 Traducción de un proyecto completo de aprendizaje automático en Python: primera parte .
Traducción de un proyecto completo de aprendizaje automático en Python: primera parte .Cuando lees un libro o escuchas un curso de capacitación sobre análisis de datos, a menudo tienes la sensación de que estás enfrentando algunas partes separadas de una imagen que no se pueden juntar. Puede asustarse ante la posibilidad de dar el siguiente paso y resolver completamente un problema con la ayuda del aprendizaje automático, pero con la ayuda de esta serie de artículos ganará confianza en la capacidad de resolver cualquier problema en el campo de la ciencia de datos.
Para que finalmente tenga una imagen completa en su cabeza, le proponemos analizar de principio a fin el proyecto de utilizar el aprendizaje automático utilizando datos reales.
Siga sucesivamente los pasos:
- Limpieza y formateo de datos.
- Análisis exploratorio de datos.
- Diseño y selección de características.
- Comparación de las métricas de varios modelos de aprendizaje automático.
- Ajuste hiperparamétrico del mejor modelo.
- Evaluación del mejor modelo en un conjunto de datos de prueba.
- Interpretación de los resultados del modelo.
- Conclusiones y trabajo con documentos.
Aprenderá cómo los pasos van uno al otro y cómo implementarlos en Python.
Todo el proyecto está disponible en GitHub, la primera parte se encuentra
aquí. En este artículo consideraremos las tres primeras etapas.
Descripción de la tarea
Antes de escribir el código, debe comprender el problema que se está resolviendo y los datos disponibles. En este proyecto, trabajaremos con
datos de eficiencia energética disponibles públicamente
para edificios en Nueva York.
Nuestro objetivo: utilizar los datos disponibles para construir un modelo que prediga el número de Energy Star Score para un edificio en particular, e interpretar los resultados para encontrar los factores que influyen en el puntaje final.
Los datos ya incluyen el Energy Star Score asignado, por lo que nuestra tarea es el aprendizaje automático con regresión controlada:
- Supervisado: conocemos los signos y el propósito, y nuestra tarea es formar un modelo que pueda comparar el primero con el segundo.
- Regresión: el Energy Star Score es una variable continua.
Nuestro modelo debe ser preciso, para poder predecir el valor del Energy Star Score cercano a verdadero, e interpretable, para que podamos entender sus predicciones. Conociendo los datos de destino, podemos usarlos al tomar decisiones a medida que profundizamos en los datos y creamos el modelo.
Limpieza de datos
No todos los conjuntos de datos son un conjunto de observaciones perfectamente coincidentes, sin anomalías y valores faltantes (una pista de los
conjuntos de datos mtcars y
iris ). En los datos reales, hay poco orden, por lo que antes de comenzar el análisis, debe
borrarlo y llevarlo a un formato aceptable. La limpieza de datos es un procedimiento desagradable pero obligatorio para resolver la mayoría de las tareas de análisis de datos.
Primero, puede cargar los datos en forma de un marco de datos de Pandas y examinarlos:
import pandas as pd import numpy as np # Read in data into a dataframe data = pd.read_csv('data/Energy_and_Water_Data_Disclosure_for_Local_Law_84_2017__Data_for_Calendar_Year_2016_.csv') # Display top of dataframe data.head()
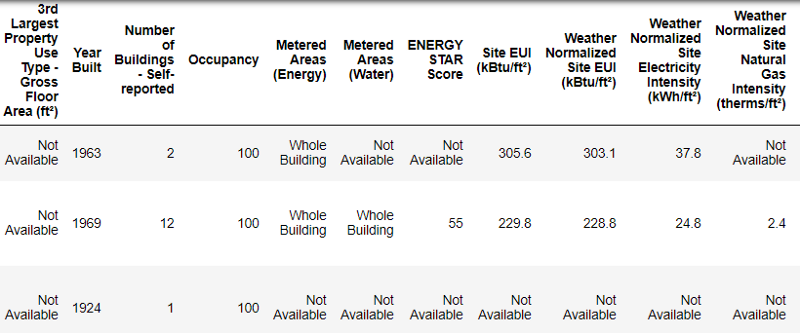 Así es como se ven los datos reales.
Así es como se ven los datos reales.Este es un fragmento de una tabla de 60 columnas. Incluso aquí, son visibles varios problemas: necesitamos predecir el
Energy Star Score , pero no sabemos qué significan todas estas columnas. Aunque esto no es necesariamente un problema, porque a menudo puede crear un modelo preciso sin saber nada de variables. Pero la interpretabilidad es importante para nosotros, por lo que necesitamos descubrir el significado de al menos unas pocas columnas.
