Hola habr.
El tema de los "cuadrados mágicos" es bastante interesante, porque Por un lado, se conocen desde la antigüedad, por otro lado, el cálculo del "cuadrado mágico" aún hoy es una tarea computacional muy difícil. Recuerde que para construir un "cuadrado mágico" NxN, debe ingresar los números 1..N * N para que la suma de sus horizontales, verticales y diagonales sea igual al mismo número. Si simplemente ordena el número de todas las opciones para organizar los números para un cuadrado de 4x4, ¡obtenemos 16! = 20,922,789,888,000 opciones.
Considere cómo esto se puede hacer de manera más eficiente.

Para empezar, repetimos la condición del problema. Debe organizar los números en un cuadrado para que no se repitan, y la suma de los contornos, verticales y diagonales es igual al mismo número.
Es fácil demostrar que esta suma es siempre la misma, y se calcula mediante la fórmula para cualquier n:
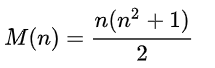
Consideraremos cuadrados 4x4, entonces la suma = 34.
Denote todas las variables por X, nuestro cuadrado se verá así:
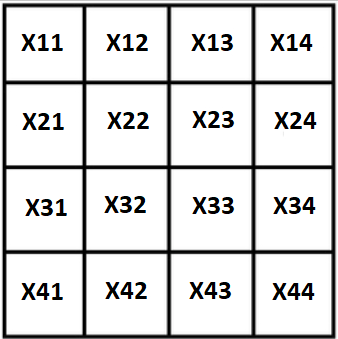
La primera y obvia propiedad: se conoce la suma del cuadrado, los valores extremos se pueden expresar a través de los 3 restantes:
X14 = S - X11 - X12 - X13
X24 = S - X21 - X22 - X23
...
X41 = S - X11 - X21 - X31Por lo tanto, un cuadrado de 4x4 en realidad se convierte en un cuadrado de 3x3, lo que reduce el número de opciones de búsqueda de 16. hasta 9!, es decir 57 millones de veces. Sabiendo esto, comenzamos a escribir código, vemos cuán complicada es una búsqueda tan exhaustiva de computadoras modernas.
C ++ - versión de un solo hilo
El principio del programa es muy simple. Tomamos el conjunto de números 1..16 y el ciclo for sobre este conjunto, será x11. Luego tomamos el segundo conjunto, que consiste en el primero con la excepción del número x11, y así sucesivamente.
Una forma aproximada del programa se ve así:
int squares = 0; int digits[] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 }; Set mset(digits, digits + N*N); for (int x11 = 1; x11 <= MAX; x11++) { Set set12(mset); set12.erase(x11); for (SetIterator it12 = set12.begin(); it12 != set12.end(); it12++) { int x12 = *it12; Set set13(set12); set13.erase(x12); for (SetIterator it13 = set13.begin(); it13 != set13.end(); it13++) { int x13 = *it13; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) continue; if (x14 == x11 || x14 == x12 || x14 == x13) continue; ... int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue;
El texto completo del programa se puede encontrar debajo del spoiler.
