Hola, Habr, en este artículo hablaré sobre la biblioteca ignite , con la que puedes entrenar y probar fácilmente redes neuronales usando el marco PyTorch.
Con ignite, puede escribir ciclos para entrenar la red en solo unas pocas líneas, agregar el cálculo de métricas estándar desde el cuadro, guardar el modelo, etc. Bueno, para aquellos que se mudaron de TF a PyTorch, podemos decir que la biblioteca de ignición es Keras para PyTorch.
El artículo examinará en detalle un ejemplo de entrenamiento de una red neuronal para una tarea de clasificación usando ignite.

Agrega más fuego a PyTorch
No perderé tiempo hablando de lo genial que es el framework PyTorch. Cualquiera que ya lo haya usado entiende de lo que estoy escribiendo. Pero, con todas sus ventajas, todavía es de bajo nivel en términos de ciclos de escritura para entrenamiento, prueba, prueba de redes neuronales.
Si observamos ejemplos oficiales del uso del marco PyTorch, veremos al menos dos ciclos de iteraciones por época y por lotes del conjunto de entrenamiento en el código de entrenamiento de la cuadrícula:
for epoch in range(1, epochs + 1): for batch_idx, (data, target) in enumerate(train_loader):
La idea principal de la biblioteca ignite es factorizar estos bucles en una sola clase, mientras permite al usuario interactuar con estos bucles utilizando controladores de eventos.
Como resultado, en el caso de las tareas estándar de aprendizaje profundo, podemos ahorrar mucho en la cantidad de líneas de código. Menos líneas, ¡menos errores!
Por ejemplo, a modo de comparación, a la izquierda está el código para el entrenamiento y la validación del modelo usando ignite , y a la derecha está PyTorch puro:
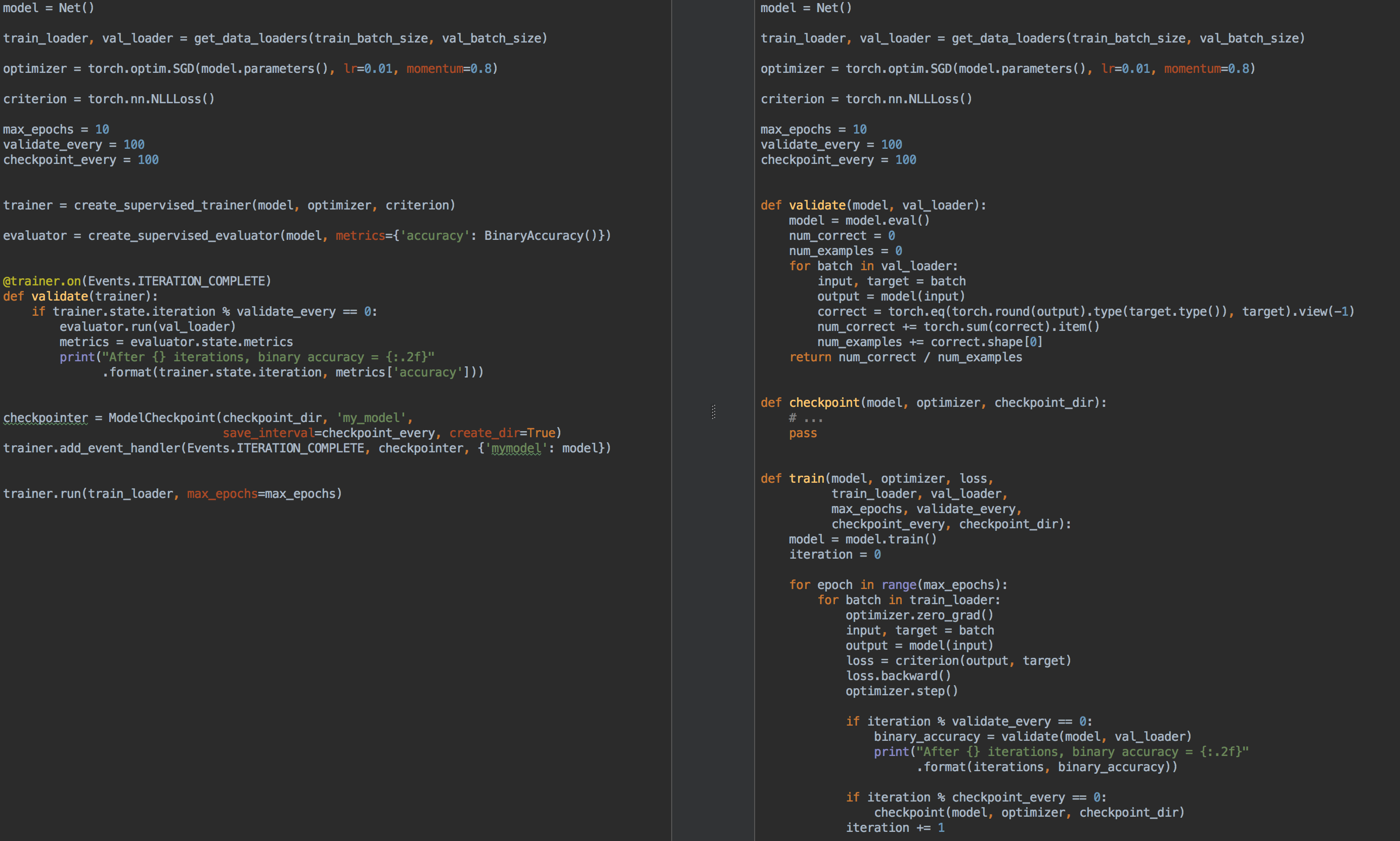
Entonces, de nuevo, ¿para qué sirve ignite ?
- ya no necesita escribir para cada
for epoch in range(n_epochs) tareas for epoch in range(n_epochs) y for batch in data_loader . - le permite factorizar mejor el código
- le permite calcular métricas básicas fuera de la caja
- proporciona "bollos" de tipo
- guardar los últimos y mejores modelos (también optimizador y programador de velocidad de aprendizaje) durante el entrenamiento,
- temprano deja de aprender
- etc.
- se integra fácilmente con herramientas de visualización: tensorboardX, visdom, ...
En cierto sentido, como ya se mencionó, la biblioteca ignite se puede comparar con todos los famosos Keras y su API para redes de capacitación y prueba. Además, la biblioteca ignite a primera vista es muy similar a la biblioteca tnt , ya que inicialmente ambas bibliotecas tenían objetivos comunes y tenían ideas similares para su implementación.