Cuando recibimos estos datos, no preguntamos sobre los valores, sino que miramos el nombre del archivo:
y decidió buscar "Ley Local 84". Encontramos
esta página , que decía que estamos hablando de la ley vigente en Nueva York, según la cual los propietarios de todos los edificios de cierto tamaño deben informar sobre el consumo de energía. Una búsqueda adicional ayudó a encontrar
todos los valores de columna . Así que no descuides los nombres de archivo, pueden ser un buen punto de partida. Además, este es un recordatorio de que no te apresures y no te pierdas algo importante.
No estudiaremos todas las columnas, pero definitivamente trataremos con el Energy Star Score, que se describe a continuación:
La clasificación porcentual es de 1 a 100, que se calcula sobre la base de informes anuales sobre el consumo de energía de los propios propietarios del edificio. Energy Star Score es una medida relativa utilizada para comparar el rendimiento energético de los edificios.
El primer problema se resolvió, pero el segundo permaneció: valores faltantes, marcados como "No disponible". Este es un valor de cadena en Python, lo que significa que incluso las cadenas con números se almacenarán como tipos de datos de
object , porque si hay alguna cadena en la columna, Pandas la convierte en una columna que consiste completamente en una cadena. Los tipos de datos de columna se pueden encontrar utilizando el método
dataframe.info() :
# See the column data types and non-missing values data.info()
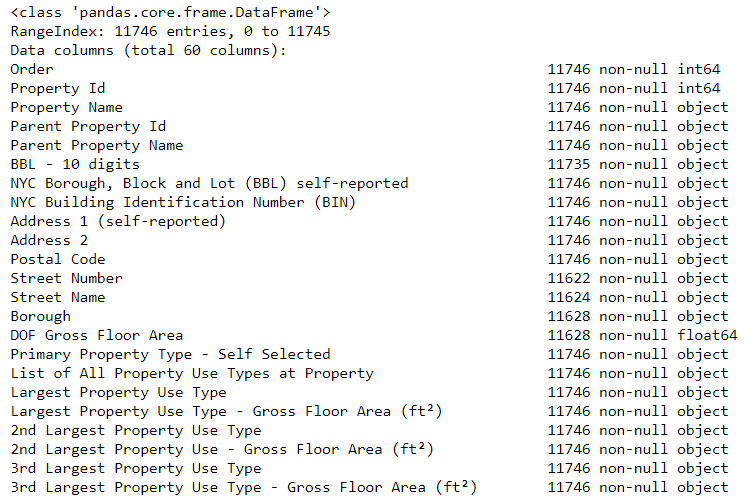
Seguramente algunas columnas que contienen números explícitamente (como ft²) se almacenan como objetos. ¡No podemos aplicar el análisis numérico a los valores de cadena, por lo que los convertimos a tipos de datos numéricos (especialmente
float )!
Este código primero reemplaza todo "No disponible" con
un número (
np.nan ), que puede interpretarse como números, y luego convierte el contenido de ciertas columnas a un tipo
float :
# Replace all occurrences of Not Available with numpy not a number data = data.replace({'Not Available': np.nan}) # Iterate through the columns for col in list(data.columns): # Select columns that should be numeric if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in col or 'therms' in col or 'gal' in col or 'Score' in col): # Convert the data type to float data[col] = data[col].astype(float)
Cuando los valores en las columnas correspondientes con nosotros se convierten en números, podemos comenzar a examinar los datos.
Datos faltantes y anormales
Junto con los tipos de datos incorrectos, uno de los problemas más comunes es la falta de valores. Pueden estar ausentes por varias razones, y antes de entrenar el modelo, estos valores deben completarse o eliminarse. Primero, descubramos cuántos valores tenemos en cada columna (el
código está aquí ).
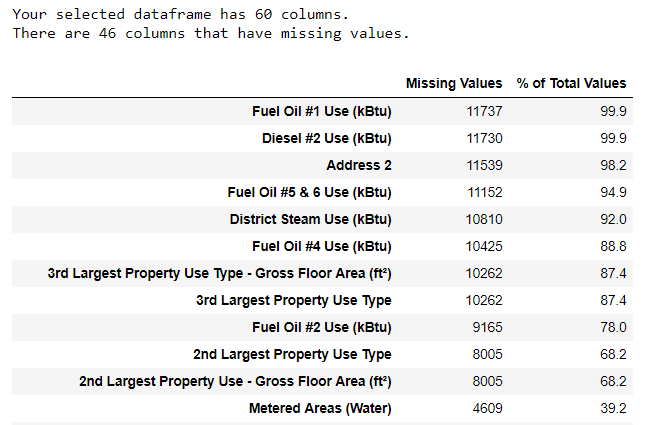 Para crear una tabla, se utilizó una función de una rama en StackOverflow .
