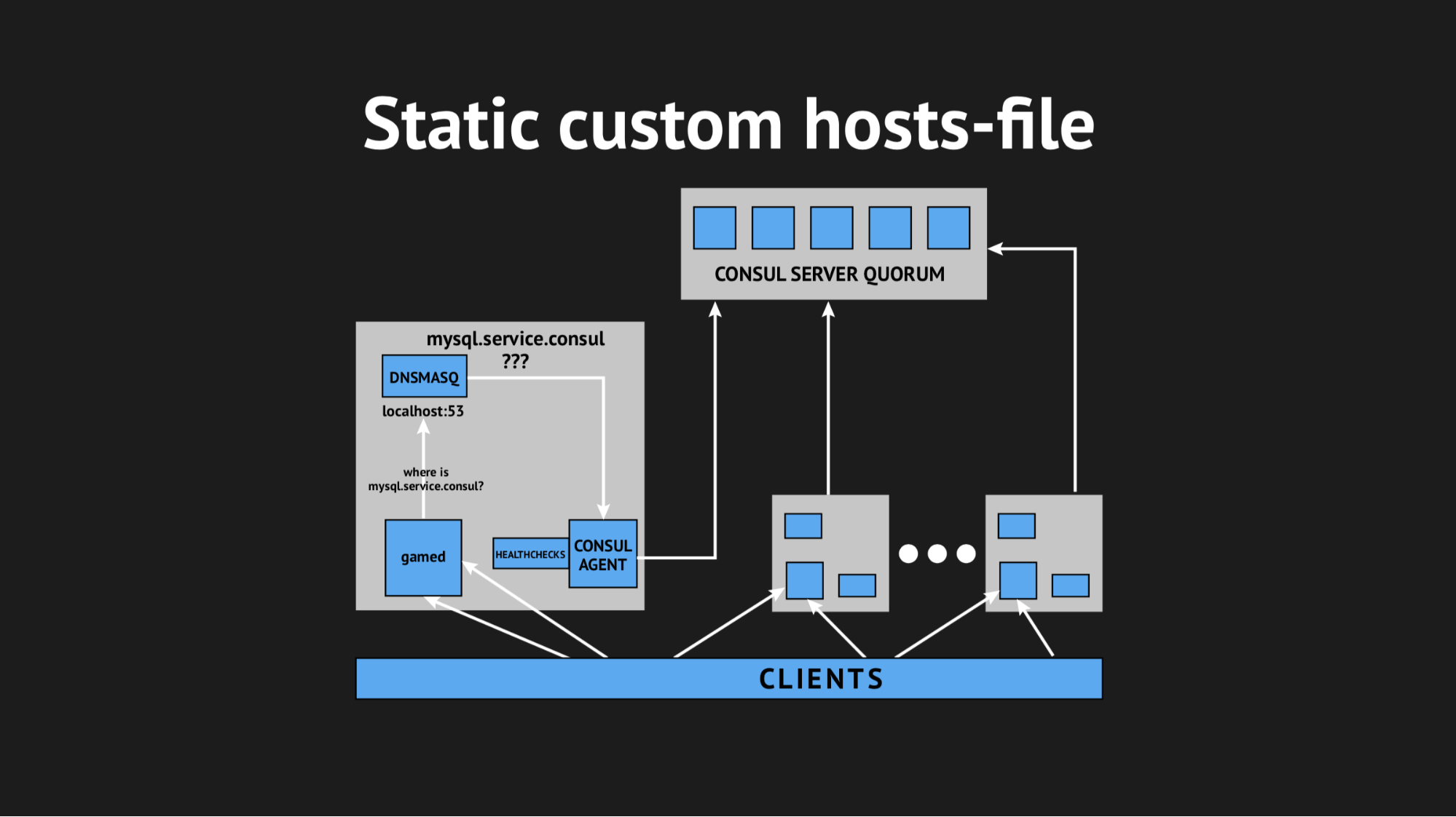
Es bueno que tengamos todo para esto: un excelente sistema de plantillas de Consul, que, según el estado del clúster y el script de plantilla, genera un archivo de cualquier tipo, cualquier configuración es todo lo que desea. Además, Dnsmasq tiene un parámetro de configuración addn-hosts que le permite utilizar un archivo de host que no sea del sistema como el mismo archivo de host adicional.
