
A menudo, los programadores tienen que lidiar con el código desconocido de otra persona. Este puede ser el estudio de proyectos interesantes de código abierto y la necesidad de trabajar, en caso de unirse a un nuevo proyecto, al analizar una gran cantidad de código heredado, etc. Creo que cada uno de ustedes se ha encontrado con esto.
En el proceso de dicho trabajo, siempre sentí la necesidad de una herramienta especialmente diseñada para facilitar el proceso de inmersión rápida en grandes volúmenes de código desconocido. Con el tiempo, aparecieron ideas cada vez más interesantes en diferentes áreas, y todas ellas requirieron el estudio de grandes volúmenes de código de otras personas. Redes descentralizadas, criptomonedas, compiladores, sistemas operativos: todos estos son grandes proyectos que requieren el estudio de cantidades significativas de código. En algún momento, decidí: solo necesitas tomar y hacer esta herramienta especial. En este artículo, presento a su atención lo que surgió como resultado.
¿Qué puede ayudar en general a aprender el código? Por supuesto, es bueno cuando hay documentación detallada para el código; por regla general, no está allí; un buen estilo de codificación y comentarios también son buenos, pero esto generalmente no es suficiente. También hay varios generadores de documentación de código, como doxygen. Al analizar la estructura del código y los comentarios documentales especiales, generan documentación en forma de hipertexto en formato html. La principal desventaja de dicha documentación es su falta de interactividad; En el proceso de estudiar el código, el programador puede tener una nueva comprensión, y para reflejarlo en la documentación, debe escribir nuevos comentarios documentales y volver a generar toda la documentación.
Además, dicha documentación no se relaciona directamente con el código en el entorno de desarrollo, es decir. Al hacer clic en el hipervínculo no se abrirá el archivo con este código en el IDE. Existe una buena analogía para tales herramientas, arraigadas en la antigüedad: los primeros desensambladores fueron herramientas de línea de comandos que generaron código sin intervención del usuario. Luego vino el primer desensamblador interactivo ("IDA pro"), que asumió la participación activa del usuario en el proceso de desensamblaje: asignando nombres de variables y funciones, definiendo estructuras, escribiendo comentarios en el código, etc.
El análisis de grandes volúmenes de código extranjero en un lenguaje de alto nivel es, de alguna manera, muy similar al desmontaje. Por lo tanto, comencé a desarrollar una idea de lo que quiero exactamente. La mayoría de los IDE tienen paneles clásicos de Vista de archivo y Vista de clase que muestran la estructura de los archivos y los espacios de nombre / clase dentro de ellos. Pero esta estructura generalmente está estrechamente relacionada con la sintaxis del lenguaje y no le permite realizar una carga semántica personalizada. Por lo tanto, lo primero que quería tener era la capacidad interactiva de construir árboles arbitrarios que contengan referencias de código con nombres significativos, a las mismas clases y funciones, o a lugares arbitrarios. Y el segundo es el deseo de marcar de alguna manera el código directamente en el editor. Las marcas pueden tener una variedad de significados: desde simples "aprendidas", "resueltas", "reescritas", hasta códigos que pertenecen a diferentes grupos semánticos. Puedes marcarlo con un comentario, pero quería algo más notable. Por ejemplo, cambios en el color de fondo de un fragmento de código. Por lo tanto, los separadores de color KDPV son una analogía bastante precisa del mundo real.
Después de los primeros experimentos, rápidamente me di cuenta de que este debería ser un complemento para el entorno de desarrollo moderno, y no mi propio editor. Trabajar desde dos editores al mismo tiempo es estúpido e inconveniente; La posibilidad de repetir todas las posibilidades del entorno de desarrollo no inspiró alegría, y ¿por qué hacer lo que ya se ha hecho? Por lo tanto, el complemento. Qt Creator fue elegido como el primer IDE simplemente porque las operaciones de navegación de código más populares (Ir a definición, Buscar referencias, etc.) se realizan lo más rápido posible. El próximo entorno será Visual Studio, y luego, en caso de éxito del concepto mismo, implementación para otros IDE.
