Enron Corporation es una de las figuras más famosas de los negocios estadounidenses en la década de 2000. Esto fue facilitado no por su esfera de actividad (electricidad y contratos para su suministro), sino por la resonancia debido al fraude en ella. Durante 15 años, el ingreso corporativo ha crecido rápidamente, y trabajar en él prometió un buen salario. Pero todo terminó igual de fugazmente: en el período 2000-2001. el precio de la acción cayó de $ 90 / unidad a casi cero debido al fraude revelado con ingresos declarados. Desde entonces, la palabra "Enron" se ha convertido en una palabra familiar y actúa como una etiqueta para las empresas que operan en un patrón similar.
Durante el juicio, 18 personas (incluidos los acusados más importantes en este caso: Andrew Fastov, Jeff Skilling y Kenneth Lay) fueron condenados.
![imagen! [imagen] (http: // https: //habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)](https://habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)
Al mismo tiempo, se publicó un archivo de correspondencia electrónica entre los empleados de la empresa, mejor conocido como Enron Email Dataset, e información privilegiada sobre los ingresos de los empleados de esta empresa.
El artículo examinará las fuentes de estos datos y creará un modelo basado en ellos para determinar si una persona es sospechosa de fraude. Suena interesante? Entonces, bienvenido a habrakat.
Descripción del conjunto de datos
El conjunto de datos de Enron (conjunto de datos) es un conjunto compuesto de datos abiertos que contiene registros de personas que trabajan en una corporación memorable con el nombre correspondiente.
Puede distinguir 3 partes:
- pagos_características: un grupo que caracteriza los movimientos financieros;
- stock_features: un grupo que refleja los signos asociados con las existencias;
- email_features: un grupo que refleja información sobre los correos electrónicos de una persona en particular en forma agregada.
Por supuesto, también hay una variable objetivo que indica si la persona es sospechosa de fraude (el signo de 'poi' ).
Descargue nuestros datos y comience a trabajar con ellos:
import pickle with open("final_project/enron_dataset.pkl", "rb") as data_file: data_dict = pickle.load(data_file)
Después de eso, convertimos el conjunto data_dict en un marco de datos Pandas para un trabajo más conveniente con datos:
import pandas as pd import warnings warnings.filterwarnings('ignore') source_df = pd.DataFrame.from_dict(data_dict, orient = 'index') source_df.drop('TOTAL',inplace=True)
Agrupamos los signos de acuerdo con los tipos indicados anteriormente. Esto debería facilitar el trabajo con datos después:
payments_features = ['salary', 'bonus', 'long_term_incentive', 'deferred_income', 'deferral_payments', 'loan_advances', 'other', 'expenses', 'director_fees', 'total_payments'] stock_features = ['exercised_stock_options', 'restricted_stock', 'restricted_stock_deferred','total_stock_value'] email_features = ['to_messages', 'from_poi_to_this_person', 'from_messages', 'from_this_person_to_poi', 'shared_receipt_with_poi'] target_field = 'poi'
Datos financieros
En este conjunto de datos hay un NaN conocido por muchos, y expresa la brecha habitual en los datos. En otras palabras, el autor del conjunto de datos no pudo encontrar ninguna información sobre un atributo particular asociado con una línea particular en el marco de datos. Como resultado, podemos suponer que NaN es 0, ya que no hay información sobre un rasgo particular.
payments = source_df[payments_features] payments = payments.replace('NaN', 0)
Verificación de datos
Al comparar con el PDF original subyacente al conjunto de datos, resultó que los datos están ligeramente distorsionados, porque no para todas las líneas en el marco de datos de pagos , el campo total_pagos es la suma de todas las transacciones financieras de una persona determinada. Puede verificar esto de la siguiente manera:
errors = payments[payments[payments_features[:-1]].sum(axis='columns') != payments['total_payments']] errors.head()

Vemos que BELFER ROBERT y BHATNAGAR SANJAY tienen montos de pago incorrectos.
