
Quiero compartir otra noche de construcción a largo plazo, lo que demuestra que puedes hacer juegos incluso en hardware débil.
Sobre lo que tenía que hacer, cómo se decidió y cómo hacer algo más que otro clon de Pong: bienvenido a Cat.
Precaución: ¡excelente artículo, tráfico y múltiples inserciones de código!
Brevemente sobre el juego
¡Dispárales! - Ahora en AVR.
De hecho, este es otro shmap, por lo que una vez más, el personaje principal
Shepard debe salvar a la galaxia de un ataque repentino de personas desconocidas, abriéndose paso a través del espacio a través de las estrellas y los campos de asteroides que limpian simultáneamente cada sistema estelar.
Todo el juego está escrito en C y C ++ sin usar la biblioteca Wire de Arduino.
El juego tiene 4 barcos para elegir (este último está disponible después de pasar), cada uno con sus propias características:
- maniobrabilidad;
- durabilidad
- arma de fuego.
También implementado:
- Gráficos en color 2D;
- encendido para armas;
- jefes al final de los niveles;
- niveles con asteroides (y su animación de rotación);
- cambio de color de fondo en los niveles (y no solo en el espacio negro);
- el movimiento de estrellas en el fondo a diferentes velocidades (por efecto de profundidad);
- puntuación y ahorro en EEPROM;
- los mismos sonidos (disparos, explosiones, etc.);
- Un mar de oponentes idénticos.
Plataforma
El regreso del fantasma.
Aclararé de antemano que esta plataforma debe ser percibida como la vieja consola de juegos de la primera tercera generación (80, shiru8bit ).
Además, las modificaciones de hardware sobre el hardware original están prohibidas, lo que garantiza el lanzamiento en cualquier otra placa idéntica desde el primer momento.
Este juego fue escrito para el tablero Arduino Esplora, pero creo que transferirlo a GBA o cualquier otra plataforma no será difícil.
Sin embargo, incluso en este recurso, esta placa se cubrió solo un par de veces, y no valía la pena mencionar otras tablas, a pesar de la comunidad bastante grande de cada una:
- GameBuino META:
- Pokitto;
- makerBuino;
- Arduboy
- UzeBox / FuzeBox;
- y muchos otros
Para empezar, lo que no está en Esplora:
- mucha memoria (ROM 28kb, RAM 2.5kb);
- potencia (CPU de 8 bits a 16 MHz);
- DMA
- generador de personajes;
- áreas de memoria asignadas o registros especiales. destino (paleta, azulejos, fondo, etc.);
- controla el brillo de la pantalla (oh, tantos efectos en la basura);
- extensores de espacio de direcciones (mapeadores);
- depurador (¡
pero quién lo necesita cuando hay una pantalla completa! ).
Continuaré con el hecho de que hay:
- SPI de hardware (puede ejecutarse a velocidad F_CPU / 2);
- pantalla basada en ST7735 160x128 1.44 ";
- una pizca de temporizadores (solo 4 piezas);
- una pizca de GPIO;
- un puñado de botones (5 piezas + joystick de dos ejes);
- pocos sensores (iluminación, acelerómetro, termómetro);
- emisor de
irritación piezo zumbador.
Aparentemente no hay casi nada allí. ¡No es sorprendente que nadie quisiera hacer nada con ella excepto el clon de Pong y un par de tres juegos durante todo este tiempo!
Quizás el hecho es que escribir bajo el controlador ATmega32u4 (y similares) es similar a la programación para Intel 8051 (que tiene casi 40 años en el momento de la publicación), donde debe observar una gran cantidad de condiciones y recurrir a varios trucos y trucos.
Procesamiento periférico
¡Uno para todo!
Después de mirar el circuito, era claramente visible que todos los periféricos están conectados a través del expansor GPIO (multiplexor 74HC4067D más MUX) y se conmutan usando GPIO PF4, PF5, PF6, PF7 o el mordisco PORTF senior, y la salida MUX se lee en GPIO - PF1.
Es muy conveniente cambiar la entrada simplemente asignando valores al puerto PORTF por máscara y sin olvidar el mordisco menor:
uint16_t getAnalogMux(uint8_t chMux) { MUX_PORTX = ((MUX_PORTX & 0x0F) | ((chMux<<4)&0xF0)); return readADC(); }
Encuesta de clic de botón:
#define SW_BTN_MIN_LVL 800 bool readSwitchButton(uint8_t btn) { bool state = true; if(getAnalogMux(btn) > SW_BTN_MIN_LVL) {
Los siguientes son los valores para el puerto F:
#define SW_BTN_1_MUX 0 #define SW_BTN_2_MUX 8 #define SW_BTN_3_MUX 4 #define SW_BTN_4_MUX 12
Al agregar un poco más:
#define BUTTON_A SW_BTN_4_MUX #define BUTTON_B SW_BTN_1_MUX #define BUTTON_X SW_BTN_2_MUX #define BUTTON_Y SW_BTN_3_MUX #define buttonIsPressed(a) readSwitchButton(a)
Puede entrevistar con seguridad la cruz correcta:
void updateBtnStates(void) { if(buttonIsPressed(BUTTON_A)) btnStates.aBtn = true; if(buttonIsPressed(BUTTON_B)) btnStates.bBtn = true; if(buttonIsPressed(BUTTON_X)) btnStates.xBtn = true; if(buttonIsPressed(BUTTON_Y)) btnStates.yBtn = true; }
Tenga en cuenta que el estado anterior no se restablece, de lo contrario, puede perderse el hecho de presionar la tecla (también funciona como una protección adicional contra el parloteo).
Sfx
Un zumbido.
¿Qué pasa si no hay DAC, no hay chip de Yamaha, y solo hay un rectángulo PWM de 1 bit para el sonido?
Al principio, no parece tanto, pero, a pesar de esto, el astuto PWM se usa aquí para recrear la técnica de "audio PDM" y con su ayuda puede hacerlo
.La biblioteca de Gamebuino proporciona algo similar y todo lo que se necesita es transferir el generador emergente a otro GPIO y el temporizador a Esplora (salida timer4 y OCR4D). Para un funcionamiento correcto, el temporizador 1 también se utiliza para generar interrupciones y volver a cargar el registro OCR4D con nuevos datos.
El motor de Gamebuino usa patrones de sonido (como en la música del rastreador), lo que ahorra mucho espacio, pero debe hacer todas las muestras usted mismo, no hay bibliotecas con las listas para usar.
Vale la pena mencionar que este motor está vinculado a un período de actualización de aproximadamente 1/50 segundos o 20 cuadros / segundo.
Para leer patrones de sonido, después de leer el Wiki en formato de audio, dibujé una GUI simple en Qt. No emite sonido de la misma manera, pero ofrece un concepto aproximado de cómo sonará el patrón y le permite cargarlo, guardarlo y editarlo.
Gráficos
Pixelart inmortal.
La pantalla codifica los colores en dos bytes (RGB565), pero dado que las imágenes en este formato ocuparán mucho, la paleta indexó todas ellas para ahorrar espacio, que ya he descrito más de una vez en mis artículos anteriores.
A diferencia de Famicom / NES, no hay límites de color para la imagen y hay más colores disponibles en la paleta.
Cada imagen en el juego es una matriz de bytes en la que se almacenan los siguientes datos:
- ancho, alto;
- iniciar marcador de datos;
- diccionario (si lo hay, pero más sobre eso más adelante);
- carga útil
- Fin del marcador de datos.
Por ejemplo, tal imagen (ampliada 10 veces):

