Uno es cero a favor del cerebro humano. En un
nuevo estudio , los informáticos descubrieron que los sistemas de inteligencia artificial no pasan la prueba de reconocimiento visual de los objetos que cualquier niño puede manejar fácilmente.
"Este estudio cualitativo e importante nos recuerda que el" aprendizaje profundo "en sí mismo no puede presumir de la profundidad que se le atribuye", dice Gary Marcus, neurocientífico de la Universidad de Nueva York que no está asociado con este trabajo.
Los resultados del estudio se relacionan con el campo de la visión por computadora, cuando los sistemas de inteligencia artificial intentan detectar y clasificar objetos. Por ejemplo, se les puede pedir que encuentren a todos los peatones en la escena de la calle o simplemente que distingan a un pájaro de una bicicleta, una tarea que ya se ha hecho famosa por su complejidad.
Hay mucho en juego: las computadoras están comenzando gradualmente a realizar operaciones importantes para las personas, como la videovigilancia automática y la conducción autónoma. Y para un trabajo exitoso, es necesario que la capacidad de la IA para el procesamiento visual no sea al menos inferior a la humana.
La tarea no es fácil.
El nuevo estudio se centra en la sofisticación de la visión humana y las dificultades para crear sistemas de imitación. Los científicos probaron la precisión de un sistema de visión por computadora utilizando el ejemplo de una sala de estar. AI lo hizo bien, identificando correctamente la silla, la persona y los libros en el estante. Pero cuando los científicos agregaron un objeto inusual a la escena, la imagen de un elefante, el hecho mismo de su apariencia hizo que el sistema olvidara todos los resultados anteriores. De repente, comenzó a llamar a la silla un sofá, al elefante una silla, e ignorar todos los demás objetos.
"Hubo una variedad de rarezas que mostraron la fragilidad de los sistemas modernos de detección de objetos", dice Amir Rosenfeld, científico de la Universidad de York en Toronto y coautor de un estudio que él y sus colegas
John Totsotsos , también de York, y
Richard Zemel de la Universidad de Toronto.
Los investigadores todavía están tratando de aclarar las razones por las cuales el sistema de visión por computadora se desconcierta tan fácilmente, y ya tienen una buena suposición. El punto en la habilidad humana, que la IA no tiene, es la capacidad de darse cuenta de que la escena es incomprensible, y debemos considerarla más de cerca.
Elefante en la habitación
Al mirar el mundo, percibimos una asombrosa cantidad de información visual. El cerebro humano lo procesa sobre la marcha. "Abrimos los ojos y todo sucede por sí solo", dice Totsotsos.
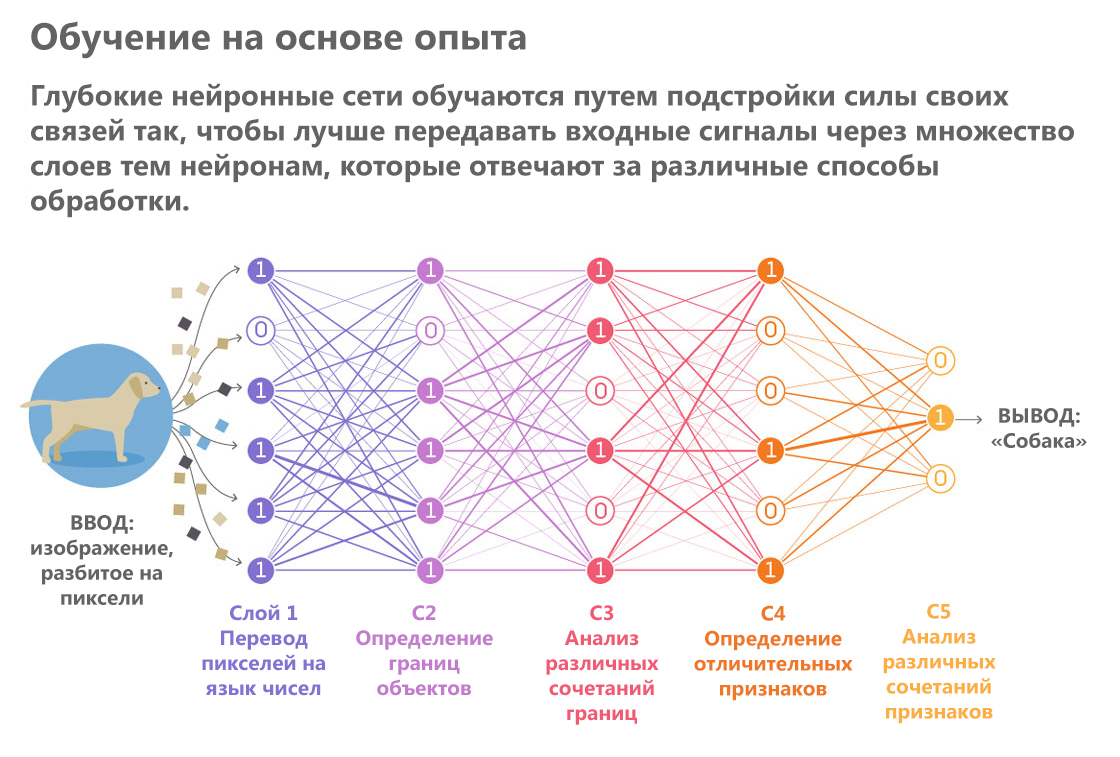