Puede corregir este error moviendo los datos en las líneas de error hacia la izquierda o hacia la derecha y contando nuevamente la suma de todos los pagos:
import numpy as np shifted_values = payments.loc['BELFER ROBERT', payments_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) payments.loc['BELFER ROBERT', payments_features] = shifted_values shifted_values = payments.loc['BHATNAGAR SANJAY', payments_features[:-1]].values payments.loc['BHATNAGAR SANJAY', payments_features] = np.insert(shifted_values, 0, 0)
Datos de stock
stocks = source_df[stock_features] stocks = stocks.replace('NaN', 0)
Realice también una verificación de validación en este caso:
errors = stocks[stocks[stock_features[:-1]].sum(axis='columns') != stocks['total_stock_value']] errors.head()

Del mismo modo, solucionaremos el error en las existencias:
shifted_values = stocks.loc['BELFER ROBERT', stock_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) stocks.loc['BELFER ROBERT', stock_features] = shifted_values shifted_values = stocks.loc['BHATNAGAR SANJAY', stock_features[:-1]].values stocks.loc['BHATNAGAR SANJAY', stock_features] = np.insert(shifted_values, 0, shifted_values[-1])
Correspondencia por correo electrónico
Si para estas finanzas o acciones, NaN era equivalente a 0, y esto encaja en el resultado final de cada uno de estos grupos, en el caso del correo electrónico, NaN es más razonable de reemplazar con algún valor predeterminado. Para hacer esto, puede usar Imputer:
from sklearn.impute import SimpleImputer imp = SimpleImputer()
Al mismo tiempo, consideraremos el valor predeterminado para cada categoría (si sospechamos que una persona es fraudulenta) por separado:
target = source_df[target_field] email_data = source_df[email_features] email_data = pd.concat([email_data, target], axis=1) email_data_poi = email_data[email_data[target_field]][email_features] email_data_nonpoi = email_data[email_data[target_field] == False][email_features] email_data_poi[email_features] = imp.fit_transform(email_data_poi) email_data_nonpoi[email_features] = imp.fit_transform(email_data_nonpoi) email_data = email_data_poi.append(email_data_nonpoi)
Conjunto de datos final después de la corrección:
df = payments.join(stocks) df = df.join(email_data) df = df.astype(float)
Emisiones
En el paso final de esta etapa, eliminaremos todos los valores atípicos, lo que puede distorsionar el entrenamiento. Al mismo tiempo, siempre surge la pregunta: ¿cuántos datos podemos eliminar de la muestra y aún así no perder como modelo capacitado? Seguí el consejo de uno de los profesores en el curso ML (Machine Learning) sobre Udacity: "Elimine 10 y verifique las emisiones nuevamente".
first_quartile = df.quantile(q=0.25) third_quartile = df.quantile(q=0.75) IQR = third_quartile - first_quartile outliers = df[(df > (third_quartile + 1.5 * IQR)) | (df < (first_quartile - 1.5 * IQR))].count(axis=1) outliers.sort_values(axis=0, ascending=False, inplace=True) outliers = outliers.head(10) outliers
Al mismo tiempo, no eliminaremos registros que sean atípicos y que se sospeche que son fraudulentos. La razón es que solo hay 18 filas con tales datos, y no podemos sacrificarlos, ya que esto puede conducir a la falta de ejemplos de capacitación. Como resultado, eliminamos solo a aquellos que no son sospechosos de fraude, pero que al mismo tiempo tienen una gran cantidad de signos por los cuales se observan emisiones:
target_for_outliers = target.loc[outliers.index] outliers = pd.concat([outliers, target_for_outliers], axis=1) non_poi_outliers = outliers[np.logical_not(outliers.poi)] df.drop(non_poi_outliers.index, inplace=True)
Finalizando
Normalizamos nuestros datos:
from sklearn.preprocessing import scale df[df.columns] = scale(df)
Permite dirigir la variable de destino a una vista compatible:
target.drop(non_poi_outliers.index, inplace=True) target = target.map({True: 1, False: 0}) target.value_counts()

Como resultado, 18 sospechosos y 121 aquellos que no fueron sospechosos.
Selección de funciones
Quizás uno de los puntos más importantes antes de aprender cualquier modelo es la selección de las características más importantes.