Lo que hicimos, nuevamente preparó el guión en Ansible, lo subió a producción y comenzó a parecerse a esto:
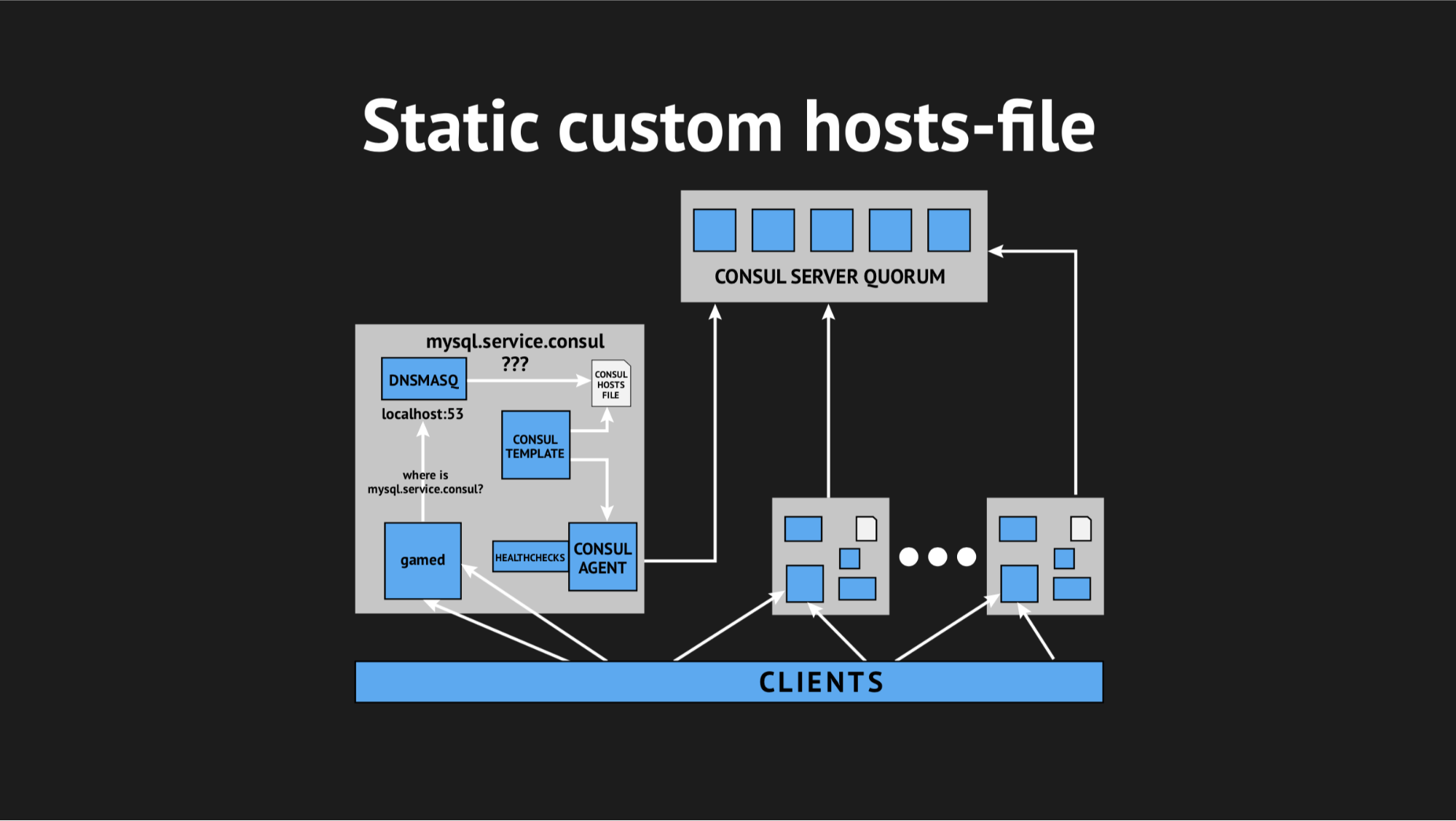
Había un elemento adicional y un archivo estático en el disco, que se regenera con bastante rapidez. Ahora la cadena parecía bastante simple: Gamed se volvió hacia Dnsmasq, y eso a su vez (en lugar de tirar del agente Consula, que preguntaría a los servidores dónde teníamos este o aquel nodo) solo miró el archivo. Esto resolvió el problema con el consumo de CPU por parte de Consul.