La inteligencia artificial, por el contrario, crea una impresión visual meticulosa, como si leyera una descripción en Braille. Recorre las yemas de sus dedos algorítmicos a través de los píxeles, formando gradualmente a partir de ellos representaciones cada vez más complejas. Una variedad de sistemas de IA que realizan procesos similares son las redes neuronales. Pasan una imagen a través de una serie de "capas". A medida que pasa cada capa, se procesan detalles de imágenes individuales, como el color y el brillo de píxeles individuales, y se forma una descripción cada vez más abstracta del objeto sobre la base de este análisis.
"Los resultados del procesamiento de la capa anterior se transfieren a la siguiente, y así sucesivamente, como en un transportador", explica Totsotsos.
 Publicado por: Lucy Reading-Ikkanda / Quanta Magazine
Publicado por: Lucy Reading-Ikkanda / Quanta MagazineLas redes neuronales son expertos en tareas rutinarias específicas en el campo del procesamiento visual. Son mejores que las personas para hacer frente a tareas altamente especializadas, como determinar la raza de perros y otras clasificaciones de objetos en categorías. Estos ejemplos exitosos dieron lugar a la esperanza de que los sistemas de visión por computadora pronto se vuelvan tan inteligentes que puedan conducir un automóvil en las calles de la ciudad.
También incitó a los expertos a explorar sus vulnerabilidades. En los últimos años, los investigadores han realizado una serie de intentos para simular ataques hostiles: idearon escenarios que obligan a las redes neuronales a cometer errores. En un experimento, los informáticos
engañaron a la red, forzándola a tomar la tortuga por un arma. Otra historia de trampa exitosa fue que, junto a objetos comunes como un plátano, los investigadores
colocaron una tostadora pintada en colores psicodélicos en la imagen.
En el nuevo trabajo, los científicos han elegido el mismo enfoque. Tres investigadores mostraron una fotografía de la red neuronal de una sala de estar. Captura a un hombre que juega un videojuego, sentado en el borde de una silla vieja e inclinándose hacia adelante. Al "digerir" esta escena, AI rápidamente reconoció varios objetos: una persona, un sofá, un televisor, una silla y un par de libros.
Luego, los investigadores agregaron un objeto inusual para escenas similares: una imagen de un elefante en un medio perfil. Y la red neuronal está confundida. En algunos casos, la aparición de un elefante la obligó a tomar una silla como sofá y, a veces, el sistema dejó de ver ciertos objetos, con el reconocimiento de que antes de eso no había problemas. Esto, por ejemplo, es una serie de libros. Además, se produjeron errores incluso con objetos ubicados lejos del elefante.
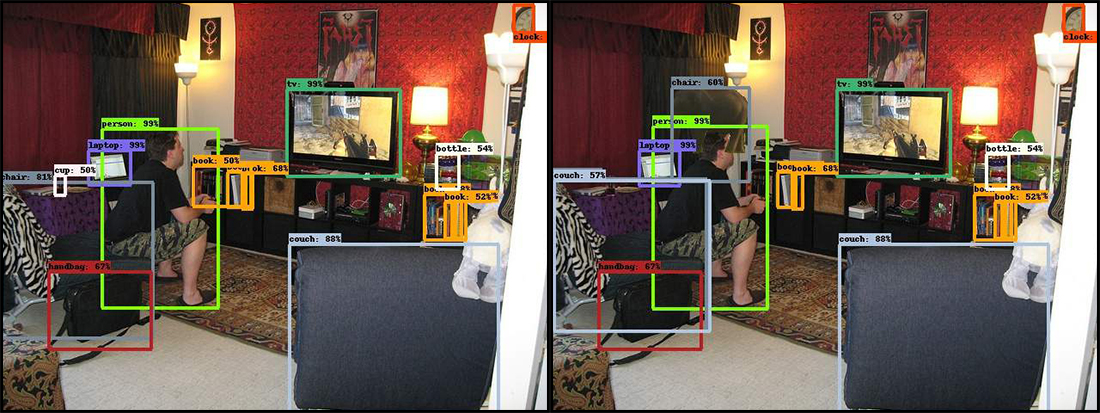 En el original a la izquierda, la red neuronal identificó correctamente y con gran confianza muchos objetos ubicados en la sala de estar llenos de varias cosas. Pero tan pronto como se agregó el elefante (imagen a la derecha), el programa comenzó a fallar. La silla en la esquina inferior izquierda se convirtió en un sofá, la copa junto a ella desapareció y el elefante se convirtió en una silla.