Entonces, enciende:
pip install pytorch-ignite
o
conda install ignite -c pytorch
A continuación, con un ejemplo específico, nos familiarizaremos con la API de ignite library.
Tarea de clasificación con ignite
En esta parte del artículo, consideraremos un ejemplo escolar de entrenamiento de una red neuronal para el problema de clasificación usando la biblioteca ignite .
Entonces, tomemos un conjunto de datos simple con imágenes de frutas con kaggle . La tarea es asociar una clase correspondiente con cada imagen de fruta.
Antes de usar ignite , definamos los componentes principales:
Flujo de datos
- cargador de muestra de entrenamiento, cargador de
train_loader - pago por lotes descargador,
val_loader
Modelo:
- tomar la pequeña red
torchvision de torchvision
Algoritmo de Optimización:
Función de pérdida:
Código from pathlib import Path import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torch.utils.data.dataset import Subset from torchvision.datasets import ImageFolder from torchvision.transforms import Compose, RandomResizedCrop, RandomVerticalFlip, RandomHorizontalFlip from torchvision.transforms import ColorJitter, ToTensor, Normalize FRUIT360_PATH = Path(".").resolve().parent / "input" / "fruits-360_dataset" / "fruits-360" device = "cuda" train_transform = Compose([ RandomHorizontalFlip(), RandomResizedCrop(size=32), ColorJitter(brightness=0.12), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) val_transform = Compose([ RandomResizedCrop(size=32), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) batch_size = 128 num_workers = 8 train_dataset = ImageFolder((FRUIT360_PATH /"Training").as_posix(), transform=train_transform, target_transform=None) val_dataset = ImageFolder((FRUIT360_PATH /"Test").as_posix(), transform=val_transform, target_transform=None) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
import torch.nn as nn from torchvision.models.squeezenet import squeezenet1_1 model = squeezenet1_1(pretrained=False, num_classes=81) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device)
import torch.nn as nn from torch.optim import SGD optimizer = SGD(model.parameters(), lr=0.01, momentum=0.5) criterion = nn.CrossEntropyLoss()
Así que ahora es el momento de ejecutar ignite :
from ignite.engine import Engine, _prepare_batch def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item() trainer = Engine(process_function)
Veamos qué significa este código.