Para crear una tabla, se utilizó una función de una rama en StackOverflow .La información siempre debe eliminarse con precaución, y si hay muchos valores en la columna, entonces probablemente no beneficiará a nuestro modelo. El umbral después del cual es mejor tirar las columnas depende de su tarea (
aquí hay una discusión ), y en nuestro proyecto eliminaremos las columnas que estén más que medio vacías.
También en esta etapa es mejor eliminar los valores anormales. Pueden ocurrir debido a errores tipográficos al ingresar datos o debido a errores en las unidades de medida, o pueden ser correctos, pero valores extremos. En este caso, eliminaremos los valores "extra", guiados por la
definición de anomalías extremas :
- Debajo del primer cuartil hay un rango intercuartil de 3 ∗.
- Por encima del tercer cuartil + 3 range rango intercuartil.
El código que elimina columnas y anomalías aparece en el Bloc de notas en Github. Una vez completado el proceso de limpieza de datos y eliminación de anomalías, tenemos más de 11,000 edificios y 49 letreros.
Análisis exploratorio de datos
La aburrida pero necesaria etapa de limpieza de datos ha finalizado, ¡puedes ir al estudio!
El análisis exploratorio de datos (RAD) es un proceso de tiempo ilimitado durante el cual calculamos estadísticas y buscamos tendencias, anomalías, patrones o relaciones en los datos.
En resumen, RAD es un intento de descubrir qué datos nos pueden decir. Por lo general, el análisis comienza con una revisión de la superficie, luego encontramos fragmentos interesantes y los analizamos con más detalle. Los hallazgos pueden ser interesantes por derecho propio, o pueden contribuir a la elección del modelo, ayudando a decidir qué características utilizaremos.
Gráficos de una variable
Nuestro objetivo es predecir el valor del Energy Star Score (renombrado a nuestro
score en nuestros datos), por lo que tiene sentido comenzar examinando la distribución de esta variable. Un histograma es una forma simple pero efectiva de visualizar la distribución de una sola variable, y se puede construir fácilmente usando
matplotlib .
import matplotlib.pyplot as plt # Histogram of the Energy Star Score plt.style.use('fivethirtyeight') plt.hist(data['score'].dropna(), bins = 100, edgecolor = 'k'); plt.xlabel('Score'); plt.ylabel('Number of Buildings'); plt.title('Energy Star Score Distribution');
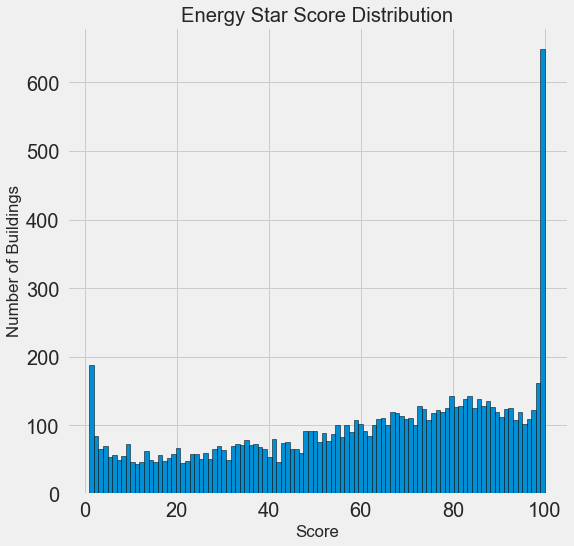
¡Parece sospechoso! El Energy Star Score es un percentil, por lo que debe esperar una distribución uniforme cuando cada punto se asigna al mismo número de edificios. Sin embargo, un número desproporcionadamente grande de edificios recibió los resultados más altos y más bajos (para el Energy Star Score, cuanto más grande, mejor).
Si volvemos a ver la definición de este puntaje, veremos que se calcula sobre la base de "informes rellenados independientemente por los propietarios del edificio", lo que puede explicar el exceso de valores muy grandes. Pedir a los propietarios de edificios que informen sobre su consumo de energía es como pedirles a los estudiantes que informen sus calificaciones en los exámenes. Quizás este no sea el criterio más objetivo para evaluar la eficiencia energética de los bienes raíces.