Prueba de multicolinealidad
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.set(style="whitegrid") corr = df.corr() * 100 # Select upper triangle of correlation matrix mask = np.zeros_like(corr, dtype=np.bool) mask[np.triu_indices_from(mask)] = True # Set up the matplotlib figure f, ax = plt.subplots(figsize=(15, 11)) # Generate a custom diverging colormap cmap = sns.diverging_palette(220, 10) # Draw the heatmap with the mask and correct aspect ratio sns.heatmap(corr, mask=mask, cmap=cmap, center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")
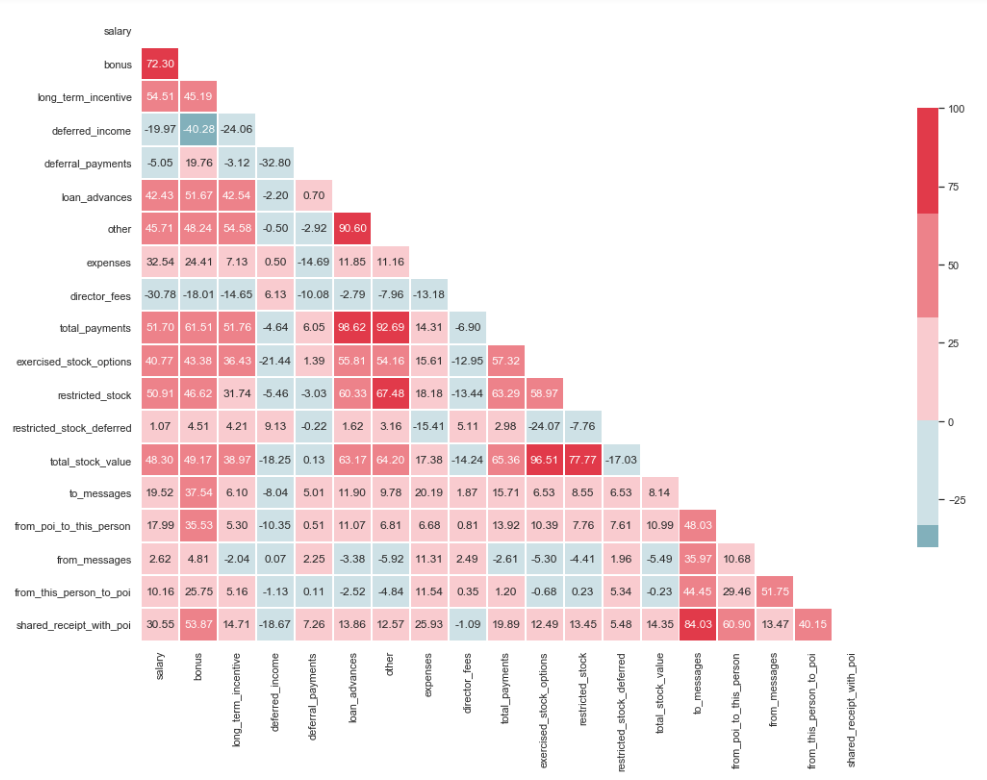
Como puede ver en la imagen, tenemos una relación pronunciada entre 'loan_advanced' y 'total_payments', así como entre 'total_stock_value' y 'restrict_stock'. Como se mencionó anteriormente, 'total_payments' y 'total_stock_value' son solo el resultado de sumar todos los indicadores en un grupo en particular. Por lo tanto, se pueden eliminar:
df.drop(columns=['total_payments', 'total_stock_value'], inplace=True)
Creando nuevas características
También se supone que los sospechosos escribieron a los cómplices con más frecuencia que a los empleados que no estuvieron involucrados en esto. Y como resultado, la proporción de tales mensajes debería ser mayor que la proporción de mensajes a empleados comunes. Según esta declaración, puede crear nuevos signos que reflejen el porcentaje de entrantes / salientes relacionados con sospechosos:
df['ratio_of_poi_mail'] = df['from_poi_to_this_person']/df['to_messages'] df['ratio_of_mail_to_poi'] = df['from_this_person_to_poi']/df['from_messages']
Detectando signos innecesarios