Motor Engine
La clase ignite.engine.Engine es el marco de la biblioteca, y el objeto de esta clase es el trainer :
trainer = Engine(process_function)
Se define con la función de entrada process_function para procesar un lote y sirve para implementar pases para la muestra de entrenamiento. Dentro de la clase ignite.engine.Engine , sucede lo siguiente:
while epoch < max_epochs:
Volver a la función process_function :
def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item()
Vemos que dentro de la función nosotros, como es habitual en el caso del modelo de entrenamiento, calculamos las predicciones y_pred , calculamos la función de loss , loss y gradientes. Este último le permite actualizar el peso del modelo: optimizer.step() .
En general, no hay restricciones en el código de la función process_function . Solo notamos que toma dos argumentos como entrada: el objeto Engine (en nuestro caso, el trainer ) y el lote del cargador de datos. Por lo tanto, por ejemplo, para probar una red neuronal, podemos definir otro objeto de la clase ignite.engine.Engine , en el que la función de entrada simplemente calcula las predicciones e implementa una pasada a través de la muestra de prueba una vez. Lea sobre esto más tarde.
Entonces, el código anterior solo define los objetos necesarios sin comenzar el entrenamiento. Básicamente, en un ejemplo mínimo, puede llamar al método:
trainer.run(train_loader, max_epochs=10)
y este código es suficiente para "en silencio" (sin derivación de resultados intermedios) entrenar el modelo.
Una notaTenga en cuenta también que para tareas de este tipo, la biblioteca tiene un método conveniente para crear el objeto de trainer :
from ignite.engine import create_supervised_trainer trainer = create_supervised_trainer(model, optimizer, criterion, device)
Por supuesto, en la práctica, el ejemplo anterior es de poco interés, así que agreguemos las siguientes opciones para el "entrenador":
- visualización del valor de la función de pérdida cada 50 iteraciones
- inicio del cálculo de métricas en el conjunto de entrenamiento con un modelo fijo
- inicio del cálculo de las métricas en la muestra de prueba después de cada era
- guardar parámetros del modelo después de cada era
- preservación de los tres mejores modelos
- cambio en la velocidad de aprendizaje según la época (programación de la tasa de aprendizaje)
- entrenamiento de parada temprana (parada temprana)
Eventos y controladores de eventos
Para agregar las opciones anteriores para el "entrenador", la biblioteca ignite proporciona un sistema de eventos y el lanzamiento de controladores de eventos personalizados. Por lo tanto, el usuario puede controlar un objeto de la clase Engine en cada etapa:
- arranque del motor / lanzamiento completado
- era comenzó / terminó
- iteración por lotes iniciada / finalizada
y ejecuta tu código en cada evento.
Muestra los valores de la función de pérdida.