Si tuviéramos un suministro de tiempo ilimitado, podríamos descubrir por qué tantos edificios tienen puntos muy altos y muy bajos. Para hacer esto, tendríamos que elegir los edificios apropiados y analizarlos cuidadosamente. Pero solo necesitamos aprender a predecir los puntajes y no desarrollar un método de evaluación más preciso. Puede marcarse que los puntos tienen una distribución sospechosa, pero nos centraremos en el pronóstico.
Búsqueda de relaciones
La parte principal del AHFR es la búsqueda de la relación entre los signos y nuestro objetivo. Las variables que se correlacionan con él son útiles para usar en el modelo, porque pueden usarse para pronosticar. Una forma de estudiar el efecto de una variable categórica (que solo toma un conjunto limitado de valores) en el objetivo es trazar la densidad utilizando la biblioteca Seaborn.
El gráfico de densidad puede considerarse un histograma suavizado porque muestra la distribución de una sola variable. Puede colorear clases individuales en el gráfico para ver cómo una variable categórica cambia la distribución. Este código traza la tabla de densidad Energy Star Score, coloreada de acuerdo con el tipo de edificio (para una lista de edificios con más de 100 dimensiones):
# Create a list of buildings with more than 100 measurements types = data.dropna(subset=['score']) types = types['Largest Property Use Type'].value_counts() types = list(types[types.values > 100].index) # Plot of distribution of scores for building categories figsize(12, 10) # Plot each building for b_type in types: # Select the building type subset = data[data['Largest Property Use Type'] == b_type] # Density plot of Energy Star Scores sns.kdeplot(subset['score'].dropna(), label = b_type, shade = False, alpha = 0.8); # label the plot plt.xlabel('Energy Star Score', size = 20); plt.ylabel('Density', size = 20); plt.title('Density Plot of Energy Star Scores by Building Type', size = 28);
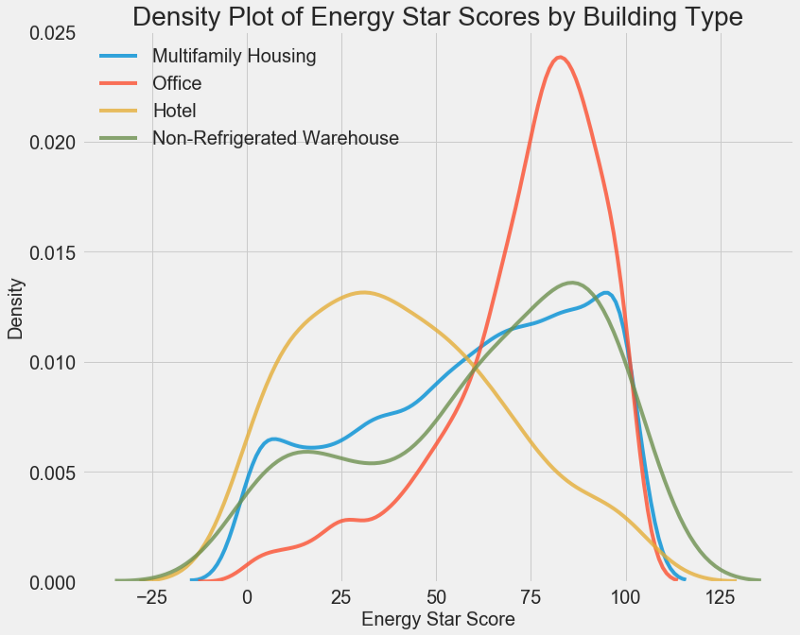
Como puede ver, el tipo de edificio afecta en gran medida el número de puntos. Los edificios de oficinas suelen tener una puntuación más alta y los hoteles más bajos. Por lo tanto, debe incluir el tipo de edificio en el modelo, porque este signo afecta nuestro objetivo. Como una variable categórica, debemos realizar una codificación de uno en caliente del tipo de construcción.