En el original a la izquierda, la red neuronal identificó correctamente y con gran confianza muchos objetos ubicados en la sala de estar llenos de varias cosas. Pero tan pronto como se agregó el elefante (imagen a la derecha), el programa comenzó a fallar. La silla en la esquina inferior izquierda se convirtió en un sofá, la copa junto a ella desapareció y el elefante se convirtió en una silla.Errores de sistema similares son completamente inaceptables para la misma conducción autónoma. La computadora no podrá conducir el automóvil si no nota a los peatones simplemente porque unos segundos antes vio un pavo al costado de la carretera.
En cuanto al elefante en sí, los resultados de su reconocimiento también diferían de un intento a otro. El sistema luego lo determinó correctamente, a veces llamado oveja, luego no lo notó en absoluto.
"Si realmente aparece un elefante en la habitación, cualquiera lo notará", dice Rosenfeld. "Y el sistema ni siquiera registró su presencia".
Relación cercana
Cuando las personas ven algo inesperado, lo ven mejor. No importa cuán simple suene, "mire más de cerca", esto tiene consecuencias cognitivas reales y explica por qué la IA se equivoca cuando aparece algo inusual.
Al procesar y reconocer objetos, las mejores redes neuronales modernas pasan información a través de sí mismas solo en la dirección hacia adelante. Comienzan seleccionando píxeles en la entrada, pasando a curvas, formas y escenas, y haciendo las suposiciones más probables en cada etapa. Cualquier idea errónea en las primeras etapas del proceso conduce a errores al final cuando la red neuronal reúne sus "pensamientos" para adivinar lo que está mirando.
"En las redes neuronales, todos los procesos están estrechamente interconectados, por lo que siempre existe la posibilidad de que cualquier característica en cualquier lugar pueda afectar cualquier resultado posible", dice Totsosos.
El enfoque humano es mejor. Imagine que le dieron un vistazo rápido a una imagen que tiene un círculo y un cuadrado, uno rojo y el otro azul. Después de eso, se le pidió que nombrara el color del cuadrado. Una breve mirada puede no ser suficiente para recordar los colores correctamente. Inmediatamente llega la comprensión de que no está seguro y que necesita mirar de nuevo. Y, lo cual es muy importante, durante la segunda visualización ya sabrá en qué debe concentrarse.
"El sistema visual humano dice:" Todavía no puedo dar la respuesta correcta, así que volveré y comprobaré dónde pudo haber ocurrido el error ", explica Totsotsos, quien está desarrollando una teoría llamada"
Sintonización selectiva "que explica esta característica de la percepción visual.
La mayoría de las redes neuronales carecen de la capacidad de regresar. Esta característica es muy difícil de diseñar. Una de las ventajas de las redes unidireccionales es que son relativamente fáciles de entrenar: simplemente "pase" las imágenes a través de las seis capas mencionadas y obtenga el resultado. Pero si las redes neuronales deben "mirar de cerca", también deben distinguir entre una línea fina, cuándo es mejor regresar y cuándo continuar trabajando. El cerebro humano cambia fácil y naturalmente entre procesos tan diferentes. Y las redes neuronales necesitan una nueva base teórica para que puedan hacer lo mismo.
Los principales investigadores de todo el mundo están trabajando en esta dirección, pero también necesitan ayuda. Recientemente, el proyecto Google AI
anunció una competencia para clasificadores de imágenes de crowdsourcing que pueden distinguir entre casos de distorsión de imagen intencional. Ganará la solución que pueda distinguir claramente la imagen del pájaro de la imagen de la bicicleta. Este será un primer paso modesto pero muy importante.