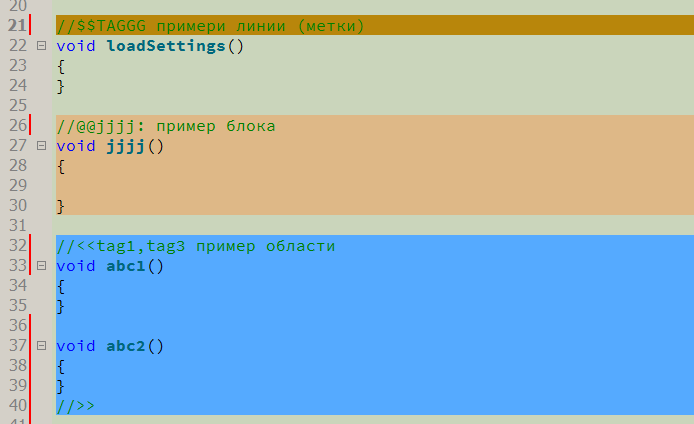
Ahora sobre cómo está todo arreglado. Se introduce el concepto de "comentarios de marcador". Este es un comentario regular de un lenguaje de programación (en este momento es un comentario de una sola línea "//" utilizado en muchos idiomas: C, C ++, C #, Java, ...), seguido de una secuencia de caracteres especiales, seguido de un identificador y / o etiquetas, que puede ser seguido por un comentario humano normal. Introduje tres tipos de comentarios de marcador
- Comentario para resaltar un área arbitraria. El único tipo que requiere un comentario de marcador "cerrar". Comienza con "// <<" y termina con "// >>".
- Comentario para indicar una línea arbitraria en el código. Denotado por "// $$"
- Comentario para resaltar el bloque de código sintácticamente correcto. Comienza con "// @@" e incluye el bloque de código a continuación, limitado por llaves "{" y "}", que se usan para bloques de código en la mayoría de los lenguajes de programación tipo C. Se ha implementado un análisis de llaves completo: se permiten llaves rizadas anidadas y el analizador omite correctamente las llaves en las líneas y los comentarios.
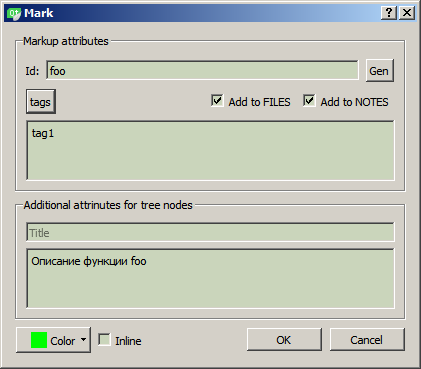
Además, inmediatamente después de los caracteres especiales, sigue uno o más identificadores, separados por comas. Los identificadores son "etiquetas" y pueden significar lo que el programador quiere: signos "estudiados", "reescribir", "comprender", autoría del código, la relación del código con algunos grupos semánticos, etc. También puede especificar un identificador único: se coloca primero y se separa del resto mediante dos puntos. Si lo desea, puede especificar explícitamente el color de fondo del fragmento de código: se coloca una cuadrícula al final de la lista de etiquetas, después de lo cual se indica el color en formato RGB (aunque este método no es el mejor, hablaremos de otra forma más "correcta" más adelante). Y al final, puede poner un espacio, luego puede escribir un comentario legible por humanos. Traté de elegir la sintaxis de tal manera que fuera lo más simple posible para una entrada rápida, no saturara el código y fuera conveniente para comentarios ordinarios.
Aunque es posible el ingreso manual de comentarios de marcadores, se supone que debe usar botones especiales de la barra de herramientas para esto. El cursor se establece en la posición deseada del código y se presiona el botón (o se selecciona una de las últimas opciones del menú).
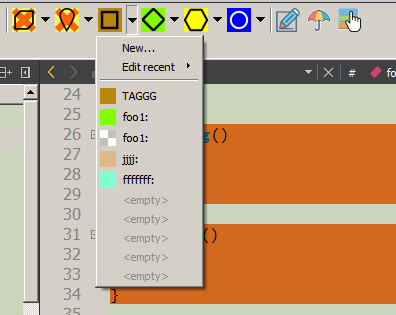
Si es necesario, se abrirá un cuadro de diálogo de entrada donde podrá ingresar etiquetas e identificadores de comentarios de marcadores, una descripción detallada y también seleccionar un color de fondo. Estos datos se ingresarán no solo en el código, sino también en el árbol “CRContentTree”, que se muestra al costado en el panel del árbol (donde FileView, ClassView, etc.). Debe tenerse en cuenta que el color de fondo puede ser "transparente"; en este caso, se utiliza el color de fondo del bloque envolvente (si lo hay) o la luz de fondo no se utiliza en absoluto.
Por el momento, el árbol consta de tres partes principales (nodos de nivel superior): ARCHIVOS, ETIQUETAS y NOTAS (esta puede no ser la solución final, porque el concepto aún no es obvio, así como la conveniencia de dicha estructura).