Se puede usar un gráfico similar para estimar el puntaje Energy Star por distrito de la ciudad:
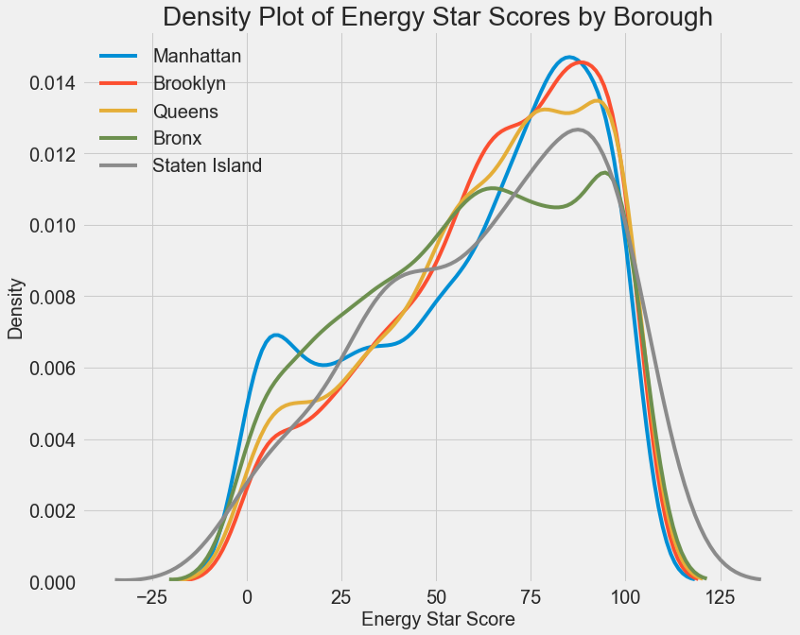
El área no afecta tanto el puntaje como el tipo de edificio. Sin embargo, lo incluiremos en el modelo, porque hay una ligera diferencia entre las regiones.
Para calcular la relación entre las variables, puede usar
el coeficiente de correlación de Pearson . Esta es una medida de la intensidad y dirección de una relación lineal entre dos variables. Un valor de +1 significa una relación positiva perfectamente lineal, y -1 significa una relación negativa perfectamente lineal. Estos son algunos ejemplos de valores del
coeficiente de correlación de
Pearson :

Aunque este coeficiente no puede reflejar dependencias no lineales, es posible comenzar con él para evaluar las relaciones de las variables. En Pandas, puede calcular fácilmente las correlaciones entre cualquier columna en un marco de datos:
# Find all correlations with the score and sort correlations_data = data.corr()['score'].sort_values()
Las correlaciones más negativas con el objetivo:

y lo más positivo:

Existen varias correlaciones negativas fuertes entre los atributos y el objetivo, y la mayor de ellas pertenece a diferentes categorías de IUE (los métodos para calcular estos indicadores difieren ligeramente).
EUI (Energy Use Intensity ) es la cantidad de energía consumida por un edificio dividido por un pie cuadrado de área. Este valor específico se utiliza para evaluar la eficiencia energética, y cuanto más pequeño sea, mejor. La lógica sugiere que estas correlaciones están justificadas: si el EUI aumenta, entonces el Energy Star Score debería disminuir.
Gráficos de dos variables
Utilizamos gráficos de dispersión para visualizar las relaciones entre dos variables continuas. Puede agregar información adicional a los colores de los puntos, por ejemplo, una variable categórica. La relación entre el Energy Star Score y el EUI se muestra a continuación, los colores indican diferentes tipos de edificios:
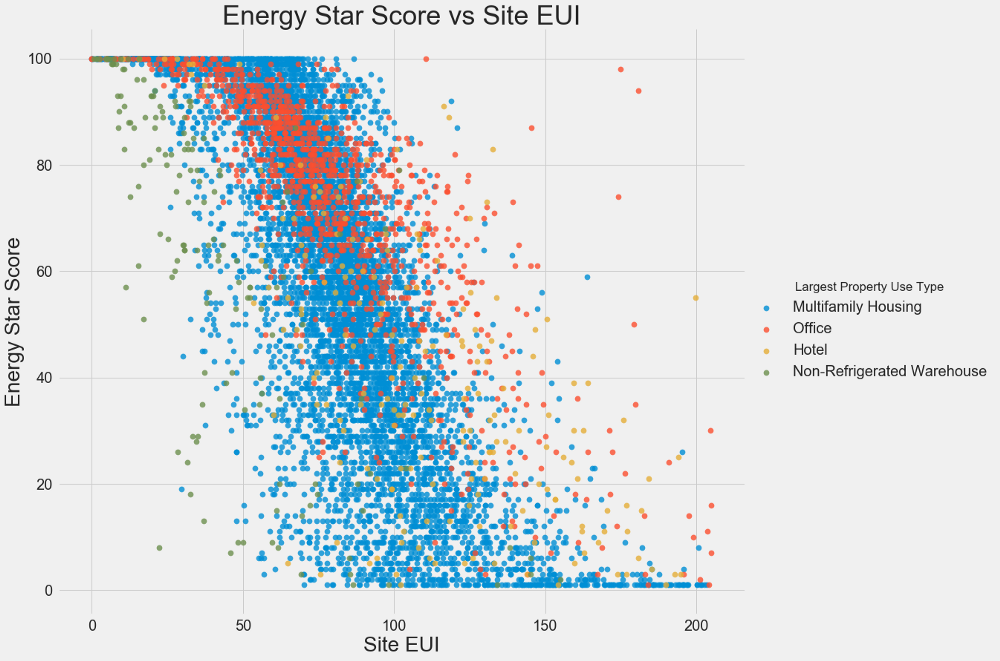
Este gráfico le permite visualizar un coeficiente de correlación de -0.7. A medida que disminuye el EUI, aumenta el puntaje Energy Star, esta relación se observa en diferentes tipos de edificios.