Ahora todo comenzó a verse como lo planeamos, absolutamente transparente para nuestra producción, prácticamente sin consumir recursos.
Estábamos bastante atormentados ese día y con gran aprensión nos fuimos a casa. No tuvieron miedo en vano, porque por la noche una alerta del monitoreo me despertó y me informó que teníamos una explosión de errores a gran escala (aunque a corto plazo).
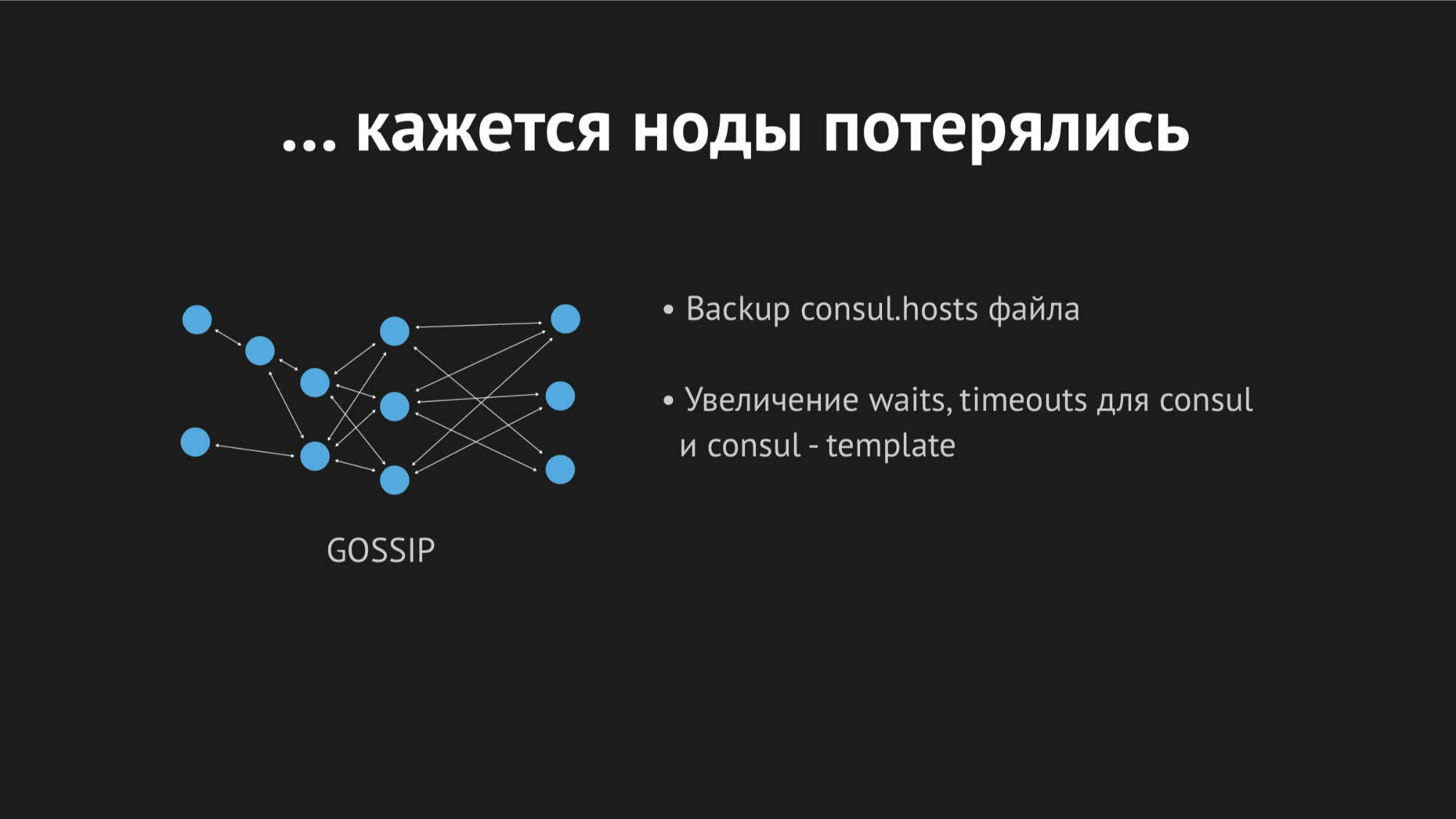
Al tratar con los registros en la mañana, vi que todos los errores eran del mismo tipo de host desconocido. No estaba claro por qué Dnsmasq no podía usar uno u otro servicio de un archivo; parecía que no existía en absoluto. Para tratar de comprender lo que estaba sucediendo, agregué una métrica personalizada para volver a generar el archivo; ahora sabía exactamente el momento en que se regeneraría. Además, la propia plantilla de Cónsul tiene una excelente opción de respaldo, es decir Puede ver el estado anterior del archivo regenerado.