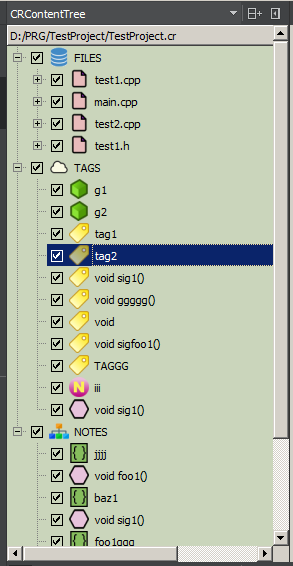
ARCHIVOS es la estructura de archivos del proyecto, que se extrae del archivo del proyecto o de la ubicación de las fuentes en el disco. Los nodos de archivo se crean durante la generación inicial del árbol. Hacer doble clic en un nodo de archivo generalmente abre el archivo en el editor IDE. Puede especificar la adición de comentarios de marcador en ARCHIVOS; luego aparecerá un nodo secundario en el archivo correspondiente. Aquí es donde se agregan identificadores de comentario de marcador únicos. El sistema verifica la unicidad del identificador dentro del nodo del archivo del árbol y hace posible generar un nombre único automáticamente.
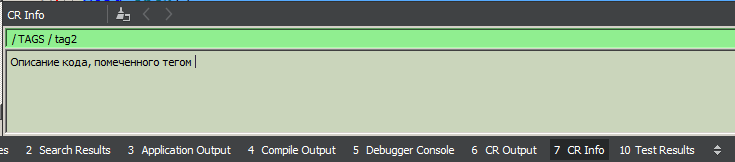
TAGS es una nube de etiquetas de proyecto global; Las etiquetas no están vinculadas al archivo de código fuente y pueden aparecer en cualquier archivo de proyecto tantas veces como desee.
NOTAS es un lugar para almacenar nodos agrupados de forma arbitraria y no vinculados a la estructura de archivos. Cada nodo contiene una ruta de archivo y un identificador. El objetivo principal es crear grupos lógicos personalizados. Por ejemplo, "todas las funciones que deben reescribirse" o "todas las funciones relacionadas con la criptografía", o "la secuencia de funciones de comunicación de red con el servidor" (dado que los nodos en el árbol están ordenados, simplemente colocando los nodos uno tras otro puede mostrar cualquier secuencia).
Cada nodo de árbol tiene un menú contextual. El nodo se puede eliminar (aunque esto no elimina los comentarios del marcador del código, siempre que no esté seguro de que sea necesario), puede editarlo. Puede agregar nodos que no están asociados con los comentarios del marcador: puede agregar, por ejemplo, un enlace (Enlace). Al hacer doble clic en dicho nodo, se abrirá un recurso relacionado en un programa asociado, por ejemplo, un hipervínculo en un navegador.
Cada nodo se puede desactivar desmarcando la casilla de verificación en el nodo. Esto hará que se elimine el resaltado de este nodo y todos los nodos secundarios en el código. Por lo tanto, al eliminar, por ejemplo, las marcas de verificación de los tres nodos raíz (ARCHIVOS, ETIQUETAS y NOTAS), puede desactivar el resaltado de todos los comentarios de marcadores, excepto aquellos cuyo color se especifica explícitamente en el código (a través de las barras).
Al hacer doble clic en el nodo, se abre el archivo correspondiente en el IDE y coloca el cursor en la posición del código correspondiente. Para las etiquetas que pueden aparecer repetidamente, en lugar de abrir el archivo, se forma una lista de todas las ocurrencias, que se carga en el panel Salida CR, y al hacer doble clic en la línea correspondiente de esta lista, puede abrir el archivo y colocarlo en el código.
Cada nodo tiene un campo para una descripción detallada (texto de varias líneas de longitud arbitraria). Esta descripción se carga en el área "Información CR" con una simple selección de un nodo en el árbol (con un solo clic del mouse), así como colocando el cursor en cualquier lugar del área resaltada en el código y haciendo clic en el botón "Buscar" en la barra de herramientas. La edición siempre está disponible, el texto modificado se guarda automáticamente (por pérdida de enfoque). Estoy pensando en admitir el formato Markdown en esta área, pero hasta ahora mis manos no han llegado a este punto.