Nuestro último cuadro de investigación se llama
Parcela de pares . Esta es una gran herramienta para ver las relaciones entre diferentes pares de variables y la distribución de variables individuales. Utilizaremos la biblioteca Seaborn y la función PairGrid para crear un gráfico de pares con un gráfico de dispersión en el triángulo superior, con un histograma diagonal, un gráfico de densidad central bidimensional y coeficientes de correlación en el triángulo inferior.
# Extract the columns to plot plot_data = features[['score', 'Site EUI (kBtu/ft²)', 'Weather Normalized Source EUI (kBtu/ft²)', 'log_Total GHG Emissions (Metric Tons CO2e)']] # Replace the inf with nan plot_data = plot_data.replace({np.inf: np.nan, -np.inf: np.nan}) # Rename columns plot_data = plot_data.rename(columns = {'Site EUI (kBtu/ft²)': 'Site EUI', 'Weather Normalized Source EUI (kBtu/ft²)': 'Weather Norm EUI', 'log_Total GHG Emissions (Metric Tons CO2e)': 'log GHG Emissions'}) # Drop na values plot_data = plot_data.dropna() # Function to calculate correlation coefficient between two columns def corr_func(x, y, **kwargs): r = np.corrcoef(x, y)[0][1] ax = plt.gca() ax.annotate("r = {:.2f}".format(r), xy=(.2, .8), xycoords=ax.transAxes, size = 20) # Create the pairgrid object grid = sns.PairGrid(data = plot_data, size = 3) # Upper is a scatter plot grid.map_upper(plt.scatter, color = 'red', alpha = 0.6) # Diagonal is a histogram grid.map_diag(plt.hist, color = 'red', edgecolor = 'black') # Bottom is correlation and density plot grid.map_lower(corr_func); grid.map_lower(sns.kdeplot, cmap = plt.cm.Reds) # Title for entire plot plt.suptitle('Pairs Plot of Energy Data', size = 36, y = 1.02);
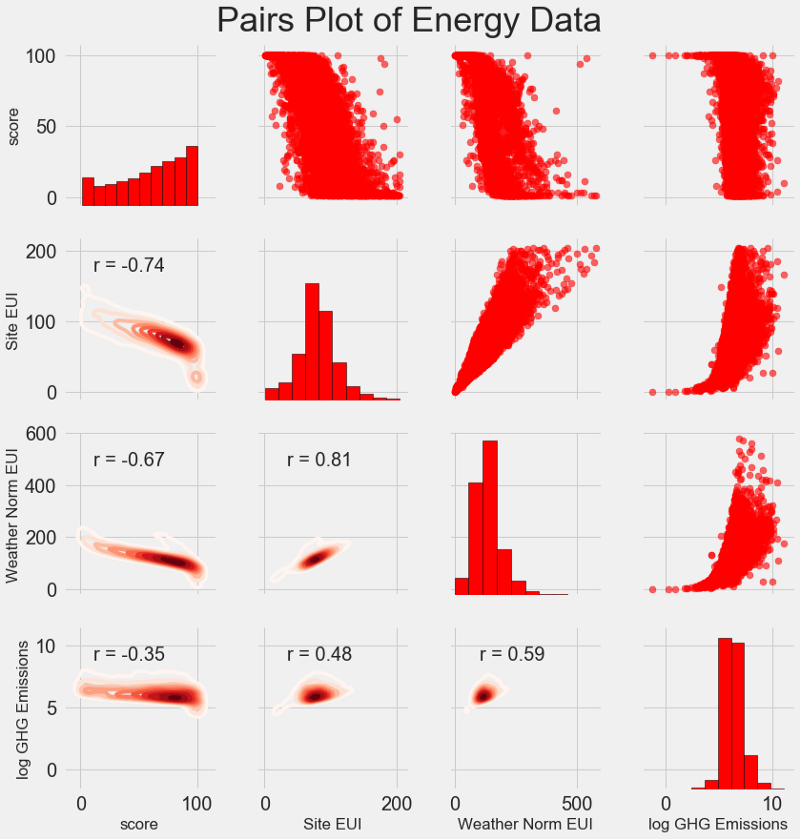
Para ver la relación de variables, busque la intersección de filas y columnas. Supongamos que desea ver la correlación entre la
Weather Norm EUI y la
score , luego buscamos la serie
Weather Norm EUI y la columna de
score , en la intersección de la cual hay un coeficiente de correlación de -0.67. Estos gráficos no solo se ven geniales, sino que también ayudan a elegir variables para el modelo.