Para hacer esto, simplemente determine la función en la que se mostrará la salida en la pantalla y agréguela al "entrenador":
from ignite.engine import Events log_interval = 50 @trainer.on(Events.ITERATION_COMPLETED) def log_training_loss(engine): iteration = (engine.state.iteration - 1) % len(train_loader) + 1 if iteration % log_interval == 0: print("Epoch[{}] Iteration[{}/{}] Loss: {:.4f}" .format(engine.state.epoch, iteration, len(train_loader), engine.state.output))
En realidad, hay dos formas de agregar un controlador de eventos: mediante add_event_handler o mediante el decorador on . Lo mismo que el anterior se puede hacer así:
from ignite.engine import Events log_interval = 50 def log_training_loss(engine):
Tenga en cuenta que cualquier argumento se puede pasar a la función de manejo de eventos. En general, dicha función se verá así:
def custom_handler(engine, *args, **kwargs): pass trainer.add_event_handler(Events.ITERATION_COMPLETED, custom_handler, *args, **kwargs)
Entonces, comencemos a entrenar en una era y veamos qué sucede:
output = trainer.run(train_loader, max_epochs=1)
Epoch[1] Iteration[50/322] Loss: 4.3459 Epoch[1] Iteration[100/322] Loss: 4.2801 Epoch[1] Iteration[150/322] Loss: 4.2294 Epoch[1] Iteration[200/322] Loss: 4.1467 Epoch[1] Iteration[250/322] Loss: 3.8607 Epoch[1] Iteration[300/322] Loss: 3.6688
No esta mal! Vamos más allá.
Comenzar el cálculo de métricas en muestras de entrenamiento y prueba
Calculemos las siguientes métricas: precisión promedio, integridad promedio después de cada era por parte del entrenamiento y la muestra de prueba completa. Tenga en cuenta que calcularemos las métricas por parte de la muestra de entrenamiento después de cada era de entrenamiento, y no durante el entrenamiento. Por lo tanto, la medición de la eficiencia será más precisa, ya que el modelo no cambia durante el cálculo.
Entonces, definimos las métricas:
from ignite.metrics import Loss, CategoricalAccuracy, Precision, Recall metrics = { 'avg_loss': Loss(criterion), 'avg_accuracy': CategoricalAccuracy(), 'avg_precision': Precision(average=True), 'avg_recall': Recall(average=True) }
A continuación, crearemos dos motores para evaluar el modelo usando ignite.engine.create_supervised_evaluator :
from ignite.engine import create_supervised_evaluator
Estamos creando dos motores para adjuntar aún más controladores de eventos adicionales a uno de ellos ( val_evaluator ) para guardar el modelo y dejar de aprender temprano (sobre todo esto a continuación).
Echemos un vistazo más de cerca a cómo se define el motor para evaluar el modelo, a saber, cómo process_function define la función de entrada process_function para procesar un lote:
def create_supervised_evaluator(model, metrics={}, device=None): if device: model.to(device) def _inference(engine, batch): model.eval() with torch.no_grad(): x, y = _prepare_batch(batch, device=device) y_pred = model(x) return y_pred, y engine = Engine(_inference) for name, metric in metrics.items(): metric.attach(engine, name) return engine
Seguimos más allá. Seleccionemos al azar la parte de la muestra de entrenamiento en la que calcularemos las métricas:
import numpy as np from torch.utils.data.dataset import Subset indices = np.arange(len(train_dataset)) random_indices = np.random.permutation(indices)[:len(val_dataset)] train_subset = Subset(train_dataset, indices=random_indices) train_eval_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device)
A continuación, determinemos en qué punto de la capacitación comenzaremos el cálculo de las métricas y saldremos a la pantalla:
@trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_offline_train_metrics(engine): epoch = engine.state.epoch print("Compute train metrics...") metrics = train_evaluator.run(train_eval_loader).metrics print("Training Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall'])) @trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_val_metrics(engine): epoch = engine.state.epoch print("Compute validation metrics...") metrics = val_evaluator.run(val_loader).metrics print("Validation Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall']))
Puedes correr!
output = trainer.run(train_loader, max_epochs=1)
Llegamos a la pantalla
Epoch[1] Iteration[50/322] Loss: 3.5112 Epoch[1] Iteration[100/322] Loss: 2.9840 Epoch[1] Iteration[150/322] Loss: 2.8807 Epoch[1] Iteration[200/322] Loss: 2.9285 Epoch[1] Iteration[250/322] Loss: 2.5026 Epoch[1] Iteration[300/322] Loss: 2.1944 Compute train metrics... Training Results - Epoch: 1 Average Loss: 2.1018 | Accuracy: 0.3699 | Precision: 0.3981 | Recall: 0.3686 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 2.0519 | Accuracy: 0.3850 | Precision: 0.3578 | Recall: 0.3845
Ya mejor!