Durante el día, el incidente se repitió varias veces y quedó claro que en algún momento (aunque era esporádico, de naturaleza no sistemática), el archivo de hosts sin ningún servicio específico se volvería a procesar. Resultó que en un centro de datos en particular (no haré antipublicidad) hay redes bastante inestables: debido al fracaso de las redes, dejamos de pasar imprevisiblemente, o incluso los nodos se cayeron del clúster. Se parecía a esto:
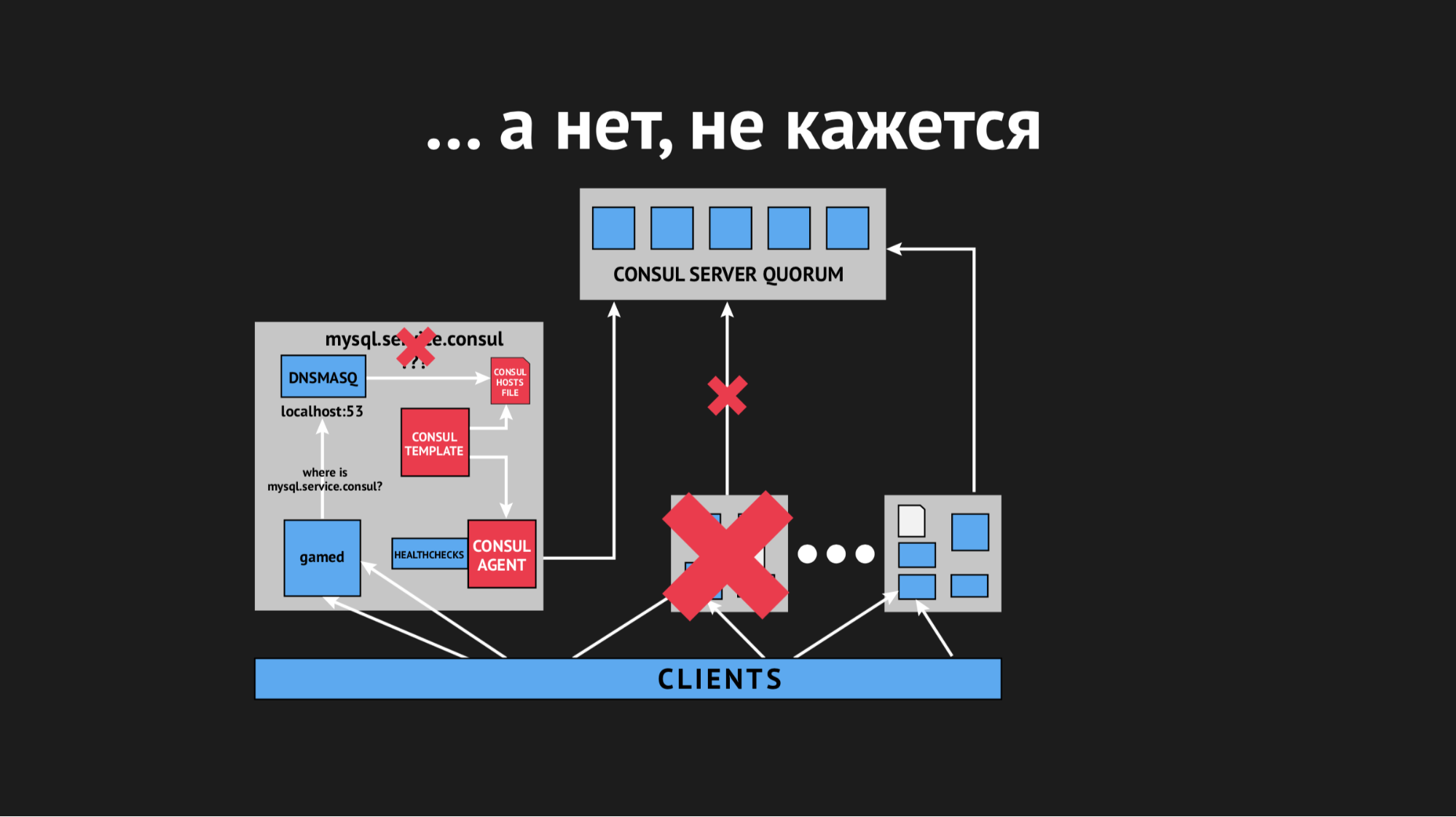
El nodo se cayó del clúster, el agente del Cónsul fue notificado de inmediato sobre esto, y la plantilla del Cónsul regeneró inmediatamente el archivo de hosts sin el servicio que necesitábamos. En general, esto era inaceptable, porque el problema es ridículo: si el servicio no está disponible durante unos segundos, configure tiempos de espera y retransmisiones (no se conectaron una vez, pero la segunda vez resultó). Pero provocamos una nueva estructura en el vendedor cuando el servicio simplemente desaparece de la vista y no hay forma de conectarse a él.
Comenzamos a pensar qué hacer y torcer el parámetro de tiempo de espera en Consul, después de lo cual se identifica después de cuánto se cae el nodo. Logramos resolver este problema con un indicador bastante pequeño, los nodos dejaron de caerse, pero esto no ayudó con el chequeo de salud.
Comenzamos a pensar en elegir diferentes parámetros para el chequeo de salud, tratando de entender de alguna manera cuándo y cómo sucede esto. Pero debido al hecho de que todo sucedió de forma esporádica e impredecible, no pudimos hacerlo.
Luego fuimos a la plantilla de Cónsul y decidimos hacer un tiempo de espera para ello, después de lo cual reacciona a un cambio en el estado del clúster. Nuevamente, era imposible ser fanático, porque podíamos llegar a una situación en la que el resultado no sería mejor que el DNS clásico, cuando apuntamos a uno completamente diferente.
Y una vez más, nuestro director técnico vino al rescate y dijo: "Chicos, intentemos renunciar a toda esta interactividad, tenemos todo en producción y no tenemos tiempo para investigar, necesitamos resolver este problema. Aprovechemos las cosas simples y comprensibles ". Entonces llegamos al concepto de usar el almacenamiento de valores clave como fuente para generar un archivo de hosts.