Diseño y selección de características.
El diseño y la selección de características a menudo brindan el mayor rendimiento en términos del tiempo dedicado al aprendizaje automático. Primero damos las definiciones:
- Construcción característica: proceso de extracción o creación de nuevas características a partir de datos sin procesar. Para usar variables en el modelo, es posible que deba transformarlas, por ejemplo, tomar el logaritmo natural, extraer la raíz cuadrada o aplicar una codificación de variables categóricas. Se puede considerar que el diseño característico crea características adicionales a partir de datos sin procesar.
- Selección de características: El proceso de seleccionar las características más relevantes de los datos, durante el cual eliminamos algunas características para ayudar al modelo a generalizar mejor los datos nuevos a fin de obtener un modelo más interpretable. La elección de los signos puede considerarse como la eliminación de "superfluo", de modo que solo queda lo más importante.
El modelo de aprendizaje automático solo puede aprender de los datos que proporcionamos, por lo que es extremadamente importante asegurarse de que incluyamos toda la información relevante para nuestra tarea. Si no proporciona al modelo los datos correctos, ¡no podrá aprender y no producirá pronósticos precisos!
Haremos lo siguiente:
- Aplicable a las variables categóricas (trimestre y tipo de propiedad) codificación one-hot.
- Agregue el logaritmo natural de todas las variables numéricas.
La codificación de hot-one es necesaria para incluir variables categóricas en el modelo. El algoritmo de aprendizaje automático no podrá comprender el tipo de "oficina", por lo que si el edificio es una oficina, le asignaremos un signo de 1, y si no es una oficina, entonces 0.
Agregar características transformadas ayudará al modelo a aprender sobre relaciones no lineales dentro de los datos. En el análisis de datos, es una práctica normal
extraer raíces cuadradas, tomar logaritmos naturales o de alguna manera transformar los signos , depende de la tarea específica o de su conocimiento de las mejores técnicas. En este caso, agregaremos el logaritmo natural de todos los signos numéricos.
Este código selecciona signos numéricos, calcula sus logaritmos, selecciona dos signos categóricos, les aplica una codificación de uno en caliente y combina ambos conjuntos en uno. A juzgar por la descripción, queda mucho trabajo por hacer, ¡pero en Pandas todo es bastante simple!
# Copy the original data features = data.copy() # Select the numeric columns numeric_subset = data.select_dtypes('number') # Create columns with log of numeric columns for col in numeric_subset.columns: # Skip the Energy Star Score column if col == 'score': next else: numeric_subset['log_' + col] = np.log(numeric_subset[col]) # Select the categorical columns categorical_subset = data[['Borough', 'Largest Property Use Type']] # One hot encode categorical_subset = pd.get_dummies(categorical_subset) # Join the two dataframes using concat # Make sure to use axis = 1 to perform a column bind features = pd.concat([numeric_subset, categorical_subset], axis = 1)
Ahora tenemos más de 11,000 observaciones (edificios) con 110 columnas (etiquetas). No todos los signos serán útiles para predecir el puntaje Energy Star, por lo que tomaremos la selección de signos y eliminaremos algunas de las variables.
Selección de funciones
Muchos de los 110 signos disponibles son redundantes porque se correlacionan fuertemente entre sí. Por ejemplo, aquí hay un gráfico del EUI y el EUI del sitio normalizado del clima, con un coeficiente de correlación de 0.997.