Fuente completa #include <set> #include <stdio.h> #include <ctime> #include "stdafx.h" typedef std::set<int> Set; typedef Set::iterator SetIterator; #define N 4 #define MAX (N*N) #define S 34 int main(int argc, char *argv[]) { // x11 x12 x13 x14 // x21 x22 x23 x24 // x31 x32 x33 x34 // x41 x42 x43 x44 const clock_t begin_time = clock(); int squares = 0; int digits[] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 }; Set mset(digits, digits + N*N); for (int x11 = 1; x11 <= MAX; x11++) { Set set12(mset); set12.erase(x11); for (SetIterator it12 = set12.begin(); it12 != set12.end(); it12++) { int x12 = *it12; Set set13(set12); set13.erase(x12); for (SetIterator it13 = set13.begin(); it13 != set13.end(); it13++) { int x13 = *it13; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) continue; if (x14 == x11 || x14 == x12 || x14 == x13) continue; Set set21(set13); set21.erase(x13); set21.erase(x14); for (SetIterator it21 = set21.begin(); it21 != set21.end(); it21++) { int x21 = *it21; Set set22(set21); set22.erase(x21); for (SetIterator it22 = set22.begin(); it22 != set22.end(); it22++) { int x22 = *it22; Set set23(set22); set23.erase(x22); for (SetIterator it23 = set23.begin(); it23 != set23.end(); it23++) { int x23 = *it23, x24 = S - x21 - x22 - x23; if (x24 < 1 || x24 > MAX) continue; if (x24 == x11 || x24 == x12 || x24 == x13 || x24 == x14 || x24 == x21 || x24 == x22 || x24 == x23) continue; Set set31(set23); set31.erase(x23); set31.erase(x24); for (SetIterator it31 = set31.begin(); it31 != set31.end(); it31++) { int x31 = *it31; Set set32(set31); set32.erase(x31); for (SetIterator it32 = set32.begin(); it32 != set32.end(); it32++) { int x32 = *it32; Set set33(set32); set33.erase(x32); for (SetIterator it33 = set33.begin(); it33 != set33.end(); it33++) { int x33 = *it33, x34 = S - x31 - x32 - x33; if (x34 < 1 || x34 > MAX) continue; if (x34 == x11 || x34 == x12 || x34 == x13 || x34 == x14 || x34 == x21 || x34 == x22 || x34 == x23 || x34 == x24 || x34 == x31 || x34 == x32 || x34 == x33) continue; int x41 = S - x11 - x21 - x31, x42 = S - x12 - x22 - x32, x43 = S - x13 - x23 - x33, x44 = S - x14 - x24 - x34; if (x41 < 1 || x41 > MAX || x42 < 1 || x42 > MAX || x43 < 1 || x43 > MAX || x44 < 1 || x41 > MAX) continue; if (x41 == x11 || x41 == x12 || x41 == x13 || x41 == x14 || x41 == x21 || x41 == x22 || x41 == x23 || x41 == x24 || x41 == x31 || x41 == x32 || x41 == x33 || x41 == x34) continue; if (x42 == x11 || x42 == x12 || x42 == x13 || x42 == x14 || x42 == x21 || x42 == x22 || x42 == x23 || x42 == x24 || x42 == x31 || x42 == x32 || x42 == x33 || x42 == x34 || x42 == x41) continue; if (x43 == x11 || x43 == x12 || x43 == x13 || x43 == x14 || x43 == x21 || x43 == x22 || x43 == x23 || x43 == x24 || x43 == x31 || x43 == x32 || x43 == x33 || x43 == x34 || x43 == x41 || x43 == x42) continue; if (x44 == x11 || x44 == x12 || x44 == x13 || x44 == x14 || x44 == x21 || x44 == x22 || x44 == x23 || x44 == x24 || x44 == x31 || x44 == x32 || x44 == x33 || x44 == x34 || x44 == x41 || x44 == x42 || x44 == x43) continue; int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue; printf("%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d\n", x11, x12, x13, x14, x21, x22, x23, x24, x31, x32, x33, x34, x41, x42, x43, x44); squares++; } } } } } } } } } printf("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); return 0; }
Resultado: se encontraron un total de
7040 opciones de "cuadrados mágicos" 4x4, y el tiempo de búsqueda fue de
102 segundos .