en el código se verá así:
pic_t weaponLaserPic1[] PROGMEM = { 0x0f,0x07, 0x02, 0x8f,0x32,0xa2,0x05,0x8f,0x06,0x22,0x41,0xad,0x03,0x41,0x22,0x8f,0x06,0xa2,0x05, 0x8f,0x23,0xff, };
¿Dónde sin un barco en este género? Después de cientos de bocetos de prueba con una diferencia de píxeles, solo quedaron estos barcos para el jugador:

Es de destacar que los barcos no tienen una llama en las baldosas (aquí está para mayor claridad), se aplica por separado para crear una animación del escape del motor.
No te olvides de los pilotos de cada barco:

La variación de las naves enemigas no es demasiado grande, pero déjame recordarte que no hay demasiado espacio, así que aquí hay tres naves:

Sin bonos canónicos en la forma de mejorar las armas y restaurar la salud, el jugador no durará mucho:

Por supuesto, con el aumento en el poder de las armas, el tipo de proyectiles emitidos cambia:

Como se escribió al principio, el juego tiene un nivel de asteroides, viene después de cada segundo jefe. Es interesante porque hay muchos objetos móviles y giratorios de diferentes tamaños. Además, cuando un jugador los golpea, colapsan parcialmente, volviéndose más pequeños en tamaño.
Sugerencia: los asteroides grandes ganan más puntos.



Para crear esta animación simple, 12 imágenes pequeñas son suficientes:

Se dividen en tres para cada tamaño (grande, mediano y pequeño) y para cada ángulo de rotación necesita 4 más rotados 0, 90, 180 y 270 grados. En el juego, es suficiente reemplazar el puntero a la matriz con la imagen en un intervalo igual, creando así la ilusión de rotación.
void rotateAsteroid(asteroid_t &asteroid) { if(RN & 1) { asteroid.sprite.pPic = getAsteroidPic(asteroid); ++asteroid.angle; } } void moveAsteroids(void) { for(auto &asteroid : asteroids) { if(asteroid.onUse) { updateSprite(&asteroid.sprite); rotateAsteroid(asteroid); ...
Esto se hace solo debido a la falta de capacidades de hardware, y una implementación de software como la transformación Affine tomará más que las imágenes en sí y será muy lenta.
Un pedazo de satén para los interesados.
Puedes notar parte de los prototipos y lo que aparece solo en los créditos después de pasar el juego.
Además de los gráficos simples, para ahorrar espacio y agregar un efecto retro, los glifos en minúsculas y todos los glifos que tenían hasta 30 y después de 127 bytes de ASCII fueron eliminados de la fuente.
Importante!
No olvide que const y constexpr en AVR no significa en absoluto que los datos estarán en la memoria del programa, aquí para esto necesita usar PROGMEM adicionalmente.
Esto se debe al hecho de que el núcleo AVR se basa en la arquitectura de Harvard, por lo que se necesitan códigos de acceso especiales para la CPU para acceder a los datos.
Exprimiendo la galaxia
La forma más fácil de empacar es RLE.
Después de estudiar los datos empaquetados, puede observar que no se utiliza el bit más significativo en el byte de carga útil en el rango de 0x00 a 0x50. Esto le permite agregar los datos y el marcador de inicio para el inicio de la repetición (0x80), y el siguiente byte para indicar el número de repeticiones, lo que le permite empaquetar una serie de 257 (+2 por el hecho de que RLE de dos bytes es estúpido) de bytes idénticos en solo dos.
Implementación y visualización del desempacador:
void drawPico_RLE_P(uint8_t x, uint8_t y, pic_t *pPic) { uint16_t repeatColor; uint8_t tmpInd, repeatTimes; alphaReplaceColorId = getAlphaReplaceColorId(); auto tmpData = getPicSize(pPic, 0); tftSetAddrWindow(x, y, x+tmpData.u8Data1, y+tmpData.u8Data2); ++pPic;
Lo principal es no mostrar la imagen fuera de la pantalla, de lo contrario será basura, ya que no hay verificación de bordes aquí.
La imagen de prueba se descomprime en ~ 39 ms. al mismo tiempo, ocupa 3040 bytes, mientras que sin compresión tomaría 11,200 bytes o 22,400 bytes sin indexar.
Imagen de prueba (ampliada 2 veces):