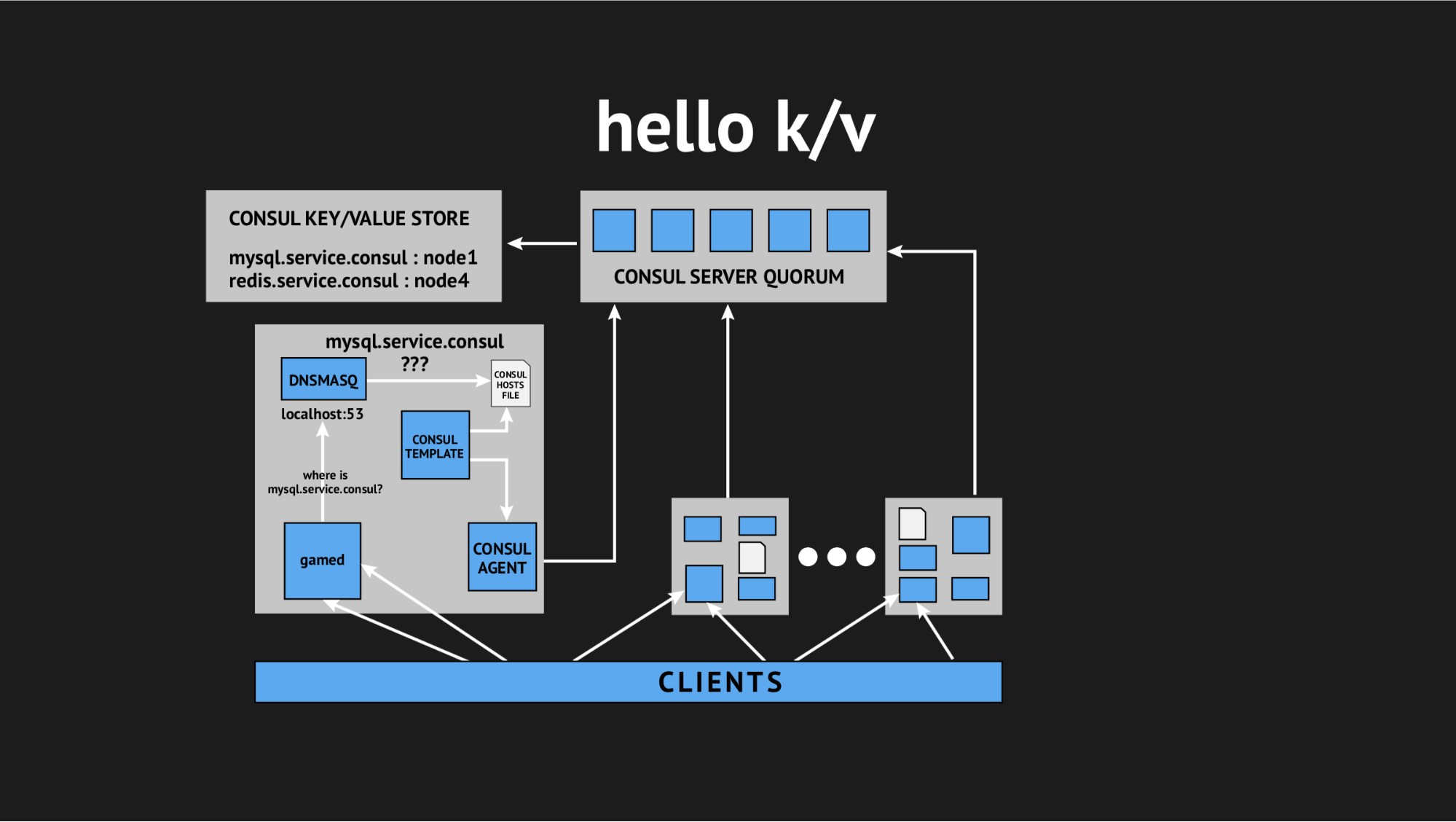
Cómo se ve: rechazamos todas las comprobaciones de estado dinámicas, reescribimos nuestro script de plantilla para que genere un archivo basado en los datos registrados en el almacenamiento de valores-clave. En el almacenamiento de valores clave, describimos toda nuestra infraestructura en forma de nombre clave (este es el nombre del servicio que necesitamos) y el valor clave (este es el nombre del nodo en el clúster). Es decir si el nodo está presente en el clúster, entonces obtenemos fácilmente su dirección IP y la escribimos en el archivo de hosts.
Probamos todo, lo llenamos en producción y se convirtió en una bala de plata en una situación específica. Una vez más, nos atormentamos durante todo el día, volvimos a casa, pero regresamos descansados, entusiasmados, porque estos problemas ya no se repitieron y no se repitieron en la presentación durante un año. De lo cual personalmente concluyo que esta fue la decisión correcta (específicamente para nosotros).