Por cierto, es interesante comprobar si la lista de cuadrados contiene el mismo que se muestra en el grabado de Durer. Por supuesto que sí, porque el programa muestra
todos los cuadrados 4x4:
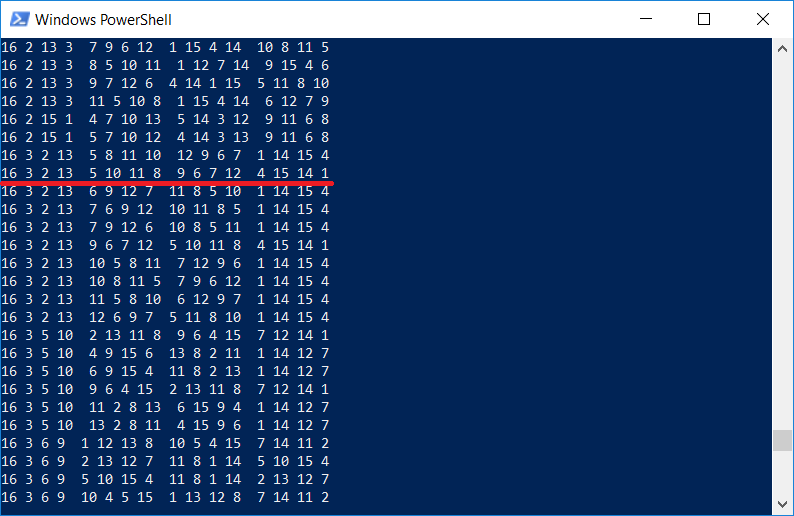
Cabe señalar que Durero insertó un cuadrado en la imagen por una razón, los números
1514 también indican el año del grabado.
Como puede ver, el programa funciona (marcamos la tarea como verificada en 1514 por Albrecht Dürer;), sin embargo, el tiempo de ejecución no es tan pequeño para una computadora con un procesador Core i7. Obviamente, el programa se ejecuta en un solo hilo, y es aconsejable usar todos los demás núcleos.
C ++ - versión multiproceso
Reescribir un programa usando streams es básicamente sencillo, aunque un poco engorroso. Afortunadamente, hoy existe una opción casi olvidada: el uso de soporte para
OpenMP (Open Multi-Processing). Esta tecnología existe desde 1998 y permite que las directivas del procesador le digan al compilador qué partes del programa deben ejecutarse en paralelo. OpenMP también es compatible con Visual Studio, por lo que para convertir un programa en multiproceso, simplemente agregue una línea al código:
int squares = 0; #pragma omp parallel for reduction(+: squares) for (int x11 = 1; x11 <= MAX; x11++) { ... } printf("CNT: %d\n", squares);
La
directiva #pragma omp parallel for indica que el siguiente ciclo for puede ejecutarse en paralelo, y los cuadrados de parámetros adicionales establecen el nombre de la variable, que será común para hilos paralelos (sin esto, el incremento no funciona correctamente).
El resultado es obvio: el tiempo de ejecución se redujo de 102s a
18s .

Fuente completa #include <set> #include <stdio.h> #include <ctime> #include "stdafx.h" typedef std::set<int> Set; typedef Set::iterator SetIterator; #define N 4 #define MAX (N*N) #define S 34 int main(int argc, char *argv[]) { // x11 x12 x13 x14 // x21 x22 x23 x24 // x31 x32 x33 x34 // x41 x42 x43 x44 const clock_t begin_time = clock(); int squares = 0; #pragma omp parallel for reduction(+: squares) for (int x11 = 1; x11 <= MAX; x11++) { int digits[] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 }; Set mset(digits, digits + N*N); Set set12(mset); set12.erase(x11); for (SetIterator it12 = set12.begin(); it12 != set12.end(); it12++) { int x12 = *it12; Set set13(set12); set13.erase(x12); for (SetIterator it13 = set13.begin(); it13 != set13.end(); it13++) { int x13 = *it13; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) continue; if (x14 == x11 || x14 == x12 || x14 == x13) continue; Set set21(set13); set21.erase(x13); set21.erase(x14); for (SetIterator it21 = set21.begin(); it21 != set21.end(); it21++) { int x21 = *it21; Set set22(set21); set22.erase(x21); for (SetIterator it22 = set22.begin(); it22 != set22.end(); it22++) { int x22 = *it22; Set set23(set22); set23.erase(x22); for (SetIterator it23 = set23.begin(); it23 != set23.end(); it23++) { int x23 = *it23, x24 = S - x21 - x22 - x23; if (x24 < 1 || x24 > MAX) continue; if (x24 == x11 || x24 == x12 || x24 == x13 || x24 == x14 || x24 == x21 || x24 == x22 || x24 == x23) continue; Set set31(set23); set31.erase(x23); set31.erase(x24); for (SetIterator it31 = set31.begin(); it31 != set31.end(); it31++) { int x31 = *it31; Set set32(set31); set32.erase(x31); for (SetIterator it32 = set32.begin(); it32 != set32.end(); it32++) { int x32 = *it32; Set set33(set32); set33.erase(x32); for (SetIterator it33 = set33.begin(); it33 != set33.end(); it33++) { int x33 = *it33, x34 = S - x31 - x32 - x33; if (x34 < 1 || x34 > MAX) continue; if (x34 == x11 || x34 == x12 || x34 == x13 || x34 == x14 || x34 == x21 || x34 == x22 || x34 == x23 || x34 == x24 || x34 == x31 || x34 == x32 || x34 == x33) continue; int x41 = S - x11 - x21 - x31, x42 = S - x12 - x22 - x32, x43 = S - x13 - x23 - x33, x44 = S - x14 - x24 - x34; if (x41 < 1 || x41 > MAX || x42 < 1 || x42 > MAX || x43 < 1 || x43 > MAX || x44 < 1 || x41 > MAX) continue; if (x41 == x11 || x41 == x12 || x41 == x13 || x41 == x14 || x41 == x21 || x41 == x22 || x41 == x23 || x41 == x24 || x41 == x31 || x41 == x32 || x41 == x33 || x41 == x34) continue; if (x42 == x11 || x42 == x12 || x42 == x13 || x42 == x14 || x42 == x21 || x42 == x22 || x42 == x23 || x42 == x24 || x42 == x31 || x42 == x32 || x42 == x33 || x42 == x34 || x42 == x41) continue; if (x43 == x11 || x43 == x12 || x43 == x13 || x43 == x14 || x43 == x21 || x43 == x22 || x43 == x23 || x43 == x24 || x43 == x31 || x43 == x32 || x43 == x33 || x43 == x34 || x43 == x41 || x43 == x42) continue; if (x44 == x11 || x44 == x12 || x44 == x13 || x44 == x14 || x44 == x21 || x44 == x22 || x44 == x23 || x44 == x24 || x44 == x31 || x44 == x32 || x44 == x33 || x44 == x34 || x44 == x41 || x44 == x42 || x44 == x43) continue; int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue; printf("%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d\n", x11, x12, x13, x14, x21, x22, x23, x24, x31, x32, x33, x34, x41, x42, x43, x44); squares++; } } } } } } } } } printf("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); return 0; }
Esto es mucho mejor, porque la tarea está casi perfectamente paralelizada (los cálculos en cada rama son independientes entre sí), el tiempo es menor que la cantidad de veces igual a la cantidad de núcleos de procesador. Pero, por desgracia, no
es posible sacar mucho más provecho de este código, aunque algunas optimizaciones pueden ganar un pequeño porcentaje. Pasamos a artillería más pesada, cálculos en la GPU.
Computación con NVIDIA CUDA
Si no entra en detalles, el proceso de cálculo que se realiza en la tarjeta de video puede representarse como varios bloques (bloques) de hardware paralelos, cada uno de los cuales realiza varios procesos (hilos).