Algunos detalles
Veamos un poco el código anterior. El lector puede haber notado la siguiente línea de código:
metrics = train_evaluator.run(train_eval_loader).metrics
y probablemente hubo una pregunta sobre el tipo de objeto obtenido de train_evaluator.run(train_eval_loader) , que tiene el atributo de metrics .
De hecho, la clase Engine contiene una estructura llamada state (tipo State ) para poder transferir datos entre controladores de eventos. Este atributo de state contiene información básica sobre la era actual, la iteración, el número de eras, etc. También se puede usar para transferir cualquier dato de usuario, incluidos los resultados del cálculo de métricas.
state = train_evaluator.run(train_eval_loader) metrics = state.metrics
Cálculo de métricas durante el entrenamiento.
Si la tarea tiene un gran conjunto de entrenamiento y un cálculo de métricas después de cada época de entrenamiento, es costoso, pero aún así le gustaría ver algunos cambios en las métricas durante el entrenamiento, entonces puede usar el siguiente controlador de eventos RunningAverage de la caja. Por ejemplo, queremos calcular y mostrar la precisión del clasificador:
acc_metric = RunningAverage(CategoryAccuracy(...), alpha=0.98) acc_metric.attach(trainer, 'running_avg_accuracy') @trainer.on(Events.ITERATION_COMPLETED) def log_running_avg_metrics(engine): print("running avg accuracy:", engine.state.metrics['running_avg_accuracy'])
Para usar la funcionalidad RunningAverage , debe instalar ignite desde las fuentes:
pip install git+https:
Programación de tasa de aprendizaje
Hay varias formas de cambiar la velocidad de aprendizaje usando ignite . A continuación, considere el método más simple llamando a la función lr_scheduler.step() al comienzo de cada era.
from torch.optim.lr_scheduler import ExponentialLR lr_scheduler = ExponentialLR(optimizer, gamma=0.8) @trainer.on(Events.EPOCH_STARTED) def update_lr_scheduler(engine): lr_scheduler.step()
Guardar los mejores modelos y otros parámetros durante el entrenamiento
Durante el entrenamiento, sería genial registrar los pesos del mejor modelo en el disco, así como guardar periódicamente los pesos del modelo, los parámetros del optimizador y los parámetros para cambiar la velocidad de aprendizaje. Esto último puede ser útil para reanudar el aprendizaje del último estado guardado.
Ignite tiene una clase especial ModelCheckpoint para esto. Entonces, ModelCheckpoint un ModelCheckpoint eventos ModelCheckpoint y ModelCheckpoint el mejor modelo en términos de precisión en el conjunto de prueba. En este caso, definimos una función score_function que proporciona el valor de precisión al controlador de eventos y decide si guardar el modelo o no:
from ignite.handlers import ModelCheckpoint def score_function(engine): val_avg_accuracy = engine.state.metrics['avg_accuracy'] return val_avg_accuracy best_model_saver = ModelCheckpoint("best_models", filename_prefix="model", score_name="val_accuracy", score_function=score_function, n_saved=3, save_as_state_dict=True, create_dir=True)
Ahora cree otro ModelCheckpoint eventos ModelCheckpoint para mantener el estado de aprendizaje cada 1000 iteraciones:
training_saver = ModelCheckpoint("checkpoint", filename_prefix="checkpoint", save_interval=1000, n_saved=1, save_as_state_dict=True, create_dir=True) to_save = {"model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler} trainer.add_event_handler(Events.ITERATION_COMPLETED, training_saver, to_save)
Entonces, casi todo está listo, agregue el último elemento:
Entrenamiento de parada temprana (parada temprana)
Agreguemos otro controlador de eventos que dejará de aprender si no hay una mejora en la calidad del modelo durante 10 eras. Evaluaremos la calidad del modelo nuevamente utilizando la score_function score_function.