Entonces Finalmente obtuvimos lo que queríamos y organizamos un espacio de nombres dinámico para nuestros backends. Además, nos dirigimos a garantizar una alta disponibilidad.

Pero el hecho es que está bastante asustado de la integración del cónsul y, debido a los problemas que encontramos, pensamos y decidimos que introducir la conmutación por error automática no es una buena solución, porque de nuevo corremos el riesgo de falsos positivos o fallas Este proceso es opaco e incontrolable.
Por lo tanto, seguimos un camino más simple (o complejo): decidimos dejar la conmutación por error en la conciencia del administrador de turno, pero le dimos otra herramienta adicional. Hemos reemplazado la replicación maestra esclava por la replicación maestra maestra en modo de solo lectura. Esto elimina una gran cantidad de dolor de cabeza en el proceso de failover'ov: cuando obtienes un asistente, todo lo que necesitas hacer es cambiar el valor en k / v-storage usando la interfaz de usuario web o un comando en la API y antes de eso, modo de solo lectura maestro de respaldo.
Una vez que termina el incidente, el maestro contacta y automáticamente llega a un estado coordinado sin acciones innecesarias. Nos detuvimos en esta opción y la usamos como antes: para nosotros es lo más conveniente posible y, lo más importante, lo más simple, claro y controlado posible.
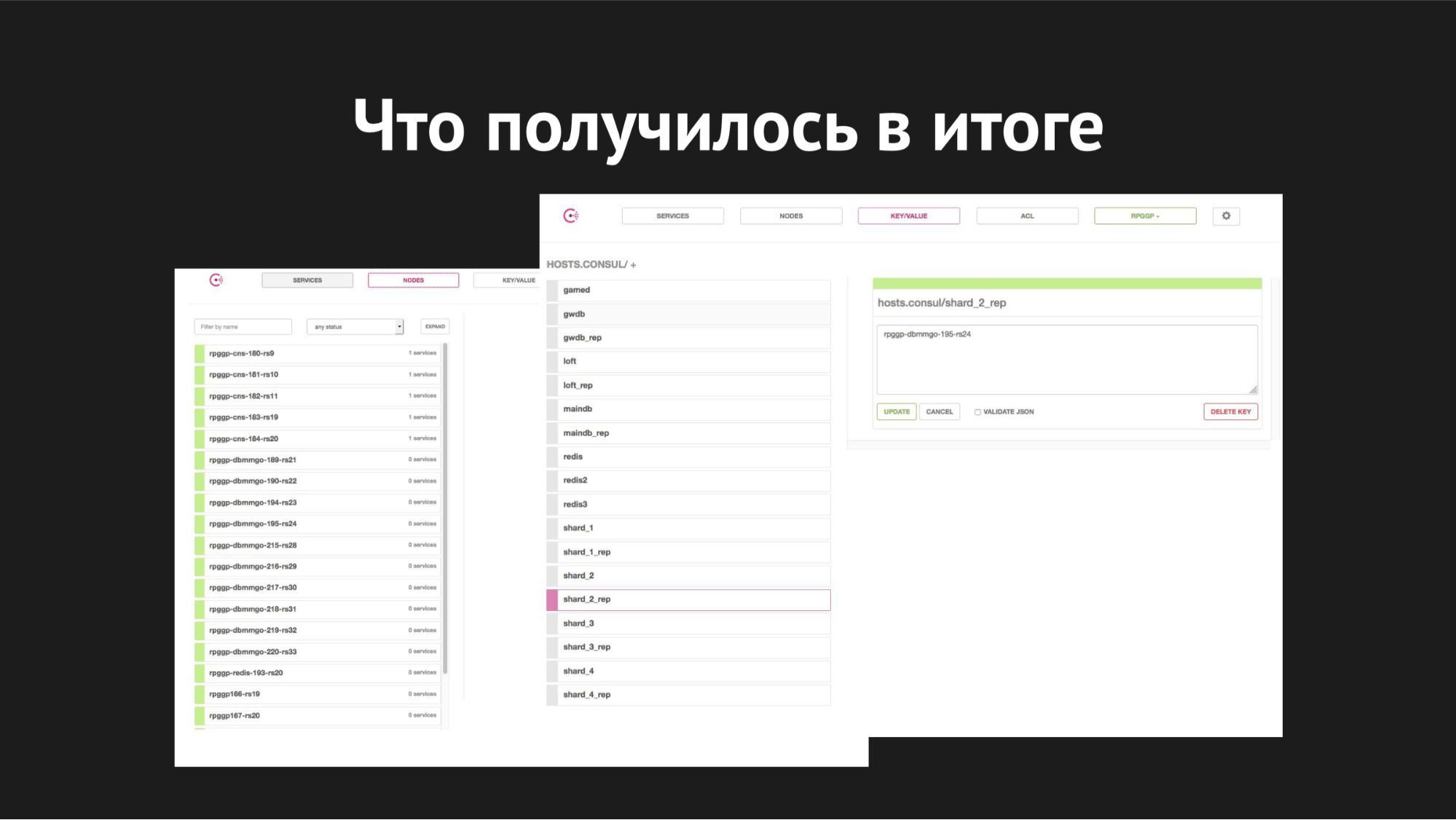 Interfaz web cónsul
Interfaz web cónsulA la derecha está el almacenamiento de k / v y nuestros servicios son visibles, que utilizamos en gamed; valor es el nombre del nodo.
En cuanto al escalado, comenzamos a implementarlo cuando los fragmentos ya estaban abarrotados en un servidor, las bases crecieron, se volvieron lentas, el número de jugadores aumentó, intercambiamos y tuvimos la tarea de distribuir todos los fragmentos a nuestros diferentes servidores separados.