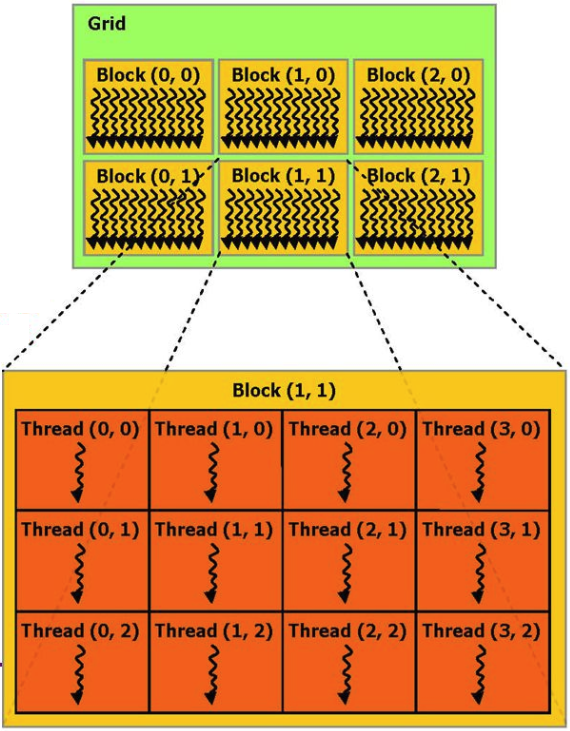
Por ejemplo, podemos dar un ejemplo de la función de agregar 2 vectores de la documentación de CUDA:
__global__ void add(int n, float *x, float *y) { int index = threadIdx.x; int stride = blockDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }
Las matrices xey son comunes para todos los bloques, y la función en sí misma se ejecuta simultáneamente en varios procesadores a la vez. La clave aquí es el paralelismo: los procesadores de tarjetas de video son mucho más simples que una CPU normal, pero hay muchos de ellos y están enfocados específicamente en el procesamiento de datos numéricos.
Esto es lo que necesitamos. Tenemos una matriz de números X11, X12, .., X44. Comencemos el proceso de 16 bloques, cada uno de los cuales ejecutará 16 procesos. El número de bloque corresponderá al número X11, el número de proceso al número X12, y el código mismo calculará todos los cuadrados posibles con los X11 y X12 seleccionados. Es simple, pero hay una sutileza: los datos no solo deben calcularse, sino también transferirse desde la tarjeta de video, para esto almacenaremos el número de cuadrados encontrados en el elemento cero de la matriz.
El código principal es muy simple:
#define N 4 #define SQ_MAX 8*1024 #define BLOCK_SIZE (SQ_MAX*N*N + 1) int main(int argc,char *argv[]) { const clock_t begin_time = clock(); int *results = (int*)malloc(BLOCK_SIZE*sizeof(int)); results[0] = 0; int *gpu_out = NULL; cudaMalloc(&gpu_out, BLOCK_SIZE*sizeof(int)); cudaMemcpy(gpu_out, results, BLOCK_SIZE*sizeof(int), cudaMemcpyHostToDevice); squares<<<MAX, MAX>>>(gpu_out); cudaMemcpy(results, gpu_out, BLOCK_SIZE*sizeof(int), cudaMemcpyDeviceToHost); // Print results int squares = results[0]; for(int p=0; p<SQ_MAX && p<squares; p++) { int i = MAX*p + 1; printf("[%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d]\n", results[i], results[i+1], results[i+2], results[i+3], results[i+4], results[i+5], results[i+6], results[i+7], results[i+8], results[i+9], results[i+10], results[i+11], results[i+12], results[i+13], results[i+14], results[i+15]); } printf ("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); cudaFree(gpu_out); free(results); return 0; }
Seleccionamos el bloque de memoria en la tarjeta de video usando cudaMalloc, ejecutamos la función de cuadrados, indicando 2 parámetros 16.16 (el número de bloques y el número de hilos) correspondientes a los números 1..16 iterados, luego copiamos los datos nuevamente a través de cudaMemcpy.
La función de cuadrados en sí misma esencialmente repite el código de la parte anterior, con la diferencia de que el incremento del número de cuadrados encontrados se realiza utilizando atomicAdd; esto asegura que la variable cambiará correctamente durante las llamadas simultáneas.
El resultado no requiere comentarios: el tiempo de ejecución fue de
2.7 s , que es aproximadamente 30 veces mejor que la versión inicial de un solo subproceso:

Como se sugiere en los comentarios, puede usar incluso más bloques de hardware de la tarjeta de video, por lo que se intentó la opción de 256 bloques. Cambiar el código es mínimo:
__global__ void squares(int *res_array) { int index1 = blockIdx.x/MAX, index2 = blockIdx.x%MAX; ... } squares<<<MAX*MAX, 1>>>(gpu_out);
Esto redujo el tiempo en otras 2 veces, a
1.2s . Además, en cada bloque, se pueden iniciar 16 procesos, lo que da el mejor tiempo de
0.44s .