from ignite.handlers import EarlyStopping early_stopping = EarlyStopping(patience=10, score_function=score_function, trainer=trainer) val_evaluator.add_event_handler(Events.EPOCH_COMPLETED, early_stopping)
Comience a entrenar
Para comenzar a entrenar, es suficiente para nosotros llamar al método run() . Entrenaremos el modelo durante 10 eras:
max_epochs = 10 output = trainer.run(train_loader, max_epochs=max_epochs)
Salida de pantalla Learning rate: 0.01 Epoch[1] Iteration[50/322] Loss: 2.7984 Epoch[1] Iteration[100/322] Loss: 1.9736 Epoch[1] Iteration[150/322] Loss: 4.3419 Epoch[1] Iteration[200/322] Loss: 2.0261 Epoch[1] Iteration[250/322] Loss: 2.1724 Epoch[1] Iteration[300/322] Loss: 2.1599 Compute train metrics... Training Results - Epoch: 1 Average Loss: 1.5363 | Accuracy: 0.5177 | Precision: 0.5477 | Recall: 0.5178 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 1.5116 | Accuracy: 0.5139 | Precision: 0.5400 | Recall: 0.5140 Learning rate: 0.008 Epoch[2] Iteration[50/322] Loss: 1.4076 Epoch[2] Iteration[100/322] Loss: 1.4892 Epoch[2] Iteration[150/322] Loss: 1.2485 Epoch[2] Iteration[200/322] Loss: 1.6511 Epoch[2] Iteration[250/322] Loss: 3.3376 Epoch[2] Iteration[300/322] Loss: 1.3299 Compute train metrics... Training Results - Epoch: 2 Average Loss: 3.2686 | Accuracy: 0.1977 | Precision: 0.1792 | Recall: 0.1942 Compute validation metrics... Validation Results - Epoch: 2 Average Loss: 3.2772 | Accuracy: 0.1962 | Precision: 0.1628 | Recall: 0.1918 Learning rate: 0.006400000000000001 Epoch[3] Iteration[50/322] Loss: 0.9016 Epoch[3] Iteration[100/322] Loss: 1.2006 Epoch[3] Iteration[150/322] Loss: 0.8892 Epoch[3] Iteration[200/322] Loss: 0.8141 Epoch[3] Iteration[250/322] Loss: 1.4005 Epoch[3] Iteration[300/322] Loss: 0.8888 Compute train metrics... Training Results - Epoch: 3 Average Loss: 0.7368 | Accuracy: 0.7554 | Precision: 0.7818 | Recall: 0.7554 Compute validation metrics... Validation Results - Epoch: 3 Average Loss: 0.7177 | Accuracy: 0.7623 | Precision: 0.7863 | Recall: 0.7611 Learning rate: 0.005120000000000001 Epoch[4] Iteration[50/322] Loss: 0.8490 Epoch[4] Iteration[100/322] Loss: 0.8493 Epoch[4] Iteration[150/322] Loss: 0.8100 Epoch[4] Iteration[200/322] Loss: 0.9165 Epoch[4] Iteration[250/322] Loss: 0.9370 Epoch[4] Iteration[300/322] Loss: 0.6548 Compute train metrics... Training Results - Epoch: 4 Average Loss: 0.7047 | Accuracy: 0.7713 | Precision: 0.8040 | Recall: 0.7728 Compute validation metrics... Validation Results - Epoch: 4 Average Loss: 0.6737 | Accuracy: 0.7778 | Precision: 0.7955 | Recall: 0.7806 Learning rate: 0.004096000000000001 Epoch[5] Iteration[50/322] Loss: 0.6965 Epoch[5] Iteration[100/322] Loss: 0.6196 Epoch[5] Iteration[150/322] Loss: 0.6194 Epoch[5] Iteration[200/322] Loss: 0.3986 Epoch[5] Iteration[250/322] Loss: 0.6032 Epoch[5] Iteration[300/322] Loss: 0.7152 Compute train metrics... Training Results - Epoch: 5 Average Loss: 0.5049 | Accuracy: 0.8282 | Precision: 0.8393 | Recall: 0.8314 Compute validation metrics... Validation Results - Epoch: 5 Average Loss: 0.5084 | Accuracy: 