En la imagen de arriba puede ver el entrelazado, pero en la pantalla se suaviza por hardware, creando un efecto similar al CRT y al mismo tiempo aumentando significativamente la relación de compresión.
RLE no es una panacea
Somos tratados por deja vu.
Como sabes, RLE va bien con los empacadores tipo LZ. WiKi acudió al rescate con una lista de métodos de compresión. El ímpetu fue el video de "GameHut" sobre el análisis de la
introducción imposible
en Sonic 3D Blast.Habiendo estudiado muchos empacadores (LZ77, LZW, LZSS, LZO, RNC, etc.), llegué a la conclusión de que sus desempacadores:
- requieren mucha RAM para datos desempaquetados (al menos 64kb. y más);
- voluminoso y lento (algunos necesitan construir árboles Huffman para cada subunidad);
- tener una baja relación de compresión con una pequeña ventana (requisitos de RAM muy estrictos);
- tener ambigüedades con las licencias.
Después de meses de adaptaciones inútiles, se decidió modificar el empaquetador existente.
Por analogía con los empaquetadores tipo LZ, para lograr la máxima compresión, se utilizó el acceso al diccionario, pero a nivel de bytes: los pares de bytes repetidos con mayor frecuencia se reemplazan con un puntero de bytes en el diccionario.
Pero hay una trampa: ¿cómo distinguir un byte de "cuántas repeticiones" de un "marcador de diccionario"?
Después de una larga sesión con un trozo de papel y un juego mágico con murciélagos, esto apareció:
- El "marcador de diccionario" es un marcador RLE (0x80) + byte de datos (0x50) + número de posición en el diccionario;
- limite el byte "cuántas repeticiones" al tamaño del marcador de diccionario - 1 (0xCF);
- el diccionario no puede usar el valor 0xff (es para el marcador del final de la imagen).
Aplicando todo esto, obtenemos un tamaño de diccionario fijo: no más de 46 pares de bytes y reducción de RLE a 209 bytes. Obviamente, no todas las imágenes se pueden empaquetar así, pero ya no se convertirán.
En ambos algoritmos, la estructura de la imagen empaquetada será la siguiente:
- 1 byte por ancho y alto;
- 1 byte para el tamaño del diccionario, es un puntero marcador al comienzo de los datos empaquetados;
- de 0 a 92 bytes del diccionario;
- 1 a N bytes de datos empaquetados.
La utilidad de empaquetador resultante en D (pickoPacker) es suficiente para colocar en una carpeta con archivos indexados * .png y ejecutar desde la terminal (o cmd). Si necesita ayuda, ejecute con la opción "-h" o "--help".
Después de que se ejecuta la utilidad, obtenemos archivos * .h, cuyo contenido es conveniente para transferir al lugar correcto en el proyecto (por lo tanto, no hay protección).
Antes de desempacar, se preparan la pantalla, el diccionario y los datos iniciales:
void drawPico_DIC_P(uint8_t x, uint8_t y, pic_t *pPic) { auto tmpData = getPicSize(pPic, 0); tftSetAddrWindow(x, y, x+tmpData.u8Data1, y+tmpData.u8Data2); uint8_t tmpByte, unfoldPos, dictMarker; alphaReplaceColorId = getAlphaReplaceColorId(); auto pDict = &pPic[3];
Una pieza de datos leída se puede empaquetar en un diccionario, por lo que lo revisamos y desempaquetamos:
inline uint8_t findPackedMark(uint8_t *ptr) { do { if(*ptr >= DICT_MARK) { return 1; } } while(*(++ptr) != PIC_DATA_END); return 0; } inline uint8_t *unpackBuf_DIC(const uint8_t *pDict) { bool swap = false; bool dictMarker = true; auto getBufferPtr = [&](uint8_t a[], uint8_t b[]) { return swap ? &a[0] : &b[0]; }; auto ptrP = getBufferPtr(buf_unpacked, buf_packed); auto ptrU = getBufferPtr(buf_packed, buf_unpacked); while(dictMarker) { if(*ptrP >= DICT_MARK) { setPicWData(ptrU) = getPicWData(pDict, *ptrP); ++ptrU; } else { *ptrU = *ptrP; } ++ptrU; ++ptrP; if(*ptrP == PIC_DATA_END) { *ptrU = *ptrP;
Ahora, desde el búfer recibido, desempaquetamos RLE de una manera familiar y lo mostramos en la pantalla:
inline void printBuf_RLE(uint8_t *pData) { uint16_t repeatColor; uint8_t repeatTimes, tmpByte; while((tmpByte = *pData) != PIC_DATA_END) {
Sorprendentemente, la sustitución del algoritmo no afectó significativamente el tiempo de desempaquetado y es de ~ 47 ms. Esto es casi 8 ms. más tiempo, ¡pero la imagen de prueba solo toma 1650 bytes!
Hasta la ultima medida
¡Casi todo se puede hacer más rápido!
A pesar de la presencia de SPI de hardware, el núcleo AVR produce mucho dolor de cabeza cuando se usa.
Desde hace tiempo se sabe que SPI en AVR, además de ejecutarse a velocidad F_CPU / 2, también tiene un registro de datos de solo 1 byte (no es posible cargar 2 bytes a la vez).
Además, casi todo el código SPI en AVR que conocí funciona de acuerdo con este esquema:
- Descargar datos SPDR
- interrogar el bit SPIF en el SPSR en un bucle.
Como puede ver, el suministro continuo de datos, como se hace en el STM32, no huele aquí. ¡Pero, incluso aquí, puede acelerar la salida de ambos desempacadores en ~ 3 ms!
Al abrir la hoja de datos y mirar la sección "Relojes del conjunto de instrucciones", puede calcular los costos de CPU al transmitir un byte a través de SPI:
- 1 ciclo para cargar registros con nuevos datos;
- 2 latidos por bit (o 16 latidos por byte);
- 1 barra por línea de reloj mágica (un poco más tarde sobre "NOP");
- 1 reloj para verificar el bit de estado en SPSR (o 2 relojes en la rama);
En total, para transmitir un píxel (dos bytes), se deben gastar 38 ciclos de reloj o ~ 425600 ciclos de reloj para la imagen de prueba (11,200 bytes).
Sabiendo que F_CPU == 16 MHz obtenemos
0.0000000625 62.5 nanosegundos por ciclo de reloj (
Proceso0169 ), multiplicando los valores, obtenemos ~ 26 milisegundos. Surge la pregunta: “¿Desde dónde escribí antes que el tiempo de desempaque es de 39 ms? y 47 ms. Todo es simple: lógica de desempaquetado + manejo de interrupciones.
Aquí hay un ejemplo de salida de interrupción:
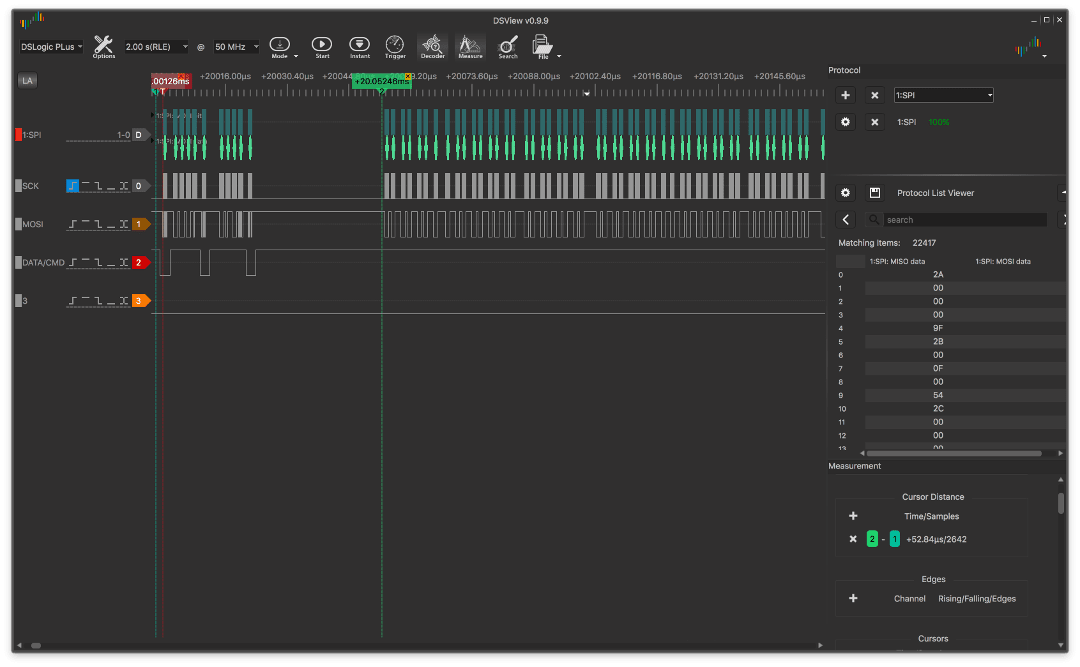
y sin interrupción:

Los gráficos muestran que el tiempo entre la configuración de la ventana de dirección en la pantalla VRAM y el comienzo de la transferencia de datos en la versión sin interrupciones es menor y casi no hay espacios entre bytes durante la transmisión (el gráfico es uniforme).
Desafortunadamente, no puedes desactivar las interrupciones para cada salida de imagen, de lo contrario el sonido y el núcleo de todo el juego se romperán (más sobre eso más adelante).
Fue escrito anteriormente sobre un cierto "NOP mágico" para una línea de reloj. El hecho es que para estabilizar el CLK y establecer el indicador SPIF, se necesita exactamente 1 ciclo de reloj y para cuando se lee este indicador, ya está configurado, lo que evita la ramificación en 2 barras en la instrucción BREQ.
Aquí hay un ejemplo sin un NOP:
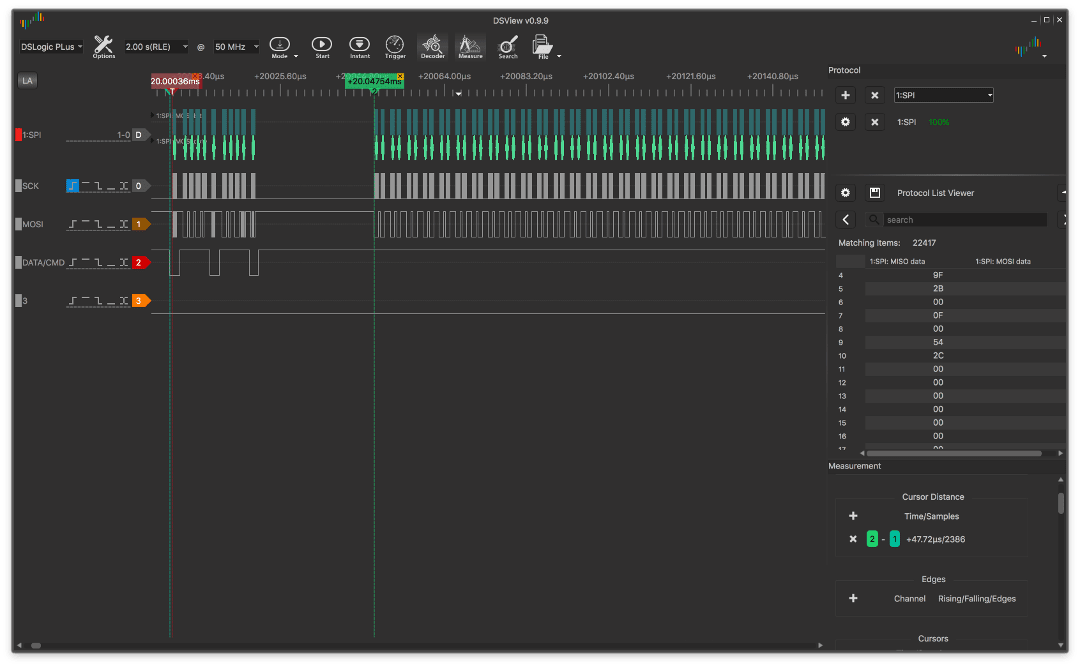
y con el