Código final #include <stdio.h> #include <ctime> #define N 4 #define MAX (N*N) #define SQ_MAX 8*1024 #define BLOCK_SIZE (SQ_MAX*N*N + 1) #define S 34 // Magic square: // x11 x12 x13 x14 // x21 x22 x23 x24 // x31 x32 x33 x34 // x41 x42 x43 x44 __global__ void squares(int *res_array) { int index1 = blockIdx.x/MAX, index2 = blockIdx.x%MAX, index3 = threadIdx.x; if (index1 + 1 > MAX || index2 + 1 > MAX || index3 + 1 > MAX) return; const int x11 = index1+1, x12 = index2+1, x13 = index3+1; if (x13 == x11 || x13 == x12) return; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) return; if (x14 == x11 || x14 == x12 || x14 == x13) return; for(int x21=1; x21<=MAX; x21++) { if (x21 == x11 || x21 == x12 || x21 == x13 || x21 == x14) continue; for(int x22=1; x22<=MAX; x22++) { if (x22 == x11 || x22 == x12 || x22 == x13 || x22 == x14 || x22 == x21) continue; for(int x23=1; x23<=MAX; x23++) { int x24 = S - x21 - x22 - x23; if (x24 < 1 || x24 > MAX) continue; if (x23 == x11 || x23 == x12 || x23 == x13 || x23 == x14 || x23 == x21 || x23 == x22) continue; if (x24 == x11 || x24 == x12 || x24 == x13 || x24 == x14 || x24 == x21 || x24 == x22 || x24 == x23) continue; for(int x31=1; x31<=MAX; x31++) { if (x31 == x11 || x31 == x12 || x31 == x13 || x31 == x14 || x31 == x21 || x31 == x22 || x31 == x23 || x31 == x24) continue; for(int x32=1; x32<=MAX; x32++) { if (x32 == x11 || x32 == x12 || x32 == x13 || x32 == x14 || x32 == x21 || x32 == x22 || x32 == x23 || x32 == x24 || x32 == x31) continue; for(int x33=1; x33<=MAX; x33++) { int x34 = S - x31 - x32 - x33; if (x34 < 1 || x34 > MAX) continue; if (x33 == x11 || x33 == x12 || x33 == x13 || x33 == x14 || x33 == x21 || x33 == x22 || x33 == x23 || x33 == x24 || x33 == x31 || x33 == x32) continue; if (x34 == x11 || x34 == x12 || x34 == x13 || x34 == x14 || x34 == x21 || x34 == x22 || x34 == x23 || x34 == x24 || x34 == x31 || x34 == x32 || x34 == x33) continue; const int x41 = S - x11 - x21 - x31, x42 = S - x12 - x22 - x32, x43 = S - x13 - x23 - x33, x44 = S - x14 - x24 - x34; if (x41 < 1 || x41 > MAX || x42 < 1 || x42 > MAX || x43 < 1 || x43 > MAX || x44 < 1 || x44 > MAX) continue; if (x41 == x11 || x41 == x12 || x41 == x13 || x41 == x14 || x41 == x21 || x41 == x22 || x41 == x23 || x41 == x24 || x41 == x31 || x41 == x32 || x41 == x33 || x41 == x34) continue; if (x42 == x11 || x42 == x12 || x42 == x13 || x42 == x14 || x42 == x21 || x42 == x22 || x42 == x23 || x42 == x24 || x42 == x31 || x42 == x32 || x42 == x33 || x42 == x34 || x42 == x41) continue; if (x43 == x11 || x43 == x12 || x43 == x13 || x43 == x14 || x43 == x21 || x43 == x22 || x43 == x23 || x43 == x24 || x43 == x31 || x43 == x32 || x43 == x33 || x43 == x34 || x43 == x41 || x43 == x42) continue; if (x44 == x11 || x44 == x12 || x44 == x13 || x44 == x14 || x44 == x21 || x44 == x22 || x44 == x23 || x44 == x24 || x44 == x31 || x44 == x32 || x44 == x33 || x44 == x34 || x44 == x41 || x44 == x42 || x44 == x43) continue; int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue; // Square found: save in array (MAX numbers for each square) int p = atomicAdd(res_array, 1); if (p >= SQ_MAX) continue; int i = MAX*p + 