0.8304 | Precision: 0.8386 | Recall: 0.8328 Learning rate: 0.0032768000000000007 Epoch[6] Iteration[50/322] Loss: 0.4433 Epoch[6] Iteration[100/322] Loss: 0.4764 Epoch[6] Iteration[150/322] Loss: 0.5578 Epoch[6] Iteration[200/322] Loss: 0.3684 Epoch[6] Iteration[250/322] Loss: 0.4847 Epoch[6] Iteration[300/322] Loss: 0.3811 Compute train metrics... Training Results - Epoch: 6 Average Loss: 0.4383 | Accuracy: 0.8474 | Precision: 0.8618 | Recall: 0.8495 Compute validation metrics... Validation Results - Epoch: 6 Average Loss: 0.4419 | Accuracy: 0.8446 | Precision: 0.8532 | Recall: 0.8442 Learning rate: 0.002621440000000001 Epoch[7] Iteration[50/322] Loss: 0.4447 Epoch[7] Iteration[100/322] Loss: 0.4602 Epoch[7] Iteration[150/322] Loss: 0.5345 Epoch[7] Iteration[200/322] Loss: 0.3973 Epoch[7] Iteration[250/322] Loss: 0.5023 Epoch[7] Iteration[300/322] Loss: 0.5303 Compute train metrics... Training Results - Epoch: 7 Average Loss: 0.4305 | Accuracy: 0.8579 | Precision: 0.8691 | Recall: 0.8596 Compute validation metrics... Validation Results - Epoch: 7 Average Loss: 0.4262 | Accuracy: 0.8590 | Precision: 0.8685 | Recall: 0.8606 Learning rate: 0.002097152000000001 Epoch[8] Iteration[50/322] Loss: 0.4867 Epoch[8] Iteration[100/322] Loss: 0.3090 Epoch[8] Iteration[150/322] Loss: 0.3721 Epoch[8] Iteration[200/322] Loss: 0.4559 Epoch[8] Iteration[250/322] Loss: 0.3958 Epoch[8] Iteration[300/322] Loss: 0.4222 Compute train metrics... Training Results - Epoch: 8 Average Loss: 0.3432 | Accuracy: 0.8818 | Precision: 0.8895 | Recall: 0.8817 Compute validation metrics... Validation Results - Epoch: 8 Average Loss: 0.3644 | Accuracy: 0.8713 | Precision: 0.8784 | Recall: 0.8707 Learning rate: 0.001677721600000001 Epoch[9] Iteration[50/322] Loss: 0.3557 Epoch[9] Iteration[100/322] Loss: 0.3692 Epoch[9] Iteration[150/322] Loss: 0.3510 Epoch[9] Iteration[200/322] Loss: 0.3446 Epoch[9] Iteration[250/322] Loss: 0.3966 Epoch[9] Iteration[300/322] Loss: 0.3451 Compute train metrics... Training Results - Epoch: 9 Average Loss: 0.3315 | Accuracy: 0.8954 | Precision: 0.9001 | Recall: 0.8982 Compute validation metrics... Validation Results - Epoch: 9 Average Loss: 0.3559 | Accuracy: 0.8818 | Precision: 0.8876 | Recall: 0.8847 Learning rate: 0.0013421772800000006 Epoch[10] Iteration[50/322] Loss: 0.3340 Epoch[10] Iteration[100/322] Loss: 0.3370 Epoch[10] Iteration[150/322] Loss: 0.3694 Epoch[10] Iteration[200/322] Loss: 0.3409 Epoch[10] Iteration[250/322] Loss: 0.4420 Epoch[10] Iteration[300/322] Loss: 0.2770 Compute train metrics... Training Results - Epoch: 10 Average Loss: 0.3246 | Accuracy: 0.8921 | Precision: 0.8988 | Recall: 0.8925 Compute validation metrics... Validation Results - Epoch: 10 Average Loss: 0.3536 | Accuracy: 0.8731 | Precision: 0.8785 | Recall: 0.8722
Ahora verifique los modelos y parámetros guardados en el disco:
ls best_models/ model_best_model_10_val_accuracy=0.8730994.pth model_best_model_8_val_accuracy=0.8712978.pth model_best_model_9_val_accuracy=0.8818188.pth
y
ls checkpoint/ checkpoint_lr_scheduler_3000.pth checkpoint_optimizer_3000.pth checkpoint_model_3000.pth