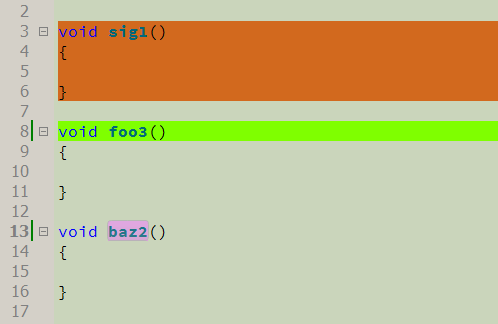
No siempre es deseable (o no siempre conveniente) insertar comentarios en el código. Por lo tanto, la segunda posibilidad son las 'firmas', es decir utilizar como marcadores del código en sí. Una firma es una cierta secuencia de tokens (excluyendo espacios y saltos de línea, es decir, "foo (1,2,3)" y "foo (1, 2, 3) son uno y lo mismo). Hay tres tipos de firmas:
- bloque: se resalta un bloque, que comienza con una firma e incluye una secuencia de código entre corchetes.
- línea única: se resalta toda la línea con la firma
- simbólico: solo se resalta la secuencia de firma. Es conveniente utilizar tales firmas para resaltar nombres individuales: variables, funciones, clases.
Trabajar con bloques de firma es lo mismo que con bloques de marcador. Del mismo modo, se crean nodos en un árbol.
Si para los nodos marcadores el identificador y las etiquetas se crearon por separado, entonces para los nodos de firma se propone indicar exactamente cómo queremos considerar la firma, como un identificador (adjunto a un archivo) o como una etiqueta global. Por ejemplo, para los "nombres" es lógico usar el modo de etiqueta; luego, el nombre correspondiente se resaltará en el código durante todo el proyecto.
Otra característica interesante es la cobertura del código de construcción. Una función especial escanea el código y determina los lugares que no están marcados, y forma una lista de dichos lugares en la "Salida CR". Esto no tiene en cuenta las líneas vacías y los comentarios, es decir el escaneo solo tiene en cuenta el código significativo. Al hacer doble clic en la línea de la lista, puede ir a este lugar en el código y, después de estudiarlo, marcarlo de una forma u otra.
Un poco sobre el formato de almacenamiento de la base de datos. En realidad, solo los comentarios de marcador se almacenan en el código fuente; El contenido del árbol se almacena en un archivo xml especial con la extensión ".cr". No existe un enlace explícito del archivo de la base de datos a los proyectos, aunque cuando abre un proyecto, se intenta abrir un archivo cr con el mismo nombre si no se ha cargado ningún archivo cr.
Para resumir. En general, implementé casi todo lo que quería. El concepto es nuevo e inusual y, por lo tanto, se necesita algo de tiempo y comentarios de los usuarios para comprender qué se necesita desarrollar y qué se puede abandonar. En un intento por aprovechar la mayor cantidad de oportunidades posible, algo resultó ser demasiado complicado, lo cual es inevitable. Es posible que la interfaz en sí misma aún no se haya establecido y cambie. Pero en general, parece haber funcionado bastante bien.
Lo que hay en los planes. Esta versión es demo, en gran parte sin formato y no está destinada a uso comercial. Tengo un sueño: hacer mi propio producto comercial, con ingresos pequeños pero constantes, suficientes para hacer otros proyectos interesantes. Además, algunas cosas no están adaptadas para uso comercial. Me imagino cómo adaptar un sistema similar para el modo multiusuario, teniendo en cuenta el hecho de que el código puede ser editado por varias personas que trabajan simultáneamente a través del sistema de control de versiones. También es posible mirar hacia la generación de documentación familiar (html), posiblemente herramientas para una integración más profunda con el código (análisis en lugar de léxico / soporte, recibir automáticamente listas de clases y métodos y convertirlos en nodos de árbol). Por supuesto, es necesario corregir errores (que todavía están allí) y mejorar las funciones. Y, por supuesto, estoy esperando tus comentarios con ideas y sugerencias :)
Eso es todo por ahora (aunque todavía hay algunas características pequeñas que no mencioné en el artículo; por ejemplo, consideré necesario agregar pestañas, ya que sin ellas es realmente triste, aunque hay varios complementos para pestañas; algunos comandos básicos de Qt también se muestran en la barra de herramientas Creador no relacionado con el complemento; etc.).
Enlace de descarga:
https://www.dropbox.com/s/9iiw5x7elwy3tpe/CodeRainbow4.zip?dl=0Requisitos del sistema: Windows, Qt Creator> = 4.5.1 compilado por MSVC2015 de 32 bits (este es el conjunto estándar distribuido en download.qt.io)
instalación: descomprima el archivo comprimido y copie el complemento en la carpeta c: /Qt/Qt5.10.1/Tools/QtCreator/lib/qtcreator/plugins (este es un ejemplo para la colocación estándar de Qt, si tiene Qt instalado de manera diferente u otra versión, la ruta será diferente) y (re) ejecute Qt Creator.