1; res_array[i] = x11; res_array[i+1] = x12; res_array[i+2] = x13; res_array[i+3] = x14; res_array[i+4] = x21; res_array[i+5] = x22; res_array[i+6] = x23; res_array[i+7] = x24; res_array[i+8] = x31; res_array[i+9] = x32; res_array[i+10] = x33; res_array[i+11] = x34; res_array[i+12]= x41; res_array[i+13]= x42; res_array[i+14] = x43; res_array[i+15] = x44; // Warning: printf from kernel makes calculation 2-3x slower // printf("%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d\n", x11, x12, x13, x14, x21, x22, x23, x24, x31, x32, x33, x34, x41, x42, x43, x44); } } } } } } } int main(int argc,char *argv[]) { int *gpu_out = NULL; cudaMalloc(&gpu_out, BLOCK_SIZE*sizeof(int)); const clock_t begin_time = clock(); int *results = (int*)malloc(BLOCK_SIZE*sizeof(int)); results[0] = 0; cudaMemcpy(gpu_out, results, BLOCK_SIZE*sizeof(int), cudaMemcpyHostToDevice); squares<<<MAX*MAX, MAX>>>(gpu_out); cudaMemcpy(results, gpu_out, BLOCK_SIZE*sizeof(int), cudaMemcpyDeviceToHost); // Print results int squares = results[0]; for(int p=0; p<SQ_MAX && p<squares; p++) { int i = MAX*p + 1; printf("[%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d]\n", results[i], results[i+1], results[i+2], results[i+3], results[i+4], results[i+5], results[i+6], results[i+7], results[i+8], results[i+9], results[i+10], results[i+11], results[i+12], results[i+13], results[i+14], results[i+15]); } printf ("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); cudaFree(gpu_out); free(results); return 0; }
Lo más probable es que esto esté lejos de ser ideal, por ejemplo, puede ejecutar incluso más bloques en la GPU, pero esto hará que el código sea más confuso y difícil de entender. Y, por supuesto, los cálculos no son "gratuitos": cuando se carga la GPU, la interfaz de Windows comienza a disminuir notablemente y el consumo de energía de la computadora aumenta casi 2 veces, de 65 a 130W.
Editar : como sugirió el usuario de
Bodigrim en los comentarios, una igualdad más se cumple para un cuadrado de 4x4: la suma de 4 celdas "internas" es igual a la suma de las "externas", también es S.

X22 + X23 + X32 + X33 = X11 + X41 + X14 + X44 = SEsto hará posible acelerar el algoritmo al expresar algunas variables a través de otras y eliminar otros 1-2 bucles anidados; en el comentario a continuación se puede encontrar una versión actualizada del código.Conclusión
La tarea de encontrar "cuadrados mágicos" resultó ser técnicamente muy interesante y, al mismo tiempo, difícil. Incluso con los cálculos en la GPU, la búsqueda de todos los cuadrados de 5x5 puede llevar varias horas, y la optimización para encontrar cuadrados mágicos de 7x7 y dimensiones superiores aún está por hacer.Matemáticamente y algorítmicamente, también hay varios problemas sin resolver:- « » N. 22 , 33 8 ( 1, ), 44 , 7040, . .
- , .
- . , NVIDIA Tesla , - , . , . , ;)
Se puede escribir un artículo separado sobre el análisis y las propiedades de los cuadrados mágicos, si hay interés.PD: A la pregunta que probablemente seguirá, "¿por qué es esto necesario?" En términos de consumo de energía, calcular cuadrados mágicos no es mejor ni peor que calcular bitcoins, entonces, ¿por qué no? Además, es un ejercicio interesante para la mente y una tarea interesante en el campo de la programación aplicada.