Predicciones por un modelo entrenado
Primero, cree un cargador de datos de prueba (por ejemplo, tome una muestra de validación) para que el lote de datos consista en imágenes y sus índices:
class TestDataset(Dataset): def __init__(self, ds): self.ds = ds def __len__(self): return len(self.ds) def __getitem__(self, index): return self.ds[index][0], index test_dataset = TestDataset(val_dataset) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
Usando ignite, crearemos un nuevo motor de predicción para los datos de prueba. Para hacer esto, definimos la función inference_update , que devuelve el resultado de la predicción y el índice de la imagen. Para aumentar la precisión, también utilizaremos el conocido truco "aumento del tiempo de prueba" (TTA).
import torch.nn.functional as F from ignite._utils import convert_tensor def _prepare_batch(batch): x, index = batch x = convert_tensor(x, device=device) return x, index def inference_update(engine, batch): x, indices = _prepare_batch(batch) y_pred = model(x) y_pred = F.softmax(y_pred, dim=1) return {"y_pred": convert_tensor(y_pred, device='cpu'), "indices": indices} model.eval() inferencer = Engine(inference_update)
A continuación, cree controladores de eventos que notifiquen sobre la etapa de predicciones y guarde las predicciones en una matriz dedicada:
@inferencer.on(Events.EPOCH_COMPLETED) def log_tta(engine): print("TTA {} / {}".format(engine.state.epoch, n_tta)) n_tta = 3 num_classes = 81 n_samples = len(val_dataset) # y_probas_tta = np.zeros((n_samples, num_classes, n_tta), dtype=np.float32) @inferencer.on(Events.ITERATION_COMPLETED) def save_results(engine): output = engine.state.output tta_index = engine.state.epoch - 1 start_index = ((engine.state.iteration - 1) % len(test_loader)) * batch_size end_index = min(start_index + batch_size, n_samples) batch_y_probas = output['y_pred'].detach().numpy() y_probas_tta[start_index:end_index, :, tta_index] = batch_y_probas
Antes de comenzar el proceso, descarguemos el mejor modelo:
model = squeezenet1_1(pretrained=False, num_classes=64) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device) model_state_dict = torch.load("best_models/model_best_model_10_val_accuracy=0.8730994.pth") model.load_state_dict(model_state_dict)
Lanzamos:
inferencer.run(test_loader, max_epochs=n_tta) > TTA 1 / 3 > TTA 2 / 3 > TTA 3 / 3
A continuación, de manera estándar, tomamos el promedio de las predicciones de TTA y calculamos el índice de clase con la mayor probabilidad:
y_probas = np.mean(y_probas_tta, axis=-1) y_preds = np.argmax(y_probas, axis=-1)
Y ahora podemos calcular una vez más la precisión del modelo de acuerdo con las predicciones:
from sklearn.metrics import accuracy_score y_test_true = [y for _, y in val_dataset] accuracy_score(y_test_true, y_preds) > 0.9310369676443035
, , . , , , ignite .
.
github
- fast neural transfer
- reinforcement learning
- dcgan
Conclusión
, ignite Facebook (. ). 0.1.0, API (Engine, State, Events, Metric, ...) . , , , pull request- github .
Gracias por su atencion!