La diferencia parece insignificante, solo unos pocos microsegundos, pero si toma una escala diferente:
NOP grande:
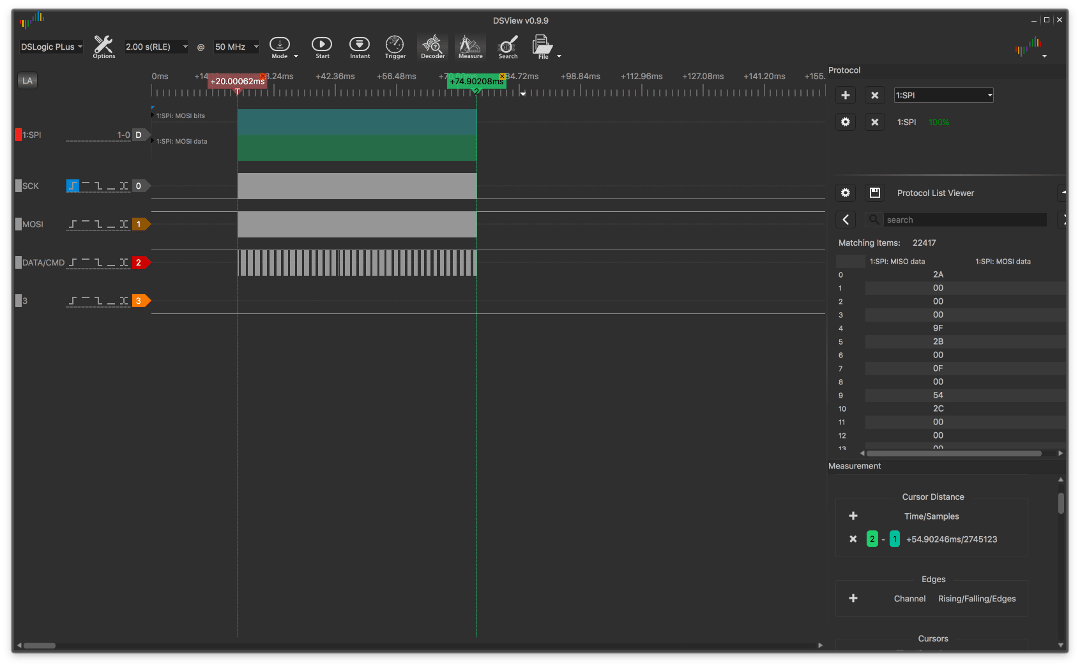
y con ella demasiado grande:

entonces la diferencia se hace mucho más notable, llegando a ~ 4.3ms.
Ahora hagamos el siguiente truco sucio:
Cambiamos el orden de carga y lectura de los registros y no puede esperar cada segundo byte del indicador SPIF, pero verifíquelo solo antes de cargar el primer byte del siguiente píxel.
Aplicamos conocimiento e implementamos la función "pushColorFast (repeatColor);":
#define SPDR_TX_WAIT(a) asm volatile(a); while((SPSR & (1<<SPIF)) == 0); typedef union { uint16_t val; struct { uint8_t lsb; uint8_t msb; }; } SPDR_t; ... do { #ifdef ESPLORA_OPTIMIZE SPDR_t in = {.val = repeatColor}; SPDR_TX_WAIT(""); SPDR = in.msb; SPDR_TX_WAIT("nop"); SPDR = in.lsb; #else pushColorFast(repeatColor); #endif } while(--repeatTimes); } #ifdef ESPLORA_OPTIMIZE SPDR_TX_WAIT("");
A pesar de la interrupción del temporizador, el uso del truco anterior proporciona una ganancia de casi 6 ms.

Así es como el simple conocimiento del hierro le permite exprimir un poco más y generar algo similar:

Colisiones del Coliseo
La batalla de las cajas.
Para empezar, todo el conjunto de objetos (barcos, proyectiles, asteroides, bonos) son estructuras (sprites) con los siguientes parámetros:
- coordenadas actuales X, Y;
- nuevas coordenadas X, Y;
- puntero a la imagen.
Como la imagen almacena el ancho y la altura, no es necesario duplicar estos parámetros, además, dicha organización simplifica la lógica en muchos aspectos.
El cálculo en sí mismo se simplifica al banal, basado en la intersección de los rectángulos. Aunque no es lo suficientemente preciso y no calcula conflictos futuros, esto es más que suficiente.
La verificación se realiza alternativamente en los ejes X e Y. Debido a esto, la ausencia de intersección en el eje X reduce el cálculo de la colisión.
Primero, el lado derecho del primer rectángulo con el lado izquierdo del segundo rectángulo se verifica para la parte común del eje X. Si tiene éxito, se realiza una verificación similar para el lado izquierdo del primer y el lado derecho del segundo rectángulo.
Después de detectar con éxito las intersecciones a lo largo del eje X, se realiza una verificación de la misma manera para los lados superior e inferior de los rectángulos a lo largo del eje Y.
Lo anterior parece mucho más fácil de lo que parece:
bool checkSpriteCollision(sprite_t *pSprOne, sprite_t *pSprTwo) { auto tmpDataOne = getPicSize(pSprOne->pPic, 0); auto tmpDataTwo = getPicSize(pSprTwo->pPic, 0); uint8_t objOnePosEndX = (pSprOne->pos.Old.x + tmpDataOne.u8Data1); if(objOnePosEndX >= pSprTwo->pos.Old.x) { uint8_t objTwoPosEndX = (pSprTwo->pos.Old.x + tmpDataTwo.u8Data1); if(pSprOne->pos.Old.x >= objTwoPosEndX) { return false;
Queda por agregar esto al juego:
void checkInVadersCollision(void) { decltype(aliens[0].weapon.ray) gopher; for(auto &alien : aliens) { if(alien.alive) { if(checkSpriteCollision(&ship.sprite, &alien.sprite)) { gopher.sprite.pos.Old = alien.sprite.pos.Old; rocketEpxlosion(&gopher);
Curva de Bezier
Rieles espaciales.
Como en cualquier otro juego con este género, las naves enemigas deben moverse a lo largo de las curvas.
Se decidió implementar curvas cuadráticas como las más simples para el controlador y esta tarea. Tres puntos son suficientes para ellos: el inicial (P0), el final (P2) y el imaginario (P1). Los dos primeros especifican el principio y el final de la línea, el último punto describe el tipo de curvatura.
Gran artículo sobre curvas.Como se trata de una curva paramétrica de Bezier, también necesita un parámetro más: el número de puntos intermedios entre los puntos inicial y final.
Total obtenemos aquí tal estructura:
typedef struct {
En él, position_t es una estructura de dos bytes de coordenadas X e Y.
Encontrar un punto para cada coordenada se calcula utilizando esta fórmula (thx Wiki):
B = ((1.0 - t) ^ 2) P0 + 2t (1.0 - t) P1 + (t ^ 2) P2,
t [> = 0 && <= 1]
Durante mucho tiempo, su implementación se resolvió de frente sin una matemática de punto fijo:
... float t = ((float)pItemLine->step)/((float)pLine->totalSteps); pPos->x = (1.0 - t)*(1.0 - t)*pLine->P0.x + 2*t*(1.0 - t)*pLine->P1.x + t*t*pLine->P2.x; pPos->y = (1.0 - t)*(1.0 - t)*pLine->P0.y + 2*t*(1.0 - t)*pLine->P1.y + t*t*pLine->P2.y; ...
Por supuesto, esto no se puede dejar. Después de todo, deshacerse del flotador no solo podría mejorar la velocidad, sino también liberar la ROM, por lo que se encontraron las siguientes implementaciones:
- avrfix;
- stdfix;
- libfixmath;
- fixedptc.
El primero sigue siendo un caballo oscuro, ya que es una biblioteca compilada y no quería meterse con el desensamblador.
El segundo candidato del paquete GCC tampoco funcionó, ya que el avr-gcc utilizado no fue parcheado y el tipo "short _Accum" no estuvo disponible.
La tercera opción, a pesar de que tiene una gran cantidad de tapete. funciones, tiene operaciones de bits codificadas en bits específicos bajo el formato Q16.16, lo que hace que sea imposible controlar los valores de Q e I.
Esta última puede considerarse una versión simplificada de "matemáticas fijas", pero la principal ventaja es la capacidad de controlar no solo el tamaño de la variable, que por defecto es de 32 bits con el formato Q24.8, sino también los valores de Q e I.
Resultados de la prueba en diferentes configuraciones:
| Tipo | IQ | Banderas adicionales | Byte ROM | Tms. * |
|---|
| flotar | - | - | 4236 | 35 |
| matemática fija | 16,16 | - | 4796 | 119 |
| matemática fija | 16,16 | FIXMATH_NO_OVERFLOW | 4664 | 89 |
| matemática fija | 16,16 | FIXMATH_OPTIMIZE_8BIT | 5036 | 92 |
| matemática fija | 16,16 | _NO_OVERFLOW + _8BIT | 4916 | 89 |
| fixedptc | 24,8 | FIXEDPT_BITS 32 | 4420 | 64 |
| fixedptc | 9,7 | FIXEDPT_BITS 16 | 3490 | 31 |
* La verificación se realizó en el patrón: "195,175,145,110,170,70,170" y la tecla "-Os".
Se puede ver en la tabla que ambas bibliotecas tomaron más ROM y se mostraron peor que el código compilado de GCC cuando se usaba flotante.
También se ve que una pequeña revisión para el formato Q9.7 y una disminución de la variable a 16 bits dio una aceleración de 4 ms. y liberando ROM a ~ 50 bytes.
El efecto esperado fue una disminución en la precisión y un aumento en el número de errores:

que en este caso no es crítico.
Asignación de recursos
Los martes y jueves trabajan solo una hora.
En la mayoría de los casos, todos los cálculos se realizan en cada fotograma, lo que no siempre está justificado, ya que puede que no haya suficiente tiempo en el fotograma para acortar algo y tendrá que engañar alternando, contando fotogramas u omitiéndolos. Así que fui más allá: abandoné por completo la dotación de personal.
Habiendo dividido todo en pequeñas tareas, ya sea: calcular colisiones, procesar sonido, botones y mostrar gráficos, es suficiente realizarlas en un cierto intervalo, y la inercia del ojo y la capacidad de actualizar solo una parte de la pantalla harán el truco.Gestionamos todo esto no una vez con el sistema operativo, sino con la máquina de estado que creé hace un par de años o, más simplemente, no con el gestor de tareas tinySM desplazado.Repetiré las razones para usarlo en lugar de cualquiera de los RTOS:- requisitos de ROM más bajos (~ 250 bytes de núcleo);
- requisitos de RAM más bajos (~ 9 bytes por tarea);
- principio de trabajo simple y comprensible;
- determinismo de comportamiento;
- se pierde menos tiempo de CPU;
- deja acceso al hierro;
- plataforma independiente;
- escrito en C y fácil de envolver en C ++;
Necesitaba mi propia bicicleta.
Como describí una vez, las tareas se organizan en una matriz de punteros a estructuras, donde se almacena un puntero a una función y su intervalo de llamada. Esta agrupación simplifica la descripción del juego en etapas separadas, lo que también le permite reducir el número de ramas y cambiar dinámicamente el conjunto de tareas.Por ejemplo, durante la pantalla de inicio, se realizan 7 tareas, y durante el juego ya hay 20 tareas (todas las tareas se describen en el archivo gameTasks.c).Primero debe definir algunas macros para su conveniencia: #define T(a) a##Task #define TASK_N(a) const taskParams_t T(a) #define TASK(a,b) TASK_N(a) PROGMEM = {.pFunc=a, .timeOut=b} #define TASK_P(a) (taskParams_t*)&T(a) #define TASK_ARR_N(a) const tasksArr_t a##TasksArr[] #define TASK_ARR(a) TASK_ARR_N(a) PROGMEM #define TASK_END NULL
La declaración de tarea en realidad está creando una estructura, inicializando sus campos y colocándola en la ROM: TASK(updateBtnStates, 25);
Cada una de estas estructuras ocupa 4 bytes de ROM (dos por puntero y dos por intervalo).Una buena ventaja de las macros es que no funciona para crear más de una estructura única para cada función.Habiendo declarado las tareas necesarias, las agregamos a la matriz y también las colocamos en la ROM: TASK_ARR( game ) = { TASK_P(updateBtnStates), TASK_P(playMusic), TASK_P(drawStars), TASK_P(moveShip), TASK_P(drawShip), TASK_P(checkFireButton), TASK_P(pauseMenu), TASK_P(drawPlayerWeapon), TASK_P(checkShipHealth), TASK_P(drawSomeGUI), TASK_P(checkInVaders), TASK_P(drawInVaders), TASK_P(moveInVaders), TASK_P(checkInVadersRespawn), TASK_P(checkInVadersRay), TASK_P(checkInVadersCollision), TASK_P(dropWeaponGift), TASK_END };
Al establecer el indicador USE_DYNAMIC_MEM en 0 para la memoria estática, lo principal a recordar es inicializar los punteros al almacén de tareas en la RAM y establecer el número máximo de ellos que se ejecutarán: ... tasksContainer_t tasksContainer; taskFunc_t tasksArr[MAX_GAME_TASKS]; ... initTasksArr(&tasksContainer, &tasksArr[0], MAX_GAME_TASKS); …
Establecer tareas para la ejecución: ... addTasksArray_P(gameTasksArr); …
La protección contra el desbordamiento se controla mediante el indicador USE_MEM_PANIC; si está seguro del número de tareas, puede deshabilitarla para guardar la ROM.Solo queda ejecutar el controlador: ... runTasks(); ...
Dentro hay un bucle infinito que contiene la lógica básica. Una vez dentro, la pila también se restaura gracias a "__attribute__ ((noreturn))".En el bucle, los elementos de la matriz se analizan alternativamente en busca de la necesidad de llamar a la tarea después de que haya pasado el intervalo.La cuenta regresiva de los intervalos se realizó sobre la base del temporizador 0 como un sistema con una cantidad de 1 ms ...A pesar de la distribución exitosa de las tareas en el tiempo, a veces se superponían (jitter), lo que causaba un desvanecimiento a corto plazo de todo y todo en el juego.Definitivamente tenía que decidirse, pero ¿cómo? Acerca de cómo se perfiló todo la próxima vez, pero por ahora intente encontrar el huevo de Pascua en la fuente.El final
Entonces, usando muchos trucos (y muchos más de los cuales no he descrito), todo resultó en una ROM de 24kb y 1500 bytes de RAM. Si tiene alguna pregunta, me complacerá responderla.Para aquellos que no encontraron o no buscaron un huevo de Pascua::
void invadersMagicRespawn(void) { for(auto &alien : aliens) { if(!alien.alive) { alien.respawnTime = 1; } } }
, ?
invadersMagicRespawn: void action() { tftSetTextSize(1); for(;;) { tftSetCP437(RN & 1); tftSetTextColorBG((((RN % 192 + 64) & 0xFC) << 3), COLOR_BLACK); tftDrawCharInt(((RN % 26) * 6), ((RN & 15) * 8), (RN % 255)); tftPrintAt_P(32, 58, (const char *)creditP0); } } a(void) { for(auto &alien : aliens) { if(!alien.alive) { alien.respawnTime = 1; } } }
«(void)» , «action()» 10 , «disablePause();». «Matrix Falling code» . 130 ROM.
Para compilar y ejecutar es suficiente poner la carpeta (o enlace) "esploraAPI" en "/ arduino / bibliotecas /".Referencias
PD: Puedes ver y escuchar cómo se ve todo un poco más tarde cuando hago un video aceptable.