En el conjunto de herramientas de personas asociadas con ML, hay muchas herramientas excelentes para seleccionar las características más significativas (SelectKBest, SelectPercentile, VarianceThreshold, etc.). En este caso, se utilizará RFECV, ya que incluye validación cruzada, que le permite calcular las características más importantes y verificarlas en todos los subconjuntos de la muestra:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df, target, test_size=0.2, random_state=42)
from sklearn.feature_selection import RFECV from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(random_state=42) rfecv = RFECV(estimator=forest, cv=5, scoring='accuracy') rfecv = rfecv.fit(X_train, y_train) plt.figure() plt.xlabel("Number of features selected") plt.ylabel("Cross validation score of number of selected features") plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, '--o') indices = rfecv.get_support() columns = X_train.columns[indices] print('The most important columns are {}'.format(','.join(columns)))
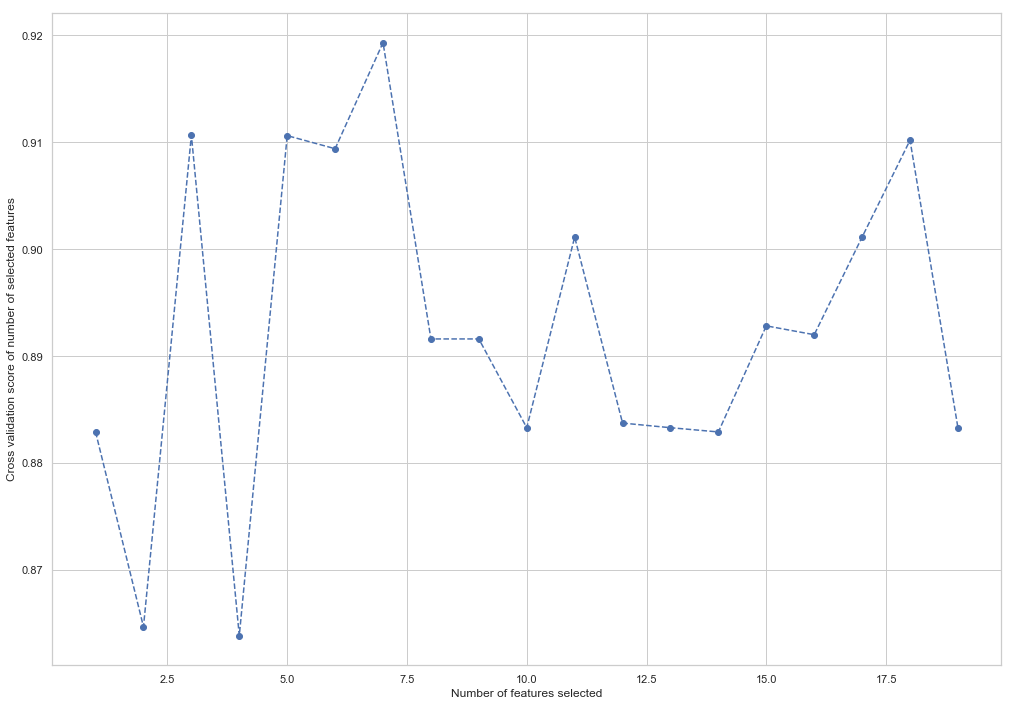
Como puede ver, RandomForestClassifier calculó que solo 7 de los 18 atributos importan. Usar el resto reduce la precisión del modelo.
The most important columns are bonus, deferred_income, other, exercised_stock_options, shared_receipt_with_poi, ratio_of_poi_mail, ratio_of_mail_to_poi
Estas 7 características se utilizarán en el futuro para simplificar el modelo y reducir el riesgo de reentrenamiento:
- bono
- ingreso diferido
- otro
- opciones_de_stocked
- shared_receipt_with_poi
- ratio_of_poi_mail
- ratio_of_mail_to_poi
Cambie la estructura de la capacitación y las muestras de prueba para la capacitación futura del modelo:
X_train = X_train[columns] X_test = X_test[columns]
Este es el final de la primera parte que describe el uso de Enron Dataset como un ejemplo de una tarea de clasificación en ML. Basado en los materiales del curso de Introducción al aprendizaje automático sobre Udacity. También hay un cuaderno de Python que refleja toda la secuencia de acciones.
La segunda parte esta aqui