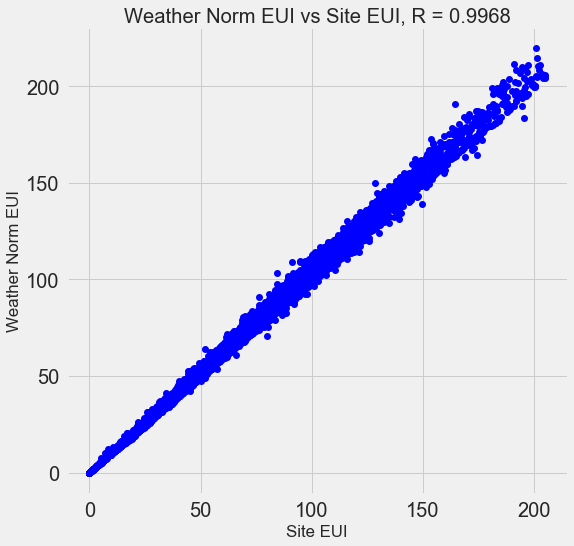
Los signos que se correlacionan fuertemente entre sí se denominan
colineales . Eliminar una variable en tales pares de atributos a menudo ayuda al
modelo a generalizarse y ser más interpretable . Tenga en cuenta que estamos hablando de la correlación de algunos signos con otros, y no de la correlación con el objetivo, ¡lo que solo ayudaría a nuestro modelo!
Existen varios métodos para calcular la colinealidad de las características, y uno de los más populares es el
factor de inflación de varianza . Usaremos el coeficiente de bcorrelación para buscar y eliminar entidades colineales. Descartamos un par de signos si el coeficiente de correlación entre ellos es superior a 0.6. El código está en el bloc de notas (y en respuesta al
desbordamiento de pila ).
Este valor parece arbitrario, pero de hecho probé diferentes umbrales, y lo anterior me permitió crear el mejor modelo. El aprendizaje automático es
empírico y, a menudo, tiene que experimentar para encontrar la mejor solución. Después de la selección, tenemos 64 atributos y un objetivo.
# Remove any columns with all na values features = features.dropna(axis=1, how = 'all') print(features.shape) (11319, 65)
Elige un nivel base
Limpiamos los datos, realizamos un análisis exploratorio y construimos los signos. Y antes de continuar con la creación del modelo, debe elegir el nivel base inicial (línea de base ingenua), una especie de suposición con la que compararemos los resultados de los modelos. Si caen por debajo del nivel básico, asumiremos que el aprendizaje automático no es aplicable para esta tarea, o que se debe intentar un enfoque diferente.
Para las tareas de regresión, como nivel base, es razonable adivinar el valor medio de la meta en el conjunto de entrenamiento para todos los ejemplos en el conjunto de prueba. Estos kits establecen una barrera que es relativamente baja para cualquier modelo.
Como métrica, tomamos el
error absoluto promedio (mae) en los pronósticos. Hay muchas otras métricas para las regresiones, pero me gusta el
consejo de elegir una métrica y usarla para evaluar modelos. Y el error absoluto promedio es fácil de calcular e interpretar.
Antes de calcular el nivel base, debe dividir los datos en conjuntos de entrenamiento y prueba:
- Un conjunto de atributos de capacitación es lo que proporcionamos a nuestro modelo junto con las respuestas durante la capacitación. El modelo debe aprender a igualar las características de la meta.
- Un conjunto de características de prueba se utiliza para evaluar el modelo entrenado. Cuando procesa el conjunto de pruebas, no ve las respuestas correctas y debe predecir basándose solo en las funciones disponibles. Conocemos las respuestas para los datos de la prueba y podemos comparar los resultados del pronóstico con ellos.
Para la capacitación, utilizamos el 70% de los datos y para las pruebas, el 30%:
# Split into 70% training and 30% testing set X, X_test, y, y_test = train_test_split(features, targets, test_size = 0.3, random_state = 42)
Ahora calculamos el indicador para el nivel base inicial:
# Function to calculate mean absolute error def mae(y_true, y_pred): return np.mean(abs(y_true - y_pred)) baseline_guess = np.median(y) print('The baseline guess is a score of %0.2f' % baseline_guess) print("Baseline Performance on the test set: MAE = %0.4f" % mae(y_test, baseline_guess))
La estimación inicial es un puntaje de 66.00
Rendimiento de referencia en el conjunto de prueba: MAE = 24.5164El error absoluto promedio en el conjunto de prueba fue de aproximadamente 25 puntos. Como evaluamos en el rango de 1 a 100, el error es del 25%, ¡una barrera bastante baja para el modelo!
Conclusión
En este artículo, pasamos por las primeras tres etapas de resolución de un problema mediante el aprendizaje automático. Después de configurar la tarea, nosotros:
- Datos sin procesar borrados y formateados.
- Se realizó un análisis exploratorio para estudiar los datos disponibles.
- Desarrollamos un conjunto de características que utilizaremos para nuestros modelos.
Finalmente, calculamos el nivel base con el que evaluaremos nuestros algoritmos.En el próximo artículo, aprenderemos cómo usar Scikit-Learn para evaluar modelos de aprendizaje automático, elegir el mejor modelo y realizar su ajuste hiperparamétrico.