Cómo se veía: usando la utilidad XtraBackup, restauramos nuestra copia de seguridad en un nuevo par de servidores, después de lo cual el nuevo maestro fue colgado con un esclavo en el anterior. Llegó a un estado consistente, cambiamos el valor clave en k / v-storage del nombre del nodo del maestro antiguo al nombre del nodo del nuevo maestro. Luego (cuando creíamos que todo iba correctamente y todo se jugaba con sus selecciones, actualizaciones, inserciones para el nuevo maestro), solo teníamos que eliminar la replicación y crear la codiciada base de datos de caída en producción, ya que a todos nos encanta hacer con bases de datos innecesarias.

Así que destrozamos los fragmentos. Todo el proceso de movimiento duró de 40 minutos a una hora y no causó el tiempo de inactividad de nadie, fue completamente transparente para nuestros backends y por sí solo fue completamente transparente para los jugadores (excepto que tan pronto como se movieron, se volvió más fácil y más agradable para ellos jugar).

En cuanto a los procesos de conmutación por error, aquí el tiempo de conmutación es de 20 a 40 segundos, más el tiempo de reacción del administrador del sistema en servicio. Así es como se ve todo con nosotros ahora.
Lo que me gustaría decir como conclusión: desafortunadamente, nuestras esperanzas de una automatización absoluta e integral se han estrellado contra la dura realidad del medio de transmisión de datos en un centro de datos cargado y factores aleatorios que no podíamos prever.
En segundo lugar, nos enseñó una vez más que una teta simple y probada en manos del administrador de su sistema es mejor que una grúa nueva, auto-reaccionante y autoescalada en algún lugar más allá de las nubes, que ni siquiera comprende si se está cayendo a pedazos o si realmente comenzó a escalar.
La introducción de cualquier infraestructura, la automatización en su producción no debería causar un dolor de cabeza innecesario para el personal que lo atiende; no debería aumentar significativamente el costo de mantener la producción de infraestructura: la solución debe ser simple, clara, transparente para sus clientes, conveniente y controlada.
Preguntas de la audiencia
¿Cómo se escribe k / v con servidores? ¿Un script o simplemente lo parcheas?K/v- Consul- - , http- RESTful API Web UI.
, - , , .
, Redis?, - .
-, backend. -, backend', — . Es decir , MAINDB , . . - , .
- , inmemory key-value -.
?MySQL — Percona server.
? Maria, MHA for MySQL, Galera.Galera. - « » Galera , . , .
, — , , - , , , .
Pixonic DevGAMM Talks